基于CiteSpace的國內(nèi)命名實體識別技術(shù)的知識圖譜分析
2024-10-22 00:00:00李源蔡忠祥李娜黃子鳴
現(xiàn)代信息科技 2024年15期



摘 要:命名實體識別(NER)是自然語言處理(NLP)領(lǐng)域的重要任務(wù)。量化梳理NER的文獻(xiàn)進(jìn)程,有助于未來NER乃至NLP技術(shù)的突破發(fā)展。目前已有大量學(xué)者對NER任務(wù)進(jìn)行了綜述回顧。但是這些基于傳統(tǒng)文獻(xiàn)計量學(xué)的回顧方式,既過于依賴專家經(jīng)驗,又無法直觀呈現(xiàn)知識變遷。因此,文章以知網(wǎng)中文核心文獻(xiàn)為驅(qū)動,基于CiteSpace工具,對國內(nèi)NER技術(shù)進(jìn)行了知識圖譜展示和數(shù)據(jù)挖掘分析。分析結(jié)果顯示:以2016年為界,國內(nèi)已形成基于數(shù)據(jù)驅(qū)動的兩個快速發(fā)展期;“當(dāng)?shù)馗咝?省立實驗室”的形式已成為國內(nèi)機(jī)構(gòu)合作的主流;“深度學(xué)習(xí)”“知識圖譜”“實體識別”“信息抽取”“神經(jīng)網(wǎng)絡(luò)”和“詞向量”是國內(nèi)NER領(lǐng)域的研究熱點;未來對NER的研究傾向于應(yīng)用落地、數(shù)據(jù)增強(qiáng)和知識抽取。
關(guān)鍵詞:命名實體識別;CiteSpace;知識圖譜;中國知網(wǎng)
中圖分類號:TP391.4 文獻(xiàn)標(biāo)識碼:A 文章編號:2096-4706(2024)15-0124-06
Knowledge Graph Analysis of Domestic Named Entity Recognition Based on CiteSpace
LI Yuan, CAI Zhongxiang, LI Na, HUANG Ziming
(Faculty of Information Engineering, Xinyang Agriculture and Forestry University, Xinyang 464000, China)
Abstract: Named Entity Recognition (NER) is an important task in the field of Natural Language Processing (NLP). Quantitative review of the literature process of NER technology is conducive to the breakthrough development of NER and even NLP technology in the future. At present, a large number of scholars have reviewed the NER tasks. However, these review methods based on traditional bibliometrics not only rely too much on expert experience, but also can not directly present the change of knowledge paradigm. Therefore, this paper, driven by the Chinese core literature of CNKI and based on CiteSpace, presents the Knowledge Graph display and data mining