基于數據增強和擴張卷積的ICD編碼分類
2024-12-31 00:00:00閆婧趙迪孟佳娜林鴻飛
計算機應用研究 2024年11期
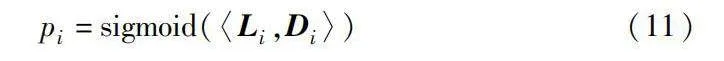

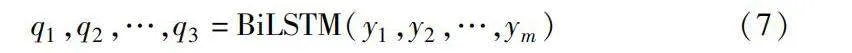
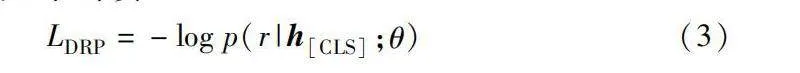


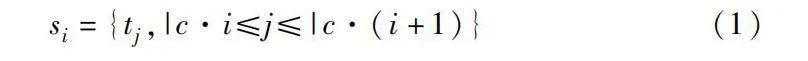
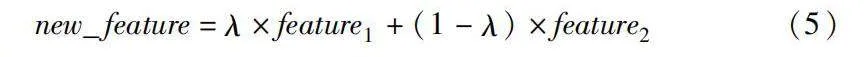


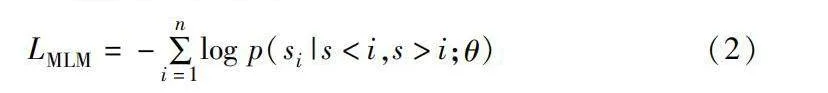


摘 要:針對ICD編碼分類任務存在的標簽分布不平衡、臨床記錄文本過長和標簽空間龐大等問題,提出一種基于數據增強和擴張卷積的ICD編碼分類方法。首先,引入預訓練模型BioLinkBERT,在生物醫學領域采用無監督學習方式進行訓練,以緩解域不匹配問題;其次,運用Mixup數據增強技術擴充隱藏表示,從而增加數據多樣性及提升模型分類的魯棒性,解決標簽分布不平衡問題;最后,利用多粒度擴張卷積有效捕獲文本數據中的長距離依賴關系,避免因輸入文本過長影響模型效果。實驗結果表明,該模型在MIMIC-Ⅲ數據集的兩個子集上與多種方法進行比較,相較于基準模型的F1值和precision@k值分別提升0.4%~1.5%和1.2%~1.6%。因此,本研究為解決ICD編碼分類中的挑戰提供有效的解決方案。
關鍵詞:ICD編碼分類;BioLinkBERT預訓練模型;Mixup數據增強;擴張卷積
中圖分類號:TP391.1 文獻標志碼:A 文章編號:1001-3695(2024)11-018-3329-08
doi:10.19734/j.issn.1001-3695.2024.03.0088
ICD coding classification based on data augmentation and dilated convolution
Yan Jing1, Zhao Di1, 2, 3?, Meng Jiana1, Lin Hongfei2
(1.School of Computer Science amp; Engineering, Dalian Minzu University, Dalian Liaoning 116600, China; 2.School of Computer Science amp; Technology, Dalian University of Technology, Dalian Liaoning 116024, China; 3. Dalian Yongjia Electronic Technology Co., Dalian Liaoning 116024, China)
Abstract:To address the problems of unbalanced label distribution, excessively long medical record text and large label space in the international classification of diseases (ICD) coding classification task, this paper proposed an ICD coding classification method based on data augmentation and dilated convolution. Firstly, this method introduced the pre-trained model BioLinkBERT, trained in the biomedical domain using unsupervised learning, to alleviate the domain mismatch problem. Secondly, it applied the Mixup data augmentation technique to expand the hidden representations, thereby increasing data diversity and improving model robustness for classification, addressing the problem of imbalanced label distribution. Finally, the model effectively captured long-range dependencies in the text data using multi-granularity dilated convolution, avoiding the impact of long input text on the model’s performance. The experimental results demonstrate that the proposed model achieves notable improvements over the baseline model on two subsets of the MIMIC-Ⅲ dataset when compared with various methods. Specifically, the F1 scores and precision@k values improves 0.4% to 1.5% and 1.2% to 1.6%, respectively. Therefore, this study provides an effective solution to solve the challenges of ICD coding classification.
