基于深度強化學習的水聲網絡公平跨層MAC協議
2024-09-22 00:00:00韓翔張育芝李夢凡馮曉美
現代電子技術 2024年17期
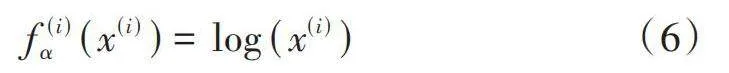
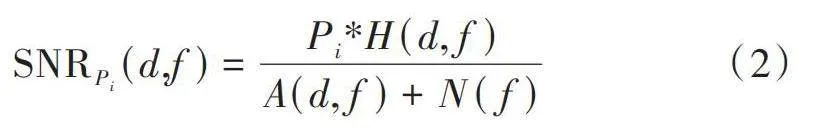

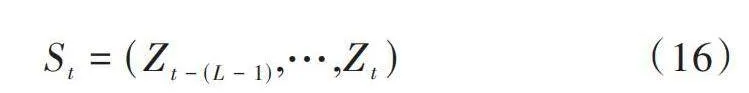
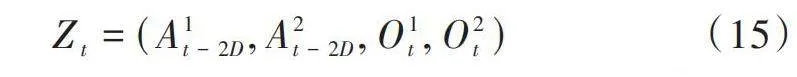
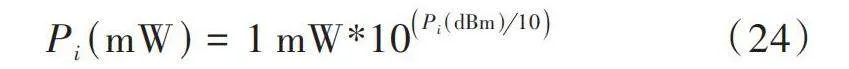
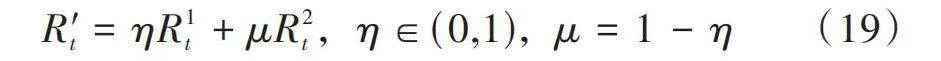
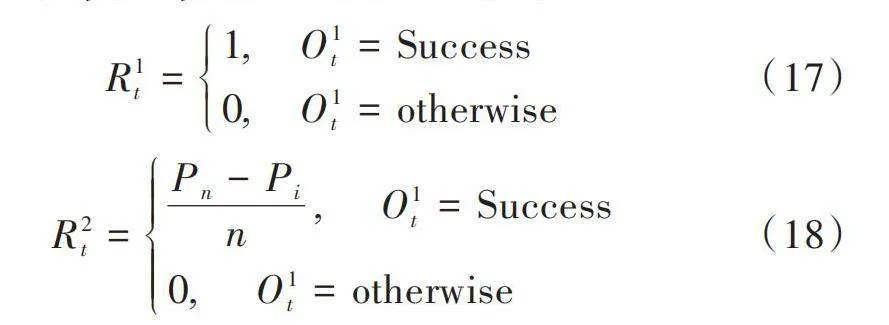
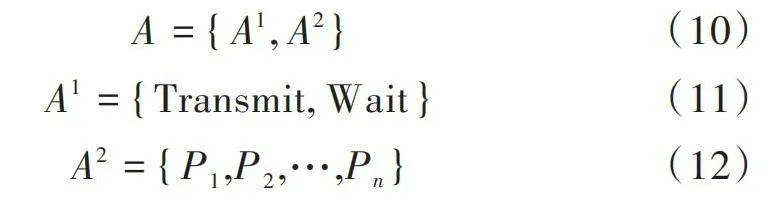

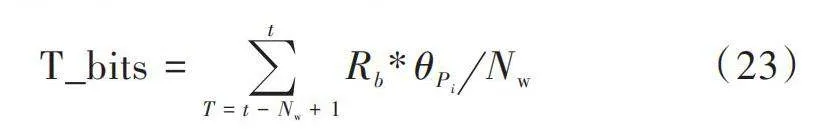
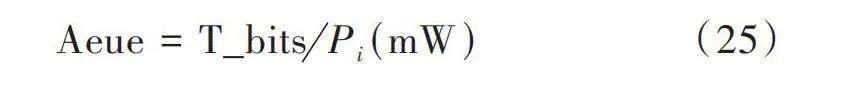
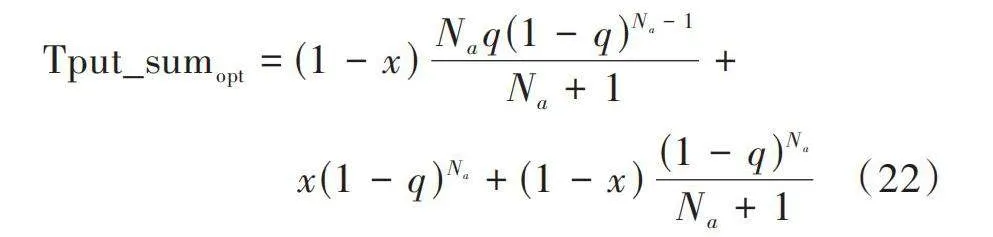


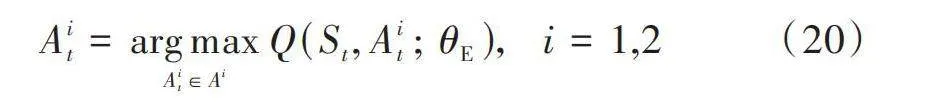
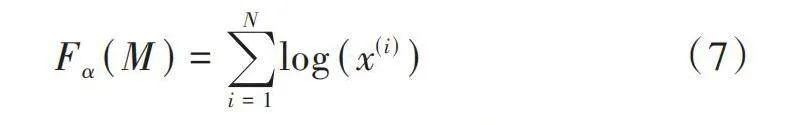



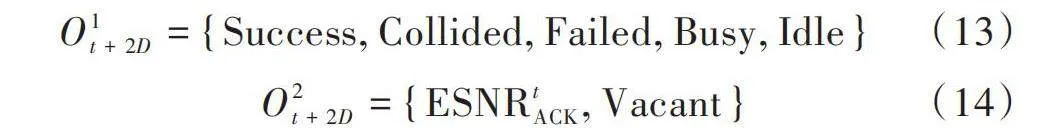
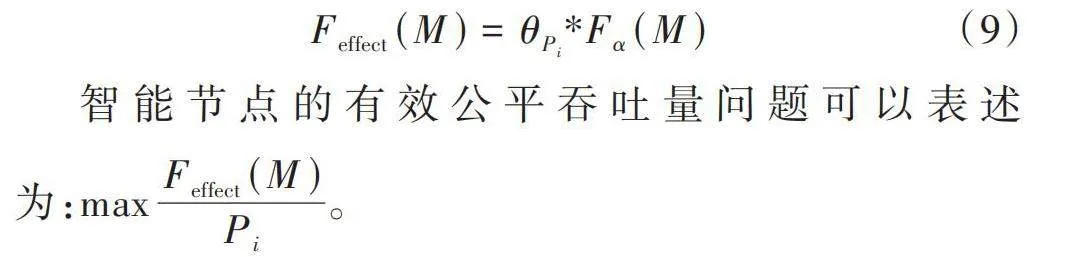
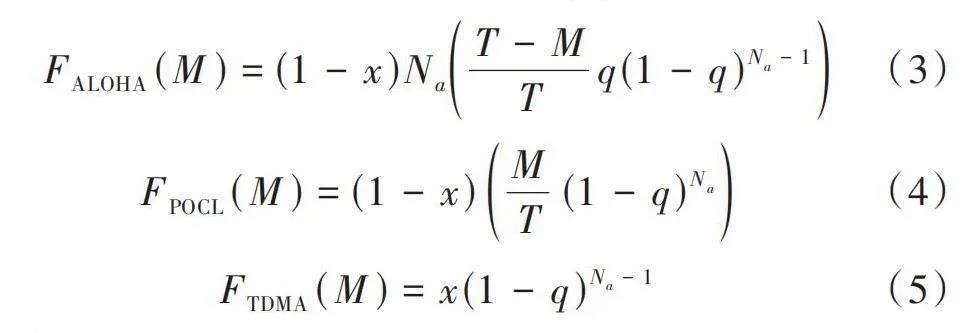
摘" 要: 針對水聲通信異構網絡中信道分配不公和節點能量受限的問題,基于深度強化學習方法,提出跨層聯合優化公平信道接入和功率控制的媒介訪問控制(POCL?MAC)協議。根據反饋ACK包獲知時延狀態下的信道沖突結果和接收機處信噪比,基于深度強化學習的狀態、動作和獎勵序列自主學習,調整認知用戶的接入時隙和發射功率;采用公平函數實現異構網絡中認知用戶和主用戶吞吐量性能的比例公平。設計了一個聯合狀態序列和獨立式獎勵函數,在不增加神經網絡復雜度的前提下,提高跨層聯合優化的子動作決策準確度。仿真結果表明,相比于傳統DRL算法,所提算法實現了接近于最優公平性吞吐量性能,同時具有更好的能量利用效率。
關鍵詞: 深度強化學習; 水聲通信網絡; MAC協議; 沖突避免; 功率優化; 信道分配
中圖分類號: TN929.3?34" " " " " " " " " " " " " 文獻標識碼: A" " " " " " " " " " " "文章編號: 1004?373X(2024)17?0001?09
Deep reinforcement learning based proportional?fair optimized cross?layer MAC
protocol for underwater acoustic networks
HAN Xiang, ZHANG Yuzhi, LI Mengfan, FENG Xiaomei
(College of Communication and Information Engineering, Xi’an University of Science and Technology, Xi’an 710054, China)
Abstract: In view of the unfair channel allocation and energy?constrained nodes in underwater acoustic communication heterogeneous networks, a proportional?fair optimized cross?layer medium access control (POCL?MAC) protocol is proposed based on deep reinforcement learning (DRL). It strives to optimize fair channel access and power control by cross?layer joint. By feedback ACK packets, the channel conflict outcomes and receiver?side signal?to?noise ratio (SNR) under delay status are obtained. Autonomous learning is carried out based on the state, action and reward sequence of DRL to adjust the access slot and transmission power of cognitive users. Fairness function is employed to achieve proportional fairness between cognitive users and primary users′ throughput performance in heterogeneous networks. A joint state sequence and independent