基于符號距離函數的體渲染表面重建研究綜述
2024-12-30 00:00:00余瑛萬貽前洪瀚葉青
計算機應用研究 2024年12期






摘 要:
在計算機視覺和圖形學領域,多視圖物體表面重建是一個重要的研究方向。符號距離函數的體渲染技術是一種新興的物體表面重建方法,因其在復雜場景重建中的出色表現受到人們廣泛關注。旨在對符號距離函數的體渲染技術進行全面分析和總結,為未來研究人員提供參考。首先介紹了有向符號距離函數的基本原理及其在體渲染技術中的應用;隨后,從提升表面重建質量、加快訓練速度、稀疏視圖重建、重光照和材料編輯、特定場景重建等方面整理分析了該領域的關鍵模型改進和技術進展;此外,還對比分析了不同模型在速度和性能方面的表現,并簡要介紹了模型評估的主要指標和公開數據集;最后,對該領域的研究現狀進行了總結,并對未來的研究前景進行了展望和探討。
關鍵詞:符號距離函數;體渲染技術;物體表面重建
中圖分類號:TP391.9"" 文獻標志碼:A""" 文章編號:1001-3695(2024)12-002-3533-10
doi: 10.19734/j.issn.1001-3695.2024.05.0242
Review of research on volume rendering surface reconstruction based on signed distance function
Yu Yinga,b, Wan Yiqiana, Hong Hana, Ye Qinga,b
(a.School of Computer Science, b.Key Laboratory of Artificial Intelligence in Chinese Medicine, Jiangxi University of Chinese Medicine, Nanchang 330004, China)
Abstract:
In the fields of computer vision and graphics, multi-view object surface reconstruction is a significant research direction. SDF volume rendering, as an emerging method for object surface reconstruction, garners widespread attention due to its outstanding performance in reconstructing complex scenes. This study provided a comprehensive analysis and summary of SDF volume rendering techniques, serving as a reference for future researchers. Firstly, this paper introduced the fundamental principles of directed SDF and its application in volume rendering technology. Subsequently, it organized and analyzed key model improvements and technological advancements in areas such as enhancing surface reconstruction quality, accelerating training speed, sparse view reconstruction, relighting, and material editing, as well as specific scene reconstruction. Additio-nally, this paper compared the speed and performance of different models and briefly introduced the main evaluation metrics and publicly available datasets. Finally, it summarized the current research status in this field, discussed and explored the future research prospects.
Key words:signed distance function(SDF); volume rendering technology; object surface reconstruction
0 引言
在計算機視覺和計算機圖形學領域中,多視圖物體表面重建一直是一個重要的研究方向。傳統的多視圖立體法(multi-view stereo, MVS)在處理復雜場景時往往面臨諸多挑戰。近年來,神經輻射場(neural radiance field, NeRF)技術的突破性發展為這一問題提供了新的解決思路。NeuS[1]和VolSDF[2]引入有向符號距離函數(SDF)隱式表示三維物體表面,顯著提高了物體表面三維重建的質量。由于目前還未有針對SDF體渲染重建技術的綜述性文章,所以,本文全面回顧和總結基于SDF的神經隱式曲面重建的最新研究進展,以助人們更好地追蹤和深入理解該領域的動態發展。
1 神經隱式曲面
1.1 多視圖曲面重建
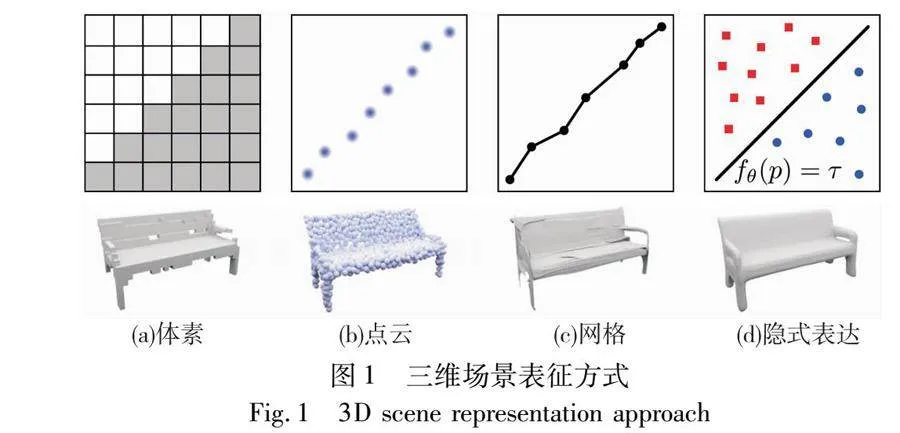
傳統的多視圖三維重建方法通常可以分為深度估計的特征匹配法[3~6]和基于體素的形狀表示法[7~10]兩類。在深度估計的特征匹配方法中,首先需要從圖像中提取特征,并在不同視圖之間進行匹配以估計深度。然后,將預測的深度圖融合生成密集點云。最后利用泊松表面重建等方法[11]將三維表面進行網格化。然而,這種方法受匹配準確性影響較大,對于紋理較弱的物體,匹配過程中常產生嚴重的偽影和缺失。而基于體素重建的方法則是通過從多視角圖像中估計體素網格的占用和顏色,并評估每個體素的顏色一致性,從而規避了特征匹配的困難。可是由于受到可實現的體素分辨率的限制,該方法也無法實現高精度的重建。近年來,一些方法通過引入歸納偏差,將三維理解嵌入到深度學習框架中。這些歸納偏差可以是顯式表示,如體素網格、點云和網格,也可以是隱式表示,如圖1所示。其中,由于神經網絡編碼隱式表示的連續性和高空間分辨率受到人們廣泛關注,這些方法通過使用連續函數對空間中的物體進行隱式表達,實現了高效的三維結構編碼,例如,占用預測網絡[12]和SDF[13]利用神經網絡來逼近一個連續可微的信號,并在神經網絡中對該信號進行編碼。另外,隱式神經表征還可以在任意空間分辨率下進行采樣,克服了顯示表征在分辨率上的限制,并成功應用于形狀表示、新視圖合成和多視圖3D重建等領域。
1.2 神經輻射場
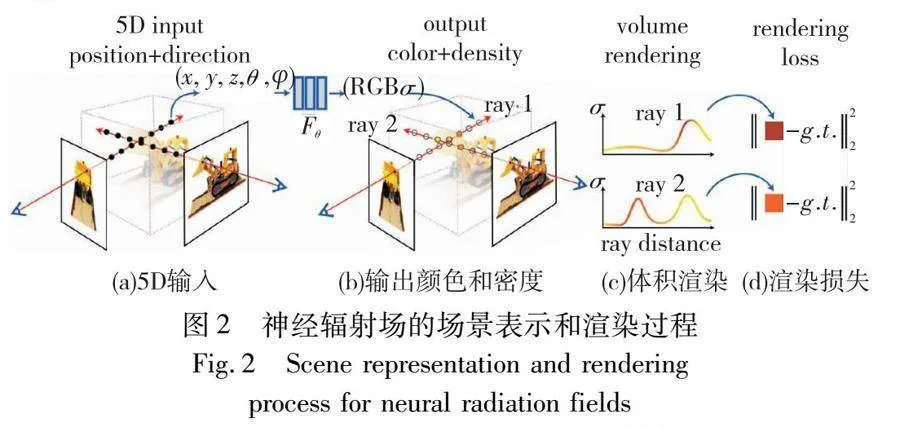
