基于用戶行為數據的學術用戶畫像構建方法研究
2024-10-22 00:00:00張良肖銀濤
現代信息科技 2024年15期




摘 要:闡述了一種基于用戶行為數據的學術用戶畫像構建方法,包括標記用戶行為數據并按照三個維度標記用戶身份;收集、清洗用戶行為數據、用戶訪問過的學術資源的特征信息;構建用戶興趣領域和每個興趣領域的關鍵詞向量表達;結合用戶賬號相關信息構建學術用戶畫像。能夠基于用戶IP、賬號、終端標識三個維度的歷史行為數據,通過挖掘分析相關學術資源特征信息,構建學術用戶畫像。其中基于終端的學術用戶畫像不依賴于用戶賬號體系,為后續的機構讀者個性化知識推薦服務提供支撐。
關鍵詞:用戶畫像;個性化推薦;知識服務;學術資源;用戶行為
中圖分類號:TP391.1 文獻標識碼:A 文章編號:2096-4706(2024)15-0119-05
Research on the Construction Method of Academic User Profile Based on
User Behavior Data
ZHANG Liang, XIAO Yintao
(Tongfang Knowledge Network Digital Publishing Technology Co., Ltd., Beijing 100192, China)
Abstract: This paper elaborates a method for constructing academic user profiles based on user behavior data, including labeling user behavior data and labeling user identity according to three dimensions. It collects and clean user behavior data and characteristic information of academic resources accessed by users, constructs vector representations of user interest domains and key words of each interest domain, and constructs an academic user profile based on user account related information. Based on historical behavioral data from