reward function are designed to enhance the accuracy of sub?action decisions in cross?layer joint optimization without increasing neural network complexity. Simulation results demonstrate that the proposed algorithm can achieve near?optimal fairness throughput performance while exhibiting better energy utilization efficiency in comparison with the traditional DRL?based algorithms.
Keywords: DRL; underwater acoustic communication network; MAC protocol; conflict avoidance; power optimization; channel allocation
0" 引" 言
海洋監測、水下探索等領域中,水聲傳感器網絡[1](Underwater Acoustic Sensor Networks, UWANs)發揮了重要作用。UWANs依賴水聲信道,其特性包括傳輸延遲長、帶寬資源稀缺、多徑和多普勒效應、能量限制等[2]。這些獨有特性要求重新設計媒介訪問控制(Media Access Control, MAC)協議,以適應水下環境。水下MAC協議的設計必須考慮時空不確定性[3]導致的接收端沖突。水聲環境中能量受限,設計MAC協議必須減少無效的重傳成本。這要求信道資源合理分配單次的傳輸能耗。
早期研究致力于緩解UWANs中長時延帶來的碰撞問題[4?6]。這些研究減少了數據包沖突,但沒有在長時延條件下提高吞吐量。為了充分利用信道資源,提出一些自適應算法,如:信道感知ALOHA協議[7]、DOTS協議[8]等。這些算法通常基于特定模型,并需要完整的網絡先驗信息,實現在特定場景下的最優決策。但是由于水聲網絡具有復雜的時空特性,這些網絡先驗信息是動態變化的,很難實時獲取。此外,水聲通信網絡中的能量效率問題也一直是關注的重點。經典的能耗解決方案是設計睡眠/喚醒機制[9]以及使用最大功率的控制包[10]。由于水聲信道的快速時變性,基于時不變模型的功率控制方法容易受到干擾或者消耗大量能量。自適應傳輸功率控制方法是根據傳輸距離和噪聲干擾等自動調整傳輸功率[11?13],以降低網絡中的整體能耗。這些數據鏈路層的協議,通過調整傳輸功率,縮小傳輸范圍,減少沖突情況。這些分層協議設計沒有考慮實際路徑損耗,在強時變水聲信道下,對于能量利用效率的提升比較有限。
近年來深度強化學習(Deep Reinforcement Learning, DRL)技術已被應用于MAC協議設計中[14]。DRL結合了深度神經網絡(Deep Neural Network, DNN)的多維感知能力和強化學習的自主決策能力。在地面無線網絡中,基于DRL的DeepMAC框架[15]將協議解耦為一組參數模塊,用作DRL輸入并以模塊化方式分析學習。基于DRL的DLMA協議[16]用于解決異構網絡中的信道公平性沖突避免問題,用戶在每個時隙選擇是否傳輸,根據傳輸結果獲得獎勵。基于DRL的Dueling?DDQN算法被提出[17],以便在快速變化的無線通信網絡中最大限度地提高系統吞吐量。由于水聲信道長時延等特性,這些基于地面無線網絡的DRL方法協議不再適用于水聲信道。
水聲通信網絡中,DR?DLMA協議[18]將長時延納入DRL框架中以適應水聲信道。DL?MAC協議[19]學習并利用長時延特性,通過同步或異步傳輸模式提高系統吞吐量。但是這些協議沒有考慮水聲信道的時變衰減特性,忽視了能量效率問題。文獻[20]通過DRL根據反饋鏈路的信道狀態預測前饋信道,聯合調度發射功率、調制順序和編碼速率,在物理層優化能效。文獻[21]明確指出,跨層設計有益于協同調度資源以提高用戶能量效率。文獻[22]提出了集群UWANs的聯合時隙調度和功率分配的跨層協議,但其目標在于實現最佳吞吐量性能而非能量利用效率,同時代價是復雜度高。上述文獻均未考慮從物理層和數據鏈路層跨層聯合優化來提高節點能量效率。
為解決水聲異構網絡中公平信道接入和功率控制聯合優化問題,本文提出了基于深度強化學習的公平優化跨層動作媒介訪問控制(POCL?MAC)協議。應用聯合狀態和獨立獎勵的設計有助于節點準確判斷系統狀態,提高兩種子動作決策效率,實現強時變性環境下的穩定決策。最后,通過仿真實驗對本文所提方法的公平性吞吐量和能量效率的收斂性能和穩定性能進行了驗證。
1" 水下無線通信網絡系統模型
1.1" 水聲異構網絡模型
本文考慮一個數據收集UWANs異構網絡模型,包括[N]個傳感器節點,如圖1所示。設UWANs模型中包括TDMA協議節點、ALOHA協議節點和POCL?MAC協議智能節點。異構網絡涵蓋了多種協議,不失一般性,本文考慮基于固定分配的TDMA協議和隨機接入的ALOHA協議,并將其作為主用戶。POCL?MAC協議智能節點則視作認知用戶,自主選擇空閑時隙接入信道。這[N]個節點以時隙方式,通過一個共享的水聲上行鏈路將數據包傳輸到目的浮標,即接收端(Access Point, AP)。AP在一個時隙只能成功接收一個數據包,若接收到多個數據包則產生信道沖突。
