基于特征和語義的電網設備技術標準差異分析方法研究
2024-10-21 00:00:00王瑞杰王倩王軍袁葆玄鑫鄭倩
標準科學 2024年13期
摘 要:針對電網設備技術標準條款內容存在差異問題,提出了一種基于特征和語義的電網設備技術標準差異分析方法。該方法通過條款特征提取、特征語義分析、特征權重評定和條款差異分析4個環節,有效解決傳統文本相似度計算方法適用性不足的問題。進一步對電網設備技術標準條款結構化,分析挖掘條款間存在的差異情況。通過真實標準條款進行實驗,將本文方法同其他算法比較,結果表明本文所提方法在相似度計算方面優于其他參與比較算法,并能指出條款的差異情況。
關鍵詞:電網設備,技術標準,相似度,差異分析
0 引 言
標準被定義為可用于通過提供特性、指南、規范或要求來確保產品、流程、服務和材料適合其目的的文件(國際標準化組織,2017)。目前,電網設備技術標準條款內容存在差異,利用NLP(Natural Language Processing,自然語言處理)等處理電力行業的標準差異條款問題尚不成熟,NLP是將人類間交流溝通轉化為機器語言,目的是實現人機交互[1-2]。基于詞嵌入、深度學習和無監督學習與遷移學習和語言模型與機制等關鍵技術,自然語言處理實現了中文分析、語義分析和命名實體識別、構建知識圖譜和信息檢索等功能。目前,國家越發重視自然語言處理、大模型等人工智能技術,因此,對自然語言處理進行深入研究具有重要作用。
語義相似度指的是詞義之間的相似程度,由語義距離和語義相關性決定。影響語義相似度的因素有語義關系、語義距離、調節參數和節點深度。近年來,語義相似度已經成為自然語言處理中的重要研究方向,并且在眾多場景如智能問答、實體消歧[3]、輿情分析、情感分析[4]都應用廣泛。文本相似度是通過其內容屬性及非內容屬性確定相似程度[5]。文本相似度計算是通過將文本轉化為特征向量,通過對比兩個文本的向量值來判斷其相似度[6]。文本相似度計算應用于文本查重、文本分類檢索[7],智能推薦系統[8]等多方面,同時,在電力智能交互平臺上,系統可以根據用戶提問,通過自然語言處理快速檢索,將結果反饋給用戶[9]。
1 文本相似度
文本相似度從文本的長短程度可以分為長文本相似度和短文本相似度。早期對文本相似度的研究主要是通過關鍵詞匹配來實現,而忽略了語義的重要性。文本相似度對于文本分類、詞義消歧、關系抽取等方面具有至關重要的作用。隨著大模型等人工智能技術的發展,目前,主要有兩種主要的文本相似度研究方向。
基于詞頻的文本相似度算法是通過比較文本中詞語的相似性來判斷其相似程度,如:TF-IDF(Term Frequency-Inverse Document Frequency)[9],它通過詞頻來區分與其他文檔的特征。最長公共子序列(LCS)算法[10]是通過查找文本間的最長公共序列來計算文本相似度。SimHash[11]提出了一種新的局部敏感哈希算法,通過哈希函數將文本轉化為向量,進而通過計算兩個向量之間的余弦來評估相似度。俞婷婷提出一種基于改進的Jaccard系數文檔相似度計算方法,該方法主要考慮詞在文檔中所占比例來計算文本相似度[12]。
