基于神經(jīng)網(wǎng)絡(luò)和注意力機(jī)制的協(xié)同過(guò)濾推薦算法的研究
2024-10-17 00:00:00王寧李然王客程吳江范利利
現(xiàn)代電子技術(shù) 2024年20期




摘" 要: 針對(duì)協(xié)同過(guò)濾推薦算法中用戶?物品矩陣的稀疏性,使得傳統(tǒng)協(xié)同過(guò)濾算法推薦度較差的問(wèn)題,提出一種改進(jìn)的基于神經(jīng)網(wǎng)絡(luò)和注意力機(jī)制的協(xié)同過(guò)濾推薦算法B?SDAECF,旨在解決傳統(tǒng)推薦系統(tǒng)中數(shù)據(jù)稀疏的問(wèn)題。結(jié)合Transformer模型的變式Bert模型和堆疊式降噪自動(dòng)編碼器(SDAE),利用Bert模型從用戶評(píng)論中提取高質(zhì)量的特征表示,以獲得向量矩陣;并將向量矩陣作為SDAE的初始權(quán)重,從而使SDAE模型能夠更快速地運(yùn)算,進(jìn)而填充原有的用戶?項(xiàng)目評(píng)分矩陣。實(shí)驗(yàn)結(jié)果顯示,相比傳統(tǒng)方法,所提方法在推薦系統(tǒng)的準(zhǔn)確性和魯棒性上有顯著提升,推薦效果更優(yōu)秀。
關(guān)鍵詞: 神經(jīng)網(wǎng)絡(luò); 注意力機(jī)制; 協(xié)同過(guò)濾; 推薦系統(tǒng); Bert模型; SDAE
中圖分類號(hào): TN911?34; TP391.1" " " " " " " " " "文獻(xiàn)標(biāo)識(shí)碼: A" " " " " " " " " " 文章編號(hào): 1004?373X(2024)20?0095?06
Research on collaborative filtering recommendation algorithm based on neural
network and attention mechanism
WANG Ning, LI Ran, WANG Kecheng, WU Jiang, FAN Lili
(School of Information Engineering, Dalian Ocean University, Dalian 116023, China)
Abstract: In order to solve the problem that the sparseness of the user?item matrix in the collaborative filtering recommendation algorithm can cause poor recommendation degree of the traditional collaborative filtering algorithm, an improved collaborative filtering recommendation algorithm B?SDAECF based on neural network and attention is proposed to solve the problem of data sparsity in the traditional recommendation system. By combining the transformer Bert model of the Transformer model and the stacked denoise auto?encoder (SDAE), the Bert model is used to extract high?quality feature representations from user reviews to obtain the vector matrix. The vector matrix is used as the initial weight of the SDAE, so that the SDAE model can