神經輻射場是一種將三維重建技術和神經渲染技術相結合的新視圖合成方法。該方法使用多層感知器(multilayer perceptron,MLP)來學習3D場景體積密度以及顏色等物理屬性,通過優化連續的體積場景,從而實現對場景的高精度渲染。如圖2[14]所示,通過輸入三維空間位置(x, y, z)和觀察方向 (θ, φ),利用MLP模型來預測每個三維點的RGB顏色值和體積密度。接著,通過體積渲染技術,模擬光線在場景中穿越多個三維點時的累積效應,從而生成高精度的二維圖像。在訓練過程中,從攝像機位置出發,沿光線方向采樣多個三維點,并使用MLP模型預測這些點的顏色和密度。然后,將渲染圖像與真實圖像進行比較,計算它們之間的差異來定義渲染損失。通過使用優化算法不斷調整MLP的參數,最小化渲染損失,使得渲染的圖像與真實圖像之間的差異逐漸減小。通過這種方式,NeRF能夠精確地重建復雜的三維場景,并生成高質量的渲染圖像。
在此基礎上,許多研究者對NeRF模型[14]進行了改進和優化[15~19],并有相關文獻總結了其最新進展[20~22]。盡管NeRF在生成新視角圖像方面表現出色,但由于其主要關注體積渲染而非表面重建,使用NeRF方法得到的三維模型表面可能存在大量噪聲和空間漂浮物。為解決這一問題,UNISURF[23]、VolSDF[2]和NeuS[1]等方法將占用函數或帶符號距離函數引入體繪制方程。其中,UNISURF通過體積渲染優化二進制占用函數,VolSDF將這概念擴展到SDF,而NeuS則通過分析得出體積渲染優化SDF時會引起偏差,并提出了一種無偏差且能夠感知遮擋的加權方案,能夠有效恢復更精確的表面細節。
1.3 基于SDF的體渲染
神經隱式表示法采用連續隱式函數,直接從二維圖像中重建物體形狀。例如,IDR[24]和DVR[25]分別使用SDF和占用網格來表示場景。通過應用可微分渲染技術,這些方法能夠恢復高頻的幾何形狀和顏色。然而,這兩種方法都需要掩碼監督,這在實踐中不容易獲得。為了消除對掩碼監督信息的依賴,研究者們開始將體渲染技術應用于表面重建,并據此開展了一系列基于體渲染的多視角三維重建研究。本節將簡要介紹基于SDF的體渲染技術的基本工作原理。
1.3.1 場景表示
為了將體積渲染方法應用于SDF網絡的訓練,還需要引入一個概率密度函數S(f(x)),其中f(x),x∈Euclid ExtraaBp3為有符號距離函數。這個概率密度函數S(f(x))函數能將SDF的輸出轉換成一個概率值,用于判斷一個點x是否接近物體表面。S(x)=Se-Sx/(1+e-Sx)2,通常稱為邏輯密度分布,是sigmoid函數ΦS(x)=(1+e-Sx)-1的導數,即S(x)=Φ′S(x)。它的分布為鐘型,中心峰值對應零點,即物體的表面。因此接近物體表面的點x會有較高的概率值。在訓練過程中,概率密度函數的標準差1/S是可調整的參數,隨著網絡對物體表面的表示越來越精確,1/S會逐漸趨于零,這表明網絡對表面位置的預測更為準確。
1.3.2 體渲染
想要從SDF表示中渲染圖像,需要先學習神經SDF和顏色場(color field)的參數。給定一個像素,定義該像素發出的光線{p(t)=o+vt|t≥0},其中o是相機的中心,v是光線的單位方向向量,t是光線在該方向上的距離參數。為了得到該像素的最終顏色,需要對光線上每一點的顏色進行加權并積分來實現,積分公式為
C(o,v)=∫∞0a(t)c(p(t),v)dt(2)
其中:C(o,v)是該像素的輸出顏色;C(p(t),v)是觀察方向v上點p的顏色;權重函數w(t)是光線在點p(t)結束的概率,它是通過透射率T(t)計算得來的;其中T(t)是從光線的起點到點p(t)之間透射率的累積,可以用式(3)表示。
ω(t)=T(t)σ(t), T(t)=exp(-∫t0σ(s)ds)(3)
其中:σ(s)是介質的密度函數,表示在路徑上點s處的吸收率。在實驗中,并不是對整個連續的光線路徑進行積分,而是在一組采樣點{pi}ni=1上評估密度和光的強度。這些點是按照光線方向等間隔取樣的,用離散化的公式來近似顏色積分:
C^(o,v)=∑Ni=1Tiαici(4)
其中:Ti是到達點pi之前的累積透射率;ai是點pi的不透明度。光線從起點到點pi之間的透射率乘積Ti表示為
Ti=∏i-1j=1(1-αj)(5)
每個點pi的不透明度可以從密度函數σ(t)估計得來,使用式(6)表示。
αi=1-exp(-∫ti+1tiσ(t)dt)(6)
2 基于SDF體渲染的改進與優化
目前,NeuS是基于SDF的表面重建領域中的一種主流方法。通過結合多層感知器對SDF進行建模,并優化體積渲染過程,NeuS能夠有效地從多視圖圖像中恢復場景的幾何結構。然而,盡管NeuS在重建物體表面上取得了顯著成就,但在處理動態場景和復雜幾何結構等方面仍存在局限性。為了進一步提高重建效果和適用性,大量研究人員對最初的NeuS模型進行了大量的改進和優化。這些改進主要包括提升對復雜區域的重建能力、加快處理速度,以及增強在特定應用場景下的表現。
2.1 提高表面重建質量
物體表面的重建質量是衡量模型重建效果的關鍵指標。本節將著重介紹幾個關鍵模型,它們通過對原始NeuS模型的理論和方法進行創新性改進,有效提高表面重建質量。此外,為了減輕體渲染過程中出現的偏差,不少研究通過引入幾何約束來降低這些偏差,從而進一步提升重建質量。這些進展不僅提高了重建質量,也為體渲染重建領域帶來了新的理論和技術突破。
表1~4對部分SDF體渲染模型的改進進行了對比分析。表中PSNR、CD(chamfer distance)值均為多個測試場景的平均值,由于不同文獻實驗所使用GPU的內存和算力有所不同,因此表中的實驗結果數據僅作參考。
2.1.1 理論方法的創新與改進
為了得到帶符號距離函數f,VolSDF和NeuS分別對密度函數σ(r(t))=f(r(t))和加權函數w(r(t))=f(r(t))進行建模。HF-NeuS[26]提出了一種新的透明度函數建模方法,通過將SDF分解為基函數和位移函數來模擬透明度,有效地捕獲了低頻和高頻細節。這種方法可以更精確地重建表面的細節和紋理,尤其是在處理高頻部分時。此外,它還應用了自適應優化策略,專注于改善表面附近的偽影區域。與VolSDF和NeuS相比,HF-NeuS簡化了采樣過程,并提供了一個更簡化的密度計算公式,減少了由于分割導致的數值問題。
NeuS模型通過構造無偏權重函數ω(t)來保證無偏性。然而后續的實驗證明,該方法并不能得到真正的無偏。Zhang等人[27]分析了現有基于SDF的體繪制策略存在的偏差,并為無偏差的SDF體繪制提供了一個附加條件:繪制深度應等于射線上第一個交點到攝像機中心沿著的距離。為了減小這種偏差,還引入了一種新的從SDF場到密度場的變換。采用觀察方向與表面法向量夾角的余弦來縮放SDF場,然后將縮放后的SDF場與一定的累計分布函數(cumulative distribution function,CDF)相結合來模擬密度場。實驗結果表明該方法能有效減少渲染偏差。
D-NeuS[28]對NeuS模型進行了兩個方面的優化,以減少偏差。首先,在體積渲染中減少了幾何偏差。它通過在體積渲染過程中生成額外的距離圖,然后將其回投影到3D點,并對其絕對SDF值施加懲罰,從而實現體積渲染與基礎表面之間的一致性;其次,應用了多視圖特征一致性。它通過線性插值SDF零交叉點來確定表面點,然后在多個視圖之間進行特征比較,以確保幾何細節的一致性。這些改進顯著提高了重建質量。
PET-NeuS[29]采用三平面數據結構來編碼局部特征。這種結構不僅在內存消耗上更少,而且更容易擴展到更高的分辨率。在該方法中,首先將三平面數據結構整合到一個表面重建框架中,以便能夠對具有更多局部細節的SDF進行建模;其次,由于三平面像素之間的特征不共享可學習參數,采用位置編碼來調制三平面特征,從而增強可學習特征的平滑性;第三,位置編碼涉及不同頻率的函數。為了更好地匹配不同的頻率,使用具有不同窗口大小的多尺度自注意卷積核在空間域中進行卷積,以生成不同頻帶的特征,進一步提高了真實性
