改進YOLOv5的布匹缺陷檢測方法
2024-10-17 00:00:00張凱旋杜景林
現代電子技術 2024年20期



摘" 要: 現階段布匹缺陷種類繁雜,且包含大量人眼難以辨別的小目標缺陷和長寬比極端不平衡缺陷,使得在復雜背景下的布匹缺陷檢測成為一項艱巨任務。為此,提出一種改進YOLOv5的布匹缺陷檢測方法。首先,在YOLOv5的C3模塊中增加注意力機制NAM,設計為C3NAM模塊,其可以抑制特征值中不顯著的權重,在保持性能的同時進行高效計算;其次,采用一個新的CNN模塊SPD?Conv,以解決大部分的布匹缺陷檢測在分辨率較低或者瑕疵較小時性能迅速下降的問題;最后,在檢測端引入新的損失函數Alpha?IoU,促進真實框和預測框的擬合,并提升對缺陷預測的準確性。實驗結果表明:改進的YOLOv5網絡模型較原YOLOv5網絡模型mAP@0.5值提高了5.4%,mAP@0.5:0.95值提高了2.2%,且檢測效果優于原網絡模型和其他主流目標檢測模型。
關鍵詞: 布匹缺陷檢測; YOLOv5; 注意力機制; 小目標缺陷; 卷積操作; 消融實驗
中圖分類號: TN911.73?34; TP391.7" " " " " " " " " "文獻標識碼: A" " " " nbsp; " " " 文章編號: 1004?373X(2024)20?0109?09
Method of fabric defect detection based on improved YOLOv5
ZHANG Kaixuan1, 3, DU Jinglin2
(1. College of Computer Science, Nanjing University of Information Science and Technology, Nanjing 210044, China;
2. School of Artificial Intelligence, Nanjing University of Information Science and Technology, Nanjing 210044, China;
3. NUIST?TianChang Research Institute, Tianchang 239300, China)
Abstract: There are various types of fabric defects, including a large number of small target defects that are difficult for the human eye to distinguish and extremely imbalanced aspect ratio defects, making fabric defect detection in complex backgrounds a daunting task. Therefore, a method of fabric defect detection based on improved YOLOv5 method is proposed. The C3NAM (normalization?aware mechanism) module is designed by adding attention mechanism NAM to the C3 module of YOLOv5, which can suppress the insignificant weights in the characteristic value and perform efficient computation while maintaining performance. A new CNN (convolutional neural networks) module SPD?Conv (space?to?depth?convolution), is adopted to solve the problem of rapid performance degradation in most fabric defect detection when the resolution is low or the defects are small. A new loss function Alpha?IoU is introduced in the detection side to facilitate the fitting of the real box and the prediction box, and improve the accuracy of the defect prediction. The experimental results show that, in comparison with the original YOLOv5 network model, the improved YOLOv5 network model has an increase of 5.4% mAP@0.5 and 2.2% mAP@0.5:0.95, and the detection effect is superior to the original network model and other mainstream target detection models.
