CCA并行構(gòu)件程序分布式負(fù)載均衡方法
2024-12-30 00:00:00彭云峰劉家磊石聰明高國(guó)偉
計(jì)算機(jī)應(yīng)用研究 2024年12期



摘 要:現(xiàn)有的并行構(gòu)件程序大多采用靜態(tài)或者集中式的動(dòng)態(tài)負(fù)載均衡策略,性能優(yōu)化效果并不理想。通過(guò)分析CCA(Common Component Architecture)并行構(gòu)件程序的運(yùn)行機(jī)制,提出一種動(dòng)態(tài)的、分布式的并行構(gòu)件程序負(fù)載均衡方法。使用基于面向?qū)ο髾C(jī)制的方法建立計(jì)算節(jié)點(diǎn)的類庫(kù),通過(guò)數(shù)據(jù)流分析管理不同并行構(gòu)件調(diào)用之間的依賴關(guān)系,將不存在依賴的并行構(gòu)件實(shí)例作為可以并行執(zhí)行的任務(wù)分配給計(jì)算平臺(tái)上的不同計(jì)算節(jié)點(diǎn)執(zhí)行。實(shí)驗(yàn)表明,相對(duì)于已有的靜態(tài)或集中式的負(fù)載均衡策略,能更好地利用計(jì)算資源,同時(shí)避免可能由管理節(jié)點(diǎn)造成的瓶頸效應(yīng),有較小的負(fù)載均衡開銷,能取得更好的性能效果,具有較好的可擴(kuò)展性。
關(guān)鍵詞:并行構(gòu)件;性能優(yōu)化;負(fù)載均衡;并行計(jì)算;資源管理
中圖分類號(hào):TP311"" 文獻(xiàn)標(biāo)志碼:A
文章編號(hào):1001-3695(2024)12-036-3793-08
doi: 10.19734/j.issn.1001-3695.2024.04.0159
Distributed load balancing method for CCA parallel component applications
Peng Yunfeng1, Liu Jialei2a, 2b, Shi Congming1, Gao Guowei1
(1.School of Software Engineering, Anyang Normal University, Anyang Henan 455000, China; 2. a. School of Computer Engineering, b. Hubei Key Laboratory of Power System Design amp; Test for Electrical Vehicle, Hubei University of Arts amp; Science, Xiangyang Hubei 441053, China)
Abstract:Existing parallel component applications use static or centralized dynamic load balancing strategy, and the perfor-mance optimization effect is not satisfactory. This paper analyzed the running mechanism of CCA (Common Component Architecture) parallel component applications, and proposed a dynamic and distributed load balancing method. The method established a class library for computing nodes using an object-oriented mechanism based approach. It managed the dependency relationships between different parallel component calls through data flow analysis, and assigned parallel component instances that do not have dependencies to different computing nodes on the computing platform as tasks that can be executed in parallel. Experiments show that, compared to existing static or centralized load balancing strategies, it can better utilize computing resources while avoiding bottleneck effects that may be caused by management nodes, with smaller load balancing costs, can achieve better performance, and has good scalability.
Key words:parallel component; performance optimization; load balance; parallel computing; resource management
0 引言
并行計(jì)算是解決許多復(fù)雜計(jì)算任務(wù)的重要手段。在航空航天、天氣預(yù)報(bào)、分子動(dòng)力學(xué)模擬等許多關(guān)系國(guó)計(jì)民生的重要領(lǐng)域,并行計(jì)算軟件都有著廣泛的應(yīng)用。由于結(jié)構(gòu)復(fù)雜,代碼量大,并行計(jì)算軟件的開發(fā)效率問(wèn)題日漸引起人們的重視。傳統(tǒng)依靠特定領(lǐng)域的科學(xué)家手工編寫的方式存在很多問(wèn)題,其開發(fā)時(shí)間長(zhǎng),質(zhì)量得不到保證,維護(hù)和復(fù)用也很困難。1998年,美國(guó)的多個(gè)大學(xué)和國(guó)家實(shí)驗(yàn)室聯(lián)合成立了CCA(Common Component Architecture)論壇,開始針對(duì)并行構(gòu)件技術(shù)開展研究[1]。之后,英國(guó)、法國(guó)、意大利等國(guó)的科研人員也紛紛將注意力投入到了對(duì)并行構(gòu)件技術(shù)的研究當(dāng)中[2]。他們?cè)噲D在傳統(tǒng)的串行軟件的構(gòu)件技術(shù)基礎(chǔ)之上,將構(gòu)件技術(shù)引入到并行軟件的開發(fā)過(guò)程中,通過(guò)建立相應(yīng)的構(gòu)件模型,體系結(jié)構(gòu)規(guī)范和運(yùn)行框架,支持對(duì)并行軟件的高效開發(fā)和性能優(yōu)化。在國(guó)內(nèi),清華大學(xué)、國(guó)防科技大學(xué)、北京科技大學(xué)、哈爾濱工業(yè)大學(xué)等許多研究機(jī)構(gòu)也開展了對(duì)并行構(gòu)件技術(shù)的相關(guān)研究[3~9]。在這些研究中,美國(guó)CCA論壇提出的CCA構(gòu)件體系結(jié)構(gòu)規(guī)范由于其規(guī)范性和簡(jiǎn)潔性成為許多其他并行構(gòu)件技術(shù)研究的基礎(chǔ)。
并行構(gòu)件是一種軟件構(gòu)件,其內(nèi)部封裝了并行計(jì)算的程序代碼。并行構(gòu)件程序由不同的并行構(gòu)件連接組成。使用構(gòu)件化的方法開發(fā)并行軟件,提高了軟件的開發(fā)效率。為提高程序的靈活性,在對(duì)程序進(jìn)行構(gòu)件化時(shí),要盡量使用細(xì)粒度的構(gòu)件。這造成了構(gòu)件間相互交互的開銷增大。這些開銷包括多語(yǔ)言互操作,數(shù)據(jù)格式轉(zhuǎn)換,數(shù)據(jù)的收集和分發(fā)以及遠(yuǎn)程方法調(diào)用。并行軟件本身就對(duì)性能有較高的要求,而并行構(gòu)件程序由于引入了構(gòu)件的連接和管理的開銷,對(duì)性能產(chǎn)生了負(fù)面影響。于是,如何優(yōu)化構(gòu)件化后的并行程序的性能,成為一個(gè)亟待解決的問(wèn)題。
并行構(gòu)件程序的負(fù)載均衡方法往往基于已有的并行或分布式平臺(tái)的負(fù)載均衡策略。已有的并行構(gòu)件程序性能優(yōu)化主要采用性能預(yù)測(cè)、自適應(yīng)和負(fù)載均衡的方法。其中負(fù)載均衡的方法試圖平衡計(jì)算平臺(tái)上不同計(jì)算節(jié)點(diǎn)上的負(fù)載,提高系統(tǒng)的資源利用率,提高系統(tǒng)的吞吐量和總體性能。在Concerto平臺(tái)[10]中,執(zhí)行環(huán)境由對(duì)象建模,對(duì)象引用所提供的不同資源,將組件在執(zhí)行過(guò)程中可能使用的任何硬件或軟件實(shí)體視為資源,實(shí)現(xiàn)軟件到硬件的映射。Osama等人[11]提出了一種GPU細(xì)粒度負(fù)載平衡抽象,該抽象將負(fù)載平衡與工作處理解耦,并通過(guò)可編程接口支持靜態(tài)和動(dòng)態(tài)調(diào)度,以實(shí)現(xiàn)新的負(fù)載平衡調(diào)度。王家柱等人[12]針對(duì)對(duì)象存儲(chǔ)系統(tǒng)中負(fù)載均衡方法的不足,將監(jiān)控系統(tǒng)引入對(duì)象存儲(chǔ)系統(tǒng),動(dòng)態(tài)完成節(jié)點(diǎn)間的負(fù)載再平衡。Beraldi等人[13]結(jié)合順序傳輸和自適應(yīng)傳輸兩種新算法,設(shè)計(jì)了一種霧計(jì)算環(huán)境下的負(fù)載均衡算法。王春波[14]在傳統(tǒng)的負(fù)載均衡模型基礎(chǔ)上增加了負(fù)載權(quán)重預(yù)測(cè)功能,采用機(jī)器學(xué)習(xí)的經(jīng)典算法線性回歸來(lái)預(yù)測(cè)各個(gè)負(fù)載權(quán)重值,動(dòng)態(tài)調(diào)整負(fù)載參數(shù),改善了負(fù)載均衡效果。張璐璐等人[15]使用虛擬化服務(wù)器,將物理服務(wù)器虛擬成若干個(gè)服務(wù)實(shí)例,根據(jù)負(fù)載均衡處理需求判斷結(jié)果,完成通信終端的負(fù)載均衡處理。楊乾龍等人[16]選取影響任務(wù)響應(yīng)時(shí)間的特征參數(shù),使用集成學(xué)習(xí)預(yù)測(cè)新任務(wù)的響應(yīng)時(shí)間,分配任務(wù)以達(dá)到服務(wù)器節(jié)點(diǎn)之間負(fù)載均衡的目的。FIRB項(xiàng)目[17]建立資源分配體系結(jié)構(gòu)(RAA)的設(shè)計(jì)準(zhǔn)則,考慮到低層提供的流量模型和服務(wù)原語(yǔ),將來(lái)自網(wǎng)格計(jì)算應(yīng)用程序的請(qǐng)求映射到適當(dāng)?shù)馁Y源上。
