面向高維數據發布的差分隱私算法及應用綜述
2024-12-01 00:00:00龍春秦澤秀李麗莎李婧楊帆魏金俠付豫豪
農業大數據學報 2024年2期








摘要:隨著大數據和機器學習技術的進一步發展,處理具有幾十上百維特征的復雜結構和關系且蘊含豐富語義信息的高維數據成為一項挑戰。在保障個人隱私不被泄露的前提下,如何安全地使用這些高維數據,成為當前的一個重要話題。我們查閱資料發現:關于差分隱私技術本身的綜述很多,但是面向高維數據發布的差分隱私算法及應用的綜述卻很少。基于此,本文通過對差分隱私在高維數據領域的應用進行綜述,深入了解不同方法在保護高維數據隱私方面的優劣,并指導面向高維數據發布的差分隱私算法未來研究的方向,從而更好地應對隱私保護和數據分析的挑戰。本文首先介紹了差分隱私的原理和特性,總結了當前差分隱私技術本身的研究工作。然后從數據降維和數據合成兩個角度分析了差分隱私在高維數據環境中的應用,探討了差分隱私面臨的問題和挑戰,并提出了初步的解決方法,旨在更好地解決當前高維數據保護和使用的問題。最后,本文提出了未來可能的研究方向以促進技術交流,推動差分隱私在高維數據應用中的進一步突破。
關鍵詞:差分隱私;高維數據;擾動機制;隱私分配
1 "引言
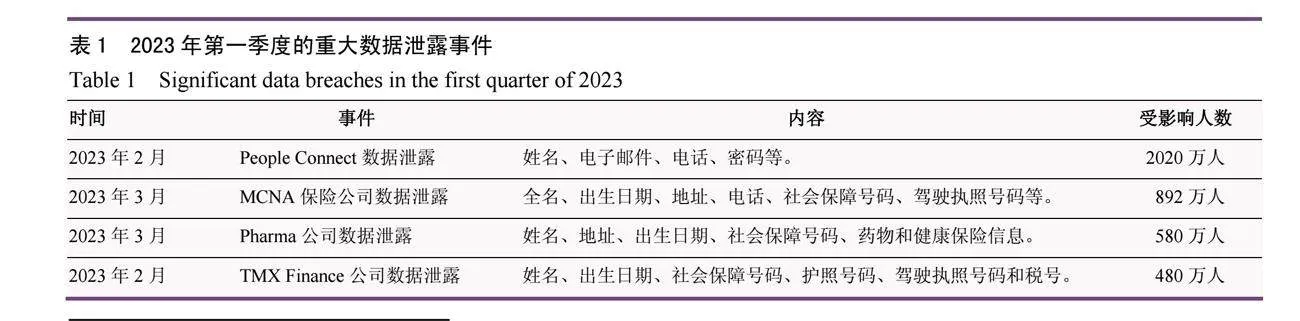
隨著大數據和機器學習技術的迅速發展,越來越多的敏感數據被收集和分析[1],例如個人健康信息、金融記錄和個人行為數據等。然而,由于企業和組織對用戶隱私數據的不當收集、存儲和使用導致了隱私泄露事件和隱私侵犯事件頻繁發生,這嚴重影響了個人和企業的隱私安全。2021年10月,醫療中心Broward Health的網站遭到攻擊,超130萬個人信息泄露;2022年6月,Flagstar銀行遭黑客攻擊,150萬客戶的數據泄露。另外,表1展示了2023年第一季度的重大數據泄露事件,這些事件凸顯了在數字時代強有力的隱私保護措施的重要性,尤其是在醫療健康、電子商務和金融安全等領域。在上述背景下,加強隱私保護措施已成為當務之急。只有通過加強數據保護技術、完善隱私保護法律法規、加強數據安全意識教育等措施,才能有效應對不斷演變的隱私安全挑戰,確保用戶個人隱私和數據安全不受侵犯。
歐盟于2018年出臺《通用數據保護條例(GDPR)》[2],規定了如何處理個人數據,包括數據主體的知情同意、數據保護官員的指定、數據遷移權、數據泄露通知等。它還強調了個人數據的可控性和可訪問性,為數據保護設定了嚴苛的標準。同年,加州發布《加州消費者隱私法案(CCPA)》[3]。該法案為加州居民更好地保護個人數據,包括請求數據的訪問和刪除,要求企業提供透明的數據處理政策。2021年中國的《中華人民共和國數據安全法》[4]開始施行,它加強了對個人數據的保護,包括明確個人數據的定義和分類、規定數據處理原則、加強跨境數據傳輸的監管等。這些法規的實施促使企業和研究機構尋求更加高效和合規的隱私保護技術,特別是在處理包含豐富個人信息的高維數據時。在這樣的環境下,各種數據保護技術蓬勃發展。
差分隱私[5]是一種先進的隱私保護技術,它通過在數據發布或查詢過程中添加噪聲來保護個體的隱私。差分隱私技術被認為是保護數據隱私的有效手段,已經被諸如Microsoft、Google等科技巨頭在其數據收集和分析中采用[6-7],美國國家標準與技術研究所(NIST)也發布了差分隱私標準的草案,并鼓勵其在各個領域的采用[8]。
李曉曄、李楊和趙禹齊等人[9-11]的三篇綜述概括了差分隱私的各種保護方法及其在不同場景下的應用,并分析了該領域未來的研究方向。與此同時,高志強和葉青青等人[12-13]對中心化差分隱私和本地化差分隱私進行了綜述,總結了差分隱私技術所面臨的主要問題和解決方案。近年來,隨著差分隱私研究的不斷增加,劉俊旭和Ahmed等人[14-15]總結了差分隱私在機器學習和深度學習中的應用情況,分析了當前研究的動態并對未來的研究方向進行了展望。孔鈺婷等人[16]對差分隱私在K-means算法中的應用進行了總結,展望了基于差分隱私的K-means算法的未來發展趨勢。此外,王騰等人[17]綜述了聯邦學習中的幾種隱私保護技術,其中包括以差分隱私為基礎的隱私保護技術,探討了聯邦學習中隱私保護的若干關鍵問題,并提出了未來的研究方向。
我們查閱資料發現:關于差分隱私的綜述很多,但是在面向高維數據發布的差分隱私算法及應用的綜述卻很少。當前面對越來越復雜的高維數據,差分隱私在該領域的綜述顯得尤為必要。通過對差分隱私在高維數據領域的應用進行綜述,深入了解不同方法在保護高維數據隱私方面的優劣,并指導未來研究的方向,從而更好地應對隱私保護和數據分析的挑戰。
Narayanan等人[18]認為高維數據是指每一條記錄都包含許多屬性的數據,而Wang等人[19]認為高維數據是指每一條記錄的維度都大于等于二,褚雪君和Amaratunga等人[20-21]認為高維數據是指每一條記錄具有幾十上百維特征。這里采納廣泛使用的褚雪君等人關于高維數據的定義,認為具有復雜的結構和關系,蘊含豐富語義信息,通常具有幾十上百維特征的數據是高維數據。傳統的差分隱私都是保護單個屬性或是某幾個屬性,但Sweeney證明[22]87%的美國人可以通過郵編、出生日期和性別這三個組合屬性唯一識別,所以如果假設數據集中的屬性可分為隱私屬性和公共屬性,然后只保護某幾個隱私屬性,這是不合理的。因為隱私屬性和公共屬性并不存在明顯的分界,任何屬性組合皆有可能泄漏個人的獨有特征規律。針對這種有幾十上百維特征的數據,并沒有特別適合的保護方法。總的來說,直接將傳統的保護低維數據的差分隱私方法推廣到高維數據,會出現以下問題[23-24]:(1)與低維數據相比,高維數據的屬性過多,想達到與低維數據相同的隱私保護效果,高維數據需要添加更多的噪聲。增加噪音可以提高隱私保護級別,但會降低數據的效用;(2)面向高維數據發布的差分隱私保護技術往往需要在隱私和效用之間做出權衡,但目前沒有很好的方法,來平衡兩者之間的關系。
這種情況要求業界開發新的算法和技術,更好地適應高維數據的特點。隨著技術的不斷發展,出現了更多更復雜的應用場景,如何在保護數據隱私的同時保持數據的高效利用,仍然需要進一步探索。希望本綜述可以給研究者提供不同思路,幫助其探索和改進差分隱私在高維數據環境中的應用,解決當前數據科學領域面臨的高維數據的保護和使用問題。
本文組織如下。引言部分詳細介紹了本文的主題,即面向高維數據的差分隱私算法及應用研究。通過強調高維數據集發布的隱私保護現狀,突顯了這一領域的研究意義。基礎知識部分首先明確了差分隱私的定義和性質,為讀者奠定了深入理解的基礎。隨后,詳細介紹了差分隱私的擾動機制,以便讀者了解在隱私保護中采用的基本原理。第3部分,面向高維數據的差分隱私發布技術。將該章節分為數據降維和數據合成兩大類,系統分析了當前高維數據差分隱私發布技術的現狀。第4部分,面向高維數據發布的差分隱私技術的應用。本章節將探討差分隱私技術在處理高維數據時在不同領域中的應用場景,深入研究現有的成果和挑戰。第5部分,問題和挑戰。在問題和挑戰章節,對現有研究不足進行總結,并提供解決思路。通過對當前研究存在的問題的深入分析,為未來研究方向的預測提供了有力支持。最后的結束語部分對全文內容進行了全面的總結和分析,強調研究的重要性和成果。
