基于知識圖譜和數據增強的網絡安全信息采集與分析
2024-12-31 00:00:00葉麗珠代麗娜鄭冬花修位蓉
電腦知識與技術 2024年33期

關鍵詞:知識圖譜;網絡安全信息;數據增強;采集與分析
0 引言
隨著互聯網信息技術的迅速發展,人們獲取信息的方式逐漸從書本走向智能化,但隨之而來的網絡安全問題也日益頻繁。因此,對更高層次的網絡安全數據進行采集與分析具有重要的實踐和理論價值[1]。知識圖譜技術是一種通過圖結構對客觀世界的實體、實體關系和屬性進行描述的語義網絡,已被廣泛應用于醫療、能源和金融等數據采集領域[2]。例如,吳小剛等人[3]基于知識圖譜設計了一種新的電網智能調度輔助決策系統,對電網智能調度的時間與頻率進行了優化。實驗結果表明,該系統能夠在較短時間內實現電網的智能調度,提高了電網的調度頻率。韓一搏等人[4]為了提升煤礦綜采設備的實體識別精度,提出了一種基于聯合編碼的煤礦綜采設備知識圖譜構建方法。實驗結果顯示,該方法對綜采設備實體的識別準確率較現有方法提高了1.26%以上。周冰原等人[5]通過知識圖譜技術對針灸治療失語癥領域進行了可視化 分 析 ,并 采 用 CiteSpace 6.1. R 2 及 VOSviewer V1.6.16軟件對中國知網、萬方數據知識服務平臺和維普期刊全文數據庫中的相關文獻進行了數據整理。實驗結果表明,知識圖譜網絡可視化分析得出的頻次排名前五位的失語癥類型為運動性失語、癔癥性失語、經皮質運動性失語、命名性失語和感覺性失語。然而,目前尚未將知識圖譜技術應用于網絡安全領域的研究。鑒于此,本文針對網絡安全的實體抽取與關系分類,引入了基于深度學習的知識圖譜補全技術與數據增強方法,并利用預訓練模型對數據增強方法進行了改進,提出了一種新型的基于知識圖譜和數據增強的網絡安全信息采集與分析的方法。
1 知識圖譜技術的構建
在網絡安全信息的采集過程中,通常會遇到多樣化的阻礙,而知識圖譜能夠利用大數據對異常信息進行追蹤溯源,從而應對復雜多變的網絡攻擊,針對性地減緩攻擊,幫助管理者實時感知網絡安全態勢。同時,知識圖譜技術通常需要多個環環相扣的流程與步驟來共同構建,主要包括知識抽取、知識融合和知識加工等三個步驟[6]。知識抽取負責網絡數據的實體抽取、關系抽取與屬性抽取;知識融合負責網絡數據的實體消歧與實體對齊;知識加工則負責網絡數據的圖譜構建、知識更新與質量評估。通過對網絡結構化數據的深度處理,知識圖譜技術能夠形成結構化的知識體系和高質量的知識集合,從而實現知識的統一管理,契合網絡安全信息抽取的需求。網絡安全信息的實體抽取模塊結構圖如圖1所示。
由圖1可知,該網絡安全信息實體抽取模塊主要包含變壓器雙向編碼器詞嵌入層、雙向長短期記憶網絡特征提取層、注意力機制層和條件隨機場層這4個部分。首先,將網絡安全信息輸入至變壓器雙向編碼器詞嵌入層中,經過數據預處理,將網絡安全信息處理為含有目標特征的向量信息。其次,將該向量信息數據輸入至雙向長短期記憶網絡特征提取層中,以捕捉所需的目標特征信息。最后,通過注意力機制層與條件隨機場層,輸出實體標簽。然而,知識圖譜的不完整性限制了其進一步開發和應用,知識圖譜補全技術是一種可以預測知識圖譜中缺失的實體和關系,以保證知識圖譜完整性的優秀技術[7]。傳統的知識圖譜補全方法主要分為三類:基于翻譯距離的方法、基于張量分解的方法和基于深度學習的方法[8]。考慮到網絡安全信息數據的復雜性,以及為了提高實體抽取的分類性能,研究在網絡安全信息的實體抽取模塊中引入了基于深度學習的知識圖譜補全技術。
2 基于知識圖譜和數據增強的網絡安全信息采集與分析的方法