three dimensions of user IP, account, and terminal identification, academic user profiles can be constructed by mining and analyzing relevant academic resource characteristic information. The academic user profile based on terminals does not rely on the user account system, providing support for personalized knowledge recommendation services for institutional readers in the future.
Keywords: user profile; personalized recommendation; knowledge service; academic resource; user behavior
0 引 言
20世紀90年代,庫帕[1]提出用戶畫像的概念,用戶畫像是對用戶各種行為、特征的總結,是建立在用戶數據基礎之上的模型,通過收集用戶的社會屬性、消費習慣、偏好特征等各個維度的數據,對用戶或產品特征屬性進行刻畫,并對這些特征進行分析、統計,挖掘潛在價值信息,從而抽象出用戶的信息全貌[2]。用戶畫像技術的本質工作就是用戶信息標簽化[3]。
用戶畫像可看作應用大數據的根基,是個性化推薦的前置條件,為數據驅動運營奠定了基礎[2]。國內學者引入用戶畫像的思想或方法[4-5],廣泛應用于電子商務、公共圖書館和衛生健康等領域[6-8]。在用戶畫像的設計與構建方法上,陳晶等[9]提出了基于聯邦學習的多源數據用戶畫像設計方案,利用聯邦學習的計算機制和隱私求交算法實現了多源數據共享。房志明等[10]利用用戶的靜態屬性和動態屬性進行評審專家畫像建模。吳迪等[11]提出一種微博用戶行為影響力計算方法,構建熱點話題下的用戶畫像。李帥等[12]提出一種基于實時用戶畫像的軍事情報推薦技術。該技術通過收集用戶的自然標簽和行為標簽等信息,并結合時間上下文,生成動態實時用戶畫像。
用戶畫像已得到部分學者的關注,但鮮少有針對學術用戶畫像的領域細分研究。如何構建學術用戶畫像,動態地將個體讀者多個興趣領域與學術資源分類體系深度結合并表達出來,是學術類數字資源提供者為讀者提供精準個性化知識服務的前提。本文所述數據來源于知網學術資源和用戶行為數據,提出一種基于用戶行為數據的學術用戶畫像構建方案,能夠基于用戶IP、賬號、終端標識三個維度的歷史行為數據,通過挖掘分析相關學術資源特征信息,構建學術用戶畫像。