通過(guò)對(duì)已有研究的分析發(fā)現(xiàn),負(fù)載均衡技術(shù)可以將并行程序中的計(jì)算任務(wù)合理地分配到不同的計(jì)算資源上執(zhí)行,從而縮短并行程序的執(zhí)行時(shí)間,提高并行程序的性能和計(jì)算資源的利用率。從已有研究來(lái)看,負(fù)載均衡策略大致可以分為靜態(tài)和動(dòng)態(tài)兩類。靜態(tài)負(fù)載均衡策略在執(zhí)行前使用已知的任務(wù)信息將任務(wù)分配到不同的硬件資源上,并且在運(yùn)行時(shí)負(fù)載分布保持不變。而動(dòng)態(tài)負(fù)載均衡在運(yùn)行時(shí)根據(jù)動(dòng)態(tài)生成的任務(wù)信息和計(jì)算節(jié)點(diǎn)的負(fù)載情況,作出任務(wù)分配決策來(lái)滿足不斷變化的需求。動(dòng)態(tài)負(fù)載均衡可以是集中式的,也可以是分布式的。在集中式負(fù)載均衡中,存在一個(gè)計(jì)算節(jié)點(diǎn)作為管理節(jié)點(diǎn),負(fù)責(zé)維護(hù)全局負(fù)載信息并作出負(fù)載均衡決策。而分布式負(fù)載均衡中,每個(gè)計(jì)算節(jié)點(diǎn)在本地作出決策,在承擔(dān)全局負(fù)載均衡責(zé)任的所有計(jì)算節(jié)點(diǎn)之間維護(hù)負(fù)載信息。考慮到如何選擇負(fù)載遷移的目標(biāo)節(jié)點(diǎn),常見的算法有輪詢算法、性能優(yōu)先算法、最快響應(yīng)時(shí)間算法等。已有的研究中,并行構(gòu)件程序的負(fù)載均衡往往使用靜態(tài)的負(fù)載均衡策略或者集中式的動(dòng)態(tài)負(fù)載均衡策略。靜態(tài)的策略不能很好地應(yīng)對(duì)運(yùn)行時(shí)的負(fù)載變化,而集中式的動(dòng)態(tài)策略往往會(huì)對(duì)管理節(jié)點(diǎn)造成較大的負(fù)擔(dān),從而使管理節(jié)點(diǎn)成為整個(gè)系統(tǒng)的瓶頸,影響系統(tǒng)的整體性能。
本文通過(guò)分析CCA并行構(gòu)件的運(yùn)行機(jī)制,提出一種動(dòng)態(tài)的、分布式的并行構(gòu)件程序負(fù)載均衡方法(parallel component dynamic and distributed balance,PCDDB)。通過(guò)基于面向?qū)ο蟮漠悩?gòu)集群計(jì)算資源管理機(jī)制建立計(jì)算節(jié)點(diǎn)的類庫(kù),在類庫(kù)中定義承擔(dān)負(fù)載均衡任務(wù)的相關(guān)接口。通過(guò)編譯這些接口生成計(jì)算節(jié)點(diǎn)的本地計(jì)算資源代理。業(yè)務(wù)功能構(gòu)件通過(guò)編譯業(yè)務(wù)功能接口生成,然后被資源管理節(jié)點(diǎn)部署到使用自定義的聚合算法生成的一個(gè)簇內(nèi)。一個(gè)簇代表了具有良好通信條件的計(jì)算節(jié)點(diǎn)的集合。通過(guò)數(shù)據(jù)流分析得出一個(gè)并行構(gòu)件程序內(nèi)的不同構(gòu)件調(diào)用之間的依賴關(guān)系。在程序運(yùn)行時(shí),將并行構(gòu)件實(shí)例作為待分配的任務(wù)。通過(guò)分布式的表更新算法,維護(hù)計(jì)算平臺(tái)上相關(guān)節(jié)點(diǎn)的負(fù)載信息。當(dāng)有新的構(gòu)件實(shí)例任務(wù)待分配時(shí),任務(wù)分配請(qǐng)求會(huì)在各個(gè)計(jì)算節(jié)點(diǎn)間傳遞,每個(gè)節(jié)點(diǎn)根據(jù)自身的負(fù)載情況,可以選擇接收任務(wù)分配請(qǐng)求中的部分任務(wù),將這些構(gòu)件實(shí)例在本地生成并執(zhí)行。通過(guò)在運(yùn)行時(shí)捕捉計(jì)算節(jié)點(diǎn)的動(dòng)態(tài)負(fù)載信息,分布式地執(zhí)行負(fù)載均衡策略,以較小的開銷實(shí)現(xiàn)了較好的負(fù)載均衡效果,在性能和可擴(kuò)展性方面要優(yōu)于已有方法。
1 基于面向?qū)ο髾C(jī)制的計(jì)算資源管理
1.1 計(jì)算節(jié)點(diǎn)類庫(kù)
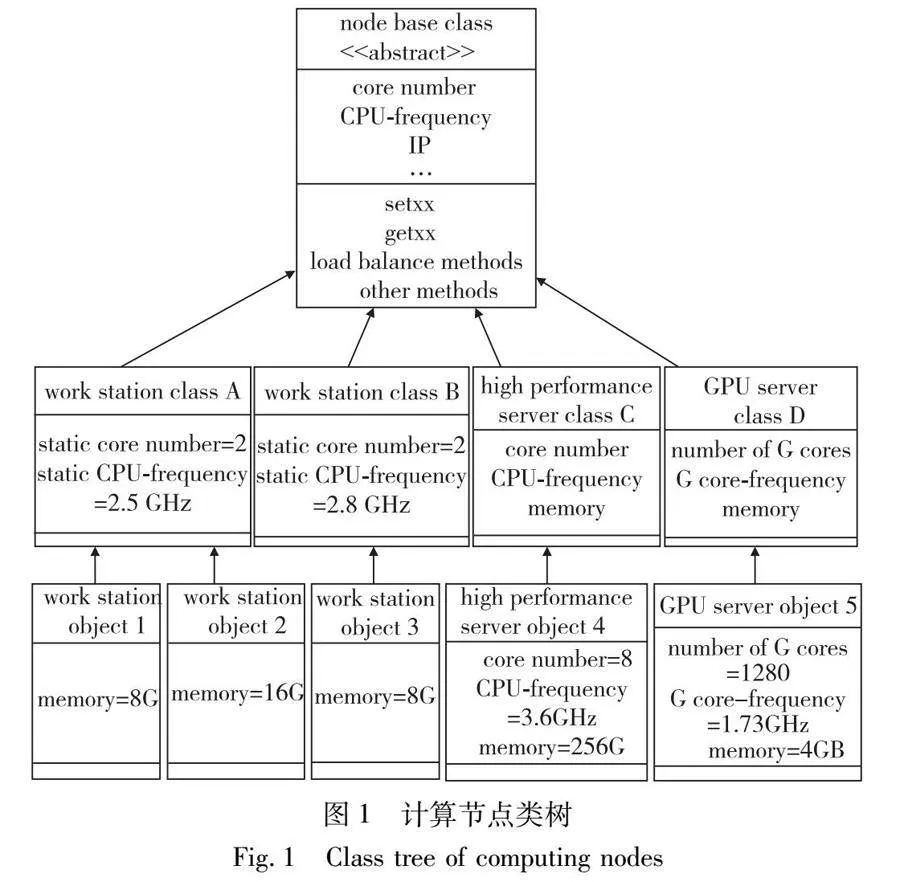
并行構(gòu)件應(yīng)用往往被部署在異構(gòu)的計(jì)算機(jī)集群上運(yùn)行。為更好地管理集群中的計(jì)算資源,實(shí)現(xiàn)并行構(gòu)件的負(fù)載均衡,PCDDB方法首先包括一種基于面向?qū)ο髾C(jī)制的計(jì)算資源管理方法。一個(gè)異構(gòu)的計(jì)算機(jī)集群由很多不同配置的計(jì)算節(jié)點(diǎn)通過(guò)網(wǎng)絡(luò)連接而成,這里的異構(gòu)指的是各個(gè)節(jié)點(diǎn)的配置不同。每個(gè)節(jié)點(diǎn)可以抽象為面向?qū)ο蠹夹g(shù)里的一個(gè)對(duì)象。它有CPU核心數(shù)、CPU主頻、內(nèi)存大小、網(wǎng)絡(luò)帶寬等一些直接影響其運(yùn)行性能的計(jì)算資源屬性,也有主機(jī)名、IP地址等對(duì)節(jié)點(diǎn)進(jìn)行管理時(shí)所使用的屬性。對(duì)于每一個(gè)屬性,基于反射機(jī)制實(shí)現(xiàn)相應(yīng)的set和get方法。對(duì)于不同的節(jié)點(diǎn),它們可能擁有不同的屬性和方法,比如一個(gè)擁有GPU的節(jié)點(diǎn)可能有一個(gè)屬性為CUDA核心數(shù),以及訪問(wèn)這個(gè)屬性的set和get方法。對(duì)于那些擁有相同屬性的節(jié)點(diǎn),抽象出它們共有的特征,定義一個(gè)計(jì)算節(jié)點(diǎn)類。比如可以定義一個(gè)工作站類代表配置相同的某些工作站。當(dāng)有新的節(jié)點(diǎn)需要加入集群時(shí),只要生成某個(gè)計(jì)算節(jié)點(diǎn)類的一個(gè)對(duì)象即可。除set和get方法外,還可以在計(jì)算節(jié)點(diǎn)類中定義一些其他的方法,用來(lái)對(duì)節(jié)點(diǎn)進(jìn)行管理。所有的計(jì)算節(jié)點(diǎn)類有一個(gè)共同的基類,這個(gè)基類被定義為abstract類型,所有的計(jì)算節(jié)點(diǎn)類共有的屬性和方法被定義在這個(gè)基類中,它代表了一個(gè)計(jì)算節(jié)點(diǎn)最基本特征的抽象。圖1給出了本文定義的計(jì)算節(jié)點(diǎn)類樹的一個(gè)例子。
對(duì)于整個(gè)的異構(gòu)集群,需要選擇一個(gè)高性能服務(wù)器作為資源管理節(jié)點(diǎn),在它之上部署一個(gè)集群資源管理器。這個(gè)集群資源管理器建立一個(gè)類庫(kù),管理所有的計(jì)算節(jié)點(diǎn)類。在一個(gè)新的節(jié)點(diǎn)加入集群時(shí),集群資源管理器將查詢這個(gè)節(jié)點(diǎn)的CPU主頻,內(nèi)存容量等計(jì)算資源的信息,根據(jù)這些信息在已有的節(jié)點(diǎn)類里查找對(duì)應(yīng)的類,如果找到一個(gè)類中定義的屬性和新的節(jié)點(diǎn)相符,則使用Babel編譯工具[18]生成這個(gè)類的一個(gè)構(gòu)件實(shí)例(對(duì)象),然后將它發(fā)送給新加入的節(jié)點(diǎn)。這個(gè)構(gòu)件實(shí)例將作為一個(gè)節(jié)點(diǎn)的本地計(jì)算資源代理和其他節(jié)點(diǎn)進(jìn)行交互。如果集群資源管理器在已有的計(jì)算節(jié)點(diǎn)類中找不到和新加入的節(jié)點(diǎn)的屬性相符的類,它將用新節(jié)點(diǎn)的屬性值生成一個(gè)新的節(jié)點(diǎn)類加入類庫(kù),然后再生成新節(jié)點(diǎn)的計(jì)算資源代理并發(fā)送給它。集群資源管理器和所有的資源代理都使用C++語(yǔ)言實(shí)現(xiàn),和同樣是C++實(shí)現(xiàn)的并行構(gòu)件運(yùn)行框架CCAFFEINE[18]有良好的接口。
1.2 計(jì)算節(jié)點(diǎn)聚簇
為減小負(fù)載均衡機(jī)制帶來(lái)的通信開銷,根據(jù)節(jié)點(diǎn)間的網(wǎng)絡(luò)情況,需要將集群中的所有節(jié)點(diǎn)聚合不同的簇。簇是一個(gè)邏輯上的概念,一個(gè)簇相當(dāng)于整個(gè)異構(gòu)集群平臺(tái)的一個(gè)子集。PCDDB方法定義簇的聚合算法如下:
a)設(shè)整個(gè)集群的所有節(jié)點(diǎn)組成集合S,根據(jù)集群中計(jì)算節(jié)點(diǎn)的總數(shù)N,預(yù)估可能的最小簇的規(guī)模m。根據(jù)日常高性能計(jì)算平臺(tái)的資源使用情況,對(duì)于N≤50的集群,一般取m=30%*N」,這個(gè)取值既能為程序分配足夠的資源,又能避免一個(gè)簇的規(guī)模過(guò)大,造成資源的分配不均。
