基于合作博弈和強化學習的優先信號控制方法
2024-12-31 00:00:00秦浩張維石
計算機應用研究 2024年11期


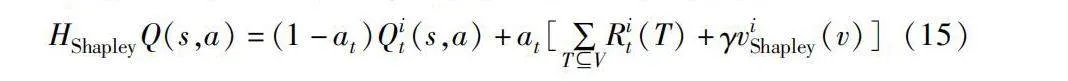

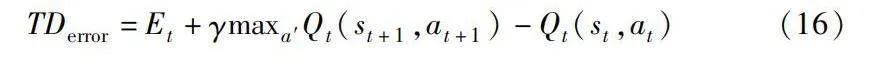


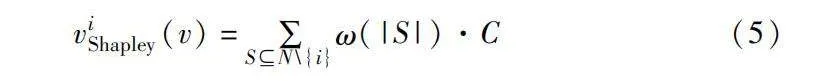

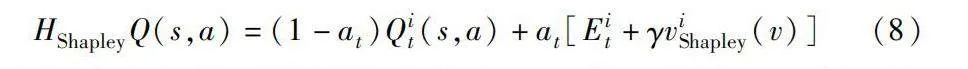


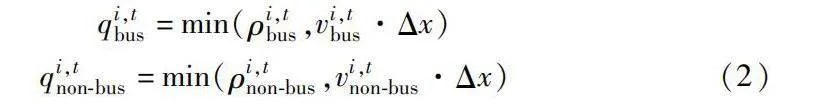



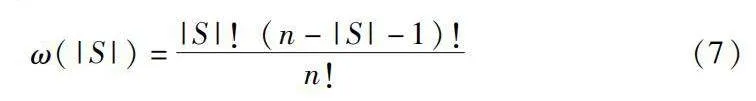

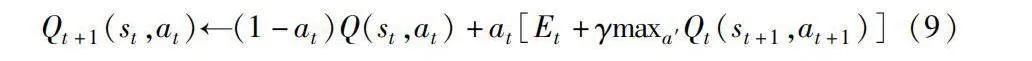
摘 要:針對智能交通系統優先信號控制效率低問題,提出一種基于合作博弈與強化學習混合決策的八相位優先信號控制方法CBQL-TSP。該方法將公交信號優先權分配抽象成一個八相位信號時序的多目標決策問題,將信號相序細化為優先相位與非優相位,構建合作博弈模型。提出一種混合決策算法CBQL,解決八相位信號時序的多目標決策問題,通過求解夏普利值函數獲取博弈各成員邊緣貢獻,根據夏普利值比構建狀態轉移概率方程。與常見控制方法相比,CBQL-TSP具有合作博弈的公平性原則和Q-learning的適應性學習能力,能夠根據實時交通狀況動態調整信號時序,在優先信號控制上具有更高的靈活性和效率。建立仿真測試平臺,比較不同需求量下系統平均等待車數和平均通行時間,評估方法的穩定性和效率。實驗結果表明,提出方法具有更高的穩定性,并且整體平均通行時間減少了約24.57%,公交平均通行時間減少約37.40%。CBQL-TSP在公交優先路口具有更高的控制效率,可顯著減少整體和公交平均通行時間。
關鍵詞:交通信號優先控制;合作博弈;強化學習;八相位優先信號
中圖分類號:TP391.9 文獻標志碼:A 文章編號:1001-3695(2024)11-021-3350-07
doi:10.19734/j.issn.1001-3695.2024.03.0090
Control method of transit signal priority based on coalitional bargaining games and reinforcement learning
Qin Hao, Zhang Weishi?
(College of Information Science amp; Technology, Dalian Maritime University, Dalian Liaoning 116026, China)
Abstract:This paper proposed an eight-phase transit signal priority control method, CBQL-TSP, based on a hybrid decision-making approach combining cooperative game theory and reinforcement learning, aiming to address the low efficiency of transit signal priority control in intelligent transportation systems. The method abstracted the allocation of bus signal priority into a multi-objective decision-making problem with an eight-phase signal sequence, refining the signal phase sequence into priority and non-priority phases, and constructing a cooperative game model. The paper introduced a hybrid decision-making algorithm, CBQL, to solve the multi-objective decision-making problem of eight-phase signal timing. The algorithm calculated the marginal contributions of each game member by solving the Shapley value function and constructed the state transition probabi-lity equation based on the Shapley value ratio. Compared to conventional control methods, CBQL-TSP incorporated the fairness principle of cooperative game theory and the adaptive learning ability of