analysis of domestic NER technology. The analysis results show that the domestic research on NER has formed two rapid development periods based on data drive from 2016. The form of “l(fā)ocal university + provincial laboratory” has become the mainstream of domestic institutional cooperation. “Deep Learning” “Knowledge Graph” “entity recognition” “information extraction” “Neural Network” and “word vector” are the hot spots of domestic NER research. Future research on NER tends to apply landing, data enhancement and knowledge extraction.
Keywords: Named Entity Recognition; CiteSpace; Knowledge Graph; CNKI
0 引 言
命名實體識別(Named Entity Recognition, NER)技術(shù)是自然語言處理(Natural Language Processing, NLP)領(lǐng)域的一個重要且基礎(chǔ)的前置任務(wù)[1],影響著諸多下游NLP子任務(wù)的性能,如信息檢索、機(jī)器翻譯、輿情檢測等。
自21世紀(jì)起,國內(nèi)就有研究者陸續(xù)對實體的高精度識別和提取進(jìn)行研究,目前在知網(wǎng)上已經(jīng)積累了數(shù)以千計的相關(guān)文獻(xiàn)資料,并仍在快速增加中。文獻(xiàn)回顧工作是一個長期的、煩瑣的但是又極其重要的工作。目前國內(nèi)已有學(xué)者在不同時期論述了NER技術(shù)在不同階段的變遷情況。如,張曉艷等[2]回顧了從1985年到2005年間NER技術(shù)的由來脈絡(luò)、識別方法和評測指標(biāo);劉瀏等[3]指出目前的主流NER方法仍然是基于規(guī)則和統(tǒng)計機(jī)器學(xué)習(xí)的方法;趙繼貴等[4]在回顧傳統(tǒng)的NER任務(wù)同時,又補(bǔ)充了當(dāng)前基于深度學(xué)習(xí)的方法,并對未來中文NER任務(wù)的發(fā)展進(jìn)行了展望。
但是這些基于傳統(tǒng)文獻(xiàn)計量方式進(jìn)行文獻(xiàn)回顧的方法,往往過度依賴于外部專家的學(xué)習(xí)經(jīng)驗,從而可能造成對某些關(guān)鍵研究文獻(xiàn)的忽略。此外,這種基于傳統(tǒng)文獻(xiàn)計量方式也難以直觀呈現(xiàn)與NER相關(guān)的研究范式的產(chǎn)生、發(fā)展、變遷乃至消亡的過程。如何在海量的文獻(xiàn)中快速、準(zhǔn)確、直觀的發(fā)現(xiàn)關(guān)鍵信息一直是人們關(guān)注的焦點。CiteSpace[5]是一種能直觀展現(xiàn)知識點間聯(lián)系、發(fā)展、變化的文獻(xiàn)可視化工具。因此,本文基于CiteSpace對國內(nèi)的NER技術(shù)研究進(jìn)行了可視化分析,旨在展示發(fā)展脈絡(luò),探索合作模式,挖掘知識范式,厘定前沿?zé)狳c。