2 "基礎知識
差分隱私[5](Differential Privacy)是一種非常嚴謹且有效的隱私保護技術,它的主要功能是在收集和分析個體數據時,保護個體的隱私信息不被泄露。本章接下來將介紹差分隱私的定義,然后再介紹擾動機制的研究現狀。
2.1 "差分隱私相關概念
2.1.1 "差分隱私
一個隨機算法A,當且僅當對于任意鄰近數據集D和D',以及任意輸出O,滿足如下條件:
則稱隨機算法A滿足差分隱私。
其中,Pr[A(*)=O]是指向算法A輸入數據集*時,輸出O的概率。上面這個條件將相鄰數據集D和D'的查詢結果相同的概率限制在了一個范圍內,這樣的話,無論攻擊者的背景知識如何,他都無法推斷出具有很高置信度的個體信息,由此可以保護數據集。當ε越接近于0,即eε越接近于1時,輸出O的概率也應該越接近,這樣隨機算法A的輸入對輸出O的影響就應該越小。最理想的情況,ε=0,Pr[A(D)=O]= Pr[A(D')=O],即無論輸入數據集多相近,隨機算法A輸出O的概率都應該是一樣的。應該如何控制輸出O的概率,使得滿足上述條件呢?
假設有一個癌癥患者數據集D,需要在不泄露隱私的情況下,發布下面這個查詢結果。
設這個查詢為M(D),為滿足差分隱私,向M(D)的結果中添加噪聲Y,得到最后的發布結果A(D)=M(D)+Y。如果查詢M(D)的結果為O的概率和加噪操作A(D)的結果為O的概率滿足上式,就說最后發布的這個結果滿足差分隱私。
2.1.2 "敏感度
敏感度直接決定加入的噪聲量的大小,它是指刪
除數據集中任意一條記錄可以對最后查詢結果造成多大的改變。即查詢函數f(·)最大的變化范圍,比如查詢數量,敏感度就是1。
全局敏感度:設有函數f:D→Rd,D為輸入數據集,輸出R為d維實數向量。對于任意的鄰近數據集D和D',ΔGf= ||f(D)-f(D')||1稱為函數f的全局敏感度。其中,||f(D)-f(D')|| 1之間的1-階范數距離。
函數的全局敏感度由函數本身決定,不同函數的全局敏感度可能不同。有的函數的全局敏感度較大(如中位數函數),有的函數的全局敏感度較小(如計數函數,全局敏感度為1)。中位數函數:設數據集中有n個數據,x1=x2=...=xi=a,xi+1=...=xn=b,當修改一個數據時,可能對結果造成較大的影響。如果全局敏感度較大,必須添加足夠大的噪聲才能保證數據的隱私安全,這使得數據效用減小。為解決這個問題,有人提出了局部敏感度。
2.1.3 "差分隱私的性質
當遇到復雜的隱私保護問題時,需要多次使用差分隱私。在這種情況下,為了保證整體的隱私預算,需要進行合理的隱私預算分配。在分配過程中,可以利用差分隱私技術的組合性質:
序列組合性[16]:設有算法M1,M2,...,Mn,隱私保護預算分別為ε1,ε2,...,εn,那么對于同一數據集D,由這些算法構成的算法M(M1(D),M2(D),...,Mn(D))提供 差分隱私保護。
說明:如果算法序列的輸入是同一個數據集,則這個算法序列的隱私預算為所有算法的隱私預算總和。
并行組合性[16]:設有算法M1,M2,...,Mn,其隱私保護預算分別為ε1,ε2,...,εn,那么對于不相交的數據集D1,D2,...,Dn,由這些算法構成的組合算法M(M1(D1), M2(D2),...,Mn(Dn))提供max(εi)-差分隱私保護。
說明:如果算法序列的輸入是不相交的數據集,則這個算法序列的隱私預算為算法序列中最大的隱私預算。
2.2 "擾動機制
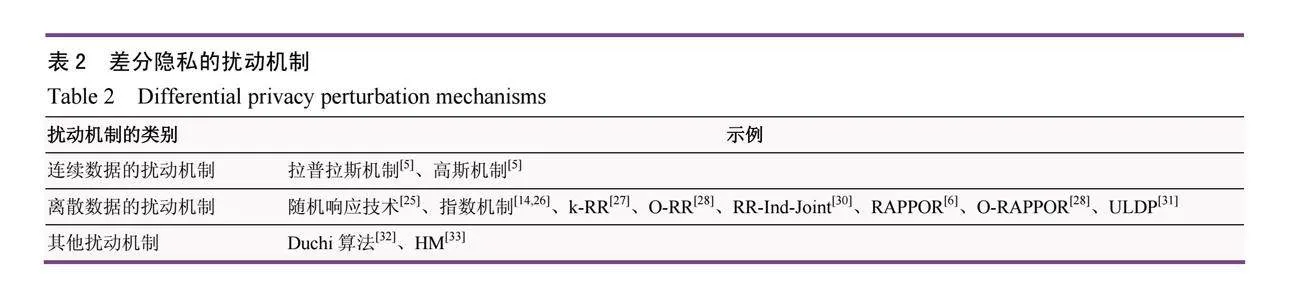
差分隱私于2006年提出,由于它具有強隱私保障,還可以量化隱私可能泄露的程度,所以自提出以來逐漸成為隱私保護領域的標準。一般來說,使用差分隱私有四個步驟,收集數據、擾動數據、發布數據、使用數據。在這四個步驟中,最為核心的步驟就是擾動數據,差分隱私的擾動機制一般分為三類:針對連續數據的擾動機制、針對離散數據的擾動機制和其他擾動機制(見表2)。
2.2.1 "連續數據的擾動機制
最經典的連續數據擾動方法是拉普拉斯機制[5],通過在真實數據上添加符合拉普拉斯分布的噪聲來保護原始數據,適用于連續數據。拉普拉斯機制簡單直觀、強隱私保證、適用性廣泛,適用于各種類型的查詢和數據集。因此,拉普拉斯機制在實際場景中被廣泛應用。
拉普拉斯機制:給定數據集D,設函數f:D→Rd,為滿足ε-差分隱私,拉普拉斯機制的返回結果為
M(D)=f(D)+Y
其中,M是隨機算法,M(D)是最后返回的結果(查詢之后擾動的結果);f是查詢函數,f(D)是查詢結果;Y是拉普拉斯隨機噪聲,是獨立同分布的隨機變量,服從尺度參數b為 的拉普拉斯分布。
2.2.2 "離散數據的擾動機制
拉普拉斯機制是簡單地對輸出的數值結果中加入噪聲實現差分隱私,而對于離散型數據而言,它的輸出是一組不相關的元素。經典的離散數據擾動方法有隨機響應技術(Randomized Response Technique)、指數機制(Exponential Mechanism)、k-RR及其優化機制、RAPPOR及其優化機制等。
(1)隨機響應技術
隨機響應技術[25]是當被詢問一個問題時,回答者以一定概率給出準確的答案,也以一定概率給出隨機的答案,這種隨機性保護了回答者的個人隱私,因為無法確定回答者的回答是否真實,同時,由于隨機響應的答案數量足夠多,可以通過統計分析得出準確的答案。適用于離散型數據或二進制數據的發布場景,例如對于是否患有某種疾病、是否購買某種商品等情況的調查統計,隨機響應技術可以在保護個體隱私的同時提供一定程度的數據分析準確性。隨機響應技術簡單易行,可以很容易地與現有的數據收集和發布系統集成,但是當數據量不夠時,或者可能的回答超出兩種時,這個方法就無法使用。舉個例子:假定有n個用戶,其中艾滋病患者的真實比例為π,其統計量為 。用戶在提交答案前需要按照一個擾動概率p進行擾動,即用戶以概率p回答真實的答案,1-p回答虛假的答案。則最后收集到的回答“是”和“否”的比例如下:
P(Xi=是)=πρ+(1-π)(1-ρ)
P(Xi=否)=π(1-ρ)+(1-π)ρ
顯然,這不是π無偏估計,因此需要修正。假定回答“是”的人數有n1,通過極大似然估計可以得到修正后的統計結果為: 。同時,為了保證算法滿足差分隱私,隱私預算應該設置為: 。
(2)指數機制
指數機制[26]不僅考慮了查詢結果中的每個元素的概率分布,還考慮了元素之間的相對重要性。指數機制的思想是基于數據項之間的敏感度來確定輸出結果的概率分布,使得概率與敏感度成指數關系。這樣,具有較高敏感度的數據項將具有較低的概率被輸出,從而保護隱私。指數機制適用于需要發布查詢結果的場景并且需要保護用戶的隱私,如數據分析、統計查詢等。
指數機制:設隨機化算法M輸入為數據集D,輸出為一個實體對象Ri∈R,μ(D,R)為效用函數,?μ為函數μ(D,R)的敏感度,若以正比于 的概率從輸入中選擇并輸出Ri,則算法M是滿足差分隱私。
(3)k-RR及其優化機制