Q-learning, enabling dynamic adjustment of signal timing based on real-time traffic conditions. This method offered higher flexibility and efficiency in priority signal control. This paper established a simulation test platform to compare the average waiting car count and average travel time under different demand levels, evaluating the stability and efficiency of the method. The experimental results demonstrate that the proposed method exhibits higher stability. Furthermore, the overall average travel time is reduced by approximately 24.57%, and the average travel time for buses is reduced by about 37.40%. CBQL-TSP demonstrates higher control efficiency at bus-priority intersections, significantly reducing both overall and bus average travel times.
Key words:transit signal priority(TSP); coalitional bargaining; reinforcement learning; eight-phase priority signal
0 引言
公交優先是城市發展與規劃中的核心戰略之一,它通過政策扶持、資金投入和技術支持,確保公交建設與管理的優先地位,進而為廣大市民提供更為快捷、高效的交通服務。以國內外城市交通建設的經驗為基礎,公交優先是解決交通問題的重要舉措。公交運載能力是私家車和出租車的數倍,可以有效地降低道路交通流量。
優先信號控制(TSP)是公交優先的一種重要技術手段,是交通工程和智能交通系統(ITS)的一個重要研究領域。TSP系統通過調整交通信號的時序,為公交車輛在交叉口提供優先通行權,從而顯著減少公交車輛的行程時間和等待時間。這不僅提升了公交服務的可靠性和效率,還增加了公交的吸引力,進一步鼓勵市民選擇公共交通作為出行方式,有助于減輕城市交通擁堵。TSP的主要目的是提高交通系統的效率和安全性,特別是對公共交通和緊急車輛。交叉口公交優先智能信號控制對緩解交通擁堵具有重要意義。快速公交系統(bus rapid transit,BRT)是將ITS與具有優先權的專用道進行整合,用來提供一種類似鐵路的可靠、高速和低成本的運輸服務[1]。但是與鐵路運輸情況不同的是,BRT車輛將與其他車輛在路口發生沖突。因此通過研究TSP的控制方法可以加大提高BRT運行效率[2]。
最早的交通信號控制方法依賴于固定時間信號時間表,即交通信號按照預定時間表變化。這種方法雖然簡單易行,但往往效率低下,在交通需求低時導致不必要的延誤,而在交通需求高時則造成擁堵。現有TSP方法存在協調效率低、優先權不平衡等問題。存在這些問題的原因是,不同類型車輛之間的優先級和通行需求不同,如果信號控制無法合理協調優先車輛與非優先車輛的通行時間,會導致交通流的混亂和不平衡,增加交通擁堵、延長通行時間,對整體交通效率產生負面影響。目前對于優先車輛與非優車輛的協同優化模型研究較少,缺乏對等因素的考慮,完整控制模型的構建等研究還相對缺乏。本文提出一種八相位優先信號控制方法,考慮到快速公交系統的公交信號優先,以實現私家車的最大穩定性和可靠的公交服務。該方法基于合作博弈與強化學習,對公交車和私家車的優先權進行聯合決策,決策包括條件限制和提供優先權的公交車策略。合作博弈能夠有效模擬不同優先級車輛之間的相互作用與決策過程,提供策略框架,通過協同優化達到平衡各方利益的目的。強化學習適用于處理具有高度動態性和不確定性的環境,能夠基于交通流的實時數據不斷學習和調整信號控制策略。此外,該策略是離散的,即只取決于每個交叉路口的局部條件。本文將模擬設定在一個有快速公交系統的真實道路網絡上。
1 相關工作
面向公交優先的信號控制方法主要分為被動優先控制、主動優先控制和自適應優先控制三種。
被動優先概念的提出可追溯到1972年,Urbanik和Holder提出了利用信號周期、區域綠波協調和匝道控制來實現公交被動信號優先的概念[3]。被動優先的最大優點是不需要增加專門的檢測設備,因此實施成本通常較低[4]。但是,由于被動優先技術缺乏對公交實時運營狀態的感知能力,需要對公交線路的客流情況、運營班次等方面有充分的了解。現階段被動優先往往設置在公交車輛頻繁通過的路口,通過被動優先邏輯來解決因優先請求頻率高而導致的決策難問題[5,6]。Ni等人[7]提出了一種基于微觀模擬的被動TSP方法,使用遺傳算法求解最優TSP策略,通過協調BRT信號偏移最小化車輛延誤,并在真實BRT系統中進行了以系統容量為指標的實驗。