本文其他部分的結(jié)構(gòu)如下:第1部分介紹本文使用的數(shù)據(jù)來源和進(jìn)行數(shù)據(jù)處理的手段,第2部分使用CiteSpace工具對知網(wǎng)數(shù)據(jù)進(jìn)行可視化展示和數(shù)據(jù)分析,最后總結(jié)國內(nèi)NER領(lǐng)域的研究方法并在此基礎(chǔ)上展望了未來。
1 數(shù)據(jù)采集與處理
1.1 數(shù)據(jù)來源
受到布拉德福文獻(xiàn)離散定律的啟發(fā),本文在CNKI中選取高質(zhì)量的、有影響力的北大核心和CSSCI檢索期刊作為數(shù)據(jù)的分析來源。為提高文獻(xiàn)查全率,本文使用了高級檢索設(shè)置,設(shè)置檢索條件為主題=(*命名實體識別*)NOT 主題=(*綜述*)NOT主題=(*進(jìn)展*),并剔除了新聞、書籍介紹、廣告等無關(guān)數(shù)據(jù),共獲得數(shù)據(jù)948條。
1.2 數(shù)據(jù)處理
為進(jìn)一步提高主題精準(zhǔn)度,本文使用了CiteSpace 6.2.R6進(jìn)行數(shù)據(jù)預(yù)處理和可視化操作,最終獲得去重的期刊文章884條。
2 研究現(xiàn)狀與分析
2.1 文獻(xiàn)隨年代分布情況
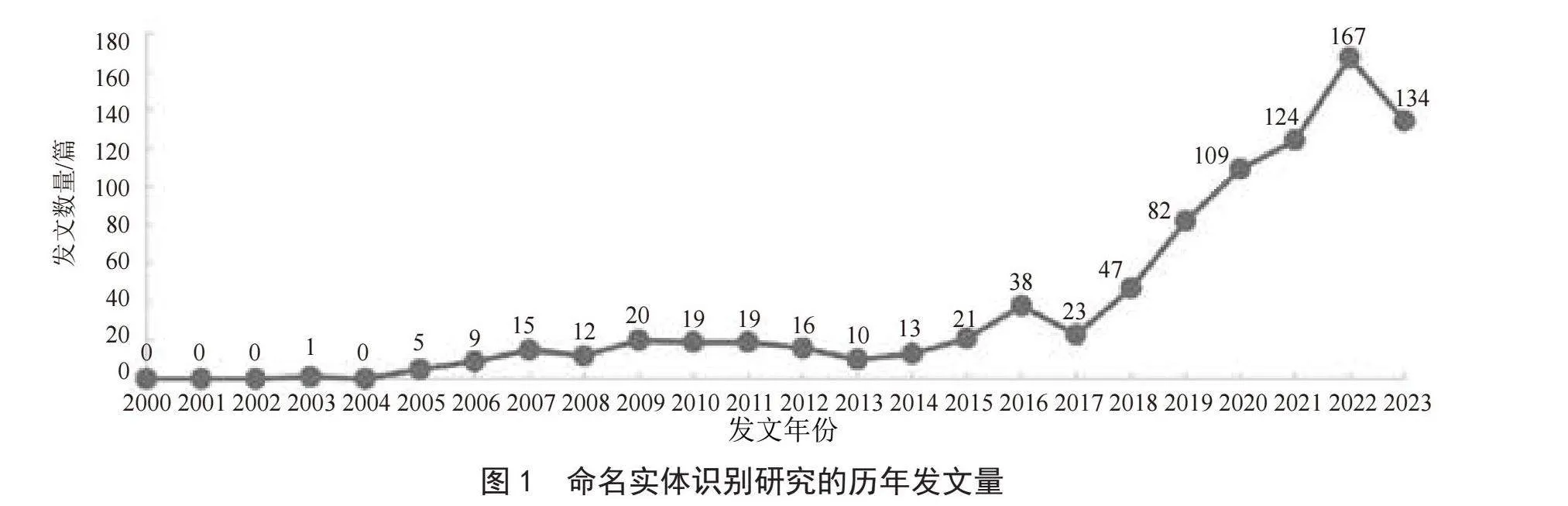
文獻(xiàn)的發(fā)表年代可以反映出總體研究的發(fā)展脈絡(luò)及其受到關(guān)注的情況。本節(jié)以1年為時間間隔,分組統(tǒng)計并繪制出了國內(nèi)進(jìn)行命名實體識別研究的歷年發(fā)文量。如圖1所示,可知2000—2004年的發(fā)文量較低,僅有1篇應(yīng)用型論文[6],整體處于發(fā)文短缺期。此時國內(nèi)尚未形成完整的理論體系研究,仍處于跟跑英文NER研究和探索中文NER理論階段,因此少有高水平中文論文產(chǎn)出。
2004年之后,隨著數(shù)據(jù)的不斷積累,基于數(shù)據(jù)驅(qū)動的方法逐漸引起了相關(guān)學(xué)者的關(guān)注并成為研究的重點。基于數(shù)據(jù)驅(qū)動的發(fā)展可分為兩個時期:第一次快速發(fā)展期(2005—2015年),基于統(tǒng)計機(jī)器學(xué)習(xí)的方法占據(jù)了研究的主流,整體發(fā)文呈現(xiàn)先快遞增長后平穩(wěn)波動的趨勢。2005年和2006年的發(fā)文量分別為5篇和9篇,同2000—2004年相比,發(fā)文數(shù)量快速上升,基于隱馬爾可夫(Hidden Markov Model, HMM)[7-8]的實體抽取模型在國內(nèi)得到了廣泛的應(yīng)用。
但齊次馬爾科夫假設(shè)和觀測獨立假設(shè)也極大地限制了基于HMM模型的捕獲更多和更長遠(yuǎn)上下文的能力,因此在2007年之后,基于線性鏈的條件隨機(jī)場(Liner Conditional Random Field, CRF)[9-12]的NER模型獲得了更多的關(guān)注;第二次快速發(fā)展期(2016—2023年),隨著數(shù)據(jù)和軟硬資源的完善,能夠提取自動深度語義特征的神經(jīng)網(wǎng)絡(luò)模型進(jìn)入人們的視野,基于深度學(xué)習(xí)的方法成為后續(xù)研究的主流。典型的算法包括循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network, RNN)[13-16]、卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network, CNN)[17-18]及預(yù)訓(xùn)練語言模型(Pretrained Language Model, PLM)[19-22]等。