Key words:ICD code classification; BioLinkBERT pre-trained model; Mixup data augmentation; dilated convolution
0 引言
近年來,隨著機器學習技術的發展,人們在語音、圖像和文本處理等領域取得新突破[1,2]。在大規模文本數據處理中,文本自動分類技術發揮著關鍵作用,然而在復雜多變的文本數據環境中,該技術面臨著諸多嚴峻挑戰。傳統的單標簽文本分類方法已無法應對人們需求的多樣性和復雜性,為此亟需以多標簽文本分類方法逐步取代單標簽文本分類方法[3]。傳統的多標簽分類方法基于機器學習理論,其構建分類模型的過程涉及特征選擇和特征提取技術。然而,這種方法存在模型復雜性高、數據表達能力不足等問題。當前,深度學習作為機器學習的重要分支,憑借其強大的自動學習能力和高度靈活性,在多標簽文本分類領域取得了一系列進展[4]。
深度學習神經網絡以模擬人腦著稱,由多層人工神經網絡組成,通過自主學習和抽取抽象高級特征來處理數據。在文本分類領域,深度學習模型通過分析訓練數據來構建抽象的文本表示,然后將這些表示傳遞到分類器中,以實現文本分類。與傳統機器學習方法不同,深度學習模型具有內在的特征工程機制,無須預先設計大規模特征工程。然而,這種自動特征提取的特性使得深度學習模型采用更為復雜的結構,訓練過程需要更多的計算資源支持。近年來,學者們從不同角度探索文本特征的優化,以獲得更精準的分類結果[5]。盡管尚未確立通用解決方案,但基于深度學習的方法在構建更高效、可靠的多標簽文本分類模型方面具有重要的研究價值[6]。
為了降低人工編碼的難度,一些工作開始嘗試使用機器自動完成ICD編碼任務。早期工作通常使用有監督的機器學習方法進行ICD編碼,這種方法的效率相對較低。近年來,采用卷積神經網絡(convolutional neural network,CNN)和注意力機制結合的方式,大大提高了編碼的效率和準確度。雖然之前的方案有所成效,但ICD編碼依然存在一些挑戰:a)臨床記錄往往擁有非常長的文本,其中僅有少部分關鍵文本片段與某一特定的ICD編碼相關;b)ICD編碼的標簽空間非常龐大,在ICD-9中包含大約17 000個編碼,ICD-10中有超過40 600個編碼,龐大的標簽空間意味著標簽分布存在不平衡的問題。
綜上所述,ICD編碼分類的研究仍在不斷演進,如何獲得強大的文本表示并有效地利用標簽之間的復雜關系仍然是提升任務性能的關鍵挑戰[7]。本文的主要貢獻概括如下:
a)鑒于在自動ICD編碼任務中存在的標簽分布不平衡、臨床記錄文本過長及標簽空間龐大等問題,提出一種基于數據增強和擴張卷積的ICD自動編碼分類方法。
b)利用BioLinkBERT預訓練語言模型[8]引入無監督學習,以獲取單詞語義信息。進一步,采用Mixup數據增強技術[9]對隱藏表示進行形變,以優化增強樣本質量并減少噪聲干擾。最后,引入多粒度擴張卷積[10],旨在提高單詞之間的交互能力。
c)實驗結果表明,在公開數據集MIMIC-Ⅲ的驗證集上,該模型相較于其他ICD編碼分類方法表現出更為卓越的分類性能,具有一定的可靠性。
1 相關工作
深度學習的多標簽文本分類方法主要包括基于CNN的方法、基于循環神經網絡(recurrent neural network, RNN)的方法以及基于注意力機制的方法。
a)基于CNN的方法。2014年,Kim[11]所提文本分類網絡模型中,采用不同大小的卷積核對文本進行卷積操作,以覆蓋不同長度的詞語組合,通過卷積和池化操作有效地捕獲文本中的局部特征。該模型通過全連接層對特征進行組合和分類,從而實現對文本的精確分類。2017年,Liu等人[13]提出一種基于CNN-XML的文本分類模型,旨在解決多標簽文本分類中特征空間和標簽空間龐大導致的數據稀疏等問題。該模型采用動態最大池化技術對卷積層輸出的特征進行分塊處理,隨后對每個塊進行最大池化操作,在保持關鍵特征的同時保留其相對位置信息。為解決層級標簽數據稀疏性等問題,2018年Shimura等人[12]提出基于CNN的分層微調(hierarchical fine-tuning based CNN, HFT-CNN)模型。該模型采用層級結構,利用Fasttext學習上層標簽信息,并將這些信息傳遞到下層標簽學習過程中。在學習下層標簽信息時,采用與上層相同的結構,并通過fine-tuning方式微調上層模型的參數,以促進對下層標簽的學習。2020年,Yang等人[13]提出混合孿生卷積神經網絡模型(hybrid-siamese convolutional neural network, HSCNN),以解決多標簽文本分類中樣本標簽分布不平衡的問題。該模型通過采用混合CNN模型,對頭部和尾部分類采用不同的網絡結構,從而在一定程度上緩解標簽類別不平衡的問題。2021年,Tan等人[14]首次將動態嵌入投影門(dynamic embedding projection gated, DEPG)應用于詞嵌入矩陣,提出動態嵌入投影卷積神經網絡(dynamic embedding projection convolutional neural network, DEPCNN)。該模型旨在提升模型的精度并縮短訓練時間,通過引入DEPG技術,期望在文本處理任務中取得更為優越的性能表現。在多標簽分類領域,為解決多標簽圖像分類問題,Chen等人[15]首次引入圖卷積網絡(graph convolutional network, GCN),提出一種基于圖卷積網絡的多標簽分類模型。該模型以標簽空間為基礎構建有向圖,并將其映射到相互依賴的分類器中以提升分類性能,并更好地捕獲標簽間的相關性。另一方面,Zhang等人[16]采用顯式的標簽圖模型,結合非線性嵌入和基于圖先驗的方法,以更有效地捕捉標簽之間的相關性。鑒于CNN限制模型捕獲長距離特征的能力,為了更有效地處理長文本數據,可以改進模型結構,使其能夠更好地適應并捕捉長文本中的關鍵信息。