b)因?yàn)橐獙?duì)整個(gè)集群中的所有節(jié)點(diǎn)進(jìn)行聚簇的操作,所以聚簇的起點(diǎn)可以取出集群中任意一個(gè)節(jié)點(diǎn)n0,從這個(gè)節(jié)點(diǎn)向集群中發(fā)送廣播消息,收到這個(gè)消息的節(jié)點(diǎn)向n0發(fā)送回復(fù)。根據(jù)n0收到回復(fù)的順序,記錄前m-1個(gè)返回回復(fù)信息的節(jié)點(diǎn),再加上n0,共m個(gè)節(jié)點(diǎn)組成集合S1。前m-1個(gè)返回回復(fù)信息的節(jié)點(diǎn)代表了整個(gè)集群中和n0之間通信條件最好的m-1個(gè)節(jié)點(diǎn),組成了一個(gè)以n0為中心的,相互之間能夠良好通信的集合S1。
c)取出S1中任意一個(gè)節(jié)點(diǎn)n1,且n1≠n0,重復(fù)步驟b),得到集合S2。注意,雖然n1≠n0,但n1SymbolNC@ S1且n1SymbolNC@ S2,S2是由n1擴(kuò)展生成的,故有可能S2= S1。S2中的節(jié)點(diǎn)組成一個(gè)以n1為中心的,相互之間能夠良好通信的集合。又n1SymbolNC@ S1,所以S1和 S2之間也能進(jìn)行良好的通信。
d)取出S2中任意一個(gè)節(jié)點(diǎn)n2,且n2≠n0,n2≠n1。重復(fù)步驟b),得到集合S3。同樣,由于n2SymbolNC@ S2,而S3是由n2擴(kuò)展生成的,故有可能S3= S2。
e)求S1、S2和S3的并集Sc1=S1∪S2∪S3,Sc1即為所求的一個(gè)簇。因?yàn)閙=30%*N」,經(jīng)過(guò)三次廣播,Sc1的最小規(guī)模是m(當(dāng)S1= S2= S3時(shí)),最大規(guī)模可能接近N的90%。因此, Sc1作為一個(gè)簇已經(jīng)可以接受。
f)在集合S′=S-Sc1中選取任意一個(gè)節(jié)點(diǎn)n0′,重復(fù)步驟b)~e),可得一個(gè)簇Sc2。
g)若S=Sc1∪Sc2,則聚簇過(guò)程結(jié)束,此時(shí)整個(gè)集群中的所有節(jié)點(diǎn)都已經(jīng)被分在了Sc1 或Sc2中。Sc1和Sc2即為最終得到的兩個(gè)簇。否則,取出集合S\"=S-(Sc1∪Sc2)中的任意一個(gè)節(jié)點(diǎn),重復(fù)步驟b)~e),得到新簇后,計(jì)算所有簇的并集,直到所求得的所有簇的并集等于S(整個(gè)集群),算法結(jié)束。
這種聚合簇的方法的依據(jù)是集群中節(jié)點(diǎn)間的網(wǎng)絡(luò)狀況,每個(gè)簇內(nèi)所包含的節(jié)點(diǎn)間具有較好的通信條件。同一個(gè)并行構(gòu)件程序內(nèi)不同構(gòu)件實(shí)例的負(fù)載均衡將在同一個(gè)簇內(nèi)進(jìn)行,以減少負(fù)載均衡的開銷。每個(gè)簇的大小不小于m。同時(shí),算法求出不同的簇可能沒有交集,但也有可能包含一些相同的節(jié)點(diǎn),這是很自然的。聚簇算法中并沒有強(qiáng)制性地要求Sc1∩Sc2=。比如,如果S={n0,n1,n2,n3,n4,n5,…,n14},通過(guò)聚簇得到了簇Sc1={n0,n1,n2,n3,n4},然后在S-Sc1中選擇n6為起點(diǎn)繼續(xù)進(jìn)行聚簇希望得到Sc2,如果n3、n4和n6間的通信條件很好,那么n3、n4同樣會(huì)在n6發(fā)送廣播消息時(shí)率先返回,從而使n3、n4也屬于Sc2。對(duì)于同一個(gè)簇包含的各個(gè)節(jié)點(diǎn),在本地計(jì)算資源代理構(gòu)件實(shí)例(對(duì)象)中,簇ID屬性取相同的值。如果一個(gè)節(jié)點(diǎn)屬于多個(gè)簇,它將具有多個(gè)簇ID。在聚簇過(guò)程結(jié)束后,將由用戶在每一個(gè)簇內(nèi)手工指定一個(gè)節(jié)點(diǎn)作為啟動(dòng)節(jié)點(diǎn),負(fù)責(zé)部署到本簇上的并行構(gòu)件程序的啟動(dòng)。計(jì)算節(jié)點(diǎn)類庫(kù)的維護(hù),簇的聚合將利用集群負(fù)載較低的空閑時(shí)刻進(jìn)行。
2 CCA并行構(gòu)件程序的負(fù)載均衡
2.1 CCA-balance環(huán)境
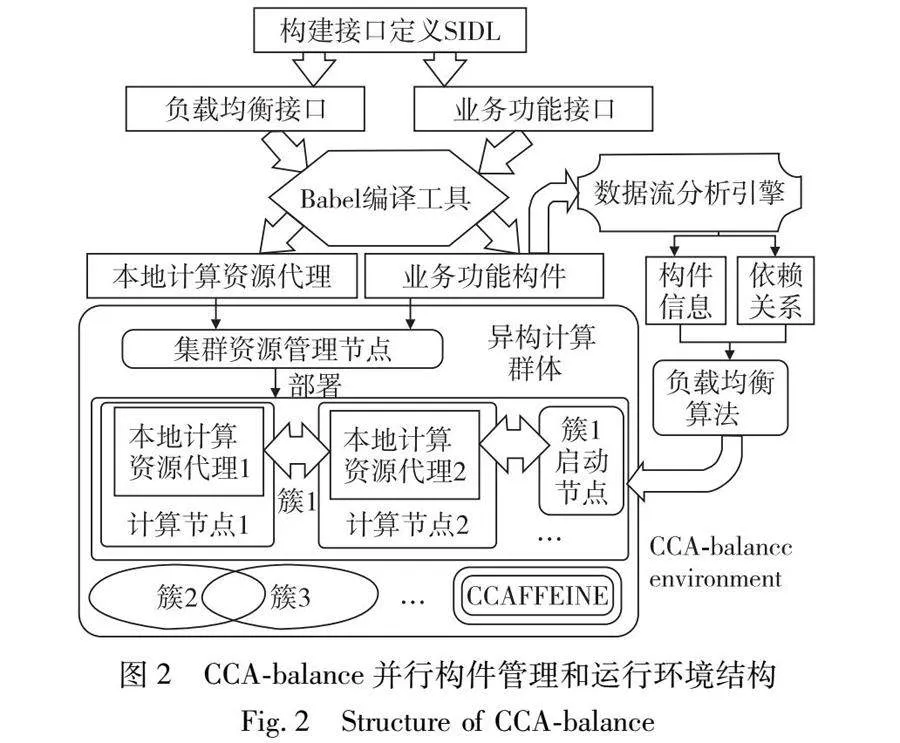
基于CCA體系結(jié)構(gòu)規(guī)范的并行構(gòu)件被稱為CCA并行構(gòu)件,由這種構(gòu)件組成的程序被稱為CCA并行構(gòu)件程序。美國(guó)能源部Sandia國(guó)家實(shí)驗(yàn)室開發(fā)了cca-tools[18]工具箱。CCA并行構(gòu)件的制作主要使用Babel編譯器生成構(gòu)件框架,由用戶填寫代碼實(shí)現(xiàn)。CCAFFEINE框架負(fù)責(zé)在運(yùn)行時(shí)鏈接構(gòu)件的構(gòu)件庫(kù),支持構(gòu)件的運(yùn)行。一個(gè)構(gòu)件實(shí)例用一個(gè)C++對(duì)象表示。這個(gè)對(duì)象中包括了該構(gòu)件運(yùn)行需要的所有數(shù)據(jù)結(jié)構(gòu)的定義,相當(dāng)于該構(gòu)件定義的一個(gè)拷貝。CCA并行構(gòu)件程序?qū)⑼粋€(gè)構(gòu)件的多個(gè)實(shí)例部署到不同的計(jì)算節(jié)點(diǎn)上,以多進(jìn)程的方式并行執(zhí)行。異構(gòu)的集群平臺(tái)上往往同時(shí)運(yùn)行著多個(gè)構(gòu)件程序。原始的CCA并行構(gòu)件程序沒有考慮到執(zhí)行平臺(tái)上不同計(jì)算節(jié)點(diǎn)處理能力的差異,這就造成了不同節(jié)點(diǎn)間構(gòu)件任務(wù)的不均衡。那些計(jì)算能力強(qiáng),分配到的構(gòu)件實(shí)例較少的節(jié)點(diǎn)將較早地完成自己的任務(wù),從而處于空閑狀態(tài)。而其他節(jié)點(diǎn)則需要花費(fèi)較長(zhǎng)的時(shí)間完成自己的任務(wù)。這種不均衡造成了集群平臺(tái)上計(jì)算資源的浪費(fèi),降低了并行構(gòu)件程序的性能和整個(gè)系統(tǒng)的吞吐率。為解決這個(gè)問(wèn)題,PCDDB方法在Babel編譯器和CCAFFEINE框架的基礎(chǔ)上,增加了異構(gòu)集群計(jì)算節(jié)點(diǎn)資源管理、業(yè)務(wù)構(gòu)件數(shù)據(jù)流分析和構(gòu)件實(shí)例負(fù)載均衡功能,集成為一個(gè)高效的并行構(gòu)件程序管理和運(yùn)行環(huán)境CCA-balance。整個(gè)環(huán)境的結(jié)構(gòu)如圖2所示。
從圖2中可以看出,在CCA-balance中,通過(guò)科學(xué)計(jì)算構(gòu)件接口定義語(yǔ)言SIDL[19]定義負(fù)載均衡接口和業(yè)務(wù)功能接口。Babel編譯工具通過(guò)編譯這兩類接口,分別生成計(jì)算節(jié)點(diǎn)本地計(jì)算資源代理和業(yè)務(wù)功能構(gòu)件。異構(gòu)集群的資源管理節(jié)點(diǎn)將這些構(gòu)件(實(shí)例)部署到集群中的計(jì)算節(jié)點(diǎn)上。數(shù)據(jù)流分析引擎分析業(yè)務(wù)功能構(gòu)件程序代碼,得到構(gòu)件調(diào)用接口、輸入?yún)?shù)等信息,以及構(gòu)件間的依賴關(guān)系。根據(jù)分布式的負(fù)載均衡算法,需要執(zhí)行的構(gòu)件實(shí)例任務(wù)將在一個(gè)簇內(nèi)進(jìn)行分配。這個(gè)簇內(nèi)的計(jì)算節(jié)點(diǎn)根據(jù)自身負(fù)載情況,選擇接收任務(wù)分配請(qǐng)求中的部分任務(wù),在節(jié)點(diǎn)本地調(diào)用CCAFFEINE框架,生成構(gòu)件實(shí)例并執(zhí)行。
2.2 負(fù)載均衡接口
PCDDB方法在普通并行構(gòu)件業(yè)務(wù)功能接口的基礎(chǔ)上,定義了一類新的構(gòu)件接口,即負(fù)載均衡接口。這類接口主要供計(jì)算節(jié)點(diǎn)的本地計(jì)算資源代理對(duì)象使用。這些接口被定義在計(jì)算節(jié)點(diǎn)類樹中的根節(jié)點(diǎn)中,所有計(jì)算節(jié)點(diǎn)類都繼承對(duì)這些接口的定義。Babel工具編譯這些接口,生成對(duì)應(yīng)的計(jì)算節(jié)點(diǎn)本地計(jì)算資源代理對(duì)象,從而提供分布式的負(fù)載均衡機(jī)制。這些接口采用SIDL語(yǔ)言定義。SIDL是一種類似于C語(yǔ)言的接口定義語(yǔ)言,通過(guò)說(shuō)明接口的名稱、返回值和輸入?yún)?shù)來(lái)對(duì)一個(gè)接口進(jìn)行定義。在對(duì)接口定義以后,通過(guò)Babel編譯工具對(duì)這些接口進(jìn)行編譯,在編譯過(guò)程中,填寫代碼的實(shí)現(xiàn)部分,加入各個(gè)接口需要實(shí)現(xiàn)的功能。負(fù)載均衡接口被各個(gè)計(jì)算節(jié)點(diǎn)的本地資源代理實(shí)現(xiàn),承擔(dān)分布式的負(fù)載均衡任務(wù)。接口的功能包括檢查節(jié)點(diǎn)自身負(fù)載狀態(tài)、接收和發(fā)送任務(wù)分配請(qǐng)求、更新本地相關(guān)表、接收構(gòu)件實(shí)例任務(wù)等功能。在執(zhí)行本文的動(dòng)態(tài)、分布式負(fù)載均衡算法時(shí),不同的計(jì)算節(jié)點(diǎn)間將使用這些功能進(jìn)行交互。這些功能將在本文定義的負(fù)載均衡算法工作時(shí),起到分布式地分配并行構(gòu)件實(shí)例任務(wù)到負(fù)載較輕的計(jì)算節(jié)點(diǎn)上的作用。從這些接口的定義可以看出,這些接口所主要處理的輸入數(shù)據(jù)包括任務(wù)分配請(qǐng)求和一些相關(guān)的本地表。