Keywords: fabric defect detection; YOLOv5; attention mechanism; small object detection; convolution operation; ablation experiment
0" 引" 言
紡織品是一種廣泛應用于工業和生活中的衣物原料,對人類社會具有重要的價值。中國在紡織品的生產和出口方面位居世界第一,紡織業是中國國民經濟的支柱產業之一,對國家發展起著關鍵性作用。布匹在工業生產和加工過程中,會出現多種多樣的表面缺陷,這些缺陷有80多種不同的分類,它們不僅直接影響了紡織品的質量水平,也限制了紡織行業的快速進步[1?2]。因此,紡織品生產中,對布匹表面缺陷實施精準檢測是不可或缺的一環[3]。
早期的缺陷檢測主要依賴人工肉眼識別,效率低下且成本高昂,易產生漏檢和誤判。目前的檢測方法一部分基于傳統機器視覺,主要分為空間統計法、模型分析法和頻域分析法;另一部分為基于深度學習的目標檢測算法。基于深度學習的布匹缺陷檢測方法已經成為當前研究的重點。
深度學習在檢測任務中的應用,依據其運作機制,可以劃分為兩大流派:一種是基于區域建議的雙階段檢測網絡,另一種是基于直接回歸的單階段檢測模型。雙階段檢測網絡的檢測過程分為兩個步驟:首步,利用網絡生成潛在區域;隨后,另一網絡對這些區域進行分類和坐標的精準調整。雙階段檢測網絡的典型模型有Faster?RCNN[4]、Cascade RCNN[5]和DETR[6]等。單階段檢測網絡不需要生成候選區域,而是直接用一個網絡完成分類和精確坐標回歸的任務,典型模型有SSD[7]、RetinaNet[8]和YOLO[9?11]系列等。相較于雙階段網絡,單階段網絡在檢測速度上更為迅捷,在實現實時檢測的同時可維持較高精度,因此已成為當前織物缺陷檢測領域的主要研究焦點。陳康等人通過對卷積神經網絡進行研究,利用Faster R?CNN進行改進,顯著提高了檢測精度。但由于傳統CNN網絡的計算復雜度高且對小目標檢測不足,檢測速度完全不能滿足工業化需求,不能對瑕疵點進行分類檢測[12]。周君等人采用K?means算法優化YOLOv3的候選框數量與尺寸,同時精簡網絡結構進行剪枝,實現模型壓縮與加速,以滿足工業化應用的高效需求,但是同樣沒有在公開數據集進行訓練,不具有泛化能力[13]。文獻[14]在傳統CNN網絡的基礎上,通過圖像直方圖均衡、降噪和邊緣檢測對織物圖像進行增強,進一步提高了檢測精度,但依舊沒有解決速度問題。孫浩東等人設計出新的SimAM注意力機制增強缺陷提取能力,提高小尺寸缺陷精度,在檢測端運用新的損失函數CIoU提高了檢測精度,但對布匹缺陷只分了6類,不符合現代工業化對于缺陷更細致的分類要求[15]。
綜上所述,現有的深度學習布匹缺陷檢測算法在速度與精度間常需權衡,且數據集多局限于顯著缺陷和簡單背景,導致小目標檢測中準確率低、漏檢、誤檢等問題頻發。本文為解決圖像背景噪聲大、小目標及極度長寬比瑕疵的檢測難題,并擴展缺陷種類的識別范圍,顯著提升YOLO網絡對布匹缺陷的檢測精度,提出了一種基于YOLOv5的布匹缺陷檢測方法。本文主要工作與創新如下。
1) 提出了一種新型的C3NAM模塊,將原有的C3模塊進行改進,加入了NAM(Normalization? Aware Mechanism)[16]注意力機制并嵌入原主干網絡中。針對缺陷較小時其特征易與周圍特征產生融合,使得在卷積過程中難以提取到小目標瑕疵的特征,導致網絡中出現信息丟失的現象,NAM注意力機制增強對小目標缺陷的提取能力,強化對缺陷區域的關注度。
2) 由于布匹背景的復雜性及其與缺陷的融合現象,小目標缺陷通常表現為較低的分辨率,這在進行卷積和池化操作時易導致細粒度信息丟失,進而影響學習效率。為解決這一問題,本文加入了一種新的CNN模塊,稱為SPD?Conv[17],以取代原有的卷積層和池化層。SPD?Conv由SPD(space?to?depth)層和Conv(non?strided convolution)層組成。
3) 在檢測端采用新的Alpha?IoU[18]損失來加強真實框和檢測框擬合,提高對布匹瑕疵小目標檢測的精度。
1" YOLOv5s的目標檢測方法
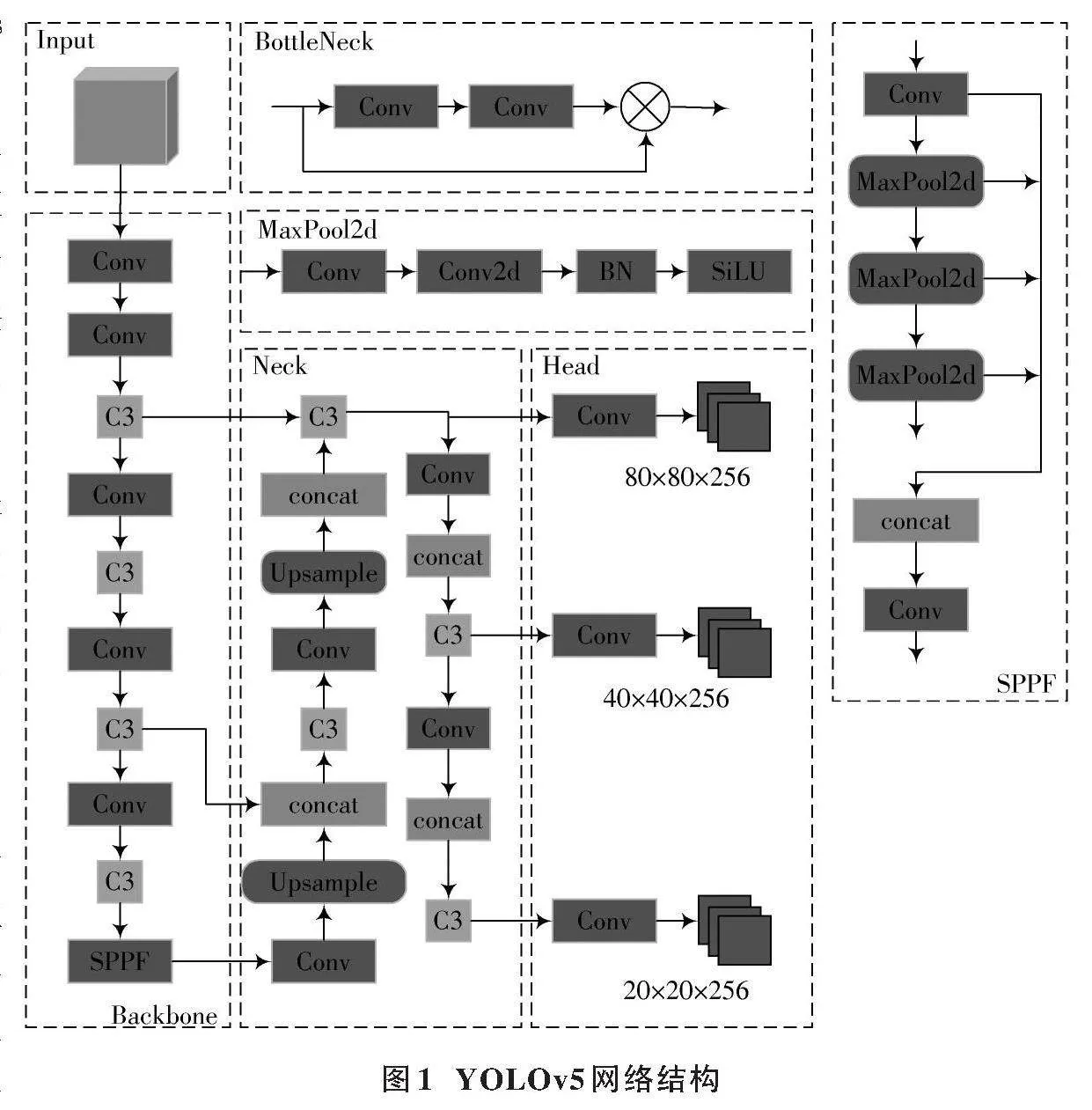
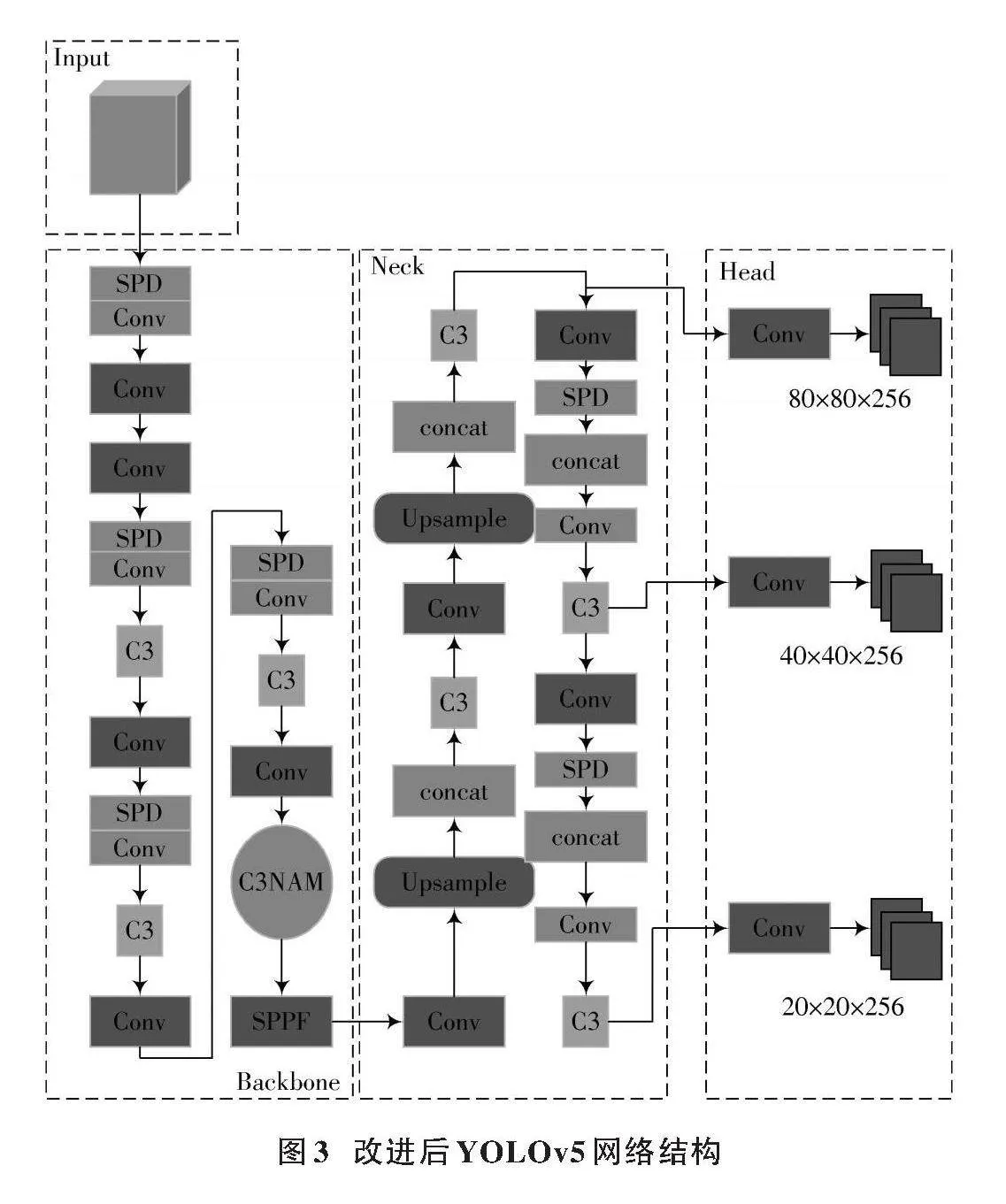
YOLOv5?v6.2目標檢測是v5系列最新版本[19],它包含n、s、m、l、x五個小版本,檢測精度隨版本遞升而提升,但訓練與推理時間也相應增加。為平衡工業應用的效率與準確性,本文選用YOLOv5s作為基準模型。該模型由輸入端、Backbone、Neck和Head四部分構成,網絡框架如圖1所示。
