基于統計推理的不一致數據清洗方法
2024-10-14 00:00:00張安珍胡生吉夏秀峰
計算機應用研究 2024年10期







摘 要:不一致數據修復是數據清洗領域的一個重要研究方向,現有方法大多是基于完整性約束規則的,采用最小代價原則進行修復,然而,代價最小的修復方案通常是不正確的,導致現有修復方法的準確率較低。針對現有方法準確率較低的問題,提出了一種基于統計推理的不一致數據清洗方法BayesOUR,兼顧修復的代價與質量,提高修復準確性。BayesOUR主要分為三個階段:首先根據完整性約束規則進行錯誤檢測;然后利用貝葉斯網絡推理所有可能的一致性修復方案概率;最后選擇概率最大的修復方案進行數據清洗。真實數據上的實驗結果表明,該方法與目前領先的方法相比,能夠顯著提高不一致數據修復的準確性。
關鍵詞:不一致數據;貝葉斯網絡;統計推理
中圖分類號:TP301 文獻標志碼:A 文章編號:1001-3695(2024)10-015-2987-06
doi:10.19734/j.issn.1001-3695.2024.02.0055
Cleaning inconsistent data based on statistical inference
Zhang Anzhen1,2,Hu Shengji2,Xia Xiufeng2
(1.Shenyang Institute of Computing Technology,Chinese Academy of Sciences,Shenyang 110168,China;2.School of Computer Science,Shenyang Aerospace University,Shenyang 110136,China)
Abstract:Inconsistent data repair is an important research direction in the field of data repair.Most of the existing methods are based on integrity constraint rules and use the principle of minimum cost for repair.However,the repair scheme with the minimum cost is usually incorrect,which leads to the low accuracy rate of the existing repair methods.To address the problem of low accuracy of existing methods,this paper proposed an inconsistent data repair method based on statistical inference BayesOUR,to balance the cost and quality of repair and improve the repair accuracy.It mainly divided BayesOUR into three phases.Firstly,it performed error detection based on the integrity constraint rule,and then utilized Bayesian network to reason about the probability of all the possible consistent repair schemes.Finally,it selected the repair scheme with the largest probabGKv+QZu+Td7KJLWmUnZiFA==ility for data repair.Experimental results on real data show that the method in this paper can significantly improve the accuracy of inconsistent data repair compared with the current leading methods.