POCL?MAC協議中,智能節點首先隨機決定在當前時隙是否傳輸數據包。若傳輸,智能節點再隨機選擇傳輸功率。無論智能節點是否傳輸數據包,都將接收到來自AP的ACK消息。根據ACK消息,智能節點獲知信道沖突狀態以及信道衰減信息。此后,智能節點根據已有信息決定是否傳輸數據包,并選擇相應的傳輸功率,最終根據反饋信息學習并調整節點傳輸策略。
由三個節點組成的時隙沖突模型如圖2所示。由于節點間的傳輸時延差,在一個時隙內,TDMA和ALOHA節點發送的數據包將分別在不同的時隙內被AP接收,在接收端不會造成沖突,在不同時隙內發送的數據包可能會同時到達AP,導致接收端沖突,這與傳統的地面無線通信理論相悖。雖然TDMA和ALOHA這些已有節點的沖突無法避免,但本文所提出的協議旨在學習各節點發送機制在時延條件下的信道沖突結果,避免沖突,利用信道中空閑的時隙進一步提高網絡吞吐量。
由于水聲信道的復雜特性,在設計MAC協議時必須要考慮到信道的影響,如時延的大小、多徑和多普勒效應帶來的路徑損耗,以及各種噪聲對接收端的干擾等因素。
1.2" 水聲信道特性
對于一個特定的節點[i],[i∈{1,2,…,N}]。設節點[i]和AP之間的距離為[di]。因此,節點[i]到AP之間的傳輸延遲[Di]為:
[Di=dic-τ] (1)
式中:[c]為UWANs中的聲速;[τ]為系統中一個時隙的時間單位;[x]為大于[x]的最小整數。因此,[Di]的物理意義是從節點[i]發送數據包到AP或從AP反饋ACK包所需的時隙數。在實際應用中,不同節點與AP之間的距離與傳輸延遲不同。本文協議中智能節點無需獲取各節點的傳輸時延,即可實現可靠的沖突避免,提高網絡吞吐量。
在一定信道估計和信道均衡算法的前提下,影響系統性能的因素主要取決于信噪比。UWANs中的信道衰減通常由信道大尺度衰落和時變的多徑衰落來描述。受風浪、湍流等因素影響,水聲信道瞬時信道衰減會產生變化,從而影響瞬時接收的信噪比。在接收端平均窄帶信噪比為:
[SNRPi(d,f)=Pi*H(d, f)A(d, f)+N(f)] (2)
式中:[Pi]為信號傳輸功率;[H(d, f)]為信道增益;[A(d, f)]為傳播損失;[N(f)]為環境噪聲。接收端的BER隨著接收端SNR的增加而減小,當接收端信噪比足夠大,使誤碼率在接收端可容忍范圍內,數據包才能被正確接收和解調。在時變信道下為了保證正確的接收與解調,非自適應系統通常采用較高的傳輸功率,但是能耗也隨之增加。由于水聲網絡系統中能量嚴重受限,在時變信道下必須考慮自適應調整發送功率,以取得更優的能量利用效率。
1.3" 目標函數
本文提出了一種用于水聲信道基于DRL的比例公平的跨層聯合優化MAC協議,即POCL?MAC協議。該協議實現的目標是:通過跨層聯合優化數據鏈路層,接入分配和物理層功率分配,最大化上行網絡能量利用效率。智能節點動態學習整體網絡中的信道沖突結果,并在空閑時隙接入網絡,實現公平吞吐量的最大化。同時,在保證數據包傳遞效率的前提下,通過選擇最優的傳輸功率來降低功率消耗,提高能量利用效率。
為了衡量系統沖突,定義[F(M)]為沖突避免概率函數。沖突避免概率函數與TDMA節點占用的時隙比例[x]、ALOHA節點的發送概率[q]有關。在已知[x]和[q]的情況下,各節點沖突避免概率即各節點單位吞吐量為:
[FALOHA(M)=(1-x)NaT-MTq(1-q)Na-1] (3)
[FPOCL(M)=(1-x)MT(1-q)Na] (4)
[FTDMA(M)=x(1-q)Na-1] (5)
式(3)~式(5)分別表示ALOHA節點、智能節點和TDMA節點的單位吞吐量。其中[Na]為ALOHA節點數量。智能節點在每[T]個時隙中,學習選擇無沖突的時隙,此時發送的時隙數為[M],達到最大化沖突避免概率,實現最大總吞吐量的目標。
然而在異構網絡中,智能節點會與其他競爭型節點競爭,以最大總吞吐量作為系統性能指標,會占用其他競爭型節點的時隙,造成信道資源的不公平分配。因此,本文采用基于公平的吞吐量來調整系統性能的度量指標。對于一個特定的節點[i],其吞吐量表示為[x(i)],則其比例公平性吞吐量定義如下:
[f(i)α(x(i))=log(x(i))] (6)
因此最大比例公平性吞吐量為:
[Fα(M)=i=1Nlog(x(i))] (7)
設智能節點在時隙[t]發送一個功率為[Pi]的數據包,則數據包投遞率如下:
[θPi=Pr{BERPi≤δ}] (8)
式中[δ]為接收端可正確解調的最小誤碼率門限。考慮沖突避免和數據包投遞率因素,定義有效公平吞吐量為:
[Feffect(M)=θPi*Fα(M)] (9)
智能節點的有效公平吞吐量問題可以表述為:[maxFeffect(M)Pi]。
在實際中,由于水聲信道的先驗信息很難獲取,因此本文采用DRL技術來自主學習,解決復雜水聲信道中MAC的設計問題。
2" 基于DRL的跨層聯合優化MAC協議
2.1" 系統設計
POCL?MAC協議中DRL的動作、狀態和獎勵的定義如下。
動作:使用POCL?MAC協議的節點視為智能節點。在每個時隙中,智能節點需要決定以何種功率訪問信道。將智能節點的動作集定義為:
[A={A1, A2}] (10)
[A1={Transmit, Wait}] (11)
[A2={P1,P2,…,Pn}] (12)