主動優先控制是指在公交車上或交叉路口安裝傳感設備,以提高交通狀態識別能力。觸發條件的分類包括手動控制[8]和自動控制[9],后者主要基于模型的決策觸發[10,11]。在研究信號調整策略時,現有文獻重點介紹了截斷紅燈信號或提前綠燈信號[12]和延長綠燈信號[13]兩種突出的主動方法。研究人員還對復雜控制策略進行了研究,這些策略雖然要求更強的交通感知和信號調整能力,但由于其在相位切換方面可能更具侵略性,所以也帶來了挑戰[14]。盡管存在潛在的安全風險以及較高的成本,但這些策略為TSP 控制方法的創新作出了貢獻[15]。
自適應優先控制是利用道路檢測、車輛定位技術等,獲得該地區的道路交通狀態以及公交車輛的運行狀態,從而對信號進行實時控制,以確保公交優先[16]。道路交通狀態包括該地區車輛的平均車速、各路口的交通狀況、公共汽車的運營情況等。隨著強化學習理論的發展,強化學習因為強大的經驗學習優勢而在交通控制領域得到應用,被認為是交通網絡控制領域最有前景的方法[17,18]。Li等人[19]提出了一種使用合作自適應巡航控制模型CACC和深度Q網絡DQN算法的自適應TSP方法,利用DQN算法促進場景數據收集、分析和反饋,在獎勵函數中加入均衡獎勵項,以優化交通平衡。Kolat等人[20]提出了一種基于強化學習的信號控制方法,該方法基于多智能體和深度Q學習算法,將多智能體和DQN相結合,從多目標優化角度解決信號控制問題。文獻[21]采用深度神經網絡處理交叉口視頻,提取交通狀態,并應用深度強化學習網絡學習交叉口信號控制策略,構建了一種智能信號燈控制方法。對于基于視頻的交通控制,本質上是監督學習,需要借助具有代表性的訓練實例進行訓練,但在交通網絡的實際交互環境中應用這些實例可能存在一定困難。為理解交通參與者的競爭與合作行為并建立模型,博弈論已被廣泛應用于研究互動過程中的理性自私或合作行為,并被應用于先進的交叉口管理[22]。Abdoos等人[23]提出了一種基于博弈論的雙模式智能體架構,利用多智能體系統MAS,通過獨立模式和合作模式調整信號控制策略。澳大利亞斯威本科技大學與莫納什大學[24]聯合提出了一個數學框架,建立了基于單一目標網絡的TSP系統,以及動態交通分配方法。美國明尼蘇達大學[25]對最大壓力控制方法[26]進行了針對TSP問題的優化,提出了一種基于最大壓力控制算法的TSP方法,為公交車提供優先級的約束,以實現非優車輛的最大穩定性和可靠的公交服務,實現BRT的自適應TSP控制。Zhang等人[27]提出了一種自適應TSP方法,采用D3QN算法以公交車和私家車總乘客等待時間為優化目標,求解最優TSP策略,并在廣州BRT系統中進行了以車輛等待時間為指標的實驗。
交通信號優先控制領域仍面臨一些挑戰。自適應信號控制雖可根據實時交通情況調整信號時間,但對交通流的突發或不尋常變化可能難以迅速適應。協調多個交叉口的信號時間存在困難,優先信號可能改善一個路口的車輛行駛時間,但也可能引發連鎖反應,干擾下游路口的交通流。研究者傾向于采用基于交叉口的代理模型,模擬信號控制的決策行為,通過人工智能決策方法實現協同優化。在私家車和優先車輛協同決策時,需要解決博弈論中多方互動決策問題,通過分析各方策略、目標和利益,設計交叉口信號控制方法,以最大程度實現協同效果。
2 八相位優先信號模型
2.1 研究路線
本文提出一個新的TSP控制方法CBQL-TSP(cooperative bargaining games and Q-learning for transit signal priority),將TSP系統的交通信號問題建模成一個多智能體多動作空間的馬爾可夫模型,采用合作博弈策略來解決模型中關于優先信號和非信號決策的問題,其中模型的優化目標是將總延遲時間和優先車輛的最大延遲時間最小化。
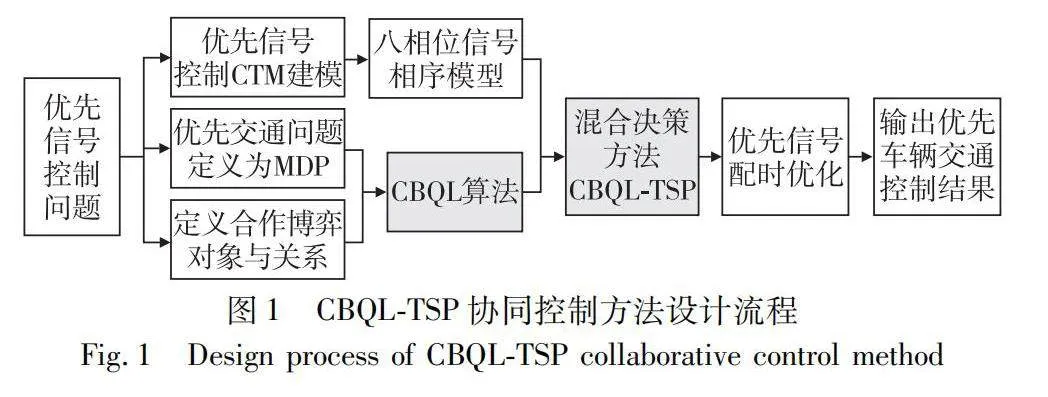
CBQL-TSP 控制方法的設計過程如圖1所示。首先是對交通信號優先問題的全面描述。該方法結合了博弈分析,重點關注優先級車輛與非優先級車輛之間的互動。這一分析為 CBQL 算法的實施奠定基礎。CBQL算法是一種動態學習方法,可調整兩類車輛的信號控制策略,以實現多智能體的貢獻均衡,確保在博弈論背景下獲得均衡和最優解決方案。考慮到優先信號控制的復雜性,對交通信號優先級環境進行配置,根據算法得到的最優策略對優先信號配時。系統輸出交通優先信號控制結果,驗證CBQL-TSP的有效性。為了增強系統的適應性,提出了八相位優先信號控制方法,同時對核心參數進行嚴格定義和整合,確保所提方法在動態控制交通信號的穩定性和效率。
2.2 優先車輛的元胞傳輸模型
利用短時交通流預測得到的數據在元胞傳輸模型CTM(cell transmission model)基礎上進行建模。在 CTM 中,道路被離散化為單元,交通狀態的演變發生在離散的時間步長內。本文將在這個單元框架內表示公共汽車和非公共汽車的交通密度、流量和速度。
讓ρibus和ρinon-bus表示t 時刻i 單元中公交車和非公交車的密度,qibus和qinon-bus表示相應的流量。速度vibus和vinon-bus表示i單元中公共汽車和非公共汽車的平均速度。