Key words:inconsistent data;Bayesian network;probabilistic inference
0 引言
數據清洗(data cleaning)是數據預處理過程中的一個重要步驟,旨在識別和糾正數據中的錯誤、缺失、重復或者不一致之類的問題。數據清洗有助于提高數據的質量、準確性和可用性,使其更適合分析和挖掘。隨著大數據時代的到來,數據質量問題也隨之而來,嚴重影響了生產生活的方方面面,數據清洗變得越發重要。
本文主要研究數據不一致問題的數據清洗[1],現有的數據清洗方法一是為了盡可能減少對原始數據的改動,通常遵循最小化修復代價原則,將對數據改動最少的修復方案作為最優修復;二是單純地統計數據整體出現的頻率估計概率,將概率最大的修復方案作為最優修復方案。然而,這些方法僅僅考慮了整體的修復代價或者修復概率,沒有考慮整體上的修復質量,導致修復的準確率較低。
為此,本文提出了一種基于統計推理的不一致數據清洗方法BayesOUR,該方法利用貝葉斯網絡上的數據結構,考慮其相關屬性之間的概率信息,進行概率的統計推理來計算每種修復方案的正確性概率,選擇概率最大的修復方案作為最優修復方案,進而提高了修復準確性。具體過程如下:首先,利用完整性約束規則進行不一致檢測,識別不一致元組以及可能出錯的屬性;其次,對每個出錯元組,計算其所有可能的一致性修復方案;最后,利用貝葉斯網絡建模屬性之間的關聯關系,并在此基礎上設計高效的統計推理方法,計算每種修復方案的正確概率并從中選擇概率最大的作為最優方案。
綜上所述,本文的主要貢獻如下:
a)提出一種高效的啟發式錯誤檢測方法,可以有效減小不一致元組規模,提高修復效率。
b)提出了正確性概率模型來量化修復方案質量,并提出一種高效的統計推理方法計算每種修復方案的正確性概率。
c)通過大量實驗評估,驗證本文方法在真實世界數據集上的有效性和高效性。
1 相關工作
目前,數據清洗領域的研究工作主要分為基于完整性約束規則的以及規則與概率相結合的兩大類[2~6]。基于完整性約束規則的方法通常采用最小化修復代價原則,選擇對數據改動最小的方案進行數據修復[7~12]。例如,文獻[13~16]提出了多種啟發式修復方法來提高修復準確性;文獻[17]提出了迭代式修復框架DEC,利用聯合概率分布修復數據錯誤;文獻[18]提出了“統計失真”定義修復后的數據分布與理想數據分布之間的距離;文獻[19]提出了基于最大似然估計的錯誤修復框架SCARE;文獻[20]設計了增量式數據清洗框架ActiveClean;文獻[21]提出了基于信念傳播和關系依賴網絡的迭代修復框架ERACER。這類方法忽視了數據之間的關聯關系,導致修復準確性不高。
為了提高修復準確率,Prokoshyna等人[22]最早將概率與規則相結合,提出了概率擾動最小的修復方案求解方法。隨后,文獻[23,24]提出了基于馬爾可夫邏輯網絡與拒絕約束規則的混合式數據清洗框架。Rekatsinas等人[25]提出了將完整性約束、知識庫、統計學等多種修復方法相結合的HoloClean系統。由于滿足約束規則的方法不止一個,Yu等人[26]提出選取概率較大的幾種修復方案提交給用戶,讓用戶從中選擇真實值,然后根據反饋結果更新概率計算模型。Mahdavi等人[27]同樣提出結合統計學習、完整性約束以及概率推理的Raha系統來進行錯誤數據修復。這些方法在一定程度上提高了修復準確率,然而還未達到實際應用場景對數據質量的要求。
2 預備知識以及問題定義