b)基于RNN的方法。針對文本語義相關性對分類準確率的重要影響,Hu等人[17]采用word2vec和雙向長短期記憶網絡(bi-directional long short-term memory, BiLSTM)進行模型訓練,以獲取文本數據前向和后向的語義信息及其相關性。考慮到基于LSTM的模型存在計算量大和計算復雜度高的不足,研究者們逐漸轉向關注門控循環單元(gated recurrent unit, GRU)應用,并提出基于GRU的多標簽文本分類方法,以克服LSTM模型的局限性。Xie等人[18]使用樹型序列LSTM進行ICD編碼,以處理ICD代碼的層次結構,更有效地提取文本特征。Liu等人[19]在GRU模型基礎上,提出創新的混合模型(TCN and GRU network, TGNet),結合時間序列信息以更好地適應中文和英文文本數據。相對于LSTM,GRU在參數數量上進行優化,并在性能上取得顯著改進。為提升分類效果,Yang等人[20]通過整合標簽間的相關性,采用LSTM解碼器按順序生成標簽,充分考慮標簽關聯性,獲得更優異的性能。另一方面,Lin等人[21]在傳統seq2seq模型基礎上引入多級擴展卷積,從源文本的上下文中提取有效信息,并提取文本序列的單元級和單詞級語義信息,以減少對標簽序列先驗分布的影響。此外,Xiao等人[22]對傳統seq2seq模型進行改進,擺脫對文本隱藏狀態的依賴,結合歷史信息與seq2seq模型,以獲取上下文和標簽信息,更準確地捕獲文本中的重要單詞并減少信息傳播中的錯誤。基于RNN的模型存在計算量大和計算復雜度高的問題,會導致訓練時間變長,特別是在處理大規模數據集時,所需的時間顯著增加。
c)基于注意力機制的方法。研究者普遍趨向于將深度學習模型與注意力機制相融合,以提升模型效能。Zhou等人[23]采用長短期記憶神經網絡與注意力機制相結合的策略,旨在獲取文本中最為關鍵的語義信息。為了獲取不同場景下的重要文本信息,Yang等人[24]提出一種多層次的注意力機制,并在不同的層級上采用差異化的注意策略用于文本分類。自注意力機制[25]在序列學習任務中表現出顯著的優勢。相較于傳統的RNN,該機制更有效地捕獲序列中的長期依賴關系。Transformer中的多頭注意力機制具有獨特的優勢,能夠實現序列中每個位置與其他位置的直接連接,從而學習到更為全面的全局依賴關系。一些研究者們將自注意力機制應用于文本分類,Lu等人[26]提出基于自注意力的卷積神經網絡(self-attention-based convolutional neural network, SACNN)用于句子分類,包括兩個自注意力層和一個卷積神經網絡,從而提高文本分類效率。同時,其他研究者嘗試采用不同的圖網絡模型,如圖注意網絡(graph attention network, GAT)和圖同構網絡(graph isomorphism network, GIN)等,以捕獲標簽之間的注意依賴結構。自注意力和多頭注意力機制雖然擅長處理文本內部的信息交互,但它們不足以充分捕捉標簽之間的相關性和語義聯系,特別是在對出現頻率較低的標簽進行分類時,難以獲取充分的信息,從而影響分類效果。
以上研究表明,CNN在處理文本內容時,利用卷積核對文本進行窗口計算,結構相對簡單。然而,CNN對于長距離的依賴關系建模能力相對有限,同時池化操作也會導致部分文本語義信息丟失。雖然基于RNN的多標簽文本分類方法在一定程度上能夠處理醫療文本數據,但其在長序列建模、計算效率和泛化能力等方面存在一些限制和挑戰。自注意力和多頭注意力主要關注輸入序列中的自身依賴關系,而在多標簽文本分類任務中,標簽之間的依賴關系也非常重要。基于此,本文提出基于數據增強和擴張卷積的ICD編碼分類方法:引入擴張卷積處理長文本和捕獲長距離依賴關系,還可以降低計算量;同時采用標簽注意力機制關注標簽之間的相關性,從而更適合多標簽文本分類的需求。另外,使用Mixup數據增強技術增加數據多樣性,并結合預訓練模型BioLinkBERT,進一步提升ICD編碼分類任務的性能和分類準確度。
2 研究方法
2.1 整體架構
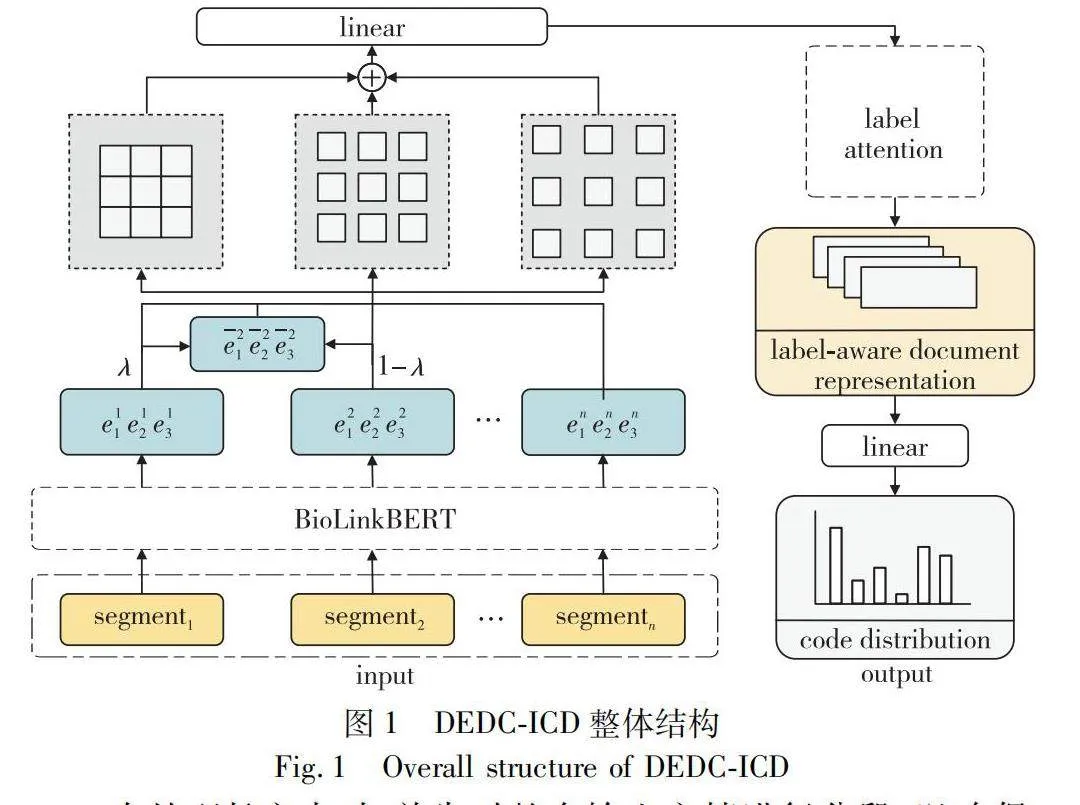
本文采用的模型結構如圖1所示,主要包括預訓練模型BioLinkBERT、Mixup數據增強模塊、多粒度擴張卷積模塊以及標簽注意力機制。
在處理長文本時,首先對整個輸入文檔進行分段,以確保每個段落長度在最大限制內。隨后,利用預訓練語言模型(pre-trained language model, PLM)對這些分段進行編碼,獲取各自的表示。在對分段文本進行編碼后,分段表示被聚合為完整文本的表示。進一步,引入Mixup技術對數據進行增強,該技術在高層隱藏表示上對輸入進行變形,以優化增強樣本質量并降低噪聲干擾,通過線性插值生成新的樣本。接著引入多粒度擴張卷積以捕獲不同距離單詞之間的交互作用,其中擴張率決定卷積核在輸入上的采樣間隔。在此基礎上采用串聯機制將所有token表示聚合,形成整體文檔的表示。隨后,采用標簽注意力機制作為增強模塊,旨在學習捕獲與特定標簽相關的關鍵文本片段。通過生成特定于標簽的表示,并對特征矩陣進行加權處理,最終輸出通過注意力加權后的特征矩陣。最后,通過線性層操作,將特定于標簽的文檔表示用于標簽的分類。
2.2 輸入
ICD編碼分類任務是一個多標簽分類問題,給定電子病歷中的臨床記錄d=(t1,t2,…,tn),目標是預測一組ICD碼yY,其中Y表示所有可能編碼的集合。通常,標簽表示為二進制向量y∈{0,1},其中每一位yi表示電子病歷中是否出現相應的標簽。
分段池化機制首先將整個文檔分割成小于最大長度的段segment為s,將其分割成c個連續的片段:
si={tj,|c·i≤j≤|c·(i+1)}(1)