表1列出了本文使用的負(fù)載均衡接口的定義和作用。除負(fù)載均衡接口外,Babel工具還將編譯并行構(gòu)件的業(yè)務(wù)功能接口,生成對(duì)應(yīng)的業(yè)務(wù)功能構(gòu)件。對(duì)于一個(gè)并行構(gòu)件程序,當(dāng)業(yè)務(wù)功能構(gòu)件的代碼生成以后,通過(guò)調(diào)用Babel工具和Libtool[20]工具將每個(gè)構(gòu)件的代碼編譯成一個(gè).la動(dòng)態(tài)庫(kù)。在構(gòu)件程序運(yùn)行以前,整個(gè)集群的資源管理節(jié)點(diǎn)將選擇一個(gè)簇,把這個(gè)程序的每個(gè)構(gòu)件的.la動(dòng)態(tài)庫(kù)復(fù)制到這個(gè)簇的每個(gè)計(jì)算節(jié)點(diǎn)上。在運(yùn)行時(shí)屬于同一個(gè)程序的構(gòu)件實(shí)例的負(fù)載均衡將在這個(gè)簇的內(nèi)部進(jìn)行。把一個(gè)構(gòu)件實(shí)例動(dòng)態(tài)地指派到簇內(nèi)的一個(gè)計(jì)算節(jié)點(diǎn)上,并不需要通過(guò)網(wǎng)絡(luò)傳輸這個(gè)構(gòu)件實(shí)例的代碼,只需要將構(gòu)件的名稱、接口和參數(shù)發(fā)送給這個(gè)節(jié)點(diǎn),由節(jié)點(diǎn)本地計(jì)算資源代碼調(diào)用CCAFFEINE框架,鏈接構(gòu)件的.la動(dòng)態(tài)庫(kù),生成這個(gè)構(gòu)件實(shí)例并執(zhí)行。
2.3 數(shù)據(jù)流分析
為實(shí)現(xiàn)MCMD(multiple component multiple data)方式執(zhí)行并行構(gòu)件程序,為負(fù)載均衡提供實(shí)現(xiàn)基礎(chǔ),需要對(duì)業(yè)務(wù)功能構(gòu)件的代碼進(jìn)行數(shù)據(jù)流分析。PCDDB方法的數(shù)據(jù)流分析只討論對(duì)構(gòu)件的源代碼進(jìn)行分析的情況,對(duì)可執(zhí)行的二進(jìn)制文件或動(dòng)態(tài)鏈接庫(kù)暫不考慮。
PCDDB方法包含一個(gè)數(shù)據(jù)流分析引擎,通過(guò)分析構(gòu)件程序源代碼,統(tǒng)計(jì)代碼中出現(xiàn)的構(gòu)件調(diào)用的次數(shù),沿?cái)?shù)據(jù)流方向標(biāo)記和計(jì)算構(gòu)件的輸入?yún)?shù)。
代碼片段1:
bash file:mpiexec -n 4 -host node0
C++ file:
for (i=1;ilt;=10;i++)
{…
m=Component A.interface1(in i)
Component B.interface2(in m)
…}
例如,通過(guò)對(duì)上面的代碼片段1進(jìn)行數(shù)據(jù)流分析,可以得出在這段C++代碼內(nèi)調(diào)用了A和B兩個(gè)構(gòu)件各10次。對(duì)A的10次調(diào)用都是通過(guò)接口interface1調(diào)用的,輸入?yún)?shù)為i,用in標(biāo)識(shí)這是一個(gè)不用對(duì)外返回的參數(shù)。并且,即使不執(zhí)行interface1的相關(guān)代碼,也能分析出A的10次調(diào)用之間不存在依賴關(guān)系,每次的輸入?yún)?shù)的值分別為1~10。而對(duì)于構(gòu)件B的10次調(diào)用,可以分析出每次調(diào)用的輸入?yún)?shù)依賴于構(gòu)件A的執(zhí)行結(jié)果,也就是構(gòu)件B依賴于構(gòu)件A。對(duì)構(gòu)件代碼的數(shù)據(jù)流分析將包含兩個(gè)結(jié)果,即構(gòu)件間的依賴關(guān)系和依賴關(guān)系已解決的構(gòu)件的接口、輸入?yún)?shù),也就組成了待分配的構(gòu)件實(shí)例任務(wù)。需要注意的是,數(shù)據(jù)流分析是以源代碼內(nèi)構(gòu)件的調(diào)用為基本單元進(jìn)行的。如果在構(gòu)件程序執(zhí)行時(shí),一個(gè)構(gòu)件調(diào)用處在并行的代碼結(jié)構(gòu)中,如多個(gè)MPI進(jìn)程中,那么需要根據(jù)代碼的并行度生成這個(gè)構(gòu)件的多個(gè)實(shí)例并行執(zhí)行,每個(gè)構(gòu)件實(shí)例占用一個(gè)進(jìn)程。在代碼片段1中,構(gòu)件A被調(diào)用了10次,每次調(diào)用都被包含在一段4個(gè)MPI[21]進(jìn)程的程序中,所以程序總共需要生成的構(gòu)件A的實(shí)例為40個(gè),每個(gè)實(shí)例部署到一個(gè)CPU核心上運(yùn)行。
數(shù)據(jù)流分析的結(jié)果將被記錄在一個(gè)XML文件中。下面的XML文件片段為對(duì)代碼片段1進(jìn)行數(shù)據(jù)流分析的結(jié)果記錄。
XML文件片段:
〈component〉
〈name〉A(chǔ)〈/name〉
〈instance〉
〈interface〉interface1〈/interface〉
〈args〉[p4]{1-10}〈/args〉
〈depend〉
〈map〉default〈/map〉
〈list〉B.interface2{m*10}〈/list〉
〈/depend〉
〈/instance〉
〈/component〉
〈component〉
〈name〉B〈/name〉
〈instance〉
〈interface〉interface2〈/interface〉
〈args〉[p4]{m*10}〈/args〉
〈/instance〉
〈/component〉
再選擇一個(gè)簇,用來(lái)部署和執(zhí)行一個(gè)并行構(gòu)件應(yīng)用程序時(shí),對(duì)這個(gè)程序的數(shù)據(jù)流分析結(jié)果XML文件將放在這個(gè)簇的啟動(dòng)節(jié)點(diǎn)上。根據(jù)數(shù)據(jù)流分析的結(jié)果,如果一個(gè)構(gòu)件不依賴于其他任何未執(zhí)行的構(gòu)件,并且它自身還未被執(zhí)行,這個(gè)構(gòu)件處于就緒狀態(tài),也就是可以立即執(zhí)行的狀態(tài)。
2.4 構(gòu)件實(shí)例任務(wù)的生成和計(jì)算資源分配
在程序執(zhí)行過(guò)程中,構(gòu)件實(shí)例任務(wù)的生成和計(jì)算資源分配就是要為處于就緒狀態(tài)的構(gòu)件動(dòng)態(tài)地分配計(jì)算資源執(zhí)行,以達(dá)到負(fù)載均衡的目的。PCDDB方法包含一個(gè)負(fù)載均衡任務(wù)管理器來(lái)完成構(gòu)件實(shí)例任務(wù)生成和啟動(dòng)資源分配的工作。這個(gè)負(fù)載均衡任務(wù)管理器部署在每個(gè)簇的啟動(dòng)節(jié)點(diǎn)上。兩類事件的發(fā)生將激活這個(gè)管理器,執(zhí)行相應(yīng)的負(fù)載均衡策略。第一類事件是用戶啟動(dòng)該簇上部署的一個(gè)并行構(gòu)件程序的執(zhí)行,那些在程序執(zhí)行一開始就處于就緒狀態(tài)的構(gòu)件需要被分配資源并執(zhí)行。當(dāng)一個(gè)構(gòu)件處于就緒狀態(tài)時(shí),通過(guò)查詢數(shù)據(jù)流分析結(jié)果的XML文件,可以知道這個(gè)構(gòu)件需要生成多少個(gè)實(shí)例,以及這些實(shí)例的接口和輸入?yún)?shù)。負(fù)載均衡任務(wù)管理器會(huì)把這些信息包裝為任務(wù)分配請(qǐng)求,在本簇內(nèi)的欠載節(jié)點(diǎn)之間進(jìn)行傳遞,分布式地為這些實(shí)例分配計(jì)算資源并執(zhí)行。第二類事件是當(dāng)本簇內(nèi)的一個(gè)并行構(gòu)件調(diào)用執(zhí)行完畢,執(zhí)行的結(jié)果會(huì)由執(zhí)行該構(gòu)件的節(jié)點(diǎn)上的本地計(jì)算資源代理返回本簇的啟動(dòng)節(jié)點(diǎn),負(fù)載均衡任務(wù)管理器修改數(shù)據(jù)流分析XML文件,將所有依賴于已完成構(gòu)件的其他構(gòu)件修改為就緒狀態(tài),將它們的信息包裝為任務(wù)分配請(qǐng)求,啟動(dòng)負(fù)載均衡算法分布式地為處于就緒狀態(tài)的構(gòu)件實(shí)例分配計(jì)算資源并執(zhí)行。
2.5 負(fù)載均衡算法
定義兩個(gè)閾值LT和MT。每個(gè)計(jì)算節(jié)點(diǎn)維護(hù)著一個(gè)本地的構(gòu)件實(shí)例表,記錄了自己擁有的構(gòu)件實(shí)例的數(shù)量。如果這個(gè)數(shù)量小于LT,就認(rèn)為這個(gè)節(jié)點(diǎn)上的任務(wù)過(guò)少,需要接收新的任務(wù)。一個(gè)簇內(nèi)的每個(gè)節(jié)點(diǎn)還要維護(hù)一個(gè)本地的欠載節(jié)點(diǎn)表,記錄那些本簇內(nèi)任務(wù)過(guò)少的節(jié)點(diǎn)的信息。MT代表了負(fù)載適中的情況,當(dāng)需要為任務(wù)過(guò)少的節(jié)點(diǎn)分配新的任務(wù)時(shí),要保證這個(gè)節(jié)點(diǎn)上的任務(wù)總數(shù)不超過(guò)MT。LT和MT的初始值針對(duì)單核節(jié)點(diǎn)進(jìn)行設(shè)置。如果一個(gè)節(jié)點(diǎn)是多核節(jié)點(diǎn)(n個(gè)CPU核心),那么在該節(jié)點(diǎn)上相應(yīng)的LT和MT的值是單核節(jié)點(diǎn)的n倍。一般情況下,單核節(jié)點(diǎn)的LT取2~4,MT取6~10即可。當(dāng)大多數(shù)并行構(gòu)件實(shí)例的計(jì)算量都很小時(shí),可適當(dāng)提高LT的值。當(dāng)計(jì)算節(jié)點(diǎn)的個(gè)數(shù)較多,可用資源充足,可適當(dāng)降低MT的值。相反,當(dāng)計(jì)算資源較少,需要適當(dāng)提高M(jìn)T的值。在本文的實(shí)驗(yàn)部分給出了具體的例子。