本章首先介紹函數依賴與數據修復背景知識,其次給出基于統計推理的不一致數據清洗方法的問題定義,最后介紹基于統計推理的數據修復方法。值得一提的是,本文只考慮由拼寫錯誤、替換錯誤等引發的數據不一致問題,其他類型的錯誤(如缺失值、重復值等)不在本文研究范圍內。
2.1 函數依賴和數據修復
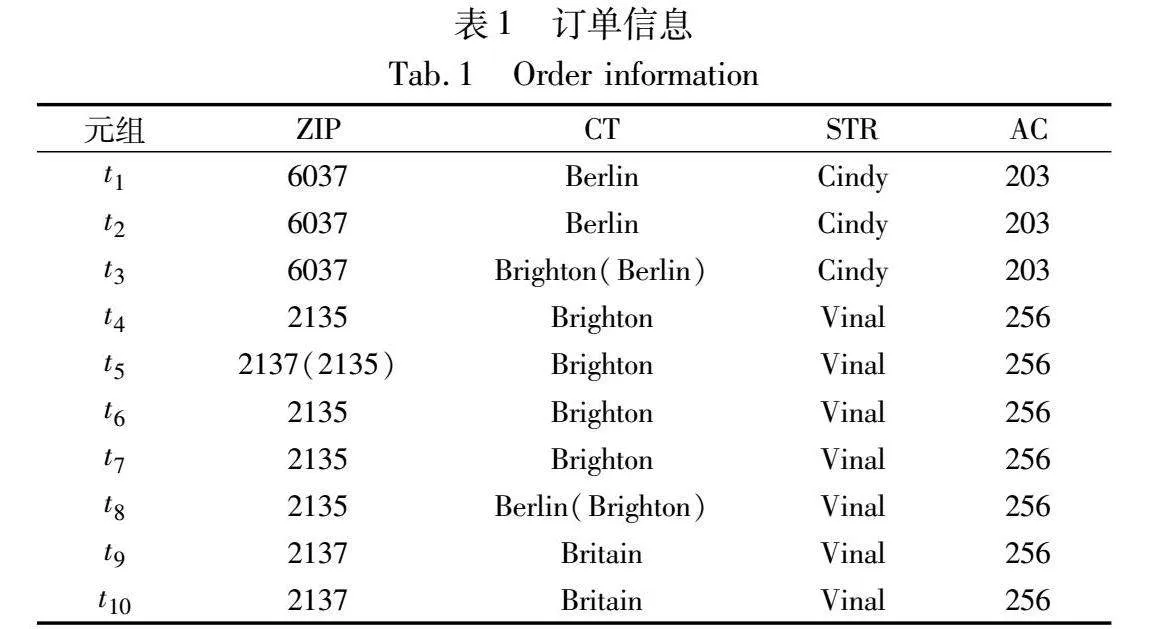
函數依賴(functional dependency,FD)是數據清洗領域中經常使用的一種完整性約束規則,可以簡潔有效地表達屬性之間的關聯關系。為了討論方便,本文也采用函數依賴作為完整性約束規則。值得一提的是,本文方法可以通過一些擴展應用于其他類型的完整性約束規則。下面,首先介紹本文用到的一個真實數據集。表1展示了部分訂單信息表(ZIP表示郵政編碼,CT表示城市,STR表示街道,AC表示區編碼),其中標紅的數據表示錯誤,括號中的是其真實值。
定義1 函數依賴。給定一個關系模式R,X和A是R上屬性集,I是R上的實例。R中FD:X→A,表示X中的屬性取值能夠唯一地確定A中的屬性取值。更正式地說,令ti[A]表示ti元組在A屬性中的取值,FD:X→A對于所有元組對ti,tj∈I成立的充要條件如下:如果對所有B∈X,ti[B]=tj[B],則ti[A]=tj[A]。稱X為FD的左部屬性(left hand side,LHS),A為右部屬性(right hand side,RHS)。
定義2 屬性字典。給定關系實例I及FD集合Σ,Ic是I上的干凈數據,若存在Σ中任意FD:X→A,那該FD對應的屬性字典為Ic上X屬性和A屬性的所有取值集合。
例1 假設表1上的FD為ZIP→CT(即郵政編碼能夠唯一確定城市名稱)。對應的屬性字典為{(6037,Berlin),(2135,Brighton),(2137,Britain)}。
定義3 不一致元組。給定關系實例I及FD集合Σ,對于I中任意元組ti,若存在Σ中任意FD:X→A以及元組tj,j≠i,使得ti[X]=tj[X],但ti[A]=tj[A],則ti是不一致元組;反之,ti是一致元組。
例2 假設表1上的FD為ZIP→CT。對于t1元組,由于存在t3元組使得t1[ZIP]=t3[ZIP],但t1[CT]≠t3[CT],所以t1是不一致元組。
定義4 不一致數據集。給定數據集實例D及FD集合Σ,若I中所有元組都是一致元組,則D是一致的,記作D|=Σ;否則,D不一致,記作D|≠Σ。
例3 表1中元組t1、t2和元組t3是不一致的,可以通過修改t1、t2或者修改t3解決不一致問題,形成一致數據集。由此看出,表中存在指數多個一致數據集,即,經過錯誤檢測后,會得到多種修復方案,為了兼顧數據修復的質量與數量,通過統計推理的方法得到最優的修復方案。
2.2 問題定義
給定關系實例I及一組FD集合Σ,Iu是I的一個更新集合,對于Iu中的元組t的最大概率修復方案J為
J=argmax{∏t∈Iup(tui):tui∈Ut,Σ}(1)
其中:Ut,Σ表示t的所有一致性修復方案集合;tui為更新后的元組t,概率為p(ti),p(ti)∈[0,1]。
3 數據修復框架BayesOUR
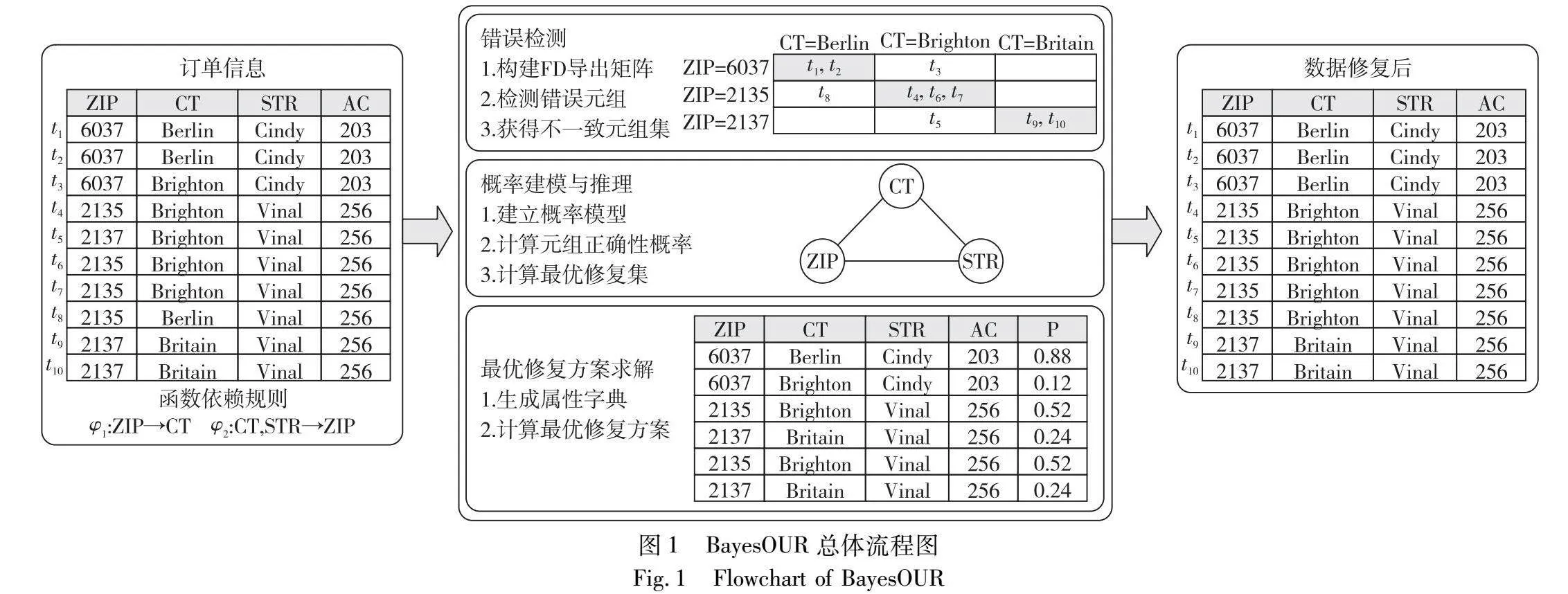
基于統計推理的不一致數據清洗方法BayesOUR的總體流程如圖1所示,輸入是關系實例I以及FD集合Σ,輸出是修復后的數據元組集合,BayesOUR框架主要包括三個階段:錯誤檢測、概率建模以及最優修復方案求解。錯誤檢測階段利用FD導出矩陣進行錯誤檢測,將數據分成錯誤元組和正確元組;概率計算階段對修復方案正確性概率進行建模并給出一種高效的概率推理方法;修復階段計算所有一致性修復方案,并從中選擇概率最大的作為最終的修復方案。
3.1 錯誤檢測
本節介紹錯誤檢測階段的具體過程,并且給出FD導出矩陣的定義以及檢測流程。