2.2 作者合作分析
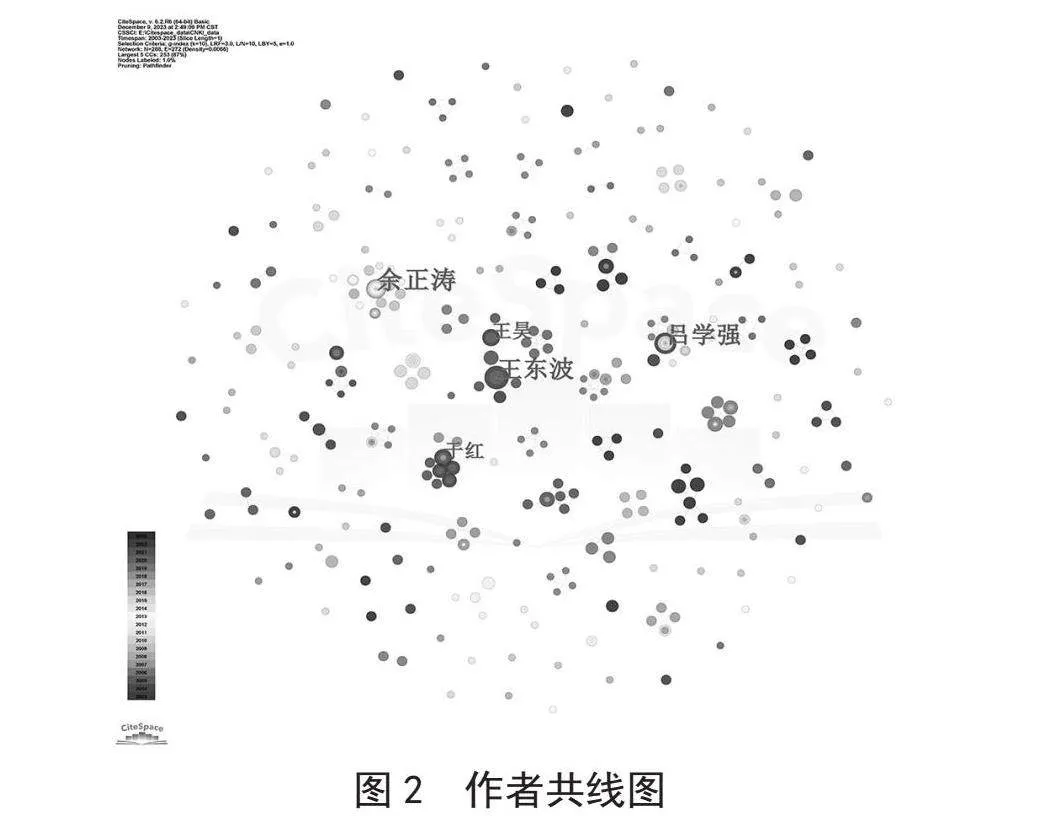
作者共線圖能夠反應(yīng)不同作者間的發(fā)文合作情況以及研究內(nèi)容的變化情況。其中,節(jié)點的大小表示作者發(fā)文的數(shù)量。節(jié)點的色系對應(yīng)發(fā)文的時間早晚,發(fā)文越早,節(jié)點的顏色越接近紫色,發(fā)文越新,節(jié)點顏色越接近紅色。節(jié)點間的線條粗細(xì)則表示不同作者間的合作緊密情況。
圖2中存在288個節(jié)點,272條連線,并形成了以余正濤(12篇)、王東波(11篇)、呂學(xué)強(qiáng)(10篇)和于紅(6篇)為首的4大核心作者群體研究組。通過查看核心作者的節(jié)點詳情可知:李桂蘭等主要研究與旅游領(lǐng)域8[23]相關(guān)的文本任務(wù),并形成以柬埔寨語[24]和越南語[25-26]為主的小語種處理隊伍;崔競烽等團(tuán)隊擅長于對中華典籍進(jìn)行數(shù)字化處理和識別,并在古詩詞[27]、引書[28]、史記[29]、醫(yī)書[30]等中文歷史文本上進(jìn)行了深遠(yuǎn)的嘗試;劉殷等團(tuán)隊則緊跟時代理論前沿,分別研究了HMM7、CRF[31]以及神經(jīng)網(wǎng)絡(luò)[32]等模型在中文NER任務(wù)上的應(yīng)用;任媛等團(tuán)隊主要基于深度學(xué)習(xí)技術(shù)深入研究了神經(jīng)網(wǎng)絡(luò)在識別水產(chǎn)類文本[33-35]上的效用。
但是這些大型研究組之間并沒有直接連線,而且圖中也存在大量無連線的其他小型作者研究群體。這一現(xiàn)象在一方面表明現(xiàn)階段各個研究群體間的合作較為局限,但也在另一方面表明命名實體識別技術(shù)的適用范圍廣,尚有極大的發(fā)展空間。
2.3 機(jī)構(gòu)合作分析
為了進(jìn)一步分析各個研究群體間的合作,本節(jié)繪制了機(jī)構(gòu)共線關(guān)系圖。圖3中共有298個節(jié)點,134條邊。結(jié)合機(jī)構(gòu)分析,發(fā)文機(jī)構(gòu)常以“當(dāng)?shù)馗咝?省立實驗室”的形式進(jìn)行合作,如“昆明理工大學(xué)信息工程與自動化學(xué)院+云南省計算機(jī)技術(shù)應(yīng)用重點實驗室智能信息處理研究所”等。整體上各個研究機(jī)構(gòu)主要以高校的二級學(xué)院為依托,同一個單位內(nèi)的作者合作發(fā)文較多。這一現(xiàn)象也進(jìn)一步顯現(xiàn)各個研究群體間的合作較為局限,尚有極大的發(fā)展空間的推論。
2.4 研究熱點分析
高頻的關(guān)鍵詞通常能夠表示一個研究的熱點[36]。為了直觀分析研究熱點的發(fā)展變化,本節(jié)按照文章的關(guān)鍵詞進(jìn)行了關(guān)鍵詞共線分析。具體操作如下:
1)首先將經(jīng)過去重處理的文獻(xiàn)以CSSCI格式導(dǎo)入CiteSpace。
2)設(shè)置時間切片間隔為每年。
3)為了減少低頻數(shù)據(jù)的影響,使用了Pathfinder選項進(jìn)行網(wǎng)絡(luò)裁剪。
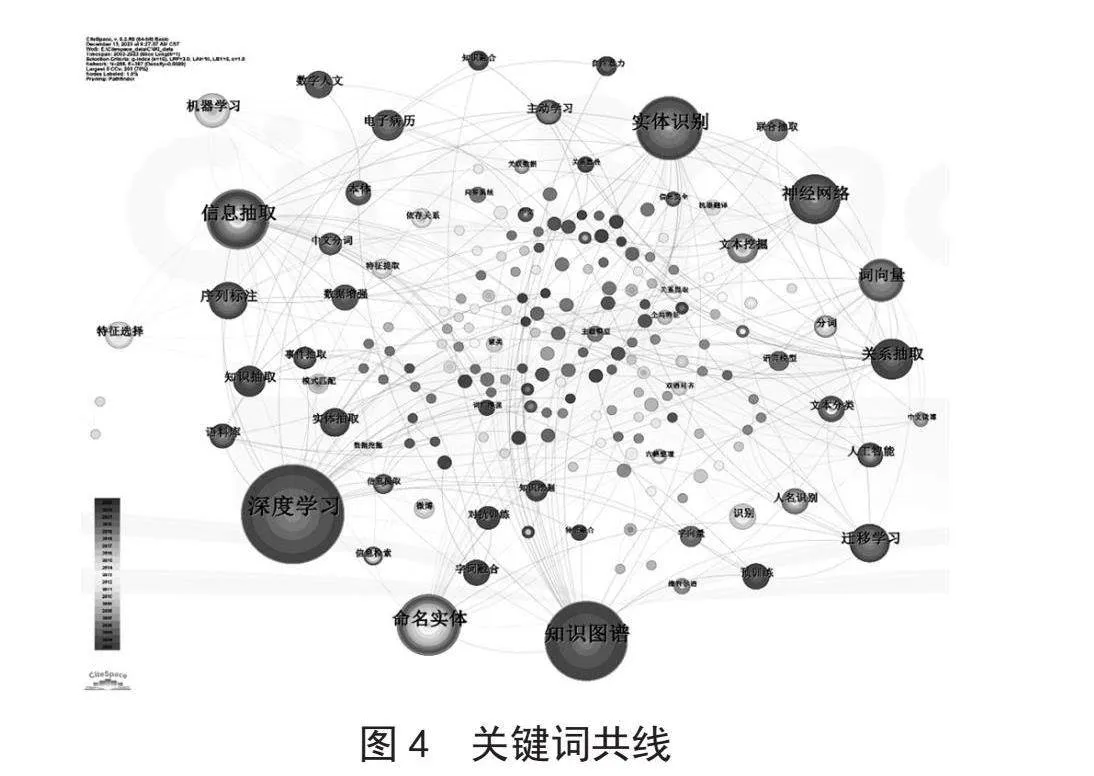
4)以頻率為分類標(biāo)準(zhǔn),篩選出現(xiàn)頻次高于5次的節(jié)點信息。最終得到關(guān)鍵詞共線圖,如圖4所示。