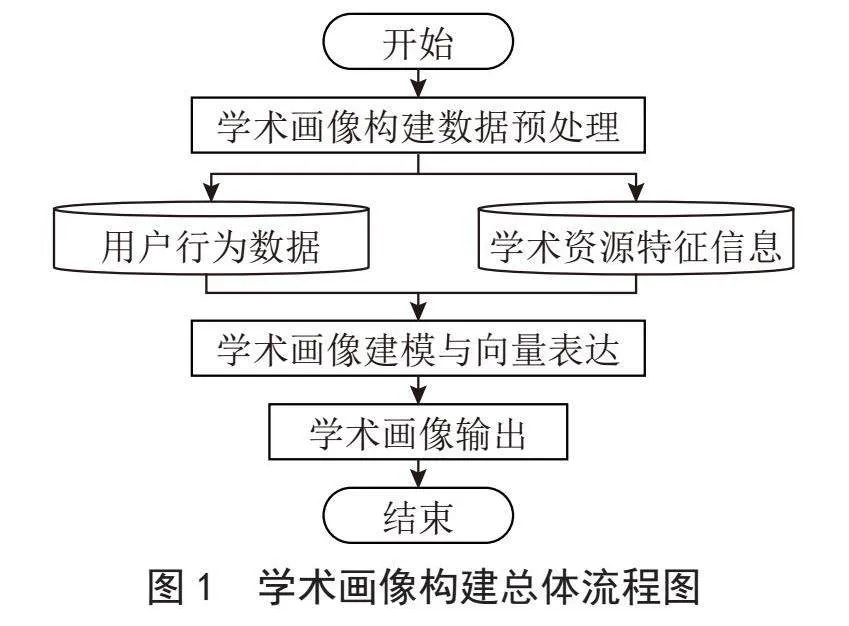
1 學術畫像構建總體流程
學術畫像構建方案總體分為數據預處理、畫像建模與向量表達、畫像輸出三個模塊。其中,數據預處理模塊負責標記用戶身份,收集、清洗用戶行為數據和用戶訪問過的學術資源,輸出規范化的用戶行為數據和學術資源特征信息。畫像建模與向量表達模塊利用數據預處理模塊產生的數據構建用戶興趣領域和每個興趣領域的關鍵詞向量表達,需綜合考慮用戶行為類型、行為時間、資源特征等多個因素。畫像數據模塊結合用戶單位、學歷、研究領域等基本信息,以JSON格式描述用戶畫像。總體流程如圖1所示。
2 學術畫像構建數據預處理
2.1 標記用戶行為數據并從三個維度標記用戶身份
業務系統記錄用戶登錄、檢索、瀏覽、收藏、關注、在線閱讀及下載的行為日志,內容包括用戶IP、賬號、終端標識、操作時間、檢索詞、瀏覽或下載的文獻等字段信息,如表1所示。其中,IP是用戶產生行為時的終端設備IP;賬號是用戶產生行為時使用的賬號,匿名操作時記錄匿名賬號標識;終端標識是用戶產生行為時的終端設備標識,是系統為每一個終端設備生成存儲在終端設備中的ID,當新的終端訪問系統時,由系統自動生成并存儲在終端設備中。
通過用戶IP、賬號、終端標識三個維度的標記以及行為分析對常用賬號和常用終端建立關聯,可以在用戶未登錄、登錄個人賬號、登錄機構賬號等多種使用場景下記錄用戶行為數據。在確保讀者數據和隱私安全的前提下,用戶行為數據成為構建讀者學術用戶畫像的重要依據。
具體步驟包括:
1)在用戶產生行為時記錄用戶的IP。
2)在用戶產生行為時,判斷用戶是否是登錄狀態,如果是,記錄用戶賬號;如果未登錄,記錄匿名賬號標識。
3)在用戶產生行為時記錄用戶的終端標識。從用戶終端設備中獲取用戶終端標識時,若不存在,系統生成終端標識并存儲在終端設備中;若存在,則直接獲取使用。
4)若同一賬號在同一終端多次使用,則認為該終端是用戶的常用設備,為用戶建立賬號和設備之間的關聯關系。在后續收集、清洗用戶行為數據時,終端設備上產生的行為數據,在匿名狀態下也能選擇性地視為關聯賬號的行為數據。
2.2 收集、清洗用戶行為數據