定義5 FD導出矩陣。給定實例I及FD:X→A,若I中元組在X屬性集合上有m種可能取值x1,x2,…,xm,在A屬性上有n種可能的取值a1,a2,…,an,將I中元組按X與A的取值劃分到m×n的導出矩陣Mφ中。矩陣的行表示按X劃分的分組,第i行代表X=xi分組,每個分組按照A屬性值劃分為不同單元格,位于第j列的格子稱為A=aj單元格,Mφ反映了I中元組在X屬性和A屬性上的取值分布情況。
例4 假設表1中數據按照FD:ZIP→CT,按照ZIP和CT取值劃分得到FD導出矩陣Mφ,結果如圖2所示。根據FD語義可知,ZIP值可以確定唯一的CT值,因此FD導出矩陣的每個分組中應有且僅有一個單元格非空。
錯誤檢測階段遵循少數服從多數的原則,將每個分組中規模最大的單元格中的元組標記為正確元組,其余單元格內的元組標記為錯誤元組。例如,圖2中對于ZIP=6037分組,CT=Brighton單元格中的元組數量大于其他分組中的數量,因此將該單元格內的元組t1和t2標記為正確,t3標記為錯誤。
算法1 FD導出矩陣錯誤檢測算法
輸入:實例I以及函數依賴集合Σ。
輸出:不一致數據修復元組集合U。
1 for i←1 to|Σ|do
2 根據給定函數依賴Σ以及數據構建FD導出矩陣Mφ
3 計算每個分組|X=xi|內所有單元格的大小
4 for X=xi∈Mφi do
5 if |X=xi|分組的任一單元格內元組數量最大
6 將該單元格內的元組標記為正確
7 else
8 將該單元格內的元組標記為錯誤
9 將標記錯誤的元組放入更新數據修復集U
FD導出矩陣的錯誤檢測算法如算法1所示。算法的輸入是關系實例I和FD集合Σ,輸出是不一致數據修復集合U。算法首先對Σ中的每條函數依賴φi構建FD導出矩陣Mφ,并計算每個分組內單元格的大小,然后檢測Mφ中的分組,并將其中錯誤元組進行標記(行1~3);其次,遍歷FD導出矩陣Mφi,若分組內某個單元格內元組數量最大,確定該單元格內元組是正確的,將不在正確單元格內的元組標記為錯誤(行4~8);最后,將標記的元組加入U中(行9)。
定理1 FD導出矩陣錯誤檢測算法的時間復雜度為O(|Σ|N)。
證明 算法1遍歷函數依賴規則共進行|Σ|次循環,每次循環遍歷FD導出矩陣中的元組并標記錯誤,實例I中共有N個元組,因此,總時間開銷為O(|Σ|N)。
3.2 概率建模與推理
本節給出修復方案正確性概率模型,并給出一種基于馬爾可夫毯的概率推理方法,可以有效提高推理效率。
對于錯誤元組t∈U和FD :X→A,錯誤可能出現在FD的左部屬性X或者右部屬性A,在沒有進一步分析的情況下,無法確定錯誤發生的具體位置。因此,將X中的屬性和A中的屬性都添加到查詢集合Q中,該查詢集合表示可能發生錯誤的噪聲屬性,稱其他屬性E=A-Q為證據屬性,它代表干凈的屬性(本文僅考慮不一致性錯誤)。因此,錯誤元組t可以分為兩部分:噪聲部分t[Q]和干凈部分t[E]。本文目標是使用干凈的屬性值來預測修改后錯誤元組的噪聲屬性的概率。
設t[E]=t[E1,E2,…,EL]且t[Q]=t[Q1,Q2,…,QL],SE=DOM(E1)×DOM(E2)×…×DOM(EL)表示證據屬性的空間,SQ=DOM(Q1)×DOM(Q2)×…×DOM(QK)表示t的查詢屬性的空間。假設根據SQ×SE上的概率分布P(Q,E)隨機生成元組。本文將t修改后的元組tui正確概率建模為給定證據屬性值的查詢屬性值的條件概率,即P(Q=tui[Q]|E=tui[E])(簡稱P(tui[Q]|tui[E]))。根據貝葉斯理論,得到
p(tui)=P(tui[Q]|tui[E])=P(tui[Q],tui[E])P(tui[E])(2)
例5 以錯誤元組t3為例。由于t3違反了FD:ZIP→CT,在其查詢集合中添加噪聲屬性ZIP和CT,即Q={ZIP,CT},而其他屬性添加到證據屬性中,即E={AC,STR}。在給定E的情況下,依據屬性字典元組t3的一致性修復方案共有兩種,兩種修復方案的正確概率分別為p(tu13)=P(ZIP=6037,CT=Berlin|STR=Cindy,AC=203)和p(tu23)=P(ZIP=6037,CT=Brighton|STR=Cindy,AC=203)。