基于深度學習的文本相似度算法研究主要有無監督學習和有監督學習兩種方法。google在2013年提出word2vec,通過windows窗口的移動來獲取詞的上下文關系,從而將詞轉化為向量。Huang[13]等提出一種深度學習模型,該模型將高緯度向量轉到低維度向量,然后通過兩個低緯度向量的余弦值來計算短文本相似度,同時,還使用了單詞哈希的技術擴大了深度語義模型,以便于處理大規模的數據。Shen等人[14]提出了CLSM(Convolutional LatentSemantic Model),該模型從每個詞開始通過卷積層來獲取上下文關系以降低維度,用于搜索查詢和Web文檔的語義向量表示。ReimersN等人[15]提出了S-BERT模型,該模型基于BERT模型,通過兩個編碼解碼的雙塔網絡來實現文本相似度的計算。盧美情[16]提出一種基于SBERT的文本匹配改進模型SBMAA。該模型首先利用SBERT實現文本的向量化表示,同時,引入多頭注意力的對齊,增加句向量交互,并通過拼接融合層來獲取交互信息的能力。實驗表明,提出的SBMAA模型能夠有效提升文本匹配的效果,且具有一定的魯棒性。目前,針對電網設備技術標準條款內容存在差異問題,本文提出一種基于特征和語義的電網設備技術標準條款差異分析方法。
2 基于特征和語義的標準條款差異分析方法
基于特征和語義的電網設備技術標準條款差異分析方法包含4方面內容:條款特征提取、特征語義分析、特征權重評定、條款差異分析。
2.1 條款特征提取
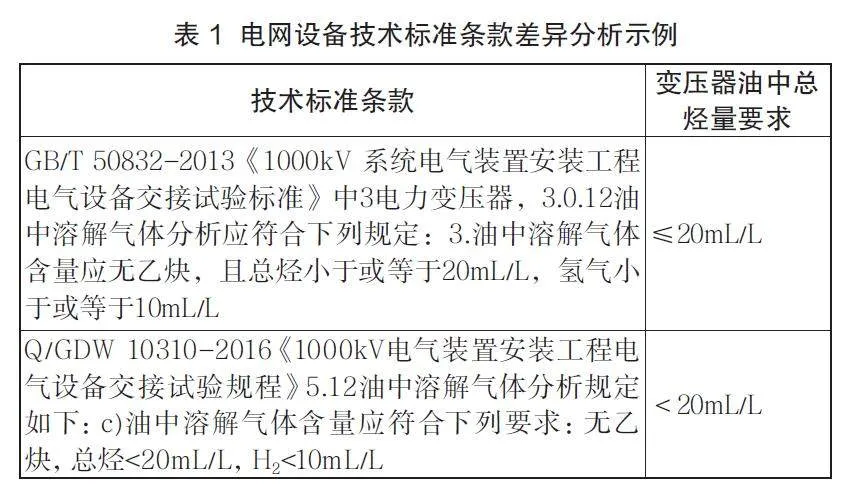
在電力行業技術標準條款中,實體詞語和語義是選擇特征詞的兩個主要依據。傳統通過詞頻、語義等方法選擇文本關鍵詞,容易遺漏數量較少的核心關鍵詞。在此,以電網設備技術標準條款為例來說明此問題,“GB/T 50832-2013《1000kV 系統電氣裝置安裝工程電氣設備交接試驗標準》中3電力變壓器,3.0.12 油中溶解氣體分析應符合下列規定:3.油中溶解氣體含量應無乙炔,且總烴小于或等于20mL/L,氫氣小于或等于10mL/L。”“電力變壓器”作為核心關鍵詞,在本條條款中僅出現1次。因此,本文方法基于HanLP中文分詞、命名實體識別和電網設備專業詞庫從條款文本中提取特征詞。
從電網設備技術標準中拆解的條款記作c,第i個條款記作ci。從標準條款ci中提取的實體、屬性等內容作為特征詞fj(j=1,2,…,l),形成特征詞集合Ai,即Ai={f1,f2,…,fl}。例如:示例條款提取的特征詞集合A={電力變壓器,油,溶解氣體,乙炔,氧氣…}。
2.2 特征語義分析
為了解決特征詞一義多詞問題,確定實體、屬性和屬性值之間的關系,采用語義理解技術開展特征詞標準化處理和條款內容深入分析。
特征詞標準化處理。本方法采用電網設備專業詞庫與歐氏距離結合的方式開展特征詞標準化處理,若在電網設備專業詞庫中明確指出該特征詞不是標準詞語,則以詞庫中的標準化特征詞進行替換;若在電網設備專業詞庫中未找到類似詞語,則將該特征詞作為標準詞語,并補充進專業詞庫。
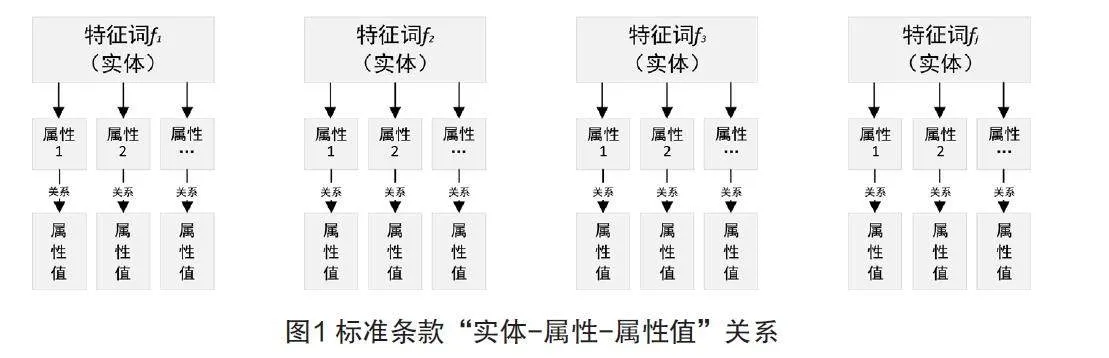
標準條款內容深入分析。基于HanLP詞性標注對標準條款內容進行深入分析,挖掘條款中存在的“實體-屬性-屬性值”關系,如圖1所示。
2.3 特征權重評定
本文方法結合電網設備圖譜網絡拓撲和特征詞位置計算特征詞權重。
定義1 特征詞fj在電網設備網絡拓撲中距離根節點的最短距離記作Dfj。