1) 輸入端:YOLOv5的輸入端是CNN,能處理任意大小圖像并轉換為特征圖。它根據輸入分辨率選擇模型變體,并利用預訓練參數提升通用性和效率。
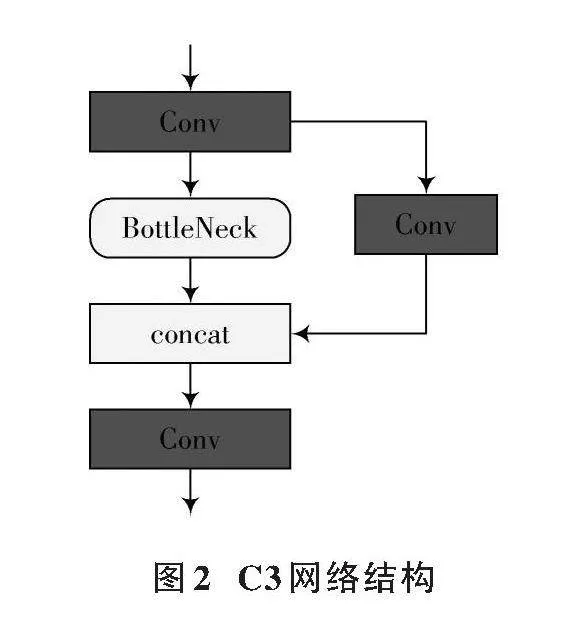
2) Backbone網絡:Backbone網絡融合了Conv、C3與SPPF模塊,用于提取圖像特征。Conv層調整特征通道;C3模塊是關鍵,汲取CSPNet精髓,含標準卷積層、多BottleNeck及拼接模塊;SPPF[20]由SPP改進,利用最大池化整合局部與全局信息,增強特征表達。C3網絡結構如圖2所示。
3) Neck網絡:YOLOv5的Neck模塊由FPN和PANet雙塔結構組成,融合多尺度特征提升檢測性能。FPN構建特征金字塔,PANet[21]結合上下采樣實現多層次特征融合,優化特征表達。
4) Head輸出層:Head部分包含三個檢測器,確保精確檢測。對于640×640的圖像,Head層對Neck層三個輸出執行卷積,在20×20、40×40和80×80特征圖上生成預測框。
目前,YOLOv5作為工業上廣泛使用的目標檢測方法,雖兼容性強,但布匹上小目標缺陷檢測面臨諸多挑戰。復雜背景與缺陷融合、拍攝條件限制導致輕微缺損與背景融合,使模型識別困難。缺陷種類、形狀、大小的變化進一步加劇了檢測難度,且小目標缺陷信息量少,易在卷積中丟失。此外,YOLOv5網絡結構復雜,計算資源需求高,對硬件要求嚴苛。
2" 改進YOLOv5的布匹缺陷檢測方法
本文基于YOLOv5進行布匹缺陷檢測改進,其網絡結構如圖3所示。改進后的模型保留原架構,實現高效目標檢測。
2.1" 基于NAM的注意力機制的C3NAM模塊
在原有的基準模型中,由于復雜的背景和小目標缺陷與布匹紋理交織,導致原本不顯著的特征信息受到其他信息的干擾,難以發揮檢測作用。為了解決這一問題,本文受到卷積注意力模塊(NAM)的啟發,將其嵌入到主干網絡的C3模塊中。這樣做可以加強模型對布匹缺陷細節的提取能力,并減少其他無關細節的影響,從而提升檢測效果。
以往的注意力機制多聚焦于顯著特征的提取,但忽視了權重在抑制噪聲中的作用。SE機制將空間信息引入至通道特征,通過多層感知器計算注意力。CBAM則按照順序嵌入通道和空間子模塊。這些機制雖考慮了空間與通道特征,但常忽視權重因素,難以有效抑制無關信道或像素。
CBAM注意力機制擁有空間與通道注意力兩個模塊,它們分別進行通道和空間上的特征捕捉,減少了參數和注意力計算,保證其能夠很好地嵌入到模型網絡當中。以通道注意力機制為例,具體流程為:將輸入的特征圖在空間維度進行壓縮,分別送入基于長寬的全局最大池化和全局平均池化中,聚合特征映射的空間信息;得到處理后的特征圖,再分別送入共享雙層神經網絡,而后將共享雙層神經網絡輸出的特征圖經過加和操作送入Sigmoid進行激活操作,最終得到輸出特征。通過平均池化操作可以對圖像中每一個像素點進行操作;而進行最大池化是為了保證在梯度反向操作時,模型能夠對特征圖中響應最大的地方有反饋。對于輸入的操作,CBAM會沿著通道和空間兩個獨立的維度進行操作,最后分別將得到的注意力圖與輸入的圖相乘進行優化。
NAM作為一種高效輕量的注意力機制,創新性地融合了CBAM模塊,對通道與空間注意力子模塊進行了精巧的重新設計。這種設計使得NAM能夠在特征圖的通道維度與空間維度上精準地實施注意力機制。為了達到這一目的,本文引入了權重的影響因素來優化注意機制。特別地,采用了批歸一化的比例因子,通過標準差來量化權重的重要性,從而實現更精準的注意力分配。使用批處理歸一化(BN)中的比例因子計算,定義為:
[Bout=BN(Bin)=γBin-μBσ2B+ε+β]" " " (1)
式中:[μB]為小批量B的值;[σB]為小批量B的偏差度量值;[γ]、[β]為可調整的仿射變換因子(包括縮放與偏移量);[ε]為趨近于0的量,確保分母非0。
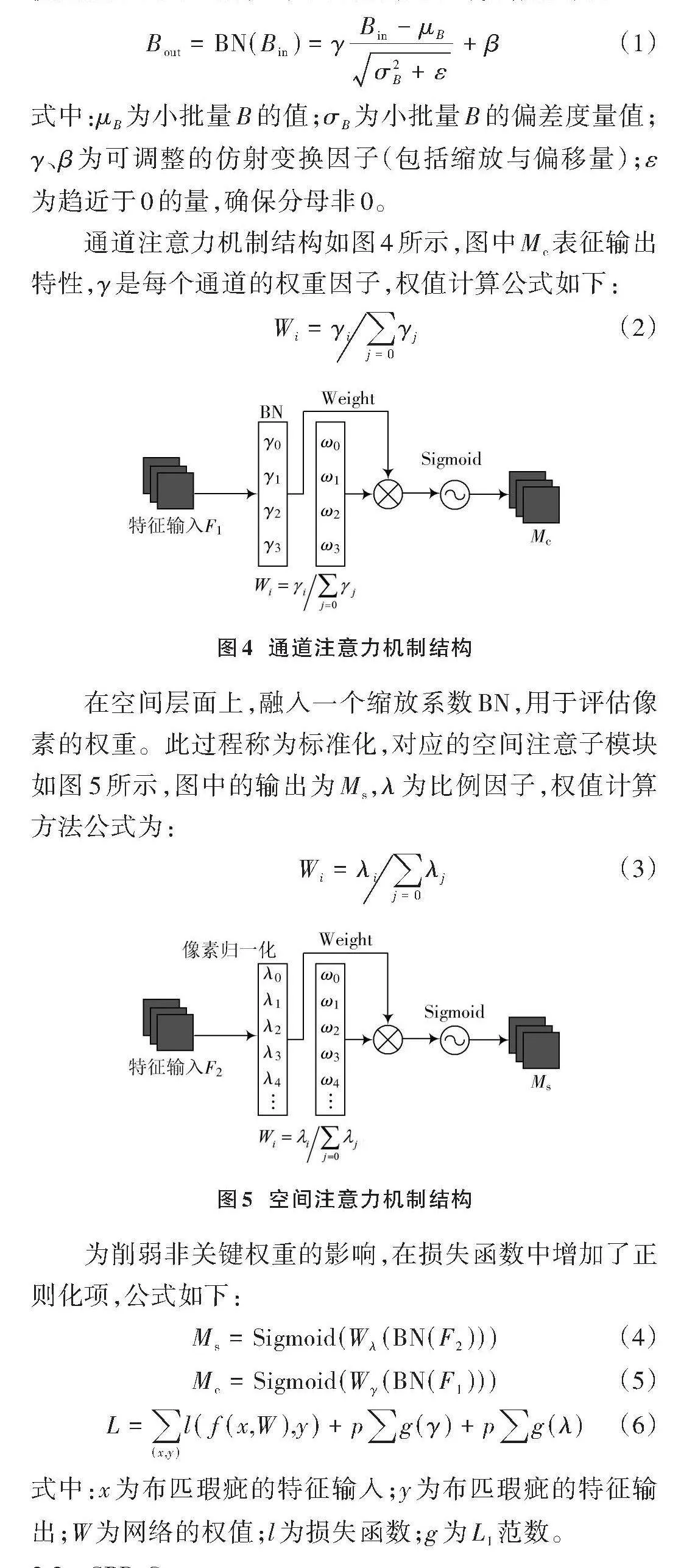
通道注意力機制結構如圖4所示,圖中[Mc]表征輸出特性,[γ]是每個通道的權重因子,權值計算公式如下:
[Wi=γij=0γj]" " " " " (2)
在空間層面上,融入一個縮放系數BN,用于評估像素的權重。此過程稱為標準化,對應的空間注意子模塊如圖5所示,圖中的輸出為[Ms],[λ]為比例因子,權值計算方法公式為:
[Wi=λij=0λj]" " " " " " "(3)
為削弱非關鍵權重的影響,在損失函數中增加了正則化項,公式如下:
[Ms=Sigmoid(Wλ(BN(F2)))]" (4)
[Mc=Sigmoid(Wγ(BN(F1)))]" (5)
[L=(x,y)lf(x,W),y+pg(γ)+pg(λ)]" (6)
式中:[x]為布匹瑕疵的特征輸入;[y]為布匹瑕疵的特征輸出;[W]為網絡的權值;[l]為損失函數;[g]為[L1]范數。