為了推斷正確的概率,本文使用了一個廣泛的概率圖模型——貝葉斯網絡,它提供了一種簡潔地描述屬性的概率分布的方法(圖3)。根據貝葉斯網絡中的局部馬爾可夫性質,網絡中所有變量的聯合分布都可以因式分解為以其父變量為條件的單個密度函數的乘積。給定A=Q∪E上的貝葉斯網絡,式(2)中的P(tui[Q],tui[E])可以用以下方程式來近似。
P(tui[Q],tui[E])=∏Ki=1P(tui[Qi]|parent(Qi))∏Lj=1P(t[Ei]|parent(Ei))(3)
其中:父節點parent(Qi)和parent(Ei)分別表示Qi和Ej的父節點集。由于所有屬性的值都是已知的,所以P(tui[Qi]|parent(Qi))和P(tui[Ej]|parent(Ej))是貝葉斯網絡中的條件概率表(CPT)中的常量。
式(2)中的P(tui[E])是證據屬性的邊際分布,可以通過邊際化查詢屬性上的聯合分布來計算,如式(4)所示。類似于先前的分析,對于Q={Q1,Q2,…,Qk}中的每個Q,可以根據CPT有效地確定P(q,tui[E])。
P(tui[E])=∑q∈SQP(q,tui[E])(4)
事實上,Qi的分布取決于其馬爾可夫毯子中屬性的聯合分布。因此,本文提出在馬爾可夫毯子的基礎上對Qi進行剪枝。具體地說,設MB(Q)表示Q的馬爾可夫毯,且MB(Q)=MB(Q1)∩MB(Q2)∩…∩MB(QK)是所有查詢變量的馬爾可夫毯的交集。然后使用MB(Q)中的證據屬性來剪枝Q,即只考慮與E∩MB(Q)的值在數據集中至少出現一次的查詢屬性值。貝葉斯網絡結構以及條件概率表如圖3所示。
例6 以元組t3為例,當t3修復為tu13時,其正確性概率計算過程如下:P(tu13[Q],tu13[E])=P(ZIP=6037|CT=Berlin)·P(CT=Berlin|AC=203)·P(STR=Cindy|CT=Berlin,ZIP=6037)·P(AC=203)=0.5×0.67×1×0.33=0.111,對應的MB(Q)={STR}。原始數據中STR=Cindy,則ZIP和CT的組合可以是{6037,Berlin}或者{6037,Brighton}。因此,P(tu13[E])=P(ZIP=6037,CT=Berlin,STR=Cindy,AC=203)+P(ZIP=6037,CT=Brighton,STR=Cindy,AC=203)=0.1105+0.0154=0.1259,則p(tu13)=P(tu13[Q],tu13[E])/P(tu13[E])=0.88。
3.3 最優修復方案求解
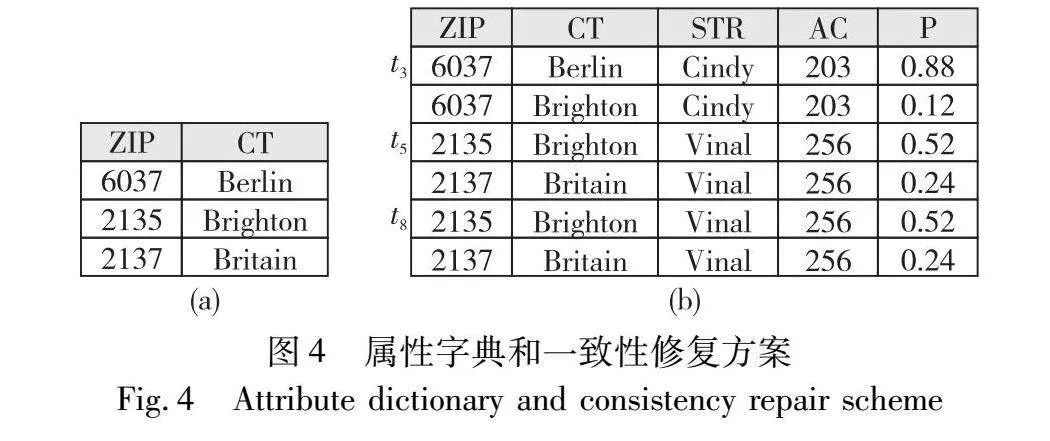
通過概率建模和推理檢測出錯誤元組,根據FD規則為錯誤元組建立屬性字典,其中包含了錯誤屬性在e9DVJSLY/gDjqjrqWbJVuGNVt7QSjogsbgz2knQ+q84=干凈數據(標記為正確的元組)中的所有取值情況。給定證據屬性下,將屬性字典中的屬性取值賦給錯誤元組對應的屬性,從而得到錯誤元組所有可能的一致性修復方案。針對所有一致性修復方案,利用式(2)計算每種一致性修復方案的正確性概率,并選擇其中概率最高的修復方案作為錯誤元組的最終修復方案。
例7 依據屬性字典并計算一致性修復方案的正確性概率如圖4所示。在給定E={STR,AC}時,t3僅有一種修復方案,選擇概率為0.88的一致性修復方案。同理,t5和t8選擇概率為0.52的一致性修復方案。通過對比表1中的真實值可以發現,BayesOUR的修復結果都是正確的。
4 實驗
在本章中,本文在不同的數據集上將BayesOUR和最先進的方法HoloClean進行對比,此外,還對不同的錯誤率以及錯誤類型進行分析。
4.1 實驗設置