隨著人們對數據保護需求的增多,這些經典的擾動方法已經不能滿足需求,于是很多學者提出新的數據擾動方法,或是對這些經典方法進行修改以適應新需求。Kairouz等人[27]將隨機響應技術擴展到多個候選值的情況,提出一種新的隨機響應技術k-RR。它適用于需要在保護隱私的同時提供更高的數據效用的場景,特別是在需要發布數據時保持數據的分布特性或者提供更精確的結果時使用。
k-RR機制:對于任意的輸入R∈X,其響應輸出R′∈X的方式如下公式所示:
即有 的概率擾動為原來的結果(真實值),以 的概率擾動為其余k-1個結果中的其中一個,使其滿足差分隱私。
為解決k-RR機制需要知道變量的定義域才能進行加噪的問題,Kairouz等人[28]在k-RR機制的基礎上引入哈希映射和分組操作,提出了O-RR方法。O-RR方法無需預先知道變量的定義域,可以直接進行隨機響應。Ma等人[29]采用Hadamard響應算法在降低通信成本的同時,提高了結果的準確性。隨著屬性數量的增加,屬性值組合的數量呈指數增長,極大地影響了隨機響應估計的計算成本和準確性。Kikuchi等人[30]提出一種技術RR-Ind-Joint,將所有屬性獨立隨機化,然后將這些隨機化矩陣聚合為單個聚合矩陣,之后再估計多維聯合概率分布。聚合隨機化矩陣的逆矩陣可以在輕量級計算成本和可管理的存儲需求下有效地計算。
為更好地進行統計工作Erlingsson等人改進隨機響應技術的思想,提出了RAPPOR方法[6],這個方法將數據編碼為一系列的值,然后進行擾動,數據中心接收到數據之后,再按規則進行聚合。這個方法和隨機響應技術一樣,可以將擾動后的數據聚合在一起,以獲得整體統計信息,而不泄露個體數據。
(4)RAPPOR及其優化機制
RAPPOR方法:假設總共有n個用戶端,第i個用戶端Ui對應某個敏感取值xi∈Χ,且|Χ|=k,現在希望統計取值xi(1≤i≤k)的頻數,RAPPOR方法分為兩部分,客戶端擾動數據如圖1所示,數據收集者收集數據如圖2所示。RAPPOR適用于需要同時考慮局部和全局敏感度的場景,它通過將局部擾動和全局擾動相結合,以最大限度地保護隱私,并在數據發布中提供高效的數據利用。
用戶端:
① 使用h個哈希函數將客戶端的值v哈希到大小為k的布隆過濾器B上;
② 永久隨機響應:將前一步哈希得到的布隆過濾器B擾動為B′。即將每一位Bi擾動為Bi′。
③ 瞬時隨機響應:分配大小為k的位數組S并初始化為0。數組S中各位為1的概率:
④ 報告:向服務器發送S。
數據收集者:
① 客戶被分配成為m個群組之一的永久成員,客戶端提交報告時,也需要說明其屬于哪個群組;
② 統計群組中每一位上1的個數,組成一個向量Y;
③ 候選串個數為M,將每一個候選串的Bloom Filter映射值拼接,得到映射矩陣X;
④ 利用Lasso回歸,求Ymk×1=Xmk×M × βM×1系數βM×1,這個系數(M維向量)就是每個候選串出現的次數。
針對RAPPOR方法需要預先知道變量定義域的問題,Kairouz等人[28]提出O-RAPPOR方法解決這一問題。O-RAPPOR和O-RR相同,都是通過引入了哈希映射和分組的操作,解決RAPPOR需要知道變量定義域才能進行擾動的問題。Murakami等人根據實際需求對RAPPOR進行了改進,提出了效用優化本地差分隱私[31]。這種方法中敏感數據只能擾動為敏感數據,也可以個性化地將自己獨有的敏感數據擾動為敏感數據,這樣不僅可以進一步提高數據的可用性,還可以個性化地保護用戶的隱私。這類方法在簡單的問題中效果較好,但是在數據量大,維度高,連續數據和離散數據組合的時候,并不方便使用。
(5)其他擾動機制
在多維數據中,會出現連續數據和離散數據組合的問題,Duchi等人[32]提出了一種在LDP下擾動多維數字元組的方法。這種方法可以在包含連續數據和離散數據的多維數據情況下使用,同時能夠得到方差較小的統計結果。但當ε較大時,Duchi等人提出的這種方法的性能比不上拉普拉斯機制。基于上述問題,Ning等人[33]提出了新的差分隱私擾動方法混合機制。與Duchi等人提出的方法相比,這種方法易于實現也易于理解,同時可以實現漸近最優誤差。
3 "面向高維數據的差分隱私發布技術現狀
隨著數字化進程的加快,使得所擁有的數據量越來越大,數據結構越來越復雜,數據特點逐漸由低維向高維轉變。當前高維數據發布的算法主要是簡單的基于降維的方法,如Li等人[34]提出的方法,該方法首先使用主成分分析降低數據的維度,然后通過引入敏感偏好理論設計隱私保護,設計出了可以對敏感屬性進行分級保護的高維數據集發布算法。但各種特征降維方法的計算復雜度,會隨著數據維度的增加而迅速增加。另外,將數據降維保護后再發布數據,會減少數據的屬性,導致數據的效用大大降低。且這種傳統的數據保護技術并沒有數學上嚴格定義的隱私保障,未必能夠抵抗不同背景知識的攻擊者。
隨著差分隱私的不斷發展完善,人們將其拓展至高維數據領域,期望差分隱私可以在保證高維數據安全的情況下,發布效用更高的數據。但處理高維數據時,直接使用傳統的差分隱私技術面臨諸多挑戰。因為高維數據通常具有復雜的結構和關系,使用傳統差分隱私方法可能會導致數據效用低下和隱私保護不足。這種情況要求開發新的算法和技術,以更好地適應高維數據的特點。基于上述需求,面向高維數據的差分隱私發布技術逐漸發展起來。
差分隱私在高維數據發布中的應用主要分為兩類。第一類是基于數據降維的方法,它通過對降維后的數據,或是降維過程進行加噪,以此來保護數據;另外還有數據合成的方法,他們結合機器學習的方法,學習數據集的分布特征,合成新的數據集,然后再發布。
3.1 "數據降維
Chaudhuri等人[35]將指數機制用在主成分分析選擇k維子空間的階段,由此將差分隱私和主成分分析(PCA)結合,提出了基于差分隱私可用于高維數據發布的數據保護算法PPCA。具體過程如算法1所示。首先輸入矩陣Xd×k、隱私預算ε、維數k,然后計算 ,再通過A去計算賓厄姆分布,即 。
另外,Jiang等人[36]提出PPDP方法,將隱私預算分為兩部分,分別是用于主成分分析中去構建噪聲協方差矩陣的部分,和用于主成分分析中對投影矩陣加噪的部分,通過這兩部分的操作將差分隱私的拉普拉斯機制和主成分分析結合。具體步驟如下:
1) 給定一個矩陣Xn×p,假設矩陣中的每個元素的取值都在[0, 1],計算∑x∈Xx和∑x∈XxxT。
2) 在∑x∈Xx的每個元素和∑x∈XxxT的上三角加上Lap(2s/ε),得到x和xxT的噪聲和,然后將∑x∈XxxT的下三角對稱地填充上三角。
3) 用樣本數n除以噪聲和,得到E[X]noisy和E[XXT]noisy。
4) 步驟3確保 =E[XXT]noisy-E[X]noisyE[X]Tnoisy是對稱矩陣。可對其進行特征分解 ,并從 中選擇特征值最大的k ≤ p個特征向量組成 。
5) 在(X-E[X]noisy) "上添加噪聲Lap(2 ),乘以 ,并在每個樣本上添加E[X]noisy,得到噪聲X。
Yang等人[37]通過分析發現,在同一個環境中,先對數據進行加噪處理的方法和先對數據進行特征選擇處理的方法相比較,先對數據進行加噪處理的方法保護效果更好。由于不同的降維方法適用于不同的機器學習,降維后的數據很難適用于大多數模型訓練,隨著機器學習的進一步發展,這類方法的研究逐漸減少。
3.2 "數據合成
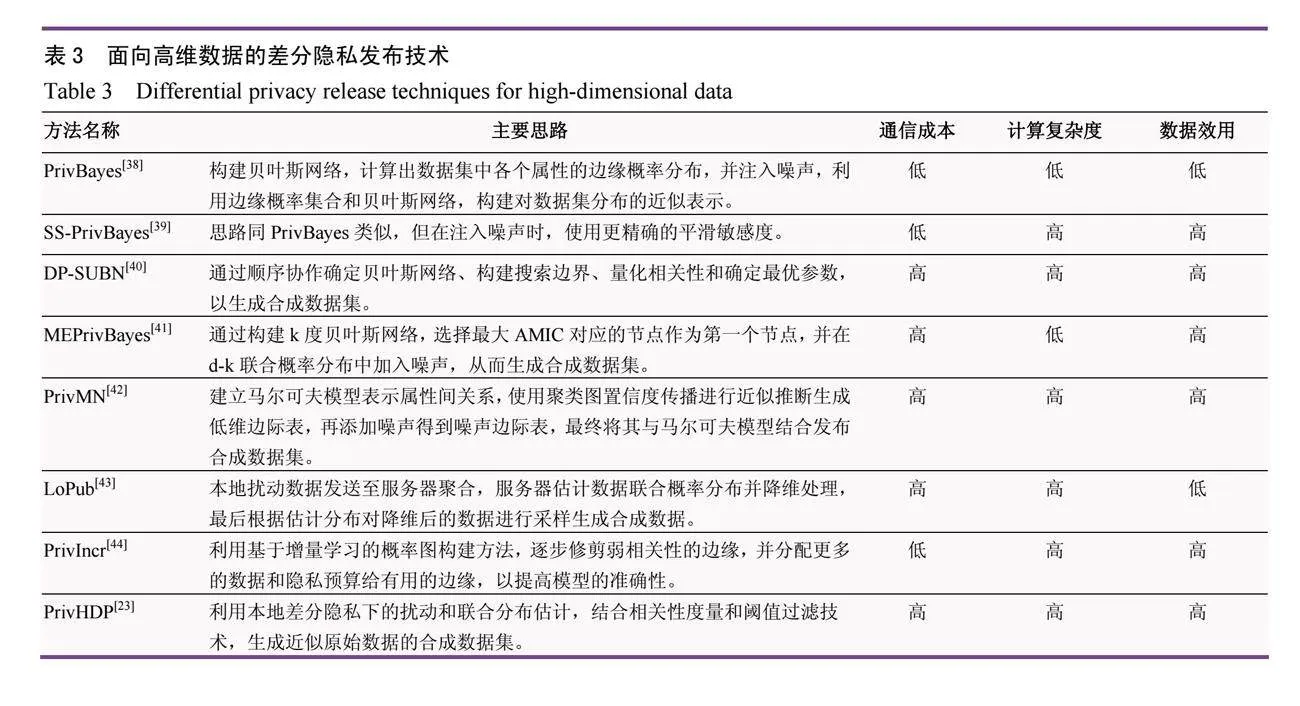