定義2 特征詞fj在標準條款中的位置記作Pfj。若特征詞fj從技術標準的標題中提取,則Pfj=1;若特征詞i從技術標準的非標題中提取,則Pfj=2。
根據定義1、定義2,特征詞 的權重按式(1)計算:
ωi=α×Dfj+β×Pfj(1)
其中,α和β為常數,分別表示Dfj和Pfj的占比;特征詞i的權重值ωi越小,代表特征詞越重要。
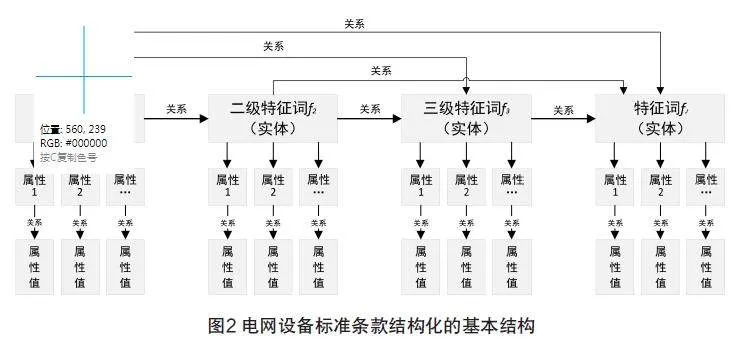
按照權重值自小向大調整特征詞順序,形成電網設備技術標準條款結構化的基本結構,如圖2所示。
2.4 條款差異分析
在分析標準條款cm和 cn的差異情況時,首先提取兩個條款的特征向量集合Am={ f1,f2,… ,fp}和An={ f1,f2,… ,fq};其次,通過特征語義分析和特征權重評定兩個環節,對特征詞標準化處理、“實體-屬性-屬性值”關系挖掘和特征詞順序調整;再次,比較兩個條款的相應特征詞內容,按式(2)計算兩個條款的相似度Simmn;最后,通過比較對應特征詞的屬性和屬性值,分析標準條款cm和cn的差異性,尤其是屬性值的差異情況。
Sim mn=t/min(p,q)(2)
其中,p為標準條款cm提取出的特征詞數量,q為標準條款cn提取出的特征詞數量,min(p,q)為p和q中的最小值,t為標準條款cm和cn中相同特征詞的數量。
3 實驗與分析
3.1 實驗環境
本文實驗硬件的CPU為Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz 1.80 GHz,內存為16GB,操作系統為Windows 10(64bit)。算法研發語言為python(Python 3.11),研發平臺為PyCharm。
3.2 實驗數據
從《電網設備技術標準差異條款統一意見》中隨機抽取10組存在差異的條款內容。為了實驗方便,條款內容統一按照文本方式編排。
3.3 實驗結果
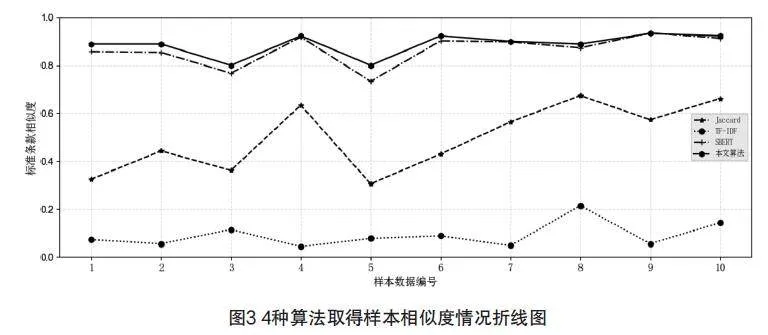
在本文算法實驗中,3.4節所提供兩個條款相似度Simmn計算公式中α和β分別為0.6和0.4。同時,選取Jaccard、TF-IDF、SBERT等3個算法進行實驗,并對實驗結果進行比較。為了使實驗結果更直觀,將4種算法計算10組樣本相似度情況繪制折線圖,如圖3所示。
3.4 結果分析
從圖3中可以看出,在計算電網設備技術標準條款相似度方面,Jaccard和TF-IDF 算法計算結果不理想,本文算法和SBERT算法遠優于其他兩種算法,本文在相似度上又有所提升,有利于發現相似條款內容。同時,本文算法可準確發現條款間存在的差異性,例如可準確發現變壓器油中總烴量要求存在的差異性,如表1所示。
4 結 語
本文提出的基于特征和語義的標準條款差異分析方法,從條款特征提取、特征語義分析、特征權重評定、條款差異分析4個方面開展相關工作。通過真實電網設備技術標準條款進行實驗,結果表明本文方法在標準條款相似度計算和條款差異情況分析方面優于Jaccard、TF-IDF、SBERT算法。但是,本文方法未考慮到標準中表格數據,仍需進一步優化完善。
參考文獻
[1]趙京勝,宋夢雪,高祥.自然語言處理發展及應用綜述[J].信息技術與信息化,2019(07):142-145.