在學習的初始化階段,智能節點將隨機選擇動作[A1t]確定是否傳輸數據包,如果智能節點將發送,再選擇動作[A2t=Pi],以功率[Pi]向AP發送數據包。經過一個傳輸時延[D],AP在時隙[t+D]接收到數據包并反饋ACK信號給智能節點。智能節點在時隙[t+2D]中從ACK信號得到對應的觀測值[O1t+2D]和[O2t+2D]。
[O1t+2D={Success, Collided, Failed, Busy, Idle}" " "] (13)
[O2t+2D={ESNRtACK, Vacant}] (14)
式(13)中等號右側各項分別表示傳輸成功、信道沖突導致傳輸失敗、功率不足而傳輸失敗、信道被其他節點占用、信道處于空閑狀態。[O2t+2D]中如果智能節點成功傳輸數據包,則記錄時隙[t]的信道狀態信息,否則,信道狀態信息為空。智能節點在時隙[t+2D]接收到ACK信號后,根據觀測值[O1t+2D]獲知時隙[t]中智能節點發送的數據包是否被AP成功接收,根據觀測值[O2t+2D]獲知時隙[t]的信道狀態信息。在一定的初始化階段后,智能節點可以根據已有的知識進行在線學習:如果[A1t=Wait],表示智能體不發送數據包,則[A2t=NULL],智能節點在時隙[t]無需選擇功率;如果[A1t=Transmit],則根據反饋的SNR信息,選擇一個最優的傳輸功率[A2t=Pi]。
狀態:將系統狀態定義為動作和觀測值的序列耦合。在時隙[t]中,智能節點收到先前動作[A1t-2D]、[A2t-2D]產生的觀測值[O1t]、[O2t],將對應的[A1t-2D]、[A2t-2D]和[O1t]、[O2t]組合,構成一組動作?觀測對:
[Zt=(A1t-2D, A2t-2D, O1t, O2t)] (15)
因為時變系統中單組動作?觀測對無法準確表征短期內的信道狀態變化,也無法準確擬合信道狀態,一組動作?觀測對的長期序列可以更好地表征短期信道特征從而提高決策性能。因此,時隙[t]中智能節點的狀態[St]定義為:
[St=(Zt-(L-1),…,Zt)] (16)
式中[L]表示歷史狀態序列長度。當前系統狀態由時隙[t]及其之前共[L]個動作?觀測對組成。[L]值越大,系統狀態越能夠更好地表征信道沖突和信道衰減情況,使智能節點更好地學習系統的運行規律,做出更好的決策。
獎勵:獎勵的計算取決于系統的目標,即在單位能量下最大化有效公平吞吐量。因此獎勵與AP的接收結果直接相關,[R1t]和[R2t]由以下表達式給出:
[R1t=1," " "O1t=Success0," " "O1t=otherwise] (17)
[R2t=Pn-Pin," " " O1t=Success0," " " O1t=otherwise] (18)
公式(17)中[R1t]取決于智能節點是否發送與沖突結果,只有當智能節點完成無沖突傳輸時,獎勵為1,否則為0。單位吞吐量可通過對一個窗口長度內所有[R1t]取平均計算得出,用于公式的公平性優化目標。公式(18)中[R2t]取決于智能節點消耗的功率。其中[i∈(1, n)],[if" "ilt;j, Pilt;Pj]。智能節點所選擇的功率[Pi]越大,其[R2t]越小,使得其趨于選擇較小但能夠成功傳輸的功率來節約能耗。智能節點根據單步的獎勵值,決定其下一步的動作選擇,每一步都選擇最優的動作,每一步均實現最優的單位能量有效公平吞吐量。通過對這兩個獨立目標的分別優化,最終實現系統能量利用效率最大的目標。
2.2" 聯合狀態獨立獎勵算法
1) 獨立獎勵優化策略
在跨層聯合優化DRL算法中,分別考慮了接入分配策略和功率優化策略,優化吞吐量獎勵[R1t]和能耗獎勵[R2t]。吞吐量獎勵[R1t]需要獨立估值,并計算用于協調智能節點發送策略的公平函數。吞吐量獎勵[R1t]和能耗獎勵[R2t]的優化目標相對獨立。[R1t]的目標是最大化時隙利用率,而[R2t]的目標是最小化單位能耗。它們的獎勵函數式(17)和式(18)是階躍函數和歸一化的離散函數,獎勵函數之間的相關性較弱。
在處理由兩個子動作組成的問題時,傳統的DRL算法只能優化加權獎勵。加權獎勵如式(19)所示:
[R′t=ηR1t+μR2t,η∈(0,1),μ=1-η] (19)
式中:[η]和[μ]分別是[R1t]和[R2t]的權重因子,權重因子確定接入分配和功率優化的重要性。基于權重因子的策略通常會以犧牲一個目標的利益來保護另一個目標,這會導致系統達到次優解。
為了避免權重因子造成的決策偏頗,本文分別優化[R1t]和[R2t]以實現接入分配和功率優化的目標。多目標系統中,獨立學習可以避免偏見決策,更好地實現公平接入分配和功率優化目標。
2) 聯合狀態優化策略
本文系統中,功率優化子動作依賴于物理層反饋信道狀態信息,這些信息又受數據鏈路層信道接入信息的影響。將接入分配的狀態和反饋信道狀態信息組合,聯合的狀態[St]將包括完整的歷史[L]組動作?觀察對[Zt=(A1t-2D, A2t-2D, ][O1t, O2t)],這種跨層的聯合狀態集有助于智能節點獲取更全面的信息,通過循環神經網絡充分考慮歷史的沖突狀態和信道狀態,更好地匹配狀態[St]和實際信道狀態信息,以做出更優的決策。
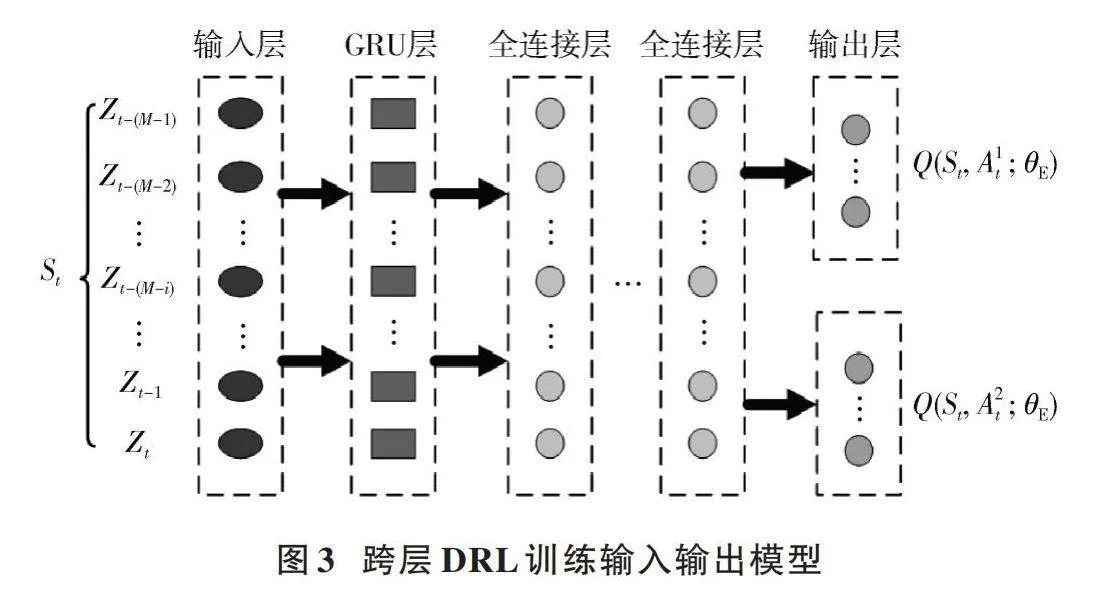
因此,必須采用一種聯合狀態獨立獎勵的跨層聯合優化DRL算法,以有效學習基于歷史聯合狀態信息的信道接入和信道狀態信息。這種算法旨在實現最佳的接入和功率策略,確保網絡吞吐量穩定,并最小化智能節點的能量消耗。跨層DRL訓練輸入輸出模型如圖3所示。