圖4中包含288個節(jié)點,和367條邊。節(jié)點上的圓環(huán)顏色的種類對應(yīng)關(guān)鍵詞的出現(xiàn)頻率,關(guān)鍵詞的頻率越高,則對應(yīng)的圓環(huán)和字體越大,該關(guān)鍵詞也就越重要。據(jù)圖可知,目前“深度學(xué)習(xí)”“知識圖譜”“實體識別”“信息抽取”“神經(jīng)網(wǎng)絡(luò)”“詞向量”等關(guān)鍵詞字號較大、圓環(huán)顏色種類多且與其他節(jié)點之間具有較多的連線。這一現(xiàn)象說明這些高頻關(guān)鍵詞在多個時期內(nèi)都是研究的主要對象,彼此相互交織,聯(lián)系緊密,但難以區(qū)分各個時期的主要研究熱點。為此,本節(jié)在關(guān)鍵詞共線的基礎(chǔ)上進(jìn)行了聚類分析,并按時間順序進(jìn)行結(jié)果展示,其結(jié)果如圖5所示。
通過LLR聚類算法,CiteSpace形成了85個具有288個節(jié)點和367條邊的關(guān)鍵詞聚類結(jié)果(Q值為0.660 8,S值為0.894 5)。本節(jié)篩選了前6個最大的聚類規(guī)模進(jìn)行研究熱點變化分析。該時序圖的橫軸表示時間的變化,縱軸的每一條線則對應(yīng)一組聚類的結(jié)果,而線上的每一個圓環(huán)都對應(yīng)一個關(guān)鍵詞。
由圖5可知目前對命名實體識別的研究主要集中在“信息抽取”“知識圖譜”“命名實體”“實體識別”“深度學(xué)習(xí)”以及“機(jī)器學(xué)習(xí)”這6個方面。繼續(xù)分析每一組聚類的結(jié)果可得到以下結(jié)論:
#0信息抽取的聚類結(jié)果主要包括“數(shù)據(jù)挖掘[37]”“決策樹[38]”“神經(jīng)網(wǎng)絡(luò)[39]”“對抗學(xué)習(xí)[40]”“字詞融合[41]”。這些研究者采用了經(jīng)典的決策樹或神經(jīng)網(wǎng)絡(luò)等數(shù)據(jù)挖掘算法完成了NER。造成這一現(xiàn)象的原因可能是NER是信息抽取[42]的子任務(wù),相關(guān)研究者會嘗試將之前解決其他類似任務(wù)的方法應(yīng)用到同一個領(lǐng)域的其他問題上來。
#1知識圖譜的聚類結(jié)果主要包括“關(guān)系抽取[43]”“人工智能[44]”“知識抽取[45]”“知識融合[46]”等。知識圖譜是包含事實、實體、關(guān)系以及語義表述的大規(guī)模結(jié)構(gòu)化表示的語義網(wǎng)絡(luò)[47]。在一方面知識圖譜的形成需要使用NER術(shù)進(jìn)行知識實體抽取,在另一方面NER的性能又會受到對外部背景知識理解程度的影響,二者相輔相成,聯(lián)系密切。
#2命名實體和#3實體識別則分被對應(yīng)NER任務(wù)的用途和對象。命名實體是自然語言處理的一項重要基礎(chǔ)任務(wù),能夠為信息檢索、機(jī)器翻譯[48-49]、情感分析[50]等一系列下游任務(wù)提供豐富的實體級別語義信息。
#4深度學(xué)習(xí)和#5機(jī)器學(xué)習(xí)則對應(yīng)進(jìn)行NER的技術(shù)手段。結(jié)合時間線的變化,目前基于深度學(xué)習(xí)的自動融合多種深層特征的方法已經(jīng)取代基于機(jī)器學(xué)習(xí)的提取淺層的方法,并成為新的完成NER的基線方法。
#6詞向量的聚類結(jié)果則主要包括“語料庫[51]”“字向量[52]”“語言模型[53]”。字詞數(shù)值化的效果好壞能夠極大的影響下游自然語言處理任務(wù)的性能,對自然語言處理研究者來說,如何在計算機(jī)中合適的表達(dá)字詞語言一直是一個關(guān)鍵的問題。目前基于BERT等預(yù)訓(xùn)練語言模型獲得的字詞向量已經(jīng)成為完成NER任務(wù)的主要范式。