2.2" SPD?Conv
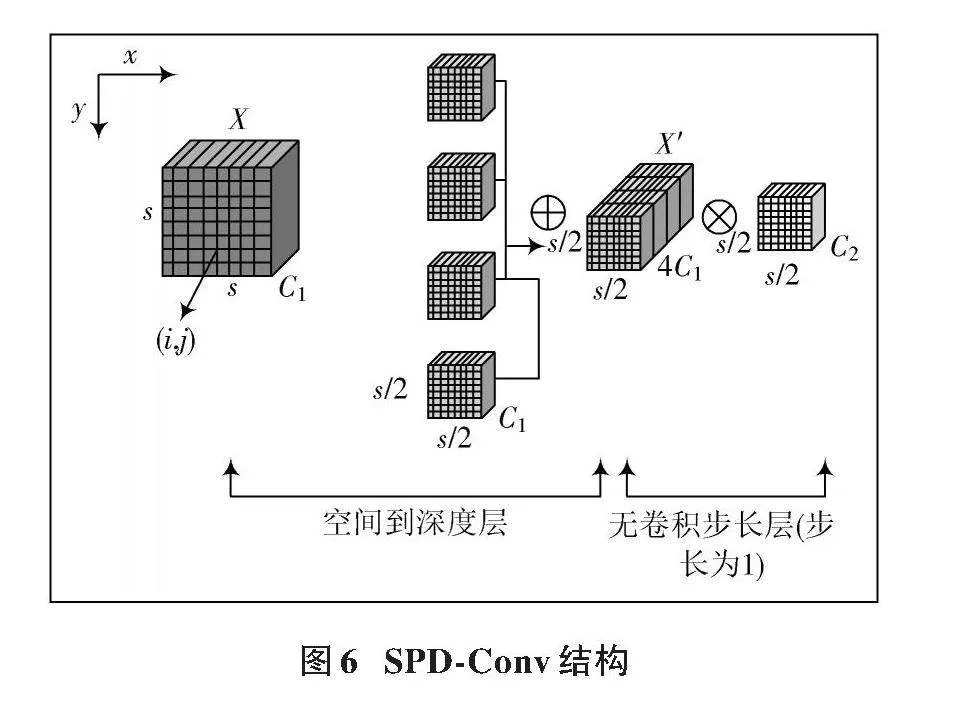
布匹表面常會出現肉眼難以識別的小目標缺陷,這些小目標缺陷在原模型中由于占據的位置小,攜帶的特征信息少,常常面臨檢測困難。在YOLOv5模型的卷積操作過程中,隨著不斷的下采樣,輸入的特征圖大小逐漸減小,導致原本有限的小目標特征信息在特征圖中出現嚴重缺失。此外,由于YOLOv5采用跨層連接技術,不同尺度的特征被直接相加或拼接,這進一步加劇了小目標信息的退化現象。為了解決這一問題,本文提出使用新的卷積池化層來替代原有的卷積操作,以期在連續的卷積過程中保留更多的有效信息,從而提升小目標缺陷的檢測效果。本文采用SPD?Conv模塊替代傳統的卷積步長和池化層,減少特征信息的損失,進而提高布匹缺陷在復雜背景下的檢測準確度。SPD?Conv結構如圖6所示。
在SPD中,假如輸入尺寸為[s×s×C1]的特征圖[X],可將它分塊為 [i+x]和 [j+y]各種子圖[fx,y],生成的每個子圖都會對[X]下采樣。圖6中比例因子為2,那么每個子圖尺寸為 [(s2)×(s2)×C1]。最后本文將處理過的子圖進行拼接獲得特征圖[X],可以得到一個新的尺寸為[(s2)×(s2)×22C1]的圖像。通過將輸入模型的布匹圖像的特征信息重組進入深度通道,增加了通道的個數,解決了在原有模型中小目標經常丟失精細目標的現象,保留了更加豐富的特征信息進入新的非步長卷積層中。
在Conv中使用了一個步長為1的卷積層,這意味著相較于傳統的卷積操作將特征圖不斷變小,新的卷積操作會在特征圖中以像素級進行移動,對特征圖中的每一個像素信息都進行采集操作,確保特征圖中每一個位置都能夠進行卷積操作,最大程度地保留了布匹缺陷信息,形成信息豐富的特征圖。非步長卷積層用來處理經過池化操作重新排列的特征信息,由于本文設置步長為1,所以在下采樣環節并不會造成圖像的分辨率降低,這就使得可以在不丟失布匹信息的同時降低特征圖的通道數量。
根據上述分析,SPD?Conv模塊相較于傳統卷積運算,在保留信息方面更具優勢,有助于提升對小目標的特征提取能力。在本文模型Conv部分,SPD?Conv模塊使用了一個步長為1的卷積層將特征X′的尺寸變為[s2×s2×C2],令[C2lt;22C1],以盡可能地保存布匹缺陷的重要信息,并且使用一個步長為1的卷積層,較好地控制模型參數的增加,避免過度復雜化,有效提升模型推理速度。
2.3" 改進損失函數
基準模型YOLOv5的損失函數是采用基于回歸損失的GIoU[22],實際框和預測框在水平方向或者豎直方向重合,或者預測框被包含在實際框中,那么它們之間的相對位置關系就無法正常確定,此時GIoU和普通的IoU擁有相同值,GIoU就會退化變成普通的IoU。
為了解決原有基礎模型不完善的缺點,在改進的布匹缺陷檢測方法中引入了α?IoU,這個損失函數的優點在于可以完全地保留原有損失函數的優點。α?IoU能夠檢測布匹的小缺陷目標,提高了檢測的準確性,并且可以將原有的GIoU更換為CIoU[23],增加了長和寬的Loss,讓預測框更加符合真實框。α?IoU是在原有的基礎上加上了一個冪指數,以[α]為冪,公式如下:
[Lossα?IoU=1-IoUαα," αgt;0]" " " " "(7)
在保持原有損失函數優點的同時,α?IoU能夠不增加額外的參數和訓練時間,通過對其參數進行調節,達到參數和速度的雙向優化。
本文方法采用效果較好的α?IoU,其公式如下所示:
[Lossα?CIoU=1-IoU+ρ2α(b,bgt)c2α+(βv)α]" "(8)
[v=4π2arctanwgthgt-arctanwh2] (9)
[β=v(1-IoU)+v]" " " " " " " " " " (10)
式中:[b]、[bgt]用以描述預測框與真實框中心之間的距離;[ρ2α]代表兩中心點間的歐氏距離,為其間距標識;[c]為包含預測框與真實框的最小封閉區間對角長度;[wgthgt]表示目標框的寬高比;[wh]表示預測框各自的寬高比。
3" 實驗結果處理與分析
3.1" 數據集介紹和評價指標
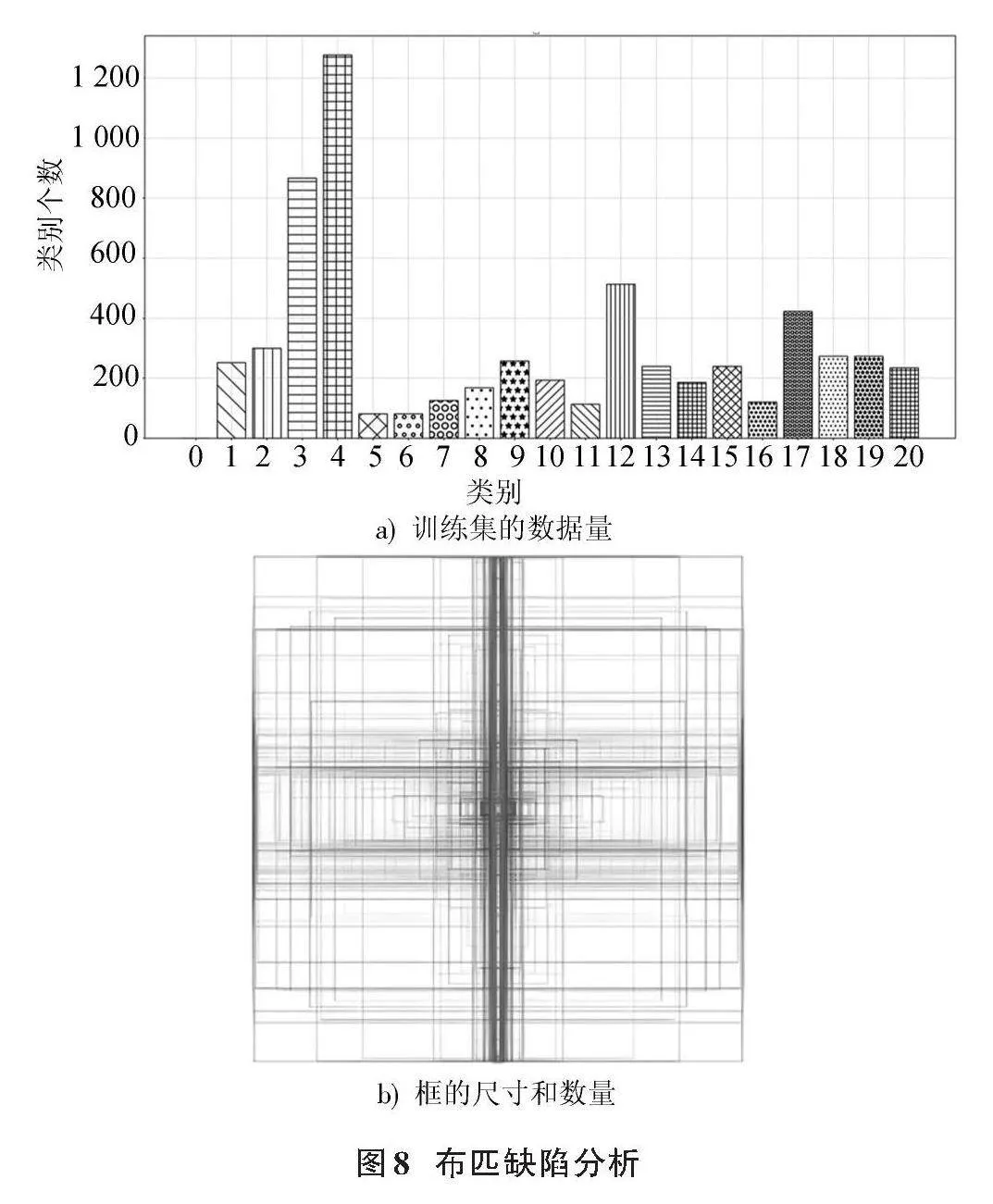
本文選用阿里的布匹瑕疵數據集,含4 774張圖像,按4∶1比例劃分為訓練集與驗證集。該數據集圖像背景復雜,瑕疵目標小且難識別。布匹瑕疵種類繁多,本文整合相似部分,將檢測任務細致劃分為21個類別,具體包括無疵點、破洞、污漬、三絲、結頭、花板跳、百腳、毛粒、粗經、松經、斷經、吊經、粗維、緯縮、漿斑、整經結、星跳、斷氨綸、稀密檔、磨痕、死皺。為了方便查看,將按照0~20進行排序。缺陷織物圖像如圖7所示。
為驗證算法的有效性,采用精度(P)、召回率(R)、平均精度(AP)及平均精度均值(mAP)來評估模型性能。同時,考慮模型復雜度,通過參數量和大小衡量;以計算量評估檢測速度。本文基于COCO數據集,以mAP@0.5和mAP@0.5:0.95為主要評估基準,其中mAP@0.5是在IoU閾值為0.5時的mAP,用于衡量模型性能。具體計算公式如下:
[P=TPTP+FP×100%]" " " " " " " (11)
[R=TPTP+FN×100%]" " " " " " "(12)
[AP=01P(R)dR]" " " " " " (13)
[mAP=1Ki=1KAP(i)]" " " " " (14)
式中:TP為成功檢測數;FP為錯誤檢測數;FN為未檢測數;TN為檢測到的背景值;K為缺陷類別總數。布匹缺陷分析結果如圖8所示,布匹缺陷以污漬、斷經、整經結為主,這些缺陷易與背景融合,且存在小破損難以識別,給檢測任務帶來了極大挑戰。真實瑕疵點標簽框顯示缺陷長寬比極不平衡,因此,一個具有更強適應能力的損失函數對于提升真實框與預測框的擬合效果至關重要。
3.2" 實驗環境和參數配置
實驗環境為Windows 10系統,配備12 GB顯存的NVIDIA GeForce RTX3060顯卡。平臺結合Anaconda與Pycharm,確保環境穩定。環境配置包括CUDA 11.3、Python 3.8、PyTorch 1.10.1及Torchvision 0.11.0,以優化性能與兼容性。參數配置方面,初始學習率為0.01,采用余弦退火策略調整;動量為0.937,加速收斂;權重衰減系數為5×10-4,防止過擬合。實驗批量處理大小為32,使用SGD優化器迭代訓練300次,確保模型充分學習。
3.3" 消融實驗
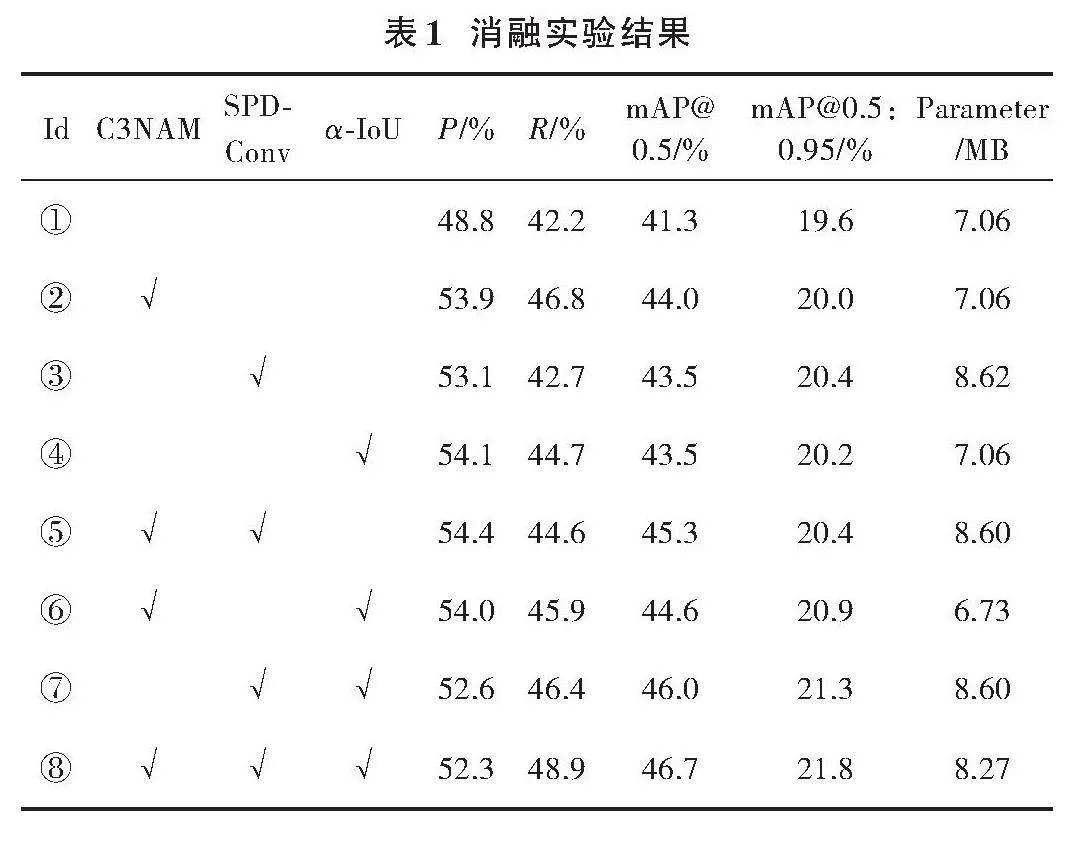
為探究本文改進的YOLOv5s模型中各模塊對布匹缺陷檢測性能的影響,在統一環境下進行消融實驗。表1展示了實驗結果,其中“√”表示該模塊被使用,Id編號表示的含義具體如下。
① 為未經改進的基準模型進行了實驗,以其結果作為后續實驗的參照基準,旨在對比各改進模塊的性能提升效果。
② 為在主干網絡的C3中添加NAM注意力機制,形成C3NAM模塊,顯著增強了模型對小目標的識別能力,有效減少了缺陷邊緣與紋理的交織。因此,P值提升5.1%,mAP@0.5提高2.7%,mAP@0.5:0.95增加0.4%。
③ 在網絡模型中引入SPD?Conv模塊替代卷積步長和池化層,有效減少主干網絡中的卷積特征損失。實驗結果顯示,P值提升4.3%,mAP@0.5提高2.2%,mAP@0.5:0.95增加0.8%,同時參數量略有增加。
④ 為僅引入損失函數,參數量未增加且使得P值提升了5.3%,mAP@0.5值提高了2.2%,而mAP@0.5:0.95值也增加了0.6%。這證實了Alpha?IoU損失函數在提升布匹缺陷檢測準確性方面的有效性。
⑤ 為同時添加了C3NAM模塊和SPD?Conv。與實驗②相比,引入SPD?Conv后,mAP@0.5值提升了1.3%,而mAP@0.5:0.95值也增加了0.4%,說明SPD?Conv能夠有效降低在卷積過程中的特征損失。
⑥ 為結合C3NAM模塊與α?IoU損失函數。α?IoU的引入使P值提升5.2%,mAP@0.5提高3.3%,mAP@0.5:0.95增加1.3%,證實其有助于預測框更貼合真實框,提升檢測準確性。
⑦ 為引入SPD?Conv和α?IoU損失函數的實驗,mAP@0.5和mAP@0.5:0.95值分別提高了4.7%和1.7%。
⑧ 相較于基準網絡YOLOv5s,準確率P提升3.5%,召回率提升6.7%,mAP@0.5提升5.4%,且未顯著增加模型參數量。消融實驗驗證了各改進點及其組合的有效性,尤其在小目標檢測方面表現突出,凸顯了本文方法在布匹缺陷檢測中的高效性和實用性。
3.4" 對比實驗
首先,通過實驗驗證C3NAM模塊在主干網絡中的適用性,并與四種主流注意力機制進行對比;其次,多角度對比改進模型與基準模型的性能;最后,將本文方法與五種經典檢測方法進行比較。
3.4.1" 不同注意力機制對比實驗
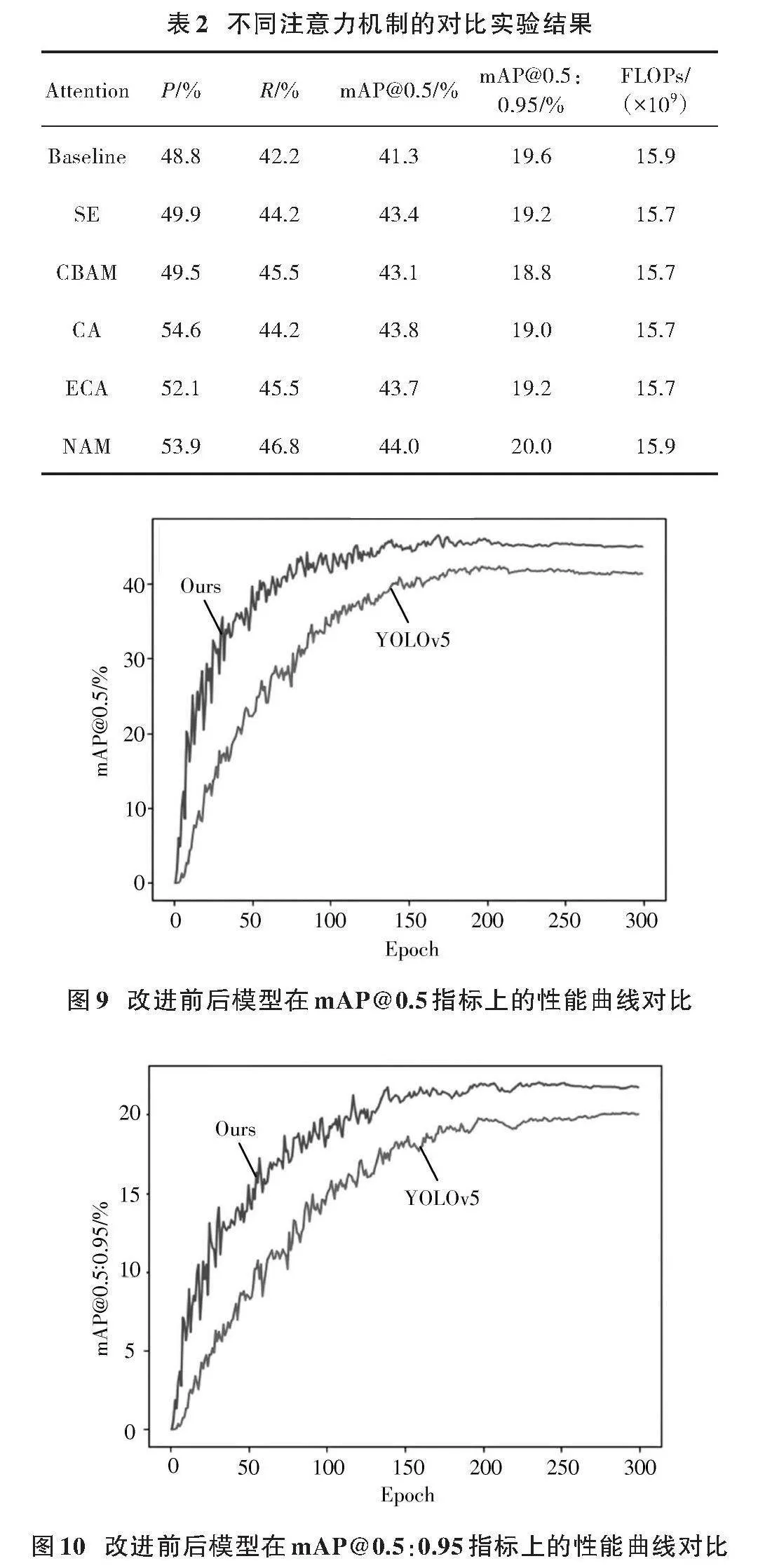
為驗證C3模塊中NAM注意力機制的先進性,選用四種主流注意力機制嵌入C3模塊進行對比實驗。如表2所示,本次實驗在同樣位置的C3模塊融入通道注意力機制SE[24]、卷積塊注意力機制CBAM[25]、坐標注意力機制CA[26]、高效通道注意機制ECA[27],并同時訓練300次Epoch進行對比。
表2顯示,在C3模塊中融入NAM注意力機制后,顯著提升了小目標缺陷的定位及布匹缺陷檢測能力。與主流注意力機制相比,NAM在提升mAP@0.5(2.7%)和mAP@0.5:0.95(0.4%)方面表現卓越,驗證了其在提升檢測精度方面的顯著優勢及在布匹缺陷檢測任務中的有效性。
3.4.2" 改進模型和基準模型性能對比
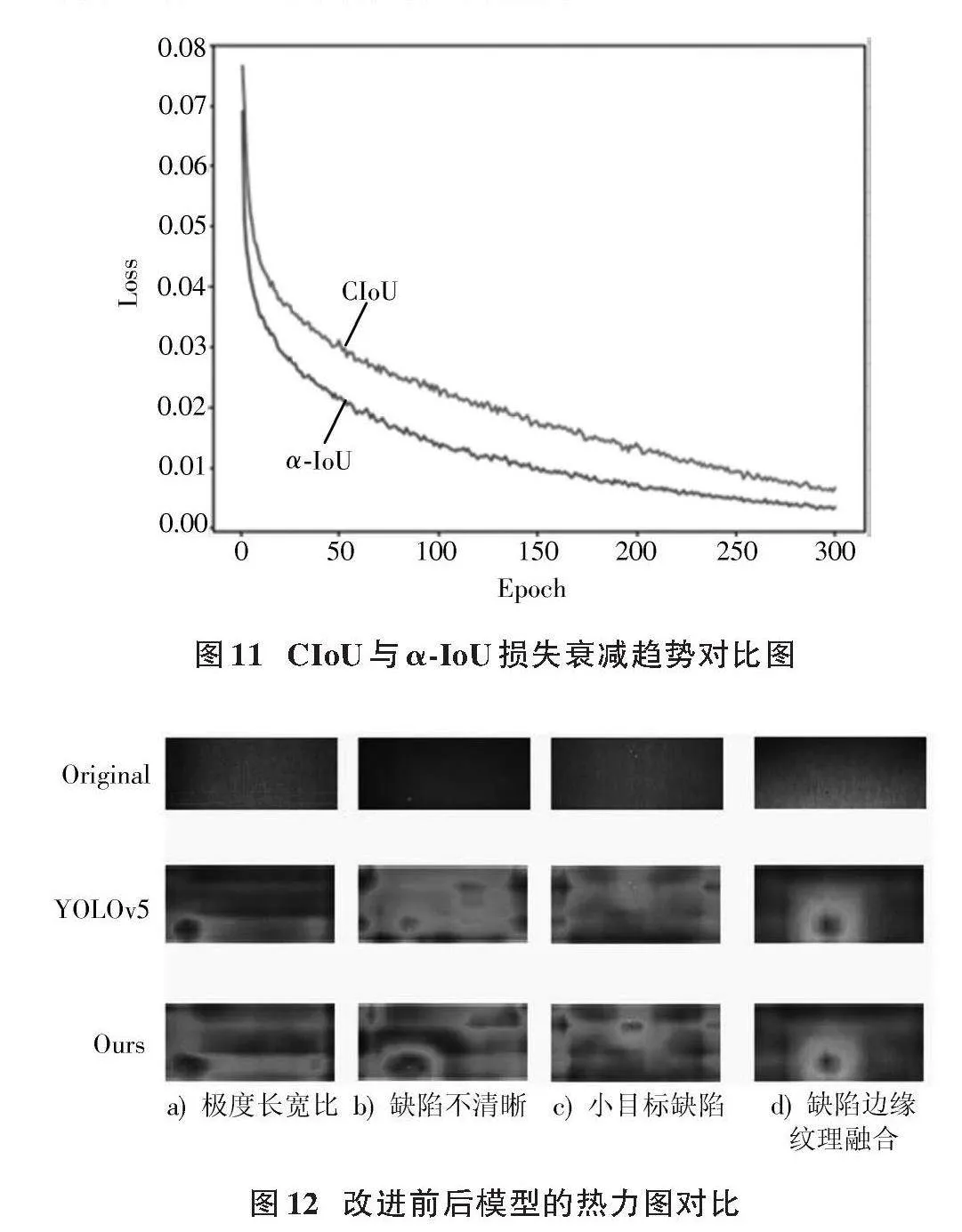
為驗證改進模型的優越性,進行了對比實驗。如圖9、圖10所示,改進模型在mAP@0.5和mAP@0.5:0.95上均優于原模型,精度高且波動小,訓練收斂更平滑。同時,α?IoU損失相較于CIoU損失下降更快,全程損失值更低,提升了訓練與推理效率。因此,引入α?IOU損失函數顯著提升了模型性能。CIoU與α?IoU損失衰減趨勢對比圖如圖11所示。