2.3 預訓練模型BioLinkBERT
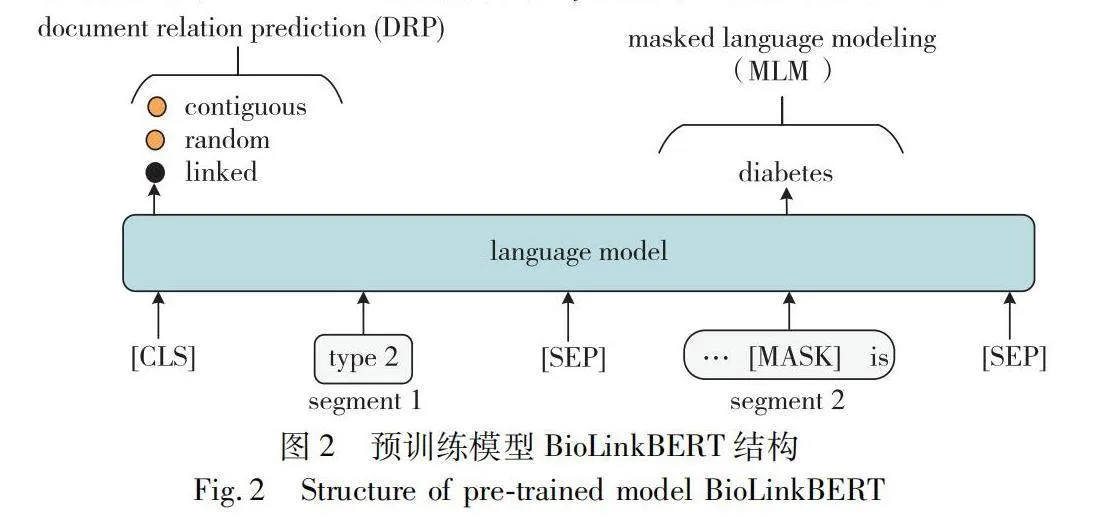
BioLinkBERT是一種在生物醫學領域基于文檔鏈接關系進行預訓練的語言模型。基于BERT模型構建,它是一種基于Transformer架構的雙向編碼器,具有強大的語言理解能力。BERT模型利用Transformer的編碼器來學習輸入序列的雙向表示,通過預訓練階段學習通用語言表示,然后可以在各種下游任務中進行微調,特別是在文本分類、命名實體識別等方面。
預訓練模型BioLinkBERT的結構如圖2所示,它基于BERT模型構建,但在預訓練階段引入額外的文檔鏈接關系預測任務,從而豐富模型的語義理解能力。在該方法中,將文本語料庫視為文檔之間的圖,并通過將鏈接的文檔放置在同一上下文中來構建語言模型(language model, LM)的輸入。其預訓練目標包括掩碼語言建模(mask language model, MLM)和文檔關系預測(document relationship prediction, DRP)兩個自監督目標。MLM目標旨在引入同一上下文的概念,鼓勵跨文檔知識的學習。DRP目標則通過對輸入中兩個文本段之間的關系(連續、隨機或鏈接)進行分類,鼓勵模型學習文檔之間的相關性。有助于模型更好地理解文檔之間的關聯性和語義關聯,為下游任務提供更豐富的語義表示。以下是BioLinkBERT預訓練中兩個主要任務的實現過程:
給定一個標記序列S=(s1,s2,…,sn),其中一部分標記YS被隨機掩蓋,任務是預測這些掩蓋的標記。MLM的損失函數通常使用交叉熵損失來計算:
LMLM=-∑ni=1log p(si|slt;i,sgt;i;θ)(2)
其中:p(si|slt;i,sgt;i;θ)是在給定模型參數θ下,當前標記si的條件概率;slt;i和sgt;i分別表示si之前和之后的上下文。
對于由兩個文檔片段SA和SB組成的輸入實例,DRP的任務是預測這兩個片段之間的關系r。DRP的損失函數可以使用分類交叉熵損失來計算:
LDRP=-log p(r|h[CLS];θ)(3)
其中:p(r|h[CLS];θ)是在給定模型參數θ下,關系r的條件概率;hCLS是[CLS]標記的向量表示,通常用于句子級別的任務。
結合這兩個任務,BioLinkBERT的總損失函數為
L=LMLM+LDRP(4)
在訓練過程中,模型的參數θ通過最小化損失函數L來調整。
將分段后的文本s作為輸入,使用預訓練模型BioLinkBERT轉換為詞嵌入表示,使用多層的雙向Transformer編碼器對輸入序列進行編碼。在編碼器的每一層,將輸入序列轉換為高維特征表示,將編碼器的最后一層輸出進行最大池化操作,得到整個序列的固定維度的表示,最終得到整個輸入序列的編碼表示。在微調階段,BioLinkBERT利用預訓練的生物醫學語言表示,在特定的生物醫學任務上進行微調,還可以凍結部分模型層,只微調部分層,以提高模型在特定任務上的性能。通過預訓練和微調,BioLinkBERT可以捕捉生物醫學領域特有的語義信息和關系,從而更好地應用于生物醫學領域的ICD編碼任務中。
2.4 Mixup數據增強
當前公開的多標簽文本分類數據集相對有限,這給實現自動化分類帶來了一定挑戰。為解決人工標注的時間成本和高資源成本等問題,本文引入Mixup數據增強方法。文本數據增強技術主要分為兩類:a)針對原始語料的方法,通過同義詞替換、隨機插入、隨機交換以及隨機刪除等方式對語料進行處理,以獲取更多與訓練語料相似的語句,從而擴充原始數據;b)針對文本表示的方法,即在語料的特征表示層面進行增強處理,例如注入隨機噪聲等。這些方法旨在提高訓練數據的多樣性和豐富性,以增強模型的泛化性能。
本文采用Mixup作為數據增強方法,重點在于對輸入樣本的高層隱藏表示進行變換,以精細控制增強樣本的質量并降低噪聲的影響。該方法的具體操作如下:a)隨機從訓練數據集中選擇兩個樣本,分別記為樣本A和B,其中樣本A是輸入樣本的特征表示,樣本B是對應的標簽序列;b)針對每個輸入序列樣本A,通過模型的隱藏表示層獲得對應的特征表示;c)對特征表示進行線性插值,生成新的特征表示。對于每個特征向量的相應位置,通過式(5)進行計算,得到插值后的特征值。
new_feature=λ×feature1+(1-λ)×feature2(5)
其中:λ為一個參數,用于控制插值的程度。
采用插值后的特征表示進行CRF解碼,以獲取新的標簽序列。這些插值后的特征表示和相應的新標簽序列被視為增強樣本,并與原始樣本一同參與模型的訓練。通過Mixup技術,充分利用輸入樣本之間的特征關聯和上下文信息,生成多樣化的訓練樣本,有效提升模型性能。
2.5 多粒度擴張卷積
擴張卷積是一種通過采用不同擴張率的多個二維卷積核,在不降低特征圖分辨率的前提下增加感受野的技術。這一操作可以幫助網絡涵蓋更廣泛的信息范圍,從而提高模型對輸入數據的理解能力。擴張卷積通過調整卷積核的擴張率來決定在輸入上的采樣間隔,較大的擴張率有助于捕獲更遠距離的單詞之間的關聯性,進而提高模型的表征能力。相比傳統的卷積操作,擴張卷積能夠在不增加網絡參數的情況下增加感受野,從而提高模型的感知范圍和上下文理解能力。
在多粒度擴張卷積的計算過程中,針對每個擴張率l∈[1,2,3],首先使用具有該擴張率l的二維卷積核對輸入進行卷積操作,得到相應的輸出Ql。然后,對每個擴張率的輸出Ql應用GELU激活函數進行非線性變換。接著,將所有擴張率的輸出Ql拼接在一起,形成最終的輸出結果Q。這種多粒度擴張卷積的方法能夠有效地捕獲不同距離單詞之間的關系,從而提升模型的性能。在具體實現中,首先利用預訓練模型BioLinkBERT獲取上下文中單詞的表示,然后構建單詞對的二維網格。通過引入多粒度的二維卷積,可以對詞對表示進行精細化處理,從而有力地捕獲近距離和遠距離單詞對之間的交互關系。具體而言,擴張卷積的計算公式如下:
Ql=σ(DConvl(C))(6)