目前,針對高維數據的差分隱私發布技術主要采用數據合成方法。本文收集了2014年到2023年期間的相關論文進行了分析比較。其中,諸如PrivBayes[38]、SS-PrivBayes[39]、DP-SUBN[40]、MEPrivBayes[41]等方法均采用了貝葉斯網絡建模。PrivBayes方法和SS-PrivBayes方法通過構建貝葉斯網絡模型來理解數據屬性之間的相互關系,他們適用于處理大規模數據和高相關性的高維數據;而DP-SUBN方法則考慮到了分布式多方環境的需求,適用于在分布式多方環境中發布高維數據的情況;MEPrivBayes則解決了貝葉斯網絡結構不穩定和隱私預算分配不合理的問題,適用于解決現有基于貝葉斯網絡的差分隱私高維數據發布方法中數據可用性不穩定的問題。此外,PrivMN[42]方法利用馬爾可夫模型表示屬性之間的關系,適用于處理實際應用中變量之間的關系無法確定的情況。而LoPub[43]、PrivIncr[44]和PrivHDP[23]等方法則通過估計數據的聯合概率分布或概率圖模型,然后對數據進行降維采樣,由此得到合成數據,適用于在分布式用戶場景下實現本地隱私保護和數據發布。上述這些方法豐富了差分隱私發布技術的應用領域,并為處理高維數據提供了多樣化的選擇。
表3整理了面向高維數據的差分隱私發布技術,其中介紹了PrivBayes、SS-PrivBayes、DP-SUBN等方法的主要思路,并從通信成本、計算復雜度、數據效用等不同的維度分析各個方法。
Zhang等人[38]提出了一種用于發布高維數據的差分隱私方法PrivBayes,通過將噪聲注入低維邊緣概率集合P中,避免了維度詛咒。PrivBayes具體流程如圖3所示,首先構建一個貝葉斯網絡N,以簡潔建模數據集D中屬性之間的相關性,并利用低維度的邊緣概率來近似表示數據集D的分布。然后,對P中的每個邊緣概率進行注入噪聲,以確保差分隱私。最后,通過使用注入噪聲后的邊緣概率集合P和貝葉斯網絡N,構建了對數據集D的分布的近似表示,并從近似分布中對元組進行采樣,以構建合成數據集。該方法通信成本低,靈活性高,數據效用低。
隨后,Li等人[39]提出SS-PrivBayes算法,解決基于貝葉斯網絡的差分隱私保護發布方法[38]在數據量大、相關性高時,數據實用性較差的問題。它通過使用更精確的平滑敏感度來減少額外的噪聲,提高數據實用性,降低數據失真,適用于處理大數據量和高相關性數據。該方法與PrivBayes相比通信成本降低,數據效用提高,通信成本增加。
Cheng等人[40]提出貝葉斯網絡差分隱私順序更新(DP-SUBN)方法,解決分布式多方環境中發布高維數據時,管理者半可信的問題。DP-SUB中生成合成
數據集的方式是各方和管理員先以順序的方式協作確定最適合集成數據集的貝葉斯網絡。該方法核心是構建搜索邊界,用以指導各方更新先驗知識。通過精確和啟發式的方法,利用屬性對之間的相關性構建搜索邊界,并提出了非重疊覆蓋設計(NOCD)方法來私下量化屬性對的相關性,進而設計了確定NOCD中最優參數的動態規劃方法。該方法數據效用高,靈活性高,但是計算復雜、通信成本高,且依賴先驗知識。
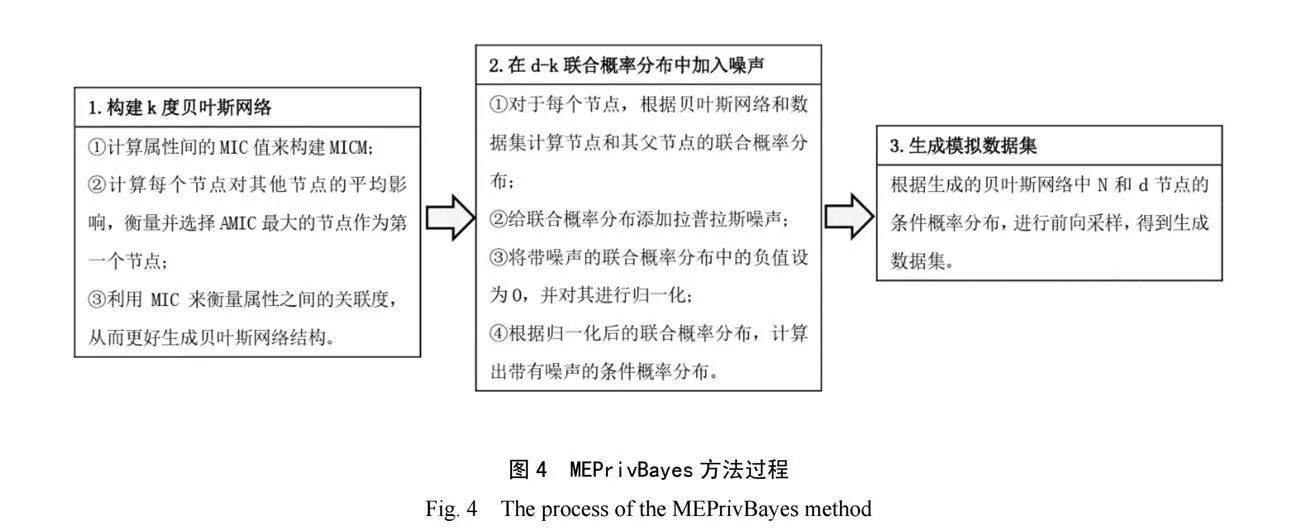
Lu等人[41]對PrivBayes算法[38]進行改進,提出MEPrivBayes方法。它從貝葉斯結構不穩定和隱私預算分配策略不合理兩個方面,解決現有基于貝葉斯網絡的差分隱私高維數據發布方法中數據可用性不穩定的問題。MEPrivBayes方法分為三個步驟,具體流程見圖4。首先構建k度貝葉斯網絡,選擇最大AMIC對應的節點作為第一個節點,解決隨機選擇第一個節點的貝葉斯網絡結構不穩定問題。然后在d-k聯合概率分布中加入噪聲,以滿足ε-差分隱私。最后從貝葉斯網絡中采樣,生成模擬數據集。該方法通信成本高,數據效用高。
Wei等人[42]結合馬爾可夫模型提出一種新的方法PrivMN,它利用馬爾可夫模型來表示屬性之間的相互關系,解決實際應用中變量之間的關系無法確定的問題,然后利用近似推理計算差分隱私下高維數據的聯合分布。這種方法通過優化推理過程來處理高維數據
中普遍存在的數據稀疏問題,從而減少噪聲,保持數據的實用性。具體來說分為如下四個部分。該方法靈活性高,數據效用較高,但是計算復雜,通信成本高,且依賴先驗知識。
(1)表示屬性關系。使用圖形模型表示屬性之間的關系,建立馬爾可夫模型。
(2)近似推斷。根據聚類圖置信度傳播的方法對模型進行近似推斷,由此得到低維邊際表。
(3)生成噪聲邊際表。通過拉普拉斯機制向低維邊際表中添加噪聲,得到噪聲邊際表。
(4)發布合成數據集。將噪聲邊際表與馬爾可夫模型相結合,生成合成數據集。
Ren等人[43]提出的發布高維數據的LoPub方法。首先每個用戶通過RAPPOR方法對元組進行擾動,然后將其發送給數據收集者;數據收集者估計數據的聯合概率分布,并對數據進行數據降維;再使用前面估計的聯合概率分布去合成一個數據集。這種方法在構建聯合概率分布時注入大量的噪聲,從而降低了合成數據的質量。具體來說分為如下四個模塊。總的來說,該方法通信成本高,計算復雜,但是數據效用低。
(1)本地隱私保護。通過引入局部轉換過程和隨機響應技術,將原始多維數據記錄以局部隱私的形式隱藏在分布式用戶中,并將經過本地隱私保護的數據發送至中央服務器進行聚合。
(2)多維分布估計。提出了多維聯合分布估計方案,包括基于EM的高維估計、基于Lasso的快速估計和在精度和效率之間取得平衡的混合方法。
(3)降維。本文提出了一種降維方法,將高維屬
性劃分為緊湊的低維屬性簇,考慮了異構屬性,并利用互信息和無向依賴圖來度量和建模屬性相關性,同時引入啟發式修剪方案以提高相關性識別過程的效果。
(4)合成新數據集。根據每個屬性簇上估計的聯合分布或條件分布對每個低維數據集進行采樣,從而合成一個新的隱私保護數據集。
Liu等人[44]提出基于增量學習的概率圖構建方法合成數據,提高合成數據質量,解決LoPub[43]需要計算大量屬性對的邊緣值來構建PGM,且不能很好地計算PGM中大團的邊緣分布,從而降低了合成數據的質量。它逐漸修剪具有弱相關性的邊緣(屬性對),并將更多的數據和隱私預算分配給有用的邊緣,從而提高模型的準確性。該方法計算復雜,但是數據效用高,靈活性高。
蔡夢男等人[23]針對現有方案在構建概率圖模型和計算大規模屬性子集的聯合分布時存在的高計算復雜度問題,提出了一種本地差分隱私下的高維數據發布方法PrivHDP。它在用戶本地對數據進行擾動,保證每個用戶的輸出滿足本地差分隱私,將擾動后的數據發送到服務器。然后使用兩種分布估計方案計算成對屬性的邊緣分布,并根據估計誤差的影響選擇適當的方法和擾動機制。再引入新的相關性度量方法,結合閾值過濾技術構建Markov網,生成一組屬性子集。將屬性子集的聯合分布分解為條件概率的乘積,消除條件獨立性,得到更精確的聯合分布。最后根據屬性子集的聯合分布和子集間的相關性,對低維屬性數據集進行采樣,得到近似原始數據的合成數據集。該方法靈活性高,數據效用高,但計算復雜,通信成本高。
4 "面向高維數據發布的差分隱私技術的應用
