基于主動學習的深度半監督聚類模型
2024-10-14 00:00:00付艷艷黃瑞章薛菁菁任麗娜陳艷平林川
計算機應用研究 2024年10期








摘 要:深度半監督聚類旨在利用少量的監督信息達到更好的聚類效果。然而,由于標注成本昂貴,監督信息的數量往往是有限的。因此,在監督信息有限的情況下,如何選擇對聚類最有價值的監督信息變得至關重要。針對以上問題,提出了基于主動學習的深度半監督聚類模型(DASCM)。該模型設計了一種主動學習方法,能夠挑選出蘊涵豐富信息的邊緣文本,并進一步生成蘊涵邊緣文本的高價值監督信息。該模型利用這些監督信息指導聚類,從而提升聚類性能。在5個真實文本數據集上的實驗表明,DASCM的聚類性能有顯著提升。這一結果驗證了利用主動學習方法生成的涵蓋邊緣文本的監督信息對于提升聚類效果是有效的。
關鍵詞:深度半監督聚類;主動學習;邊緣文本
中圖分類號:TP181 文獻標志碼:A 文章編號:1001-3695(2024)10-011-2955-07
doi:10.19734/j.issn.1001-3695.2024.01.0025
Deep active semi-supervised clustering model
Fu Yanyan Huang Ruizhang Xue Jingjing Ren Lina Chen Yanping Lin Chuana,b,c
(a.Text Computing & Cognitive Intelligence Engineering Research Center of National Education Ministry, b.State Key Laboratory of Public Big Data, c.College of Computer Science & Technology, Guizhou University, Guiyang 550025, China)
Abstract:Deep semi-supervised clustering aims to achieve better clustering results using a small amount of supervised information. However, the amount of supervised information is often limited due to the expensive labelling cost. Therefore, with limited supervised information, it becomes crucial to select the most valuable supervisory information for clustering. To address the above problem, this paper proposed a deep active semi-supervised clustering model(DASCM) which designed an active learning method that was able to select marginal texts containing rich information and further generated high-value supervised information containing edge texts. The model used this supervised information to guide the clustering, thus improving the clustering performance. The experimental results on five real text datasets show that the clustering performance of DASCM is signi-ficantly improved. This result verifies that supervised information generated using active learning methods that cover marginal text is effective in improving clustering.
Key words:deep semi-supervised clustering; active learning; marginal text
0 引言
聚類是數據挖掘領域中一個非常重要且十分具有挑戰性的任務[1],旨在將數據在無監督的情況下劃分為不同的類簇[2]。半監督聚類方法[3]通過給予少量監督信息可以進一步提高聚類的準確性。近年來,隨著深度學習的發展,結合神經網絡[4]的半監督深度聚類模型逐漸成為該領域研究熱點。