其中:Ql∈?N×N×dc表示具有膨脹率l的膨脹卷積的輸出;σ是GELU激活函數。
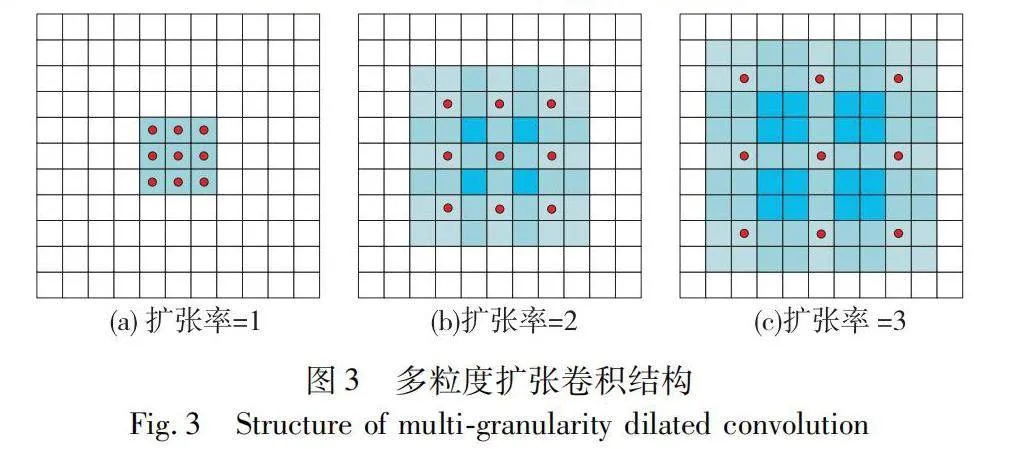
在此之后,可以獲得最終的詞對網格表示Q=[Q1,Q2,Q3]∈?N×N×3dc。多粒度擴張卷積結構如圖3所示,通過在基礎卷積核中引入間隔,實現更廣范圍的感受野,從而增強模型對輸入數據的感知能力。圖3(a)展示基礎卷積核的結構,而圖3(b)(c)分別展示擴張率為2和3的擴張卷積核的結構。具體而言,擴張率為2的卷積核具有7×7的感受野,但僅有9個參數,其他位置的參數均為零。同樣,擴張率為3的卷積核具有9×9的感受野,但也僅有有限數量的參數捕獲全局特征。
多粒度二維卷積作為關系捕捉的關鍵技術之一,利用多個擁有不同擴張率的二維卷積層來處理單詞之間的交互關系。這些卷積層的擴張率可以靈活設定,通過采用不同的擴張率,實現對不同距離范圍內單詞交互關系的捕獲。該擴張率的設置使得模型能夠有效地捕獲單詞之間的遠距離依賴關系,從而提升模型對輸入的電子病歷文本信息的理解能力和表征能力。
2.6 標簽注意力
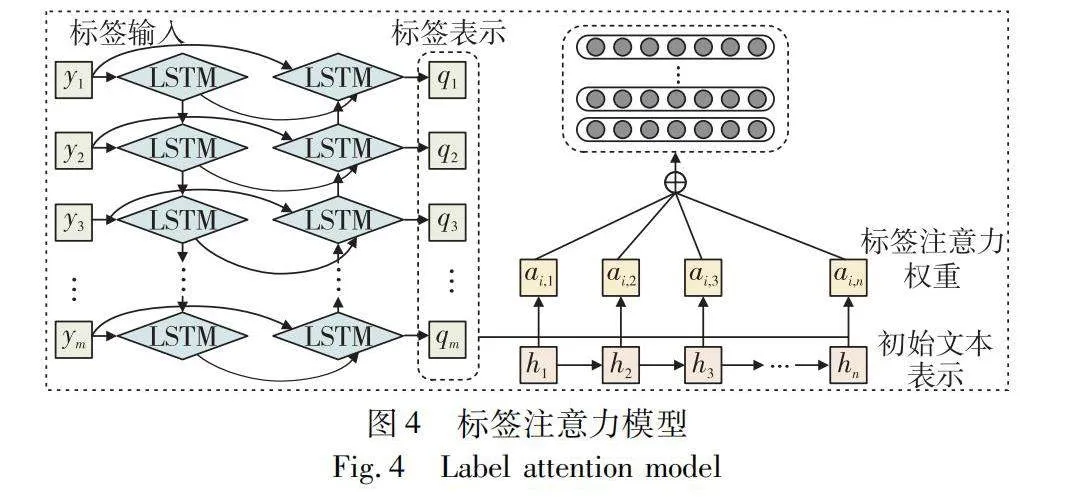
在多標簽分類任務中,一個樣本一般會對應多個標簽,每個標簽代表樣本都具有的某種特定屬性或類別。它有助于ICD編碼分類模型在預測多個標簽時更加關注相關性更高的標簽,并且在模型解釋性方面提供一定的幫助。其架構如圖4所示,模型包含嵌入層、BiLSTM、注意力層以及輸出層。
a)嵌入層是模型的輸入層,負責將臨床文本中的詞標記轉換為密集的詞嵌入向量。
b)BiLSTM層被用來捕獲輸入詞的上下文信息。采用雙向結構,它能夠同時考慮詞語的前后文信息,從而更全面地理解臨床文本的語境和含義,為后續注意力層提供更豐富的輸入信息,其實現過程如下:
q1,q2,…,q3=BiLSTM(y1,y2,…,ym)(7)
其中:y表示標簽輸入;q則為標簽表示。
c)鑒于臨床文獻長度不一且文檔包含多個標簽,注意力層將隱藏狀態矩陣轉換為表示輸入文檔的標簽特定向量。注意力層將雙向LSTM層的隱藏狀態矩陣轉換為表示輸入文檔的標簽特定向量,通過對隱藏狀態進行加權,該層能夠聚焦于與ICD編碼相關的關鍵信息,提高模型對文本中重要部分的關注程度,從而提升模型的預測性能。
d)對于每個特定于標簽的表示,將其輸入相應的單層前饋網絡(feedforward neural network,FFNN)。該網絡具有單節點輸出層,接著是一個激活函數,以生成給定標簽的文檔概率。輸出層接收來自注意力層的標簽特定向量,并將其輸入到FFNN中。FFNN具有單個節點的輸出層,緊跟著一個激活函數,通常是sigmoid或softmax函數,用于生成給定標簽的文檔概率。
為了解決大標簽集的問題,本文采用標簽注意力機制來增強預訓練語言模型,以學習捕獲與特定標簽相關的重要文本片段的標簽特定表示。一旦獲取令牌隱藏表示H,利用注意機制將H轉換為特定于標簽的表示。標簽注意力機制將H作為輸入,并計算特定于標簽的表示。該機制可以分為兩個步驟。首先,計算標簽關注權重矩陣A:
Z=tanh(VH)(8)
A=softmax(WZ)(9)
其中:V和W是線性變換;A的第i行表示第i個標簽的權重,對每個標簽執行softmax函數以在所有令牌上形成分布。
然后,使用矩陣A對H進行加權和,計算特定于標簽的文檔表示:
Di=HAT(10)
其中:Di表示第i個標簽的文檔表示。
最后,使用特定于標簽的文檔表示D來進行預測:
pi=sigmoid(〈Li,Di〉)(11)
其中:Li是第i個標簽的向量;〈〉表示兩個向量之間的內積;pi是第i個標簽的預測概率。然后,基于預定義的閾值t為文檔分配標簽。
訓練目標是最小化二進制交叉熵損失L(y,p):
-1|y|∑|y|i=1(yilog pi+(1-yi)log(1-pi))(12)
3 實驗與結果
3.1 數據集
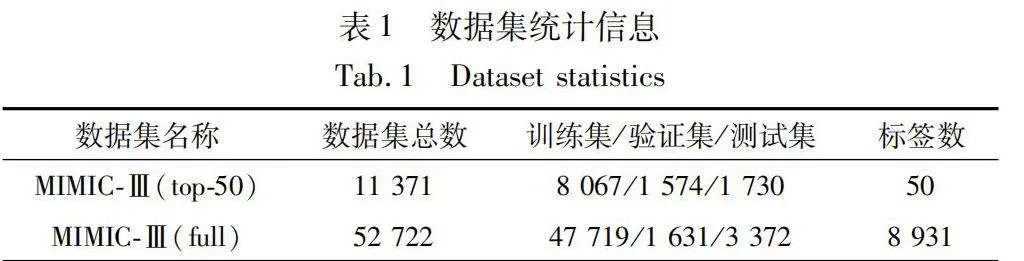
本文采用MIMIC-Ⅲ數據集,其中包括MIMIC-Ⅲ(top-50)和MIMIC-Ⅲ(full)兩個重要的子集,MIMIC-Ⅲ作為一個全面、詳細的數據集,收錄了重癥監護病房(ICU)患者的醫療記錄,包括生命體征、實驗室測試結果、藥物使用、病情發展和治療方案等,具體統計信息如表1所示。
基于MIMIC-Ⅲ數據集,能夠探索豐富的臨床數據,從中獲取有關患者診斷、治療和疾病預后的詳細信息。這樣的數據資源不僅有助于醫學研究和臨床實踐的發展,還可以為人工智能在醫療健康領域的應用提供強有力的支持和驗證。
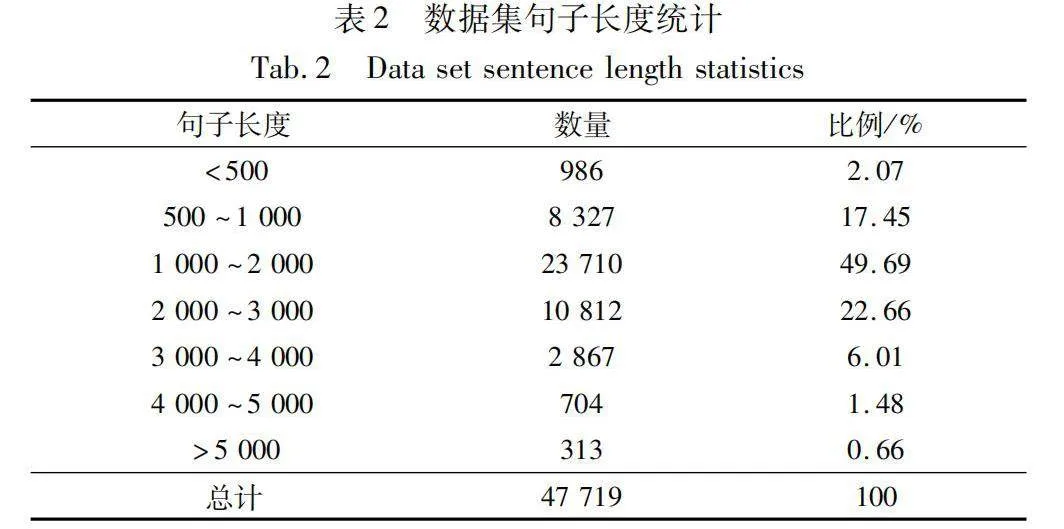
本實驗對MIMIC-Ⅲ(full)數據集中的句子長度進行詳細統計,并將其分布情況整理如表2所示。表中展示句子長度在不同區間范圍內的比例,以便對句子長度分布有一個直觀的了解。這些統計信息有助于確定適當的模型輸入序列長度,并為模型設計和調參提供參考。通過對句子長度的分析,可以更好地理解臨床文本數據的特點,從而更有效地處理和利用這些數據進行后續的任務和分析。
3.2 測試環境
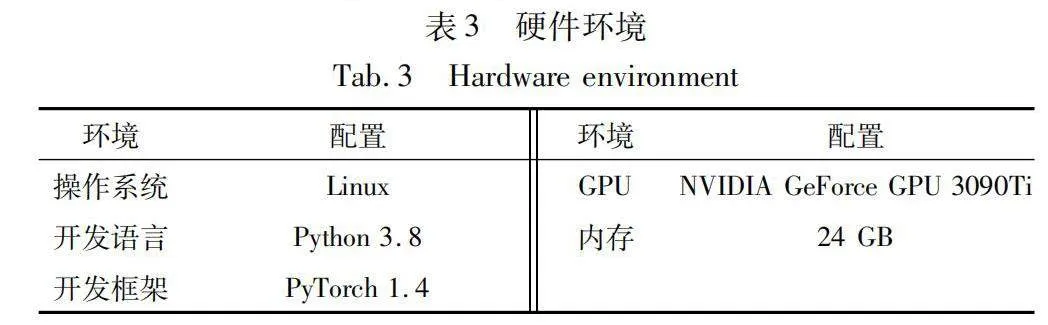
為了開展與ICD編碼分類相關的研究,本文進行廣泛的實驗,采用PyTorch框架搭建實驗模型。表3詳細描述本文所采用的硬件配置,這些硬件環境可以提供足夠的計算資源和性能支持,以有效地訓練和評估模型。
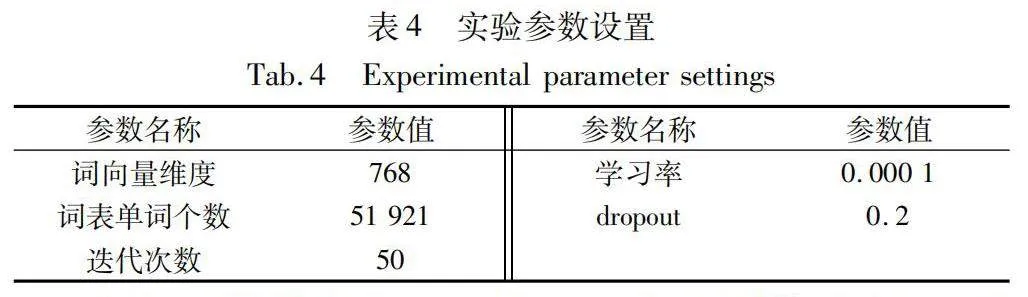
模型的具體參數如表4所示,包括各個模塊的配置參數和超參數設置。其中,詞向量維度決定詞嵌入空間的維度大小;詞表單詞個數定義詞匯表的大小;迭代次數則決定模型訓練的輪數;學習率控制模型在訓練過程中的參數更新步長;dropout作為一種正則化手段,通過隨機丟棄部分神經元來防止模型過擬合。