在現代數據科學中,面向高維數據發布的差分隱私技術的應用日益受到關注。隨著大數據時代的到來,人們對數據隱私和安全的重視程度不斷增強,尤其是涉及個人敏感信息的高維數據。在這種背景下,差分隱私技術作為一種有效的隱私保護機制,被廣泛應用于高維數據發布中。本章將探討差分隱私技術在處理高維數據時在不同領域中的應用場景和挑戰。
4.1 "在醫療健康領域的應用
在醫療領域,數據通常是高維的,其中涉及患者的個人隱私信息,包括疾病診斷、治療記錄、基因信息等,具有高度敏感性和隱私性[45]。然而,醫療研究和數據分析需要對這些數據進行共享和分析,以促進疾病診斷、藥物研發等工作。這就帶來了一個挑戰,即如何在共享數據時保護患者的隱私,同時又能夠提供有效的數據分析和挖掘[46]。差分隱私為解決這一問題提供了一種有效的解決方案。通過差分隱私技術,醫療數據的發布者可以在不泄露患者個人信息的前提下,共享醫療數據給醫療研究機構、醫生或者其他合法的數據分析者。
白伍彤等人[47]提出了一項基于差分隱私的健康醫療數據保護方案。針對醫療數據的高維度和高敏感性,該方案首先對數據進行匿名化處理,然后將數據分為連續數據和離散數據,并分別加入噪聲。此外,該方案還設置了誤差參數和誤差統計個數,通過調節這兩個參數來平衡隱私保護和數據效用之間的關系。最后,為了進一步保證數據的安全性,數據以加密方式存儲,只有使用者在獲得授權密碼后才能解密并使用數據。
Zhang等人[48]提出了一種基于屬性相關性的分類樹差分隱私數據發布算法(ACDP-Tree)。該算法首先對HIS原始數據集進行預處理,刪除其中的識別屬性,并對每個離散的準識別屬性進行泛化處理,以建立屬性泛化樹。其次,通過屬性相關性評價方法來評估準識別屬性與敏感屬性之間的相關性強度。值越小,表示隱私保護程度越高。對于數據集中的離散數據,根據屬性泛化樹進行迭代分割;而對于連續數據,則利用索引機制找出最佳的分割點,并逐步進行迭代分割。在分割完成后,對葉節點進行計數并添加拉普拉斯噪聲,以后續發布葉節點數據。
榮劍[49]提出了一種基于差分隱私保護的電子病歷數據安全風險監測系統。通過對傳統風險監測系統采用差分隱私保護模式進行系統優化,構建了電子醫療記錄數據安全風險監測系統的硬件框架,從而確保了數據安全監測系統的安全性能。在這個系統中,還建立了敏感性差分隱私算法,通過增加噪聲變量來進一步保護數據隱私。隨后,對電子醫療記錄數據進行分析,以獲取更高安全性的數據信息。最后,采用模糊分析方法發送安全預警信息,從而實現了數據安全的改善。這些措施的實施有效地提高了數據的安全性,為醫療數據的使用和共享提供了可靠的保障。
總體而言,差分隱私技術在醫療數據發布中的應用可概括為以下幾個方面:(1)數據共享與合作研究:醫療機構或研究機構可能需要共享醫療數據以進行合作研究,如疾病預測、流行病學調查等。差分隱私技術可以保證在共享數據時不泄露患者的隱私信息,同時又能夠保持數據的有效性。(2)藥物研發與臨床試驗:利用差分隱私技術,醫藥公司可以共享臨床試驗數據或病患基因信息給研究人員,用于藥物研發和個性化的治療。通過保護患者隱私,差分隱私技術有助于推動醫藥研發的進程。(3)個性化醫療與診斷:基于大規模醫療數據的個性化醫療已成為醫療領域的熱點。差分隱私技術可以幫助醫生或醫療研究人員在不暴露患者隱私的情況下,利用醫療數據進行個性化診斷和治療方案制定。(4)公共衛生政策:政府部門或公共衛生機構可能需要使用醫療數據來制定公共衛生政策或應對突發傳染病。差分隱私技術可以在確保數據安全的同時,為政府部門提供足夠的數據支持。
差分隱私技術在面向高維數據發布的醫療應用中具有廣泛的應用前景,可以為醫療研究、臨床實踐和公共衛生政策提供安全可靠的數據共享解決方案,從而促進醫療領域的發展和進步。
4.2 "在金融領域的應用
金融數據通常涉及個人賬戶信息、交易記錄、財務報表等,這些數據包含著大量的敏感信息,如個人身份、財務狀況等,因此需要進行有效的隱私保護[50]。同時,金融機構和監管部門需要對這些數據進行分析和共享,以支持風險評估、反欺詐、信用評分等業務活動[51-52]。在這種情況下,差分隱私技術成為一種理想的隱私保護和數據共享解決方案。
鄧蔚等人[53]提出了一種基于樹模型的差分隱私保護算法,并在金融數據集上進行了實驗驗證。該算法采用了CART決策樹,并將差分隱私保護機制融入其中,形成了差分隱私保護的決策樹。接著,他們將CART決策樹與隨機森林相結合,并與差分隱私算法相融合。在處理多個連續特征的情況下,將隱私保護預算平均分配給各個連續特征,并為離散特征保留了一份。通過索引機制選擇最佳的連續特征及其分裂點,并計算其相應的基尼指數。針對每個離散特征,比較其在不同分裂方式下的基尼指數,選擇最小的作為最佳的分裂特征,直至預算耗盡或滿足停止條件。隨機森林的差分隱私保護算法采用了相同的策略,生成適合數據集的CART決策樹。
Byrd等人[54]為解決金融領域中數據隱私和安全性問題,提出了一種基于差分隱私的安全多方計算框架,應用于金融領域中的聯邦學習。該框架中,差分隱私被用于聯邦學習場景中,以確保參與者在共同進行模型訓練時不會泄露其私密數據。通過將差分隱私技術與安全多方計算相結合,參與者可以在加密狀態下進行計算,而無需揭示原始數據。這樣一來,即使在聯網學習過程中,各方之間進行數據交互,也能夠保護數據的隱私性。
總體而言,差分隱私技術在金融領域的數據發布中的應用可概括為以下幾個方面:(1)保護金融機構和客戶的隱私。金融機構可能需要共享客戶數據給第三方服務提供商或數據分析公司,以進行客戶畫像、精準營銷等活動。通過應用差分隱私技術,可以在不暴露客戶個人敏感信息的前提下,共享數據給其他機構,從而保護客戶隱私。(2)幫助金融監管部門進行數據分析和監管。監管部門需要對金融機構的交易數據進行監控和分析,以發現潛在的風險和違規行為。通過差分隱私技術,監管部門可以在保護個人隱私的同時,獲取足夠的數據支持,實現對金融市場的監管。(3)金融數據的合成和共享。金融機構可能需要生成合成數據集,用于模型訓練、算法測試等目的,而合成數據集必須保持原始數據的特征和分布。通過差分隱私技術,可以在保護數據隱私的同時,生成具有相似統計特性的合成數據,用于數據共享和數據分析。
差分隱私技術在金融領域的應用涵蓋了數據隱私保護、監管數據分析和數據共享等多個方面。它為金融機構、監管部門和數據分析公司提供了一種安全可靠的數據共享和分析解決方案,有助于推動金融行業的數字化轉型和發展。
綜上所述,面向高維數據發布的差分隱私應用在保護個人隱私的同時,為數據分析和共享提供了一種有效的解決方案。通過不斷地研究和創新,可以進一步提高差分隱私在高維數據領域的應用效果,推動隱私保護和數據分析的發展。
5 "問題與挑戰
5.1 "現有研究的不足
就差分隱私的擾動技術來說,當前大部分離散數據擾動方法都側重于平衡計算復雜度,適用范圍等方面的問題。但是值得注意的是,收集離散數據的基本問題沒有得到充分地解決,離散數據擾動方法擾動的數據效用并不高。現有的大部分方法都未考慮候選值本身的差異,平等地將每個數據擾動到其他的候選值,這種做法在一定程度上,影響了數據的效用。