2.3" 系統整體網絡模型
系統整體網絡模型如圖4所示。
狀態[St]輸入DRL網絡,經過訓練后輸出公平吞吐量和功率優化的兩個[Q]表,即[Q(St, A1t;θE)A1t∈A1]和[Q(St, A2t;θE)A2t∈A2],從而選擇出兩個子動作值[A1t]和[A2t]。從環境中獲得觀察值并計算獎勵[R1t+2D]和[R2t+2D],環境狀態成為[St+1]。將單次經驗樣本[et=(St, A1t, A2t, R1t, R2t, St+1)]存入經驗池。智能節點以概率[ξ]隨機選擇動作,或以概率[1-ξ]根據公式分別決定其下一步動作[A1t]和[A2t]:
[Ait=argmaxAit∈AiQ(St, Ait;θE), i=1,2] (20)
更新損失函數時,使用從經驗池中隨機抽取的[NE]個經驗組成的一批次樣本[B]來計算損失函數,訓練網絡損失函數更新公式如下:
[Loss(θ)=1NEt∈By-Q(St, At;θE)2] (21)
式中[y=rt+2D+1+γmaxA'Q(St+2D+1,S',θ-)]為智能節點的目標值。利用隨機梯度下降(Stochastic Gradient Descent, SGD)方法最小化上述損失函數,更新eval?網絡的參數[θ]。更新后的訓練網絡與新的近似[Q]函數用于時隙[t+1]中智能節點的決策。
整體流程如算法1所示。
算法1:聯合狀態?獨立獎勵的跨層聯合優化DRL算法
1.初始化DRL算法的基本參數和數據結構;
2.開始迭代,直至完成預設的時隙數;
3.輸入當前狀態[St]到評估網絡,輸出所有動作的[Q]值,形成兩個[Q]表;
4.以概率[ξ]選擇隨機動作[A1t]和[A2t];
5.否則,根據貪婪策略公式(20),從[Q1]和[Q2]中選擇[A1]和[A2];
6.執行[A1]和[A2],獲得對應的觀測值[O1t]和[O2t],根據公式(17)、公式(18)計算獎勵[R1t]和[R2t],根據式(15)、式(16)更新并生成[St+1];
7.將[(St,A1t,A2t,R1t,R2t,St+1)]存儲進經驗池[EN];
8.從經驗池[EN]采樣并重組[NE]個匹配經驗樣本;
9.利用SGD法最小化損失函數式(21),更新eval?網絡的參數[θ]。
3" 仿真設置和性能分析
3.1" 仿真設置
3.1.1" 水聲網絡系統設置及性能指標
本文研究的是一個水聲異構網絡,其中包含一個POCL?MAC智能節點、一個TDMA節點和一個ALOHA節點。仿真信道中,ALOHA節點以概率[q=0.2]隨機發送數據包,TDMA節點則在每10個時隙中固定選擇2個時隙進行發送,即時隙占用比例[x=0.2]。
本文以具有完全感知能力的節點在相同場景下的結果作為測試最優值。若已知優先節點的MAC機制,則總和理論最優公平吞吐量為:
[Tput_sumopt=(1-x)Naq(1-q)Na-1Na+1+x(1-q)Na+(1-x)(1-q)NaNa+1] (22)
式中:等號右側分別代表ALOHA節點、TDMA節點和智能節點的理論最優公平吞吐量。智能節點需要與競爭型的ALOHA節點競爭時隙接入機會,因此必須考慮基于比例公平的吞吐量。
本文將ALOHA節點和TDMA節點視為主要用戶,設其使用較大的功率進行發送以對抗信道衰減,在不與智能節點和其他MAC協議節點發生沖突的情況下,其傳輸必定會被接收端接收。智能節點作為認知用戶,必須智能地感知信道避免沖突,實現最大的總和理論最優公平吞吐量,并優化功率以實現最優的能量利用效率。設接收端所需數據包功率至少為[0 dBm]以保證正確解調,同時設智能節點的發射功率[Pj]單位為[dBm],取值區間為[[12,26]],量化級數為15。此外,發射功率等于0代表不發送。
在本文中,智能節點的目標是能量利用效率最大化,由單位時間內傳輸比特數和單位時間能量消耗決定。其中,傳輸比特數的定義如下:
[T_bits=T=t-Nw+1tRb*θPi" Nw] (23)
式中:[Nw]為平滑窗口;[Rb]為固定的信息發送速率,為3 000 b/s;[θPi]為數據包投遞率。發送功率[Pi]換算成以mW為單位,便于計算能量利用效率,其換算公式為:
[Pi(mW)=1 mW*10Pi(dBm)10] (24)
因此每毫瓦能量成功發送的比特數即平均能量利用效率,為:
[Aeue=T_bitsPi(mW)] (25)
3.1.2" 深度強化學習參數設置
DRL算法中使用的RNN架構是兩個雙層全連接的神經網絡,都擁有一個GRU層和兩個Dense層,每層中有32個隱藏神經元。GRU層和Dense層神經元的激活函數分別是Tanh和ReLU函數。DRL算法的狀態、行動和獎勵遵循先前的定義。狀態歷史長度[L]為20,當更新DNN的權重時,從一個包含1 000個先前經驗的經驗回放庫中隨機選擇64個小批經驗樣本,用于計算損失函數。經驗池以FIFO的方式進行更新,采用RMSProp算法進行隨機梯度下降,采用自適應[ε]貪婪算法使決策策略適應未來的變化。
3.1.3" 基于BELLHOP的統計仿真信道模型設置
本文采用基于BELLHOP的統計仿真信道模型[23],仿真一個淺海中頻近距離時變信道。BELLHOP通過設置特定的信道參數,包括聲速、吸收系數、頻率等以研究信道的時變性。具體的信道參數設置如表1所示。
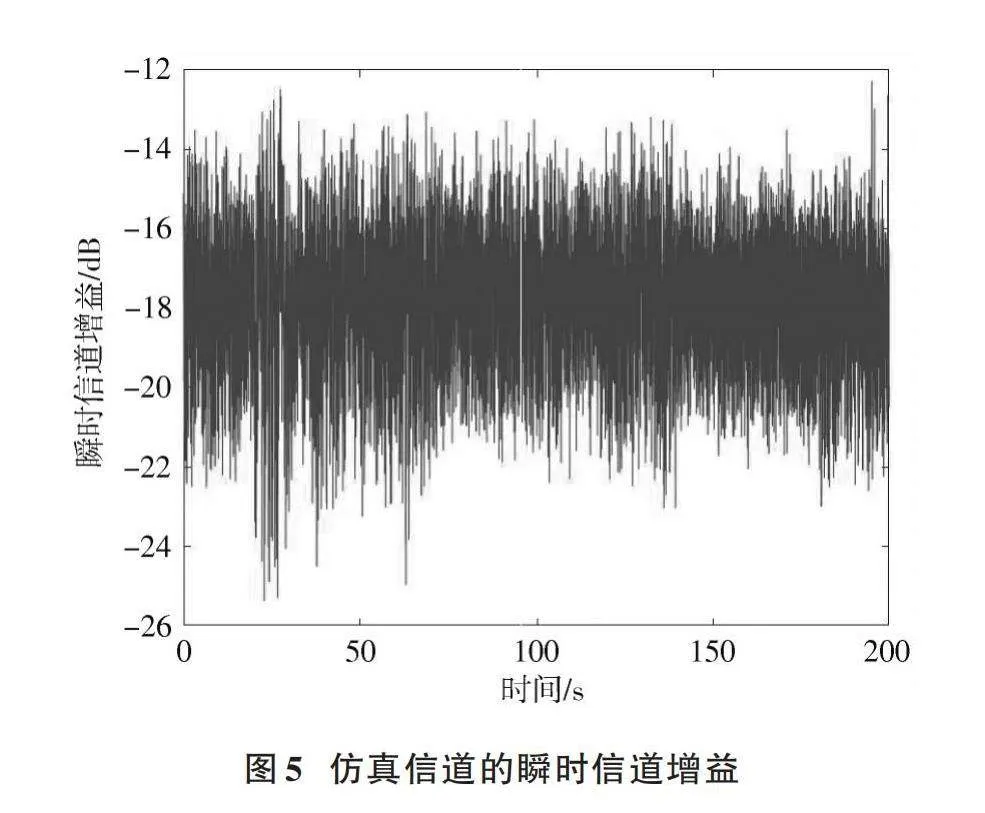