be operated more quickly, and then the original user?item scoring matrix is filled. The experimental results show that, in comparison with the traditional method, the proposed method can significantly improve the accuracy and robustness of the recommendation system, and has better recommendation performance.
Keywords: neural network; attention mechanism; collaborative filtering; recommendation system; Bert model; SDAE
0" 引" 言
當(dāng)前人們最熟悉的電影領(lǐng)域、音樂(lè)領(lǐng)域、電商領(lǐng)域、社交領(lǐng)域和圖書(shū)領(lǐng)域都有各自成熟的推薦算法[1]。自20世紀(jì)末以來(lái),推薦系統(tǒng)逐漸吸引了研究者的目光,并隨著互聯(lián)網(wǎng)技術(shù)的蓬勃發(fā)展,成為了當(dāng)下熱門的研究方向。在推薦系統(tǒng)中,必不可少的就是推薦算法,而協(xié)同過(guò)濾算法[2]在其中留下濃厚的一筆。它通過(guò)計(jì)算用戶對(duì)項(xiàng)目的評(píng)分來(lái)計(jì)算用戶間的相似度,并以此推斷用戶的喜好,進(jìn)行推薦。
在實(shí)際場(chǎng)景中,常常采用余弦相似度等方法作為用戶或項(xiàng)目之間的相似性標(biāo)準(zhǔn)。亞馬遜發(fā)表的關(guān)于其推薦算法的論文是協(xié)同過(guò)濾在推薦領(lǐng)域取得突破的關(guān)鍵事件[3]。該論文提出了兩種核心算法:基于用戶的協(xié)同過(guò)濾(UserCF)和基于物品的協(xié)同過(guò)濾(ItemCF)。這兩種算法的本質(zhì)都是計(jì)算相似度來(lái)進(jìn)行推薦。
UserCF通過(guò)尋找與當(dāng)前用戶興趣相似的用戶,然后推薦這些相似用戶購(gòu)買或評(píng)價(jià)過(guò)的物品。這種方法具有很強(qiáng)的社交特性,因?yàn)樗谟脩糸g的相似行為來(lái)推薦,然而,也受限于用戶?物品交互數(shù)據(jù)的稀疏性,即很多用戶可能只對(duì)少數(shù)物品有過(guò)交互,這會(huì)影響推薦的準(zhǔn)確性。ItemCF則側(cè)重于計(jì)算物品之間的相似度。這種方法更適用于用戶對(duì)物品評(píng)價(jià)多的場(chǎng)景,然而,同樣存在交互數(shù)據(jù)稀少的問(wèn)題。因此,傳統(tǒng)的協(xié)同過(guò)濾算法往往難以為用戶提供準(zhǔn)確的推薦。
為了解決數(shù)據(jù)稀疏性所帶來(lái)的問(wèn)題,后續(xù)的研究者提出了許多有效的方法,如引入更多的輔助信息、使用更復(fù)雜的相似度計(jì)算方法、結(jié)合其他類型的推薦算法等。這些進(jìn)步共同加快了推薦系統(tǒng)技術(shù)的發(fā)展,使得協(xié)同過(guò)濾算法在推薦領(lǐng)域應(yīng)用日益廣泛。