雖然PET-NeuS采用自注意卷積來生成基于三平面的表示,有效地提高了重建質量,但在三平面特征和位置上進行位置編碼會增加模型參數和計算復雜度。LoD-NeuS[30]提出了一種多尺度三平面位置編碼來捕獲不同的LoD。為了有效地表示高頻采樣,設計了一種多卷積特征化來近似圓錐體內的射線積分,如圖3[30]所示。多重卷積特征化利用高斯核在不同分辨率層級上處理采樣點特征,錐樣本混合則通過混合權重將錐形內采樣點的特征融合,最終在錐體內生成連續的特征表示,從而在連續方式下高效地聚合任何樣本的LoD特征。此外,文中還提出了一個錯誤引導的采樣策略,以指導SDF增長過程中的優化。
2.1.2 增添幾何約束
為了改善低紋理區域的重建,一種典型的方法是利用人造場景的平面先驗。ManhattanSDF[31]提出了一種基于曼哈頓世界假設的室內場景重建方法,旨在改善低紋理區域的重建質量。其核心思想是利用平面區域的語義信息來指導幾何重構。該方法利用語義分割檢測這些區域,并基于曼哈頓世界假設應用幾何約束來增強無紋理區域的重建。為了解決語義分割的不準確性,還將語義信息編碼到隱式場景表示中,并將語義與場景的幾何形狀和外觀一起聯合優化。實驗結果表明,該方法能夠在保持非平面區域細節的同時,重建出準確完整的平面。
由于渲染無法生成高頻紋理,通常導致3D精度較低,為了克服這個限制,NeuralWarp[32]通過對不同視角的圖像進行補丁變形優化,提高了神經網絡學習和呈現高頻紋理的能力。該方法利用預測的占用率和法線信息對整個補丁進行變形,以及通過結構相似性測量它們的相似度,有效地處理可見性和遮擋問題,從而在重建中避免了不正確的變形。
但是由于室內場景缺乏紋理,NeuralWarp在室內場景中表現并不佳。NeuRIS[33]提出了一種新的先驗引導優化框架,用于神經體繪制幾何約束。其核心思想是將室內場景的估計法線作為神經渲染框架中的先驗進行整合,以重建大型無紋理形狀。訓練過程分為兩個階段:首先,訓練一個粗略模型來適應多視角圖像和體積渲染估計的法線圖,不使用任何過濾策略;接著,通過適應性地施加法線先驗來進行監督。同時訓練兩個分支:一個分支評估幾何質量,通過計算多視圖視覺一致性;另一個分支只接受通過幾何檢查的先驗法線作為渲染法線的適當監督。實驗證明,這種方法能夠在紋理較為稀疏的區域應用先驗知識,同時在紋理豐富的小物體上保持細節的精細重建能力。
MonoSDF[34]則將單眼幾何線索整合到多視圖圖像的神經隱式表面重建中。它通過在優化過程中使用來自單眼預測器的深度和表面法線作為額外的監督信號來提高重建質量,尤其是在紋理較少和觀察較少的區域。該方法利用預訓練的Omnidata模型為每個輸入的RGB圖像生成深度圖。雖然無法精確測量絕對距離,但提供了有用的深度信息。同時,使用Omnidata模型為每個RGB圖像生成法線映射。與深度圖提供的半局部相對信息不同,法線映射提供更局部的信息,能夠捕捉到更細微的幾何細節。這兩種線索相結合,特別是在處理復雜場景時,深度圖和法線映射作為互補信息,共同優化神經隱式曲面,提高了重建的準確性和細節表現,尤其在無紋理或稀疏覆蓋區域。
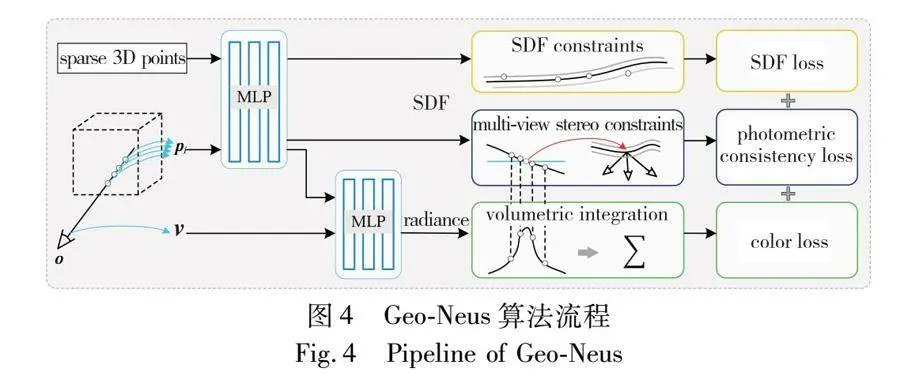
在NeuS框架中,體繪制技術通過對顏色積分的隱式監督來精確地建模物體表面。這種方法在渲染顏色方面取得了顯著的成效,然而,它在估計物體表面顏色的過程中未能充分保留物體的幾何信息。這導致了在渲染的顏色和物體的幾何形狀之間出現了一定的偏差。Geo-Neus[36]提出一種新的方法,直接定位SDF網絡的零層集。該方法通過引入了稀疏3D點的SDF損失和多視角立體的光度一致性損失,以顯式監督SDF網絡,如圖4[36]所示。這種策略相比傳統依賴顏色損失的方法,更有效地監督和優化SDF網絡,使得Geo-Neus在處理包含復雜薄結構和廣泛光滑區域的場景時,能夠實現高質量的表面重建。
相比通過結合由輔助數據預訓練的模型提供的幾何線索來減小誤差,HelixSurf[37]將傳統的PM-MVS (PatchMatch)與神經隱式表面相結合,采用互補機制,取得了更好的結果。它利用中間預測策略來指導另一種策略的學習,并在學習過程中交替應用這種正則化方法。針對MVS在預測無紋理表面區域方面不夠可靠的問題,HelixSurf設計了一種方案,通過利用觀察到的多視圖圖像中每個超像素的同質性來規范這些區域的學習過程。此外,為了提高HelixSurf在體渲染方面的效率,采用了在3D場景空間中維護動態占用網格的方法,以自適應地引導點沿著射線采樣,從而顯著提升了渲染效率。
盡管以前方法通過利用 RGB 圖像和深度圖在重建效果上取得了顯著的成果,但在弱光條件和大規模場景下仍面臨挑戰。Yan等人[38]提出了一種利用稀疏 LiDAR 點云進行隱式神經重建的方法。首先,通過里程計獲取點云序列和初始粗略位姿,并根據視點變化選擇關鍵幀,去除冗余幀和測量誤差大的幀。然后,利用關鍵幀的點云和粗略位姿進行聯合優化,訓練隱式占據場。該隱式模型采用MLP和多分辨率哈希編碼器表示3D結構。通過光線采樣,將樣本點分類為被占據或未被占據,并利用加權二元交叉熵(BCE)損失函數進行監督學習,從而實現對遮擋情況的感知和無偏見的3D重建。
2.2 提高訓練和推理速度
在NeuS模型中為了提高計算效率,采用了分層渲染技術。與傳統的樸素渲染方法需要對每條光線進行密集采樣相比,NeuS模型通過使用粗細兩個不同層次的網絡來表示場景。粗網絡的輸出用于為細網絡挑選采樣點,防止了細尺度下的密集采樣,從而降低了計算量。然而,盡管如此,NeuS模型的速度仍然無法完全滿足實際應用需求。因此,在隨后的工作中,部分工作專注于提升神經輻射場的渲染速度,以進一步優化性能。
Dogaru等人[39]通過結合神經隱式表面和粗略的球形表面重建來優化采樣過程。為了減少無效采樣空間,該系統采用一個可訓練的球形云來指導射線采樣和行走過程以提高效率。另外,研究提出了一種基于梯度下降的優化方法,允許球形云與隱式表面場同時訓練。為了避免球形云在訓練過程中陷入局部最小值,促進更全面的表面探索和更準確的重建,研究還引入點重采樣方案和排斥機制。
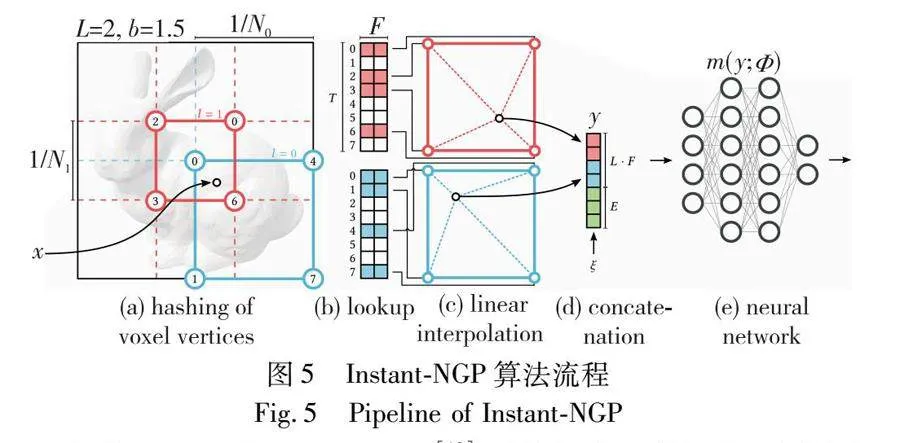
Instant-NGP模型[18]通過引入多分辨率哈希編碼顯著提升了NeRF模型的訓練和推理速度。該模型使用多分辨率哈希表存儲特征向量,這些特征向量通過隨機梯度下降優化,允許使用較小的神經網絡的同時保持高質量的結果。此外,Instant-NGP采用新的光線行進方案,將樣本數據壓縮到密集緩沖區中,以提高執行效率,并優化了浮點數運算和內存訪問,顯著減少了這些操作的次數,如圖5[18]所示。這些改進同樣可以應用于Neus模型,通過減少全連接神經網絡的參數數量、優化光線行進方案和減少計算資源的消耗,Neus模型在保持高重建精度的同時,能夠顯著提升訓練和推理速度,適應更多實時或高效計算需求的應用場景。
Voxurf[40]提出了一種基于體素網格的表面重建方法。該方法通過采用兩階段訓練過程獲得連貫的粗略形狀并連續恢復精細細節。為此,研究還設計了一個雙色網絡,能夠通過體素網格來表示復雜的顏色場,并通過兩個協同工作的子網絡來保持顏色幾何依賴性;此外,研究提出了基于SDF體素網格的分層幾何特征,以促進信息在更大區域內的穩定優化和共享;最后,引入了多個正則化項,以提高結果的平滑度并降低噪聲的影響。