所建立的水聲信道中瞬時信道增益如圖5所示。仿真水聲信道增益在[-12,-26]dB范圍內呈現明顯的波動性和時變性。受自然因素、機械噪聲等影響,水聲信道增益呈現出隨機波動的特征。
3.2" 仿真信道下的測試結果
本文比較了POCL?MAC算法在有或沒有跨層設計的GRU和DNN網絡設置下的性能。
1) POCL?MAC:采用GRU網絡和跨層設計的POCL?MAC。
2) NCL?GRU:基于DRL的分層設計MAC。它將利用兩個獨立的GRU網絡,兩個行動決策之間沒有信息交互。
3) CL?DNN:基于DRL的跨層設計MAC。它將使用DNN網絡而不是GRU網絡,在行動決策之間存在信息交互,然而,它缺乏保留歷史狀態信息的能力。
4) Optimal:該節點的理論最優值。
3.2.1" 吞吐量和公平性
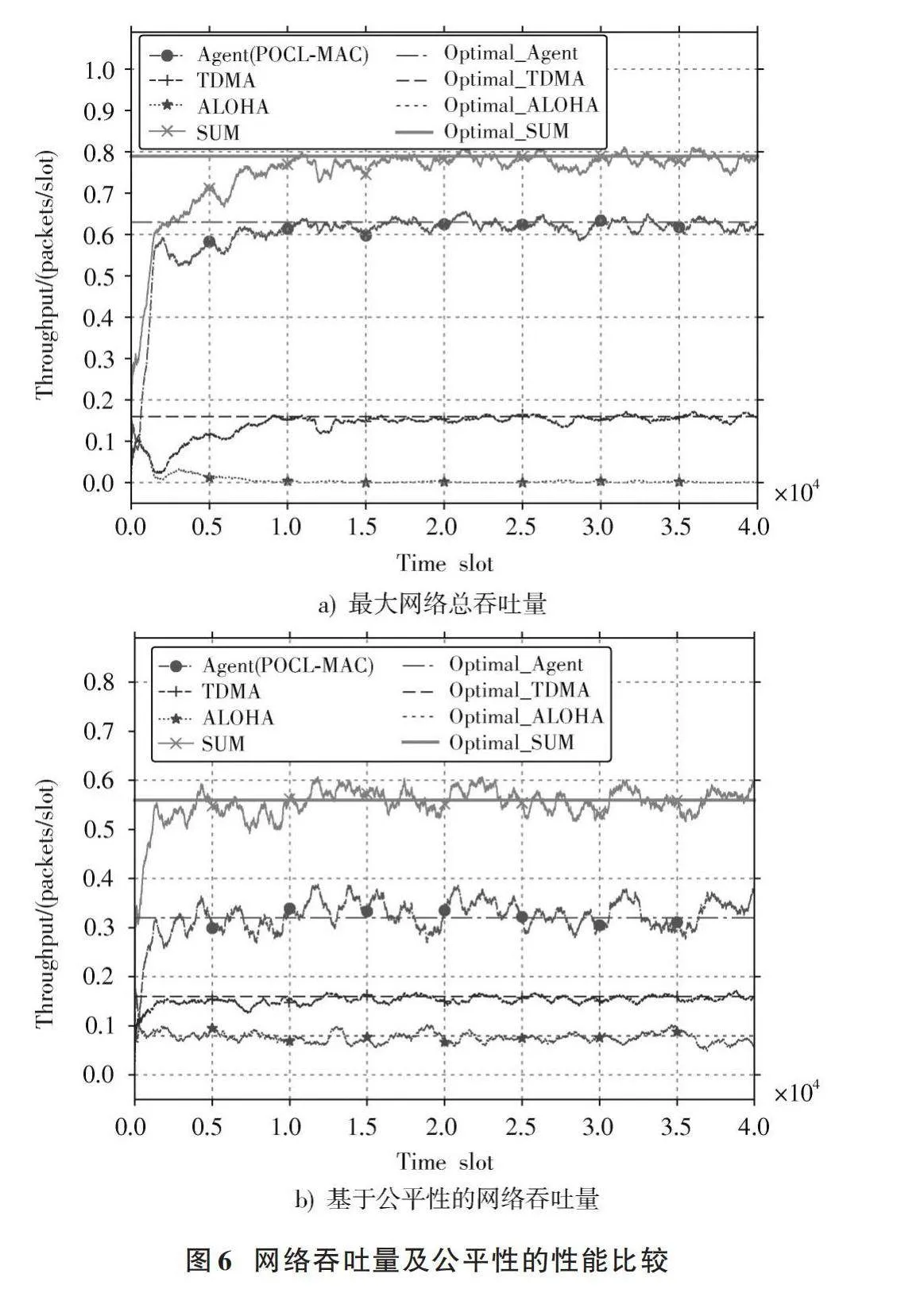
仿真信道下,本文提出的MAC協議的網絡吞吐量和公平性的性能比較如圖6所示。
不考慮公平性的基于DRL的MAC協議如圖6a)所示。智能節點和TDMA節點分別達到了最大吞吐量0.621和0.161,然而ALOHA節點的吞吐量為0.003。TDMA節點和ALOHA節點在每時隙內有[q?(1-x)+x?(1-q)+][x?q=0.36]的固定概率占用信道。因此,POCL?MAC節點達到最大吞吐量,意味著它占用了競爭型ALOHA節點所有的接收時隙。在不考慮公平性的情況下,系統的目標是實現最優的總體網絡吞吐量。智能節點占用信道的吞吐量大于避讓發送的吞吐量,盡管這會造成大量沖突。具有固定發送時隙的TDMA節點則不會與競爭型節點競爭信道。這種場景實現的最優總體網絡吞吐量,對于網絡中其他競爭型的節點不公平。
如圖6b)所示,考慮公平性的POCL?MAC協議,系統達成了節點的公平性。ALOHA節點和TDMA節點收斂后達到了各自的最優公平吞吐量的95.64%和96.98%,且表現穩健。根據公式(22),總吞吐量的最優值為0.560,實際總吞吐量為0.559,達到了最優值的99.76%。智能節點依然占用了極少量的ALOHA時隙,使得ALOHA節點吞吐量略低于理論值。但是通過公平性調度,主動退避發送,這避免了與ALOHA節點的絕大多數沖突。該系統保證了在異構網絡中主要用戶和認知用戶均能保持比例公平性。
3.2.2" 系統通用性
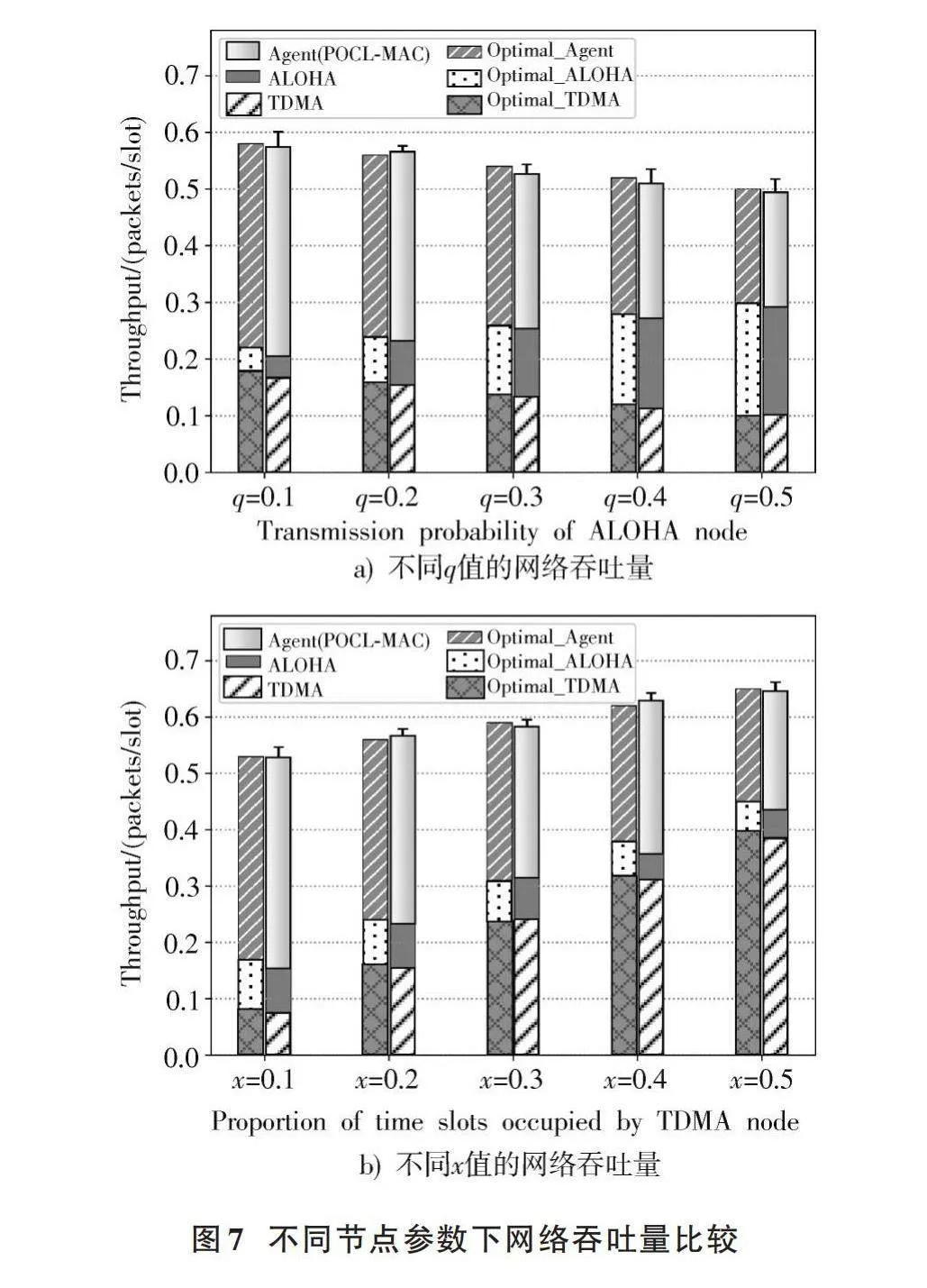
為了驗證系統在各場景下的通用性,首先模擬了具有不同[q]值的ALOHA節點的場景。設TDMA節點時隙占用率[x]=0.2。ALOHA節點的發送概率[q]從0.1增加到0.5。從圖7a)可以看出,POCL?MAC可以在多次實驗中各節點均達到對應的吞吐量。隨著[q]值的增加,顯然ALOHA的吞吐量也隨著增加,TDMA和POCL?MAC的吞吐量均有所下降。隨著ALOHA更積極地接入信道,ALOHA和TDMA的沖突隨之增加。雖然TDMA節點的發送策略保持不變,其吞吐量由于沖突而下降。POCL?MAC則是為了避免與ALOHA的沖突,采取了保守策略,主動減少了發送頻率。
其次,模擬了具有不同時隙占用率的TDMA節點的場景。ALOHA節點的發送概率[q]固定為0.2。TDMA節點的時隙占用率[x]從0.1增加至0.5。從圖7b)可以看出,POCL?MAC在這種場景隨著[x]的增加,TDMA的吞吐量有所下降。
值得注意的是,網絡總吞吐量隨著[x]的增加而增加,而隨著[q]值的增加而減少。這是因為ALOHA發送的時隙具有隨機性,智能節點不可能精準地預測其發送的時隙。這就要求智能節點需要預留出多個時隙,來確保一次成功的ALOHA節點傳輸。ALOHA節點占用的時隙越大,智能節點就越需要預留比這更多的時隙,這最終導致總吞吐量的下降。相反地,智能節點幾乎可以完美地學習具有固定傳輸時隙的TDMA節點的發送策略。因此,在不改變[q]的情況下,增加[x]值,系統直接表現出吞吐量的增加。同時,POCL?MAC和ALOHA分享其余可用的信道接入機會。
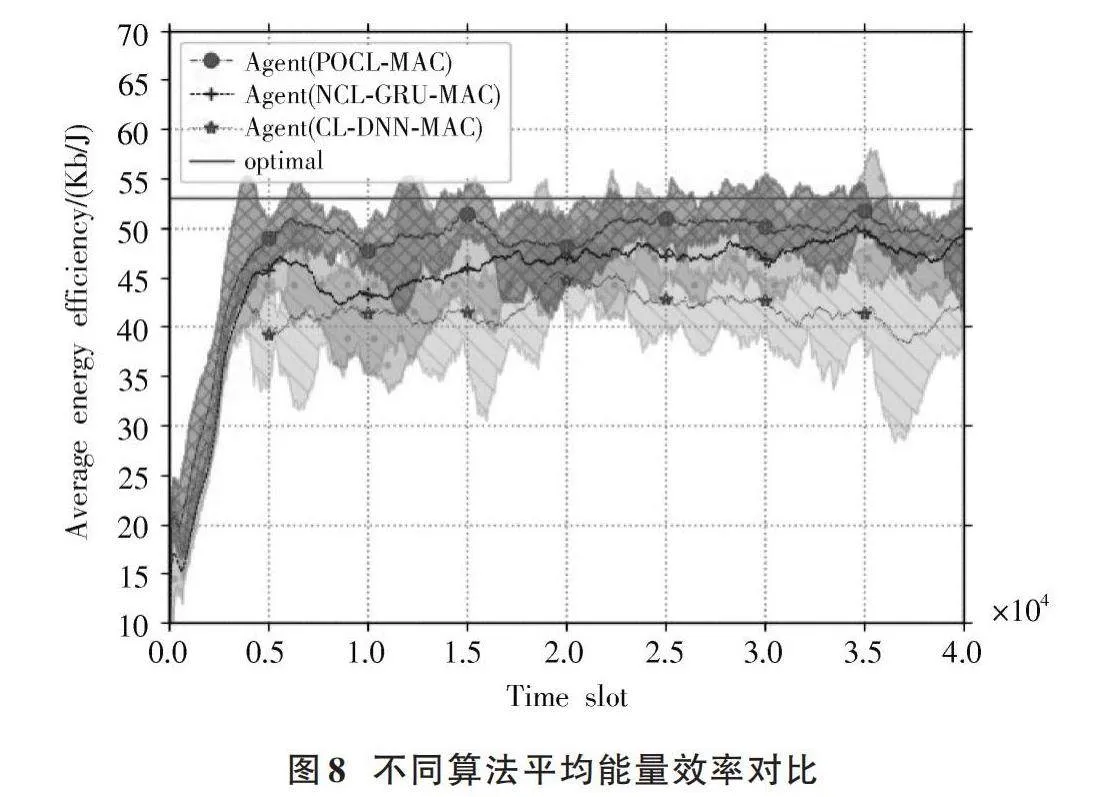
3.2.3" 能量利用效率的對比
在仿真信道下智能節點的平均能量效率的測試結果如圖8所示。
lt;E:\2024年第17期\2024年第17期\Image\61t8.tifgt;
圖8" 不同算法平均能量效率對比
智能節點在傳輸數據包時需要消耗較高能量;在不傳輸的時隙監聽信道以接收ACK數據包,保持一個較低的能耗。POCL?MAC方法在動態變化的信道衰減情況下,始終能保持良好的平均能量效率。相比NCL?GRU和CL?DNN,其平均能量效率分別提高了7.17%和18.25%。具有跨層設計的GRU算法節點通過不斷學習,最終在數據包投遞率和平均能量效率中取得了更好的表現,其以更高的概率成功送達數據包,減小了數據包的重傳,學習效率和算法穩定度均優于傳統算法。
本文所提出的POCL?MAC算法節點受劇烈變化的信道影響,短期內消耗的平均功率能隨信道變化自適應地調整以適應不同的信道衰減值。相比其他算法,該算法節點在幾乎任何時間段都能取得最優的能量效率。這表明,無論網絡中每個時隙的信道衰減信息如何,本文提出的智能節點總是可以快速適應信道急劇變化的影響,采取最佳措施來最小化功率消耗和最大化平均能量效率并接近最優的網絡吞吐量。結論顯示,POCL?MAC智能節點相對于其他算法的節點,可以實現接近最優的比例公平吞吐量,并達到更優的平均能量效率。
