改進YOLOv5s的橋梁表觀病害檢測方法
2024-10-11 00:00:00董紹江譚浩劉超胡小林
重慶大學學報 2024年9期






doi:10.11835/j.issn.1000-582X.2023.101
摘要:針對已有目標檢測方法在混凝土橋梁表觀病害檢測的應用中識別精度低且伴隨較多誤檢和漏檢的問題,提出了一種改進的YOLOv5s橋梁表觀病害檢測方法。針對目前橋梁表觀病害特征成分較復雜的問題,為了更有效地利用不同尺度的缺陷特征,在主干網中添加修改后的空間金字塔池化模塊,提高了整體網絡對缺陷特征信息的獲取能力,同時減少了運算工作量;針對由病害圖像中不同缺陷特征交叉分布導致的誤檢率、漏檢率高的問題,在YOLOv5s網絡中加入輕量化注意力模塊;針對橋梁缺陷尺寸差異大、分類困難和數據集小而導致的邊界回歸不匹配的問題,采用考慮了向量角度的損失函數。實驗證明,改進后的YOLOv5s檢測器在橋梁表觀病害目標檢測識別任務中能夠有效提高精度、降低誤檢率和漏檢率。
關鍵詞:病害檢測;YOLOv5s;特征融合;平均精度
中圖分類號:TP391.4文獻標志碼:A文章編號:1000-582X(2024)09-091-10
Apparent disease detection of bridges using improved YOLOv5s
DONG Shaojiang1,TAN Hao1,LIU Chao1,HU Xiaolin2
(1.School of Mechatronics and Vehicle Engineering,Chongqing Jiaotong University,Chongqing 400074,P.R.China;2.Chongqing Industrial Big Data Innovation Center Co.,Ltd.,Chongqing 404100,P.R.China)
Abstract:To solve the problems of low accuracy,high false detection rate,and high missed detection rate in current target detection methods for apparent diseases in concrete bridges,an improved YOLOv5s method is proposed.To achieve more effective fusion of features at different scales and increase receptive fields,an improved spatial pyramid pooling module is added to the YOLOv5s network to enhance feature extraction capabilities and reduce computational