基于大數據的深度學習網絡爬蟲算法在信息搜集與處理中的應用
2024-09-27 00:00:00于平
科技資訊 2024年16期
摘要:旨在利用大數據和深度學習技術優化網絡爬蟲算法,以更好地滿足信息搜集與處理的需求。首先,使用大數據技術進行數據收集;然后,引入詞頻反轉文檔頻率(TermFrequency-InverseDocumentFrequency,TF-IDF)權重作為輸入特征的初始權重,并利用傳播激活算法來優化爬蟲算法;最后,對多模態信息進行整合。為了測試基于大數據的深度學習網絡爬蟲算法在信息搜集與處理中的應用效果,將其與傳統方法進行了比較。通過實驗發現,在統一資源定位器(UniformResourceLocator,URL)數量為10000時,提出的方法的覆蓋率可達92.9%,而傳統方法的覆蓋率僅為73.7%。研究證明所提出的基于大數據的深度學習網絡爬蟲算法在信息收集方面具有更高的覆蓋率和更好的準確性。
關鍵詞:網絡爬蟲算法深度學習信息收集和處理大數據
ApplicationofDeepLearningWebCrawlerAlgorithmsBasedonBigDatainInformationCollectionandProcessing
YUPing
GuangzhouHuananBusinessCollege,Guangzhou,GuangdongProvince,510650China
Abstract:ThisarticleaimstooptimizewebcrawleralgorithmsbyusingBigDataandDeepLearningtechnologytobettermeettheneedsofinformationcollectionandprocessing.Firstly,useBigDatatechnologyfordatacollection;Then,theTermFrequency-InverseDocumentFrequency(TF-IDF)weightisintroducedastheinitialweightoftheinputfeature,andthePropagationActivationalgorithmisusedtooptimizethecrawleralgorithm;Finally,integratemultimodalinformation.InordertotesttheapplicationeffectofDeepLearningwebcrawleralgorithms basedonBigDataininformationcollectionandprocessing,thisarticlecomparedthemwithtraditionalmethods.Throughexperiments,itwasfoundthatthecoverageoftheproposedmethodcanreach92.9%whenthenumberofUniformResourceLocators(URL)is10000,whilethecoverageoftraditionalmethodsisonly73.7%.ResearchhasshownthattheDeepLearningwebcrawleralgorithmbasedonBigDataproposedinthisarticlehashighercoverageandbetteraccuracyininformationcollection.
KeyWords:Webcrawleralgorithm;DeepLearning;Informationcollectionandprocessing;BigData