BayesOUR以及對比方法HoloClean均采用Python實現,實驗運行環境配置為IntelCoreTMi7-7700HQ CPU @ 2.80 GHz處理器,8 GB內存,運行Windows 10操作系統。
本文在三個真實世界的數據集和一個生成的數據集上進行了實驗,這些數據集大多用于測試數據清理工作。表2中給出了數據集、大小、錯誤率以及錯誤類型。
Flights是一個真實世界的數據集,該數據集包含網絡上不同數據源報告的航班起飛和到達時間的信息。本文使用四個函數依賴來確保每個航班都有唯一的預計和實際的出發和到達時間。
Hospital是一個真實世界的數據集,該數據集是多篇數據清理論文中使用的基準數據集,其擁有高達十五個函數依賴并且具有多屬性列決定一個屬性列,通過Hospital數據集來確定BayesOUR具有處理多數量以及多屬性的函數依賴的數據集性能。
Rayyan是一個真實世界的數據集,該數據是關于文章的相關信息,里面數據的重復率極低。
Tax是一個合成數據集,該數據集來自于BART存儲庫的綜合數據集,獲取其中的一部分用于測試BayesOUR對合成數據集的清理性能。
分別給這些數據集注入5%、10%、15%、20%、25%和30%的替換錯誤和拼寫錯誤,并且控制拼寫錯誤比例為20%、40%、60%、80%、100%,來檢測BayesOUR對于兩種不同錯誤造成數據不一致的修復性能。
1)對比方法 本文與先進的數據修復方法HoloClean以及通用數據清理平臺NADEEF進行數據修復的實驗對比,并評估BayesOUR的性能。
HoloClean是最先進的基于機器學習的數據清理系統,具有完整性約束、外部數據和統計分析。它將現有的依賴于完整性約束或外部數據的定性數據修復方法與利用輸入數據的統計屬性的定量數據修復方法統一結合起來。
NADEEF是一個規則違規檢測系統,允許用戶指定多種類型的規則來檢測數據錯誤。
2)評估方法 本實驗采用準確率、召回率和F1-score來評估這些方法在錯誤檢測以及修復的有效性。F1-score被定義為
F1=2×Precision×RecallPrecision+Recall(5)
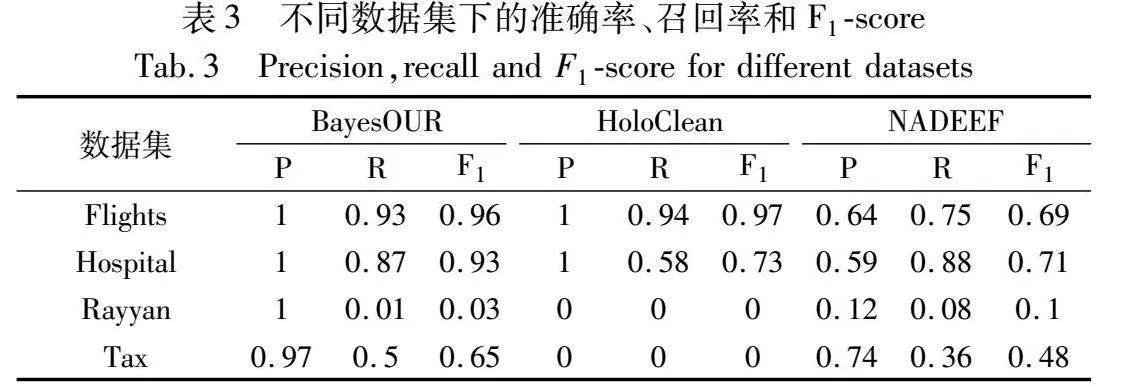
表3是四個數據集在錯誤率為0.2,type錯誤比例為0.5情況下,BayesOUR、HoloClean和NADEEF運行后的準確率、召回率和F1-score。從表中可以看出,BayesOUR在不一致數據集(替換錯誤和拼寫錯誤)上面,相比于其他方法擁有更高的準確率、召回率以及F1-score。
4.2 實驗分析
為了證明BayesOUR對不一致數據具有很好的修復結果,本文分別對Flights、Hospital、Rayyan和Tax數據集進行不同錯誤率以及錯誤類型比例的注錯,來測試錯誤率以及錯誤類型對BayesOUR性能的影響。通過大量實驗結果分析表明了BayesOUR對于不同錯誤率和錯誤類型的數據集都具有良好的修復結果,能夠準確修復大部分錯誤數據。
4.2.1 錯誤率分析
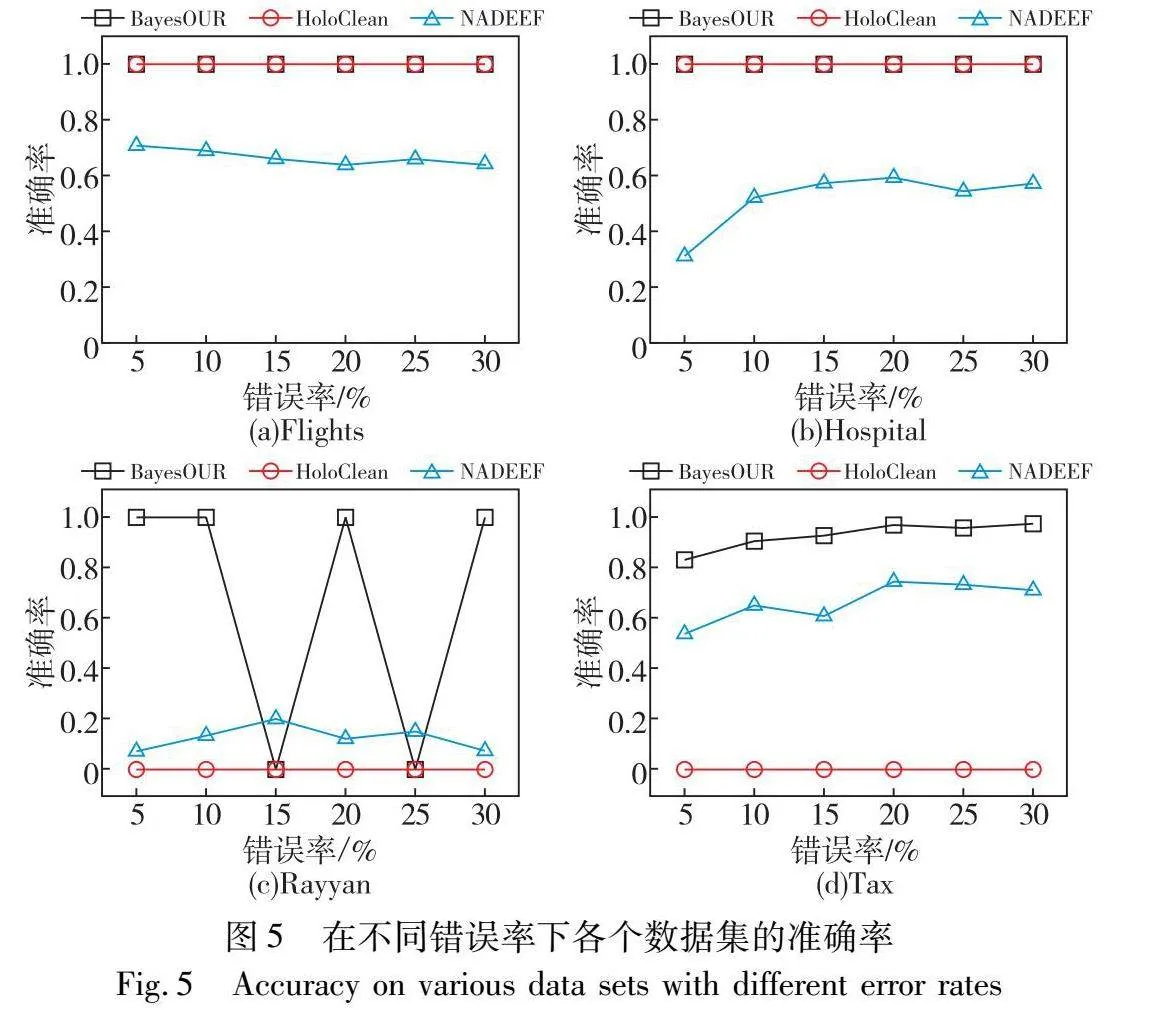
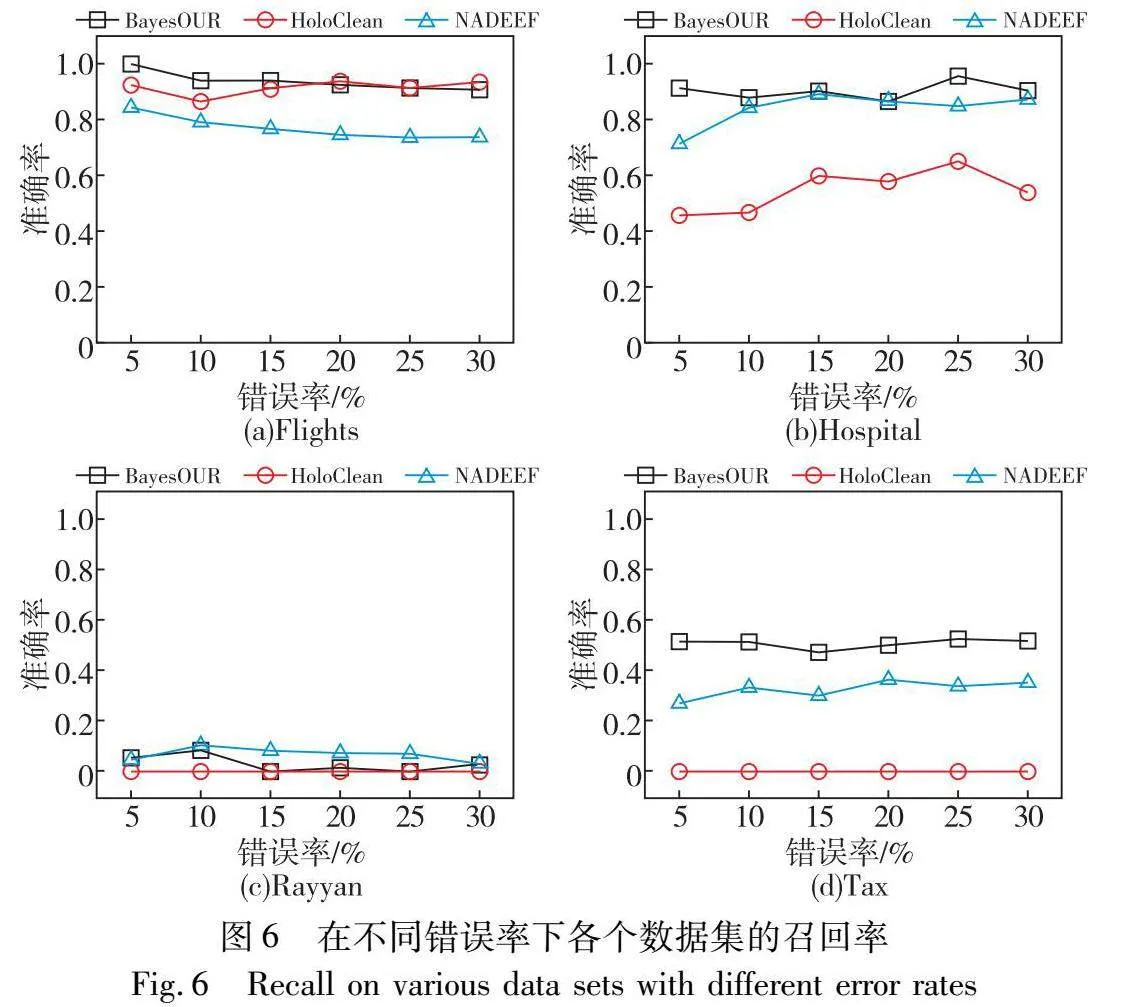
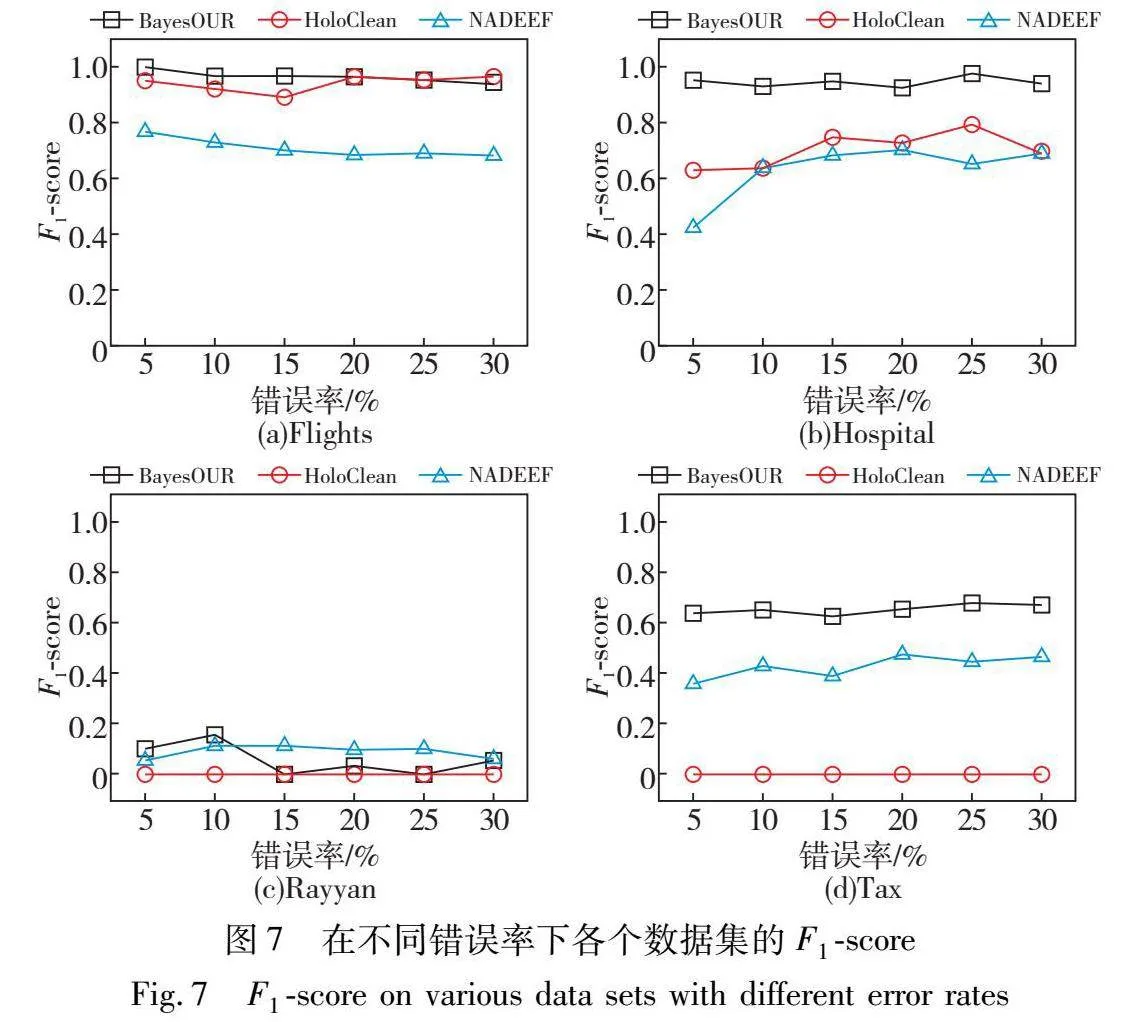
為了考察錯誤率對BayesOUR的影響,在錯誤率為5%~30%的不同數據集上運行BayesOUR、HoloClean和NADEEF,分別得到準確率、召回率以及F1-score實驗結果,如圖5~7所示。
在準確率方面,隨著錯誤率的不斷增加,BayesOUR在四種數據集上的實驗結果均優于HoloClean和NADEEF,這表明了BayesOUR的基于統計推理的算法能夠準確建立數據的正確概率并識別出錯誤數據。NADEEF在四種數據集上的準確率不高,因為它是根據FD規則去識別錯誤,并沒有結合概率。HoloClean在Rayyan數據集上表現不佳是因為數據集中數據重復率很低,在注入錯誤后仍具有數據唯一性,無法利用概率信息檢測到錯誤數據,在Tax數據集上表現不佳是因為該數據集由BART自動生成的,生成的數據中有很多數據符合不一致錯誤,使得其無法識別其中的錯誤。