cost;a light-weight attention module is incorporated into the YOLOv5s network to tackle the high false detection and missed detection rates caused by the cross-distribution of different defect features in disease images;and a loss function considering vector angles is adopted to solve the problems related to varying defect sizes,classification difficulties and small dataset-induced boundary box regression mismatches.Experimental results show that the improved YOLOv5s detector significantly improves accuracy while reducing false detection and missed detection rates in the task of detecting apparent diseases in bridges.
Keywords:disease detection;YOLOv5s;feature fusion;mean average accuracy
截至2021年底,中國的公路橋梁總共有96.11萬座,全長73 802.1 km。橋梁的運營過程中,隨之而來的是橋梁功能的退化和橋梁本體結構的損傷,因此對橋梁結構的表觀檢測是橋梁運維的重要工作之一。目前橋梁表觀缺陷檢測的主要方式為目測和簡單儀器測量,但這些檢測方法主觀性較強,且受現場環境等綜合因素影響,對一些存在病害的地方可能產生大量誤檢、漏檢。為了解決這一問題,基于機器視覺的檢測方法被提出,通過無人機和爬壁機器人[1]等設備來獲取圖像,將獲取的圖像導入計算機并且提取圖像特征,進一步識別和分類,達到缺陷識別的目的,如Nishikawa等[2]在對橋梁表面裂縫識別中引入機器學習的方法。雖然機器學習方法相較于傳統檢測技術在檢測效率、魯棒性上有一定提升[3],但這些方法的特征提取過程十分繁瑣,且不能夠一次性、端到端地解決缺陷識別問題。
近年來,基于深度學習的缺陷檢測方法解決了傳統機器學習方法檢測速率低、漏檢率高的問題,同時兼具檢測速度快、魯棒性強等優點。基于深度學習的檢測方式按照其網絡體系結構分為以下2類:第1類是以區域卷積神經網絡[4](regional convolutional neural networks,R-CNN)為代表的Fast R-CNN[5]、Faster R-CNN[6]等雙階段檢測算法。