針對基于差分隱私的高維數據發布技術現狀來說,當前差分隱私在高維數據發布中的應用研究主要偏向于使用數據合成方法對數據進行處理之后再發布,不可否認,這種方法優勢很多,但是也存在如下問題:這樣發布的數據蘊含的原始信息會降低,很難再用于統計工作;合成數據可能無法完全模擬真實世界的復雜性和多樣性,如果將數據用于訓練,模型在合成數據上表現良好并不一定能夠很好地泛化到真實數據。
而差分隱私在深度學習中的應用中,直接將差分隱私作用于模型的方法能很好保護模型,但他并不能使得最后的模型性能最優。而直接使用隱私保護后發布的高維數據,無法抵御模型反演攻擊的問題,難以保障模型的安全性。
5.2 "未來研究的方向
在面對當前研究存在的不足時,為了推動差分隱私領域的進一步發展,我們提出了一系列簡明而實用的解決方案。這些方案旨在應對離散數據擾動方法、基于差分隱私的高維數據發布以及差分隱私與深度學習融合等方面的問題。通過更智能的擾動策略、更高效的差分隱私方法以及兼顧隱私與模型性能的深度學習模型設計。除此之外,我們還期望為未來研究提供有益的指導和啟示。
5.2.1改進差分隱私算法
從第三節的分析可以看出,現有的大多數解決方案都側重于復雜的數據類型或復雜的數據分析任務。但是值得注意的是,收集離散數據的基本問題沒有得到充分解決。當前大部分離散數據的加噪方法都是未考慮候選值本身的差異,平等地將數據擾動到各個候選值,這種做法在一定程度上,影響了數據的效用。比如針對離散數據擾動方法,可以考慮候選值本身的差異,而非平等擾動所有候選值。這種個性的擾動策略有助于提高數據效用,實現隱私與數據質量的平衡。未來研究方向可考慮改進差分隱私算法,減少噪音引入,進一步提高高維數據發布中的隱私保護效果,提高數據質量仍然值得研究。
5.2.2 基于差分隱私的高維數據發布
當前高維數據發布領域使用的隱私保護方法偏向于發布合成后的數據,但合成數據無法完全模擬真實高維數據的復雜性和多樣性。所以研究人員可以從改進噪聲添加策略、查詢優化技術等方面探索更高效、更精確的用于高維數據的差分隱私方法,以平衡隱私保護和數據分析的準確性。而為了達到維持高維度和反映真實多樣性的目標,可能需要采用更先進的算法和模型。
5.2.3差分隱私與深度學習的融合
隨著數字化進程加快,具有復雜的結構和關系,蘊含豐富語義信息,通常具有幾十上百維特征的高維數據越來越多。直接使用這些高維數據來進行模型訓練,會泄露敏感信息,所以保護訓練數據中的敏感信息成了一個重要課題。雖然當前差分隱私和深度學習結合的工作已經非常多了,但是通過上面的分析可以看到,在隱私保護和數據效用的權衡上,仍然存在問題。所以未來可以更注重平衡隱私與模型性能,結合高維數據和差分隱私的特性進行研究。可能的解決方案包括改進模型結構、訓練算法和梯度更新機制,設計更隱私友好、兼顧效用的深度學習模型。這些簡單而有前瞻性的建議有望為當前研究提供有效的方向。
6 "結束語
本文介紹了差分隱私的原理和特性,總結歸納了差分隱私當前在高維數據中的應用等工作。希望通過本文,為研究者提供一個全面的視角,推動其對差分隱私領域更進一步的探索。高維數據的發布與保護是數據科學領域亟待解決的難題,希望本綜述對當前數據科學領域面臨的高維數據保護和使用問題產生積極的影響,為未來的研究和應用提供有益的啟示,促使更多前沿技術的涌現,推動差分隱私在高維數據應用中取得更大突破。
參考文獻
[1] Zeng D D, Liu Y, Yan P, et al. Location-aware real-time recommender systems for Brick-and-Mortar Retailers[J]. INFORMS Journal on Computing, 2021, 33:1608-1623. https://doi.org/10.1287/ijoc.2020. 1020.
[2] The EU General Data Protection Regulation (GDPR). [EB/OL]. . https://eur-lex.europa.eu/eli/reg/2016/679/oj.
[3] The California Consumer Privacy Act (CCPA) [EB/OL]. https://cdp. cooley.com/ccpa-2018/.
[4] Data Security Law of the People's Republic of China [EB/OL]. [2021-06-13]. https://www.gov.cn/xinwen/2021-06/11/content_5616919.htm.
[5] Dwork C, McSherry F, Nissim K, et al. Calibrating Noise to Sensitivity in Private Data Analysis[C]. Theory of Cryptography Conference, Lecture Notes in Computer Science, 2006. https://doi. org/10.1007/11681878_14.
[6] Erlingsson ú, Korolova A, Pihur V. RAPPOR: Randomized Aggregatable Privacy-Preserving Ordinal Response[C]. Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, 2014. https://doi.org/10.1145/2660267. 2660348.
[7] Ding X, Wang C, Choo K R, et al. A novel privacy preserving framework for large scale graph data publishing[J]. IEEE Transactions on Knowledge and Data Engineering, 2019, 33: 331-343. https://doi. org/10.1109/TKDE.2019.2931903.
[8] Draft NIST Privacy Framework: A Tool for Improving Privacy through Enterprise Risk Management. [EB/OL]. https://www.nist.gov/ system/files/documents/2020/01/16/NIST%20Privacy%20Framework_V1.0.pdf.
[9] Li X Y, Sun Z L, Deng J B, et al. A comprehensive review of privacy protection technologies[J]. Computer Science, 2013, 40(S2): 199-202.
[10] Li Y, Wen W, Xie G Q. A review of differential privacy protection research[J]. Journal of Computer Applications Research, 2012, 29(9): 3201-3205+3211.