矩陣分解[4?5]是一種改善數(shù)據(jù)稀疏問(wèn)題常用的技術(shù),它將用戶和項(xiàng)目的評(píng)分矩陣拆分成兩個(gè)低秩矩陣并進(jìn)行內(nèi)積操作,然后使用這兩個(gè)低秩矩陣對(duì)用戶和項(xiàng)目的交互做預(yù)測(cè)[6]。然而,矩陣分解模型存在局限性,即難以處理非線性關(guān)系。為了解決這些問(wèn)題,人們把目光轉(zhuǎn)移到了神經(jīng)網(wǎng)絡(luò)上,其中最具代表性的是神經(jīng)協(xié)同過(guò)濾(Neural Collaborative Filtering, NCF)框架[7]。它代替?zhèn)鹘y(tǒng)的推薦算法來(lái)學(xué)習(xí)用戶與商品之間的聯(lián)系,以此解決非線性關(guān)系。此外,NCF還具有很好的通用性,可以適用于不同類型的數(shù)據(jù)和推薦場(chǎng)景。盡管NCF在推薦領(lǐng)域取得了一定的成功,但它仍然基于用戶行為數(shù)據(jù),沒(méi)有充分考慮用戶、物品和上下文信息,這意味著在推薦過(guò)程中,這些因素可能沒(méi)有得到充分利用,從而影響推薦的質(zhì)量和準(zhǔn)確性。上述方法雖然有著各自的優(yōu)勢(shì),但是均存在數(shù)據(jù)稀疏的問(wèn)題。
近年來(lái),注意力機(jī)制在自然語(yǔ)言處理領(lǐng)域的應(yīng)用確實(shí)取得了顯著的成果,其能夠通過(guò)賦予不同部分不同的權(quán)重,從而有效地聚焦于關(guān)鍵信息,其中較優(yōu)秀的則是Transformer模型[8]。用來(lái)獲取序列中不同位置關(guān)系的重中之重的是自注意力機(jī)制,這種機(jī)制使得Transformer具有上下文感知的能力,在處理自然語(yǔ)言任務(wù)時(shí),能夠更好地理解和處理上下文信息,從而提高模型的準(zhǔn)確性和魯棒性。
在推薦系統(tǒng)中,結(jié)合注意力機(jī)制與神經(jīng)網(wǎng)絡(luò)已然成為提高推薦效率的有效方法。卷積神經(jīng)網(wǎng)絡(luò)[9](Convolutional Neural Networks, CNN)是一種包含卷積運(yùn)算的前饋神經(jīng)網(wǎng)絡(luò),文獻(xiàn)[10]利用CNN提取用戶和項(xiàng)目的輔助信息特征。長(zhǎng)短期記憶[11](Long Short Term Memory, LSTM)網(wǎng)絡(luò)則是一種特殊的循環(huán)神經(jīng)網(wǎng)絡(luò),它可以控制信息的保留和遺忘,用來(lái)處理與時(shí)間相關(guān)的數(shù)據(jù)。文獻(xiàn)[12]使用注意力機(jī)制有效地捕捉用戶短期興趣,它充分強(qiáng)調(diào)用戶興趣按照時(shí)間的變化,并嘗試?yán)眠@種變化來(lái)對(duì)用戶進(jìn)行推薦。然而,這種方法忽略了用戶長(zhǎng)期興趣的影響,因此在某些場(chǎng)景下可能不夠準(zhǔn)確。但該方法利用了注意力機(jī)制,為解決數(shù)據(jù)稀疏問(wèn)題奠定了基礎(chǔ)。
文獻(xiàn)[13]結(jié)合附加堆疊式降噪自編碼器和基于CNN的矩陣分解來(lái)進(jìn)行特征提取。這種方法在某些情況下表現(xiàn)良好,在一定程度上緩解了數(shù)據(jù)稀疏的問(wèn)題,但卷積層未能充分考慮文本的上下文關(guān)系和順序性,仍存在缺陷。
文獻(xiàn)[14]提出的降噪自編碼器在特征提取方面取得了新的進(jìn)展,但是其沒(méi)有考慮隨機(jī)的初始權(quán)重會(huì)使得模型產(chǎn)生運(yùn)算過(guò)擬合等問(wèn)題,大大降低了推薦的準(zhǔn)確度,沒(méi)有很好地解決數(shù)據(jù)稀疏問(wèn)題。
針對(duì)上述問(wèn)題,本文提出了一種以Transformer模型為基礎(chǔ)的Bert模型[15]與堆疊式降噪自編碼器[16](Stacked Denoise Auto?Encoder, SDAE)相結(jié)合的協(xié)同過(guò)濾推薦算法,來(lái)對(duì)稀疏矩陣進(jìn)行處理,將這種方法定義為B?SDAECF。算法使用Transformer模型對(duì)數(shù)據(jù)集中用戶的文本評(píng)論進(jìn)行分析,從而對(duì)SDAE模型的初始權(quán)重進(jìn)行規(guī)定,使得SDAE模型在訓(xùn)練初期就盡可能地捕捉到數(shù)據(jù)的特征,提高模型的訓(xùn)練效率和準(zhǔn)確性。