網絡安全數據樣本的標記需要利用專家的專業知識進行,這不僅復雜且耗時巨大[9]。數據增強方法是一種擴充訓練數據的方法,通過對訓練集進行變換來增加訓練集的數量,能夠有效提高模型的泛化能力[10]。因此,為了更加簡便地對網絡安全數據進行標記,研究還引入了數據增強方法來補充訓練數據,并通過對訓練集知識的實體替換來擴充訓練集的數量。實體字典的數學表達式如式(1) 所示。
式(1) 中,Z 代表實體字典,Counter 代表算法,X 與L 分別代表訓練集與實體類型。增強句子數學表達式如式(2) 所示。
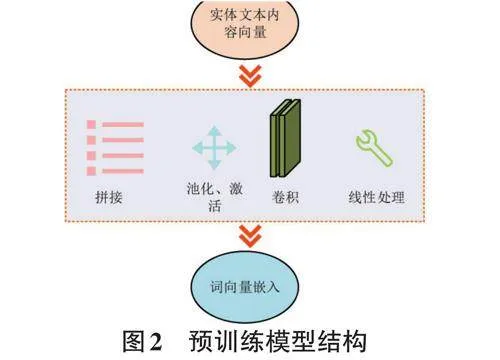
式(2) 中,J 代表增強句子,Augmentation 代表算法,其余代數含義與式(1) 一致。為了獲得更具表達能力的實體內容特征,研究還引入了預訓練模型對數據增強方法進行改進,提出了一種基于預訓練的編碼器數據增強方法。預訓練模型的結構如圖2所示。
由圖2可知,在研究所提出的預訓練模型中,以卷積神經網絡(Convolutional Neural Networks, CNN) 作為核心網絡。首先,通過word2vec獲得實體內容的詞向量。其次,將獲得的詞向量作為原始數據輸入至模型中,經過拼接、池化、激活、卷積與線性處理操作,最終輸出可用的嵌入表示。線性處理的表達式如式(3) 所示。
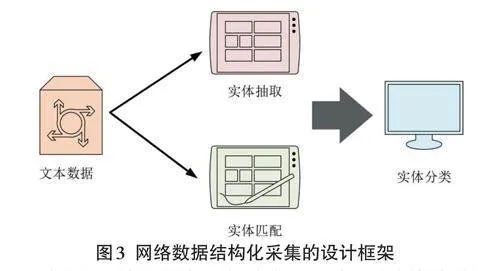
式(3) 中,wemb 代表詞向量嵌入,a 與b 代表權重。最終,研究將知識圖譜補全技術與改進后的數據增強方法相結合,提出了一種新型的基于知識圖譜增強的網絡數據結構化采集與知識融合方法。研究所提方法的結構設計圖如圖3所示。
由圖3可知,研究所提出的基于知識圖譜增強的網絡數據結構化采集與知識融合方法主要由三個部分組成:網絡安全信息實體抽取模塊、網絡安全信息實體分類模塊和網絡安全信息實體匹配模塊。首先,將網絡安全數據輸入至實體抽取模塊,以進行目標數據的采集。其次,將采集的數據輸入至實體匹配模塊,利用正則表達式對采集到的數據進行匹配。最后,對匹配的數據進行實體分類,從而成功實現網絡數據的采集與分析。
3 網絡安全信息采集與分析方法的性能測試
3.1 實體抽取性能測試
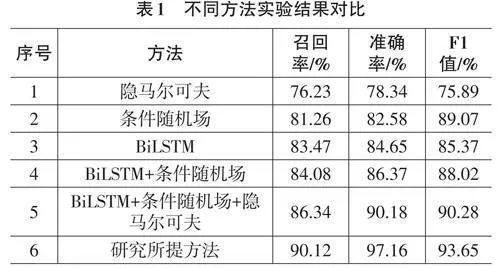
實體抽取是構建網絡安全信息采集與分析方法的關鍵環節。因此,研究選取了CyberMonitor開源倉庫和Trendmicro安全公司的網絡安全數據作為測試環境。通過數據預處理與文章分句處理后,利用In? ception工具進行網絡數據的實體標注和句子篩選。按照6∶2∶2的比例將句子數量劃分為訓練集、驗證集和測試集。操作系統版本選擇Ubuntu 7.5.0,GPU選擇GeForce GTX 1080 Ti,使用Pytorch框架進行設計實現。不同方法的實體抽取性能對比結果如表1所示。
由表1可知,研究所提出的新型基于知識圖譜增強的網絡數據結構化采集與知識融合方法的召回率、準確率與F1值分別為90.12%、97.16%和93.65%,均高于隱馬爾可夫、條件隨機場、BiLSTM、BiLSTM+條件隨機場以及BiLSTM+條件隨機場+隱馬爾可夫方法。與隱馬爾可夫方法相比,研究所提方法的召回率、準確率與F1值分別提升了13.89%、18.82%和17.76%。上述數據表明,研究方法在網絡安全數據實體抽取方面表現出色。
3.2 實體關系分類性能測試
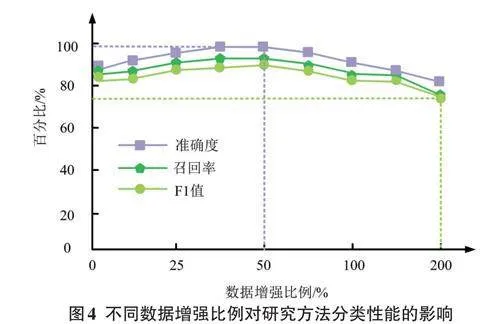