網絡爬蟲是一種自動化工具,能夠按照一定的規則和算法從指定的起始網頁開始逐一抓取目標網頁中的鏈接[1-2]。隨著互聯網規模的爆炸式增長,網絡爬蟲面臨著越來越多的挑戰。傳統的網絡爬蟲算法往往無法有效地處理大規模和結構復雜的網絡數據,同時,網頁更新速度很快,要求網絡爬蟲必須具有實時性和高效率。為了解決這些問題,研究者們開始將深度學習技術應用于網絡爬蟲算法中。他們利用深度學習技術對網頁進行特征提取和分類,從而提高了網頁的抓取準確性與覆蓋率,這不僅有助于提高信息收集與處理的效果,還具有重要的現實意義和理論價值。
1信息收集與處理的方法與過程
1.1數據收集
使用大數據技術進行廣泛的數據收集,并通過深度學習算法進行數據清理,以確保數據的準確性。數據收集是信息檢索過程中的重要步驟,其會直接影響后續深度學習網絡爬蟲算法的效果。本文利用大數據技術進行廣泛的數據收集,旨在構建一個全面和多樣化的數據集,以提高深度學習模型的泛化能力和適應能力。
首先,要選擇數據源,搜索并且下載用戶相關的網頁,通過大數據,選擇4個熱門業務。然后,通過大數據技術,在網頁上讀取信息,搜索網頁的其他鏈接地址,設置不同訪問層數,通過這種方式,把所有的網頁全部讀取完畢。最后,將網頁中的有效信息進行抓取,如文本、聲音、圖像和視頻等,在抓取網頁中的信息時,一般利用HTTP協議協助進行。
1.2深度學習網絡設計
在互聯網中,主題特征向量與其出現的頻率和網頁的頁面結構和位置有關,一個主題特征向量出現在網頁中的頻率越高,則其出現在標題或其他特殊超文本標記語言文本中的次數越多,這些對主題判別具有高影響的詞特征容易被選擇作為負采樣特征,剔除或修改這些負面特征有助于對主題相關的網頁特征進行聚合。負面特征選擇可用公式表示為:
式中,為網頁結構和位置,為所有負特征的權重和,;
為系數。
在網頁主題采集中,需要通過主題網頁的正采樣和非主題網頁的負采樣過濾,就會得到多棵主題強相關的特征樹。每顆特征樹需要有多個層級,最多為4層,按照樹的層級,對樹的每層特征進行橫向排列,形成主題特征梯形[3]。梯形的每層由若干個主題特征和對應的詞頻反轉文檔頻率(TermFrequency-InverseDocumentFrequency,TF-IDF)組成,這一梯形的主題樹中,由上至下,隨著梯形主題特征的增多,主題深度越弱。
傳統模式下,循環神經網絡處理文本特征有一定的局限性,隨著時間的遞增,新特征的輸入與早期特征的路徑過長,這種局限性導致對早期主題的遺忘。為了解決這個問題,本章提出了一種改進的神經網絡判別器。該判別器基于循環神經網絡并引入了TF-IDF權重作為輸入特征的初始權重,這對于改善特征被遺忘的問題具有很大的幫助作用。
1.3爬蟲算法的優化
對爬蟲算法進行優化是為了更好地抓取網頁資源中的主題,因此,要對神經網絡資源進行修改,結合傳播激活算法,以實現網頁資源的抓取。首先,將Hopfield神經網絡模型轉化為前向傳播的神經網絡,主要分為3個步驟:初始化、激活—傳播—迭代和終止。
聚焦爬蟲,以一組與目標領域主題高度相關的種子網頁為起點,并將網頁節點的權重初始化為1。在神經網絡首次激活迭代時,聚焦爬蟲,從搜索隊列中逐一獲取種子網頁并解析。在迭代第s次時,網頁節點a的權重記作,權重值會在所有的種子網頁中進行調整,有。主題爬蟲在解析種子網頁過程中獲取的新網頁將添加到神經網絡中[4]。
在完成初始化后,聚焦爬蟲,將進入下一次迭代,通過神經網絡的激活和傳播來計算新獲取的網頁節點權重值。網頁節點權重值公式為:
式中,為網頁節點a在第s+1次迭代時的結點權重,為父節點c和子節點s之間的超文本鏈接權重。
通過憶阻器模型和信息熵的主題相關性分析算法計算,我們能夠得到為父節點c和子節點s之間的超文本鏈接的權重。采用分段線性和單調遞增的憶阻器模型來設計激活方程,能夠更好地適應聚焦爬蟲算法。