R-CNN借用了滑動窗口來產生候選框域的思想,這種方法步驟復雜、計算量大。針對R-CNN較費時的選擇性搜索,Faster R-CNN使用了一個區域候選網絡來取代選擇性搜索,如Cha等[7]將Faster R-CNN用于識別混凝土和鋼鐵裂縫相關的多種表面損傷。雖然大量研究證實了雙階段檢測方法可用于鋼筋混凝土等結構件表面缺陷的檢測,但中間過程繁瑣,且需要大量重復性實驗,因此其檢驗效率不夠好,無法適應現場檢測要求。第2類是以SSD(single shot detector)[8]、YOLO(you only look once)[9]為代表的單階段檢測算法。它并不要求先給出目標候選框,而是直接把目標圖像特征的提取和預測框的確定結合在一起進行圖像的類別估計和區域坐標評估,極大地提高了檢測效率。SSD算法的缺點明顯,一是較低層級的特征非線性程度不夠,導致訓練精度不如YOLO;二是候選框尺寸需要人工經驗判斷。隨著YOLOv3[10]、YOLOv4[11]、YOLOv5的先后提出,YOLO系列算法與其他算法比較在檢測速率和精度上均表現出較大的優越性。Peng等[12]提出一種使用改進YOLO的雙網絡方法來提高算法對塊狀缺陷和裂縫病害的檢測能力;Jang等[13]提出一種基于混合擴展卷積塊的深度學習網絡HDCB-Net,并結合YOLOv4用于實現像素級的裂紋檢測。
現有基于YOLOv3、YOLOv4的橋梁表觀病害檢測識別方法在現場作業時不能滿足實時檢測需求,YOLOv5系列算法則在檢測精度、速度上都優于YOLOv3,其在一些公共數據集如COCO[14](common objects in context)數據集上有較好的表現,但在數據特征較為復雜的橋梁表觀病害檢測中尚有改進空間。本研究的目的是探討對YOLOv5s算法的改進及其對橋梁表觀病害檢測任務的適用性。
1 YOLOv5s模型框架
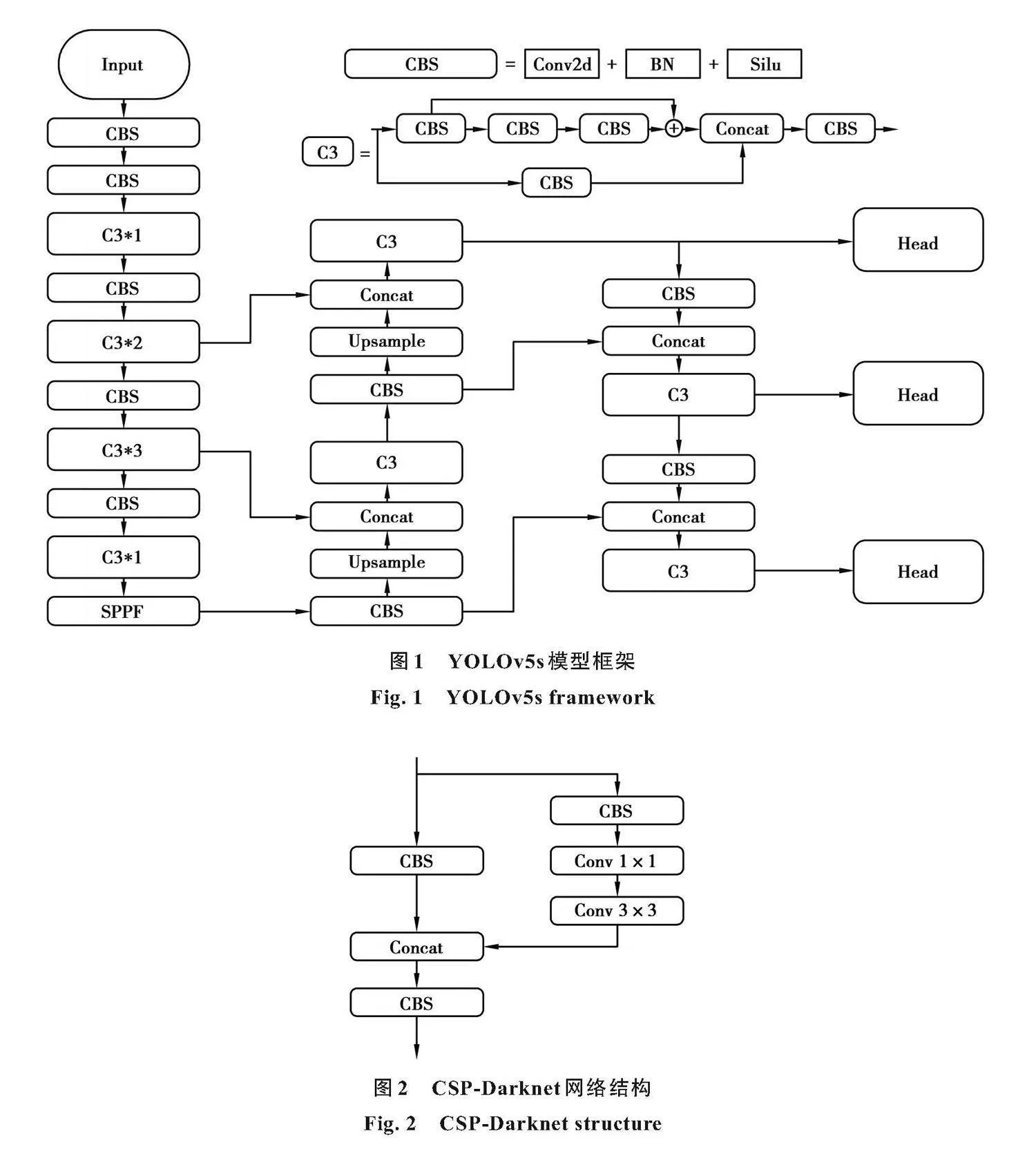
YOLOv5s是一種單階段檢測方法,結合特征提取和預測框設定對目標的分類概率和定位坐標進行評估。相對于其他算法,YOLOv5s具有模型小、檢測速度快和檢測精度高等優勢。YOLOv5s結構如圖1所示,可將YOLOv5s算法模型劃分為4個部分。
第1部分是輸入層,主要負責對已提供的圖像數據進行預處理,包括數據強化、自適應錨框算法和自適應圖像縮放。YOLOv5s使用Mosaic數據增強技術,通過對前4張圖片隨機壓縮、剪切、重新排布并加以拼接,以加強對小目標的檢測效果;自適應錨框主要是根據當前數據集選擇與其長寬對應的錨框;自適應圖像縮放不同于上一代YOLOv4,為圖片增加最少像素的額外黑邊,最大程度保持圖片的原有性質,同時減少不必要的計算量。圖1中Input為輸入;Conv2d表示二維卷積;BN表示歸一化層;Silu為激活函數;CBS表示順序連接的Conv2d層、BN層和Silu層;C3表示包含3個卷積層的跳躍連接模塊,C3的數量為模塊中殘差結構的數量;SPPF表示空間金字塔池融合模塊;Concat為拼接;Upsample為上采樣;Head為模型輸出頭。
