基于大數據分析的油源對比初試
2024-12-31 00:00:00沈東義
電腦知識與技術 2024年33期
關鍵詞:大數據分析;油源對比;生物標志化合物;石臼坨凸起;機器學習
0 引言
油源對比是油氣運移示蹤及成藏過程研究的重要基礎,對于多源供烴構造,油氣來源的厘定,還是準確計算油氣資源量的前提[1-3]。目前油源對比主要通過對比原油與烴源巖抽提物中生物標志化合物參數的相似性來實現,常用生物標志化合物參數甾萜烷、類異戊二烯烷烴、芳烴等參數等,如C27-C28-C29甾烷相對含量、姥鮫烷(Pr) 和植烷(Ph) 比值、伽馬蠟烷/C30藿烷。除生標參數之外,原油與烴源巖抽提物的族組分或單體烴同位素組成,油源中微量元素組成,以及孢粉化石等,也常用于油源對比工作[1,4-5]。由此可見,可用于油源對比的參數種類繁多,比值類參數更是可隨意組合而成。但是,由于傳統的油源對比工作是通過人工分析來完成,只能選擇有效的參數進行分析。受地化參數多解性的影響,僅有個別參數進行人工對比,難以得到可靠的結論,特別是多源供烴的地區,不同的研究者選用不同的參數,可能會得到不同結論[6]。
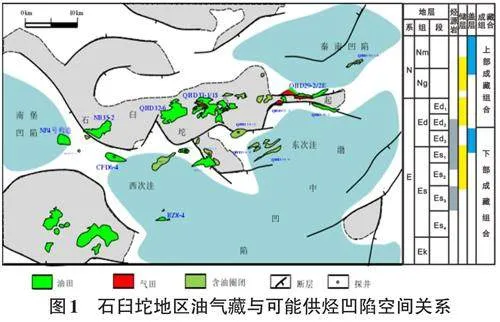
基于大數據分析的機器學習,是一種基于對數據進行表征學習的方法,它使用多層網絡,能夠學習抽象概念,同時融入自我學習,逐步抽象出相關概念,從而形成理解,并最終做出判斷與決策[7-9]。通過構建具有一定“深度”的模型,可以讓模型來自動學習好的特征表示(從底層特征,到中層特征,再到高層特征),從而最終提升預測或識別的準確性[10-11]。由此可見,機器深度學習可以解決目前油源對比中存在的參數應用不全、參數適用性難以把握等問題。對于已經獲得一定數量分析樣本的含油氣盆地,可以通過機器深度學習的技術,完成油源來源的精確分析。渤海灣盆地石臼坨凸起被秦南、渤中、南堡3個生烴凹陷圍繞,具有多源供烴的地質條件[12-14]。近40年的油氣勘探和研究工作,積累了豐富的原油和烴源巖分析資料,是基于數據分析開展油源對比的理想地區。如圖1所示為石臼坨地區油氣藏與可能供烴凹陷空間關系。
1 研究思路和方法
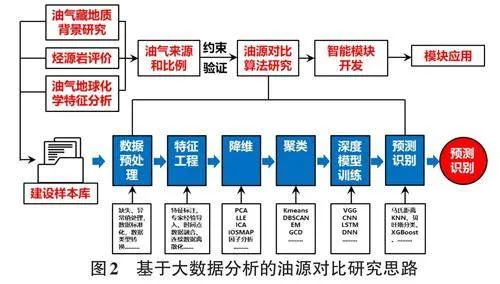
為了實現基于大數據學習的油源對比,首先需要基于成藏背景分析,綜合各類地化和成藏信息,給出已發現油氣和潛在烴源巖的親源關系,為模型訓練提供樣本。在此基礎上,構建可供訓練的樣本集,并在親源關系的約束下進行算法訓練與建模。具體包括:數據庫建立與數據預處理、特征工程、降維、聚類、深度模型訓練等。同時進行智能模塊研發和應用,形成油源對比軟件和工具,實現油源對比的標準化和智能化,提高油源對比的工作效率和準確性。具體的思路如圖2。
2 已發現油氣來源分析
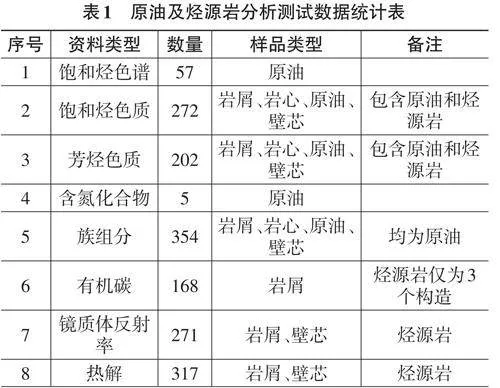
石臼坨凸起位于渤海灣盆地海域中西部,為一長期發育的古隆起,是周邊秦南、渤中、南堡等生烴凹陷油氣的長期運移指向區[15-16]。秦南、渤中、南堡3個生烴凹陷均發育沙三、沙一、東營組3套烴源巖,因此石臼坨地區存在9個潛在供烴源巖[17-19]。原油和烴源巖抽提物中的生物標志化合物,是來源于生物體的特征化合物,在地質演化過程中保留生物信息(碳骨架)的化合物,它們在原油中的含量或相對比值能夠指示母質來源、生成環境及成熟階段等信息,是進行油源對比的基礎,也是本次進行大數據分析的特征向量。本次研究共收集整理了1646組原油及烴源巖分析測試數據,其中烴源巖生物標志化合物測試數據(包括飽和烴甾萜烷、芳烴兩大類)110組,原油(包括原油和油砂抽提物)生物標志化合物測試數據162組,其他為有族組分、有機碳、熱解等(表1) 。其中用于油源對比分析的資料主要是272組生物標志化合物分析數據,有族組分、有機碳、熱解等數據主要用來判別烴源巖的有效性。