基于 CTM 的方程表達如下:
ρi,t+1bus=ρi,tbus+ΔtΔx(qi-1,tbus-qi,tbus)
ρi,t+1non-bus=ρi,tnon-bus+ΔtΔx(qi-1,tnon-bus-qi,tnon-bus)(1)
其中:
qi,tbus=min(ρi,tbus,vi,tbus·Δx)
qi,tnon-bus=min(ρi,tnon-bus,vi,tnon-bus·Δx)(2)
單元i在時刻t的總密度ρi,t是公交密度和非公交密度之和:
ρi,t=ρi,tbus+ρi,tnon-bus(3)
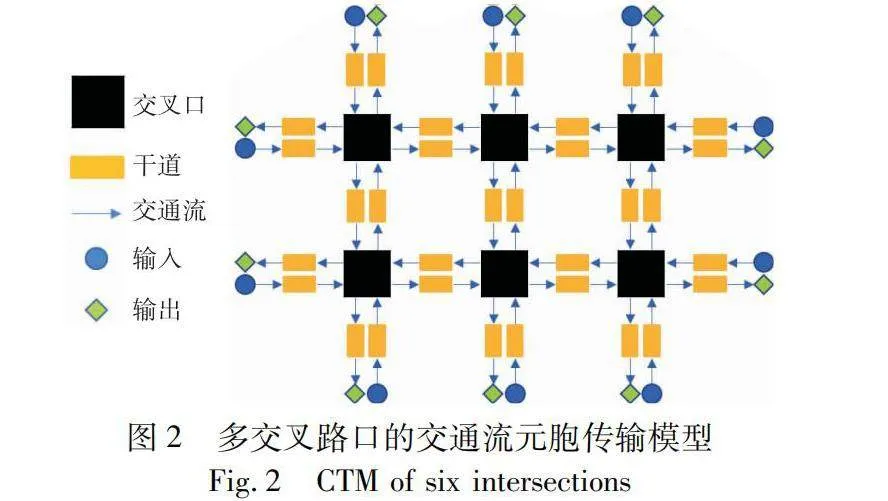
如圖2所示,以6個交叉路口的交通網絡為例,該網絡包含10個起點和目的地。起點和目的地之間的路線選擇以及每條路線的交通流量比例已納入CTM。由于交叉口的相位數對CTM的結構沒有很大的影響,所以模型易擴展到非對稱網絡。
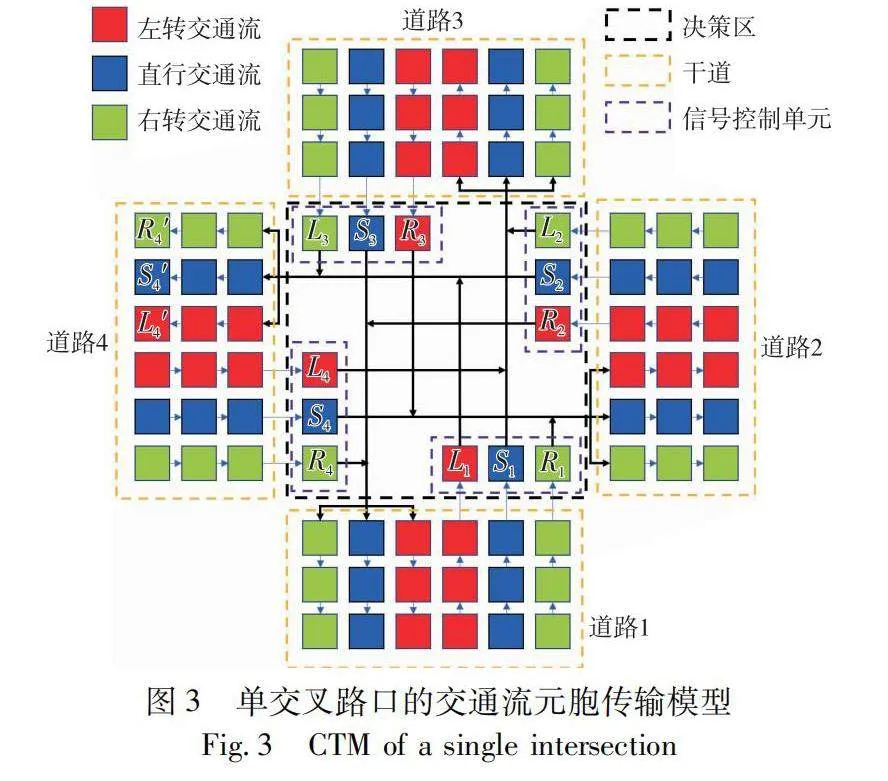
針對每個交叉口,研究使用鏈路相交的單元格表示。在鏈路中,交通流沿正反的移動方向分為上游發送區和下游接收區兩部分。并根據預測路線進一步分為左轉、直行和右轉交通流。
如圖3所示中間黑色虛線的區域是決策區也是沖突區,用于模擬車輛的沖突行為。由于考慮了不同的車輛行駛路線,交叉路口的交通流存在復雜的合并和發散行為。每個信號控制單元(Li,Si和Ri) 將交通流發散到交叉路口的三個下游接收區,同時每個接收區從三個上游發送區接收交通流。
2.3 八相位信號相序模型
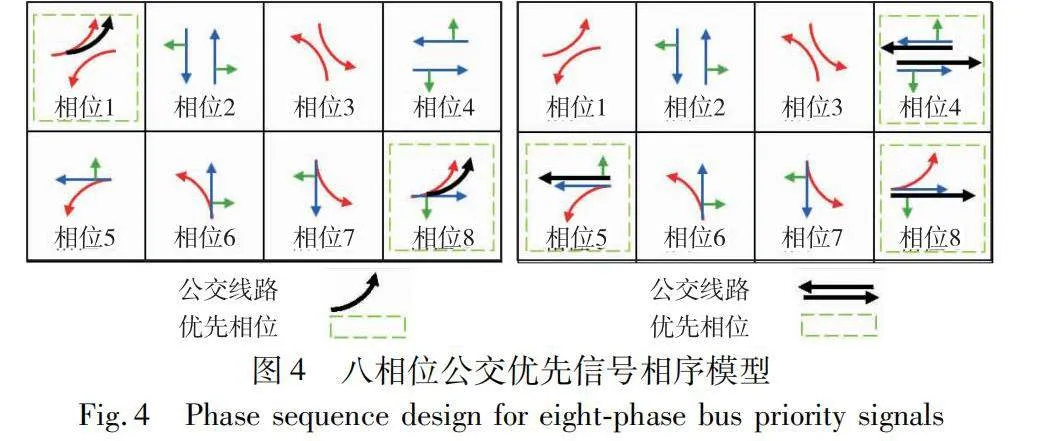
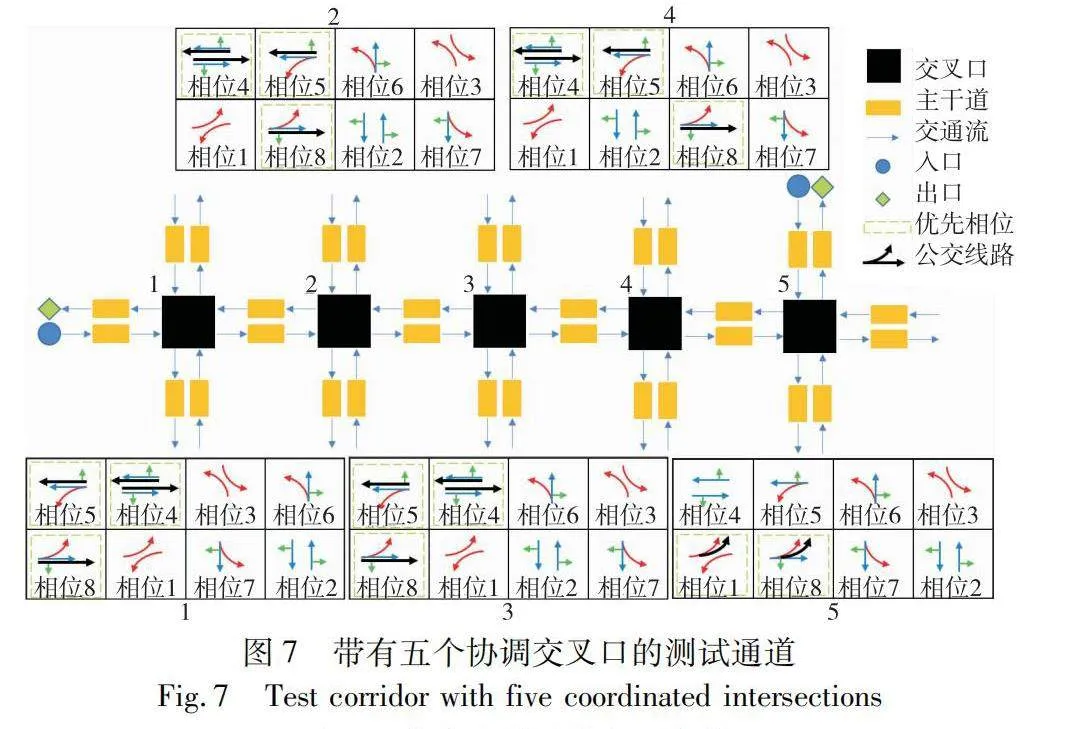
本文將公交信號優先權的實現視為信號相位序列的多步決策問題,并提出了一種八相位信號控制方法。該方法基于智慧公交的具體路線進行制定,將交叉口信號控制相序分為優先信號與非優信號兩類進行深入研究。圖4展示了根據不同優先公交路線是直行還是左行,將交叉口信號劃分為八個相位模型的相位設計。在圖例的左行模型的相位中,相位1和8被定義為包含優先公交線路的優先相位;在圖例的直行模型的相位中,相位4、5和8則被確定為包含優先公交線路的優先相位。
由于交通信號配時具有無后效性,第3章將該問題建模為一個馬爾可夫決策過程(MDP)。這種決策模型能夠更好地捕捉信號相位序列的多步決策特性,有助于在智能交通系統中實現有效的公交信號優先權控制。
3 合作博弈與強化學習混合決策方法
3.1 CBQL
本文提出一種基于合作博弈Q學習算法(cooperative bargaining Q-learning,CBQL)。
CBQL的核心思想是將合作博弈中夏普利值和邊際貢獻與Q-learning框架相結合,定義智能體合作決策。通過夏普利值和邊際貢獻,調節狀態轉移概率,使智能體在學習過程中根據合作博弈中的貢獻程度調整行為。在Q-learning學習過程中,智能體能夠更加有效地選擇動作,促進合作學習進展,達到更加公平和高效合作決策策略的目的。Q值函數定義如下:
Q*(s,a)=E(s,a)+γ∑s′p(s′|s,a)v(s′,π*)(4)
其中:Q*(s,a)是在狀態s中采取行動a并遵循最優策略的總折現獎勵;E(s,a)是即時獎勵,表示狀態s下采取行動a得到的即時回報;γ是折現系數,表示學習隨著時間推移的衰減率;π*是最優策略,是使得從任何狀態s開始的期望累積獎勵最大化的策略。
采用Shapley value函數求解由Q定義的當前博弈各成員的邊際貢獻C。記I={1,2,…,N}為N個博弈成員的集合,定義i為其中一個成員,則viShapley表示成員i的夏普利值,即成員i的貢獻度,可以表示為
viShapley(v)=∑SN\{i}ω(|S|)·C(5)
其中:S是N的一個不包括參與者i子集。邊際貢獻C是聯盟收益與去掉成員i后聯盟收益之差,即成員i對聯盟帶來的增益貢獻,也叫邊際貢獻。成員i在聯盟中的邊際貢獻C可以表示為
C=v(s)-v(S\{i})(6)
其中:v表示合作博弈的特征函數,定義每個可能的聯盟(包含一個或多個參與者)所獲得的價值或收益;
ω是聯盟中的權重因子,ω的計算公式為
ω(|S|)=|S|!(n-|S|-1)!n!(7)
其中:n表示聯盟中合作人的總數;|S|是集合S元素的個數。
在夏普利值計算過程中,研究對所有可能的合作組合S進行遍歷,并計算參與者i加入組合之后的新增貢獻,再對所有組合的新增貢獻進行加權平均,其中的權重根據組合的大小決定。
在時間步長t處agent觀察當前狀態s并采取行動,然后觀察自己的獎勵Rit、其他agent的行動、其他agent的獎勵R′t以及新的狀態s′。根據式(4)(5),CBQL的Q值為
HShapleyQ(s,a)=(1-at)Qit(s,a)+at[Eit+γviShapley(v)](8)
根據各成員的夏普利值改進對Q函數的估計。不斷迭代上式直到Q值滿足終止條件。對于所有s∈S,a∈A的Q(s,a)的初始化,Q值的更新方程為
Qt+1(st,at)←(1-at)Q(st,at)+at[Et+γmaxa′Qt(st+1,at+1)](9)