第2部分為主干網絡,主要作用是提取圖像中目標的特征。在YOLOv4算法的基礎上,使用了改進后的CSP-Darknet53結構,網絡結構如圖2所示。輸入特征圖通過2個維度進行計算,首先都使用1×1卷積(Conv)進行變換,其中一路在經過步幅為2的3×3卷積后與另一路跨階段層級拼接。這不僅保證了準確率,同時也解決了普通網絡在信息傳遞時梯度重復的問題,因此參數更小,網絡計算量更少,進一步節省內存開支。
第3部分為頸部網絡,作用為收集目標特征,其結構為特征金字塔網絡加路徑聚合網絡。特征金字塔網絡的作用是傳遞高層語義特征,路徑聚合網絡主要傳遞定位信息,對特征金字塔網絡進行補充。
第4部分為檢測層,主要用于預測信息損失部分。
2改進的橋梁表觀病害檢測模型
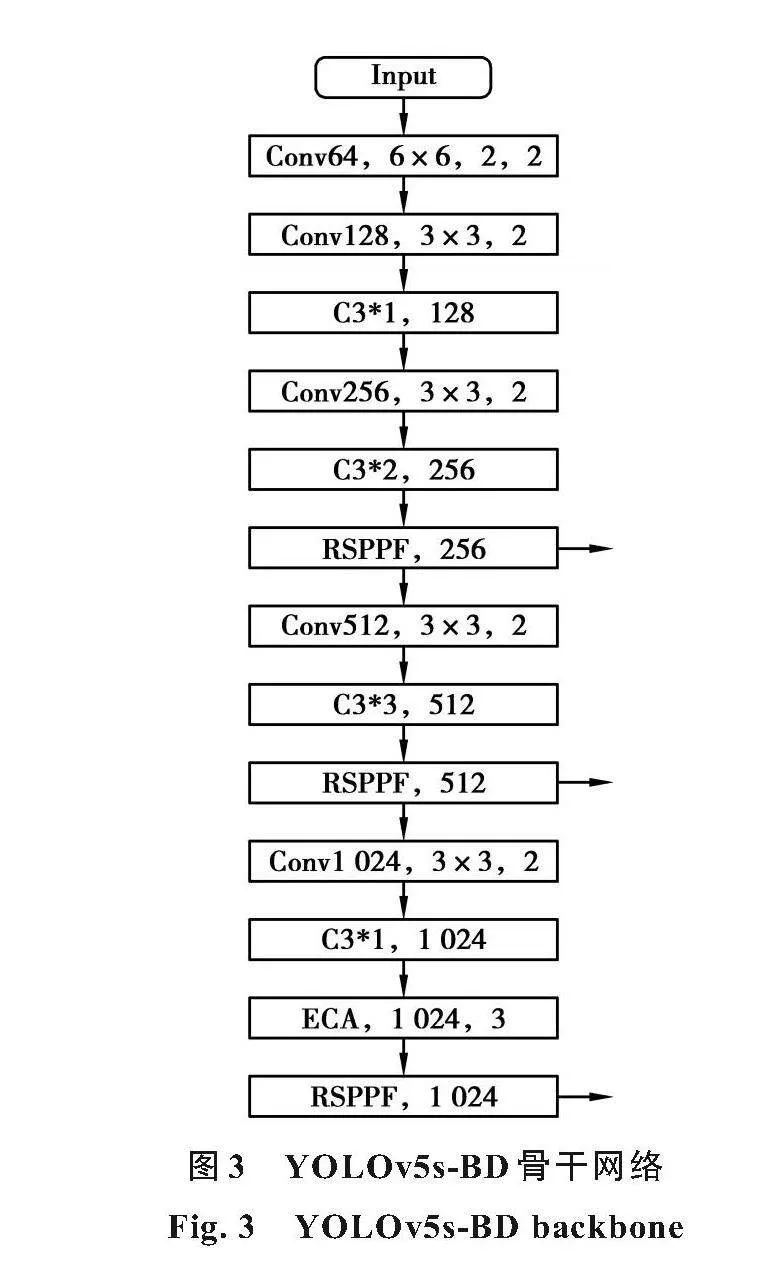
本研究中將改進的快速空間金字塔池化(Relu spatial pyramid pooling-fast,RSPPF)融入骨干網絡,加入高效通道注意力[15](efficient channel attention,ECA),提出用于橋梁表觀病害檢測的網絡(YOLOv5s of bridge detection,YOLOv5s-BD)如圖3所示,并使用SIoU[16]進行損失計算。
YOLOv5s-BD中,將原骨干網絡末端的金字塔池化塊替換為改進的RSPPF,并在網絡的第5和第8層添加RSPPF,在第11層添加ECA注意力模塊。
2.1空間金字塔池化
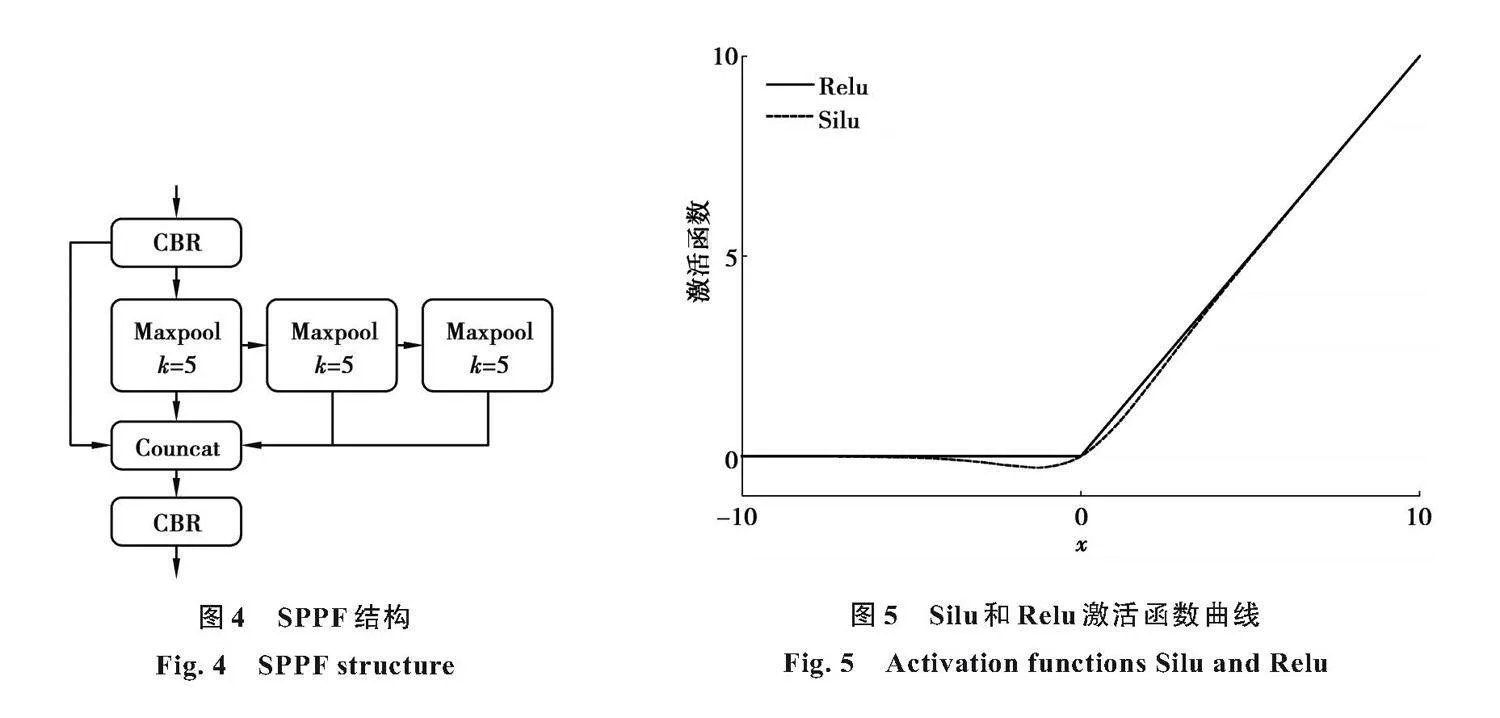
空間金字塔池化[17](spatial pyramid pooling,SPP)網絡結構是將輸入特征先通過一個卷積,然后分別進行不同卷積核的池化后與輸入拼接,再通過一個卷積,中間的卷積核大小分別為5×5、9×9和13×13。不僅在一定程度上避免了由區域裁剪、縮放導致的失真問題和重復特征提取的問題,同時也節省了計算成本。SPP能夠將圖片在不同維度上的特征信息融合到一個維度上。
YOLOv5s中的快速金字塔池化(spatial pyramid pooling-fast,SPPF)借鑒了SPP的思想,但通道間的傳遞關系改為順序傳遞,YOLOv5s中的SPPF模塊如圖4所示,圖中Maxpool表示最大池化層,k代表卷積核大小。RSPPF沿用SPPF結構,其中CBR為使用了Relu激活函數替換掉Silu激活函數的卷積操作,中間卷積核大小統一為5×5,在保證網絡精度的同時減少模塊計算量。Silu和Relu函數關系如圖5所示。
Relu函數表達式:
Silu函數表達式:
顯然Silu無上界有下界、平滑而不單調的特征使它在深層模型的效果上具有突出的優點,但其包含的指數運算和除法運算會占用大量計算量。Relu為線性函數,計算量小,更適合特征選取,且能夠有效避免反向傳播帶來的梯度彌散。
2.2輕量級注意力機制ECA