為直觀地評估改進模型對小目標缺陷及不清晰缺陷的檢測能力,引入熱力圖進行可視化對比。圖12展示了改進前后模型在檢測器上的缺陷定位熱力圖,灰色區域深淺反映定位準確度。通過對比,可評估模型改進對小目標及復雜背景下缺陷檢測的效果。在圖12a)中由于極度長寬比的缺陷對于普通缺陷有更大的尺度變換,模型沒有很好的泛化能力,改進前沒有很好地注意到缺陷整體,改進后的模型能夠更好地注意到缺陷整體。圖12b)中的缺陷不清晰,當在進行卷積操作時,原有模型由于不斷地下采樣導致模型丟失了特征信息,使得熱力圖呈現出散狀;改進后的模型由于加入了SPD?Conv,使得在卷積過程中能夠保留更多的信息,在改進后的熱力圖中模型對缺陷區域有了更多的關注。圖12c)為原有模型很難處理的小目標缺陷,小目標缺陷攜帶更少的信息使得模型無法采集足夠多的信息,模型無法對缺陷進行精準識別;在加入了SPD?Conv后模型能夠保留更多特征信息,并且加入了注意力機制后模型能夠更加關注缺陷本身。圖12d)中缺陷邊緣紋理產生融合,由于布匹缺陷通常與布匹紋理很相似,多數紋理會在邊緣部分與紋理產生融合,并且由于其攜帶信息很少導致原模型無法很好識別缺陷;在加入NAM注意力機制后,考慮到了權重影響,不僅加強了對于缺陷本身的關注,還減少了布匹缺陷附近的紋理影響,說明本文改進后的模型增強了對缺陷的檢測精度。
其次,由圖13的典型缺陷改進效果對比顯示,本文模型在解決缺陷與背景融合問題上有顯著優勢,能更準確地形成預測框。針對小目標缺陷,改進后模型有效減少了漏檢現象;對于極度長寬比缺陷,模型明顯改善了錯檢情況。特別在缺陷邊緣與周圍紋理易融合的場景中,本文模型能更好地處理缺陷與紋理關系,成功檢測出改進前模型的漏檢缺陷,展現出其優越性能。綜上所述,本文模型在處理小目標、極度長寬比及與背景融合的缺陷時均表現出良好的性能。
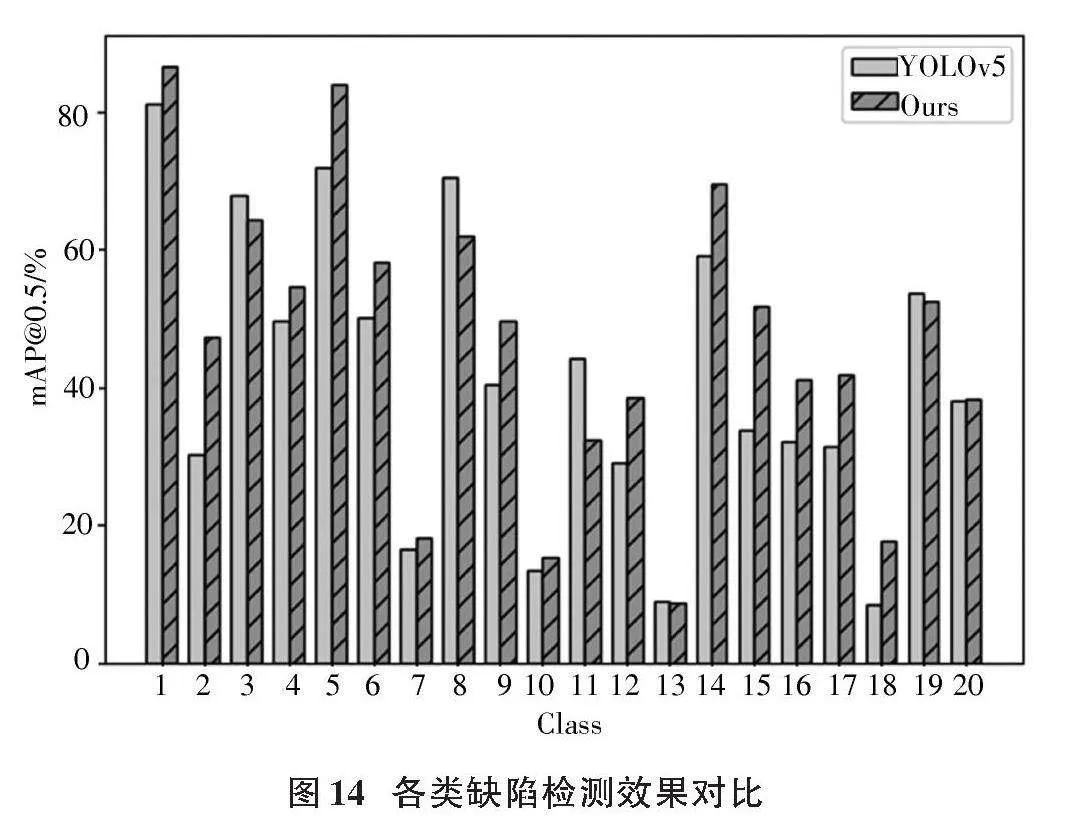
最后,直觀地展示了改進模型對20種缺陷的檢測效果,如圖14所示。
分析圖14可知,對于本數據集的20類缺陷(除無疵點),大部分類別的檢測精度在改進模型上實現顯著增長。特別是在花板跳、百腳、漿斑等小目標及背景融合缺陷上,改進效果尤為突出。這表明本文的改進模型對布匹缺陷檢測具有實質性提升,顯著增強了多分類布匹缺陷的檢測效果。
3.4.3" 主流檢測方法對比實驗
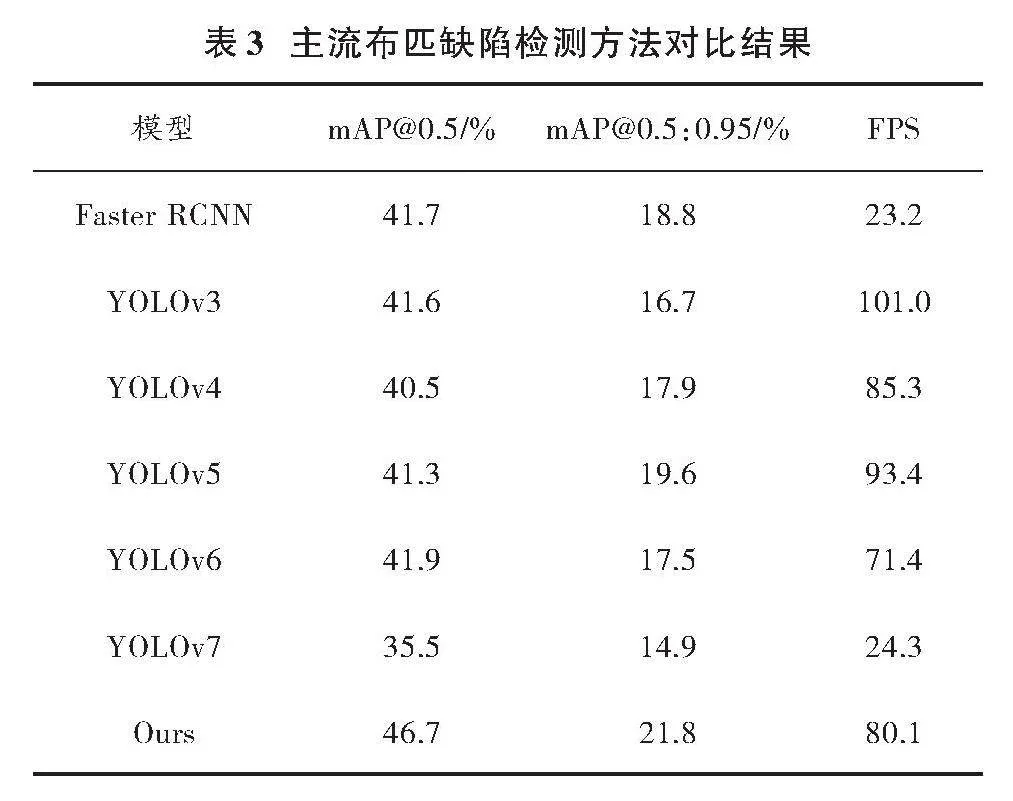
為驗證本文改進方法在織物缺陷檢測上的實際效果及優越性,選用經典檢測方法作為對比對象,整理成表3以供分析。
深入分析表3數據,改進方法在性能上較YOLOv5基準模型顯著提升,mAP@0.5和mAP@0.5:0.95分別高出5.4%和2.2%,在織物缺陷檢測中尤為突出。與其他模型相比,本文方法優勢顯著,mAP@0.5高出4.8%~11.2%,mAP@0.5:0.95高出2.2%~6.9%。盡管FPS值略有下降,但精度顯著增強,這一損失可接受。實際應用中,精度提升尤為重要。綜合比較,本文模型在精度指標上優于YOLOv3、YOLOv5、YOLOv6和YOLOv7等模型,對小目標和融合紋理缺陷檢測效果出色。
4" 結" 論
針對現階段小目標缺陷檢測及極度長寬比缺陷檢測的難點,尤其是在復雜布匹背景和低分辨率條件下,缺陷易與周圍紋理融合導致檢測困難的問題,本文提出了基于改進YOLOv5的布匹缺陷檢測方法。通過在主干網絡的C3模塊中引入NAM注意力機制,提升了模型對小目標缺陷的提取能力,有效解決了其與周圍紋理融合的問題。同時,引入了新的CNN模塊SPD?Conv,以解決布匹瑕疵較小或低分辨率情況下,因不斷下采樣導致的特征信息丟失和性能下降問題。此外,在檢測端采用了新的損失函數,在保持原有損失函數優點的同時,優化了極度長寬比缺陷的檢測,促進了模型擬合并提升了預測精度。實驗結果表明,本文提出的改進YOLOv5檢測方法在性能上明顯優于其他經典檢測方法。無論是mAP@0.5值還是mAP@0.5:0.95值,以及其他關鍵指標,本文方法均展現出更高的性能表現,相較于YOLOv5模型,mAP@0.5提升了5.4%,mAP@0.5:0.95提升了2.2%。該方法有效解決了缺陷紋理交織和特征信息丟失的問題,并成功完成了多分類缺陷檢測任務。
注:本文通訊作者為杜景林。
參考文獻
[1] 賈小軍,葉利華,鄧洪濤,等.基于卷積神經網絡的藍印花布紋樣基元分類[J].紡織學報,2020,41(1):110?117.
[2] WANG X B, FANG W J, XIANG S. Fabric defect detection based on anchor?free network [J]. Measurement science and technology, 2023, 34(12): 12.