由于標注成本昂貴,現有深度半監督聚類方法的監督信息數量往往是有限的[5]。在這種情況下,如何挑選高質量的監督信息變得至關重要。為了解決這一問題,主動學習成為一種有效的策略。主動學習旨在利用少量的標記數據最大程度提升模型性能[6]。通常,它選擇最有價值的樣本進行標注,以達到預期效果。關于主動學習的研究不得不面臨一個關鍵的問題,即在聚類任務中,如何挑選最有價值的信息。
對于文本聚類任務,處于類簇邊緣且難以明確判定其所屬類簇的邊緣文本對聚類效果的影響較大。正如圖1所示,被紅色(見電子版)圓圈標記的文本位于類簇邊界,其所屬類簇的劃分也顯得極為模糊,這些文本被稱為邊緣文本。邊緣文本呈現出較高的不確定性,其所屬的類簇難以確定。在信息論[7]中,數據的不確定性越高,其蘊涵的信息量就越大。面對聚類任務時,具有更高不確定性的邊緣文本能夠提供更豐富的信息,因而具有更高的價值。現有深度半監督聚類方法往往忽視了這些邊緣文本的存在,其監督信息也未涵蓋擁有豐富信息量的邊緣文本,從而影響最終的聚類效果。
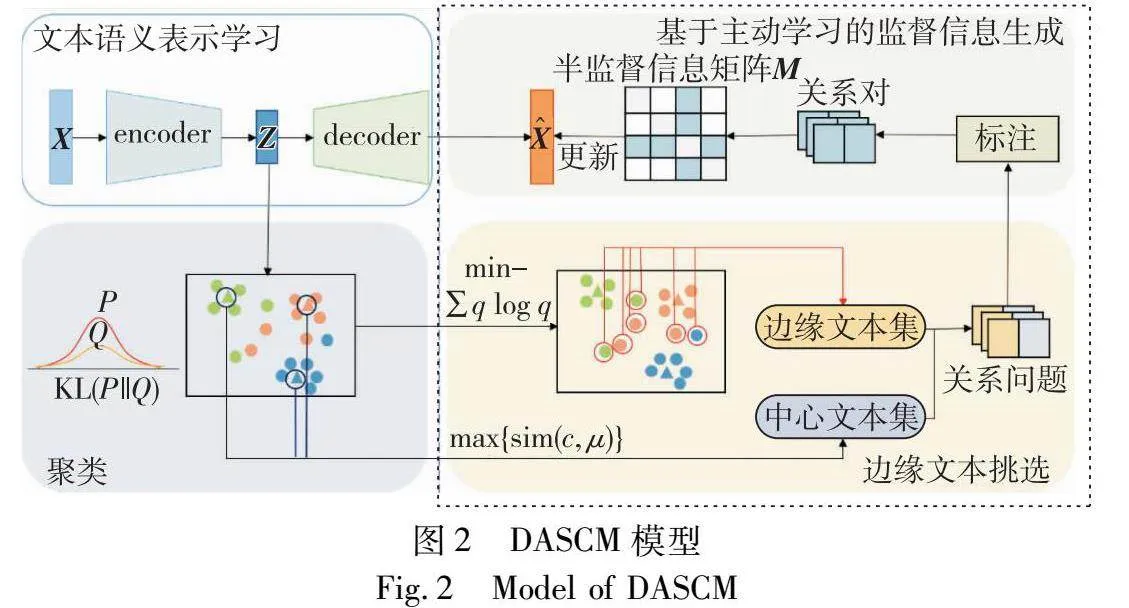
針對該問題,本文設計了基于主動學習的深度半監督聚類模型(deep active semi-supervised clustering model, DASCM)(圖2),利用主動學習方法有效提高深度半監督聚類的監督信息質量,明顯提升了聚類性能。DASCM構造了一個基于主動學習的半監督信息生成器,該生成器包含了兩個模塊。a)邊緣文本挑選模塊。該模塊基于主動學習的思想,設計了面向聚類任務的挑選機制,旨在挑選出具有豐富信息量的邊緣文本,即主動學習中的有效信息,并進一步構造“邊緣文本-中心文本”問題。b)基于主動學習的監督信息生成模塊。該模塊使用主動學習的思想,旨在生成涵蓋邊緣文本的高質量監督信息進而指導聚類。根據輸入的有關邊緣文本的問題,獲取真實的邊緣文本與類簇中心文本的關系,從而構建“邊緣文本-中心文本”的關系對。此外,半監督重構目標更新模塊將“邊緣文本-中心文本”的關系對作為半監督聚類的監督信息,從而進一步提升聚類性能。DASCM面向聚類任務,利用主動學習方法生成關于邊緣文本的高質量監督信息,提升了聚類效果。
本文的主要工作如下:
a)設計并實現了一個基于主動學習的深度半監督聚類模型,能夠使用少量的監督信息最大程度地提升模型聚類性能;
b)提出了一種面向聚類結構的主動學習方法,能夠自動選擇對聚類任務最具價值的樣本;
c)提出了一種監督信息的生成方法,通過利用主動學習方法挑選出的樣本生成高質量的聚類監督信息,進一步提升了聚類性能。
1 相關工作
1.1 半監督聚類
半監督聚類結合了聚類和半監督學習的思想[8],通過數據集中少量的標簽數據[9]或約束信息[10]來提高聚類性能。
大多數半監督聚類方法主要是在已有的經典聚類方法的基礎上,通過添加約束信息來優化聚類結果[11]。當約束信息是獨立的類標簽時,Basu等人[12]基于Seeds集對K-means進行改進,提出了Seeded-Kmeans算法,其基本思想是將標記樣本引入K-means[13]。Wagstaff等人[14]提出的COP-Kmeans算法將成對約束引入到K-means算法中,不同點在于要求數據必須滿足ML(must-link)或CL(cannot-link)約束,即任意兩個數據樣本要么滿足ML約束(這兩個樣本一定屬于同一類),要么滿足CL約束(這兩個樣本一定不屬于同一類),其聚類思想與K-means一致。
隨著深度神經網絡的發展,深度聚類已經取得了顯著的效果。目前比較有代表性的深度半監督聚類是SDEC(semi-supervised deep embedded clustering)[15],在DEC(deep embedded clustering)的基礎上將成對約束引入到特征學習過程中。Ohi等人[16]提出的AutoEmbedder能夠基于成對約束生成可聚類的嵌入點,這些嵌入點不僅維度更低,而且更能體現樣本點之間的聯系。Wang等人[17]提出的PCSA-DEC基于成對約束構造了一個約束損失函數。該損失函數可以確保同類樣本的相似性遠高于其他樣本。
半監督聚類有效利用了監督信息,相較于無監督聚類,其聚能性能得到了顯著提升。現有方法主要通過隨機選取樣本進行標注以獲取監督信息,這使得監督信息的質量難以保證。
1.2 主動學習
主動學習在機器學習領域中被廣泛研究,通過標注盡可能少的樣本,最大程度地提高模型的性能[18]。Lewis[19]提出基于池的主動學習查詢如何標記最不確定的樣本。Seung等人[20]提出的QBC(query-by-committee)算法基于一個委員會模型,委員會對候選樣本的標簽投票,被選出來的樣本是那些意見最不一致的數據樣本。Settles等人[21]提出用于判別概率模型類別的期望梯度長度(expected gradient length,EGL)方法,主要思想是挑選能夠給當前模型帶來最大變化的樣本。Settles等人[22]又提出信息密度框架,其基本思想是挑選的樣本不僅是不確定的,而且還應該代表輸入數據的分布情況。