ECA是由Huang等[18]提出的一個不降維的局部跨通道互動方法,克服了普通注意力中降維對學習的負面影響,實現了不同通道間的交互。ECA網絡模型如圖6所示,其中W、H分別為特征圖的寬和高,C為通道維數,σ表示Sigmoid激活函數,GAP為全局平均池化,χ和χ(?)分別為輸入張量和輸出張量。
ECA網絡中利用矩陣Wk來學習通道注意力:
Wk由k×C個參數組成,避免了特征在不同通道上相互獨立的問題。通道注意力ω可通過下式計算:
式中:C1D表示一維卷積,y為輸出。通道維數C與卷積核大小k關系公式如下:
式中:γ和b為可調參數。
因此,卷積核尺寸表達式為:
式中:+odd表示與+值最相近的整數;k的取值會影響網絡的整體運算速度及準確率,k值過小會導致交互的覆蓋范圍小,k值過大會增加計算量,在本網絡中,設置k=3。
2.3損失函數
交并比(intersection over union,IoU)用于計算預測框損失,很大程度上決定了模型預測結果的準確程度。YOLOv5s使用完全交并比(complete intersection over union,CIoU),減少了其他類IoU在計算中的發散現象。
CIoU計算公式為
式中:α是權重系數;v用來度量寬高比的一致性;w、h分別為候選框的寬和高;ρ為歐氏距離;c為預測框和標注框的對角線長度。
式(7)中的ρ2(b,bgt)表示預測框b和真實框bgt中心點之間的歐式距離d。c代表它們的對角線距離,如圖7所示。
在IoU、GIoU和CIoU等邊界框回歸指標中,預測框和真實框之間的方向不匹配時,會降低模型的收斂速度和效率。考慮回歸向量角度并重新定義懲罰指標的SIoU損失函數由4個代價函數組成:角度函數、距離函數、形狀函數和IoU函數。角度函數為
式中:x==sin(α),這里的cx和cy分別為對角線距離的長和寬分量。
角度函數最大限度地減少了與距離相關的不匹配變量數量,收斂過程中首先最小化α。距離函數為
形狀函數為
式中:ωw=;ωh=;θ值由數據集決定。
由SIoU定義的損失函數為
式中:IoU為預測框和真實框的交并比。
3實驗結果分析
3.1實驗環境及數據集來源
實驗在Windows操作系統環境下進行,使用CPU為AMD Ryzen7 5800H,RAM為16 GB隨機存取內存,GPU為RTX 3060 Laptop,6 GB顯示內存。深度學習框架為pytorch,整個訓練過程設置epoch為300,Batch_size為8,訓練時使用SGD優化算法進行參數優化,初始學習率為0.01,輸入圖片分辨率為640×640。
實驗數據集為Mundt等[19]在2019年公開的用于橋梁混凝土缺陷檢測的多目標具體分類數據集CODEBRIM(COncrete DEfect BRidge IMage Dataset)。該數據集包含裂縫、脫落、腐蝕、露筋和風化共5種橋梁病害,如圖8所示,有效缺陷圖像共1 052張。由于數據樣本較少,且未考慮實際檢測環境變化,因此使用數據增強技術對缺陷圖像樣本進行擴充,將原數據進行裁剪、鏡像、亮度調節操作,得到有效缺陷圖像共3 807張。將數據集按9:1的比例隨機分為訓練集、驗證集。