通過對權重值的計算,可以得到一個下載路徑,主題爬蟲會按照權重值大小來進行內容的下載。在訪問和下載完所有與主題相關的網頁(節點權重值大于預設值)后,聚焦爬蟲將根據網頁內容對所有相關網頁的節點權重值進行更新,以便在新的迭代中更準確地預測后續網頁的相關性。那么,網頁節點權重值更新公式表示為:
式中,為分段線性、單調遞增的憶阻器模型方程,為結點a所對應的網頁內容與目標域中主題相關性的大小。
主題相關性的大小直接取決于目標領域中每個關鍵詞在網頁內容中出現的頻率的總和。的值跟網頁內容的相關度有一定關系,如果網頁內容越相關,相應的值也會越大[5]。
聚焦爬蟲的工作方式很簡單,是在憶阻神經網絡框架下進行持續抓取網頁。在本次迭代中,所有節點權值的均值小于預先設定的最大不相關權值(一個較小的正實數),或者是在獲取的網頁數量達到預先設定的數目時,抓取行為終止。
2信息搜集與處理效果評估
2.1實驗設計與數據來源
通過對互聯網上的網址進行實驗,驗證了深度學習算法在信息收集和處理方面的有效性。在此基礎上,我們選取了不同數目的統一資源定位器(UniformResourceLocator,URL)作為樣本,對該算法與傳統算法進行了比較。實驗證明,該方法能夠較好地獲取數據、提高數據采集的精度,為該方法在實際應用中的應用奠定了基礎。
2.2實驗結果分析
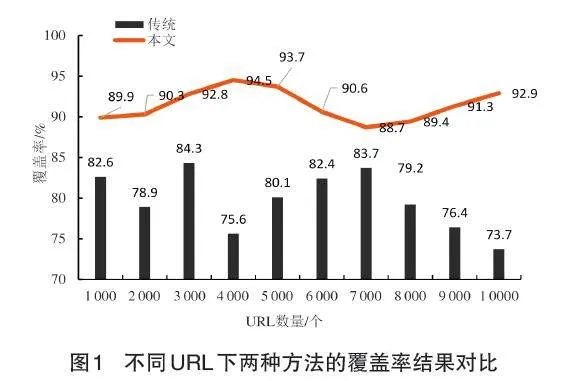
覆蓋率是衡量信息收集和處理的綜合性程度的一個重要指標。當爬行器覆蓋范圍不夠時,有可能會漏掉一些關鍵信息,從而不能完整地展現被搜索到的站點或者數據。所以,提升網絡爬行器的覆蓋率是信息收集與處理工作中不可或缺的一環,能讓使用者更全面和更有效地擷取資訊,并提升資料的品質與完整度。在此基礎上,對兩種算法在不同URL個數情況下的覆蓋情況進行了對比,得到的結果顯示在圖1中。
從圖1可以看出:在URL個數為1000的情況下,本方法得到的覆蓋率可以達到89.9%,而傳統的方式可以達到82.6%;在URL個數3000的情況下,該算法得到的覆蓋率可以達到92.8%,而傳統算法的覆蓋率可以達到84.3%;在URL個數為7000的情況下,該算法得到的覆蓋率為88.7%,而傳統算法的覆蓋率為83.7%;在URL個數為10000的情況下,該算法得到的覆蓋率可以達到92.9%,而傳統算法可以達到73.7%。由此可以看到,在URL數量相等的情況下,本論文的算法的覆蓋率要比傳統的算法高得多,這意味著我們的算法可以對數據進行更加全面的采集和處理,這有助于人們在獲取信息的過程中更好地提升信息的質量和完整性。
3結語
互聯網時代下,信息呈現爆炸式的增長模式,傳統的信息搜集與處理方式已經顯得力不從心。如何提高信息搜集與處理方式則是當前急需解決的問題。本文研究的主題便是基于大數據的深度學習網絡爬蟲算法在信息搜集與處理中的應用。研究發現,使用本文大數據的深度學習網絡爬蟲算法進行信息收集與處理,覆蓋率與準確性均相比傳統方法得到了明顯的提升,這有利于更準確和全面地獲取信息,從而更好地保證信息的質量和完整性,具有實際使用價值。但是,本文研究有所不足,由于實際條件的限制,本文實驗所選取的樣本較少,同時對于信息收集效率也缺乏驗證,在后續研究中還需對其進行更多探討。
參考文獻
[1]唐文軍,隆承志.基于Python的聚焦網絡爬蟲的設計與實現[J].計算機與數字工程,2023,51(4):845-849.
[2]馮艷茹.基于Python的網絡爬蟲系統的設計與實現[J].電腦與信息技術,2021,29(6):47-50.
[3]左薇,張熹,董紅娟,等.主題網絡爬蟲研究綜述[J].軟件導刊,2020,19(2):278-281.
[4]熊艷秋,嚴碧波.基于jsoup爬取圖書網頁信息的網絡爬蟲技術[J].電腦與信息技術,2019,27(4):61-63.
[5]張葉娥.基于帶狀無線傳感器網絡的實時智能數據收集算法[J].吉林大學學報(理學版),2023,61(2):393-399.