負(fù)載均衡算法的整體過(guò)程如下:
a)每個(gè)節(jié)點(diǎn)周期性地檢查自身狀態(tài),若自己的構(gòu)件實(shí)例表中實(shí)例個(gè)數(shù)小于LT,則在本地欠載節(jié)點(diǎn)表中記錄自身為欠載節(jié)點(diǎn),并將自身狀態(tài)發(fā)給啟動(dòng)節(jié)點(diǎn)。啟動(dòng)節(jié)點(diǎn)根據(jù)收到的狀態(tài)信息更新自己的本地欠載節(jié)點(diǎn)表。
b)在程序運(yùn)行過(guò)程中,假設(shè)啟動(dòng)節(jié)點(diǎn)上的負(fù)載均衡任務(wù)管理器發(fā)現(xiàn)有N個(gè)新的構(gòu)件實(shí)例需要生成并執(zhí)行,那么它將這N個(gè)構(gòu)件實(shí)例的構(gòu)件名稱、接口和輸入?yún)?shù),以及自己的欠載節(jié)點(diǎn)表一起包裝為任務(wù)分配請(qǐng)求,并發(fā)給自己的欠載節(jié)點(diǎn)表中的第一個(gè)節(jié)點(diǎn)。若啟動(dòng)節(jié)點(diǎn)的欠載節(jié)點(diǎn)表為空,則等待一段時(shí)間后再次查詢?cè)摫怼?/p>
c)當(dāng)一個(gè)節(jié)點(diǎn)收到任務(wù)分配請(qǐng)求后,它首先根據(jù)請(qǐng)求中的欠載節(jié)點(diǎn)表更新自己本地的欠載節(jié)點(diǎn)表,但是不更新本地表中自身狀態(tài)的信息,因?yàn)樽陨淼臓顟B(tài)信息在本地表中的時(shí)效性更強(qiáng)。
(a)根據(jù)本地表中的信息,如果當(dāng)前節(jié)點(diǎn)不是欠載節(jié)點(diǎn),則將自身從任務(wù)分配請(qǐng)求中的欠載節(jié)點(diǎn)表中刪除,再將任務(wù)分配請(qǐng)求轉(zhuǎn)發(fā)給本地欠載節(jié)點(diǎn)表中的第一個(gè)節(jié)點(diǎn)。
(b)根據(jù)本地表中的信息,如果當(dāng)前節(jié)點(diǎn)是欠載節(jié)點(diǎn),并且本地構(gòu)件實(shí)例表中的構(gòu)件實(shí)例數(shù)為x,則選取任務(wù)分配請(qǐng)求中的MT-x個(gè)構(gòu)件實(shí)例作為自身新分配到的任務(wù),調(diào)用CCAFFEINE框架在本地生成并執(zhí)行。如果當(dāng)前節(jié)點(diǎn)包括多個(gè)CPU核心,則把這MT-x個(gè)構(gòu)件實(shí)例平均分配到各個(gè)CPU核心上執(zhí)行。然后,當(dāng)前節(jié)點(diǎn)將自身從任務(wù)分配請(qǐng)求和本地的欠載節(jié)點(diǎn)表中刪除,并回復(fù)啟動(dòng)節(jié)點(diǎn),回復(fù)內(nèi)容是自身新分配到的任務(wù)信息。修改任務(wù)分配請(qǐng)求,將這MT-x個(gè)構(gòu)件實(shí)例從任務(wù)分配請(qǐng)求中刪除,如果任務(wù)分配請(qǐng)求中還剩有任務(wù)待分配,則將任務(wù)分配請(qǐng)求發(fā)送給自身欠載節(jié)點(diǎn)表中第一個(gè)節(jié)點(diǎn)。
d)啟動(dòng)節(jié)點(diǎn)收到某個(gè)節(jié)點(diǎn)的回復(fù)后,將這個(gè)節(jié)點(diǎn)從自身的欠載節(jié)點(diǎn)表中刪除。
e)如果某節(jié)點(diǎn)持有的任務(wù)分配請(qǐng)求中還有剩余任務(wù)待分配,但是本地的欠載節(jié)點(diǎn)表為空,它會(huì)將任務(wù)分配請(qǐng)求發(fā)送給啟動(dòng)節(jié)點(diǎn),由啟動(dòng)節(jié)點(diǎn)重新分配。
f) 根據(jù)收到的回復(fù)消息,啟動(dòng)節(jié)點(diǎn)了解構(gòu)件實(shí)例任務(wù)在計(jì)算節(jié)點(diǎn)上的分配情況,每個(gè)計(jì)算節(jié)點(diǎn)執(zhí)行完構(gòu)件實(shí)例任務(wù)的結(jié)果將由啟動(dòng)節(jié)點(diǎn)收集,以完成構(gòu)件程序。
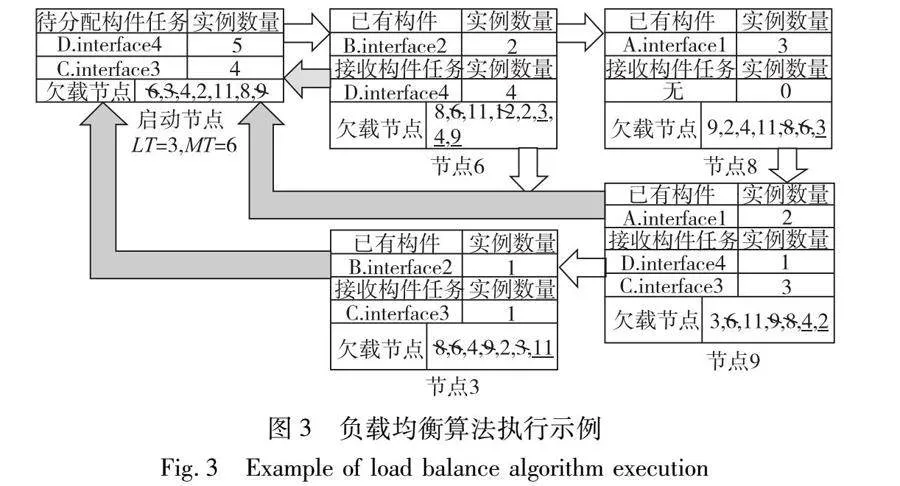
圖3為一個(gè)例子用來(lái)說(shuō)明了本文提出的負(fù)載均衡算法的執(zhí)行過(guò)程。從圖3可以看出,假設(shè)啟動(dòng)節(jié)點(diǎn)有5個(gè)構(gòu)件D的實(shí)例和4個(gè)構(gòu)件C的實(shí)例需要分配。它把這些構(gòu)件的名稱、接口和每個(gè)實(shí)例的輸入?yún)?shù),以及自己的欠載節(jié)點(diǎn)表打包為任務(wù)分配請(qǐng)求后發(fā)給自己欠載節(jié)點(diǎn)表里第一個(gè)節(jié)點(diǎn),也就是節(jié)點(diǎn)6。節(jié)點(diǎn)6收到后,首先更新本地的欠載節(jié)點(diǎn)表,加入了節(jié)點(diǎn)3、6和9,并刪除了節(jié)點(diǎn)12。根據(jù)自身的欠載狀態(tài)(已有構(gòu)件實(shí)例數(shù)量為2lt;LT),它接收4個(gè)構(gòu)件D的實(shí)例任務(wù)(MT-2=4),以在本地生成并執(zhí)行。然后它將自身從任務(wù)分配請(qǐng)求中的和本地的欠載節(jié)點(diǎn)表中刪除。接著,節(jié)點(diǎn)6修改任務(wù)分配請(qǐng)求,刪除自己接收的構(gòu)件任務(wù),然后把任務(wù)分配請(qǐng)求轉(zhuǎn)發(fā)給自己欠載節(jié)點(diǎn)表中的第一個(gè)節(jié)點(diǎn),也就是節(jié)點(diǎn)8。節(jié)點(diǎn)8發(fā)現(xiàn)自身不是欠載節(jié)點(diǎn),更新欠載節(jié)點(diǎn)表后直接將任務(wù)分配請(qǐng)求發(fā)送給自身欠載節(jié)點(diǎn)表中的第一個(gè)節(jié)點(diǎn),也就是節(jié)點(diǎn)9。節(jié)點(diǎn)9更新本地欠載節(jié)點(diǎn)表,刪除節(jié)點(diǎn)6和8,增加節(jié)點(diǎn)4和2。根據(jù)自身的構(gòu)件實(shí)例數(shù)量為2lt;LT,它接收1個(gè)構(gòu)件D的實(shí)例任務(wù)和3個(gè)構(gòu)件C的實(shí)例任務(wù),然后將自身從任務(wù)分配請(qǐng)求和自身的欠載節(jié)點(diǎn)表中刪除,將自身接收的構(gòu)件實(shí)例任務(wù)從任務(wù)分配請(qǐng)求中刪除,轉(zhuǎn)發(fā)任務(wù)分配請(qǐng)求到節(jié)點(diǎn)3。節(jié)點(diǎn)3更新本地欠載節(jié)點(diǎn)表,刪除節(jié)點(diǎn)8、6和9,增加節(jié)點(diǎn)11。根據(jù)自身已有的實(shí)例數(shù)量1lt;LT,它接收任務(wù)分配請(qǐng)求中的1個(gè)構(gòu)件C的實(shí)例任務(wù),并將自身從本地欠載節(jié)點(diǎn)表中刪除。至此,從啟動(dòng)節(jié)點(diǎn)發(fā)出的任務(wù)分配請(qǐng)求被全部處理完畢。在圖3中,白色的箭頭代表任務(wù)分配請(qǐng)求的傳遞;灰色的箭頭代表接收構(gòu)件實(shí)例任務(wù)的節(jié)點(diǎn)向啟動(dòng)節(jié)點(diǎn)發(fā)送的回復(fù)。在上面的算法中,每個(gè)節(jié)點(diǎn)檢查自身狀態(tài),更新本地欠載節(jié)點(diǎn)表,接收和轉(zhuǎn)發(fā)任務(wù)分配請(qǐng)求,接收構(gòu)件實(shí)例任務(wù),調(diào)用CCAFFEINE框架,修改任務(wù)分配請(qǐng)求以及回復(fù)啟動(dòng)節(jié)點(diǎn)的操作都被定義在表1的負(fù)載均衡接口中,由節(jié)點(diǎn)的本地計(jì)算資源代理實(shí)現(xiàn)。為減小負(fù)載均衡消息傳遞的開銷,一個(gè)程序的所有構(gòu)件實(shí)例任務(wù)在同一個(gè)簇內(nèi)進(jìn)行分配。如果一個(gè)節(jié)點(diǎn)同時(shí)是多個(gè)簇的成員,那么節(jié)點(diǎn)上包含多個(gè)欠載節(jié)點(diǎn)表,每個(gè)欠載節(jié)點(diǎn)表綁定一個(gè)簇ID值。用戶在啟動(dòng)節(jié)點(diǎn)上啟動(dòng)程序時(shí)將指定簇ID的值,并將它隨任務(wù)分配請(qǐng)求傳遞,每個(gè)節(jié)點(diǎn)根據(jù)此ID值使用對(duì)應(yīng)的本地欠載節(jié)點(diǎn)表。而對(duì)于一個(gè)節(jié)點(diǎn)上的構(gòu)件實(shí)例任務(wù),不論它屬于哪個(gè)構(gòu)件程序,都會(huì)給本地節(jié)點(diǎn)造成負(fù)載壓力,所以構(gòu)件實(shí)例任務(wù)表統(tǒng)計(jì)的是本地節(jié)點(diǎn)上所有的構(gòu)件實(shí)例任務(wù)的個(gè)數(shù),而不論這些構(gòu)件實(shí)例屬于哪個(gè)構(gòu)件程序。為簡(jiǎn)便起見,圖3中的節(jié)點(diǎn)都假設(shè)為單核節(jié)點(diǎn)。在負(fù)載均衡算法的運(yùn)行過(guò)程中,如果一個(gè)節(jié)點(diǎn)是多核的,在該節(jié)點(diǎn)上相應(yīng)的LT和MT的值是單核節(jié)點(diǎn)的n倍(n為該節(jié)點(diǎn)的CPU核心數(shù))。本地計(jì)算資源代理將把自己分配到的構(gòu)件實(shí)例任務(wù)平均分配到自己的每個(gè)CPU核心上。