利用上述數據,在烴源巖有效性分析的基礎上,采用地質-地球化學綜合分析的方法,厘定了已發現油氣的來源及烴源巖貢獻比例。具體工作流程如下:1) 構造位置確定供烴凹陷,即根據已發現油氣的構造位置,確定可能的供烴凹陷。按照這一思路,洼陷與斜坡帶的油氣,均為單凹供烴,而凸起高點的油氣可能為兩凹或三凹供烴。2) 儲集層位判斷供烴層段,即根據油氣儲集的層段,確定潛在的供烴層段,其中沙河街組油氣為單一烴源巖供烴,而東營組及以上層段儲集的油氣,可能為多層段烴源巖供烴。3) 油源關系助對比:即下部或直接對接的烴源巖供烴有效,沙三段充注能力最強。
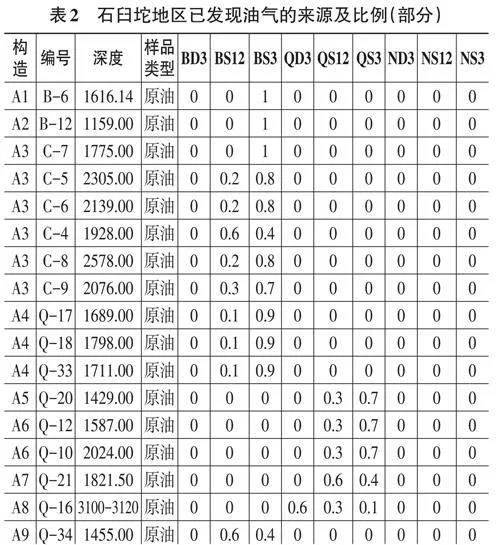
在上述地質分析的基礎上,結合地化參數,完成了石臼坨凸起162個原油/油砂樣品的來源和油源比例,對比結果(部分)如表2。
以本次厘定親源關系的烴源巖、原油(含油砂抽提物,下同)樣品為研究對象,通過數據集的構建與特征分析,完成了地球化學特征參數的降維。在此基礎上,利用分類和回歸分析算法,構建了多個油源對比模型,并進行了優選與應用。
3 數據集的構建與特征參數預處理
烴源巖抽提物和原油中含有多種生物標志化合物,利用它們的含量與比值,可以提取出多個油源對比參數,這些參數構成了烴源巖和原油的特征值,即樣品的特征向量。基于大數據分析的油源對比,需要烴源巖和原油樣品具有相同的特征參數(向量)。但是,由于分析儀器或樣品本身差異,常常導致某一化合物及與其相關參數的缺失,使得樣品之間的特征參數不一致。因此,首先需要建立數據集并對數據進行預處理。
3.1 數據集的構建
本次研究共提取了161個烴源巖抽提物和原油的特征向量,其中飽和烴化合物58個,包括正構烷烴、異戊二烯類烷烴、甾萜烷烴;飽和烴比值58個,包括Pr/Ph、Ts/Tm、伽馬蠟烷/C31升藿烷等。芳香烴化合物38 個,包括苯、菲、萘、芴及其系列化合物;芳香烴比值參數7個,包括MNR、ENR、MP1等。272個烴源巖抽提物與原油中生物標志化合物相對含量,均來源于渤海某油田的飽和烴和芳烴的色譜、色質分析資料,化合物比值由筆者計算獲得,涵蓋了目前常用的母質來源、生成環境、成熟階段等油源對比參數。
為了方便數據檢索、分類計算等,在數據集建立時,還保留了樣品的井號、所屬構造、采樣層段、樣品類型等信息。
3.2 數據預處理和特征工程
在基于大數據分析的機器學習中,數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限。油源對比所用數據,來自烴源巖抽提物和原油樣品的測試分析,在模型訓練前需要對測試結果進行分析,并優選/構建特征向量,即進行數據預處理和降維,以便最大限度地從原始數據中提取特征以供算法和模型使用。針對樣品分析數據的特點,本次數據預處理工作,是對數據進行審核,去除異常值,剔除未檢測到的化合物,以及與之有關的參數,并對各參數進行標準化處理。除此之外,還開發了特征向量關聯性分析工具,以實現對樣本庫缺失數據進行智能算法填充。