[3] 張露,朱文俊,祝雙武.織物疵點自動檢測方法及應用進展[J].紡織科技進展,2022(2):21?26.
[4] HTET K S, SEIN M M. Event analysis for vehicle classification using fast RCNN [C]// 2020 IEEE 9th Global Conference on Consumer Electronics. Kobe, Japan: IEEE, 2020: 403?404.
[5] CAI Z, VASCONCELOS N. Cascade R?CNN: delving into high quality object detection [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 6154?6162.
[6] PRANGEMEIER T, REICH C, KOEPPL H. Attention?based transformers for instance segmentation of cells in microstructures [C]// 2020 IEEE International Conference on Bioinformatics and Biomedicine. Seoul, South Korea, 2020: 700?707.
[7] DING B Q, GUO J M, HU J H. Container number localization based on SSD algorithm [C]// 2019 34rd Youth Academic Annual Conference of Chinese Association of Automation. Jinzhou, China: ACM, 2019: 460?463.
[8] WANG Y Y, LI W D, LI X, et al. Ship detection by modified RetinaNet [C]// 2018 10th IAPR Workshop on Pattern Recognition in Remote Sensing. Beijing, China: IAPR, 2018: 1?5.
[9] SHI T C, NIU Y, LIU M Y, et al. Underwater dense targets detection and classification based on YOLOv3 [C]// 2019 IEEE International Conference on Robotics and Biomimetics. Dali, China: IEEE, 2019: 2595?2600.
[10] ZHENG L, WANG X, WANG Q, et al. Fabric defect detection method based on improved YOLOv5 [C]// 2021 7th International Conference on Computer and Communications. Chengdu, China: ICCC, 2021: 620?624.
[11] HONG X, WANG F, MA J. Improved YOLOv7 model for insulator surface defect detection [C]// 2022 IEEE 5th Advanced Information Management, Communicates, Electronic and Automation Control Conference. Chongqing, China: IEEE, 2022: 1667?1672.
[12] 陳康,朱威,任振峰,等.基于深度殘差網絡的布匹疵點檢測方法[J].小型微型計算機系統,2020,41(4):800?806.
[13] 周君,景軍鋒,張緩緩,等.基于S?YOLOV3模型的織物實時缺陷檢測算法[J].激光與光電子學進展,2020,57(16):55?63.
[14] YU W, LAI D, LIU H, et al. Research on CNN algorithm for monochromatic fabric defect detection [C]// 2021 6th International Conference on Image, Vision and Computing. Qingdao, China: IEEE, 2021: 20?25.
[15] 孫浩東,周其洪,陳鵬,等.基于改進YOLOv5s的經編織物缺陷檢測[J].棉紡織技術,2023,51(7):46?52.