4" 結" 語
本文提出了一種UWANs場景下基于DRL的比例公平的跨層聯合優化MAC協議——POCL?MAC,用于在水聲長時延且動態變化信道環境下實現異構網絡的高效信道利用。其目標是找到一個最優的訪問策略與傳輸功率,以在動態信道衰減的情況下與其他節點共存時,最大限度地提高公平網絡吞吐量,并通過聯合調度傳輸時隙和功率來最大化DRL節點的能量效率。實驗結果表明,POCL?MAC協議在動態水下環境的異構網絡中具有較好的適應性,實現了不同節點基于節點數量的比例公平性,并使智能節點的能量效率最大化。同時,本文算法避免了傳統DRL中分層設計的局限性,對于水聲環境能較好的收斂。
注:本文通訊作者為韓翔。
參考文獻
[1] FELEMBAN E, SHAIKH F K, QURESHI U M, et al. Underwater sensor network applications: A comprehensive survey [J]. International journal of distributed sensor networks, 2015, 11(11): 896832.
[2] LI S N, QU W Y, LIU C F, et al. Survey on high reliability wireless communication for underwater sensor networks [J]. Journal of network and computer applications, 2019, 148: 102446.
[3] ALFOUZAN F A. Energy?efficient collision avoidance MAC protocols for underwater sensor networks: Survey and challenges [J]. Journal of marine science and engineering, 2021, 9(7): 741.
[4] MOLINS M, STOJANOVIC M. Slotted FAMA: A MAC protocol for underwater acoustic networks [C]// Proceedings of MTS/IEEE OCEANS. New York: IEEE, 2006: 1?7.
[5] HONG L, HONG F, GUO Z W, et al. A TDMA?based MAC protocol in underwater sensor networks [C]// 2008 4th International Conference on Wireless Communications, Networking and Mobile Computing. New York: IEEE, 2008: 1?4.
[6] CHIRDCHOO N, SOH W S, CHUA K C. Aloha?based MAC protocols with collision avoidance for underwater acoustic networks [C]// INFOCOM 2007: 26th IEEE International Conference on Computer Communications. New York: IEEE, 2007: 2271?2275.
[7] TO T, TO D, WANG X H, et al. A reservation?type protocol for channel?aware ALOHA [C]// 21st Annual IEEE International Symposium on Personal, Indoor and Mobile Radio Communications. New York: IEEE, 2010: 1431?1435.
[8] NOH Y, LEE U, HAN S, et al. DOTS: A propagation delay?aware opportunistic MAC protocol for mobile underwater networks [J]. IEEE transactions on mobile computing, 2014, 13(4): 766?782.
[9] XIA Y Q, CHEN S M, PEI P H, et al. COPESM?MAC: A contention?based medium access protocol using parallel reservation and sleep mode for underwater acoustic sensor networks [C]// OCEANS 2019 Conference. New York: IEEE, 2019: 1?5.
[10] CHO J, AHMED F, SHITIRI E, et al. Power control for MACA?based underwater MAC protocol: A Q?learning approach [C]// 2021 IEEE Region 10 Symposium (TENSYMP). New York: IEEE, 2021: 1?4.