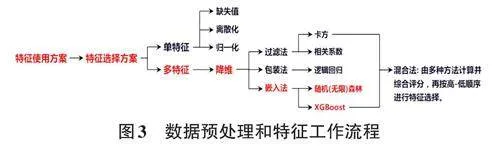
從色譜、質譜分析資料獲得的161個參數,對油源來源的指示作用不同。為了從中提取最具來源特征的參數,以供后續算法和模型的使用,需要開展特征工程。在本次研究中,筆者開發了一種混合了過濾法、嵌入法和包裝法的特征選擇算法,該混合法由6個具體算法組成,先由6個算法分別計算特征重要性,然后綜合評分,再從高分到低分順序進行特征選擇,如圖3所示。
4 數據集的構建與特征參數預處理
4.1 烴源巖智能聚類
油源對比通過比較已發現油氣與潛在烴源巖的相似性以確定油氣來源。為了準確厘定一個研究區已發現原油的來源,首先需要明確該地區各潛在烴源巖的特征,即給出烴源巖標簽。烴源巖抽提物是原地滯留的原油,可以用來表征烴源巖特征。本次研究采用智能聚類算法處理了110個烴源巖抽提物樣品的特征參數,自動給出烴源巖標簽。算法模型公式如下所示:
其中:xi、si 為第i 個參數(特征),wi、ai 為第i 個特征的權重。
函數f (w ) i xi 為不同烴源巖之間的離散程度,該值越大越能表征油源特征。
函數g (a ) i si 為同一烴源巖不同樣品之間的離散程度,該值越小越能表征油源特征。
4.2 算法與模型訓練
利用經過預處理及降維后的數據,采用分類和回歸的大數據分析算法,完成了油源對比算法研究,在KNN、SVM、MLP(神經網絡)等眾多分類和回歸算法的實驗基礎上,優選出了隨機森林分類、XGBoost分類,以及隨機森林回歸、XGBoost回歸等算法。
在模型構建過程中,筆者根據烴源巖抽提物和原油地化參數的示源意義與樣本數據的缺失情況,優選生物標志化合物等進行模型訓練與評估,并在模型訓練中加入了網格搜索法進行模型與參數的優化。在模型的訓練和優化過程中,可進一步得到該優化模型的特征選擇結果,以便地質人員對模型預測結果進行解釋。
本次研究中,優選出兩類模型,即隨機(無限)森林模型和XGBoost模型。從模型的訓練結果看,隨機(無限)森林模型平均絕對誤差 (MAE)為0.105,Test_MAE為 0.0274,(訓練)準確率為 97.26%,(實際)準確率為 72.23%。XGBoost 模型MAE 為 0.1067,Test_MAE為 0.000237283,(訓練)準確率為 99.98%,(實際)準確率 69.87%。
4.3 深度模型的應用
為驗證模型的實際應用效果,利用隨機森林、XG?Boost等分類和回歸算法模型,對未參與訓練的5個原油樣品進行了來源分析(樣品來自CFD11-3E-3d 井)。油源分析結果表明,這5個油源均源自渤中凹陷,其中以沙三段烴源巖供給為主,貢獻比為60.0%-79.7%;次為沙一段烴源巖供給,貢獻比為13.3%~23.3%;東三段烴源巖的貢獻小于10%。該結果與地質-地球化學分析結果相一致。
5 結束語
大數據分析油源對比,有效改善了傳統依賴人工經驗分析的工作模式,大大地減少了人工收集資料和綜合預測的成本。通過模塊研發和應用,將減少80% 科研數據收集時間,油源對比預測的效率預計提高近60%。需要指出的是,由于樣品數量和分析成本的限制,能夠獲得并用于機器的數據有限。另外,每一個樣品均含有多個特征向量,且受多種地質因素的影響,使得它們在示源中的作用發生改變,從而增加了機器學習的難度。因此,在下一階段研究中可以考慮如何提升樣本的質量,樣本的質量決定了算法的評估效果。另外,可以將如何提升算法的準確性作為下一步研究的重點。