3.2評價指標
多標簽圖片劃分任務中不止一種圖像標簽,因此不能用普通單標簽圖片劃分任務的精度標準來作為評判指標。本研究中采用mAP(mean average precision)作為評價指標。二元分類問題分類結果的混淆矩陣如表1所示,判斷結果依據其標記類和預測類的組合可分為4類,分別為真正例、假正例、真負例和假負例,分別對應表1的TP、FP、TN和FN。
精確度(precision,P)和召回率(recall,R)計算公式如下:
精確度表示該模型預測為正例的樣本中實際為正例的樣本所占的比例;召回率表示實際為正例的樣本中模型預測為正例的樣本所占的比例。每個類的精度值(AP)就是P-R曲線與坐標軸圍成的面積。mAP是這些缺陷分類的P-R曲線下的面積取平均值,mAP可以作為一個相對較好的度量指標。AP和mAP公式如下:
式中:M表示用于檢測的類別總數;N表示測試的圖像數量。mAP包含了mAP@0.5和mAP@0.5:0.95,具體由設定的IoU閾值決定,其表達式如下:
由式(18)和式(19)可知,mAP@0.5即IoU閾值為0.5時的平均精度,揭示了精確度P和召回率R的變化趨勢。mAP@0.5:0.95是以0.05為步進,IoU閾值從0.50到0.95的平均精度的平均值,揭示了模型在不同IoU閾值下的綜合表現,mAP@0.5:0.95越高代表模型的邊界回歸能力越強,預測框與標注框的擬合越精確。
3.3實驗結果與分析
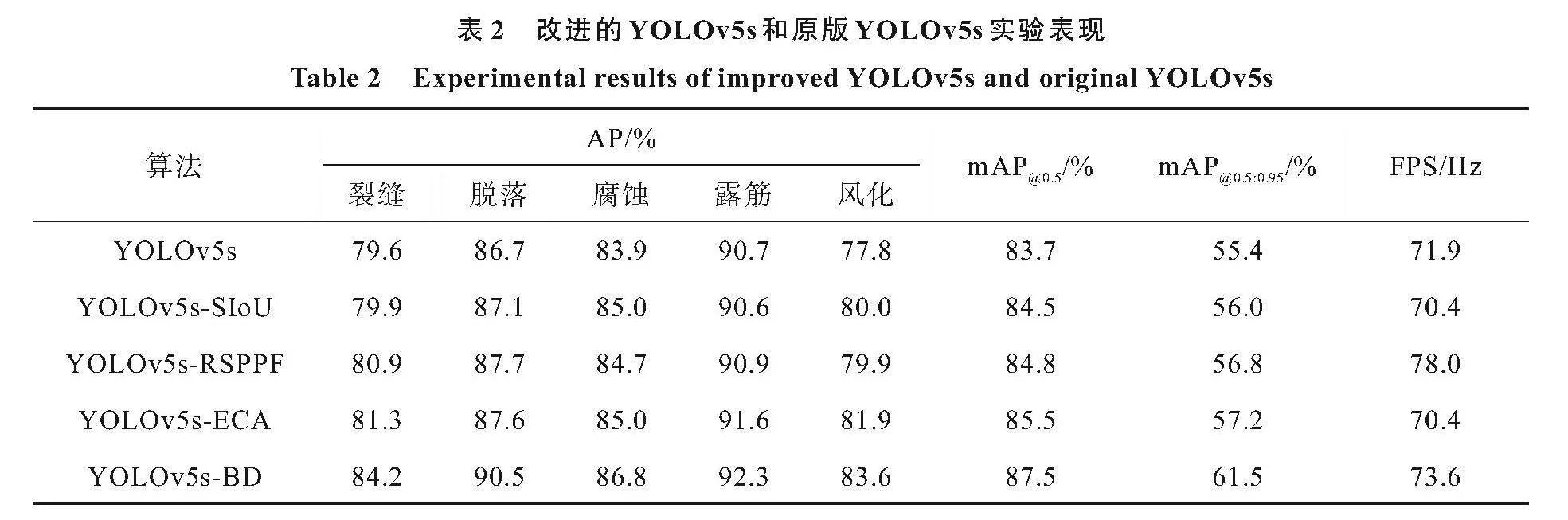
本研究中使用的數據集缺陷不易于分類,且某些缺陷(如裂縫)這樣的小目標受輸入圖片分辨率的影響,在檢測時,設置輸入圖片分辨率為640×640。為了驗證提出的方法的有效性,考慮到實時性檢測的需求,將使用了YOLOv5s的原生模型檢測效果分別與改進空間金字塔池化的YOLOv5s-RSPPF、加入ECA注意力模塊的YOLOv5s-ECA、使用SIoU進行損失計算的YOLOv5s-SIoU和本文中提出的改進骨干網絡和損失函數的YOLOv5s-BD通過測試數據集進行對比,結果見表2,其中FPS為每秒檢測幀數(frames per second)。
改進后的YOLOv5s-BD相較于YOLOv5s的原生模型對各種缺陷的檢測效果均有提升。其中,由于對預測框的損失函數做出改進,YOLOv5s-SIoU相較于原模型mAP@0.5提升了0.8%,mAP@0.5:0.95提升了0.6%;由于對原生模型的SPPF模塊做出改進,YOLOv5s-RSPPF相較于原模型mAP@0.5提升了1.1%,mAP@0.5:0.95提升了1.4%;由于在特征提取網絡尾部加入ECA注意力機制,YOLOv5s-ECA相較于原模型mAP@0.5提升了1.8%,mAP@0.5:0.95提升了1.8%。結合以上幾種方法,YOLOv5s-BD相較于原模型mAP@0.5提升了3.8%,mAP@0.5:0.95提升了6.1%。雖然總體網絡層數有所增加,但由于改進的網絡采用了更加輕量化的計算方式,每秒檢測幀數FPS也略微提升,滿足實時檢測需求。