盡管Voxurf和Instant-NGP[18]兩種方法都利用多級網格方案來擴大體素網格的感受野并鼓勵相鄰體素之間共享更多的信息。但因為體素網格所保持的幾何特征均勻地分布在3D表面周圍,從而可能無法捕獲尖銳的局部拓撲結構。NeuDA[41]提出了一種靈活的神經隱式表示,利用分層體素網格即神經變形錨進行高保真表面重建。該方法存儲3D位置,即錨點,而不是每個頂點處的常規嵌入。它通過直接內插查詢點的八個相鄰錨點的頻率嵌入來獲得查詢點的輸入特征,并通過反向傳播優化錨點,從而在建模不同的細粒度幾何結構時表現出靈活性。
針對基于SDF的體渲染表面重建的幾何形狀和顏色過于平滑的問題,PermutoSDF[42]融合了哈希編碼和隱式表面的優點加以解決。該方法通過SDF和顏色場表示場景,并采用無偏差的體積積分進行渲染。在該方法中還提出了一種規范化方案,能在保持平滑幾何形狀的同時,精確重建細節,如毛孔和皺紋。此外,PermutoSDF引入了全面體晶格,這種結構的頂點數量隨維度線性增長,而不是像立方體體素那樣指數級增長,提高了3D重建和4D背景估計的性能。
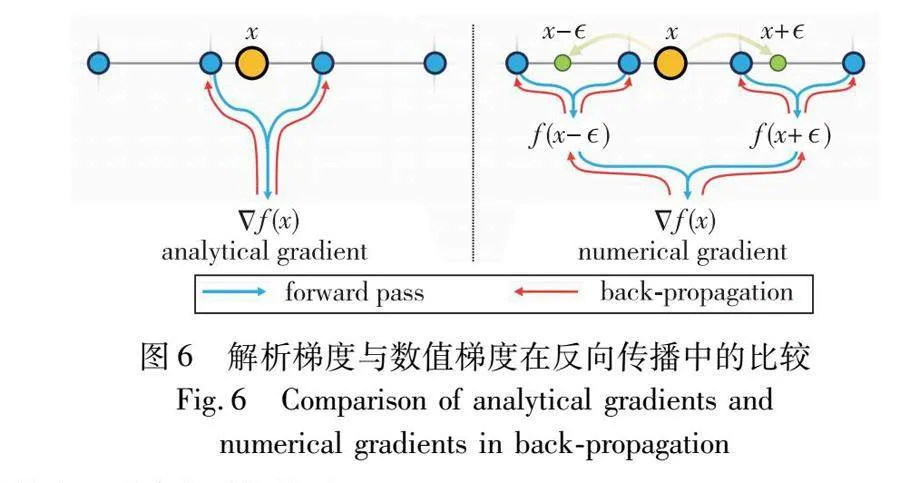
Neuralangelo[43]利用Instant NGP作為底層3D場景的神經SDF表示,通過神經表面渲染從多視圖圖像觀察進行優化,實現了復雜三維場景的高質量重建。該方法充分利用了多分辨率哈希編碼的作用。首先,它在反向傳播過程中,通過對比解析梯度和數值梯度,選擇使用數值梯度計算高階導數來穩定優化過程,如圖6[43]所示。其次,采用逐步優化策略,對哈希網格進行從粗到細的優化,有效地恢復了不同細節層面的結構。因此,即使沒有深度信息等輔助輸入,Neuralangelo也能從多視圖圖像中高效恢復密集的3D表面結構。
Neuralangelo使用多分辨率哈希網格和數值梯度計算進行神經表面重建,盡管可以實現高保真幾何重建,但增加了訓練成本。NeuS2[44]則通過利用多分辨率哈希編碼來參數化神經表面表示,并引入了輕量級的二階導數計算,大幅度提高了計算速度。為了進一步提高訓練的穩定性和速度,NeuS2還引入了漸進式學習策略,逐步優化多分辨率哈希編碼,提升了模型的效率和性能。此外,NeuS2 還將該方法應用于動態場景的快速訓練,通過增量訓練策略使系統逐步適應數據變化,同時引入全局變換預測組件,更準確地預測和理解場景中的運動和變化,使得 NeuS2能夠有效處理具有復雜運動和形變的長序列數據。
2.3 稀疏視圖重建
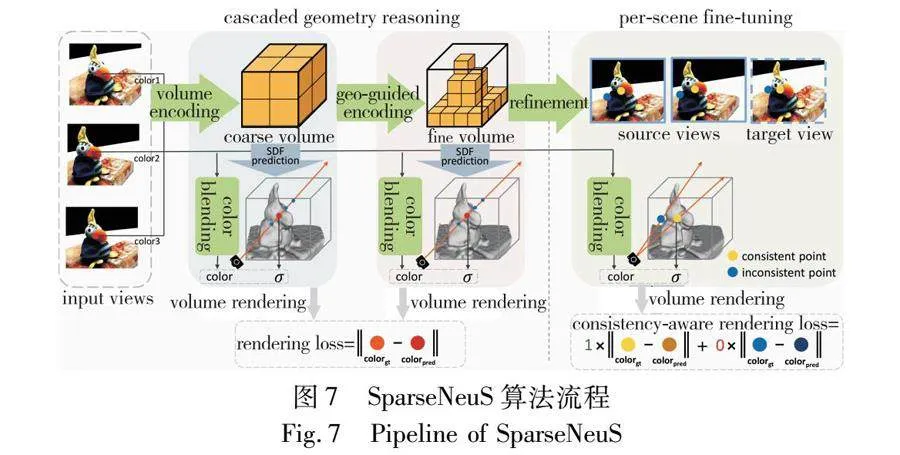
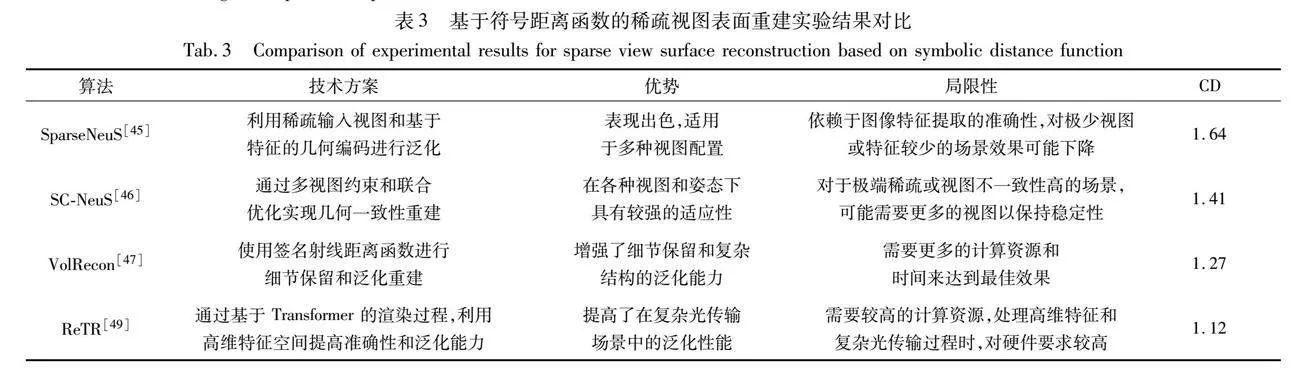
在多視圖圖像的表面重建任務中,當僅提供稀疏圖像作為輸入時,通常會產生不完整或失真的結果。為解決這一難題,SparseNeuS[45](圖7)提出了一種新的基于神經繪制的曲面重建方法,專門用于從少量的視角中重建物體表面。它通過使用SDF和幾何編碼體積作為表面的表示方式,從圖像特征中學習并應用可泛化的先驗知識,從而在數據稀疏的情況下也能準確地預測復雜表面。另外,SparseNeuS還結合了多層級的幾何推理和多尺度的顏色混合方案,以實現更可靠的顏色預測,并通過一致性感知的微調策略來處理遮擋和噪聲導致的不一致問題。
SparseNeuS通過學習圖像特征來提高稀疏場景的重建質量,但它對高精度的相機姿勢依賴性較高,這通常難以獲得。為了解決這個問題,SC-NeuS[46]提出了一種稀疏視圖一致性神經表面學習策略。該策略能夠從稀疏且帶有噪聲的相機姿勢中進行幾何一致的表面重建,包括細粒度的細節。該方法通過從顯式幾何結構中采樣點并引入額外的正則化來提高幾何一致性。此外,它還引入了一個快速可微的表面交集方法,允許從神經表面的顯式幾何形狀中采樣點。通過在這些采樣點上定義有效的視圖一致性損失,可以實現端到端的聯合學習,從而對神經表面表示和相機姿勢進行學習。同時,該方法還采用了由粗到細的學習策略,進一步提高了幾何一致性的學習效果從而保持高精度的表面重建結果。
VolRecon[47]通過引入創新的signed ray distance function (SRDF),結合投影特征和全局體積特征,并利用視圖變換器和射線變換器進行多視圖特征聚合,實現了高質量、細節豐富的3D場景重建。與傳統的SDF不同,SRDF定義了沿給定射線到最近表面的距離,通過射線變換器計算采樣點的SRDF值,并進行顏色和深度的渲染。全局特征體編碼了全局形狀先驗,提供了更精確的幾何估計。視圖變換器聚合多視圖特征,使VolRecon在遮擋和無紋理表面等復雜情況下仍能準確重建。
S-VolSDF[48]結合MVS中的概率體積和廣義交叉熵損失,通過利用MVS粗略階段的預測結果來優化神經隱式表面,從而提升稀疏視圖輸入下的3D重建性能。該方法將 MVS 概率體積與神經體積表面重建技術結合,引入軟一致性約束,以處理噪聲并確保概率體積與渲染權重之間的一致性。通過渲染的深度圖指導MVS的下一階段深度采樣,S-VolSDF實現了一種從粗到細的多視圖立體重建方法。這一方法結合了多層次特征,增強了對低級和高級特征的感知。最終,通過顏色和深度的綜合損失函數提供全面的訓練監督信號,確保了模型的準確性和重建質量。
ReTR[49]通過利用Transformer架構重新設計渲染過程,創新性地引入可學習的元射線token和交叉注意力機制,以模擬渲染過程與采樣點的復雜交互。該方法在高維特征空間中操作,而非顏色空間,減弱了對源視圖投影顏色的依賴,從而提升了表面重建的精確性和可靠性。ReTR 還引入了遮擋變換器,模擬光子與介質的交互,考慮遮擋和采樣點間隔,以增強對復雜物理效果的建模能力。通過連續位置編碼,解決了不同采樣點數量導致的位置編碼錯位問題,從而確保模型的準確性。混合特征提取器結合多層次特征,增強了對低級和高級特征的感知,進一步提高了重建質量。通過組合優化的渲染損失和深度損失,ReTR提供了更全面的訓練監督信號,進一步提升了重建效果。
2.4 重光照與材質編輯
針對野外變化的光照條件下,Sun等人[50]提出了一種混合體素表面引導采樣技術,與基線方法相比顯著縮短了訓練時間。為了減少冗余的訓練樣本,首先利用來自運動恢復結構(structure from motion,SfM)的稀疏點云來初始化稀疏體素,從而生成采樣點。然后,將這種體素引導策略與表面引導采樣技術相結合,并根據當前優化狀態生成采樣點。該方法的關鍵點在于,不僅使用SfM點云,還通過使用表面近似產生以真實表面為中心的新采樣點。這種策略引導網絡使用接近表面的采樣點來解釋渲染的顏色,從而實現更精確的幾何擬合。
IRON [51]通過引入混合優化方案顯著提高了逆向渲染的質量。首先,它利用體積輻射場優化恢復幾何拓撲結構,然后使用邊緣感知的基于物理的表面渲染來優化細節,同時解耦材料與光照。通過設計邊緣采樣算法,生成無偏梯度估計,有效改善邊緣區域的重建效果。該方法采用神經 SDF 和材料的神經表示,兼具靈活性和緊湊性,能夠輸出高質量的三角網格和材質紋理,方便與現有圖形管線兼容。通過簡化的物理渲染方程,IRON 考慮了光照與材質的相互作用,進一步優化幾何和材質參數,實現高精度的逆向渲染。另外,該方法無須額外的物體遮罩或 3D 監督,即可從多視圖光度圖像中進行優化,在實際應用中更加便捷和高效。
Zeng等人[52]提出了一種新穎的神經隱式輻射表示方法,用于從一組非結構化照片中實現自由視點的重光照。該方法通過兩個MLP來建模:第一個MLP用來建模形狀的SDF;第二個MLP建模局部和全局光傳輸。在第二個MLP中不僅考慮密度特征、當前位置、法線、視點方向和光源位置,還引入了陰影和高光提示,以幫助網絡捕捉高頻光傳輸效果。與之前的方法不同,該方法不分離不同的光傳輸組件,而是在每個點上同時建模局部和全局光傳輸。實驗結果表明,該方法在處理各種形狀、材質和全局光傳輸效果的合成以及真實場景中表現出色。