隨著理論的豐富和技術(shù)的不斷發(fā)展,對NER的研究也出現(xiàn)了新的方向。由圖6的關(guān)鍵詞突變圖可以展望:未來國內(nèi)對NER的研究將聚焦在對“電子病歷”和“數(shù)字人文”等重點領(lǐng)域的項目落地上;使用“數(shù)據(jù)增強(qiáng)”的方式解決低資源場景下的NER任務(wù)將會是一個新的方向;使用NER技術(shù)進(jìn)行“知識抽取”以及結(jié)合外部知識提高NER模型的可解釋性將得到更多NER研究者的重視。
3 結(jié) 論
本文以知網(wǎng)最近23年的核心文獻(xiàn)為數(shù)據(jù),通過CiteSpace可視化工具,量化并分析了國內(nèi)對NER任務(wù)研究的變化趨勢,并得到以下結(jié)論:對NER的研究以2016年為界,分為兩個發(fā)展時間。這兩階段又分別以統(tǒng)計機(jī)器學(xué)習(xí)和深度學(xué)習(xí)為研究的重點;目前至少已經(jīng)形成四大核心作者研究群體,但這些研究群體之間合作較為局限,通常依靠所在單位進(jìn)行研究,并形成“當(dāng)?shù)馗咝?省立實驗室”的合作模型,但跨院校之間的合作較少,未來仍有較大的深度合作空間;近23年來的研究重點主要集中于“信息抽取”“知識圖譜”“命名實體”“實體識別”“深度學(xué)習(xí)”以及“機(jī)器學(xué)習(xí)”這6個方面。結(jié)合深度學(xué)習(xí)和知識圖譜等相關(guān)技術(shù)進(jìn)行實體識別的范式依然會持續(xù)較長的一段時間。
參考文獻(xiàn):
[1] 楊錦鋒,于秋濱,關(guān)毅,等.電子病歷命名實體識別和實體關(guān)系抽取研究綜述 [J].自動化學(xué)報,2014,40(8):1537-1562.
[2] 張曉艷,王挺,陳火旺.命名實體識別研究 [J].計算機(jī)科學(xué),2005(4):44-48.
[3] 劉瀏,王東波.命名實體識別研究綜述 [J].情報學(xué)報,2018,37(3):329-340.
[4]趙繼貴,錢育蓉,王魁,等.中文命名實體識別研究綜述 [J].計算機(jī)工程與應(yīng)用,2024,60(1):15-27.
[5] CHEN C. Science Mapping: A Systematic Review of the Literature [J].Journal of Data and Information Science,2017,2(2):1-40.
[6] 昝紅英,蘇玉梅,孫斌,等.名人網(wǎng)頁的相關(guān)度評價 [J].中文信息學(xué)報,2003(5):27-33.
[7] 俞鴻魁,張華平,劉群,等.基于層疊隱馬爾可夫模型的中文命名實體識別 [J].通信學(xué)報,2006(2):87-94.
[8] 薛征山,郭劍毅,余正濤,等.基于HMM的中文旅游景點的識別 [J].昆明理工大學(xué)學(xué)報:理工版,2009,34(6):44-48.
[9] 劉非凡,趙軍,徐波.實體提及的多層嵌套識別方法研究 [J].中文信息學(xué)報,2007(2):14-21.
[10] 郭劍毅,薛征山,余正濤,等.基于層疊條件隨機(jī)場的旅游領(lǐng)域命名實體識別 [J].中文信息學(xué)報,2009,23(5):47-52.
[11] 鄒俊杰,余正濤,劉躍紅,等.融合領(lǐng)域命名實體識別的查詢擴(kuò)展方法研究 [J].計算機(jī)工程與設(shè)計,2012,33(3):1229-1233+1250.