1" 相關(guān)理論
1.1" Bert模型
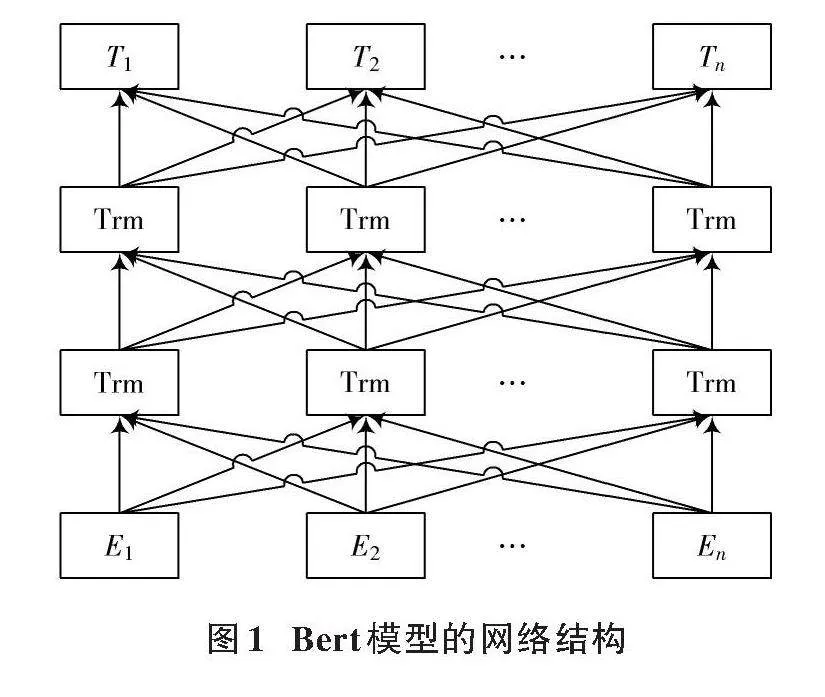
Bert模型通過(guò)雙向Transformer來(lái)構(gòu)建神經(jīng)網(wǎng)絡(luò),其最重要的優(yōu)勢(shì)就是可以得到上下文信息的深層雙向語(yǔ)言特征。Bert模型的網(wǎng)絡(luò)架構(gòu)如圖1所示,這種結(jié)構(gòu)可以在預(yù)測(cè)詞匯的同時(shí)考慮其左右兩側(cè)的詞,從而更全面地捕捉上下文之間的依賴關(guān)系。相比之下,標(biāo)準(zhǔn)的Transformer模型在訓(xùn)練時(shí)通常是單向進(jìn)行處理,這限制了它在理解全局上下文方面的能力。Bert模型的特性取得了更好的性能優(yōu)化,甚至反超了以往的模型,因此本文選用Bert模型來(lái)挖掘文本中的深層次信息。
1.2" 堆疊式降噪自編碼器
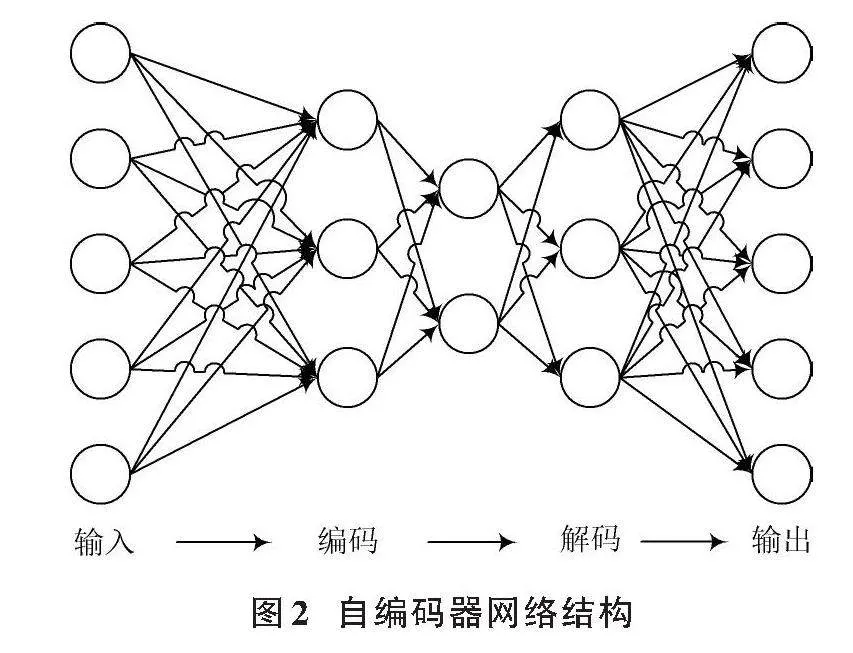
自編碼器的網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。SDAE是降噪自編碼器[17](Denoising Auto?Encoder, DAE)的一種變式,通過(guò)疊加多個(gè)自編碼器來(lái)逐步提取輸入數(shù)據(jù)的特征,隨著層數(shù)的增加,數(shù)據(jù)的特征逐步從前一層中提取出來(lái),過(guò)濾不需要的信息,從而提高數(shù)據(jù)的質(zhì)量和可用性。
在本文中,為了捕捉輸入數(shù)據(jù)的復(fù)雜特征和增強(qiáng)模型的魯棒性,選擇堆疊式降噪自編碼器作為建模的基礎(chǔ)。該編碼器通過(guò)反向傳播算法,可以對(duì)模型的參數(shù)進(jìn)行調(diào)整和優(yōu)化,從而實(shí)現(xiàn)更好的特征提取和重構(gòu)性能。
2" 基于B?SDAECF算法
本文提出了一種改進(jìn)的推薦算法B?SDAECF,圖3展示了該模型的整體架構(gòu)。首先,采用先進(jìn)的Bert模型,從豐富的用戶評(píng)論數(shù)據(jù)中深度挖掘每位用戶對(duì)不同項(xiàng)目的獨(dú)特偏好,這些數(shù)據(jù)被精心轉(zhuǎn)化為項(xiàng)目向量矩陣,為后續(xù)分析提供堅(jiān)實(shí)基礎(chǔ)。這些矩陣不僅捕捉了用戶的個(gè)性化需求,還被巧妙地用作SDAE輸入層的初始權(quán)重。通過(guò)SDAE模型能夠?qū)W習(xí)到更加穩(wěn)健和抗干擾的特征表示,進(jìn)而實(shí)現(xiàn)對(duì)稀疏矩陣填充缺失值,計(jì)算用戶間的相似度,為用戶進(jìn)行推薦。這種改進(jìn)的推薦算法極大地豐富了用戶的個(gè)性化體驗(yàn)。
2.1" 編碼處理
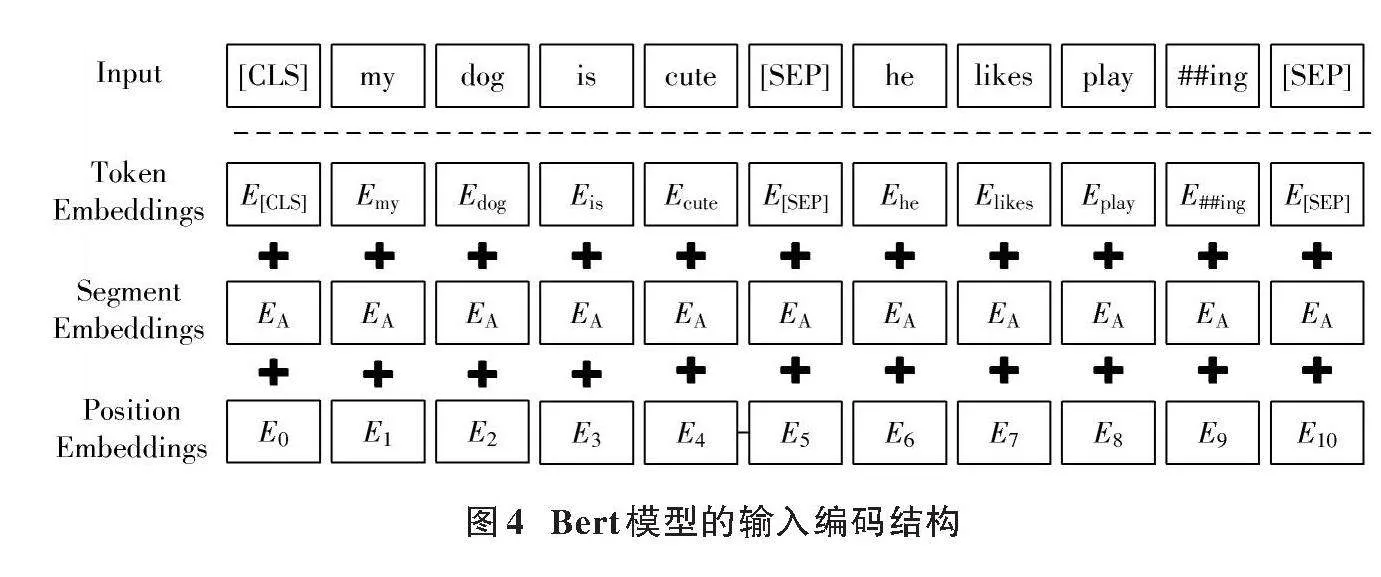
為了將文本數(shù)據(jù)轉(zhuǎn)換為自身所需要的格式,Bert模型使用WordPiece算法進(jìn)行文本分割。首先,將整個(gè)文本字符串分割成詞匯單元(tokens),這些tokens包括單詞、子單詞或者字符,目的是減少未知詞(OOV)的數(shù)量,并提高模型的通用性。這些標(biāo)記不僅包括原始文本中的詞匯,還包括特殊標(biāo)記,如通常在序列的開(kāi)始添加[CLS]標(biāo)記,在序列的結(jié)束添加[SEP]標(biāo)記。[CLS]標(biāo)記用于分類任務(wù),[SEP]標(biāo)記用于分隔兩個(gè)句子或者表示序列的結(jié)束。接著,模型將這些標(biāo)記轉(zhuǎn)換為嵌入向量,引入三種嵌入編碼標(biāo)記的語(yǔ)義信息、段落信息和順序信息,結(jié)構(gòu)如圖4所示。