根據不同參數設置下的性能差異,本文設置如表中所示的參數值以確保實現最佳的模型表現。采用768維的詞向量能夠提供豐富的信息,尤其是在處理較復雜的文本分類任務時,有助于模型理解詞義和上下文。盡管提升到更高維度(例如1 024維)的詞向量能夠提供更多的信息,但這將增加內存的使用,從而限制模型處理數據的規模。詞表大小決定模型能夠識別的單詞種類。包含51 921個單詞的詞表為模型提供一個相對平衡的詞匯覆蓋范圍,既不會過大導致模型訓練困難,也不會過小而忽視一些重要的詞匯。在微調過程中,本文執行一系列不同迭代次數的對比實驗。通過將迭代次數設定在10~70次,每次增加10次迭代,發現50次迭代能夠取得最優效果。這一設置既確保模型有足夠的時間學習數據特征,又有效避免因迭代次數過多而引起的過擬合問題。此外,將學習率設置為0.000 1,這一較低的學習率有助于模型在訓練過程中實現穩定的收斂。對于本文的龐大數據集,較小的學習率是首選。從dropout比例為0.2~0.5的實驗過程中發現,當dropout比例調整為0.2時,模型的性能表現最佳。
3.3 評估指標
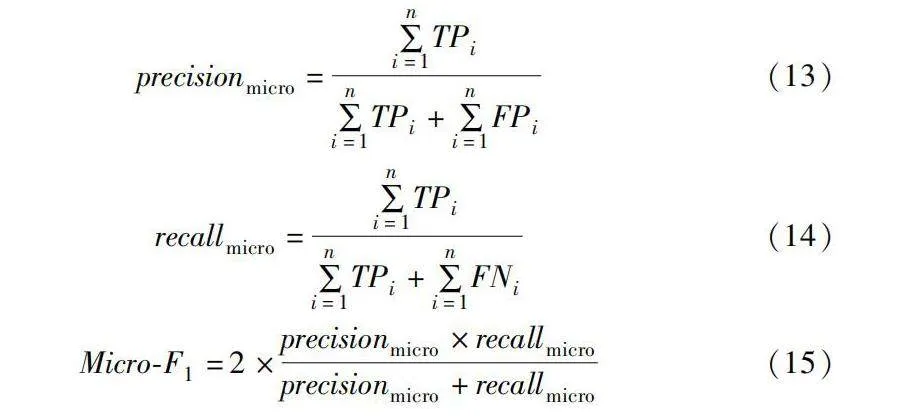
對實驗結果的評估采用微平均F1值(Micro-F1)和宏平均F1值(Macro-F1)。其中Micro-F1首先計算出所有標簽的precisionmicro和recallmicro,再通過F1計算公式進一步求得Micro-F1的值,綜合考慮所有標簽的整體召回率和精度。
precisionmicro=∑ni=1TPi∑ni=1TPi+∑ni=1FPi(13)
recallmicro=∑ni=1TPi∑ni=1TPi+∑ni=1FNi(14)
Micro-F1=2×precisionmicro×recallmicroprecisionmicro+recallmicro(15)
Macro-F1首先計算出各個標簽的平均precisionmicro和recallmicro,再通過F1計算公式求得Macro-F1的值,計算所有標簽的平均F1值。
Micro-F1考慮每個標簽在整個數據集中的出現頻率,因此更加關注頻繁出現的標簽,賦予其更高的權重。它通過對所有樣本的真實標簽和預測標簽的總體準確率、召回率進行計算得出。相比之下,Macro-F1獨立計算每個標簽的準確率和召回率,然后對它們取平均值,因此對于每個標簽都賦予相同的權重。對于大規模標簽數據集,考慮到標簽的稀疏性,本文采用每個測試樣本潛在相關標簽的簡短列表來表示分類質量。通過基于樣本的排序標準來評估模型,表示模型在第k個標簽位置的準確率。
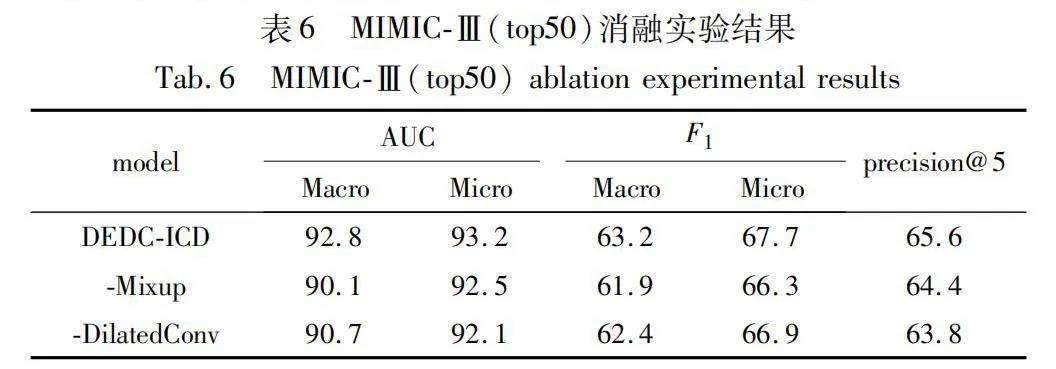
3.4 消融實驗
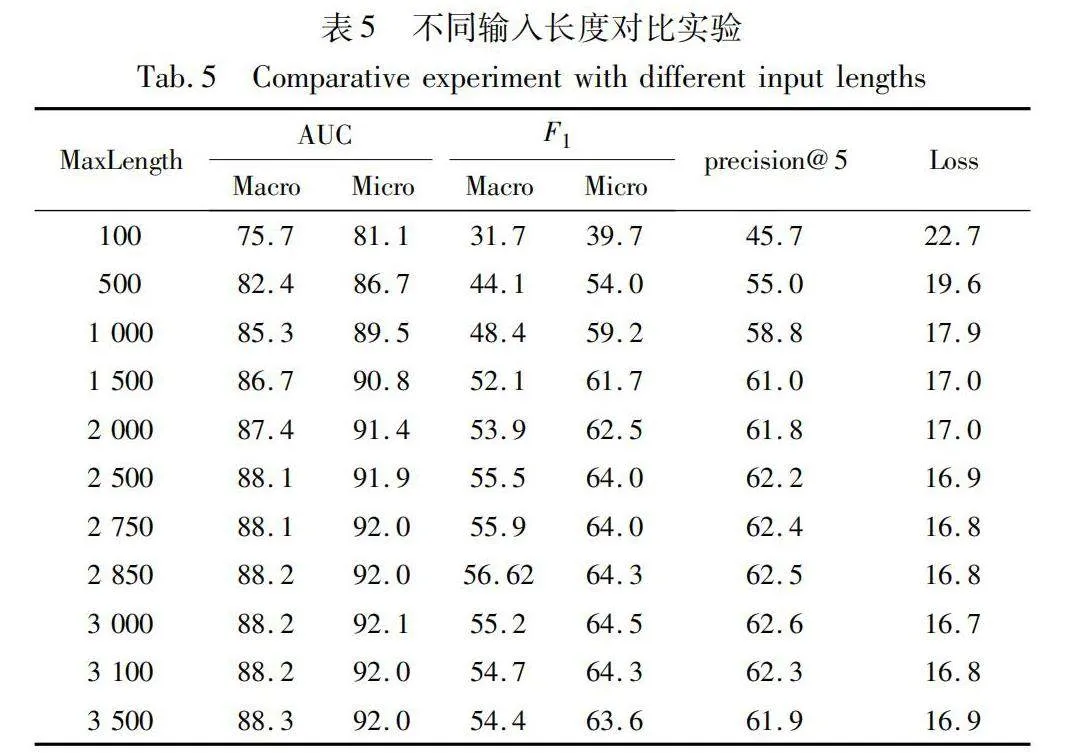
為確保整體特征矩陣的維度一致性,需要為輸入句子設定一個統一的最大長度值。若輸入句子長度過短,會導致模型對句子含義的特征提取不足,從而影響整體性能;若長度過長,不僅會增加整體模型的訓練時間,還可能影響數據集中較短句子的真實含義。為保持實驗的一致性,需要在較短句子之后進行填充操作,但這也會對模型性能造成一定影響。因此,本文進行對比實驗,分析不同輸入長度對模型性能的影響。
通過觀察表5的結果,明顯發現當MaxLength設置為3 000時,模型整體性能較MaxLength為2 500或3 500時有顯著改善。為了深入研究MaxLength在3 000附近對模型性能的影響,本文進行實驗,調整MaxLength的值。實驗結果表明,當MaxLength分別設置為2 750、2 850和3 100時,模型整體性能均不如MaxLength為3 000時。此外,在MaxLength為3 000的情況下,損失函數的值達到最低,并且多個性能指標均為最優值。因此,本文確定將MaxLength的值設置為3 000,并在這一設定下進行后續實驗。
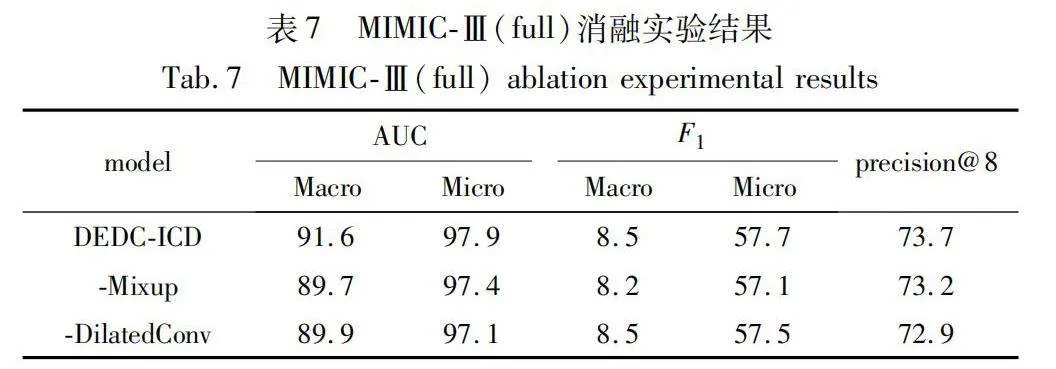
在兩個數據集上進行消融實驗,實驗結果詳見表6和7。由此看出,DEDC-ICD在MIMIC-Ⅲ上可獲得較好的實驗結果。本文做的第一個消融實驗是未使用Mixup數據增強,性能略有下降。這一結果表明,Mixup數據增強有助于提高性能。第二個消融實驗是去掉擴張卷積模塊,導致更差的性能,該結果表明,擴張卷積對于捕獲更遠距離的單詞之間的關聯性,理解上下文語義信息更有效。進一步,本文在PLM方法上融合Mixup數據增強方法和多粒度擴張卷積模塊,從實驗數據可以看出,兩種模塊融合之后效果較好,具有較強的可靠性。
3.5 對比實驗
為了全面評估本文模型的性能,將其與先前研究中的多個基線模型進行比較。所選用的評價指標涵蓋宏觀AUC值、微觀AUC值、宏觀F1值、微觀F1值、precision@5以及precision@8,這些指標能夠綜合反映模型在分類任務上的性能表現。
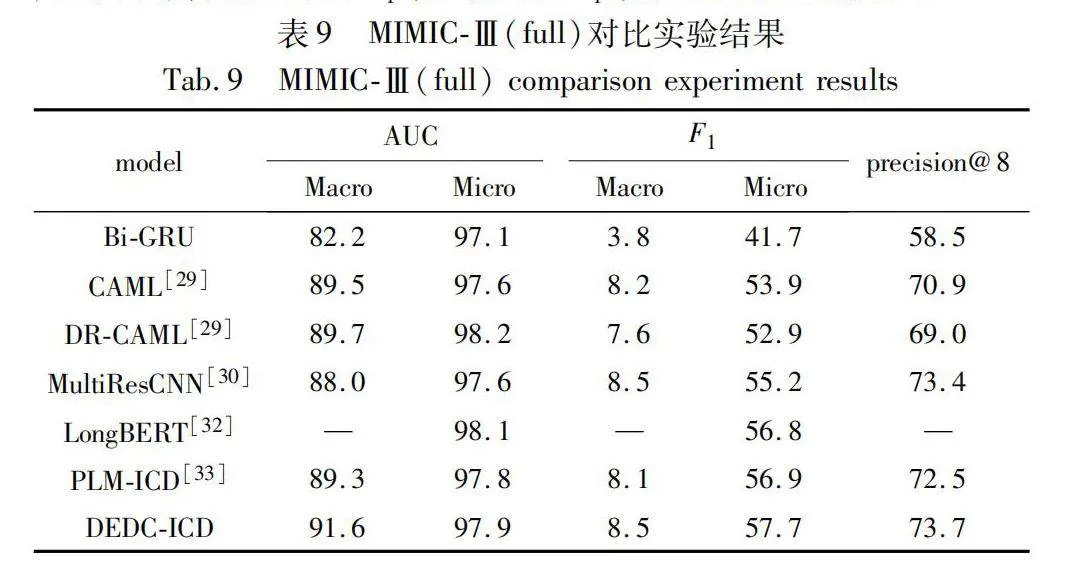
表8呈現了在 MIMIC-Ⅲ(top50) 上進行的實驗結果。結果表明,本文模型在多個評價指標上表現出色,相較于基線模型具有顯著的優勢,這驗證了模型在處理具有豐富訓練樣本的標簽時的有效性。而表9則展示在MIMIC-Ⅲ(full)上的實驗結果,盡管面臨標簽分布不平衡的挑戰,本文模型依然展現出較強的性能,特別是在處理樣本較少的標簽時,其表現尤為突出。為進一步驗證本文DEDC-ICD的性能,將其與幾個典型的文本分類算法如C-MemNN、C-LSTM-Att、CAML、DR-CAML、MultiResCNN以及LongBERT等進行對比。