[12] 潘清清,周楓,余正濤,等.基于條件隨機(jī)場的越南語命名實體識別方法 [J].山東大學(xué)學(xué)報:理學(xué)版,2014,49(1):76-79.
[13] 朱丹浩,楊蕾,王東波.基于深度學(xué)習(xí)的中文機(jī)構(gòu)名識別研究——一種漢字級別的循環(huán)神經(jīng)網(wǎng)絡(luò)方法 [J].現(xiàn)代圖書情報技術(shù),2016(12):36-43.
[14] 趙青,王丹,徐書世,等.中文醫(yī)療實體的弱監(jiān)督識別方法 [J].哈爾濱工程大學(xué)學(xué)報,2020,41(3):425-432.
[15] 宋佳芮,陳艷平,王凱,等.基于Affix-Attention的命名實體識別語義補(bǔ)充方法 [J].山東大學(xué)學(xué)報:工學(xué)版,2023,53(2):70-76.
[16]李源,馬磊,邵黨國,等.用于社交媒體的中文命名實體識別 [J].中文信息學(xué)報,2020,34(8):61-69.
[17] 許浩亮,李雁群,何云琪,等.中文嵌套命名實體關(guān)系抽取研究 [J].北京大學(xué)學(xué)報:自然科學(xué)版,2019,55(1):8-14.
[18] 于祥欽,王香,李智強(qiáng),等.基于字符級特征自適應(yīng)的生物醫(yī)學(xué)命名實體識別 [J].小型微型計算機(jī)系統(tǒng),2023,44(9):1876-1883.
[19] 陳劍,何濤,聞英友,等.基于BERT模型的司法文書實體識別方法 [J].東北大學(xué)學(xué)報:自然科學(xué)版,2020,41(10):1382-1387.
[20] 游樂圻,裴忠民,羅章凱.融合自注意力的ALBERT中文命名實體識別方法 [J].計算機(jī)工程與設(shè)計,2023,44(2):605-611.
[21] 賈李睿智,劉勝全,劉源,等.基于分層ERNIE模型的中文嵌套命名實體識別 [J].東北師大學(xué)報:自然科學(xué)版,2023,55(1):97-103.
[22] 余克健,張程,樂毅,等.基于GPT修正農(nóng)業(yè)病蟲害命名實體識別方法 [J].內(nèi)蒙古農(nóng)業(yè)大學(xué)學(xué)報:自然科學(xué)版,2023,44(5):34-43.
[23] 李桂蘭,余正濤,毛存禮,等.旅游領(lǐng)域?qū)嶓w答案的抽取 [J].廣西師范大學(xué)學(xué)報:自然科學(xué)版,2009,27(1):181-184.
[24] 徐廣義,嚴(yán)馨,余正濤,等.融合跨語言特征的柬埔寨語命名實體識別方法 [J].云南大學(xué)學(xué)報:自然科學(xué)版,2018,40(5):865-871.
[25] 潘華山,嚴(yán)馨,余正濤,等.基于支持向量機(jī)的越語新聞文本分類方法 [J].山西大學(xué)學(xué)報:自然科學(xué)版,2013,36(4):505-509.
[26] 劉艷超,郭劍毅,余正濤,等.融合實體特性識別越南語復(fù)雜命名實體的混合方法 [J].智能系統(tǒng)學(xué)報,2016,11(4):503-512.
[27] 崔競烽,鄭德俊,王東波,等.基于深度學(xué)習(xí)模型的菊花古典詩詞命名實體識別 [J].情報理論與實踐,2020,43(11):150-155.
[28] 黃水清,周好,彭秋茹,等.引書的自動識別及文獻(xiàn)計量學(xué)分析 [J].情報學(xué)報,2021,40(12):1325-1337.
[29] 劉江峰,馮鈺童,王東波,等.數(shù)字人文視域下SikuBERT增強(qiáng)的史籍實體識別研究 [J].圖書館論壇,2022,42(10):61-72.
[30] 謝靖,劉江峰,王東波.古代中國醫(yī)學(xué)文獻(xiàn)的命名實體識別研究——以Flat-lattice增強(qiáng)的SikuBERT預(yù)訓(xùn)練模型為例 [J].圖書館論壇,2022,42(10):51-60.
[31] 劉殷,呂學(xué)強(qiáng),劉坤.條件隨機(jī)場與多層算法模型的實體自動識別 [J].計算機(jī)工程與應(yīng)用,2016,52(11):141-147.
[32] 羅藝雄,呂學(xué)強(qiáng),游新冬.融合多特征的專利功效短語識別 [J].中文信息學(xué)報,2022,36(12):139-148.
[33] 任媛,于紅,楊鶴,等.融合注意力機(jī)制與BERT+BiLSTM+CRF模型的漁業(yè)標(biāo)準(zhǔn)定量指標(biāo)識別 [J].農(nóng)業(yè)工程學(xué)報,2021,37(10):135-141.