結(jié)合圖4可知,Bert的輸出形式為Token_Embedding+Segment_Embedding+Position_Embedding。
2.2" Bert生成項(xiàng)目向量
在本文中,改進(jìn)SDAE模型的隨機(jī)初始權(quán)重會(huì)導(dǎo)致推薦不準(zhǔn)確,沒(méi)有很好地解決數(shù)據(jù)稀疏問(wèn)題,故采用Bert模型從文本數(shù)據(jù)中提取高質(zhì)量的特征表示作為SDAE模型的初始權(quán)重。Bert模型基于Transformer的編碼器架構(gòu),利用其自注意力機(jī)制可允許模型在處理每個(gè)單詞的表示時(shí)考慮到句子中的其他單詞,其數(shù)學(xué)表達(dá)為:
[Attention(Q,K,V)=softmaxQKTdKV] (1)
式中:Q、K和V分別是查詢(Query)、鍵(Key)、值(Value)矩陣,它們是輸入矩陣與相應(yīng)權(quán)重矩陣的乘積;[dK]是鍵向量的維度。
本文通過(guò)并行使用多個(gè)自注意力機(jī)制(稱為“頭”)來(lái)捕獲不同的上下文關(guān)系。多頭注意力的輸出是所有頭計(jì)算結(jié)果的拼接,然后乘以一個(gè)權(quán)重矩陣,公式如下" [MultiHead(Q,K,V)=Concat(head1,head2,…,headn)WO] (2)
[headi=Attention(QWQi,KWKi,VWVi)] (3)
式中[WQi]、[WKi]、[WVi]和[WO]是參數(shù)矩陣。
在每個(gè)自注意力模塊之后,Bert使用一個(gè)前饋神經(jīng)網(wǎng)絡(luò)(FNN),對(duì)于每個(gè)位置都是相同的操作。經(jīng)過(guò)上述兩個(gè)模塊之后,Bert還應(yīng)用殘差連接和層歸一化來(lái)促進(jìn)深層網(wǎng)絡(luò)的訓(xùn)練,最后根據(jù)所需的維度進(jìn)行降維,得到項(xiàng)目向量。
2.3" SDAE填充評(píng)分矩陣
本文將Bert模型生成的項(xiàng)目向量矩陣作為SDAE的初步權(quán)重,選擇了一個(gè)簡(jiǎn)化的兩層SDAE網(wǎng)絡(luò)架構(gòu)。對(duì)于原始的評(píng)分矩陣,將每一行的數(shù)據(jù)x進(jìn)行噪聲處理,即通過(guò)補(bǔ)零的方式處理缺失值,得到處理后的數(shù)據(jù)[x′],這些處理后的數(shù)據(jù)作為SDAE模型的輸入。借助Bert模型生成的項(xiàng)目向量W作為SDAE的初始權(quán)重,模型能夠在保留已有評(píng)分信息的同時(shí),揭示潛在的規(guī)律并預(yù)測(cè)缺失的評(píng)分值。第一層的輸出公式為:
[nnx′=f′g′x′=σWTσWx′+y1+y2] (4)
對(duì)輸入數(shù)據(jù)x進(jìn)行降噪處理,得到降噪后的數(shù)據(jù)[x′],[x′]中的缺失值被補(bǔ)充為0。然后,通過(guò)編碼函數(shù)[g′]將[x′]轉(zhuǎn)換為編碼表示,再通過(guò)解碼函數(shù)f'(·)將編碼表示還原為重構(gòu)數(shù)據(jù)。在這個(gè)過(guò)程中,非線性sigmoid函數(shù)中的[σ·]用于引入非線性因素。同時(shí),y1和y2表示網(wǎng)絡(luò)中的偏差值,用于調(diào)整網(wǎng)絡(luò)的輸出。