為了進一步驗證本研究中的模型在用于混凝土橋梁表觀缺陷檢測時的優勢,在不改變數據集的情況下,使用本研究改進網絡YOLOv5s-BD與Faster RCNN、SSD和YOLOv3進行實驗驗證,結果見表3。
通過表3可以看出,由于YOLOv5s-BD擁有對交叉分布病害特征更有效的提取能力和更先進的邊界框回歸指標,不論是以Faster RCNN為代表的雙階段檢測算法,還是SSD、YOLOv3這類單階段檢測算法,平均準確率和FPS都比YOLOv5s-BD算法低,證明本研究中改進的網絡模型在應用于混凝土橋梁表觀病害檢測方面有更大的優勢。
3.4缺陷檢測的效果
對測試集中的樣本進行隨機抽檢,其檢測效果如圖9所示。
圖9(a)檢測到部分裂紋(crack),圖9(b)檢測到了更多的裂紋,且沒有誤檢;圖9(c)將脫落(spallation)誤檢為露筋(exposed bars)且漏檢了裂紋,圖9(d)準確檢測到脫落和裂紋;圖9(e)檢測到露筋但沒有檢測到脫落;圖9(f)準確識別到露筋和脫落。綜上所述,相比于YOLOv5s,YOLOv5s-BD模型平均精度mAP@0.5提升了3.8%,mAP@0.5:0.95提升了6.1%,檢測速度也略有提升,能夠有效地檢測到更多缺陷且擁有更低的誤檢率和漏檢率,因此更適用于混凝土橋梁表觀病害檢測。
4結束語
針對當前目標檢測算法在應用于橋梁表觀病害檢測時精度低、誤檢率高、漏檢率高和檢測速率低的問題,提出一種用于橋梁表觀病害檢測的改進YOLOv5s檢測網絡;針對橋梁缺陷尺寸差異大、分類困難,以及數據集小的問題,為提高缺陷預測的精確度,引入新的預測框損失函數進行訓練。實驗結果表明,改進后的YOLOv5s模型在進行橋梁表觀缺陷實時檢測時,多種缺陷的檢測平均精度均有明顯提升,且滿足實時檢測需求,相比于原模型漏檢率和誤檢率更低。下一步工作為:1)針對直接破壞橋梁結構的缺陷(如裂縫)進行尺寸檢測工作;2)研究搭載YOLOv5改進算法的無人機或者爬壁機器人在進行橋梁病害檢測中的應用,取代人工目視來達到病害精準識別和保證工人安全的目的。
參考文獻
[1]Ellenberg A,Kontsos A,Bartoli I,et al.Masonry crack detection application of an unmanned aerial vehicle[C]//2014 International Conference on Computing in Civil and Building Engineering,June 23-25,2014,Orlando,Florida,USA.Reston,VA,USA:American Society of Civil Engineers,2014:1788-1795.