NeFII算法[53]通過路徑追蹤和神經網絡結合,實現了從多視圖圖像中精確分解材料和光照,尤其是處理近場間接光照。該方法引入基于蒙特卡羅采樣的路徑追蹤,將間接光照緩存為神經輻射,從而實現物理真實且易于優化的逆向渲染。為提升效率和實用性,NeFII使用球形高斯(SG)來表示平滑的環境光照,并應用重要性采樣技術。最后,引入輻射一致性約束,通過對未觀察到的光線進行一致性訓練,減少材料與間接光照的分解歧義,實現材料和光照的聯合優化。
NeRO[54]提出了一種基于神經渲染的兩階段方法,通過創新的光照表示和近似技術,在無物體遮罩和未知環境光的情況下,準確重建多視圖圖像中的反射性物體的幾何和BRDF。在第一階段,NeRO利用分割求和近似和集成方向編碼準確重建物體幾何形狀;在第二階段,固定幾何形狀后,通過更精確的蒙特卡羅采樣估計BRDF。這種方法通過兩個獨立的MLP分別編碼直接光和間接光,并計算遮擋概率,以高效處理光照效果。
2.5 特定場景表面重建
2.5.1 人臉表面重建
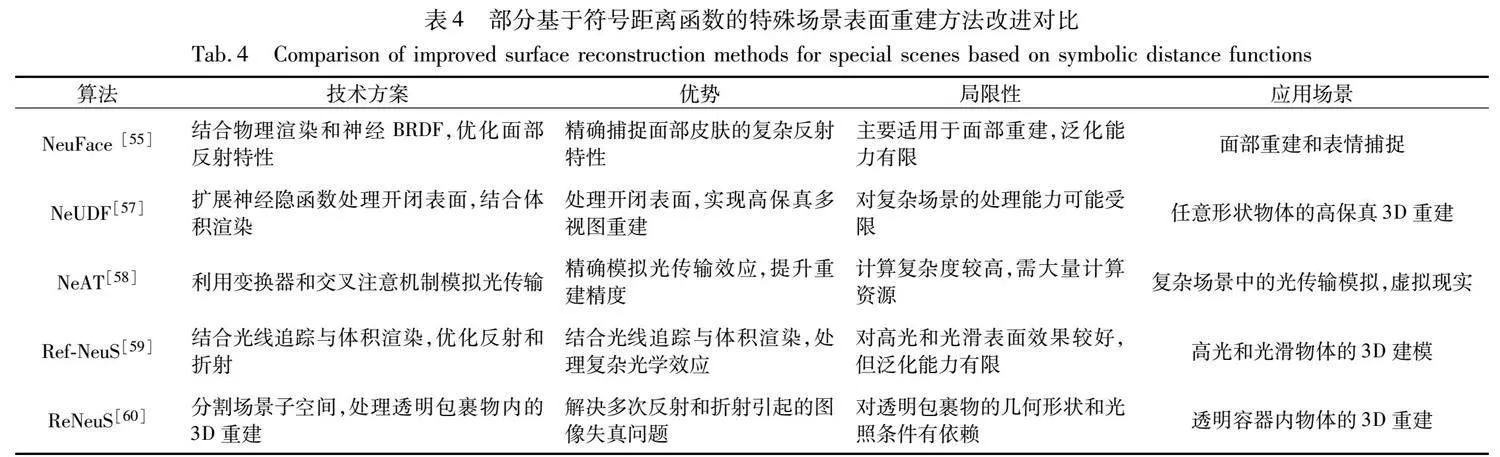
NeuFace [55]結合了物理基礎渲染(PBR)與神經雙向反射分布函數(bi-directional reflectance distribution function,BRDF),通過引入低秩先驗和積分分離技術,解決了復雜面部皮膚反射建模的難題。采用基于SDF的幾何表示,NeuFace 能夠在端到端逆向渲染過程中同步優化面部外觀和幾何。通過神經光度校準解決了相機之間顏色響應和白平衡不一致的問題,采用球體追蹤和稀疏采樣策略,在提高采樣效率的同時保持高質量渲染。最終,將外觀反射特性分解為漫反射、光積分和BRDF積分,通過學習球諧光照和神經基函數來實現高保真度和物理意義的3D面部渲染,展示出優秀的面部重建和泛化能力。
與NeuFace注重光度校準和高效渲染策略不同,Xu等人[56]通過幾何分解和模板訓練,實現了在低視角條件下的高保真度3D頭部重建。該方法通過幾何分解和兩階段訓練策略,聯合SDF表示將3D人頭分解為光滑模板、非剛性變形和高頻位移場。首先在多個個體上訓練模板和變形網絡,生成初步的幾何結構和中性模板;然后針對每個個體單獨訓練位移場,從而逐步捕捉高頻幾何細節。這種方法不需要3D監督或對象遮罩,通過體積渲染和正則化來優化幾何和顏色重建。實驗結果顯示,該方法在低視圖條件下的3D人頭重建和新視圖合成方面顯著優于現有的神經渲染方法,且預訓練的模板提高了模型在遇到新個體時的魯棒性和泛化能力。
2.5.2 開放曲面重建
基于SDF的體渲染方法擺脫了對掩膜的依賴,實現了更精確的重建。然而,由于采用SDF作為表示,這些方法僅適用于封閉曲面,而對于非封閉曲面,它們的性能下降很多。NeUDF[57]采用無符號距離函數(unsigned distance function,UDF)作為表面表示,以處理任意拓撲結構的表面,包括開放和封閉的表面,解決了以往方法在處理非封閉表面時的局限性。NeUDF引入了一種新的無偏加權機制。此外,為了解決UDF表示中的不穩定梯度問題,它還引入了法線規范化方法。這些改進使得NeUDF在重建具有開放邊界的復雜形狀方面表現出色,同時在恢復封閉表面方面也能達到與現有方法相當的效果。
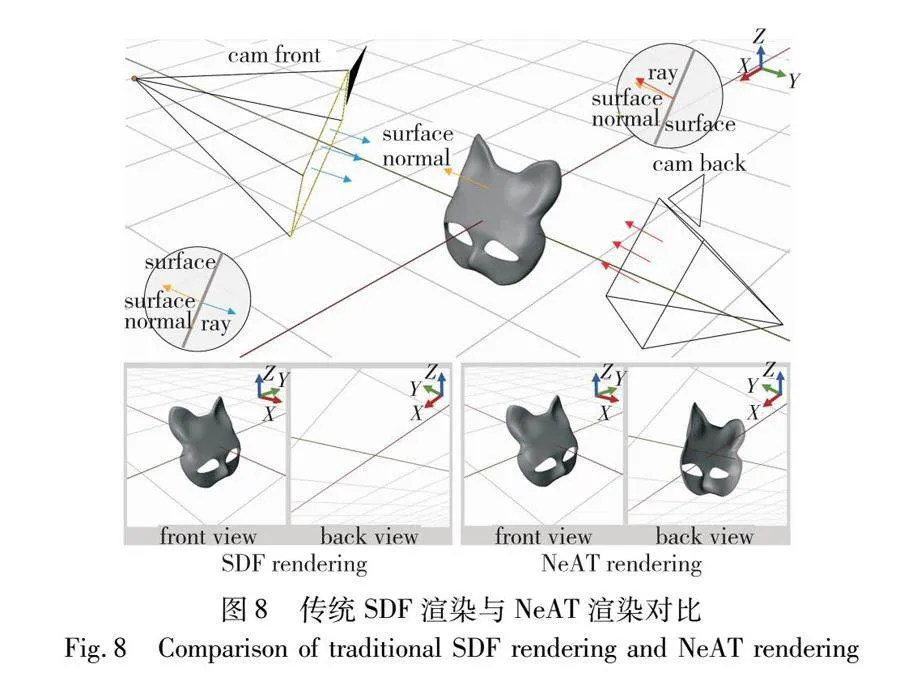
雖然NeUDF能夠有效地重建出非封閉曲面,但是將UDF轉換為網格通常會遇到偽影、法線不一致和計算成本高等問題。與基于UDF的方法相比,NeAT[58]通過引入有效性分支和雙面渲染技術,實現高精度的3D重建。它將輸入圖像的像素投影到3D空間,對這些點進行幾何、有效性和顏色信息的預測。通過有效性分支評估表面存在的概率,避免渲染低有效性點,提高渲染精度。NeAT采用的雙面渲染技術能夠同時處理和渲染表面的兩側,克服了傳統渲染方法僅處理表面正面的局限。結合體積渲染和光線追蹤,NeAT處理復雜光線交互,并通過正則化機制促進開放表面的形成,確保了重建結果的準確性和細節豐富度,如圖8[58]所示。
2.5.3 反射表面重建
在多視圖重建中,反射會導致模糊和不一致性,影響重建的準確性。為了提高對反射表面的重建效果,Ref-NeuS[59]引入了反射感知的光度損失,根據反射分數自適應地降低了對反射表面的權重,從而保持了多視圖一致性,減少了不確定性的影響。此外,Ref-NeuS還采用了一種考慮反射方向的輻射度估計方法,提高了反射表面重建的質量。這種方法在處理具有明顯反射和鏡面特性的場景時表現出色,并克服了傳統三維重建方法在這些情況下的局限性。
ReNeuS算法[60]提出了一種創新的神經隱式表示方法,通過將復雜場景分為內部和外部兩個子空間來解決透明容器內物體的3D重建問題。內部子空間使用兩個MLP分別表示幾何和外觀,外部子空間假定為均勻背景和固定環境光。ReNeuS引入了混合渲染策略,結合體積渲染和光線追蹤技術,處理跨越兩種介質界面的復雜光線交互。此外,該方法采用新的物理損失函數,直接在三維空間上進行監督,提高了訓練的準確性和效率。通過這些創新,ReNeuS能夠有效地處理透明容器中的光線折射和反射,實現高質量的3D場景重建。
3 數據集與評價指標
3.1 評價指標
峰值信噪比(peak signal-to-noise ratio,PSNR)和倒角距離(chamfer distance)[61]是目前大多數文獻采用的兩個重建效果評價指標。
PSNR是衡量重建圖像質量的一種標準指標,通常用于比較原始圖像和重建圖像之間的差異。PSNR值越高,表示圖像重建的質量越好,誤差越小。具體公式為
PSNR=10·lgMAX2IMSE(7)
其中:MAXI是圖像中可能的最大像素值,如果每個采樣點用8 bit表示,那么最大數值為255;MSE是在所有顏色通道上計算的逐像素均方誤差。對于兩張h×w的單色圖像I與K,原始圖像和重建圖像間的均方誤差(MSE)定義為
MSE=1h×w∑hi=1 ∑wj=1(I(i, j)-K(i, j))2(8)
倒角距離用于衡量重建的曲面與實際曲面之間的差異。它計算了重建曲面上的點與實際曲面上最近點之間的距離,以及實際曲面上的點與重建曲面上最近點之間的距離,然后將這些距離的平方和相加。具體公式為
3.2 數據集
SDF體渲染技術的重建效果依賴于輸入圖像的質量和視角的豐富性。盡管目前有一些模型能夠從較少的輸入視圖中進行學習和訓練,但大多數體渲染模型仍然需要大量、多樣化的圖像輸入以確保重建的準確性。在這個過程中,常用COLMAP[62]來獲取相機的姿態信息,以協助訓練過程。為了更好地理解這些模型的應用和性能,本文接下來將介紹神經隱式曲面重建領域中常用的幾個公開數據集(表5),并對它們進行簡要概述。這些數據集不僅提供了豐富的訓練材料,也為模型的評估和比較提供了基礎。
DTU數據集[63]是一個專門為多視圖立體視覺算法評估設計的重要基準數據集。由丹麥技術大學開發,包括80個不同的三維場景,涵蓋了從日常物品到復雜雕塑等多種對象。這些場景在幾何形狀、紋理和反射性方面具有高度多樣性,為MVS算法提供全面挑戰。每個場景由49到64個精確控制的相機位置拍攝,總計約3 200張高分辨率圖像。此外,數據集還包括每個場景的結構光掃描作為精確的3D參考,有助于評估和比較不同MVS算法的性能。DTU數據集因其場景的多樣性、數據的高質量和精確的基準測試而在MVS研究中被廣泛使用。