其中:at表示在選擇動作a時收到最大回報在所有回報中所占比例的估計值。
at=1 Etgt;Qmax(a)
(1-af)at+af Et=Qmax(a)
(1-af)at Etlt;Qmax(a)(10)
其中:af是學習率。對于每個動作a,算法在計算更新Q 值的同時,記錄在過去經歷中該動作下智能體曾獲得的最大回報Qmax。
混合決策的策略更新方式是逐步增加選擇Q最大的動作的概率,減少其他動作被選擇的概率:
π(s,a)←π(s,a)+af if a=arg maxa′Q(s,a′)
-af|A|-1others(11)
CBQL算法的偽代碼如下:
算法1 CBQL算法
初始化
設定時間步 t=0
獲取初始狀態 s0
設學習代理由 i 索引
循環:
對于所有代理 i :
根據夏普利值選擇一個動作ait
執行動作ait,轉移到下一個狀態s(t+1)=s′,環境返還獎勵r
更新代理i的Q值:
HShapleyQ(s,a)=(1-at)Qit(s,a)+at[Eit+γviShapley(v)]
其中at∈(0,1)是學習率, γ是折現系數
將時間步t增加1
如果滿足終止條件:
退出循環
3.2 混合決策方法
本文提出一個基于CBQL的八相位TSP方法(CBQL-TSP),根據3.1節所提CBQL決策算法,解決八相位優先信號控制決策問題。將TSP系統建模為一個MDP模型,第2章提出的八相位信號相序模型將作為依據定義MDP的動作空間集合。
為了解決TSP問題,需要將交通信號的狀態和相應的控制方案映射到智能體的狀態空間中。將交叉口信號控制智能體k的狀態表示為一個向量sk[j],包含P+3個分量j,其中P是當前交叉口的相位數量,分量j=0,1,…,P+2。前三個分量是:當前處于綠燈階段的相位、當前相位的綠信比λ和當前相位信號周期時長T,剩下P個分量對應于每個相位的當前交通流量。狀態向量的公式如下:
sk[j]=φk j=0λak j=1Tak j=2Qk[j-3]j∈{3,…,P+2}(12)
MDP的狀態空間集合為S=[S1,…,Sk,…,Sn],其中n是交叉口的數量,根據式(12),狀態空間包括綠燈相位φ、綠信比λ、信號周期T、以及每個相位的當前交通流量Q[j],則交叉口k的狀態向量為sk={fk,λk,Tk,Qk[0],…,Qk[P-1]}。
MDP的動作空間為集合A={a1,a2,…,a8},集合中元素分別對應2.3節提出的八個優先信號相位。其中ai表示信號將從當前相位執行動作ai至相位i狀態。agent采取獨立于其他狀態下的任何行動a∈A(s)A時,系統狀態s∈S隨著動作的執行而改變,其中A(s) 是在狀態s∈S中可用的行動集合。
A=∪s∈SA(s)(13)
V∈2{i, j}表示成員i和j形成的聯盟。遍歷所有可能的聯盟TV,并將他們的特征函數值相加,得到成員i的回報期望:
Ei(V)=∑TVR(T)=∑TVα·vj+β·vifj+ω·fi(14)
其中:vi和vj分別表示公交車和私家車的平均行駛速度; fi和fj分別表示公交車和私家車的交通流量;α、β和ω是調節參數。獎勵參數α用于調整不同因素獎勵的總體規模,控制整體獎勵規模,速度參數β用于調節公交車速度對獎勵的影響,流量參數ω用于調整公交車流量對獎勵的影響。
根據式(8)(14),CBQL的Q函數可以表示為
HShapleyQ(s,a)=(1-at)Qit(s,a)+at[∑TVRit(T)+γviShapley(v)](15)
CBQL-TSP方法的基本思想是將交通環境的當前狀態傳遞給兩個模型。CB模型根據狀態計算動作轉移概率,根據動作轉移概率選擇動作。動作執行會改變環境狀態,形成下一個動作間隔的新狀態,新狀態被評估實時獎勵。實時獎勵和新狀態被傳遞到QL模型。計算從執行動作到該特定狀態的Q值,而CB通過使用QL計算的Q值來更新其策略參數。CB根據更新的Q值和新狀態計算下一個動作,同時QL模型更新自身權重。CBQL-TSP的框架如圖5所示。
其中CBQL-TSP采用時序差分誤差TDerror來調節狀態轉移概率。不同于傳統Q-learning,CBQL算法中的動作選擇取決于邊緣貢獻,而非直接使用Q值函數。TD誤差評估預期值與實際值之間的差異。采用TD誤差來調整狀態轉移概率增強智能體與環境的適應能力。盡管動作選擇取決于邊緣貢獻,但Q值函數仍然通過其更新過程來輔助算法的學習過程。Q值函數的更新基于智能體與環境的交互,反映了智能體對狀態-動作對的價值估計。CBQL算法綜合了邊緣貢獻和Q值函數信息,以優化智能體學習過程和策略改進。其中TD誤差公式為
TDerror=Et+γmaxa′Qt(st+1,at+1)-Qt(st,at)(16)
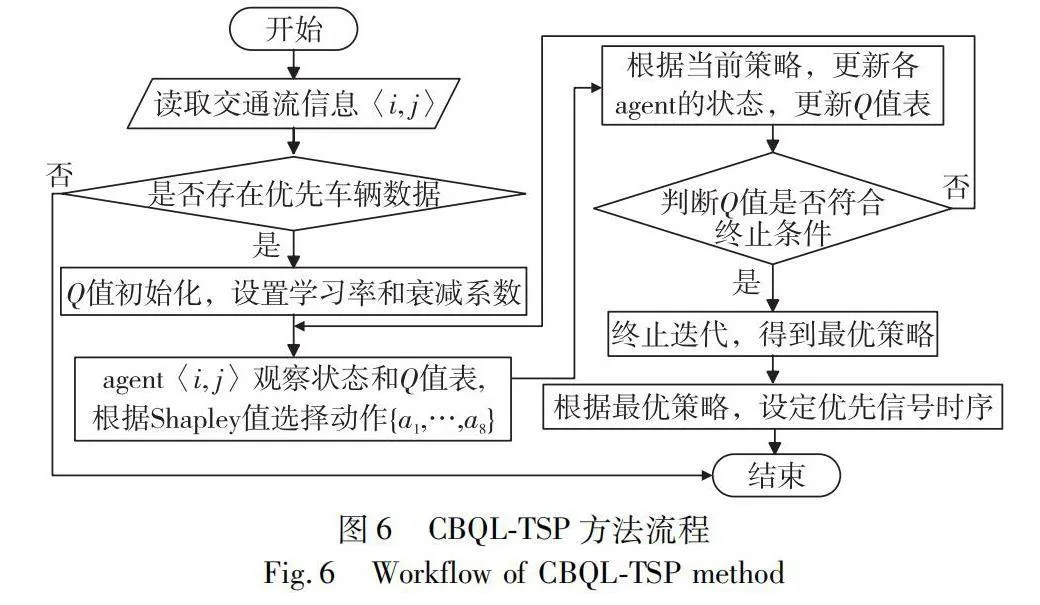
CBQL-TSP提供了一個基本的理論和結構,用于解決交通信號控制的優化問題。圖6描述了CBQL-TSP從初始化到最終決策的過程。
4 仿真和測試
為了測試本文提出的聯合控制策略的效果,進行實驗驗證及面向城市區域交通環境的應用驗證。實驗采用擁有Python 接口的微觀交通仿真軟件PARAMICS 創建一個包含公交專用道的交叉口的路網模型來定義研究區域。
4.1 仿真平臺構建