近年來,隨著深度學習的發展,結合神經網絡的深度主動學習逐漸成為領域研究熱點。Sinha等人[23]提出的VAAL模型引入生成對抗網絡用于標記樣本的擴充。VAAL可以在大規模數據集上學習有效的低維潛在表示,并通過聯合數據表示和不確定性進一步提供了一種有效的采樣方法。后續Kim等人[24]提出TA-VAAL模型,同時利用了全局數據分布和模型不確定性共同進行樣本挑選。Cho等人[25]提出一種快速且易實現的框架,稱為主動學習的最大分類器差異(MCDAL)。該框架考慮利用多個分類器預測的差異性來構建主動學習的采樣函數,以挑選最不確定的樣本進行標記。
主動學習能夠使用較少的標記樣本訓練出優秀的模型,從而在降低標記成本的同時不犧牲性能。但是,在半監督聚類任務中,主動學習如何挑選有價值的信息,目前的研究尚未提供清晰的解決思路。
2 模型設計
DASCM主要有文本語義表示學習模塊、基于主動學習的半監督信息生成器和聚類模塊三個部分組成,如圖2所示。
2.1 文本語義表示學習模塊
為了方便聚類,本文利用詞袋模型[26]對文本數據進行編碼,得到原始的向量表示X={x1,x2,…,xn}。
由于真實文本數據轉為向量后,維度通常會變得很高。所以,本文利用自動編碼器(auto-encoder,AE)對輸入向量X={x1,x2,…,xn}降維并提取文本語義表示[27]。自動編碼器使用了一組神經網絡對輸入數據進行非線性映射fθ:X→Z,其中θ是可學習的參數,Z就是網絡學習到的文本語義表示。
AE主要分為編碼器和解碼器兩個部分,其工作過程描述為
H(l)=φ(W(l)H(l-1)+b(l))(1)
其中:φ表示ReLU激活函數;W(l)和b(l)分別為第l層的權重和偏置。
AE通過縮小神經網絡的輸出X^和訓練目標X的差距,根據式(2)優化神經網絡參數,使其學習到更能代表原始數據的文本語義表示Z。
LAE=1n‖X-X^‖2F(2)
2.2 基于主動學習的半監督生成器
2.2.1 邊緣文本挑選模塊
在監督信息數量有限的情況下,所選擇的監督信息應該對優化類簇結構具有較高的價值。在半監督聚類任務中,處于類簇邊界的邊緣文本具有極高的不確定性,蘊涵了更豐富的信息。因此,若監督信息涵蓋邊緣文本,則能為類簇的劃分提供更多的信息,幫助優化類簇結構。本文提出的邊緣文本挑選模塊設計了基于主動學習方法的挑選機制,旨在發現類簇中蘊涵豐富信息的邊緣文本,從而構建關系問題,進一步生成涵蓋邊緣文本的高質量監督信息。根據觀察結果,本文所挑選的邊緣文本滿足以下特點:邊緣文本大多處于兩個或兩個以上的類簇邊界處,它們屬于周圍類的概率是相似的。例如,考慮第i個樣本是邊緣文本,該樣本位于空間位置上第j和k個類的類簇邊緣。在這種情況下,第i個樣本同時屬于第j和k個類的概率非常接近。這意味著邊緣文本對于其所屬類簇的歸屬是極其不確定的。基于上述特性,本文構造了式(3)來發現邊緣文本。
E=argminxi-∑nj=1p(yj|xi)lg(p(yj|xi))(3)
其中:yj表示樣本被分配到第j個類的事件;p(yj|xi)表示xi這個樣本被分配到第j個類這個事件的概率;∑ni=1 ∑nj=1p(yj|xi)反映了當前聚類結構分布情況。本文基于最小化信息熵,挑選一批不確定性最高的邊緣文本。
在半監督聚類中,監督信息多以約束對的形式出現。因此在挑選出邊緣文本E={e1,e2,…,en}后,還需進一步使用邊緣文本生成合適的約束對。本文的思路是:a)根據當前類簇劃分確認聚類中心文本,即與聚類質心最相似的文本,聚類中心文本可以按照式(4)求得(μj表示第j個簇的聚類質心,sim(·)表示相似度的度量,從X={x1,x2,…,xn}中選擇出文本ci,使得式(4)成立,即文本ci與聚類質心μj有最大相似度,那么文本ci被認定是第j個簇的中心文本)。b)構建關于邊緣文本和中心文本的約束對。本文將獲取邊緣文本和中心文本的真實關系,進一步形成邊緣文本-中心文本的關系對。這些關系對將作為半監督聚類中的監督信息,以優化類簇結構,提升聚類效果。
因此,如何獲取邊緣文本和聚類中心文本的關系尤為重要。本文首先設計一批關于邊緣文本-中心文本的問題,該問題將邊緣文本與中心文本一一對應,以關系對〈ei,cj〉的形式呈現,并將這些關系問題作為后續模塊的輸入,后續模塊將給出明確的關于關系的答案。
argmaxci∑kj=1sim(ci,μj)(4)
2.2.2 基于主動學習的監督信息生成模塊
本節基于主動學習的思想,旨在生成涵蓋邊緣文本的高質量監督信息,并利用該監督信息指導聚類過程。首先,將上一模塊構建的關系問題通過標注過程,查詢邊緣文本與中心文本之間的真實關系,從而構建邊緣文本-中心文本關系對。具體來說,如果當前的邊緣文本ei與中心文本cj屬于同一個類,那么在本文中,認為它們是存在聯系的,將它們形成的關系對〈ei,cj〉加入到關系對集合R當中。最終,將得到一批涵蓋了邊緣文本的關系對,這批關系對能為聚類提供更豐富的信息。
接下來,要考慮如何將關系對用于指導聚類,幫助優化類簇結構。DASCM利用關系對構造半監督信息矩陣,用于引導聚類。半監督信息矩陣為n×n的對稱矩陣M,Mij記錄了樣本xi與xj之間的關系。在本文中,設定有兩種關系:a)ML約束,表示樣本xi與xj屬于同一類;b)CL約束,表示樣本xi與xj不屬于同一類。對稱矩陣的構造如下:
Mij=1 (xi,xj)∈R0(xi,xj)R(5)
根據已獲取的關系對,本文將屬于同一類的邊緣文本ei和中心文本cj對應的半監督信息矩陣的第i行和第j列的值設置為1,由于半監督信息矩陣為對稱矩陣,Mji的值也設置為1。不屬于同一類的文本所對應的值設置為0。
DASCM利用監督信息更新重構目標,以此學習到更好的文本語義表示,從而提升聚類效果。本文設計了式(6),利用半監督信息矩陣更新文本表示學習模塊的訓練目標,監督自編碼器對文本語義表示的學習。
Y=M·X+X(6)
其中:M表示半監督信息矩陣;X表示文本向量表示。本文將重構目標更新,從而引導學習到的文本語義表示改變,進一步提升聚類效果。
本文利用主動學習方法發現類簇中蘊涵豐富信息的邊緣文本,并通過查詢邊緣文本與中心文本的實際關系,構建基于邊緣文本的關系對。本文利用這些關系對構造半監督信息矩陣,并利用這些監督信息指導聚類,從而提升聚類性能。
2.3 聚類模塊
本節將學習到的文本語義表示點進行聚類,并不斷調整參數得到更好的聚類結果。
在得到新的訓練目標Y后,根據式(2),可進一步得到如下所示的目標函數:
LAE=1n‖X^-(M·X+X)‖2F(7)
其中:X^是AE的輸出;M是利用監督信息生成的半監督信息矩陣,用于更新原來的重構目標。通過最小化損失函數LAE(式(7))得到所期望的文本語義表示Z。
給定文本語義表示學習模塊學習好的文本語義表示和初始聚類質心,本文使用兩個步驟交替的算法來改進聚類。a)計算文本語義表示點和類簇質心之間的軟分配,即文本語義表示點屬于每個類的概率;b)更新深度映射fθ,即更新神經網絡的參數,旨在調整文本語義表示點以更好地對應聚類質心,并且利用輔助目標分布來優化聚類質心。交替進行這個過程,直到滿足收斂標準。
t-分布能夠減少異常點的影響,為了更好地適應不同分布的數據,本文采用t-分布來計算zi和μj之間的軟分配。qij表示第i個文本屬于第j個類的概率,公式如下:
qij=(1+‖zi-μj‖2/α)-α+12∑j′(1+‖zi-μj′‖2/α)-α+12(8)
其中:α是t-分布的自由度,在本文中設置為1。為了優化聚類質心,使用了如下所示的輔助目標分布。
pij=q2ij/fj∑j′q2ij′/fj′(9)
其中: fi=∑jq2ij是軟類簇分配概率,輔助目標分布pij能夠幫助強化預測。
DASCM通過匹配軟分配與輔助目標分布來訓練,為此,定義聚類損失函數為軟分配和目標分布之間的KL散度損失(式(10))。
L=KL(P‖Q)=∑i ∑j(pijlogpijqij)(10)
算法1 DASCM模型的運算過程
輸入:文本數據集;關系對數量b;最大迭代次數 MaxIter,預訓練次數epochs,待學習的DASCM模型。
輸出:文本聚類結果。
1)文本語義表示的學習
while 訓練次數< epochs:
do 根據式(2)訓練文本表示模塊,更新模塊神經網絡參數W(l),b(l)
end
依據訓練好的文本表示模塊,根據式(1)得到初步的文本表示H
return H
2)聚類
使用K-means算法初始化聚類中心μ
while迭代次數< MaxIter:
do 使用式(8),根據Z和μ計算Q分布
使用式(9),根據分布Q計算目標分布P
根據式(10),更新模型參數
end
return 聚類結果
3)邊緣文本挑選
根據得到的聚類結果,利用式(3)發現類簇邊緣文本E
利用式(4)計算得到所有中心文本c,將每個邊緣文本ei與中心文本cj一一對應,生成關系問題〈ei,cj〉
4)基于主動學習的監督信息生成
將所有關系問題組通過標注查詢得到邊緣文本與中心文本的實際關系,屬于同一類的〈ei,cj〉加入關系對集R,最終得到數量為b的關系對
使用關系對集R通過式(5)構造半監督信息矩陣M
通過式(6),計算得到新的訓練目標Y
return Y
將新的訓練目標Y用于替換文本語義表示學習中的訓練目標
再次運行1)2)兩個過程
return 聚類結果
2.4 參數優化
在本文中,主要利用半監督信息矩陣M更新訓練目標,利用損失函數(式(7))使得AE能夠進一步學習到更好的文本語義表示Z。AE的參數為W,偏置為b,給定神經網絡輸出X^計算如式(11)所示。
X^=WX+b(11)
利用隨機梯度下降(stochastic gradient descent,SGD)優化深度神經網絡參數。損失函數LAE關于神經網絡參數W求導為
LAE W=2n(WX+b-(MX+X))·XT(12)
對神經網絡參數b求導,如式(13)所示。
LAE W=2n(WX+b-(MX+X))(13)
參數W的更新如下所示,其中η為學習率。
Wnew→Wold-η· LAE W(14)
參數b的更新如下所示。
bnew→bold-η· LAE b(15)
由于蘊涵豐富信息的半監督矩陣M參與了神經網絡參數的更新,模型生成的高價值監督信息將正向引導神經網絡訓練。這能夠幫助AE學習到更好的文本語義表示Z,使用更新的Z可以促進類簇的劃分,從而達到更好的聚類效果。
2.5 模型時空復雜度分析