[16] LIU Y C, SHAO Z R, TENG Y Y, et al. NAM: normalization?based attention module [EB/OL]. [2023?08?19]. https://www.xueshufan.com/publication/3215233137.
[17] RAJA S, TIE L. No more strided convolutions or pooling: a new CNN building block for low?resolution images and small objects [EB/OL]. [2023?07?14]. https://blog.csdn.net/bryant_meng/article/details/129682524.
[18] HE J B, ERFANI S, MA X J, et al. Alpha?IoU: a family of power intersection over union losses for bounding box regression [EB/OL]. [2023?11?09]. https://www.xueshufan.com/publication/3212339910.
[19] 趙磊,矯立寬,翟冉,等.基于YOLOv5的瓶蓋封裝缺陷輕量化檢測算法[J].激光與光電子學進展,2023,60(22):139?148.
[20] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. Pattern analysis amp; machine intelligence IEEE transactions on, 2015, 37(9): 1904?1916.
[21] ZHOU L, RAO X, LI Y, et al. A lightweight object detection method in aerial images based on dense feature fusion path aggregation network [J]. ISPRS international journal of geo?information, 2022, 11(3): 189.
[22] REZATOFIGHI H, TSOI N, GWAK J Y, et al. Generalized intersection over union: a metric and a loss for bounding box regression [EB/OL]. [2023?11?04]. https://ui.adsabs.harvard.edu/abs/2019arXiv190209630R/.
[23] ZHENG Z H, WANG P, REN D, et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation [J]. IEEE transactions on cybernetics, 2021, 52(8): 8574?8586.
[24] HU J, SHEN L, SUN G, et al. Squeeze?and?excitation networks [J]. IEEE transactions on pattern analysis and machine intelligence, 2020, 42(8): 2011?2023.
[25] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision. [S.l.]: IEEE, 2018: 3?19.
[26] HOU Q B, ZHOU D Q, FENG J S. Coordinate attention for efficient mobile network design [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA: IEEE, 2021: 13713?13722.
[27] WANG Q, WU B, ZHU P, et al. ECA?Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Seattle, WA, USA: IEEE, 2020: 11531?11539.
作者簡介:張凱旋(2000—),男,江蘇淮安人,碩士研究生,主要研究方向為目標檢測、疵點檢測。
杜景林(1976—),男,河北承德人,博士研究生,副教授,碩士生導師,主要從事氣象大數據、物聯網方面的研究。
DOI:10.16652/j.issn.1004?373x.2024.20.017
引用格式:張凱旋,杜景林.改進YOLOv5的布匹缺陷檢測方法[J].現代電子技術,2024,47(20):109?117.
收稿日期:2024?04?26" " " " " "修回日期:2024?05?28
基金項目:國家自然科學基金資助項目(41575155)