BlendedMVS[64]是一個大規模的多視圖立體視覺(MVS)數據集,特別設計用于支持基于學習的MVS算法的訓練。該數據集包含113個精心選擇和重建的三維模型,這些紋理模型覆蓋了多種不同場景,包括城市、建筑、雕塑和小物件。每個場景包含20~1 000張輸入圖像,總共超過17 000張高分辨率的圖像。BlendedMVS采用了一種獨特的數據生成方法,通過將渲染的色彩圖像與輸入圖像混合,以引入訓練過程中的環境光照信息。這種方法不僅增強了模型對現實世界場景的泛化能力,而且提供了豐富的視覺細節和一致的深度圖,為MVS網絡訓練提供了一個質量高、覆蓋面廣的數據集。
NeRF-synthetic dataset[14]是專為評估和測試NeRF技術而設計的合成數據集。該數據集包含八個對象,具有復雜的幾何形狀和真實非朗伯特材料。這些對象從不同視點渲染,以生成高質量的圖像。其中六個對象的視點位于上半球,另外兩個對象的視點覆蓋了完整的球體。每個場景都渲染了100個視圖作為輸入,而另外200個視圖用于測試。所有圖像的分辨率為800×800像素。
ScanNet[65]是一個大規模的真實RGB-D多模態數據集,該數據集包含1 513次掃描,覆蓋707個獨特的室內環境,擁有250萬張RGB-D圖像。深度幀以640×480像素捕獲,RGB圖像以1 296×968像素捕獲。ScanNet的特點在于其豐富的注釋,包括3D相機位姿、表面重建、紋理網格、密集的物體級語義分割以及與CAD模型的對齊。此數據集的豐富語義標簽對于使用語義信息的模型非常有用,例如場景編輯、場景分割和語義視圖合成。
Tanks and Temples[66]由14個場景組成,包括“坦克”和“火車”等單個對象,以及“禮堂”和“博物館”等大型室內場景。該數據集的獨特之處在于提供了高分辨率的視頻序列作為輸入,支持新型重建技術的開發,這些技術利用視頻輸入增加了重建的保真度。此外,使用先進的工業激光掃描器獲取的地面真實數據,確保了評估的準確性和可靠性。Tanks and Temples數據集不僅對現有重建管道的極限進行了挑戰,還為未來三維重建技術的研究和發展提供了一個豐富的實驗平臺。
OmniObject3D數據集[67]是一個大規模的三維對象數據集,專為神經輻射場三維重建和視覺感知研究而設計。該數據集包含了6 000個高質量的真實掃描的三維對象,涵蓋190個日常類別。其顯著特點是為每個三維對象提供了豐富的注釋,包括紋理化的網格、點云、多視角渲染圖像以及多個真實捕獲的視頻。OmniObject3D數據集通過專業掃描儀捕獲對象,保證了精確的形狀和逼真的外觀。這些高保真的掃描,結合廣泛的探索空間,使得OmniObject3D成為一個具有挑戰性和代表性的研究平臺,特別適合于評估和發展新型的三維感知、重建和生成技術。
4 結束語
自從SDF體渲染技術提出以來,NeuS模型在多個方面取得了顯著進展,包括速度、質量和對訓練視圖數量的需求等。這些改進有效地克服了原始模型的弱點,為三維重建技術的發展提供了強大的推動力。通過引入無偏性公式、幾何約束等方案,NeuS模型顯著提升了重建質量;同時,通過加速采樣策略、多分辨率散列位置編碼等方法,大大縮短了模型的訓練時間,使其在實際應用中更具競爭力。雖然這些進展令人振奮,SDF體渲染領域仍存在許多挑戰和未解的問題需要解決。
4.1 關于質量和速度
過去的研究在重建質量和速度方面取得了巨大進展,但重建具有高頻細節、陰影和反射表面的對象仍然是一個未解決的問題。未來,本文將致力于開發更復雜、更高效的神經網絡架構,利用更先進的優化技術和損失函數,以更好地捕捉場景中的細節和變化。在速度方面,盡管在測試階段的快速推理方面已經取得了一些進展,但縮短訓練時間仍然是一個重大挑戰。本文相信未來的研究可以專注于改進數據結構,并設計額外的學習功能,以在混合和顯式場景表示方法中實現內存與性能的平衡。
4.2 關于可擴展性
目前,重建工作主要集中在單個物體或簡單場景上,這些場景較小且結構簡單,因此現有的神經渲染方法可以較好地應用。然而,當處理如城市、復雜室內環境或大型戶外場景等大規模場景時,現有方法便會遇到困難。這些大規模場景在每個輸入幀中通常只能被部分觀察到,因此難以有效地學習和表示整個場景。為解決這些問題,未來需要開發新的存儲和檢索技術,以更高效地構建和更新場景,且無須重新計算整個模型。此外,還需高效檢索場景中的局部內容,以便處理和編輯大規模場景中的特定區域。
4.3 關于泛化性
大多數體繪制技術在重建表面結構時依賴大規模的多視圖數據集,這些數據集提供了充足的視角和信息,并要求物體形狀和結構在不同視角下保持不變,以便模型能學習到場景的結構和細節。未來研究需要減少對大量數據的依賴,并提高對非剛性場景的處理能力,以提升泛化能力。SparseNeuS等模型嘗試僅用三張視圖重建表面,盡管能有效重建物體表面,但仍處于初步階段,需要進一步改進。針對非剛性變形場景,由于場景中的物體會隨時間和視角變化而變形,增加了學習和重建難度,模型的泛化能力有限。未來研究可以利用多視圖數據集中的變化模式,或分離物體的變形和靜態部分,以減少學習難度,提高模型在不同場景中的泛化能力。
4.4 關于多模態學習
目前基于SDF的體渲染技術只專注于單一數據模式,即圖像數據。而多模態學習則意味著超越視覺信號,并結合其他數據類型,如語義、文本描述和聲音。增加語義信息可以幫助模型更好地理解場景結構,提高重建質量;而文本描述可以為模型提供額外的上下文信息,輔助視覺信號進行更準確的重建;結合聲音數據可以實現更加真實和沉浸的增強現實體驗。通過整合這些多模態數據,未來的SDF體渲染技術將能夠在更廣泛的應用場景中展現出更高的靈活性和精度。
4.5 關于應用
基于SDF體渲染的表面重建技術目前主要應用于三維重建、虛擬現實、醫療影像、動畫制作和產品設計等領域。未來,SDF體渲染技術有望在城市和建筑環境重建、自動駕駛和機器人、沉浸式體驗和互動藝術、環境監測和地質研究,以及個性化定制和制造中發揮更大作用。通過不斷發展和創新,進一步提升三維重建的精度和效率,為各行各業帶來更多可能性。
總而言之,SDF體渲染技術在計算機圖形學領域展現了巨大的潛力和廣泛的應用前景。隨著技術的不斷進步和優化,可以期待這一領域在未來呈現更多創新和突破。
參考文獻:
[1]Wang Peng, Liu Lingjie, Liu Yuan, et al. NeuS: learning neural implicit surfaces by volume rendering for multi-view reconstruction[J]. Advances in Neural Information Processing Systems, 2021, 34: 27171-27183.
[2]Yariv L, Gu Jiatao, Kasten Y, et al. Volume rendering of neural implicit surfaces[J]. Advances in Neural Information Processing Systems, 2021, 34: 4805-4815.
[3]Fridovich-Keil S, Yu A, Tancik M, et al. Plenoxels: radiance fields without neural networks [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5491-5500.