[34] 劉巨升,楊惠寧,孫哲濤,等.面向知識圖譜構(gòu)建的水產(chǎn)動物疾病診治命名實體識別 [J].農(nóng)業(yè)工程學(xué)報,2022,38(7):210-217.
[35] 劉巨升,于紅,楊惠寧,等.基于多核卷積神經(jīng)網(wǎng)絡(luò)(BERT+Multi-CNN+CRF)的水產(chǎn)醫(yī)學(xué)嵌套命名實體識別 [J].大連海洋大學(xué)學(xué)報,2022,37(3):524-530.
[36] 林德明,陳超美,劉則淵.共被引網(wǎng)絡(luò)中介中心性的Zipf—Pareto分布研究 [J].情報學(xué)報,2011,30(1):76-82.
[37] 李中言,李普躍.信息抽取技術(shù)在數(shù)字圖書館中的應(yīng)用 [J].現(xiàn)代情報,2007(10):96-97.
[38] 栗偉,趙大哲,李博,等.CRF與規(guī)則相結(jié)合的醫(yī)學(xué)病歷實體識別 [J].計算機(jī)應(yīng)用研究,2015,32(4):1082-1086.
[39] 朱娜娜,景東,薛涵.基于深度神經(jīng)網(wǎng)絡(luò)的微博圖書名識別研究 [J].圖書情報工作,2016,60(4):102-106+141.
[40] 董哲,邵若琦,陳玉梁,等.基于BERT和對抗訓(xùn)練的食品領(lǐng)域命名實體識別 [J].計算機(jī)科學(xué),2021,48(5):247-253.
[41] 宋旭暉,于洪濤,李邵梅.基于圖注意力網(wǎng)絡(luò)字詞融合的中文命名實體識別 [J].計算機(jī)工程,2022,48(10):298-305.
[42] GRISHMAN R,SUNDHEIM B M. Message Understanding Conference-6: A Brief History [C]//COLING 1996 Volume 1: The 16th International Conference on Computational Linguistics.Stroudsburg:Association for Computational Linguistics,1996:466-471.
[43] 謝雨希,楊江平,孫知建,等.雷達(dá)裝備故障原因知識圖譜構(gòu)建研究 [J].現(xiàn)代防御技術(shù),2022,50(5):114-121.
[44] 李振,周東岱,王勇.“人工智能+”視域下的教育知識圖譜:內(nèi)涵、技術(shù)框架與應(yīng)用研究 [J].遠(yuǎn)程教育雜志,2019,37(4):42-53.
[45] 鄧智嘉.基于人工智能的知識圖譜構(gòu)建技術(shù)及應(yīng)用 [J].無線電工程,2022,52(5):766-774.
[46] 楊波,廖怡茗.面向企業(yè)動態(tài)風(fēng)險的知識圖譜構(gòu)建與應(yīng)用研究 [J].現(xiàn)代情報,2021,41(3):110-120.
[47] JI S,PAN S,CAMBRIA E,et al. A Survey on Knowledge Graphs: Representation, Acquisition, a/g9VFipM+7qN44POqbpTiw==nd Applications [J].IEEE Transactions on Neural Networks and Learning Systems,2021,33(2):494-514.
[48] 王東明,徐金安,陳鈺楓,等.基于單語語料的面向日語假名的日漢人名翻譯對抽取方法 [J].中文信息學(xué)報,2015,29(5):84-90.
[49] 尹存燕,黃書劍,戴新宇,等.面向新聞?wù)Z料的中日命名實體翻譯抽取 [J].小型微型計算機(jī)系統(tǒng),2015,36(6):1393-1397.
[50] 潘正高,侯傳宇,談成訪.基于命名實體的Web新聞文本分類方法 [J].合肥工業(yè)大學(xué)學(xué)報:自然科學(xué)版,2011,34(8):1178-1182.
[51] 馮鸞鸞,李軍輝,李培峰,等.面向國防科技領(lǐng)域的技術(shù)和術(shù)語語料庫構(gòu)建方法 [J].中文信息學(xué)報,2020,34(8):41-50.
[52] 單義棟,王衡軍,黃河,等.基于注意力機(jī)制的命名實體識別模型研究——以軍事文本為例 [J].計算機(jī)科學(xué),2019,46(S1):111-114+119.
[53] 陳蕾,鄭偉彥,余慧華,等.基于BERT的電網(wǎng)調(diào)度語音識別語言模型研究 [J].電網(wǎng)技術(shù),2021,45(8):2955-2961.
作者簡介:李源(1995—),男,漢族,河南信陽人,助教,碩士,研究方向:實體抽取、自然語言處理、數(shù)據(jù)挖掘;蔡忠祥(1996—),男,漢族,河南信陽人,助教,碩士,研究方向:計算機(jī)應(yīng)用;李娜(2003—),女,漢族,河南三門峽人,本科在讀,研究方向:數(shù)據(jù)可視化;黃子鳴(2003—),男,漢族,河南信陽人,本科在讀,研究方向:數(shù)據(jù)可視化。