針對(duì)得到的結(jié)果,計(jì)算其與原始數(shù)據(jù)[x′]之間的重構(gòu)誤差。如果超過(guò)設(shè)定的值,則會(huì)將誤差反向傳遞至網(wǎng)絡(luò)的各個(gè)層級(jí),修正模型以努力縮小重構(gòu)誤差。只有當(dāng)誤差降至預(yù)設(shè)閾值以下時(shí),第一層網(wǎng)絡(luò)才會(huì)達(dá)到全局最優(yōu)狀態(tài),此時(shí)會(huì)更新網(wǎng)絡(luò)的權(quán)重W和偏差y1。這一過(guò)程旨在通過(guò)不斷優(yōu)化網(wǎng)絡(luò)參數(shù),提升網(wǎng)絡(luò)對(duì)數(shù)據(jù)的重構(gòu)能力。本文通過(guò)逐層訓(xùn)練和優(yōu)化,最終使得整個(gè)網(wǎng)絡(luò)達(dá)到全局最優(yōu)。
誤差函數(shù)的具體形式如式(5)所示,它用于量化重構(gòu)誤差的大小,指導(dǎo)網(wǎng)絡(luò)的訓(xùn)練和優(yōu)化過(guò)程。
[L(X,X)=jNnn(X)j;-Xj2] (5)
式中:Xj表示數(shù)據(jù)集中的第j行輸入向量,代表了某一特定數(shù)據(jù)點(diǎn)的多維特征;而[nnXj]則表示對(duì)評(píng)分矩陣的第j行進(jìn)行噪聲處理后,通過(guò)模型所得出的預(yù)測(cè)結(jié)果。這一預(yù)測(cè)是基于處理過(guò)的數(shù)據(jù),并通過(guò)神經(jīng)網(wǎng)絡(luò)的復(fù)雜計(jì)算得出的,用于反映處理噪聲后的數(shù)據(jù)對(duì)最終評(píng)分預(yù)測(cè)的影響。
3" 實(shí)驗(yàn)結(jié)果和分析
3.1" 實(shí)驗(yàn)數(shù)據(jù)集
本文選取帶有輔助信息的亞馬遜數(shù)據(jù)集(Amazon Review Data)作為實(shí)驗(yàn)數(shù)據(jù)集,評(píng)分范圍為1~5分。用戶的信息涵蓋了諸如用戶ID、評(píng)分、評(píng)論文本等多種屬性。為了便于處理和分析,將這些信息轉(zhuǎn)換為二進(jìn)制格式,從而更有效地進(jìn)行數(shù)據(jù)處理和運(yùn)算。同時(shí),項(xiàng)目的輔助信息,如產(chǎn)品ID、類別信息和產(chǎn)品描述等,也被轉(zhuǎn)化為適合分析處理的特定格式。通過(guò)這種轉(zhuǎn)換能夠更加高效地利用這些信息,為后續(xù)的數(shù)據(jù)挖掘和推薦提供有力支持。
3.2" 評(píng)判標(biāo)準(zhǔn)
F1值[18]是召回率(Recall)和準(zhǔn)確率(Precision)的調(diào)和平均數(shù),它試圖同時(shí)考慮到準(zhǔn)確率和召回率,從而提供一個(gè)單一的性能度量。本文采用F1值作為評(píng)測(cè)標(biāo)準(zhǔn)。[F(u)]和[O(u)]分別代表訓(xùn)練行為和測(cè)試集行為,分別反映了用戶的推薦偏好和實(shí)際行為偏好。準(zhǔn)確率(Precision)、召回率(Recall)和F1的公式如下:
[Precision=u∈UF(u)?O(u)u∈UO(u)] (6)
[Recall=u∈UO(u)?F(u)u∈UF(u)] (7)
[F1=2·Precision+RecallPrecision·Recall] (8)
3.3" 實(shí)驗(yàn)結(jié)果及分析
在SDAE模型中,影響實(shí)驗(yàn)結(jié)果的參數(shù)主要是輸入數(shù)據(jù)的加噪比例。輸入數(shù)據(jù)的加噪比例指的是在訓(xùn)練過(guò)程中,原始輸入數(shù)據(jù)被人為添加噪聲的比例或強(qiáng)度,目的是迫使模型學(xué)習(xí)從破壞的輸入中恢復(fù)出原始數(shù)據(jù),從而學(xué)習(xí)到更加魯棒和有用的數(shù)據(jù)表示。
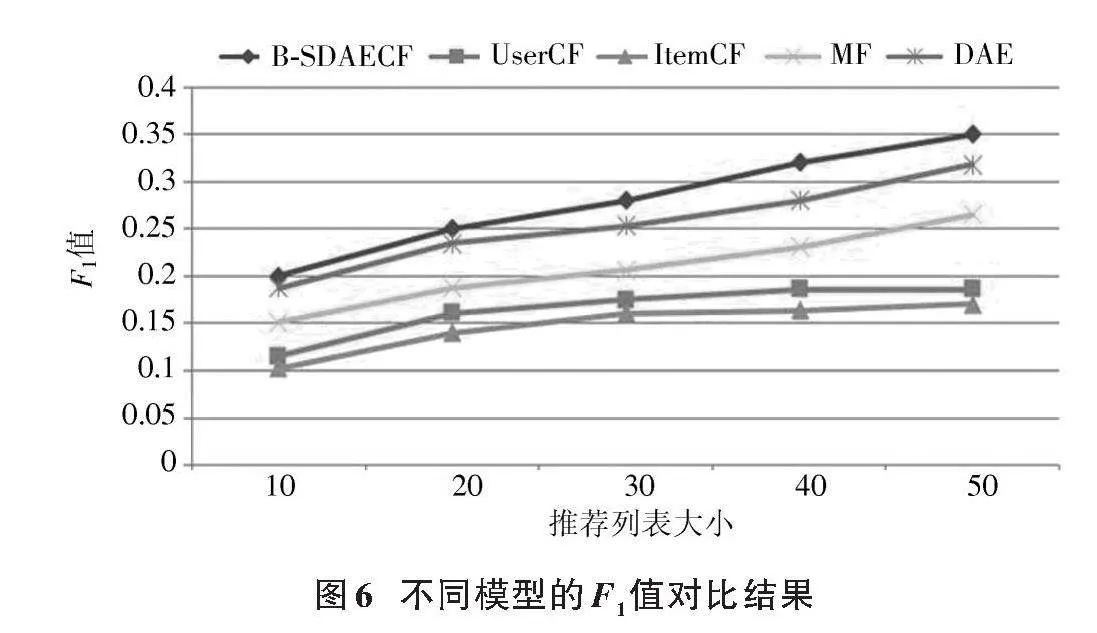
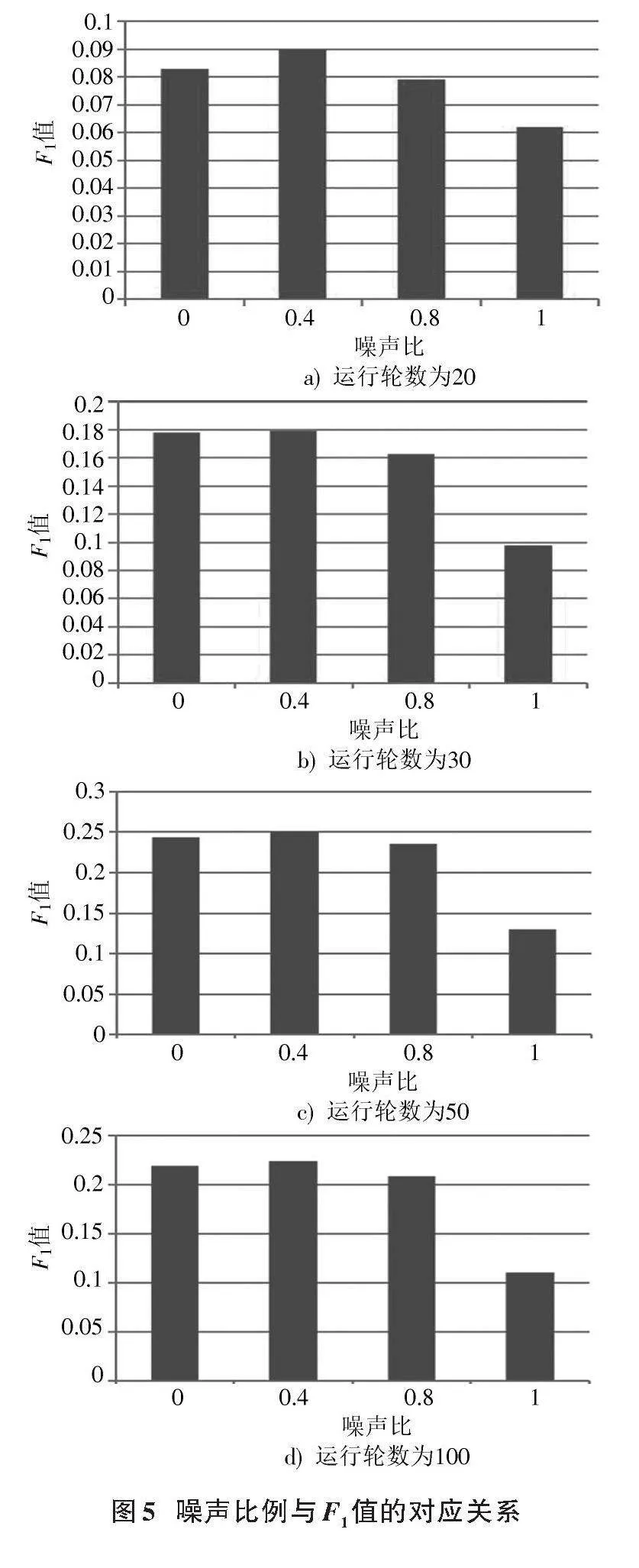