收集用戶行為數據的內容包括線下定時從業務系統收集的用戶行為數據以及線上通過分布式消息系統收集的在線用戶即時產生的行為數據。所述用戶行為數據主要包括登錄、檢索、瀏覽、收藏、關注、在線閱讀及下載的操作日志,主要數據字段包括用戶IP、賬號、終端標識、操作時間、檢索詞、瀏覽或下載的文獻ID等。為保證數據一致性、刪除重復信息、糾正存在的錯誤,對所收集的行為數據進行數據清洗。主要是根據每個變量的合理取值范圍和相互關系對數據進行一致性檢查,去除有缺失或格式錯誤的數據,去除有邏輯錯誤和不需要的數據,對短時高頻行為進行過濾或采樣(例如,按照國際在線電子資源使用統計標準COUNTER的規定,對同一個會話30秒內的重復行為數據進行去重[13]),對用戶敏感信息進行脫敏等處理,確保數據的有效性,確保用戶隱私安全。
2.3 收集、清洗用戶訪問過的學術資源的特征信息
用戶行為數據包含用戶瀏覽、下載、閱讀、收藏、關注的文獻ID。系統根據這些文獻ID從學術資源題錄庫中檢索獲取相關的資源特征信息,這些特征信息已經過預處理,具體包括篇名、作者、單位、所屬學科、所屬刊物、關鍵詞、機標關鍵詞、描述文獻的VSM向量信息、期刊指數、機構指數、作者指數、被引量、被下載量、頁數等。其中,文獻的VSM向量信息是通過TF-IDF算法把一篇文章抽象成一個多維向量,每一個維度的向量由特征詞和權重組成,權重結合了詞頻TF和逆文檔頻率IDF,代表了該詞在文章中的重要程度,排在前列的即為本文的關鍵詞。
3 學術畫像建模與向量表達
3.1 構建用戶興趣領域的向量表達
從用戶IP、賬號、終端標識三個維度分析如何構建用戶興趣領域的向量表達。該向量表達兼顧用戶的長期興趣和短期興趣,具備明顯的學術化特征。綜合考慮用戶行為類型、行為時間、資源特征等多個因素,對不同特征賦予不同權重,通過聚類分析或分類算法分析,對用戶興趣進行動態、多領域、定量的描述。
具體步驟包括:
1)收集該用戶近期的行為數據以及相關文獻的資源特征信息。獲取該用戶最近N天瀏覽、下載、閱讀、收藏、關注的行為數據,根據行為數據涉及的文獻信息,獲取相關的資源特征信息。
2)構建該用戶使用文獻與興趣領域的關系列表。用戶最終的興趣領域使用學術文獻的學科分類體系表達。分類體系可以是中圖分類法,也可以是其他學科分類體系。收集、清洗文獻與所屬學科的關系數據,針對用戶使用文獻所屬學科數據可能存在重復或錯誤的“臟數據”情況,進行去重和數據一致性檢查。文獻對興趣領域的貢獻值與該文獻的被引量、被下載量、期刊指數、機構指數、作者指數以及文獻的頁數有關系。計算式如下:
其中,C(i)表示第i篇文獻對所屬學科的貢獻值;K1、K2表示調節參數,一般K1 = 0.9,K2 = 0,n表示文獻所屬學科的數量;文獻屬于多個學科分類時,文獻的貢獻值要平均分配到各個所屬學科分類中。M表示影響貢獻值因素的數量,這里包括被引量、被下載量、期刊指數、機構指數、作者指數以及文獻的頁數,因此m = 6。α表示各因素的影響系數,可結合具體的影響因素和資源類型進行設定。F(i, j)表示第i篇文獻從學術資源題錄庫中獲取的被引量、被下載量、期刊指數、機構指數、作者指數以及文獻頁數中的第j個影響因素。