大連市高新區擁有兩條優先車輛專用車道,經過調查該道路在高峰期車流量足夠大,適宜作為實驗對象。首先將車道的相關地圖信息轉換成OpenStreetMap 格式,包括每個路段的屬性,如限速、交通量和車道數等。然后通過PARAMICS 的外部地圖導入功能部署到模擬設置中。
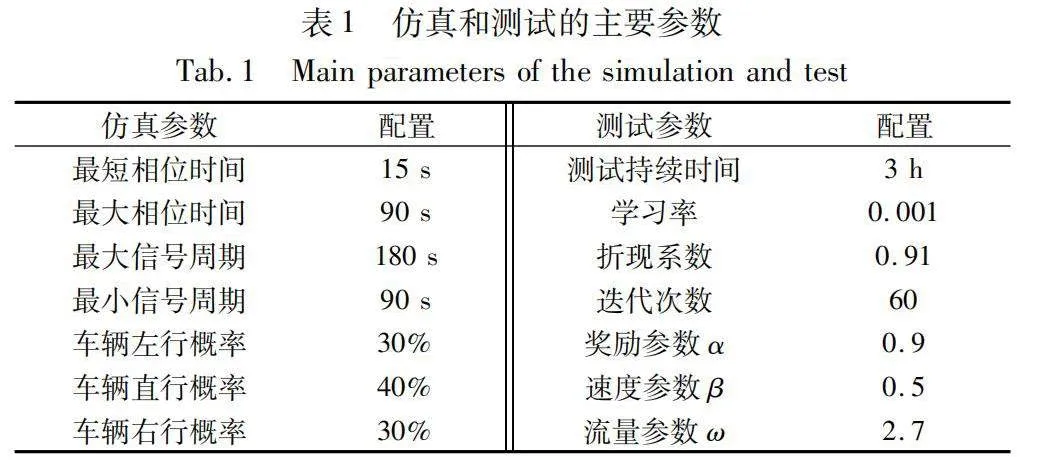
如圖7所示,為了建立一個包含五個協調交叉口的測試通道,首先收集了大連市10路公交車在這些交叉口運行時的交通流量數據。然后對這些數據進行預處理,以滿足PARAMICS仿真軟件的格式要求。這包括對數據進行整理,使其包括車輛位置、速度、方向和其他相關參數等關鍵信息,詳細參數設置如表1所示。
數據準備完畢后,將按照PARAMICS的輸入規格進行格式化。這確保了與模擬軟件的兼容性,以便進一步分析。格式化后的數據文件通過PARAMICS軟件提供的數據導入工具無縫部署到PARAMICS中。
在 PARAMICS 環境中,沿指定通道配置了五個交叉口。這些交叉口被設置為協調交叉口,允許同步交通信號控制和穿越通道的車輛之間的互動。所有交叉口的道路都有兩條直行車道和一條專用左轉車道。總體交通量處于中等擁堵水平,2和3號交叉口接近飽和,整體效果如圖8所示。
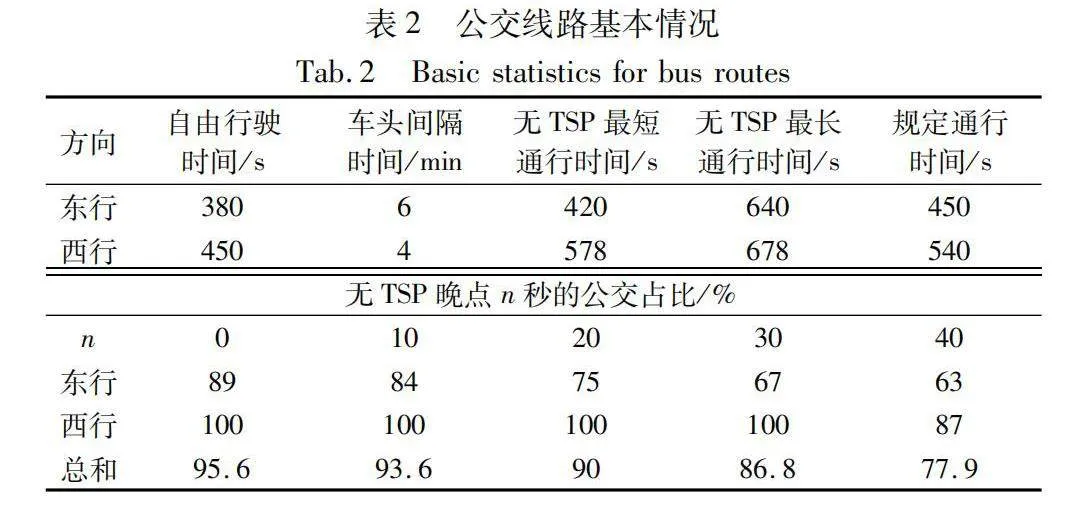
在測試通道上設置了兩條公交專用線路,一條向東,一條向西。在模擬中,所有公交車的最大速度都設置為50 km/h,比私家車慢約10 km/h。兩條巴士路線的首站和末站均被視為主要站點,其預定發車時間是已知的。公交線路的基本情況如表2所示。其中自由行駛時間指在沒有交通擁堵或其他干擾情況下,車輛在道路上自由行駛所需的時間。最后一列表示沒有使用交通信號優先(TSP)情況下晚點0~40 s的公交占總公交車數量的比例。
最后驗證網絡模型,以確保它準確地代表道路網絡和信號控制要求。通過以上步驟,實驗在PARAMICS 上部署了需要信號控制并具有優先道路的交叉口網絡模型,作為本文的優先信號控制的研究平臺。后續實驗將分析不同情況,并評估各種控制策略在優化通道性能方面的有效性。
4.2 對比算法
實驗選擇了三種近期效果較好的TSP控制方法作為對比算法。a)基于微觀模擬的TSP算法(簡稱MB-TSP)[7],屬于被動式TSP;b)基于最大壓力控制算法的主動式TSP(簡稱MP-TSP)[25];c)考慮公交信號優先的自適應信號控制(簡稱ASC-TSP),屬于自適應TSP[27]。值得注意的是,本文只對內置公交專用道的道路給予公交信號優先權,而當BRT線路上沒有公交專用道時,本仿真中的任何信號控制器都將無法實現公交信號優先。在此模擬中,網絡中的公交專用道沒有沖突的運動,對于本文中的所有交通信號控制策略,公交信號優先策略是相同的。
4.3 穩定性對比
首先,對于穩定性的定義:如果網絡中私家車的數量能保持一個有界的期望,那么就認為該網絡是穩定的。也就存在一個slt;∞,滿足
limT→∞sup{1T∑Tt=1 ∑(i , j)∈A2?{xPij(t)}}≤s(17)
在此基礎上,研究測試網絡中的私家車總數是否隨著時間的推移而增加,在不同的私家車需求水平設置下,公交車發車間隔為30 min。當私家車需求量在穩定區域內時,私家車平均保有量將收斂于一個常數。對于不穩定的需求,私人車輛的平均數量將增加到任意大的數量。
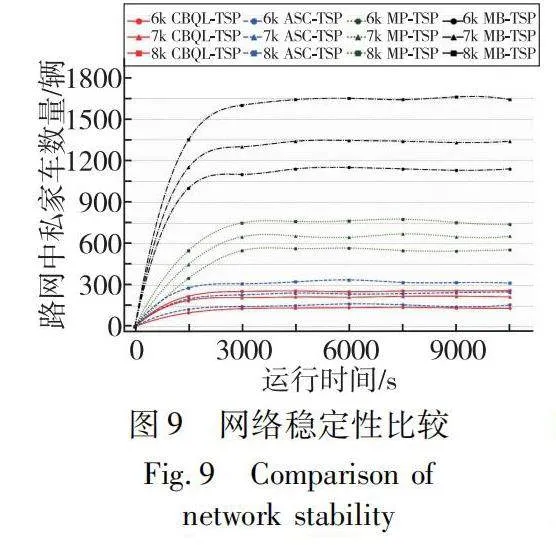
圖9比較了MP-TSP、MB-TSP、ASC-TSP 和CBQL-TSP 的平均等待私家車數的結果。在相同的私家車需求量設置下,CBQL-TSP 的私家車等待數均小于MP-TSP、MB-TSP、ASC-TSP 的實驗結果。此外,當私家車總數從6k增加到8k時,四種方法的平均等待私家車數都有所增加,相比于MB-TSP 和ASC-TSP、MP-TSP 和CBQL-TSP 均有更好的穩定區域,而CBQL-TSP 則具有更低的等待私家車數量。這些結果表明,CBQL-TSP比MP-TSP、MB-TSP、ASC-TSP 具有更大的穩定區域,并且能夠在更高的私家車需求量下保持網絡的穩定。
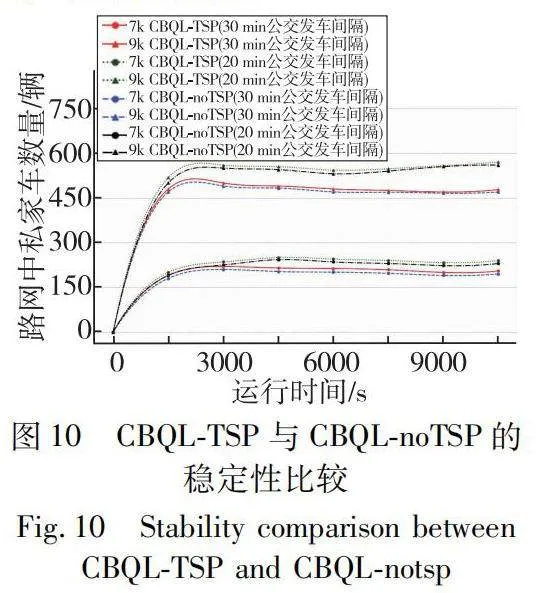
信號優先策略是否對交叉口的穩定區域產生影響是一項必要的研究。在不同的私家車需求量設置下(7k和9k需求量)進行了對比分析,涉及經典相位下CBQL 信號控制(CBQL-noTSP)以及在不同發車間隔(20 min和30 min)下采用八相位信號TSP 方法控制的情況(CBQL-TSP)。如圖10所示,本文通過對各種條件下私家車在網絡中平均等待量的研究,發現在相同的需求設置下,采用CBQL-noTSP策略時,等待私家車的數量最少。產生這種結果是可預見的,因為如果在交叉口設置公交優先信號控制,勢必會減少私家車的通行權。
當公交車的發車頻率增加(即發車間隔縮短),采用CBQL-TSP 策略時等待私家車的數量增加。這個結果是合理的,因為隨著公交需求的增加,給予公交車優先通行的時間也相應增多。與此同時本文發現當需求量從7k增加到9k時,無論是CBQL-noTSP 還是CBQL-TSP 在網絡中等待的私家車數量都增加了約300輛。相同條件下,當信號優先策略從CBQL-noTSP 改變成CBQL-TSP 時,在網絡中增加的私家車等待數量都保持一個穩定的數值,大約是10輛。這說明了在不同需求水平下本文算法對于私家車等待數量的影響較小且穩定。