PCDDB方法使用的是一種分布式的負(fù)載均衡算法,算法的核心內(nèi)容包括相關(guān)表的更新和構(gòu)件實(shí)例任務(wù)的分配。任務(wù)分配請(qǐng)求在各個(gè)節(jié)點(diǎn)之間傳遞,每個(gè)節(jié)點(diǎn)根據(jù)本地相關(guān)表的內(nèi)容選擇性地接收請(qǐng)求中的部分任務(wù),避免了由單一的管理節(jié)點(diǎn)生成負(fù)載均衡決策可能給管理節(jié)點(diǎn)帶來(lái)的巨大壓力。同時(shí),本文使用的負(fù)載均衡算法主要針對(duì)普通的以CPU處理器為核心的計(jì)算資源的分配。
當(dāng)一個(gè)并行構(gòu)件程序內(nèi)的某個(gè)并行構(gòu)件包含有CUDA代碼時(shí),對(duì)這個(gè)程序的數(shù)據(jù)流分析將對(duì)這個(gè)程序及相應(yīng)的構(gòu)件進(jìn)行特殊標(biāo)識(shí)。這個(gè)程序必須被部署到包含配備有GPU的計(jì)算節(jié)點(diǎn)的簇內(nèi)執(zhí)行。該簇內(nèi)所有配備有GPU的計(jì)算節(jié)點(diǎn)上的本地計(jì)算資源代理對(duì)象負(fù)責(zé)維護(hù)本地GPU的狀態(tài)并響應(yīng)啟動(dòng)節(jié)點(diǎn)上負(fù)載均衡任務(wù)管理器的查詢,在本地GPU處于空閑狀態(tài)時(shí),接收包含有CUDA代碼的并行構(gòu)件實(shí)例任務(wù),在本地GPU上執(zhí)行。此外,有一些并行構(gòu)件程序中的某些構(gòu)件有較為特殊的要求,比如有的構(gòu)件需要部署在FPGA上執(zhí)行,有的構(gòu)件要處理較大的數(shù)據(jù)量,需要較大的內(nèi)存等等。這些要求將在進(jìn)行數(shù)據(jù)流分析時(shí)記錄在XML文件內(nèi)。啟動(dòng)節(jié)點(diǎn)上的負(fù)載均衡任務(wù)管理器將把這些特殊要求包含在任務(wù)分配請(qǐng)求中進(jìn)行傳遞,只有符合要求的計(jì)算節(jié)點(diǎn)才會(huì)接收這些任務(wù)并執(zhí)行。
3 實(shí)驗(yàn)
3.1 CPU核心完成構(gòu)件實(shí)例任務(wù)數(shù)和時(shí)間測(cè)試
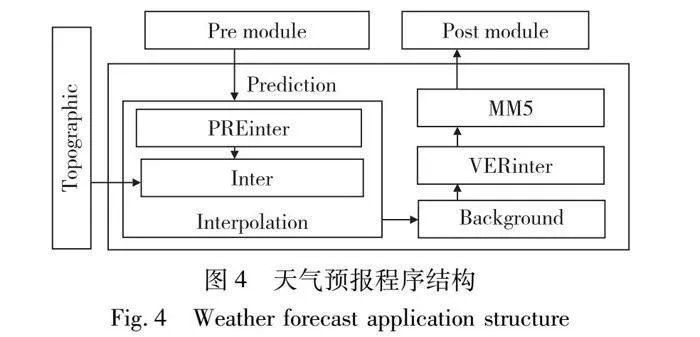
為測(cè)試PCDDB方法提出的分布式動(dòng)態(tài)負(fù)載均衡方法的有效性,本文選取一個(gè)天氣預(yù)報(bào)并行應(yīng)用程序作為應(yīng)用實(shí)例。本文首先基于MM5(第五代中尺度模式)[22]使用cca-tools制作了天氣預(yù)報(bào)并行構(gòu)件應(yīng)用程序。程序包括8個(gè)較大的功能模塊,整體模塊結(jié)構(gòu)如圖4所示。Pre對(duì)輸入數(shù)據(jù)進(jìn)行預(yù)處理,Topographic處理地形數(shù)據(jù),生成地形數(shù)據(jù)文件。PREinter讀取預(yù)處理得到的數(shù)據(jù),生成Inter所需的數(shù)據(jù)。Inter對(duì)輸入的數(shù)據(jù)進(jìn)行插值操作。Background對(duì)氣壓層上的背景場(chǎng)數(shù)據(jù)進(jìn)行分析。VERinter讀取背景場(chǎng)數(shù)據(jù),生成初始格點(diǎn)數(shù)據(jù)和邊界條件。MM5模塊根據(jù)以上各模塊得到的數(shù)據(jù)進(jìn)行分析和預(yù)報(bào)。Post根據(jù)預(yù)報(bào)的結(jié)果生成可視化的數(shù)據(jù)圖形。
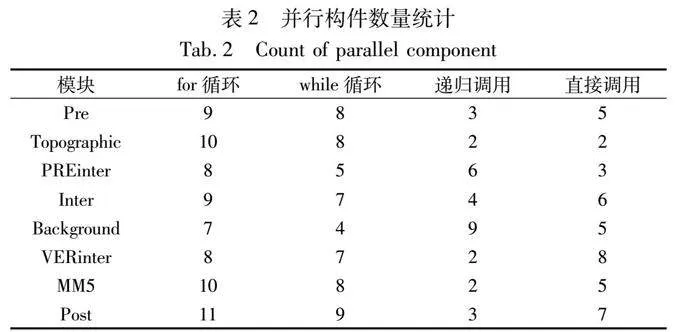
表2給出了在每個(gè)模塊內(nèi)部并行構(gòu)件出現(xiàn)的位置的統(tǒng)計(jì)。如在表2的第一行,在Pre模塊內(nèi)部,有7個(gè)構(gòu)件調(diào)用出現(xiàn)在for循環(huán)內(nèi),有5個(gè)構(gòu)件調(diào)用出現(xiàn)在while循環(huán)內(nèi),有3個(gè)構(gòu)件調(diào)用出現(xiàn)在遞歸調(diào)用結(jié)構(gòu)內(nèi),以及不包含在這三種結(jié)構(gòu)內(nèi)的5個(gè)構(gòu)件調(diào)用。從表2可以看出,整個(gè)程序中大多數(shù)構(gòu)件調(diào)用出現(xiàn)在依賴關(guān)系較簡(jiǎn)單的代碼結(jié)構(gòu)中。不同構(gòu)件并行執(zhí)行的潛力較大,能較好地應(yīng)用本文的負(fù)載均衡策略。
運(yùn)行構(gòu)件程序的計(jì)算平臺(tái)基于異構(gòu)的計(jì)算機(jī)集群。該計(jì)算平臺(tái)由30臺(tái)雙核服務(wù)器(Intel Pentium G4520 @ 3.60 GHz,內(nèi)存8 GB,1~30號(hào)節(jié)點(diǎn))、3臺(tái)8核的多核服務(wù)器(Intel Xeon Silver 4110 @ 2.10 GHz,內(nèi)存64 GB,31~33號(hào)節(jié)點(diǎn))和3臺(tái)10核的多核服務(wù)器(Intel Xeon Silver 4114 @ 2.20 GHz,內(nèi)存256 GB,34~36號(hào)節(jié)點(diǎn))組成。程序的輸入數(shù)據(jù)采用MM5提供的美國(guó)賓州2021年8月7日到8日兩天48小時(shí)內(nèi)每2小時(shí)的高度、溫度、相對(duì)濕度、氣壓、風(fēng)場(chǎng)等天氣信息。輸出為9日到10日兩天48小時(shí)的降水情況。
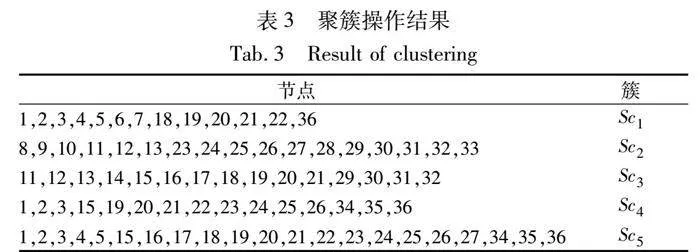
表3給出了在這個(gè)異構(gòu)集群上進(jìn)行聚簇操作的結(jié)果。根據(jù)聚簇操作的結(jié)果,選擇將構(gòu)件程序部署到Sc2上。設(shè)置LT=2,MT=10為相應(yīng)閾值在單核節(jié)點(diǎn)上的初始值,則在雙核節(jié)點(diǎn)上,LT=4,MT=20。在8核節(jié)點(diǎn)上,LT=16,MT=80。選擇33號(hào)節(jié)點(diǎn)作為啟動(dòng)節(jié)點(diǎn)啟動(dòng)構(gòu)件程序。在程序運(yùn)行過(guò)程中,需要分配的構(gòu)件實(shí)例任務(wù)信息被發(fā)送給集群中的欠載節(jié)點(diǎn),由這些節(jié)點(diǎn)生成對(duì)應(yīng)的構(gòu)件實(shí)例并執(zhí)行。對(duì)于多核節(jié)點(diǎn)來(lái)說(shuō),CPU核心是承擔(dān)構(gòu)件實(shí)例任務(wù)的基本單元。實(shí)驗(yàn)統(tǒng)計(jì)每個(gè)節(jié)點(diǎn)上的各個(gè)CPU核心完成的構(gòu)件實(shí)例任務(wù)的個(gè)數(shù)和完成這些任務(wù)所花費(fèi)的時(shí)間。
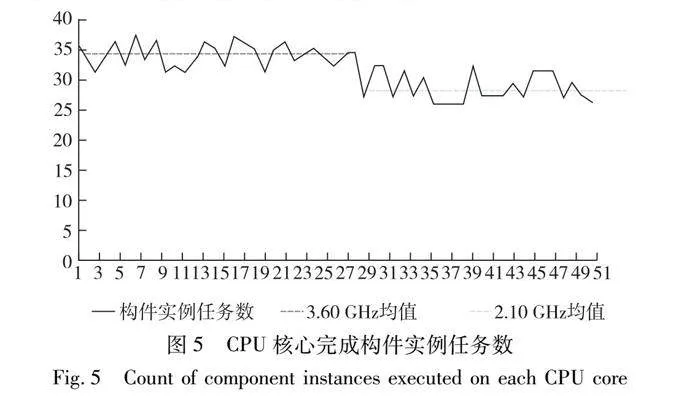
在圖5中,橫坐標(biāo)軸上共有52個(gè)刻度點(diǎn),每個(gè)刻度代表一個(gè)CPU核心。前28個(gè)刻度點(diǎn)代表簇Sc2上前14個(gè)雙核節(jié)點(diǎn)上的每個(gè)CPU核心,比如刻度點(diǎn)1和2代表節(jié)點(diǎn)8的兩個(gè)CPU核心。第29~52刻度點(diǎn)代表Sc2上最后三個(gè)8核節(jié)點(diǎn),即31、32、33號(hào)節(jié)點(diǎn)上的共24個(gè)CPU核心。縱坐標(biāo)代表每個(gè)計(jì)算核心執(zhí)行完成的構(gòu)件實(shí)例任務(wù)數(shù)。對(duì)于前14個(gè)雙核節(jié)點(diǎn),CPU主頻為3.60 GHz,每個(gè)CPU核心完成構(gòu)件實(shí)例任務(wù)數(shù)均值為34,方差為3.6。從圖5中可以看出,這些CPU核心上完成的構(gòu)件實(shí)例任務(wù)數(shù)分布比較均勻,體現(xiàn)出了PCDDB方法使用的負(fù)載均衡機(jī)制產(chǎn)生的效果。對(duì)于后3個(gè)8核節(jié)點(diǎn),每個(gè)CPU核心完成構(gòu)件實(shí)例任務(wù)數(shù)均值為28,比雙核節(jié)點(diǎn)的CPU核心稍低,這是因?yàn)?核節(jié)點(diǎn)的CPU主頻較低,為2.10 GHz。8核節(jié)點(diǎn)的CPU核心完成構(gòu)件實(shí)例任務(wù)數(shù)的方差為5.02,分布均勻。本文的負(fù)載均衡機(jī)制體現(xiàn)了“能者多勞”的原則,處理能力較強(qiáng)的CPU核心能較快地完成自己已有的任務(wù),從而變?yōu)榍份d狀態(tài),從而接收更多的新任務(wù)。
同時(shí)特別需要注意的是,PCDDB方法達(dá)到的負(fù)載均勻分布并不是說(shuō)主頻相同的CPU核心完成的構(gòu)件實(shí)例任務(wù)數(shù)就絕對(duì)一致。從圖5可以看出,即使是同樣主頻的CPU核心,在完成的任務(wù)數(shù)上也有一定的差別。這是因?yàn)闃?gòu)件實(shí)例任務(wù)有大有小。同樣主頻的CPU核心,在同樣的時(shí)間里,可能有的核心能完成多個(gè)小任務(wù),而分配到大任務(wù)的核心可能只能完成一個(gè)大任務(wù)。圖6給出了在各個(gè)節(jié)點(diǎn)上的有效工作時(shí)間的統(tǒng)計(jì)。有效工作時(shí)間是指一個(gè)CPU核心運(yùn)行自己分配到的所有構(gòu)件實(shí)例任務(wù)所花費(fèi)的總時(shí)間。從圖5和6的對(duì)比可以看出,雖然由于存在構(gòu)件實(shí)例任務(wù)大小的差別導(dǎo)致不同CPU核心在構(gòu)件實(shí)例任務(wù)數(shù)上存在一定的差距,但是從有效工作時(shí)間來(lái)看,各個(gè)CPU核心基本上是一致的,體現(xiàn)了PCDDB方法所實(shí)現(xiàn)的負(fù)載均衡的效果。