構建完的用戶使用文獻與興趣領域的關系列表包含行為類型、文獻、所屬學科、貢獻值、行為時間。其中,行為類型就是瀏覽、下載、閱讀、收藏、關注;文獻有多個所屬學科時,應存儲多行,確保每行記錄的所屬學科只有一個值。
3)計算該用戶使用過的文獻在興趣領域中的權重,構建用戶興趣領域文獻權重列表。在用戶使用文獻與興趣領域的關系列表中,影響權重的因素包括行為類型、行為時間、貢獻值。根據用戶的行為時間和操作類型進行時間衰減和行為加權。時間衰減規則是,越早的行為權重越低,越新的行為權重越高。行為加權的規則是下載、關注、收藏、瀏覽。計算式如下:
其中,FW(i)表示列表第i條記錄中的文獻在對應興趣領域中的權重;T(i)表示第i條記錄的行為時間;T1表示列表中的最早行為時間;T2表示列表中的最新行為時間;S(i)表示行為類型的評分值,按照下載、關注、收藏、瀏覽設定;C(i)表示文獻對所屬學科的貢獻值。計算后,用戶使用文獻與興趣領域的關系列表增加了文獻權重一列,構成用戶興趣領域文獻權重列表,包括行為類型、文獻、所屬學科、貢獻值、行為時間、文獻權重。
4)計算該用戶各興趣領域權重。對用戶興趣領域文獻權重列表進行分析,使用所屬學科維度進行聚類,得到每個所屬學科的權重匯總:
其中,DW( j)表示該用戶第j個興趣領域的權重匯總;FW( j)表示該用戶第j個興趣領域下n篇文獻中第i個文獻的權重值。
5)對該用戶所有興趣領域的權重進行歸一化處理、降序排列后,得到最終的用戶興趣領域的向量表達。
3.2 構建用戶每個興趣領域的關鍵詞向量表達
根據用戶興趣領域文獻權重列表,從學術資源題錄庫中提取相關學術資源的特征信息,構建用戶興趣領域關鍵詞權重列表;從賬號信息庫中提取用戶編輯的興趣領域、興趣詞,從行為數據中提取用戶近期使用的檢索詞信息,補充完善用戶興趣領域關鍵詞權重列表;根據業務處理關鍵詞重復的記錄,最終得到用戶該興趣領域的關鍵詞向量表達。
具體步驟包括:
1)根據用戶興趣領域文獻權重列表,提取相關文獻的資源特征信息。提取后的數據包含行為類型、文獻、所屬學科、貢獻值、行為時間、文獻權重、所屬刊物、關鍵詞、機標關鍵詞、描述文獻的VSM向量信息、期刊指數、機構指數及作者指數。