[4]Galliani S, Lasinger K, Schindler K. Massively parallel multiview stereopsis by surface normal diffusion [C]// Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2015: 873-881.
[5]Schnberger J L, Zheng Enliang, Frahm J M, et al. Pixelwise view selection for unstructured multi-view stereo[C]// Proc of the 14th European Conference on Computer Vision. Cham: Springer, 2016: 501-518.
[6]Zheng Enliang, Dunn E, Jojic V, et al. Patchmatch based joint view selection and depthmap estimation [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2014: 1510-1517.
[7]Curless B, Levoy M. A volumetric method for building complex mo-dels from range images [C]// Proc of the 23rd Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 1996: 303-312.
[8]Newcombe R A, Izadi S, Hilliges O, et al. KinectFusion: real-time dense surface mapping and tracking [C]// Proc of the 10th IEEE International Symposium on Mixed and Augmented Reality. Piscataway, NJ: IEEE Press, 2011: 127-136.
[9]Niener M, Zollhfer M, Izadi S, et al. Real-time 3D reconstruction at scale using voxel hashing [J]. ACM Trans on Graphics, 2013, 32(6): 1-11.
[10]Whelan T, Salas-Moreno R F, Glocker B, et al. ElasticFusion: real-time dense SLAM and light source estimation [J]. The International Journal of Robotics Research, 2016, 35(14): 1697-1716.
[11]Kazhdan M, Hoppe H. Screened Poisson surface reconstruction[J]. ACM Trans on Graphics, 2013, 32(3): 1-13.
[12]Mescheder L, Oechsle M, Niemeyer M, et al. Occupancy networks: learning 3D reconstruction in function space [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscata-way, NJ: IEEE Press, 2019: 4455-4465.
[13]Park J J, Florence P, Straub J, et al. DeepSDF: learning continuous signed distance functions for shape representation [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 165-174.
[14]Mildenhall B, Srinivasan P P, Tancik M, et al. NeRF: representing scenes as neural radiance fields for view synthesis [J]. Communications of the ACM, 2021, 65(1): 99-106.
[15]Barron J T, Mildenhall B, Tancik M, et al. MIP-NeRF: a multiscale representation for anti-aliasing neural radiance fields [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 5835-5844.
[16]Chen Anpei, Xu Zexiang, Zhao Fuqiang, et al. MVSNeRF: fast ge-neralizable radiance field reconstruction from multi-view stereo [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 14104-14113.
[17]Xu Qiangeng, Xu Zexiang, Philip J, et al. Point-NeRF: point-based neural radiance fields [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5428-5438.
[18]Müller T, Evans A, Schied C, et al. Instant neural graphics primitives with a multiresolution hash encoding [J]. ACM Trans on Graphics, 2022, 41(4): 1-15.
[19]Park K, Sinha U, Barron J T, et al. NeRFies: deformable neural radiance fields [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 5845-5854.
[20]韓開, 徐娟. 3D場景渲染技術—神經輻射場的研究綜述 [J]. 計算機應用研究, 2024, 41(8): 1-10. (Han Kai, Xu Juan. Comprehensive review of 3D scene rendering technique-neural radiance fields [J]. Application Research of Computers, 2024, 41(8): 1-10.)
[21]馬漢聲, 祝玉華, 李智慧, 等. 神經輻射場多視圖合成技術綜述 [J]. 計算機工程與應用, 2024, 60(4): 21-38. (Ma Hansheng, Zhu Yuhua, Li Zhihui, et al. A review of neural radiance field multi-view synthesis technology [J]. Computer Engineering and Applications, 2024, 60(4): 21-38.)