在召回率方面,隨著錯誤率的不斷增加,BayesOUR在四種數據集上均有良好的數值,表明了其能夠識別出數據集中大量的錯誤數據,這得益于其將規則與概率相結合以及依據數據在貝葉斯網絡中的相關性來建立概率模型進行統計推理。HoloClean表現不佳是因為其將整個數據集劃分為噪聲和干凈的部分,使用誤差檢測方法選取的干凈值來學習統計模型以推斷每個噪聲值的概率。隨著誤碼率的增加,噪聲部分和干凈部分之間的統計差異增大,導致其無法識別大部分錯誤。NADEEF僅靠FD規則來識別數據中的錯誤是不行的,尤其是在數據錯誤較多時,會把正確數據識別成錯誤數據。
在F1-score方面,通過圖中數據分析可以知道,BayesOUR的實驗效果均優于其他兩種方法,對于Rayyan這種重復率極低的數據集,BayesOUR只能識別出少量錯誤,其他兩種方法同樣很難識別出這種數據集中的錯誤。而在人工合成數據集Tax上,BayesOUR雖然表現不如Flights和Hospital數據集上的效果好,但是F1-score也高于HoloClean和NADEEF。
4.2.2 錯誤類型分析
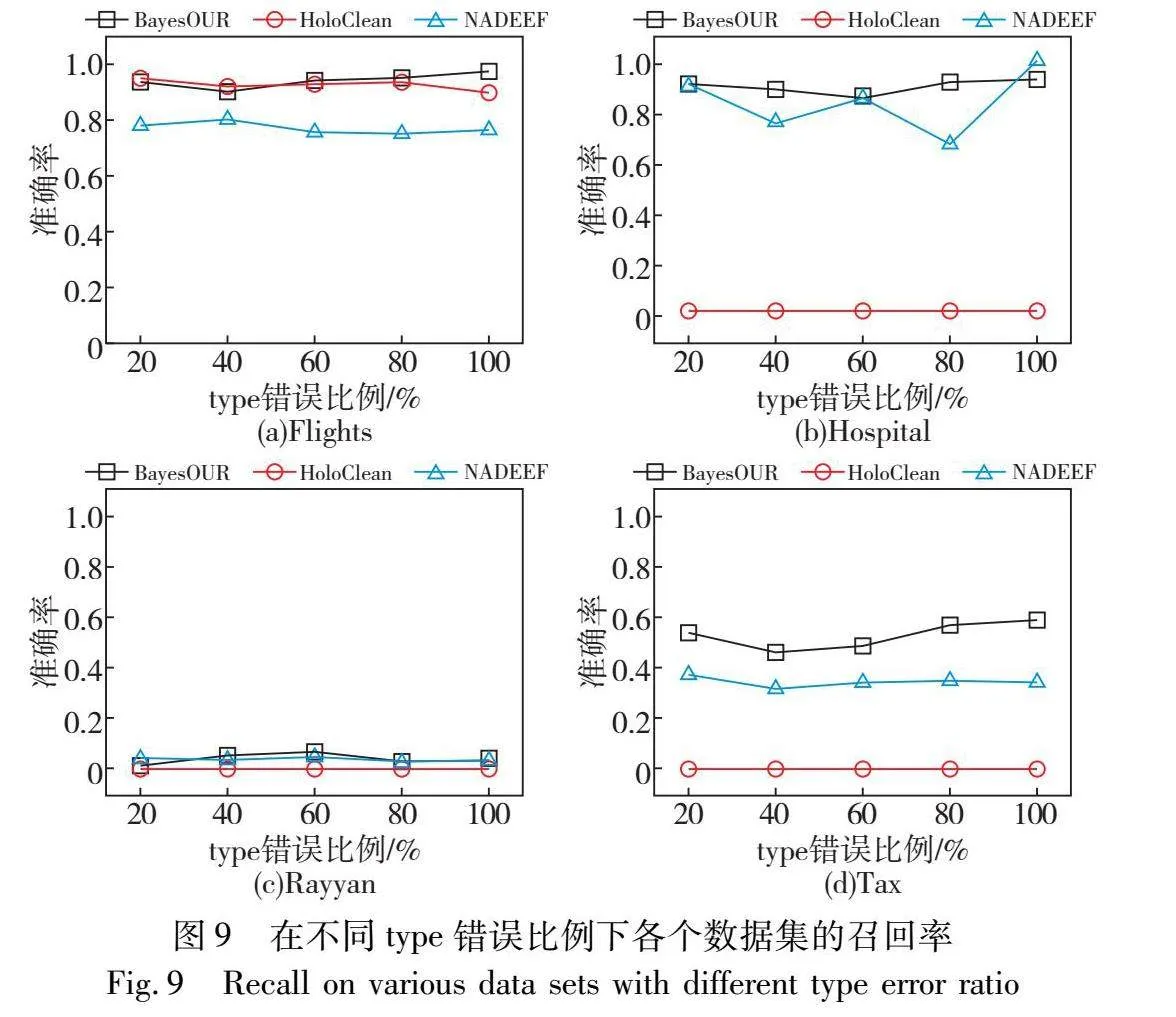
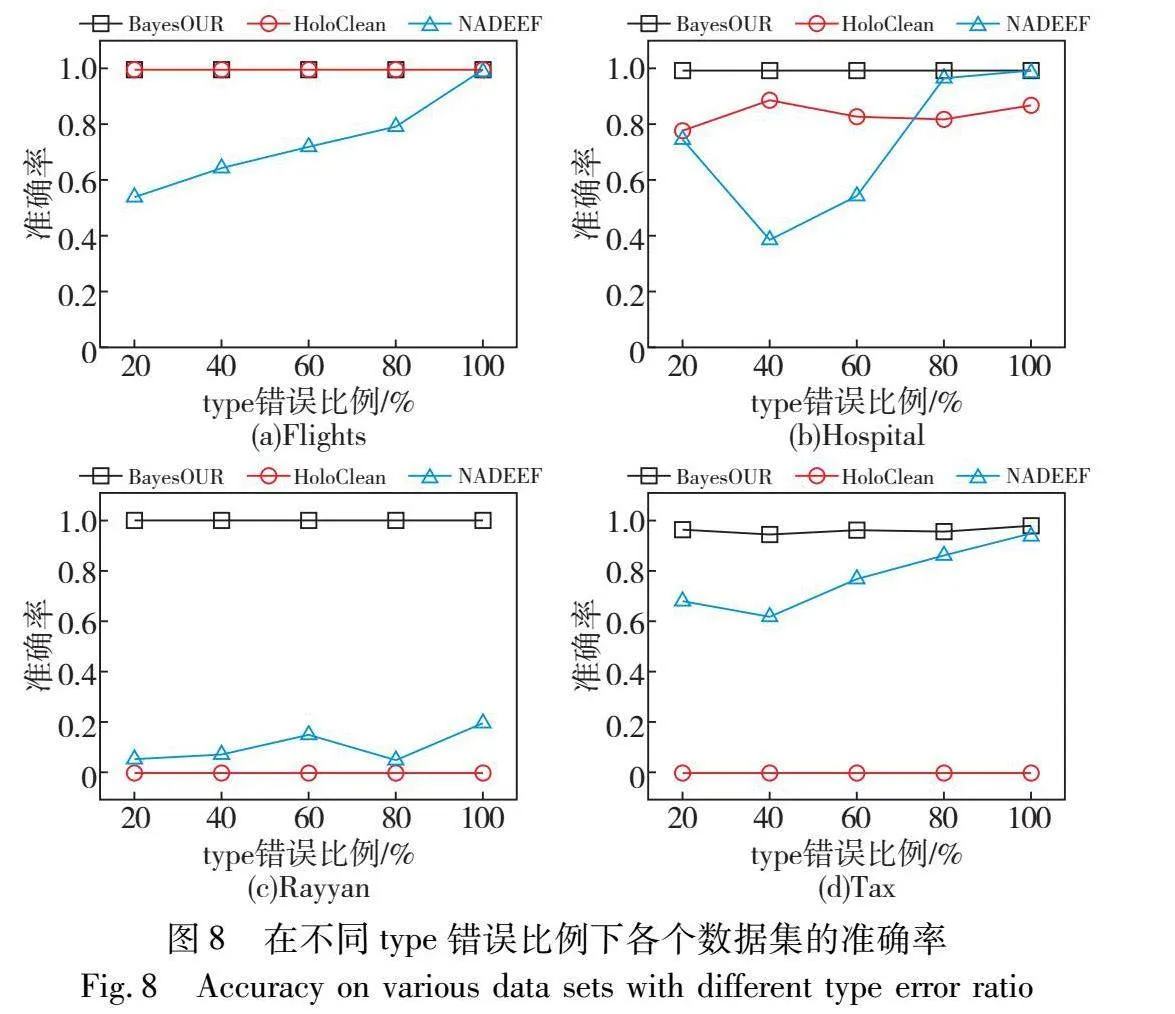
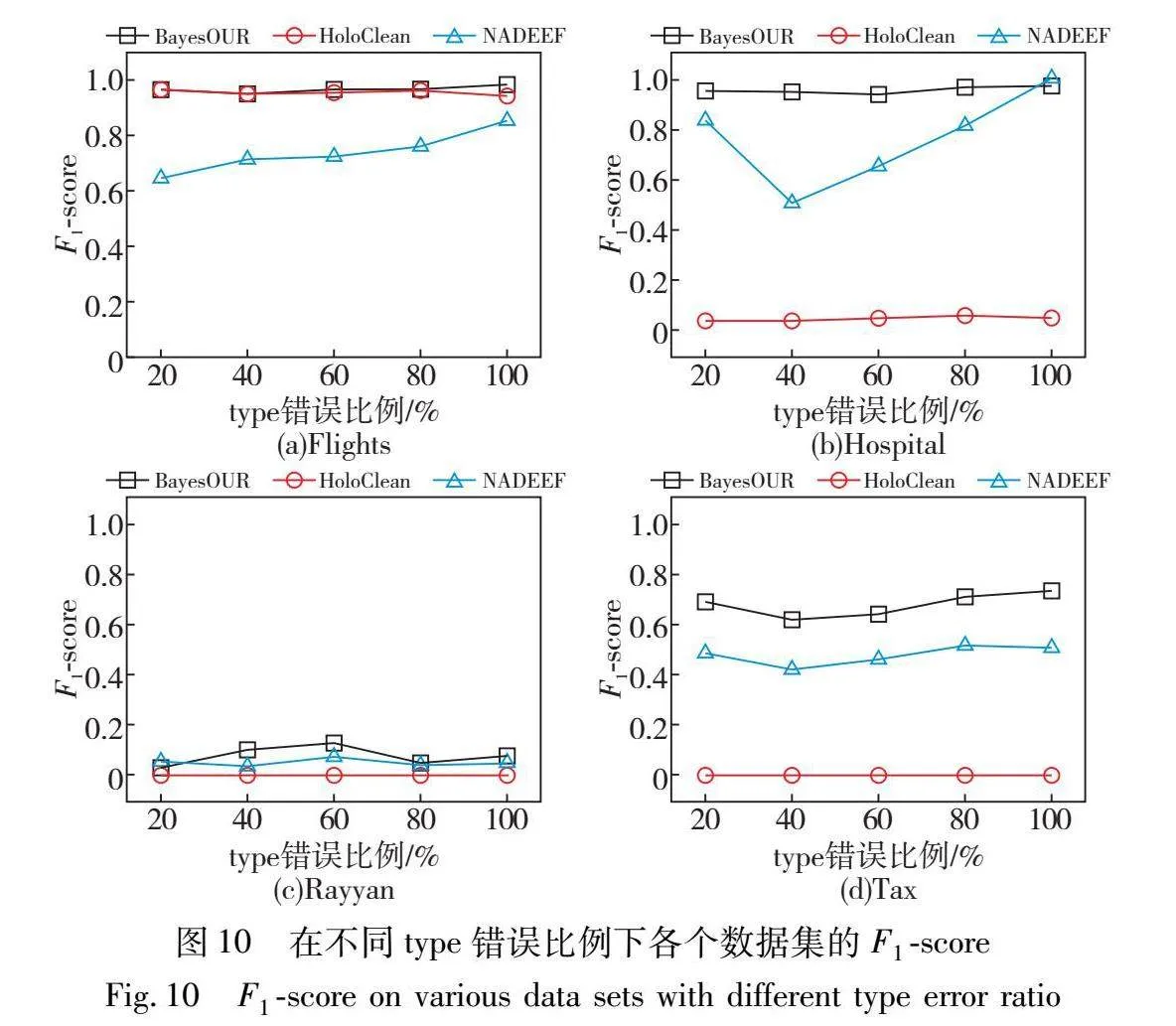
為了考察不同錯誤類型(替換錯誤和拼寫錯誤)對BayesOUR性能的影響,在type錯誤比例為20%~100%的數據集上運行BayesOUR、HoloClean和NADEEF,得到準確率、召回率以及F1-score結果,如圖8~10所示。
通過分析圖8的實驗信息可以發現,錯誤類型對BayesOUR的準確率并無影響,僅存在微乎其微的波動,而HoloClean和NADEEF的準確率卻有較大的影響。造成這種情況的原因是HoloClean和NADEEF對于替換錯誤的識別能力很弱,當替換錯誤過多時,會造成局部錯誤數據數量大于正確數據數量,進而使得其將正確數據識別為錯誤數據。
通過分析圖9的實驗信息可以發現,BayesOUR在高度的準確率情況下能夠識別出數據集中大部分錯誤,而HoloClean和NADEEF僅能夠識別出數據集中的個別錯誤或者錯誤識別正確數據,同樣證明了不同的錯誤類型對其有一定的影響。
通過分析圖10的實驗信息可以發現,不同錯誤類型的數據集下,BayesOUR都具有比HoloClean和NADEEF更高的F1-score,充分體現了數據中的不同錯誤類型并不會影響BayesOUR的數據清洗性能。
5 結束語
本文研究了不一致數據修復問題,提出了基于統計推理的不一致數據清洗方法。該方法通過FD導出矩陣進行數據錯誤檢測,并利用貝葉斯網絡進行概率推理建立概率模型,計算元組的正確性概率。最后,通過對錯誤元組數據建立屬性字典以及計算所有一致性修復方案的概率確定最終的修復方案。通過真實數據以及生成數據上的實驗結果驗證了提出方法的準確性優于現有的修復方法。然而,在重復率較低的數據上,修復性能可能會受到影響。未來的研究將致力于解決這些挑戰。
參考文獻:
[1]徐耀麗,李戰懷,陳群,等.基于可能世界模型的關系數據不一致性的修復[J].軟件學報,2016,27(7):1685-1699. (Xu Yaoli,Li Zhanhuai,Chen Qun,et al.Repairing inconsistent relational data based on possible world model[J].Journal of Software,2016,27(7):1685-1699.)