3.2 性能和加速比對(duì)比測(cè)試
為了測(cè)試本文提出的動(dòng)態(tài)的、分布式的負(fù)載均衡方法相對(duì)于已有的靜態(tài)的或動(dòng)態(tài)的、集中式的方法的優(yōu)勢(shì),在性能和加速比測(cè)試中,除了使用PCDDB方法提出的分布式負(fù)載均衡方法外,還測(cè)試了兩種其他的情況作為對(duì)比。一種是包含靜態(tài)負(fù)載均衡機(jī)制的情況,即只在程序運(yùn)行開始,將所有的構(gòu)件指派到每個(gè)計(jì)算節(jié)點(diǎn)上,運(yùn)行過(guò)程中不再改變分布。一種是動(dòng)態(tài)的、集中式的負(fù)載均衡方法,在每個(gè)計(jì)算節(jié)點(diǎn)上布置監(jiān)控代理,收集計(jì)算節(jié)點(diǎn)的負(fù)載信息發(fā)給一個(gè)中央調(diào)度器,由中央調(diào)度器統(tǒng)一生成負(fù)載遷移策略,將待執(zhí)行的構(gòu)件實(shí)例任務(wù)分配到負(fù)載較輕的節(jié)點(diǎn)上執(zhí)行。
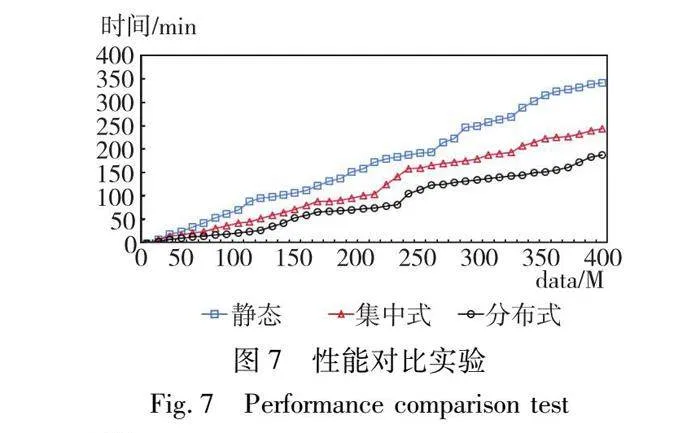
首先通過(guò)實(shí)驗(yàn)對(duì)比了三種方法在性能上的差異。使用本文提出的負(fù)載均衡方法的MM5天氣預(yù)報(bào)并行構(gòu)件程序仍然被部署在簇Sc2上,同樣設(shè)置LT=2,MT=10為相應(yīng)閾值在單核節(jié)點(diǎn)上的初始值,在雙核節(jié)點(diǎn)和8核節(jié)點(diǎn)上取值分別乘以相應(yīng)的核數(shù)。使用其他兩種負(fù)載均衡方法的程序則被部署在隨機(jī)選擇的14臺(tái)雙核節(jié)點(diǎn)和3臺(tái)8核節(jié)點(diǎn)組成的子集群上。通過(guò)改變輸入數(shù)據(jù)的規(guī)模,記錄了使用三種不同負(fù)載均衡方法的程序的執(zhí)行時(shí)間。
通過(guò)圖7可以看出,靜態(tài)的負(fù)載均衡決策在程序運(yùn)行前作出無(wú)法捕捉程序運(yùn)行時(shí)節(jié)點(diǎn)的負(fù)載情況,只能根據(jù)程序中對(duì)使用到的構(gòu)件的定義和程序運(yùn)行的進(jìn)程要求,將各個(gè)構(gòu)件在運(yùn)行前指派到不同的節(jié)點(diǎn)上,在性能上要低于其他兩種方法。動(dòng)態(tài)的、集中式的負(fù)載均衡方法根據(jù)在程序運(yùn)行過(guò)程中計(jì)算節(jié)點(diǎn)的負(fù)載情況,把構(gòu)件實(shí)例任務(wù)部署在負(fù)載較輕的節(jié)點(diǎn)上執(zhí)行,性能要好于靜態(tài)的方法。但是集中式的方法完全依賴唯一的中央調(diào)度器生成和執(zhí)行負(fù)載調(diào)度決策,中央調(diào)度器所在的管理節(jié)點(diǎn)有較大的負(fù)擔(dān),負(fù)載均衡的開銷比較大。PCDDB方法提出的動(dòng)態(tài)的、分布式的負(fù)載均衡決策能實(shí)時(shí)捕捉計(jì)算節(jié)點(diǎn)的負(fù)載情況,同時(shí)將負(fù)載均衡開銷分布到一個(gè)通信條件很好的簇內(nèi)的各計(jì)算節(jié)點(diǎn)上,和其他兩種方法相比,取得了最好的性能表現(xiàn)。
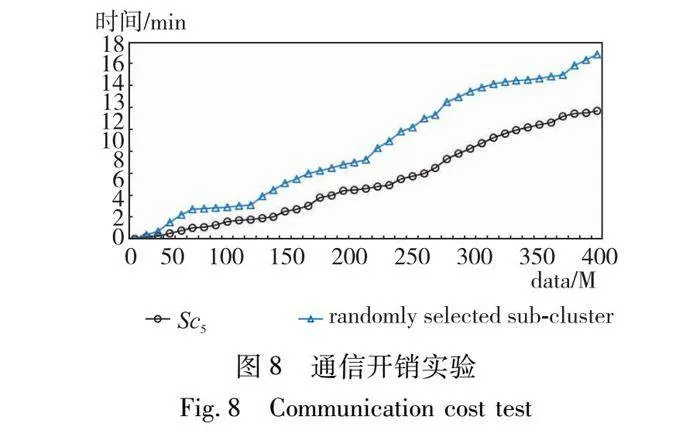
為進(jìn)一步驗(yàn)證PCDDB方法提出的聚簇方法在減小負(fù)載均衡機(jī)制的通信開銷上的優(yōu)勢(shì),將采用了PCDDB方法的分布式負(fù)載均衡機(jī)制的MM5構(gòu)件程序分別部署在簇Sc5和隨機(jī)選擇的18臺(tái)雙核節(jié)點(diǎn)組成的子集群上。設(shè)置LT=2,MT=10為相應(yīng)閾值在單核節(jié)點(diǎn)上的初始值,在雙核節(jié)點(diǎn)上LT=4,MT=20,在8核節(jié)點(diǎn)上LT=16,MT=80。通過(guò)改變輸入數(shù)據(jù)的規(guī)模,記錄了兩種不同的部署方法運(yùn)行程序時(shí)的負(fù)載均衡通信開銷,這些通信開銷包括負(fù)載均衡算法中計(jì)算節(jié)點(diǎn)向啟動(dòng)節(jié)點(diǎn)發(fā)送的自身欠載狀態(tài),構(gòu)件實(shí)例任務(wù)分配請(qǐng)求在各節(jié)點(diǎn)間的傳遞,以及接收構(gòu)件實(shí)例的節(jié)點(diǎn)發(fā)送給啟動(dòng)節(jié)點(diǎn)的回復(fù)。圖8顯示了通信開銷實(shí)驗(yàn)的結(jié)果。從圖8中可以看出,在使用PCDDB方法提出的負(fù)載均衡機(jī)制時(shí),將程序部署在使用PCDDB方法的聚簇算法生成的簇內(nèi),可以具有較小的通信開銷。
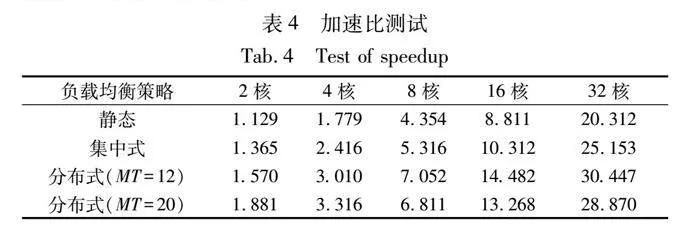
為測(cè)試PCDDB方法提出負(fù)載均衡方法的可擴(kuò)展性,選擇簇Sc5中的部分雙核節(jié)點(diǎn)來(lái)部署天氣預(yù)報(bào)構(gòu)件程序。Sc5中共有18個(gè)雙核節(jié)點(diǎn),分別取出1個(gè)、2個(gè)、4個(gè)、8個(gè)和16個(gè)節(jié)點(diǎn)進(jìn)行測(cè)試,分別對(duì)應(yīng)2核、4核、8核、16核和32核的情況,使用前面定義的三種不同的負(fù)載均衡方法,計(jì)算程序運(yùn)行時(shí)和單核(沒有任何負(fù)載均衡策略)的情況相比對(duì)應(yīng)的加速比。對(duì)于本文提出的動(dòng)態(tài)的、分布式的負(fù)載均衡方法,由于使用的全部是雙核節(jié)點(diǎn),設(shè)置雙核節(jié)點(diǎn)的LT=4,MT取值分別為MT=12和MT=20進(jìn)行了測(cè)試。
表4顯示了對(duì)加速比的測(cè)試結(jié)果。可以看出,隨著核數(shù)的增多,動(dòng)態(tài)的、分布式的負(fù)載均衡方式相對(duì)于靜態(tài)的和集中式的方法都取得了更好的加速比。同時(shí),使用PCDDB方法的分布式負(fù)載均衡方法,如果計(jì)算節(jié)點(diǎn)的個(gè)數(shù)較多,可用資源充足,而計(jì)算平臺(tái)上運(yùn)行的程序較少,即平臺(tái)的負(fù)載整體較輕,欠載節(jié)點(diǎn)較多時(shí),適當(dāng)降低MT的值,使每個(gè)欠載節(jié)點(diǎn)上分配較少新的任務(wù),就可以利用更多的欠載節(jié)點(diǎn),取得更好的運(yùn)行性能。這點(diǎn)在表4中MT=12的加速比在8核、16核、32核時(shí)比MT=20要高可以看出。相反,如果計(jì)算平臺(tái)上節(jié)點(diǎn)的個(gè)數(shù)很少,MT的值較低,但是待分配的任務(wù)較多的話,將導(dǎo)致一部分任務(wù)無(wú)法得到及時(shí)的分配。這部分任務(wù)將被返回啟動(dòng)節(jié)點(diǎn)等待再次分配。如果這種情況多次出現(xiàn),將降低系統(tǒng)的性能。這點(diǎn)從表4中,在2核和4核上MT=12的加速比比MT=20的相對(duì)較差可以看出。在執(zhí)行本文提出的負(fù)載均衡算法前,要根據(jù)集群的計(jì)算資源和負(fù)載情況,設(shè)置恰當(dāng)?shù)腖T和MT的值,能取得更好的負(fù)載均衡效果。
4 結(jié)束語(yǔ)
本文通過(guò)分析和研究CCA并行構(gòu)件程序的運(yùn)行特征,在基于面向?qū)ο髾C(jī)制的計(jì)算資源管理的基礎(chǔ)上,提出一種動(dòng)態(tài)的、分布式的并行構(gòu)件程序負(fù)載均衡方法。首先抽取異構(gòu)計(jì)算集群上計(jì)算節(jié)點(diǎn)的典型特征,建立計(jì)算節(jié)點(diǎn)的類庫(kù)。根據(jù)集群內(nèi)節(jié)點(diǎn)間的網(wǎng)絡(luò)狀況,使用自定義的聚合算法,將計(jì)算節(jié)點(diǎn)聚合成不同的簇。Babel編譯器編譯SIDL語(yǔ)言定義的負(fù)載均衡接口和業(yè)務(wù)功能接口,分別生成計(jì)算節(jié)點(diǎn)的本地計(jì)算資源代理和并行構(gòu)件程序的業(yè)務(wù)功能構(gòu)件。集群資源管理節(jié)點(diǎn)將計(jì)算資源代理分別部署到對(duì)應(yīng)的計(jì)算節(jié)點(diǎn)上。數(shù)據(jù)流分析引擎通過(guò)分析業(yè)務(wù)功能構(gòu)件的代碼,得到構(gòu)件實(shí)例任務(wù)的信息和依賴關(guān)系。對(duì)于一個(gè)構(gòu)件程序,用戶手工選擇一個(gè)簇,集群資源管理節(jié)點(diǎn)將構(gòu)件代碼部署到這個(gè)簇內(nèi)的所有節(jié)點(diǎn)上。由簇內(nèi)的啟動(dòng)節(jié)點(diǎn)啟動(dòng)程序運(yùn)行。在程序運(yùn)行過(guò)程中,啟動(dòng)節(jié)點(diǎn)通過(guò)查詢數(shù)據(jù)流分析結(jié)果XML文件,將就緒的構(gòu)件實(shí)例任務(wù)信息在簇內(nèi)的欠載節(jié)點(diǎn)間進(jìn)行傳遞,欠載節(jié)點(diǎn)根據(jù)自身的負(fù)載狀況,選擇接收部分構(gòu)件實(shí)例任務(wù),在本地調(diào)用CCAFFEINE框架生成構(gòu)件實(shí)例并執(zhí)行。這種分布式的負(fù)載均衡機(jī)制能以較小的開銷,合理地分配構(gòu)件任務(wù)到不同的計(jì)算節(jié)點(diǎn)上執(zhí)行,提高了并行構(gòu)件程序的性能,能更有效地利用系統(tǒng)的計(jì)算資源,提高了整個(gè)系統(tǒng)的吞吐率。實(shí)驗(yàn)表明,相對(duì)于已有的靜態(tài)負(fù)載均衡方法和集中式的負(fù)載均衡策略,本文提出的PCDDB方法能更充分地利用系統(tǒng)中的計(jì)算資源,從而取得更好的性能效果,同時(shí)具有較好的可擴(kuò)展性。