為了更好地闡明DASCM的效率,本文對該模型的時間和空間復雜度進行了分析。
本文設定輸入數據的維度為d,數量為n。對于文本語義表示模塊,設神經網絡層數為L,各層輸出維度分別為d1,d2,…,dL。時間復雜度為O(nd21d22…d2L),空間復雜度為O(nd)。對于聚類模塊,設定類簇數量為k, 該模塊與DEC的時空復雜度一致。時間復雜度為O(kn+n ln(n)),空間復雜度為O(kn)。
對于基于主動學習的監督信息生成模塊,設定關系對數量為b,類簇數量為k。首先是邊緣文本挑選部分,時間消耗主要在于邊緣文本的挑選過程,時間復雜度為O(kn)。該部分需要存儲邊緣文本和中心文本,因此空間復雜度為O(b/k+k)。然后是基于主動學習的監督信息生成部分,因為本文模型將邊緣文本和中心文本一一對應構造成關系對,所以時間復雜度為O(b),空間復雜度為O(b)。因為本文模型直接存儲了關系對所對應的索引,所以半監督信息矩陣的時間復雜度為O(b),空間復雜度為O(n2+b)。
綜上所述,本文DASCM總的時間復雜度為O(nd1d2…dL+2kn+n ln(n)+2b),總的空間復雜度為O(n2+(d+k)n+b/k+k+2b)。
3 實驗與結果分析
本章將分析實驗所需數據集,并在此基礎上驗證DASCM的效果,分別從數據集描述和評估方法、模型參數設置、結果和分析三個部分進行描述。
3.1 數據集描述
a)Abstract數據集(https://www.aminer.cn)。該數據集包含來自Aminer網站的 4 306 篇論文,從信息通信、數據庫和圖形三個研究領域中隨機選擇而來。該數據集通常應用于文本聚類任務,可參考文獻[28]。
b)BBC數據集(http://mlg.ucd.ie/datasets/bbc.html)。該數據集包含來自BBC新聞網站的2 250條文本數據,對應商業、娛樂、政治、體育和科技五個主題。BBC數據集不同類別的文章數量相同,且文本主題特征比較明顯,因此常被用于文本聚類任務,可參考文獻[29]。
c)ACM數據集(https://paperswithcode.com/dataset/acm)。該數據集選擇了在KDD、SIGMOD、SIGCOMM、MobiCOMM和VLDB上發表的3 025篇英文論文,并根據研究領域將論文分為數據庫、無線通信和數據挖掘三類。數據集適用于文本聚類任務,可參考文獻[30]。
d)Citeseer數據集(https://paperswithcode.com/dataset/ citeseer)。該數據集是一個引文網絡,包含3 327條數據,涉及代理、人工智能、數據庫、信息檢索、機器語言和人機交互六個領域。數據集常應用于文本聚類任務,可參照文獻[31]。
e)Reuters-10k數據集(https://github.com/slim1017/VaDE /tree/master/dataset/reuters10k)。該數據集選取了來自路透社的10 000條英語新聞故事,包含公司/工業、政府/社會、市場和經濟這四個類別,常用于文本聚類或分類任務,可參考文獻[2]。
3.2 評測指標
本文使用三種測量指標來評價聚類效果,分別是聚類精度(accuracy, ACC)、歸一化信息(normalized mutual information,NMI)、調整蘭德系數(adjusted Rand index,ARI)。
1)NMI
NMI用于衡量聚類的預測結果與標準結果之間的相似性,NMI 的取值在[0, 1],值越高表示預測的聚類結果越接近標準結果。計算如式(16)所示。
NMI(C;K)=2I(C;K)H(C)+H(K)(16)
其中:H(C)為預測聚類結果C的熵;H(K)為標準結果K的熵。計算如式(17)所示。
H(C)=-∑ni=1p(ci)log p(ci)(17)
其中:I(C;K)是C和K之間的互信息,代表聯合分布p(C,K)與乘積分布p(C)p(K)的相對熵,其計算如式(18)所示。
I(C;K)=∑c ∑kp(c,k)logp(c,k)p(c)p(k)(18)
2)ACC
ACC是一種用于衡量聚類算法性能的指標,類似于分類問題中的準確率。它衡量的是聚類結果中被正確歸類的樣本所占的比例,其計算如式(19)所示。
ACC=maxm∑ni=11{li=m(ci)}n(19)
其中:li是真實標簽;ci是模型預測的聚類分配;m(·)按照真實標簽的排列方式,將聚類分配映射成標簽結果。
3)ARI
調整蘭德系數是一種用于衡量聚類算法性能的指標,通常用于評估聚類結果與真實標簽之間的相似度。它的值越接近1,說明聚類結果越接近真實情況,計算如式(20)所示。
ARI=RI-E(RI)max(RI)-E(RI)(20)
RI(Rand index)是蘭德系數,E(RI)是RI的期望。RI為
RI=TP+TNTP+FP+TN+FN(21)