通過對表8、9的觀察可以發現,在MIMIC-Ⅲ(full)中,宏觀F1值明顯低于微觀F1值。這一現象主要歸因于MIMIC-Ⅲ(full)中存在的標簽分布不平衡問題。在該數據集中,許多標簽的訓練樣本數量較少,甚至僅有幾條或幾十條,導致模型對這些標簽的訓練不足。由于訓練樣本數量不足,模型未能充分學習這些標簽的潛在特征,所以在對這些標簽進行預測時表現較差。相反,在MIMIC-Ⅲ(top50)中,雖然宏觀F1值仍然小于微觀F1值,但兩者之間的差距顯著減小。這是因為在MIMIC-Ⅲ(top50)中,選取MIMIC-Ⅲ中最常見的50個標簽作為訓練集,這些標簽具有大量的訓練數據,模型在這些標簽上得到充分的訓練,因此宏觀F1值與微觀F1值之間的差距減小。
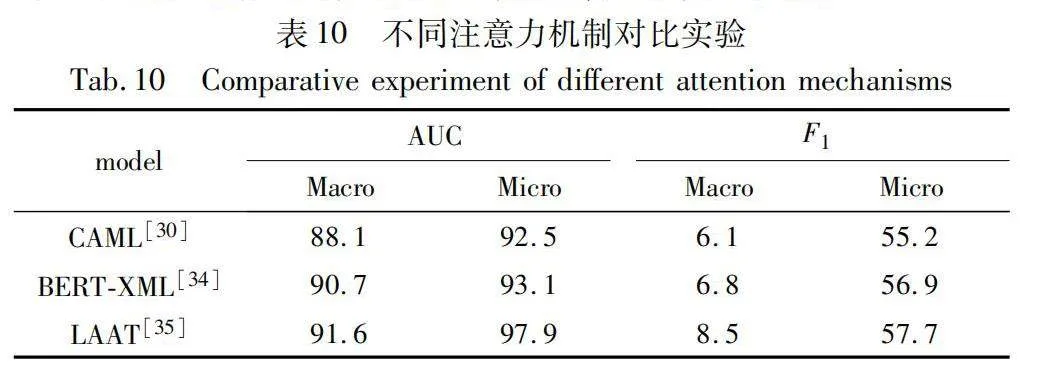
實驗采用不同的標簽注意力機制在MIMIC-Ⅲ(full)上進行比較,并在表10中展示各自的性能表現。如表10所示,具體比較包括 LAAT、CAML和BERT-XML在內的標簽注意力機制。結果顯示,本文采用的LAAT中使用標簽注意力機制表現最優。這意味著LAAT的標簽注意力機制與本文模型結構相適應,能夠更好地增強模型對重要標簽的關注度,從而提高對與ICD編碼相關的標簽的識別能力,提升模型性能。
3.6 案例分析
為了進一步驗證DEDC-ICD在ICD編碼分類任務中的有效性,隨機選取若干條電子病歷進行對比,下面以MIMIC-Ⅲ(full) 其中一條作為樣例進行分析,如圖5所示。這段臨床記錄描述了一位年輕患者的情況,因從約三層樓高的地方跌落而被送至醫院。
clinical note:
present illness this is a young male of unknown age brought by ems after having sustained an approximately three story
fall, the patient had a fast exam which showed fluid in the peritoneal cavity and was therefore forwarded rapidly to the
operating room, the patient had a right chest tube placed and there was seen to be a moderate amount of bleeding out of the
right chest, ... however there was seen to be a large retroperitoneal hematoma extending from the pelvis up to the level of
the kidneys re-troperitoneally ...
codes:
860.4(Intra-abdominal injury without mention of open wound);
868.03(Other and unspecified injuries of unspecified intra-abdominal organs);
E957.1(Fall from one level to another);
854.05(Other specified intracranial injuries following injury without mention of open intracranial wound)
MultiResCNN
860.4; 868.03; 854.00PLM-ICD860.4; 868.03; 854.05DEDC-ICD860.4; 868.03; E957.1; 854.05
在對同一電子病歷文本進行ICD編碼分類的過程中,盡管MultiResCNN方法能夠預測出3個標簽,但其中的一個標簽準確度不足,將標簽854.05(顱內損傷伴有短暫的意識喪失)預測為標簽854.00(未特指的顱內損傷)。這主要是因為模型在特定的醫療編碼任務中缺少醫學領域數據的訓練,對標簽預測不夠精準,同時會受到標簽不平衡問題的影響。與之相比,基線模型PLM-ICD也預測出3個標簽,且都是準確的,但缺少對標簽E957.1(未特指的跌落事故)的預測。本文模型能夠更準確地識別出所有標簽,這種改進主要得益于Mixup數據增強技術的應用,該技術為模型的訓練提供更多樣化的數據,從而確保模型能夠接受更為全面的學習。此外,擴張卷積的引入顯著提升模型捕獲電子病歷文本中長距離依賴關系的能力,這不僅有助于模型對病歷進行整體分類,還使得模型能夠關注到其他模型忽視的細節信息。結合預訓練模型BioLinkBERT,針對特定生物醫學領域表現更為出色。
4 結束語
本文提出一種基于數據增強和擴張卷積的ICD編碼分類方法。首先,采用預訓練模型BioLinkBERT,利用無監督學習獲得上下文相關的單詞表示,以更準確地捕捉語義信息;其次,引入Mixup技術,通過優化隱藏表示來增強樣本的質量和分類魯棒性;最后,引入多粒度擴張卷積,利用不同擴張率的卷積核增強不同距離單詞之間的交互,從而提升模型的分類性能。實驗結果表明,DEDC-ICD在MIMIC-Ⅲ數據集上的F1值和precision@k方面均有改善,相較于基準模型分別提升0.4%~1.5%和1.2%~1.6%,為ICD編碼任務提供可行的解決方案。未來的研究方向包括有效整合多模態數據以提高對醫療信息的利用能力,并將模型應用于實際的臨床環境[36]。通過系統的臨床驗證評估其在醫療決策中的效果,這一系列研究將有助于推動ICD編碼領域在實際醫學應用中的發展。
參考文獻:
[1]姜麗梅, 李秉龍. 面向圖像文本的多模態處理方法綜述[J]. 計算機應用研究, 2024, 41(5): 1281-1290. (Jiang Limei, Li Bing-long. Comprehensive review of multimodal processing methods for image-text[J]. Application Research of Computers, 2024, 41(5): 1281-1290.)