[22]成歡, 王碩, 李孟, 等. 面向自動駕駛場景的神經輻射場綜述 [J]. 圖學學報, 2023, 44(6): 1091-1103. (Cheng Huan, Wang Shuo, Li Meng, et al. A review of neural radiance fields for autonomous driving scenarios [J]. Journal of Graphics, 2023, 44(6): 1091-1103.)
[23]Oechsle M, Peng Songyou, Geiger A. UNISURF: unifying neural implicit surfaces and radiance fields for multi-view reconstruction [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 5569-5579.
[24]Yariv L, Kasten Y, Moran D, et al. Multiview neural surface reconstruction by disentangling geometry and appearance[J]. Advances in Neural Information Processing Systems, 2020, 33: 2492-2502.
[25]Niemeyer M, Mescheder L, Oechsle M, et al. Differentiable volume-tric rendering: learning implicit 3D representations without 3D supervision [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 3504-3515.
[26]Wang Yiqun, Skorokhodov I, Wonka P. HF-NeuS: improved surface reconstruction using high-frequency details [J]. Advances in Neural Information Processing Systems, 2022, 35: 1966-1978.
[27]Zhang Yongqiang, Hu Zhipeng, Wu Haoqian, et al. Towards unbiased volume rendering of neural implicit surfaces with geometry priors [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 4359-4368.
[28]Chen Decai, Zhang Peng, Feldmann I, et al. Recovering fine details for neural implicit surface reconstruction [C]// Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway, NJ: IEEE Press, 2023: 4319-4328.
[29]Wang Yiqun, Skorokhodov I, Wonka P. PET-NeuS: positional encoding tri-planes for neural surfaces [C]// Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 12598-12607.
[30]Zhuang Yiyu, Zhang Qi, Feng Ying, et al. Anti-aliased neural implicit surfaces with encoding level of detail[C]// Proc of SIGGRAPH Asia 2023 Conference. New York: ACM Press, 2023: article No.119.
[31]Guo Haoyu, Peng Sida, Lin Haotong, et al. Neural 3D scene reconstruction with the Manhattan-world assumption[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Pisca-taway, NJ: IEEE Press, 2022: 5501-5510.
[32]Darmon F, Bascle B, Devaux J C, et al. Improving neural implicit surfaces geometry with patch warping [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 6250-6259.
[33]Wang Jiepeng, Wang Peng, Long Xiaoxiao, et al. NeuRIS: neural reconstruction of indoor scenes using normal priors [C]// Proc of European Conference on Computer Vision. Cham: Springer, 2022: 139-155.
[34]Yu Zehao, Peng Songyou, Niemeyer M, et al. MonoSDF: exploring monocular geometric cues for neural implicit surface reconstruction[J]. Advances in Neural Information Processing Systems, 2022, 35: 25018-25032.
[35]Eftekhar A, Sax A, Malik J, et al. OmniData: a scalable pipeline for making multi-task mid-level vision datasets from 3D scans [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 10766-10776.
[36]Fu Qiancheng, Xu Qingshan, Ong Y S, et al. Geo-NeuS: geometry-consistent neural implicit surfaces learning for multi-view reconstruction[J]. Advances in Neural Information Processing Systems, 2022, 35: 3403-3416.
[37]Liang Zhihao, Huang Zhangjin, Ding Changxing, et al. HelixSurf: a robust and efficient neural implicit surface learning of indoor scenes with iterative intertwined regularization [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 13165-13174.
[38]Yan Dongyu, Lyu Xiaoyang, Shi Jieqi, et al. Efficient implicit neural reconstruction using lidar [C]// Proc of IEEE International Confe-rence on Robotics and Automation. Piscataway, NJ: IEEE Press, 2023: 8407-8414.
[39]Dogaru A, Ardelean A T, Ignatyev S, et al. Sphere-guided training of neural implicit surfaces [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 20844-20853.
[40]Wu Tong, Wang Jiaqi, Pan Xingang, et al. Voxurf: voxel-based efficient and accurate neural surface reconstruction [EB/OL]. (2023-08-13). https://arxiv.org/abs/2208.12697.
[41]Cai Bowen, Huang Jinchi, Jia Rongfei, et al. NeuDA: neural deformable anchor for high-fidelity implicit surface reconstruction [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 8476-8485.
[42]Rosu R A, Behnke S. PermutoSDF: fast multi-view reconstruction with implicit surfaces using permutohedral lattices [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 8466-8475.
[43]Li Z, Müller T, Evans A, et al. Neuralangelo: high-fidelity neural surface reconstruction [C]// Proceedings of the IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 8456-8465.
[44]Wang Yiming, Han Qin, Habermann M, et al. Neus2: fast learning of neural implicit surfaces for multi-view reconstruction [C]// Proc of IEEE/CVF International Conference on Computer Vision. Pisca-taway, NJ: IEEE Press, 2023: 3272-3283.
[45]Long Xiaoxiao, Lin Cheng, Wang Peng, et al. SparseNeuS: fast generalizable neural surface reconstruction from sparse views[C]// Proc of the 17th European Conference on Computer Vision. Cham: Springer, 2022: 210-227.
[46]Huang Shisheng, Zou Zixin, Zhang Yichi, et al. SC-NeuS: consis-tent neural surface reconstruction from sparse and noisy views[C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2024: 2357-2365.
[47]Ren Yufan, Wang Fangjinhua, Zhang Tong, et al. VolRecon: vo-lume rendering of signed ray distance functions for generalizable multi-view reconstruction [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 16685-16695.
[48]Wu Haoyu, Graikos A, Samaras D. S-VolSDF: sparse multi-view stereo regularization of neural implicit surfaces[C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2023: 3556-3568.
[49]Liang Yixun, He Hao, Chen Yingcong. ReTR: modeling rendering via Transformer for generalizable neural surface reconstruction[C]// Advances in Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2024: 62332-62351.
[50]Sun Jiaming, Chen Xi, Wang Qianqian, et al. Neural 3D reconstruction in the wild[C]// Proc of ACM SIGGRAPH Conference Proceedings. New York: ACM Press, 2022: article No. 26.
[51]Zhang Kai, Luan Fujun, Li Zhengqi, et al. IRON: inverse rendering by optimizing neural SDFS and materials from photometric images [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 5565-5574.
[52]Zeng Chong, Chen Guojun, Dong Yue, et al. Relighting neural radiance fields with shadow and highlight hints [C]// Proc of ACM SIGGRAPH Conference. New York: ACM Press, 2023: article No. 73.
[53]Wu Haoqian, Hu Zhipeng, Li Lincheng, et al. NeFII: inverse rendering for reflectance decomposition with near-field indirect illumination [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 4295-4304.
[54]Liu Yuan, Wang Peng, Lin Cheng, et al. NeRO: neural geometry and BRDF reconstruction of reflective objects from multiview images[J]. ACM Trans on Graphics, 2023, 42(4): 1-22.
[55]Zheng Mingwu, Zhang Haiyu, Yang Hongyu, et al. NeuFace: realistic 3D neural face rendering from multi-view images [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 16868-16877.
[56]Xu Baixin, Zhang Jiarui, Lin K Y, et al. Deformable model-driven neural rendering for high-fidelity 3D reconstruction of human heads under low-view settings[C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2023: 17878-17888.
[57]Liu Y T, Wang Li, Yang Jie, et al. NeUDF: leaning neural unsigned distance fields with volume rendering [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 237-247.
[58]Meng Xiaoxu, Chen Weikai, Yang Bo. Neat: learning neural implicit surfaces with arbitrary topologies from multi-view images [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 248-258.
[59]Ge Wenhang, Hu Tao, Zhao Haoyu, et al. Ref-NeuS: ambiguity-reduced neural implicit surface learning for multi-view reconstruction with reflection[C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2023: 4228-4237.
[60]Tong Jinguang, Muthu S, Maken F A, et al. Seeing through the glass: neural 3D reconstruction of object inside a transparent container[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 12555-12564.
[61]Fan Haoqiang, Su Hao, Guibas L. A point set generation network for 3D object reconstruction from a single image [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 2463-2471.
[62]Schnberger J L, Frahm J M. Structure-from-motion revisited[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 4104-4113.
[63]Jensen R, Dahl A, Vogiatzis G, et al. Large scale multi-view stereopsis evaluation [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2014: 406-413.
[64]Yao Yao, Luo Zixin, Li Shiwei, et al. BlendedMVS: a large-scale dataset for generalized multi-view stereo networks [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 1787-1796.
[65]Dai Angela, Chang A X, Savva M, et al. ScanNet: richly-annotated 3D reconstructions of indoor scenes[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 2432-2443.
[66]Knapitsch A, Park J, Zhou Qianyi, et al. Tanks and temples: benchmarking large-scale scene reconstruction[J]. ACM Trans on Graphics, 2017, 36(4): 1-13.
[67]Wu Tong, Zhang Jiarui, Fu Xiao, et al. OmniObject3D: large-vocabulary 3D object dataset for realistic perception, reconstruction and generation [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 803-814.