其中:TP表示在真實標簽中屬于同一個類簇且在聚類結果中也被分到同一個簇的樣本對的數量,這是聚類結果和真實標簽都正確的樣本對的數量;TN表示在真實標簽中屬于不同類簇且在聚類結果中也被分到不同簇的樣本對的數量,這是聚類結果和真實標簽都正確的樣本對的數量;FP表示在真實標簽中屬于不同類簇但在聚類結果中被分到同一個簇的樣本對的數量,這是聚類結果中錯誤分類的樣本對的數量;FN表示在真實標簽中屬于同一個類簇但在聚類結果中被分到不同類簇的樣本對的數量,這是聚類結果中錯誤分類的樣本對的數量。
3.3 參數設置
本文使用自動編碼器對數據集進行預訓練,編碼器維度設置為d-500-500-500-10,其中d為數據集的維度,解碼器為編碼器的鏡像網絡。針對所有數據集,均采用學習率η=0.01,β=0.9的優化器,批次大小為256,收斂閾值為0.1%。所有數據集的關系對數量b取1 000。每個數據集結果總共運行 10 次,并去掉最高值和最低值后算平均值,避免產生極端情況。
3.4 實驗分析
3.4.1 文本聚類實驗
本文在Abstract、BBC、ACM、Citesser、Reuters-10k共五個文本數據集上驗證DASCM的聚類性能,并選擇了三類聚類模型進行對比,分別是經典的深度聚類模型、發掘文本之間關聯信息的聚類模型、深度半監督聚類模型和帶主動學習模型。
a)經典的深度聚類模型。本文選擇了三個經典的深度聚類模型作比較。AE[32]是學習文本語義表示并進行聚類的兩階段深度聚類模型。DEC基于AE引入KL散度,以聯合優化文本語義表示和聚類兩個過程。IDEC[33]對DEC進行改進,當學習文本語義表示時,在特征空間中保留了數據的局部結構信息。
b)發掘文本之間關聯信息的聚類模型。GAE[34]將AE中的編碼器和解碼器換成圖卷積網絡(GCN)以學習圖結構信息,SDCN[31]同時學習文本語義表示和文本結構表示,并采用雙重自監督以優化學習表示和聚類兩個過程。
c)半監督聚類模型。SDEC[15]是半監督的深度聚類模型,它基于DEC引入先驗知識,以進一步優化模型提高聚類效果。
d)帶主動學習的模型。ADC(active deep image clustering)[35]模型提出了一種新穎的深度主動聚類方法,該模型能主動選擇關鍵數據進行人工標注,并用以改進深度聚類。
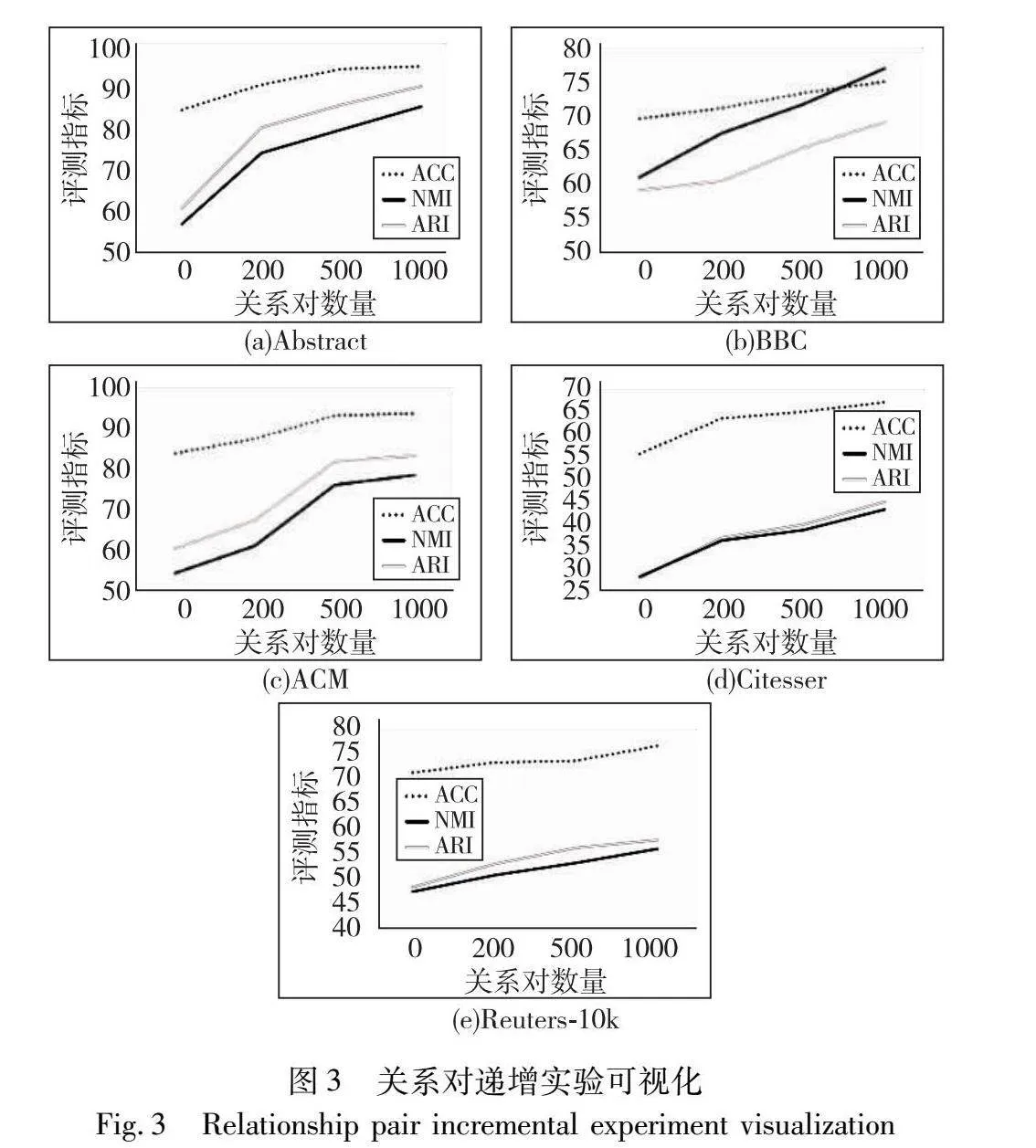
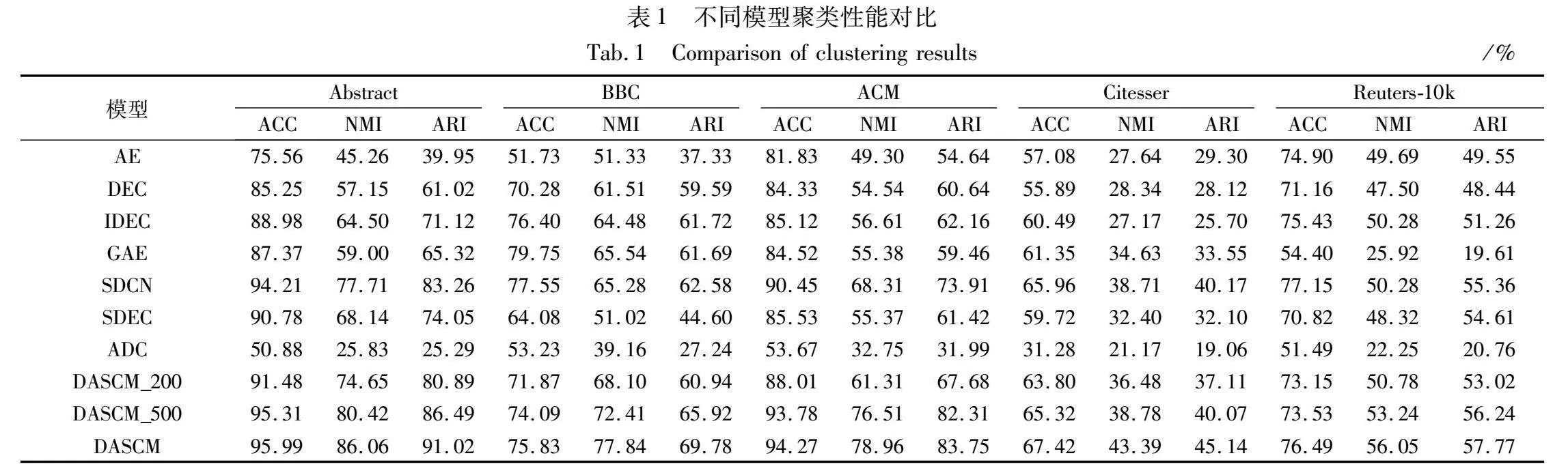
其他模型按照其文獻給出的最優參數進行實驗,ADC的約束對數量設置為1 000,訓練輪次和批次的設置與DASCM一致。為進一步驗證通過主動學習發現的邊緣文本與聚類性能提升的相關性,DASCM選取不同數量的關系對(b=200、b=500、b=1 000)進行實驗對比,實驗結果如表1所示。
在五個真實數據集上的實驗證明,DASCM 相較于其他無監督聚類模型在文本聚類結果的各項評測指標上都有明顯提升,相較于所有模型中最優的聚類結果,NMI 指標分別提升了8.35,12.3,10.65,4.68和5.77百分點,這是因為本文提出的主動學習能夠挑選出蘊涵豐富信息的邊緣文本,并生成了涵蓋邊緣文本的高質量監督信息,從而進一步提升了聚類性能。這也證明了DASCM的有效性。
DASCM的各項評測指標也高于同為深度半監督聚類模型的SDEC,說明了基于主動學習的半監督信息生成器產生的監督信息比隨機產生的監督信息對聚類更有意義。
然而含有主動學習的ADC表現較差,大概率是因為它是為處理圖像數據而設計的,所以在文本數據集上表現不佳。
為了更加直觀地展示模型性能隨著關系對數量變化而變化,本文繪制了各指標對比的折線圖,如圖3所示。隨著關系對數量的增加,各項指標也隨之提升,這是因為給的關系對越多,所提供的信息越豐富。對聚類任務而言,蘊涵更多信息的關系對具有更高的價值,對聚類的指導作用更大。這一結果也證明了本文設計的主動學習方法的有效性。但同樣可以觀察到隨著關系對數量的增加,各項聚類指標逐漸趨于平緩。這是因為隨著關系對數量的增加,所生成的關系對可能會包含那些蘊涵信息量較少的樣本,對聚類的指導作用不大,性能提升也不明顯。
3.4.2 消融實驗
為了驗證基于主動學習的半監督信息生成器每個部分的有效性,本文在同樣的5個數據集上對每個部分逐一消融實驗,并與原模型的聚類性能對比,如表2所示。如果聚類性能都比原模型的低,則表明每個部分都是有效的。
DASCM-a去掉了基于主動學習的監督信息生成部分,其他部分與參數均與原模型保持一致。DASCM-a實驗結果明顯低于原模型,這是因為該模型沒有生成涵蓋邊緣文本的監督信息,未能對聚類進行有效指導。
在DASCM-r中,邊緣文本不再通過主動學習方法進行挑選,而是隨機選取,其數量與DASCM模型中的設置保持一致。此外,DASCM-r的其余部分和參數也和原模型保持一致。DASCM-r的聚類性能同樣也比原模型低,這是因為隨機挑選的文本質量不佳,而通過主動學習方法挑選出的邊緣文本蘊涵更豐富的信息。對聚類任務而言,涵蓋邊緣文本的監督信息也具有更高的價值,能更好地指導聚類。
3.4.3 可視化實驗
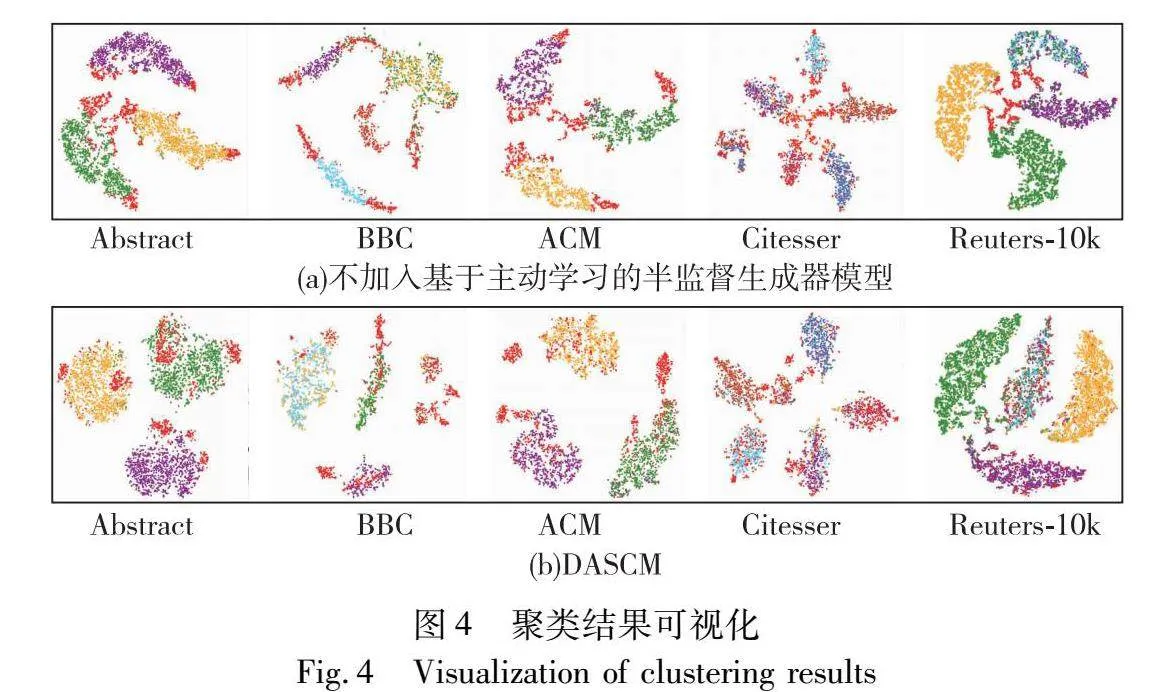
為了更加直觀體現模型的有效性,本文對比了去除基于主動學習的半監督信息生成器的模型與DASCM的可視化聚類結果,可以直觀感受到DASC模型有效提升了聚類性能。