4.4 通行時間對比
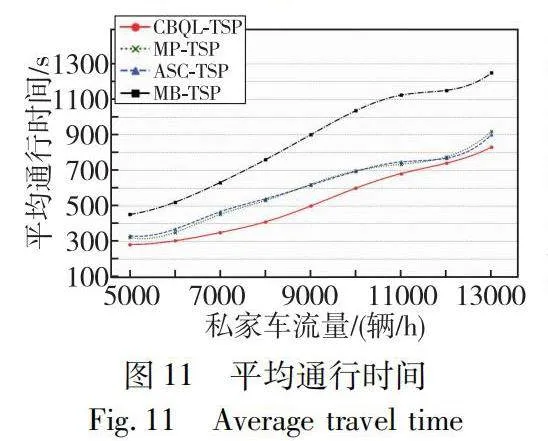
除了穩定性的對比,探究公交信號優先是如何影響網絡層面的車輛行程時間也是必要的。在30 min 公交車發車間隔時間的情況下,CBQL-TSP、ASC-TSP、MP-TSP 和MB-TSP 的公交車平均通行時間如圖11所示。隨著私家車需求量的不斷增加,車輛在路段和交叉口上花費的時間也越來越多,車輛在路段和交叉口上的通行時間也逐漸增加,這是可以預見的。在私家車需求量從5 000 輛/h逐漸增加至13 000 輛/h的過程中,分析公交車通過測試通道的通行時間。初始階段隨著私家車數量的增加,公交車的通行時間也增加,這是由于交通擁堵導致的。然而,當私家車需求量達到一定程度(例如11 000 輛/h)時,公交車的通行時間不再隨私家車數量的增加而增加,這表明采取的多種方法有效地緩解了交通擁堵。然而,當私家車的需求量繼續增加并達到更高水平(例如13 000 輛/h),交通擁堵可能會進一步加劇,導致公交車的通行時間再次增加。
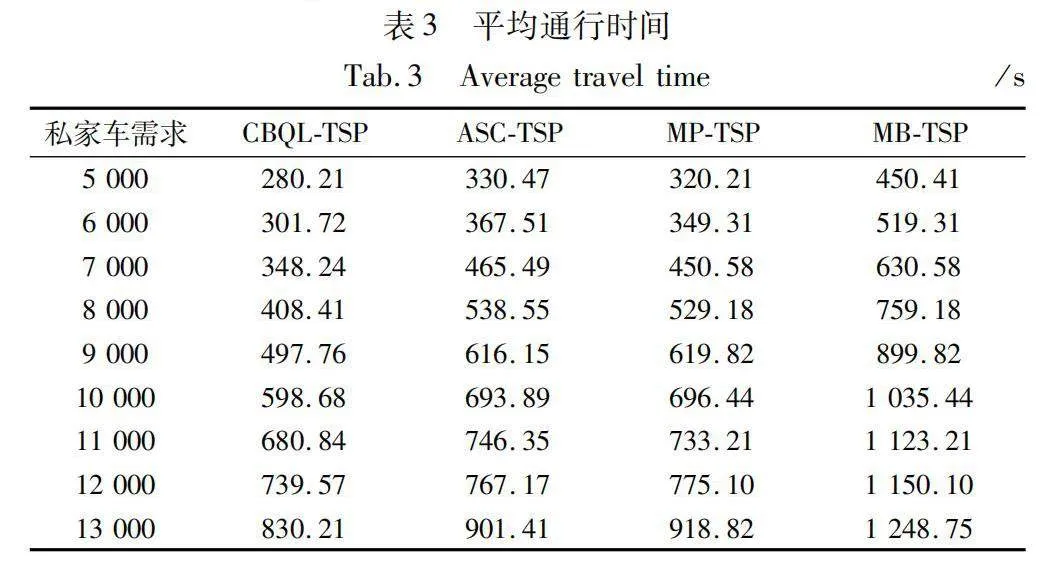
其中MB-TSP 的平均通行時間最長,MP-TSP和ASC-TSP的效果在不同私家車需求量的情況下表現各有優勢。本文算法在任何需求量的情況下對比其他三種算法都有更短的平均公交通行時間,尤其當私家車需求量在7k至10k的時候效果更為明顯。
為了更好地進行比較,研究將實驗結果匯總在表3中。MB-TSP,MP-TSP和ASC-TSP的平均通行時間分別為868.53 s、599.19 s以及603.00 s。CBQL-TSP的平均通行時間約為520.63 s,對比其他算法在平均通行時間上減少了約24.57%。
在公交車實施聯合決策控制和公交信號優先的情況下,測試其在干道的行程時間波動。實驗比較在一個固定的時間段內,不考慮信號優先的最大壓力控制(簡稱為MP-noTSP)、ASC-TSP、MP-TSP、MB-TSP、CBQL-noTSP 和CBQL-TSP 六種算法下公交車通過5個交叉口的平均通行時間。私家車需求量設置從6 000 輛/h逐漸增加到13 000 輛/h。
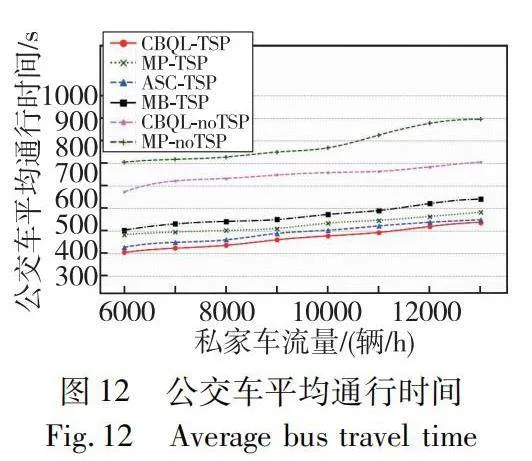
公交車平均通行時間的實驗結果如圖12所示。隨著私家車的需求量增加,五種公交信號控制方法的公交車在測試干道的平均行程時間都不斷增加。MP-noTSP下公交車平均通行時間最高,相比之下CBQL-noTSP可以降低一些中心城區公交車平均行程時間,但不是最優的。
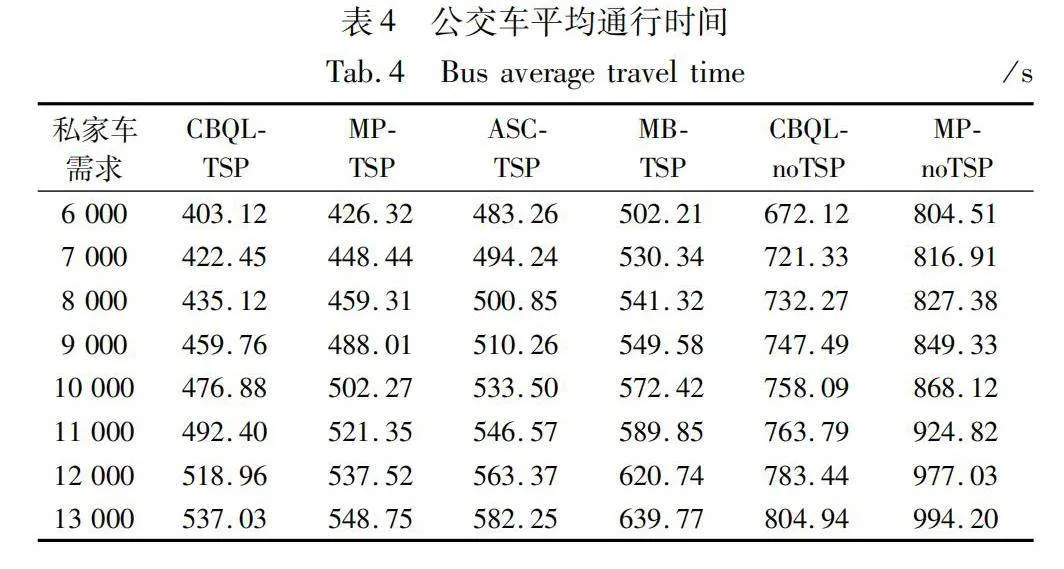
沒有公交信號優先(FT-noTSP和CBQL-noTSP)時公交車在市中心區的平均行程時間均大于公交信號優先的交通信號控制方法(MB-TSP、ASC-TSP 和CBQL-TSP)下的公交車行程時間。與MB-TSP、FT-noTSP 和MP-noTSP相比,ASC-TSP 基于更多的循環檢測器,所以它的效果是第二好的。最后,研究發現當兩個公交車發車間隔設置為30 min的情況下,CBQL-TSP 下公交車在市中心區的通行時間相對較少。表4是實驗結果的具體數據。
CBQL-TSP的市中心公交車平均通行時間約為468.22 s,而CBQL-noTSP的市中心公交車平均通行時間約為747.93 s,TSP使市中心公交車平均通行時間減少約37.40%。而MB-TSP、ASC-TSP和MB-TSP的市中心公交車平均通行時間分別為491.50 s、526.79 s和568.28 s,CBQL-TSP對比三種TSP在市中心公交車平均通行時間上減少約11.46%。
5 結束語
本文提出了一種八相位優先信號控制方法,將信號控制相序分為優先信號與非優信號進行研究。構建混合決策模型,研究優先信號與非優信號的合作博弈,通過求解夏普利值函數得到合作博弈各成員的夏普利值比例,根據夏普利值比例得到MDP狀態轉移概率。設計對比實驗,實驗結果表明提出方法在具有公交優先的路口具有更好的穩定性,并且整體平均通行時間對比其他TSP方法減少了約24.57%,公交平均通行時間對比無TSP方法減少約37.40%。本文實現了基于合作博弈和強化學習的公交信號優先策略,從邊際貢獻的角度平衡車輛優先權,通過對交叉口優先權的合理分配,提高了公共車輛在交叉口的通行效率,同時也保證了私家車輛的通行效率,使交叉口整體運行更加高效。本文方法不僅提升了交通系統的整體性能,還增強了城市交通的可持續性和公平性,為所有道路使用者創造更加平衡和高效的行駛環境。對于未來的研究方向,可以引入多級優先信號控制系統,尤其是對優先級進行內部分層方面,仍然有待提出進一步解決方案。可以考慮引入機器學習算法,根據優先車輛的交通行為模式和影響,對優先級進行細粒度控制,進一步優化優先信號控制方法。
參考文獻:
[1]Lahon D. Modeling transit signal priority and queue jumpers for BRT [J]. ITE Journal, 2011, 81(12): 20-24.