本文在不同的噪聲比下進(jìn)行20、30、50、100四種迭代次數(shù)的實(shí)驗(yàn),結(jié)果如圖5所示。由圖5可知,在不同迭代次數(shù)的情況下,噪聲比為0.4時(shí)模型的運(yùn)算情況更好。加噪比例過(guò)高會(huì)使噪聲對(duì)原數(shù)據(jù)的干擾較大,同時(shí)也干擾了模型對(duì)原數(shù)據(jù)的識(shí)別,使得模型運(yùn)算效果變差;而過(guò)低的噪聲比例會(huì)使得模型快速收斂但無(wú)法學(xué)習(xí)到數(shù)據(jù)的本質(zhì)特征。此外,也進(jìn)行了一系列對(duì)比實(shí)驗(yàn),以深入評(píng)估本文B?SDAECF模型的性能。將其與傳統(tǒng)的UserCF、ItemCF以及基于DAE的協(xié)同過(guò)濾(DAE)和矩陣分解算法(MF)進(jìn)行了對(duì)比,結(jié)果如圖6所示。從圖6中可以看出,B?SDAECF模型與其他模型相比,在推薦質(zhì)量上有著顯著的優(yōu)勢(shì)。具體而言,本文模型性能比DAE提高了約3.8%。通過(guò)利用Bert技術(shù),模型能夠更精準(zhǔn)地提取用戶的偏好。Bert的雙向上下文理解能力使得模型能夠捕捉到用戶的細(xì)微差別和深層次的興趣,這是傳統(tǒng)的DAE模型所難以做到的。相較于DAE這樣的線性模型,B?SDAECF作為非線性模型,在處理復(fù)雜的用戶?物品關(guān)系時(shí)具有更強(qiáng)的表示能力,它能夠捕捉到更多的非線性關(guān)系,從而更準(zhǔn)確地預(yù)測(cè)用戶的喜好。與傳統(tǒng)的UserCF、ItemCF相比,本文模型的F1值分別提高了15.5%、18%。這是由于UserCF和ItemCF主要依賴于用戶?物品交互數(shù)據(jù)的相似性進(jìn)行計(jì)算,沒(méi)有B?SDAECF在特征提取方面的靈活性和深度。與MF相比本文模型的F1值提升了9%,說(shuō)明該模型在處理非線性的關(guān)系時(shí)具有更好的優(yōu)勢(shì)。而MF主要基于線性關(guān)系進(jìn)行建模,無(wú)法充分捕獲數(shù)據(jù)中的復(fù)雜模式。
綜上所述,B?SDAECF模型通過(guò)深度提取用戶偏好、優(yōu)化初始權(quán)重參數(shù)以及利用非線性建模的優(yōu)勢(shì),實(shí)現(xiàn)了比傳統(tǒng)的DAE模型更高的推薦質(zhì)量。此外,與其他傳統(tǒng)的推薦模型相比,該模型也展現(xiàn)出了明顯的性能優(yōu)勢(shì),進(jìn)一步證明了非線性模型在推薦系統(tǒng)中的適用性。
4" 結(jié)" 語(yǔ)
本文提出一種改進(jìn)的推薦算法,該算法融合了Bert模型和SDAE,目的是解決傳統(tǒng)推薦系統(tǒng)中數(shù)據(jù)稀疏的問(wèn)題。首先,運(yùn)用Bert模型深度分析數(shù)據(jù)集中的用戶評(píng)論,精準(zhǔn)捕捉用戶的興趣點(diǎn),并據(jù)此生成相應(yīng)的項(xiàng)目向量;其次,將項(xiàng)目向量作為SDAE的初始權(quán)重參數(shù),從而構(gòu)建出更為精準(zhǔn)的推薦模型。
該方法不僅有效地填充了用戶?項(xiàng)目矩陣中的缺失數(shù)據(jù),還進(jìn)一步利用填充后的完整矩陣來(lái)確定與目標(biāo)用戶興趣相近的其他用戶,并為這些用戶推薦他們可能感興趣的項(xiàng)目。實(shí)驗(yàn)結(jié)果表明,本文提出的B?SDAECF模型在推薦精度和質(zhì)量上均具有顯著優(yōu)勢(shì),能夠?yàn)橛脩魩?lái)更加精準(zhǔn)、個(gè)性化的推薦體驗(yàn)。
注:本文通訊作者為李然。
參考文獻(xiàn)
[1] 龍國(guó)虎,朵琳.神經(jīng)網(wǎng)絡(luò)推薦系統(tǒng)協(xié)同過(guò)濾算法研究[J].中國(guó)水運(yùn)(下半月),2024,24(3):40?42.