[11] ALFOUZAN F, SHAHRABI A, GHOREYSHI S M, et al. An energy?conserving collision?free MAC protocol for underwater sensor networks [J]. IEEE access, 2019, 7: 27155?27171.
[12] AHMED F, CHO J, SHITIRI E, et al. Reinforcement learning?based power control for MACA?based underwater MAC protocol [J]. IEEE access, 2022, 10: 71044?71053.
[13] ALABLANI I A, ARAFAH M A. EE?UWSNs: A joint energy?efficient MAC and routing protocol for underwater sensor networks [J]. Journal of marine science and engineering, 2022, 10(4): 488.
[14] NAYAK N K S, BHATTACHARYYA B. Machine learning based medium access control protocol for heterogeneous wireless networks: A review [C]// 2021 Innovations in Power and Advanced Computing Technologies (i?PACT). [S.l.: s.n.], 2021: 1?6.
[15] PASANDI H B, NADEEM T. Mac protocol design optimization using deep learning [C]// 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC). New York: IEEE, 2020: 709?715.
[16] YU Y D, WANG T T, LIEW S C. Deep?reinforcement learning multiple access for heterogeneous wireless networks [J]. IEEE journal on selected areas in communications, 2019, 37(6): 1277?1290.
[17] 楊華,耿烜,孔寧.一種采用Dueling?DDQN算法的無線網絡MAC協議[J].北京郵電大學學報,2023,46(3):25?30.
[18] YE X W, YU Y D, FU L Q. Deep reinforcement learning based MAC protocol for underwater acoustic networks [J]. IEEE transactions on mobile computing, 2022, 21(5): 1625?1638.
[19] GENG X, ZHENG Y R. Exploiting propagation delay in underwater acoustic communication networks via deep reinforcement learning [J]. IEEE transactions on neural networks and learning systems, 2023, 34(12): 10626?10637.
[20] DONG C F, TANG Y Q, JING L Y, et al. Adaptive transmission for underwater acoustic communication based on deep reinforcement learning [C]// 2022 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC). New York: IEEE, 2022: 1?5.
[21] BHASKARWAR R V, PETE D J. Cross?layer design approaches in underwater wireless sensor networks: A survey [J]. SN computer science, 2021, 2(5): 362.
[22] JIN X C, LIU Z X, MA K. Joint slot scheduling and power allocation for throughput maximization of clustered UASNs [J]. IEEE Internet of Things journal, 2023, 10(19): 17085?17095.
[23] PORTER M B. The bellhop manual and user′s guide: Preliminary draft [EB/OL]. [2011?01?01]. https://www.researchgate.net/publication/267803064.