[2]Wang Jingwei, Han Yin, Li Peng. Integrated robust optimization of scheduling and signal timing for bus rapid transit[J]. Sustainability, 2022, 14(24): 16922.
[3]Sperry R. Urban traffic control and bus priority system[J]. Design And Installation, 1972, 1: 1-22.
[4]Zhang Tong, Mao Baohua, Xu Qi, et al. Timetable optimization for a two-way tram line with an active signal priority strategy[J]. IEEE Access, 2019, 7: 176896-176911.
[5]Liu Minglei, Zhang Huizhen, Chen Youqing, et al. An adaptive ti-ming mechanism for urban traffic pre-signal based on hybrid exploration strategy to improve double deep Q network[J]. Complex amp; Intelligent Systems, 2023, 9(2): 2129-2145.
[6]Li Jiajie, Bai Yun, Chen Yao, et al. A two-stage stochastic optimization model for integrated tram timetable and speed control with uncertain dwell times[J]. Energy, 2022, 260: 125059.
[7]Ni Yingchuan, Lo Hsienhao, Hsu Yuting, et al. Exploring the effects of passive transit signal priority design on bus rapid transit operation: a microsimulation-based optimization approach[J]. Transportation Letters, 2022, 14(1): 14-27.
[8]Gu Weihua, Mei Yu, Chen Haoyu, et al. An integrated intersection design for promoting bus and car traffic[J]. Transportation Research Part C: Emerging Technologies, 2021, 128: 103211.
[9]Cvijovic Z, Zlatkovic M, Stevanovic A. Multi-level conditional transit signal priority in connected vehicle environments[J]. Journal of Road and Traffic Engineering, 2021, 67(2): 1-12.
[10]Truong L T, Currie G, Wallace M, et al. Coordinated transit signal priority model considering stochastic bus arrival time[J]. IEEE Trans on Intelligent Transportation Systems, 2019, 20(4): 1269-1277.
[11]Xu Mingtao, An Kun, Ye Zhirui, et al. A bi-level model to resolve conflicting transit priority requests at urban arterials[J]. IEEE Trans on Intelligent Transportation Systems, 2019, 20(4): 1353-1364.
[12]Zeng Xiaosi, Zhang Yunlong, Jiao Jian, et al. Route-based transit signal priority using connected vehicle technology to promote bus schedule adherence[J]. IEEE Trans on Intelligent Transportation Systems, 2021, 22(2): 1174-1184.
[13]Seredynski M, Laskaris G, Viti F. Analysis of cooperative bus priority at traffic signals[J]. IEEE Trans on Intelligent Transportation Systems, 2020, 21(5): 1929-1940.
[14]Zhao Xuanming, Mo Hong, Yan Kefu, et al. Type-2 fuzzy control for driving state and behavioral decisions of unmanned vehicle[J]. IEEE/CAA Journal of Automatica Sinica, 2019, 7(1): 178-186.
[15]Fournier N. Hybrid pedestrian and transit priority zoning policies in an urban street network: evaluating network traffic flow impacts with analytical approximation[J]. Transportation Research Part A: Policy and Practice, 2021, 152: 254-274.
[16]Zhang Changlong, Yang Xiaodong, Wei Jimin, et al. Cooperative transit signal priority considering bus stops under adaptive signal control[J]. IEEE Access, 2023, 11: 66808-66817.
[17]Ma Dongfang, Zhou Bin, Song Xiang, et al. A deep reinforcement learning approach to traffic signal control with temporal traffic pattern mining[J]. IEEE Trans on Intelligent Transportation Systems, 2022, 23(8): 11789-11800.
[18]翟子洋, 郝茹茹, 董世浩. 大規模智慧交通信號控制中的強化學習和深度強化學習方法綜述[J]. 計算機應用研究, 2024, 41(6): 1618-1627. (Zhai Ziyang, Hao Ruru, Dong Shihao. Review of reinforcement learning and deep reinforcement learning methods in large-scale intelligent traffic signal control[J]. Application Research of Computers, 2024, 41(6): 1618-1627.)
[19]Li Hui, Li Shuxin, Zhang Xu. Coordination optimization of real-time signal priority of self-driving buses at arterial intersections considering private vehicles[J]. Applied Sciences, 2023, 13(19): 10803.
[20]Kolat M, K?vári B, Bécsi T, et al. Multi-agent reinforcement lear-ning for traffic signal control: a cooperative approach[J]. Sustainability, 2023, 15(4): 3479.
[21]Liang Xiaoyuan, Du Xunsheng, Wang Guiling, et al. A deep reinforcement learning network for traffic light cycle control[J]. IEEE Trans on Vehicular Technology, 2019, 68(2): 1243-1253.
[22]Qin Ziye, Ji Ang, Sun Zhanbo, et al. Game theoretic application to intersection management: a literature review[EB/OL]. (2023-11-21). https://arxiv.org/abs/2311.12341.
[23]Abdoos M. A cooperative multiagent system for traffic signal control using game theory and reinforcement learning[J]. IEEE Intelligent Transportation Systems Magazine, 2021, 13(4): 6-16.
[24]Islam T, Vu H L, Hoang N H, et al. A linear bus rapid transit with transit signal priority formulation[J]. Transportation Research Part E: Logistics and Transportation Review, 2018, 114: 163-184.
[25]Xu Te, Barman S, Levin M W, et al. Integrating public transit signal priority into max-pressure signal control: methodology and simulation study on a downtown network[J]. Transportation Research Part C: Emerging Technologies, 2022, 138: 103614.
[26]Varaiya P. Max pressure control of a network of signalized intersections[J]. Transportation Research Part C: Emerging Techno-logies, 2013, 36: 177-195.
[27]Zhang Xinshao, He Zhaocheng, Zhu Yiting, et al. DRL-based adaptive signal control for bus priority service under connected vehicle environment[J]. Transportmetrica B: Transport Dynamics, 2023, 11: 1455-1477.