參考文獻(xiàn):
[1]
CCAForum. The Common Component Architecture Forum [EB/OL]. (2021) [2024-02-01]. https://cca-forum. github. io/cca-forum/overview/index. html.
[2]Imperial College London. Imperial college e-science networked infrastructure (ICENI) [EB/OL].(2024) [2024-02-01]. https://www.imperial.ac.uk/london-e-science/projects/archive/.
[3]傅天豪, 田鴻運(yùn), 金煜陽(yáng),等. 一種面向構(gòu)件化并行應(yīng)用程序的性能骨架分析方法 [J]. 計(jì)算機(jī)科學(xué), 2021, 48 (6): 1-9. (Fu Tianhao, Tian Hongyun, Jin Yuyang, et al. Performance skeleton analysis method towards component-based parallel applications [J]. Computer Science, 2021, 48 (6): 1-9.)
[4]莫?jiǎng)t堯, 楊章. 學(xué)科交叉多物理場(chǎng)耦合并行計(jì)算構(gòu)件模型 [J]. 中國(guó)科學(xué): 信息科學(xué), 2023, 53 (8): 1560-1574. (Mo Zeyao, Yang Zhang. Parallel computing component model for interdisciplinary multiphysics coupling [J]. Scientia Sinica Informationis, 2023, 53 (8): 1560-1574.)
[5]楊冬亮, 焦淼, 韓源冬. 基于低代碼思想的可視化并行計(jì)算框架設(shè)計(jì) [J]. 信息技術(shù)與信息化, 2023 (12): 21-24. (Yang Dongliang, Jiao Miao, Han Yuandong. Design of a visual parallel computing framework based on low code concept [J]. Information Technology and Informatization, 2023 (12): 21-24.)
[6]彭云峰, 劉家磊, 郭磊. 基于agent技術(shù)的并行構(gòu)件組裝及性能優(yōu)化方法研究 [J]. 計(jì)算機(jī)應(yīng)用研究, 2021, 38 (6): 1819-1824. (Peng Yunfeng, Liu Jialei, Guo Lei. Research of parallel component composition and performance optimization based on agent technology [J]. Application Research of Computers, 2021, 38 (6): 1819-1824.)
[7]彭云峰, 魏勝利. 擴(kuò)展OpenMP支持CCA并行構(gòu)件及其性能優(yōu)化 [J]. 小型微型計(jì)算機(jī)系統(tǒng), 2014, 35 (9): 2034-2038. (Peng Yunfeng, Wei Shengli. Extending OpenMP for optimization of CCA parallel component application [J]. Journal of Chinese Computer Systems, 2014, 35 (9): 2034-2038.)
[8]彭云峰, 張煒. 基于異構(gòu)多核的CCA并行構(gòu)件模型 [J]. 計(jì)算機(jī)應(yīng)用研究, 2014, 31 (12): 3659-3662. (Peng Yunfeng, Zhang Wei. CCA parallel component model based on heterogeneous processor [J]. Application Research of Computers, 2014, 31 (12): 3659-3662.)
[9]彭云峰, 王瑞平. 并行構(gòu)件非功能屬性研究 [J]. 計(jì)算機(jī)科學(xué), 2014, 41 (8): 213-218. (Peng Yunfeng, Wang Ruiping. Research of parallel component non-functional attributes [J]. Computer Science, 2014, 41 (8): 213-218.)
[10]CASA Team. Concerto: parallel adaptive components [EB/OL]. (2024) [2024-02-01]. http://www-casa.irisa.fr/concerto/.
[11]Osama M, Porumbescu S D, Owens J D. A programming model for GPU load balancing [C]// Proc of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. New York:ACM Press, 2023: 79-91.
[12]王家柱, 范中磊, 畢強(qiáng),等. 對(duì)象存儲(chǔ)系統(tǒng)中基于監(jiān)控的動(dòng)態(tài)負(fù)載均衡方法 [J]. 微電子學(xué)與計(jì)算機(jī), 2022, 39 (12): 69-76. (Wang Jiazhu, Fan Zhonglei, Bi Qiang, et al. Monitoring-based dynamic load balancing approach in object-based storage system [J]. Microelectronics amp; Computer, 2022, 39 (12): 69-76.)
[13]Beraldi R, Canali C, Lancellotti R, et al. A random walk based load balancing algorithm for Fog Computing [C]// Proc of the 5th International Conference on Fog and Mobile edge computing.Piscataway,NJ: IEEE Press, 2020: 46-53.
[14]王春波. 基于機(jī)器學(xué)習(xí)的動(dòng)態(tài)負(fù)載均衡模型研究 [J]. 黑龍江工程學(xué)院學(xué)報(bào), 2022, 36 (5): 22-26, 57. (Wang Chunbo. Research on dynamic load balancing model based on machine learning [J]. Journal of Heilongjiang Institute of Technology, 2022, 36 (5): 22-26, 57.)
[15]張璐璐, 張帆. 可穿戴電子設(shè)備通信終端自適應(yīng)負(fù)載均衡系統(tǒng)設(shè)計(jì) [J]. 電子設(shè)計(jì)工程, 2023, 31 (5): 163-167. (Zhang Lulu, Zhang Fan. Design of adaptive load balancing system for wearable electronic device communication terminal [J]. Electronic Design Engineering, 2023, 31 (5): 163-167.)
[16]楊乾龍, 江凌云. 基于機(jī)器學(xué)習(xí)的微服務(wù)負(fù)載均衡算法研究 [J]. 計(jì)算機(jī)科學(xué), 2023, 50 (5): 313-321. (Yang Qianlong, Jiang Lingyun. Study on load balancing algorithm of microservices based on machine learning [J]. Computer Science, 2023, 50 (5): 313-321.)
[17]Unitn. Grid computing-firb project [EB/OL]. (2024) [2024-02-01]. http://ardent.unitn.it/grid/.
[18]Sandia National Laboratories. Sandia software portal [EB/OL]. (2024) [2024-02-01]. https://sandialabs.github.io/.
[19]LLNL. Babel homepage [EB/OL] (2024) [2024-02-01]. https://software. llnl. gov/Babel/#page=home.
[20]Free Software Foundation.Libtool-GNU project [EB/OL]. (2024) [2024-02-01]. https://www.gnu.org/software/libtool/.
[21]MPI Forum. MPICH overview [EB/OL] (2024) [2024-2-1]. (2024) [2024-02-01]. https://www.mpich.org/about/overview/.
[22]UCAR. MM5community model home [EB/OL]. (2024) [2024-02-01]. https://a.atmos.washington. edu/~ovens/newwebpage/mm5-home.html.