圖4展示了可視化聚類結果,其中圖(a)表示未加入基于主動學習的半監督信息生成器的模型聚類結果,圖(b)展示了DASCM的聚類結果。圖4中紅色的點(見電子版)表示邊緣文本,在未加入基于主動學習的半監督生成器時,類簇的邊界之間存在許多邊緣文本,嚴重影響了聚類結構的清晰度。
加入基于主動學習的半監督生成器之后,聚類結構清晰度大大提升了,這是因為模型利用主動學習方法挑選出蘊涵豐富信息的邊緣文本,并生成監督信息用于指導聚類過程。高價值的監督信息對聚類起到了正向引導作用,使得邊緣文本所屬類簇更加明確,類簇結構更加清晰。
3.4.4 主動學習代價分析
DASCM的代價主要由文本語義表示學習代價、主動學習挑選代價、標注代價和聚類代價四個部分組成。其中,文本語義表示學習成本和聚類成本類似于其他深度聚類模型。利用主動學習方法進行挑選的代價與數據集的規模密切相關。以BBC數據集為例(表3),可以觀察到使用主動學習進行挑選的代價在整個模型中占比較小。
在主動學習中,人工標注是不可避免的,并且其成本也與數據規模有關,較大規模的數據集將需要更多的時間和資源進行標注。然而,相較于其他監督模型和半監督模型,DASCM花費同樣的代價卻能更大程度地提升模型性能。如表4所示,本文對比使用隨機方法選取1 000對關系對作為監督信息(DASCM-r)和用主動學習方法選取1 000對關系對(DASCM)的聚類結果。可以注意到,當花費相同代價時,使用主動學習方法的模型性能可以得到更大提升。此外,本文挑選的關系對均為1 000對,而每個數據集可以組成上百萬的關系對(n×n對),相較而言,這個代價也是可接受的。
3.5 實現過程
本文以Abstract數據集為例,詳細描述DASCM的實現過程。如圖2所示,首先模型學習數據的文本語義表示,接著將學習到的文本語義表示進行聚類,得到初步的聚類結果。最后,DASCM根據當前聚類結果挑選邊緣文本。如圖5所示,圖5(a)展示了基于初步聚類結果挑選邊緣文本的結果。本文將每個類的邊緣文本顏色高亮展示,以示區分。
邊緣文本處于各個類的交界處,具有極高的不確定性,同時它們也蘊涵豐富的信息。為了進一步利用這些邊緣文本指導聚類。本文選擇將它們與中心文本(第一幅圖中加粗加黑的文本點)對應,以關系對的形式作為監督信息。圖5(b)展示了關系對的構造過程(因邊緣文本太多,本文只隨機選取5個邊緣文本點進行演示)。本文將邊緣文本(紅圈標明部分,參見電子版)與全部的中心文本一一對應,將這些文本對通過人工標注,標注過程詳見2.2.2小節。接著本文根據關系對構造了一個半監督信息矩陣,該矩陣是一個n×n的對稱矩陣,維度與數據集大小一致。
隨后矩陣將被用于更新重構目標,方法如式(6)所示。本文選取其中一個邊緣文本觀察其重構目標的高頻詞變化(圖5(c))。該邊緣文本真實的類別應該為數據庫,更新后增加了table、data等與數據庫主題相關的詞語,能夠幫助學習到更好的文本語義表示。最后模型將根據更新后的重構目標學習新的文本語義表示,進而將其用于聚類。圖5(d)展示了新的聚類結果,與圖5(a)比較,邊緣文本更加靠近其所屬類簇,類簇劃分也更加清晰。
4 結束語
本文提出一種基于主動學習的深度半監督聚類模型(DASCM),該模型利用主動學習方法挑選出類簇的邊緣文本,并構建了邊緣文本-中心文本關系對,為半監督聚類提供了高質量的監督信息。本文利用這些關系對進一步構建了半監督信息矩陣,顯著提升了聚類效果。
在五個真實數據集上的實驗結果證明,相較于其他模型,DASCM在聚類性能上有明顯提升。然而,DASCM關系對的數量是給定的,當聚類結果中邊緣文本數量較少時,模型仍會挑選出給定數量的邊緣文本,這可能導致資源的浪費。因此,下一步的研究方向是設計一種衡量已挑選的樣本和未挑選樣本之間關聯度的方法,以避免選取對類簇劃分貢獻相似的樣本。此外,在訓練過程中,該方法設置合適的條件,一旦選取的樣本不再對類簇劃分產生優化或其作用變得微不足道,將停止選取。
參考文獻:
[1]Ezugwu A E, Ikotun A M, Oyelade O O,et al. A comprehensive survey of clustering algorithms: state-of-the-art machine learning applications, taxonomy, challenges, and future research prospects[J]. Engineering Applications of Artificial Intelligence, 2022, 110: 104743.
[2]Xie Junyuan, Girshick R, Farhadi A. Unsupervised deep embedding for clustering analysis [C]// Proc of the 33rd International Confe-rence on Machine Learning. [S.l.]: PMLR, 2016: 478-487.