[2]高源.自然語言處理發展與應用概述[ J ] .中國新通信,2019,21(02):117-118.
[3]Attardi G , Rossi S D , Simi M .TANL-1: coreference resolutionby parse analysis and similarity clustering[J].proceedings ofinternational workshop on semantic evaluation, 2010.
[4]蔣昊達, 趙春蕾, 陳瀚, 等. 基于改進T F - I D F 與B E R T 的領域情感詞典構建方法[ J ] . 計算機科學,2024,51(S1):162-170.
[5]Wang J , Dong Y .Measurement of Text Similarity: ASurvey[J].Information (Switzerland), 2020, 11(9):421.DOI:10.3390/info11090421.
[6]胡澤文,王效岳,白如江.國內外文本分類研究計量分析與綜述[J].圖書情報工作,2011,55(06):78-81+142.
[7]張娜娜.基于機器學習的智能推薦系統設計與優化研究[J].家電維修,2024(01):37-39.
[8]荊江平,智明,楊飛,等. 基于數據分析的新型電力系統電力智能交互平臺的短文本相似性研究與應用[J/OL].電測與儀表,1-7[2 0 2 4 - 0 8-16 ].ht t ps: // knscnki-net.webvpn.ncepu.edu.cn/kcms/detail/23.1202.TH.20240429.1847.005.html.
[9]Ramos J .Using TF-IDF to Determine Word Relevance in Document Queries[J]. 2003.DOI:doi:http://dx.doi.org/.
[10]Ch vát a l , Va c láv, S a n k o f f D . L o n g e s t c o m m o nsubsequences of two random sequences[J].Journal ofApplied Probability, 1975, 12(02):306-315.DOI:10.1017/s0021900200047999.
[11]Charikar, Moses S .Similarity estimation techniquesfrom rounding algorithms[C]//Applied and ComputationalH a r m o n i c A n a l y s i s . A C M , 2 0 0 2 : 3 8 0 - 3 8 8 .DOI:10.1145/509907.509965.
[12]俞婷婷,徐彭娜,江育娥,等.基于改進的Jaccard系數文檔相似度計算方法[J].計算機系統應用,2017,26(12):137-142.DOI:10.15888/j.cnki.csa.006123.
[13]Huang P S , He X , Gao J ,et al.Learning deep structured semantic models for web search using clickthroughdata[C]//Conference on Information and Knowledge?GjRsYOnVBa/br+cqwUEtoArBW0JOzw5CjOXpRe37SRs=;Management.ACM, 2013.DOI:10.1145/2505515.2505665.
[14]Shen Y , He X , Gao J ,et al.A Latent Semantic Modelwith Convolutional-Pooling Structure for InformationRetrieval[C]//Conference on Information and KnowledgeManagement.ACM, 2014.DOI:10.1145/2661829.2661935.
[15]Reimers N , Gurevych I .Sentence-BERT: SentenceEmbeddings using S iamese B ERT-Networks[J]. 2019.DOI:10.18653/v1/D19-1410.
[16]盧美情,申妍燕.一種基于孿生網絡預訓練語言模型的文本匹配方法研究[J].集成技術,2023,12(02):53-63.