實體關系是實體之間聯系的橋梁,對研究提出的網絡數據結構化采集與知識融合方法進行實體關系分類性能的測試,能夠驗證網絡安全情報知識圖譜關系分類的有效性。因此,研究針對不同的數據增強比例,對網絡數據結構化采集與知識融合方法進行了分類性能測試。測試結果如圖4所示。
由圖4可知,在數據增強比例從0%提升至50% 的過程中,研究所提方法的實體關系分類的F1值、準確率與召回率均在緩慢提升。當數據增強比例達到50%時,本研kyxPjBdluD7tj+A1iBy6RTeuFLT+AfbWUrh7LcrzYuk=究方法的分類效果達到最優,其F1值、準確率與召回率分別為88.37%、99.27% 和90.58%。與沒有數據增強的方法相比,本研究方法的F1值、準確率與召回率分別提升了6.07%、9.26%和1.46%。上述數據表明,研究提出的基于知識圖譜增強的網絡數據結構化采集與知識融合方法在分類方面具有高效性。
3.3 多指標性能測試
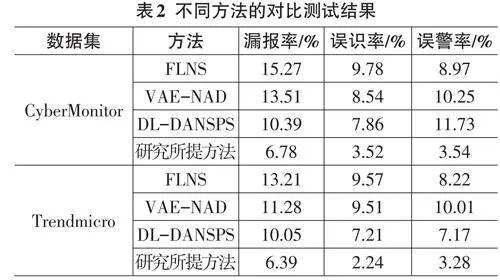
研究最后以漏報率、誤識率和誤警率為指標,對常用的網絡安全信息采集與分析方法進行多指標測試。這些方法包括結合聯邦學習驅動的網絡安全方法(Federated Learning for Network Security, FLNS) 、變分自編碼器網絡異常檢測方法(Variational Autoen? coder for Network Anomaly Detection, VAE-NAD) 和結合深度學習的動態適應網絡安全檢測方法(Deep LPeolaircnyi nSgy-stbeamse, dD LD-yDnAaNmSicP SA) 。da測pti試ve 結N果et如wo表rk 2S所ec示ur。
由表2可知,在三類指標的檢測中,FLNS感知檢測方法的性能表現欠佳,其次為VAE-NAD方法、DLDANSPSDLDANSPS以及研究提出的基于知識圖譜增強的網絡數據結構化采集與知識融合方法。其中,FLNS感知檢測方法的漏報率最低為13.21%,誤識率最低為9.57%,誤警率最低為8.22%。而本研究提出的新型基于知識圖譜增強的網絡數據結構化采集與知識融合方法,漏報率最低為6.39%,誤識率最低為2.24%,誤警率最低為3.28%。由此可知,研究所提的基于知識圖譜和數據增強的網絡安全信息采集與分析方法具有相對較優的實用性能,更適合于目前階段的網絡安全感知工作。
4 結論
針對現階段網絡安全信息分析存在的困難與挑戰,本研究引入了知識圖譜技術,并將其與數據增強方法相結合,提出了一種新型的基于知識圖譜和數據增強的網絡安全信息采集與分析方法。不同方法的實體抽取性能測試結果表明,研究所提方法的召回率、準確率與F1值分別為90.12%、97.16%和93.65%,均高于隱馬爾可夫、條件隨機場、BiLSTM、BiLSTM+條件隨機場以及BiLSTM+條件隨機場+隱馬爾可夫方法。不同數據增強比例實體關系分類性能的測試結果表明,當數據增強比例達到50%時,本研究方法的分類效果達到最優,其F1值、準確率與召回率分別為88.37%、99.27%和90.58%。與沒有數據增強的方法相比,研究方法的F1值、準確率與召回率分別提升了6.07%、9.26%和1.46%。上述實驗數據充分證明了本研究方法在網絡安全領域中良好的分類能力,為后續網絡安全數據的采集與分析提供了一些新的研究方向。然而,研究探討的數據主要來源于CyberMonitor 開源倉庫和Trendmicro安全公司,并不全面,后續可以采集更為全面的數據進行探究,以確保研究的精準性與大范圍適用性。