2)構建用戶興趣領域關鍵詞權重列表。根據用戶興趣領域涉及的文獻,提取關鍵詞信息并計算權重值,構建用戶興趣領域關鍵詞權重列表。關鍵詞主要來源于描述文獻的VSM向量信息,沒有該字段的文獻則使用關鍵詞或機標關鍵詞來替代。為了描述關鍵詞在用戶興趣領域的重要程度,每個關鍵詞需要設置一個權重值。因為VSM向量中關鍵詞的權重值指的是該詞在這篇文獻中的重要程度,不能直接拿來描述關鍵詞在用戶興趣領域中的權重。此處,我們將用戶興趣領域文獻權重列表中文獻的權重值按照VSM向量中關鍵詞權重的比例進行分配。這樣既考慮了單篇文獻對用戶興趣領域影響的最大值,又兼顧了文獻中關鍵詞重要程度的區分。用戶興趣領域關鍵詞的權重值計算式如下:
其中,DWW(i)表示用戶某個興趣領域第i個關鍵詞的權重;FWW(j)表示用戶某個興趣領域n篇文獻中第j篇文獻的VSM向量中對應關鍵詞的權重值; 表示用戶某個興趣領域中第j篇文獻VSM向量中所有m個詞權重的累加值;FW(j)表示用戶某個興趣領域中第j篇文獻的權重。
經過該步驟處理后,將得到用戶興趣領域關鍵詞列表,包含用戶興趣領域、興趣領域權重、關鍵詞、關鍵詞權重。
3)補充完善用戶興趣領域關鍵詞權重列表。補充關鍵詞是為了更準確地描述用戶的興趣領域。主要是通過用戶輸入的檢索詞或主動編輯興趣詞來實現。用戶輸入的檢索詞,可根據用戶檢索后訪問的文獻所屬分類確定檢索詞所屬的用戶興趣領域;權重值可參考該興趣領域關鍵詞的權重值進行設置,無論與已有關鍵詞重復與否,均應將該檢索詞賦以較高的權重值,比如前5位。系統提2sMtV5UWqc+SfDCCtXzBHSyh7RXScdp3/MNz1DAUFJ4=供用戶主動編輯興趣詞的功能,用戶輸入的興趣詞將取代原興趣詞,權重值不變。刪除權重值較低的重復詞。
4)處理用戶興趣領域關鍵詞權重列表中重復的關鍵詞。從學術用戶畫像整體描述考慮,重復的關鍵詞是冗余的,應該進行排重處理;但從用戶興趣領域描述來考慮,則不應進行排重處理。因此,該步驟可根據應用場景做選擇性處理。處理方法是根據用戶興趣領域的關鍵詞權重列表,對于重復的關鍵詞信息,保留關鍵詞權重高的記錄;權重值相同時保留興趣領域權重較高的記錄。
5)對用戶每個興趣領域的關鍵詞權重進行歸一化處理、降序排列后得到用戶該興趣領域的關鍵詞向量表達。
4 學術畫像輸出
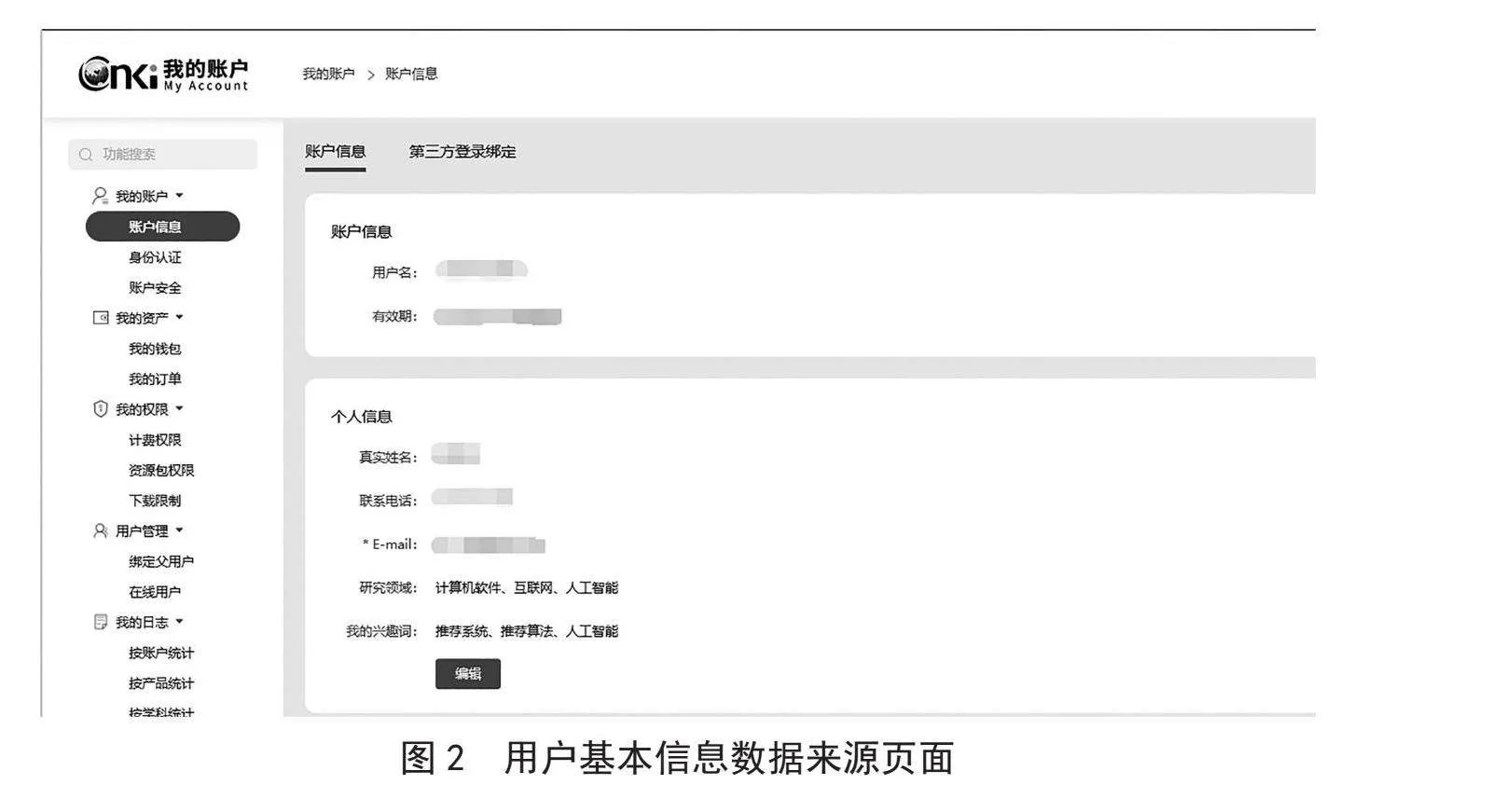
學術畫像輸出以JSON格式描述,可直接應用于產品或為推薦系統提供基礎數據支撐。學術畫像主要是對用戶興趣領域及權重、興趣詞及權重的描述,另外也對用戶基本信息(如用戶標識、研究領域、我的興趣詞等)的描述做了定義,形成一個完整的學術用戶畫像體系。其中,用戶基本信息數據來源于用戶在知網“我的賬戶”產品中自填的信息,如圖2所示。學術畫像的JSON格式表達如圖3所示。
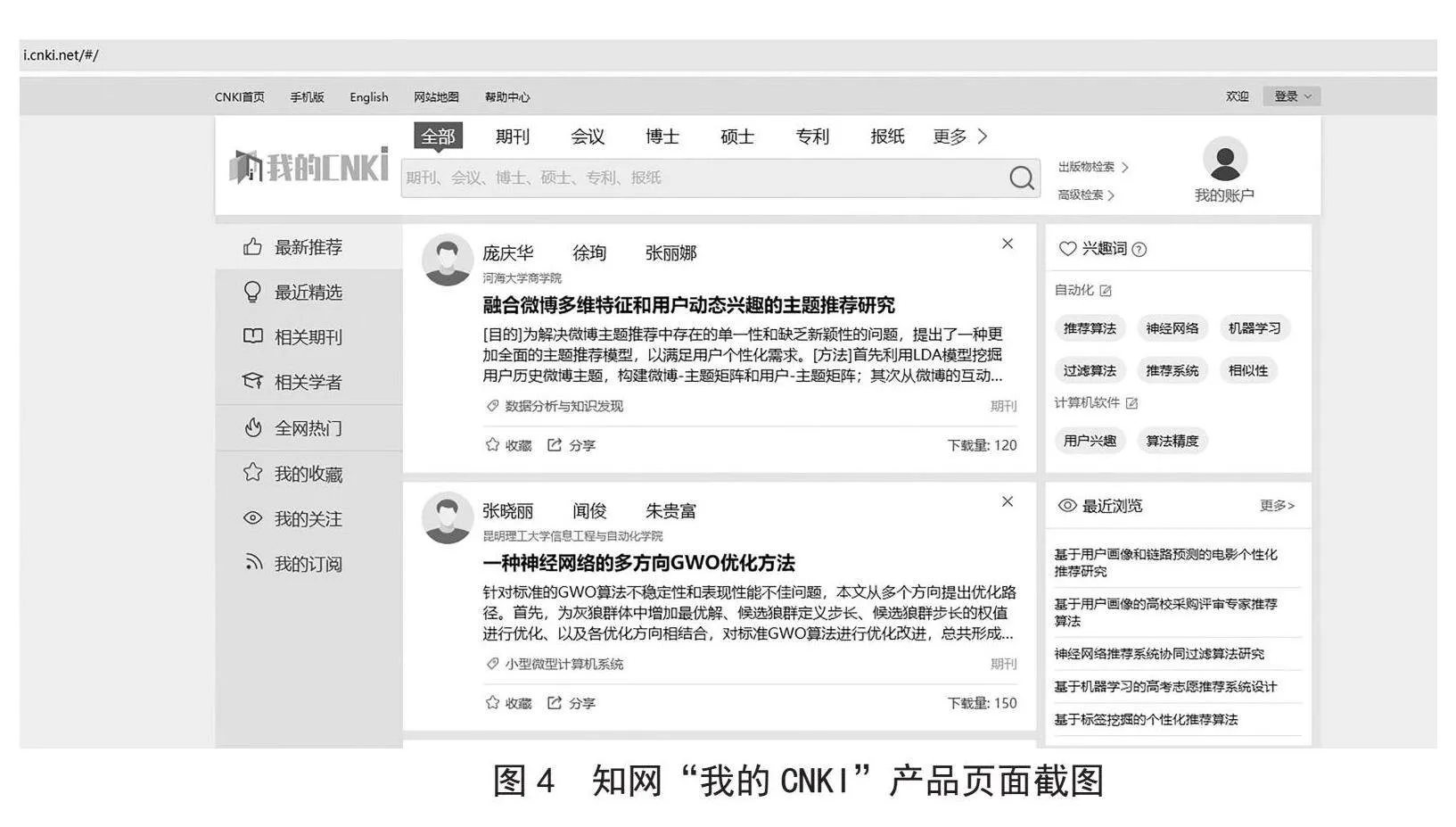