[2] GOLDBERG D, NICHOLS D A, OKI B M, et al. Using collaborative filtering to weave an information TAPESTRY [J]. Communications of the ACM, 1992, 35(12): 61?70.
[3] LINDEN G, SMITH B, YORK J. Industry report: amazon.com recommendations: item?to?item collaborative filtering [J]. IEEE internet computing, 2003, 7(1): 76?80.
[4] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation [J]. Journal of machine learning research, 2003, 3: 993?1022.
[5] KOREN Y. Factorization meets the neighborhood: a multi?faceted collaborative filtering model [C]// Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]: ACM, 2008: 426?434.
[6] 包晨.基于深度神經(jīng)網(wǎng)絡(luò)的協(xié)同過(guò)濾推薦算法研究[D].濟(jì)南:山東建筑大學(xué),2023.
[7] HE X, LIAO L, ZHANG H, et al. Neural collaborative filtering [C]// Proceedings of the 26th International Conference on World Wide Web. Perth, Australia: IEEE, 2017: 173?182.
[8] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems. Long Beach, USA: IEEE, 2017: 5998?6008.
[9] LECUN Y, BOTTOU L. Gradient?based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278?2324.
[10] SEO S Y, HUANG J, YANG H, et al. Interpretable convolutional neural networks with dual local and global attention for review rating prediction [C]// Proceeding of the Eleventh ACM Conference on Recommender Systems. Como, Italy: ACM, 2017: 297?305.
[11] HOCHREITER S, SCHMIDHUBER J. Long short?term memory [J]. Neural computation, 1997, 9(8): 1735?1780.
[12] YIN W, SCHüTZE H, XIANG B, et al. ABCNN: attention?based convolutional neural network for modeling sentence pairs [J]. Transactions of the association for computational linguistics, 2016, 4(4): 259?272.
[13] LIU J, WANG D, DING Y. PHD: a probabilistic model of hybrid deep collaborative filtering for recommender systems [J]. Journal of machine learning research, 2017, 77: 224?239.
[14] WU Y, DUBOIS C, ZHENG A X, et al. Collaborative denoising auto?encoders for top?n recommender systems [C]// Proceedings of the Ninth ACM International Conference on Web Search and Data Mining. San Francisco, CA, USA: ACM, 2016: 153?162.
[15] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre?training of deep bidirectional transformers for language understanding [EB/OL]. [2023?11?07]. https://arxiv.org/pdf/1810.04805.
[16] VINCENT P, LAROCHELLE H, LAJOIE I, et al. Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion [J]. Journal of machine learning research, 2010, 11(12): 102?110.
[17] VINCENT P, LAROCHELLE H, BENGIO Y, et al. Extracting and composing robust features with denoising autoencoders [C]// Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ICML, 2008: 1096?1103.
[18] WU Y, LIU X, XIE M, et al. CCCF: improving collaborative filtering via scalable user?item co?clustering [C]// Proceedings of the Ninth ACM International Conference on Web Search and Data Mining. San Francisco, CA, USA: ACM, 2016: 73?82.
[19] 李昌兵,陳思彤,羅陳紅,等.基于物品交互約束的自編碼器推薦模型[J/OL].重慶郵電大學(xué)學(xué)報(bào)(自然科學(xué)版):1?7[2024?03?31].http://kns.cnki.net/kcms/detail/50.1181.N.20240329.0929.002.html.
作者簡(jiǎn)介:王" 寧(1999—),男,遼寧大連人,碩士研究生,研究方向?yàn)橥扑]算法。
李" 然(1967—),女,遼寧大連人,副教授,主要研究方向?yàn)橛?jì)算機(jī)科學(xué)與技術(shù)。
王客程(2000—),男,遼寧沈陽(yáng)人,碩士研究生,研究方向?yàn)樯疃葘W(xué)習(xí)。
吳" 江(1998—),男,甘肅白銀人,碩士研究生,研究方向?yàn)樯疃葘W(xué)習(xí)。
范利利(1997—),男,山東菏澤人,碩士研究生,研究方向?yàn)橥扑]算法。
DOI:10.16652/j.issn.1004?373x.2024.20.015
引用格式:王寧,李然,王客程,等.基于神經(jīng)網(wǎng)絡(luò)和注意力機(jī)制的協(xié)同過(guò)濾推薦算法的研究[J].現(xiàn)代電子技術(shù),2024,47(20):95?100.
收稿日期:2024?04?17" " " " " "修回日期:2024?05?20
基金項(xiàng)目:中國(guó)醫(yī)藥教育協(xié)會(huì)2022重大科學(xué)攻關(guān)問(wèn)題和醫(yī)藥技術(shù)難題重點(diǎn)課題(2022KTM036)