[11] Zhao Y Q, Yang M. A review of research progress on differential privacy[J]. Journal of Computer Science, 2023, 50(4): 265-276.
[12] Gao Z Q, Wang Y T. Research progress on differential privacy techniques[J]. Journal of Communications, 2017, 38(S1): 151-155.
[13] Ye Q Q, Meng X F, Zhu M J, et al. A review of local differential privacy research[J]. Journal of Software, 2018, 29(7): 1981-2005.
[14] Liu J X, Meng X F. A review of privacy protection in machine learning[J]. Journal of Computer Research and Development, 2020, 57(2): 346-362.
[15] Ouadrhiri A E, Abdelhadi A M. Differential privacy for deep and federated learning: a survey[J]. IEEE Access, 2022, 10: 22359-22380. https://ieeexplore.ieee.org/document/9714350.
[16] Kong Y T, Tan F X, Zhao X, et al. A review of research on optimization of k-means algorithm based on differential privacy[J]. Journal of Computer Science, 2022, 49(2): 162-173.
[17] Wang T, Huo Z, Huang Y X, et al. A review of privacy protection technologies in federated learning[J]. Journal of Computer Applications, 2023, 43(2): 437-449.
[18] Narayanan A, Shmatikov V. Robust De-anonymization of Large Sparse Datasets[C]. 2008 IEEE Symposium on Security and Privacy (sp 2008), 2008. https://ieeexplore.ieee.org/document/4531148.
[19] Wang Z, Scott D W. Nonparametric Density Estimation for High- Dimensional Data—Algorithms and Applications[EB/OL]. https:// arxiv.org/abs/1904.00176.
[20] Chu X J. Research on High-Dimensional Data Publishing Method Meeting Local Differential Privacy[D]. Guizhou University, 2022. DOI: 10.27047/d.cnki.ggudu.2022.002172.
[21] Amaratunga D, Cabrera J, Shkedy Z. Exploration and Analysis of DNA Microarray and Other High-Dimensional Data (2nd edition) [EB/OL]. https://onlinelibrary.wiley.com/doi/pdf/10.1002/9781118364505. fmatter.
[22] Sweeney L. k-Anonymity: A model for protecting privacy[J]. Int. J. Uncertain. Fuzziness Knowl. Based Syst., 2002, 10: 557-570. https://doi.org/10.1142/S0218488502001648.
[23] Cai M G, Shen G H, Huang Z Q, et al. High-dimensional data publishing method under local differential privacy[J]. Journal of Computer Science, 2024, 51(2): 322-332.
[24] Zhang X, Chen H. A review of high-dimensional data publishing with differential privacy[J]. Journal of Intelligent Systems, 2021, 16(6): 989-998.
[25] Warner S L. Randomized response: a survey technique for eliminating evasive answer bias[J]. Journal of the American Statistical Association, 1965, 60(309): 63-6.. Warner-Randomized-Response-2283137.pdf (ncsu.edu).
[26] McSherry F, Talwar K. Mechanism Design via Differential Privacy[C]. 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS'07), 2007. https://doi.org/10.1109/FOCS.2007.41.
[27] Kairouz P, Oh S, Viswanath P. Extremal Mechanisms for Local Differential Privacy[C]. J. Mach. Learn. Res., 2016. https://jmlr.org/ papers/v17/15-135.html.
[28] Kairouz P, Bonawitz K A, Ramage D. Discrete Distribution Estimation under Local Privacy[C]. International Conference on Machine Learning. 2016. https://proceedings.mlr.press/v48/kairouz16. html.