學術畫像已應用于知網“我的CNKI”產品,為讀者提供個性化知識推薦服務,如圖4所示。
5 結 論
針對基于用戶行為的學術用戶畫像構建問題,本文提出從用戶IP、賬號、終端標識三個維度對歷史行為數據進行標識的方法,并通過學術畫像建模對用戶的興趣領域及每個興趣領域的興趣詞進行向量表達。最后,結合賬號其他信息一起構建學術用戶畫像,并以JSON格式進行完整描述,為后續個性化知識推薦服務提供支撐。
參考文獻:
[1] 庫帕.交互設計之路 [M].北京:電子工業出版社,2006.
[2] 趙宏田.用戶畫像:方法論與工程化解決方案 [M].北京:機械工業出版社,2020.
[3] 黃志楊.基于K-means++的大學生就業畫像構建 [J].現代信息科技,2023,7(10):109-112.
[4] 刁雪樺,朱學芳.基于用戶群體畫像分析的慕課平臺知識服務策略研究 [J].數字圖書館論壇,2023,19(12):11-20.
[5] 王世奇,劉智鋒,王繼民.學者畫像研究綜述 [J].圖書情報工作,2022,66(20):73-81.
[6] 李松,王磊,王千羽.基于評論信息的網絡購物用戶興趣畫像研究 [J].情報科學,2023,41(11):128-133.
[7] 劉一鳴,徐春霞.基于用戶畫像的公共圖書館健康信息精準服務路徑研究 [J].圖書館,2023(9):53-59.
[8] 劉樂洋,劉維維.用戶畫像在衛生健康領域應用中的研究進展 [J].中國健康教育,2023,39(9):826-831.
[9] 陳晶,彭長根,譚偉杰.基于聯邦學習的多源數據用戶畫像設計方案 [J].南京郵電大學學報:自然科學版,2023,43(5):83-91.
[10] 房志明,吳鑫卓,林原,等.基于用戶畫像的高校采購評審專家推薦算法 [J].實驗技術與管理,2024,41(4):228-237.
[11] 吳迪,馬文莉,楊利君.遺忘曲線和BTM詞頻雙層加權微博用戶畫像 [J].計算機工程與設計,2023,44(12):3800-3808.
[12] 李帥,李海霞,金山,等.基于用戶畫像的軍事情報推薦技術 [J].火力與指揮控制,2023,48(4):122-129.
[13] 楊巍,葉仁杰,吳元業,等.COUNTER Release 5的新特征及其應用研究 [J].大學圖書館學報,2020,38(1):18-25+41.
作者簡介:張良(1977—),男,漢族,山東濟寧人,高級工程師,碩士,研究方向:信息系統研發與管理;肖銀濤(1985—),男,漢族,河北保定人,項目經理,碩士,研究方向:用戶畫像與推薦系統。