[2]趙京勝, 宋夢雪, 高祥, 等. 自然語言處理中的文本表示研究[J]. 軟件學報, 2022, 33(1): 102-128. (Zhao Jingsheng, Song Mengxue, Gao Xiang, et al. Research on text representation in natural language processing[J]. Journal of Software, 2022, 33(1): 102-128.)
[3]Liu Jingzhou, Chang Weicheng, Wu Yuexin, et al. Deep learning for extreme multi-label text classification[C]// Proc of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2017: 115-124.
[4]郝超, 裘杭萍, 孫毅, 等. 多標簽文本分類研究進展[J]. 計算機工程與應用, 2021, 57(10): 48-56. (Hao Chao, Qiu Hangping, Sun Yi, et al. Research progress of multi-label text classification[J]. Computer Engineering and Applications, 2021, 57(10): 48-56.)
[5]辛梓銘, 王芳. 基于改進樸素貝葉斯算法的文本分類研究[J]. 燕山大學學報, 2023, 47(1): 82-88. (Xin Ziming, Wang Fang. Research on text classification based on improved naive Bayes algorithm[J]. Journal of Yanshan University, 2023, 47(1): 82-88.)
[6]呂學強, 彭郴, 張樂, 等. 融合BERT與標簽語義注意力的文本多標簽分類方法[J]. 計算機應用, 2022, 42(1): 57-63. (Lyu Xueqiang, Peng Chen, Zhang Le, et al. Text multi-label classification method incorporating BERT and label semantic attention[J]. Journal of Computer Applications, 2022, 42(1): 57-63.)
[7]張文峰, 奚雪峰, 崔志明, 等. 多標簽文本分類研究回顧與展望[J]. 計算機工程與應用, 2023, 59(18): 28-48. (Zhang Wenfeng, Xi Xuefeng, Cui Zhiming, et al. Review and prospect of multi-label text classification research[J]. Computer Engineering and Applications, 2023, 59(18): 28-48.)
[8]Yasunaga M, Leskovec J, Liang P. LinkBERT: pretraining language models with document links[C]// Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Asso-ciation for Computational Linguistics, 2022: 8003-8016.
[9]Wu Linzhi, Xie Pengjun, Zhou Jie, et al. Robust self-augmentation for named entity recognition with meta reweighting[C]// Proc of Confe-rence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2022: 4049-4060.
[10]Li Jingye, Fei Hao, Liu Jiang, et al. Unified named entity recognition as word-word relation classification[C]// Proc of AAAI Confe-rence on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 10965-10973.
[11]Kim Y. Convolutional neural networks for sentence classification[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1746-1751.
[12]Shimura K, Li Jiyi, Fukumoto F. HFT-CNN: learning hierarchical category structure for multi-label short text categorization[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 811-816.
[13]Yang Wenshuo, Li Jiyi, Fukumoto F, et al. HSCNN: a hybrid-siamese convolutional neural network for extremely imbalanced multi-label text classification[C]// Proc of Conference on Empirical Me-thods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2020: 6716-6722.
[14]Tan Zhipeng, Chen Jing, Kang Qi, et al. Dynamic embedding projection-gated convolutional neural networks for text classification[J]. IEEE Trans on Neural Networks and Learning Systems, 2021, 33(3): 973-982.
[15]Chen Zhaomin, Wei Xiushen, Wang Peng, et al. Multi-label image recognition with graph convolutional networks[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Pisca-taway, NJ: IEEE Press, 2019: 5177-5186.
[16]Zhang Wenjie, Yan Junchi, Wang Xiangfeng, et al. Deep extreme multi-label learning[C]// Proc of ACM on International Conference on Multimedia Retrieval. New York: ACM Press, 2018: 100-107.
[17]Hu Junlin, Kang Xin, Nishide S, et al. Text multi-label sentiment analysis based on Bi-LSTM[C]// Proc of the 6th International Confe-rence on Cloud Computing and Intelligence Systems. Piscataway, NJ: IEEE Press, 2019: 16-20.
[18]Xie Pengtao, Xing E. A neural architecture for automated ICD coding[C]// Proc of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 1066-1076.
[19]Liu Yapei, Ma Jianhong, Tao Yongcai, et al. Hybrid neural network text classification combining TCN and GRU[C]// Proc of the 23rd International Conference on Computational Science and Engineering. Piscataway,NJ:IEEE Press, 2020: 30-35.
[20]Yang Pengcheng, Sun Xu, Li Wei, et al. SGM: sequence generation model for multi-label classification[C]// Proc of the 27th International Conference on Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 3915-3926.
[21]Lin Junyang, Su Qi, Yang Pengcheng, et al. Semantic-unit-based dilated convolution for multi-label text classification[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2018: 4554-4564.
[22]Xiao Yaoqiang, Li Yi, Yuan Jin, et al. History-based attention in seq2seq model for multi-label text classification[J]. Knowledge-Based Systems, 2021, 224: 107094.
[23]Zhou Peng, Shi Wei, Tian Jun, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]// Proc of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 207-212.
[24]Yang Zichao, Yang Diyi, Dyer C, et al. Hierarchical attention networks for document classification[C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2016: 1480-1489.
[25]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]// Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[26]Lu Weijun, Duan Yun, Song Yutong. Self-attention-based convolutional neural networks for sentence classification[C]// Proc of the 6th International Conference on Computer and Communications. Pisca-taway, NJ: IEEE Press, 2020: 2065-2069.
[27]Prakash A, Zhao Siyuan, Hasan S, et al. Condensed memory networks for clinical diagnostic inferencing[C]// Proc of AAAI Confe-rence on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017: 3274-3280.
[28]Shi Haoran, Xie Pengtao, Hu Zhiting, et al. Towards automated ICD coding using deep learning[EB/OL]. (2017-11-11). https://arxiv.org/abs/1711.04075.
[29]Mullenbach J, Wiegreffe S, Duke J, et al. Explainable prediction of medical codes from clinical text[C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2018: 1101-1111.
[30]Li Fei, Yu Hong. ICD coding from clinical text using multi-filter residual convolutional neural network[C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 8180-8187.
[31]Tsai Shangchi, Huang Chaowei, Chen Yunnung. Modeling diagnostic label correlation for automatic ICD coding[C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2021: 4043-4052.
[32]Afkanpour A, Adeel S, Bassani H, et al. BERT for long documents: a case study of automated ICD coding[C]// Proc of the 13th International Workshop on Health Text Mining and Information Analysis. Stroudsburg, PA: Association for Computational Linguistics, 2022: 100-107.
[33]Huang Chaowei, Tsai S C, Chen Yunnung. PLM-ICD: automatic ICD coding with pretrained language models[C]// Proc of the 4th Clinical Natural Language Processing Workshop. Stroudsburg, PA: Association for Computational Linguistics, 2022: 10-20.
[34]Zhang Z, Liu Jingshu, Razavian N. BERT-XML: large scale automated ICD coding using BERT pretraining[C]// Proc of the 3rd Clinical Natural Language Processing Workshop. Stroudsburg, PA: Association for Computational Linguistics, 2020: 24-34.
[35]Vu T, Nguyen D Q, Nguyen A. A label attention model for ICD co-ding from clinical text[C]// Proc of the 29th International Confe-rence on International Joint Conferences on Artificial Intelligence. 2021: 3335-3341.
[36]劉建偉, 丁熙浩, 羅雄麟. 多模態深度學習綜述[J]. 計算機應用研究, 2020, 37(6): 1601-1614. (Liu Jianwei, Ding Xihao, Luo Xionglin. Survey of multimodal deep learning[J]. Application Research of Computers, 2020, 37(6): 1601-1614.)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