[3]Cai Jianghui, Hao Jing, Yang Haifeng,et al. A review on semi-supervised clustering[J]. Information Sciences, 2023, 632: 164-200.
[4]Liu Yuqiao, Sun Yanan, Xue Bing,et al. A survey on evolutionary neural architecture search[J]. IEEE Trans on Neural Networks and Learning Systems, 2021, 34(2): 550-570.
[5]張賢坤, 劉淵博, 任靜, 等. 主動糾錯式半監督聚類社區發現算法[J]. 計算機應用研究, 2019, 36(9): 2631-2635, 2660. (Zhang Xiankun, Liu Yuanbo, Ren Jing,et al. Active error-correcting community discovery algorithm based on semi-supervised clustering[J]. Application Research of Computers, 2019, 36(9): 2631-2635, 2660.)
[6]Ren Pengzhen, Xiao Yun, Chang Xiaojun,et al. A survey of deep active learning[J]. ACM Computing Surveys, 2021, 54(9): 1-40.
[7]Menin B. Unleashing the power of information theory: enhancing accuracy in modeling physical phenomena[J]. Journal of Applied Mathematics and Physics, 2023, 11(3): 760-779.
[8]李靜楠, 黃瑞章, 任麗娜. 用戶意圖補充的半監督深度文本聚類[J]. 計算機科學與探索, 2023, 17(8): 1928-1937. (Li Jingnan, Huang Ruizhang, Ren Lina. Semi-supervised deep document clustering model with supplemented user intention[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(8): 1928-1937.)
[9]Bair E. Semi-supervised clustering methods[J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2013, 5(5): 349-361.
[10]Taha K. Semi-supervised and un-supervised clustering: a review and experimental evaluation[J]. Information Systems, 2023, 114: 102178.
[11]Shen Baohua, Jiang Juan, Qian Fuan,et al. Semi-supervised hierarchical ensemble clustering based on an innovative distance metric and constraint information[J]. Engineering Applications of Artificial Intelligence, 2023, 124: 106571.
[12]Basu S, Bilenko M, Mooney R J. Comparing and unifying search-based and similarity-based approaches to semi-supervised clustering[C]// Proc of ICML-2003 Workshop on the Continuum from Labeled to Unlabeled Data in Machine Learning and Data Mining Systems. New York: ACM Press, 2003: 42-49.
[13]Kodinariya T M, Makwana P R. Review on determining number of cluster in K-means clustering[J]. International Journal, 2013, 1(6): 90-95.
[14]Wagstaff K, Cardie C. Clustering with instance-level constraints[C]// Proc of the 7th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2000: 1103-1110.
[15]Ren Yazhou, Hu Kangrong, Dai Xinyi,et al. Semi-supervised deep embedded clustering[J]. Neurocomputing, 2019, 325: 121-130.
[16]Ohi A Q, Mridha M F, Safir F B,et al. AutoEmbedder: a semi-supervised DNN embedding system for clustering[J]. Knowledge-Based Systems, 2020, 204: 106190.
[17]Wang Yalin, Zou Jiangfeng, Wang Kai,et al. Semi-supervised deep embedded clustering with pairwise constraints and subset allocation[J]. Neural Networks, 2023, 164: 310-322.
[18]Nguyen V L, Shaker M H, Hüllermeier E. How to measure uncertainty in uncertainty sampling for active learning[J]. Machine Learning, 2022, 111(1): 89-122.
[19]Lewis D D. A sequential algorithm for training text classifiers: corrigendum and additional data[C]// Proc of ACM SIGIR Forum. New York: ACM Press, 1995, 29(2): 13-19.
[20]Seung H S, Opper M, Sompolinsky H. Query by committee[C]// Proc of the 5th Annual Workshop on Computational Learning Theory. New York: ACM Press, 1992: 287-294.
[21]Settles B, Craven M, Ray S. Multiple-instance active learning[C]// Proc of the 20th International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2007: 1289-1296.
[22]Settles B, Craven M. An analysis of active learning strategies for sequence labeling tasks[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2008: 1070-1079.
[23]Sinha S, Ebrahimi S, Darrell T. Variational adversarial active lear-ning[C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 5972-5981.
[24]Kim K, Park D, Kim K I,et al. Task-aware variational adversarial active learning[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2021:8166-8175.
[25]Cho J W, Kim D J, Jung Y,et al. MCDAL: maximum classifier discrepancy for active learning[J]. IEEE Trans on Neural Networks and Learning Systems, 2022, 34(11): 8753-8763.
[26]Gálvez-López D, Tardós J D. Real-time loop detection with bags of binary words[C]// Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE Press, 2011: 51-58.
[27]任麗娜, 秦永彬, 黃瑞章, 等. 基于多層子空間語義融合的深度文本聚類[J]. 計算機應用研究, 2023, 40(1): 70-74, 79. (Ren Li’na, Qin Yongbin, Huang Ruizhang,et al. Deep document clustering model via multi-layer subspace semantic fusion[J]. Application Research of Computers, 2023, 40(1): 70-74, 79.)
[28]黃瑞章, 白瑞娜, 陳艷平, 等. CMDC: 一種差異互補的迭代式多維度文本聚類算法[J]. 通信學報, 2020, 41(8): 155-164. (Huang Ruizhang, Bai Ruina, Chen Yanping,et al. CMDC: an iterative algorithm for complementary multi-view document clustering[J]. Journal on Communications, 2020, 41(8): 155-164.)
[29]Greene D, Cunningham P. Practical solutions to the problem of diagonal dominance in kernel document clustering[C]// Proc of the 23rd International Conference on Machine Learning. New York: ACM Press, 2006: 377-384.
[30]Wang Xiao, Ji Houye, Shi Chuan,et al. Heterogeneous graph attention network[C]// Proc of World Wide Web Conference. New York: ACM Press, 2019: 2022-2032.
[31]Bo Deyu, Wang Xiao, Shi Chuan,et al. Structural deep clustering network[C]// Proc of Web Conference. New York: ACM Press, 2020: 1400-1410.
[32]Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
[33]Guo Xifeng, Gao Long, Liu Xinwang,et al. Improved deep embedded clustering with local structure preservation[C]// Proc of the 26th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017: 1753-1759.
[34]Wang Wei, Huang Yan, Wang Yizhou,et al. Generalized autoenco-der: a neural network framework for dimensionality reduction[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE Press, 2014: 496-503.
[35]Sun Bicheng, Zhou Peng, Du Liang,et al. Active deep image clustering[J]. Knowledge-Based Systems, 2022, 252: 109346.