[2]Nishikawa T,Yoshida J,Sugiyama T,et al.Concrete crack detection by multiple sequential image filtering[J].Computer-Aided Civil and Infrastructure Engineering,2012,27(1):29-47.
[3]周清松,董紹江,羅家元,等.改進YOLOv3的橋梁表觀病害檢測識別[J].重慶大學學報,2022,45(6):121-130.
Zhou Q S,Dong S J,Luo J Y,et al.Bridge apparent disease detection based on improved YOLOv3[J].Journal of Chongqing University,2022,45(6):121-130.(in Chinese)
[4]Girshick R,Donahue J,Darrell TjuEr81qsxM9H/hFKMSJDbg==,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),June 23-28,2014,Columbus,OH,USA.IEEE,2014:580-587.
[5]Girshick R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision(ICCV),December 7-13,2015,Santiago,Chile.IEEE,2015:1440-1448.
[6]Ren S,He K,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[7]Cha Y J,Choi W,Suh G,et al.Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types[J].Computer-Aided Civil and Infrastructure Engineering,2018,33(9):731-747.
[8]Liu W,Anguelov D,Erhan D,et al.SSD:single shot multibox detector[M]//Computer Vision-ECCV 2016.Cham:Springer International Publishing,2016:21-37.
[9]Redmon J,Divvala S,Girshick R,et al.You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:779-788.
[10]Redmon J,Farhadi A.YOLOv3:an incremental improvement[EB/OL].2018-04-08[2022-08-12].https://arxiv.org/abs/1804.02767.
[11]Bochkovskiy A,Wang C Y,Liao H Y M.YOLOv4:optimal speed and accuracy of object detection[EB/OL].2020-04-23[2022-08-12].https://arxiv.org/abs/2004.10934.
[12]彭雨諾,劉敏,萬智,等.基于改進YOLO的雙網絡橋梁表觀病害快速檢測算法[J].自動化學報,2022,48(4):1018-1032.
Peng Y N,Liu M,Wan Z,et al.A dual deep network based on the improved YOLO for fast bridge surface defect detection[J].Journal of Automation,2022,48(4):1018-1032.(in Chinese)
[13]Jiang W,Liu M,Peng Y,et al.HDCB-Net:a neural network with the hybrid dilated convolution for pixel-level crack detection on concrete bridges[J].IEEE Transactions on Industrial Informatics,2020,17(8):5485-5494.
[14]Lin T Y,Maire M,Belongie S,et al.Microsoft COCO:common objects in context[C]//European Conference on Computer Vision(ECCV),September 06-12,2014,Zurich,Switzerland.ECCV,2014:740-755.
[15]Wang Q,Wu B,Zhu P,et al.ECA-Net:efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR),June 13-19,2020,Seattle,WA,USA.IEEE,2020:2575-7075.
[16]Gevorgyan Z.SIoU loss:more powerful learning for bounding box regression[EB/OL].2022-05-25[2022-08-12].https://arxiv.org/abs/2205.12740.
[17]Purkait P,Zhao C,Zach C.SPP-Net:deep absolute pose regression with synthetic views[EB/OL].2017-12-09[2022-08-12].https://arxiv.org/abs/1712.03452.
[18]Wang Q,Wu B,Zhu P,et al.ECA-Net:Efficient channel attention for deep convolutional neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.IEEE,2020:11534-11542.
[19]Mundt M,Majumder S,Murali S,et al.Meta-learning convolutional neural architectures for multi-target concrete defect classification with the COncrete DEfect BRidge IMage Dataset[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR),June 15-20,2019,Long Beach,CA,USA.IEEE,2019:11188-11197.
(編輯羅敏)