[2]Bertossi L,Kolahi S,Lakshmanan L V S.Data cleaning and query answering with matching dependencies and matching functions[C]//Proc of the 14th International Conference on Database Theory.New York:ACM Press,2011:268-279.
[3]Chu Xu,Ilyas I F,Papotti P.Holistic data cleaning:putting violations into context[C]//Proc of the 29th IEEE International Conference on Data Engineering.Piscataway,NJ:IEEE Press,2013:458-469.
[4]張安珍,司佳宇,梁天宇,等.規則與概率相結合的不一致數據子集修復方法[J].軟件學報,2024,35(9):4448-4468. (Zhang Anzhen,Si Jiayu,Liang Tianyu,et al.Subset repair method combining rules and probabilities for inconsistent data[J].Journal of Software,2024,35(9):4448-4468.
[5]Livshits E,Kimelfeld B,Roy S.Computing optimal repairs for functional dependencies[J].ACM Trans on Database Systems,2020,45(1):1-46.
[6]Sun Yu,Song Shaoxu.From minimum change to maximum density:on S-Repair under integrity constraints[C]//Proc of the 37th IEEE International Conference on Data Engineering.Piscataway,NJ:IEEE Press,2021:1943-1948.
[7]Chomicki J,Marcinkowski J.Minimal-change integrity maintenance using tuple deletions[J].Information and Computation,2005,197(1-2):90-121.
[8]Afrati F N,Kolaitis P G.Repair checking in inconsistent databases:algorithms and complexity[C]//Proc of the 12th International Confe-rence on Database Theory.New York:ACM Press,2009:31-41.
[9]Arenas M,Bertossi L,Chomicki J,et al.Scalar aggregation in inconsistent databases[J].Theoretical Computer Science,2003,296(3):405-434.
[10]Lopatenko A,Bravo L.Efficient approximation algorithms for repairing inconsistent databases[C]//Proc of the 23rd IEEE International Conference on Data Engineering.Piscataway,NJ:IEEE Press,2007:216-225.
[11]Kolahi S,Lakshmanan L V S.On approximating optimum repairs for functional dependency violations[C]//Proc of the 12th International Conference on Database Theory.New York:ACM Press,2009:53-62.
[12]Bohannon P,Fan Wenfei,Flaster M,et al.A cost-based model and effective heuristic for repairing constraints by value modification[C]//Proc of ACM SIGMOD International Conference on Management of Data.New York:ACM Press,2005:143-154.
[13]Dallachiesa M,Ebaid A,Eldawy A,et al.NADEEF:a commodity data cleaning system[C]//Proc of ACM SIGMOD International Conference on Management of Data.New York:ACM Press,2013:541-552.
[14]Khayyat Z,Ilyas I F,Jindal A,et al.BigDansing:a system for big data cleansing[C]//Proc of ACM SIGMOD International Conference on Management of Data.New York:ACM Press,2015:1215-1230.
[15]Abedjan Z,Akcora C G,Ouzzani M,et al.Temporal rules discovery for Web data cleaning[J].Proceedings of the VLDB Endowment,2015,9(4):336-347.
[16]Geerts F,Mecca G,Papotti P,et al.The LLUNATIC data-cleaning framework[J].Proceedings of the VLDB Endowment,2013,6(9):625-636.
[17]Berti-équille L,Dasu T,Srivastava D.Discovery of complex glitch patterns:a novel approach to quantitative data cleaning[C]//Proc of the 27th IEEE International Conference on Data Engineering.Piscataway,NJ:IEEE Press,2011:733-744.
[18]Dasu T,Loh J M.Statistical distortion:consequences of data cleaning[J].Proceedings of the VLDB Endowment,2012,5(11):1674-1683.
[19]Yakout M,Berti-Equille L,Elmagarmid A K.Don’t be SCAREd:use SCalable automatic REpairing with maximal likelihood and bounded changes[C]//Proc of ACM SIGMOD International Conference on Management of Data.New York:ACM Press,2013:553-564.
[20]Krishnan S,Wang Jiannan,Wu E,et al.Active-Clean:interactive data cleaning for statistical modeling[J].Proceedings of the VLDB Endowment,2016,9(12):948-959.
[21]Mayfield C,Neville J,Prabhakar S.ERACER:a database approach for statistical inference and data cleaning[C]//Proc of ACM SIGMOD International Conference on Management of data.New York:ACM Press,2010:75-86.
[22]Prokoshyna N,Szlichta J,Chiang F,et al.Combining quantitative and logical data cleaning[J].Proceedings of the VLDB Endowment,2015,9(4):300-311.
[23]Ge Congcong,Gao Yunjun,Miao Xiaoye,et al.A hybrid data cleaning framework using Markov logic networks[J].IEEE Trans on Know-ledge and Data Engineering,2022,34(5):2048-2062.
[24]Ge Congcong,Gao Yunjun,Miao Xiaoye,et al.IHCS:an integrated hybrid cleaning system[J].Proceedings of the VLDB Endowment,2019,12(12):1874-1877.
[25]Rekatsinas T,Chu Xu,Ilyas I F,et al.HoloClean:holistic data repairs with probabilistic inference[EB/OL].(2017-02-02).https://arxiv.org/abs/1702.00820.
[26]Yu Zhuoran,Chu Xu.PIClean:a probabilistic and interactive data cleaning system[C]//Proc of International Conference on Management of Data.New York:ACM Press,2019:2021-2024.
[27]Mahdavi M,Abedjan Z,Fernandez R C,et al.Raha:a configuration-free error detection system[C]//Proc of International Conference on Management of Data.New York:ACM Press,2019:865-882.