[29] Ma X, Liu H, Guan S. Improving the Effect of Frequent Itemset Mining with Hadamard Response under Local Differential Privacy[C]. 2021 IEEE 20th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), 2021. https://doi.org/10.1109/TrustCom53373.2021.00072.
[30] Kikuchi H. Castell: Scalable Joint Probability Estimation of Multi-dimensional Data Randomized with Local Differential Privacy[EB/OL]. https://arxiv.org/abs/2212.01627.
[31] Murakami T, Kawamoto Y. Utility-Optimized Local Differential Privacy Mechanisms for Distribution Estimation[C]. USENIX Security Symposium. 2019. https://www.usenix.org/conference/ usenixsecurity19/presentation/murakami.
[32] Duchi J C, Wainwright M J, Jordan M I. Minimax optimal procedures for locally private estimation[J]. Journal of the American Statistical Association, 2016, 113: 182 - 201. https://arxiv.org/abs/1604.02390.
[33] Wang N, Xiao X, Yang Y D, et al. Collecting and Analyzing Multidimensional Data with Local Differential Privacy[C]. 2019 IEEE 35th International Conference on Data Engineering (ICDE), 2019. https://ieeexplore.ieee.org/document/8731512/.
[34] Li W, Zhang X, Li X, et al. "PPDP-PCAO: An efficient high-dimensional data releasing method with differential privacy protection[J]. IEEE Access, 2019, 7: 176429-176437. https:// ieeexplore.ieee.org/document/8924645.
[35] Chaudhuri K, Sarwate A D, Sinha K. A near-optimal algorithm for differentially-private principal components[J]. Journal of Machine Learnning Research, 2013, 14: 2905-2943. https://dl.acm.org/doi/10. 5555/2567709.2567754.
[36] Jiang X, Ji Z, Wang S, et al. Differential-Private Data Publishing Through Component Analysis[J]. Transactions on data privacy, 2013, 6(1): 19-34 . https://www.tdp.cat/issues11/abs.a109a12.php.
[37] Yang J, Li Y. Differentially private feature selection[C]//2014 International Joint Conference on Neural Networks (IJCNN), 2014. https://www.sciencedirect.com/science/article/pii/S1877050914010412?via%3Dihub.
[38] Zhang J, Cormode , Procopiuc C M, et al. PrivBayes: private data release via bayesian networks[C]. Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data. 2014. https://dl.acm.org/doi/10.1145/2588555.2588573.
[39] Li M, Ma X. Bayesian Networks-Based Data Publishing Method Using Smooth Sensitivity[C]. 2018 IEEE Intl Conf on Parallel amp; Distributed Processing with Applications, Ubiquitous Computing amp; Communications, Big Data amp; Cloud Computing, Social Computing amp; Networking, Sustainable Computing amp; Communications (ISPA/IUCC/ BDCloud/SocialCom/SustainCom), 2018. https://ieeexplore.ieee.org/ document/8672292.
[40] Cheng X, Tang P, Su S, et al. Multi-Party High-Dimensional Data Publishing Under Differential Privacy[J]. IEEE Transactions on Knowledge and Data Engineering, 2020, 32: 1557-1571. https:// ieeexplore.ieee.org/document/8673599/.
[41] Lu X, Piao C, Han J. Differential Privacy High-dimensional Data Publishing Method Based on Bayesian Network[C]. 2022 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), 2022. https://ieeexplore.ieee.org/document/ 9853392.
[42] Wei F., Zhang W, Chen Y, et al. Differentially Private High- Dimensional Data Publication via Markov Network[C]. Security and Privacy in Communication Networks. 2018. https://link.springer. com/chapter/10.1007/978-3-030-01701-9_8.
[43] Ren X, Yu C, Yu W, et al. LoPub: High-Dimensional Crowdsourced Data Publication With Local Differential Privacy[J]. IEEE Transactions on Information Forensics and Security, 2018, 13(9): 2151-2166. https://ieeexplore.ieee.org/document/8306916.
[44] Liu G, Tang P, Hu C, et al. Multi-Dimensional Data Publishing With Local Differential Privacy[C]. International Conference on Extending Database Technology. 2023. https://openproceedings.org/2023/conf/ edbt/paper-210.pdf.
[45] Ray P, Reddy S S, Banerjee T S. Various dimension reduction techniques for high dimensional data analysis: a review[J]. Artificial Intelligence Review, 2021, 54: 3473-3515. https://link.springer.com/ article/10.1007/s10462-020-09928-0.
[46] Chen Y. Research on health and medical data sharing and personal information protection [J]. Journal of Intelligence, 2023, 42(5): 192-199.
[47] Bai W T, Chen L X. A health medical data protection scheme based on differential privacy[J]. Computer Applications and Software, 2022, 39 (8): 304-311.
[48] Zhang S, Li X. Differential privacy medical data publishing method based on attribute correlation[J]. Scientific Reports, 2022, 12. https://www.nature.com/articles/s41598-022-19544-3.pdf.
[49] Rong J. An electronic medical record data security risk monitoring system based on differential privacy protection[J]. Automation Technology and Applications, 2022, 41(12): 169-172.
[50] Tan L. Theory and Application of Dimensionality Reduction for High- dimensional Data [D]. National University of Defense Technology, 2005.
[51] Yuan K, Cheng Y. Data risks of financial technology and its prevention and control strategies [J]. Journal of Beijing University of Aeronautics and Astronautics (Social Sciences Edition), 2023, 36(2): 46-58.
[52] Zhu Z W, Zhang X. A brief analysis of privacy computing applications in the financial field[J]. Research on Financial Development, 2023(3): 90-92.
[53] Deng W, Chen X T, Zhang Q H, et al. Differential privacy protection algorithm based on Tree Models[J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2020, 32(5): 848-856.
[54] Byrd D, Polychroniadou A. Differentially private secure multi-party computation for federated learning in financial applications[C]. Proceedings of the First ACM International Conference on AI in Finance. 2020. https://dl.acm.org/doi/10.1145/3383455.3422562.
引用格式:龍春,秦澤秀,李麗莎,李婧,楊帆,魏金俠,付豫豪.面向高維數據發布的差分隱私算法及應用綜述[J].農業大數據學報,2024,6(2):170-184. DOI:10.19788/j.issn.2096-6369.200001.
CITATION: LONG Chun,, QIN ZeXiu, LI LiSha, LI Jing, YANG Fan, WEI JinXia, FU YuHao. Survey of Differential Privacy Algorithms and Applications for High- Dimensional Data Publishing[J]. Journal of Agricultural Big Data,2024,6(2):170-184. DOI:10.19788/j.issn.2096-6369.200001.
Survey of Differential Privacy Algorithms and Applications for High- Dimensional Data Publishing
LONG Chun1,2*, QIN ZeXiu1,2, LI LiSha1,2, LI Jing1, YANG Fan1, WEI JinXia1,2, FU YuHao1
1. Computer Network Information Center, Chinese Academy of Sciences, Beijing 100083, China; 2. University of Chinese Academy of Sciences, Beijing 100049, China
Abstract: With the further development of big data and machine learning technologies, handling high-dimensional data with complex structures, relationships, and rich semantic information containing dozens to hundreds of features has become a challenge. Safely utilizing such high-dimensional data, while ensuring the privacy of individuals, has become a significant topic today. Upon reviewing existing literature, we found numerous reviews on differential privacy technology itself, but few on the algorithms and applications of differential privacy specifically tailored for high-dimensional data. Therefore, this paper provides a review of the application of differential privacy in the field of high-dimensional data, aiming to delve into the strengths and weaknesses of different methods in protecting the privacy of high-dimensional data and to guide future research directions for differential privacy algorithms tailored for high-dimensional data publishing. Firstly, this paper introduces the principles and characteristics of differential privacy, summarizing the current research work on the technology itself. Then, it analyzes the application of differential privacy in high-dimensional data environments from the perspectives of data dimensionality reduction and data synthesis, discussing the challenges and issues faced by differential privacy and proposing preliminary solutions to better address the issues of privacy protection and data analysis in the current high-dimensional data landscape. Lastly, potential future research directions are proposed to facilitate technological exchange and further advancements in the application of differential privacy in high-dimensional data settings.
Keywords: differential privacy; high-dimensional data; perturbation mechanism; privacy allocation
