標準數字化平臺技術路徑研究
2024-12-31 00:00:00顧鑫徐術坤張晨鳴劉穎顧利平涂俊李響
中國標準化 2024年19期
摘 要:隨著數字技術和信息技術的迅速發展,標準數字化平臺逐漸成為標準化領域的重要工具。本文根據ISO的SMART標準數字化成熟度劃分方法,探索level 3-4的標準數字化平臺技術實現路徑,重點介紹了標準大模型實現知識圖譜、智能問答功能的實現方法,為后續研究提供了基礎。
關鍵詞: 標準數字化,成熟度模型,知識圖譜
DOI編碼:10.3969/j.issn.1002-5944.2024.19.008
0 引 言
近年來,數字技術和信息技術的迅速發展,標準數字化平臺逐漸成為標準化領域的重要工具。標準數字化平臺是一種將標準文獻、標準規范、標準數據等標準化資源進行數字化、網絡化、智能化管理的技術平臺,旨在提高標準的制定、實施和管理效率,促進國家質量基礎設施的數字化轉型[1],標準數字化平臺建設對數字中國發展有著重要的戰略意義。《國家標準化發展綱要》《質量強國建設綱要》等頂層規劃文件中,均提出要發展新型標準化工具,探索建立全國統一協調、分工負責的標準數字化公共服務平臺,為各方廣泛參與標準化工作提供有效途徑。
1 標準數字化平臺現狀
國外標準數字化平臺的發展可以追溯到20世紀90年代。美國國家標準局(ANSI)于1993年建立了數字圖書館,旨在將國家標準轉化為數字格式,并免費向公眾提供。此后,許多國家和標準化組織也開始意識到標準數字化的重要性,并開始建立自己的標準數字化平臺[2]。目前,國際標準化組織(ISO)和歐洲標準化協會(ESA)已經建立了自己的標準數字化平臺,分別為ISOReference Platform(ISO-RF)和ESA-RF。ISO-RF是一個開放的平臺,旨在為全球標準化組織提供標準文獻、標準規范、標準數據等的數字化服務。ESA-RF是一個專門為歐洲標準化組織服務的平臺,提供標準文獻、標準規范、標準數據等的在線檢索、下載、管理等服務。除了國際標準化組織之外,許多國家和標準化組織也建立了自己的標準數字化平臺。例如,中國國家標準化管理委員會(SAC)建立了國家標準數字圖書館,提供了國家標準文獻、標準規范、標準數據等的數字化服務。此外,日本、韓國、澳大利亞、加拿大等國家和標準化組織也建立了自己的標準數字化平臺。
國內標準數字化平臺的發展相對較晚,但發展速度較快。2000年,中國國家標準化管理委員會(SAC)建立了國家標準文獻數據庫,提供國家標準文獻的數字化服務。此后,國內標準化組織也陸續建立了自己的標準數字化平臺。目前,國內已經建立了多個標準數字化平臺[3],例如,中國標準化協會(CAS)建立的中國標準數字圖書館、中國標準化研究院(CNIS)建立的中國標準文獻信息平臺、中國電子信息產業發展研究院(CESI)建立的中國標準信息服務平臺等。這些平臺提供標準文獻、標準規范、標準數據等的數字化服務,并具有檢索、下載、管理等功能。
2 發展與挑戰
國內外標準化組織都積極建立自己的標準數字化平臺,為標準化文獻、標準規范、標準數據等的數字化服務提供支持。但標準數字化是一個長期而復雜的任務。隨著數據量的不斷增長,標準的數據要素構成涵蓋越來越多,標準數字化面臨著越來越大的挑戰[4]。一是數字標準化中的重點技術是機器可讀,需要規范地描述數據結構和內容格式,但目前各行業機器可讀標準還沒有統一的定義和分類,這導致了標準數字化難以實現。二是標準數字化要廣泛應用,還需結合多個領域,如法律、技術和業務,這使得標準數字化的研究變得更加困難。三是標準數字化除了可讀外,還需要正確被機器理解,能根據復雜場景輸出可用的結構化文本信息,結合智能AI模型進行應用研究,復雜性地對較高,需要投入大量的人力、物力和財力,這使得許多組織望而卻步。
因此,如何建立一個高效、豐富、全面的標準數字化平臺就成了助力標準化高質量發展、助推新質生產力的關鍵問題。
3 標準數字化成熟度模型
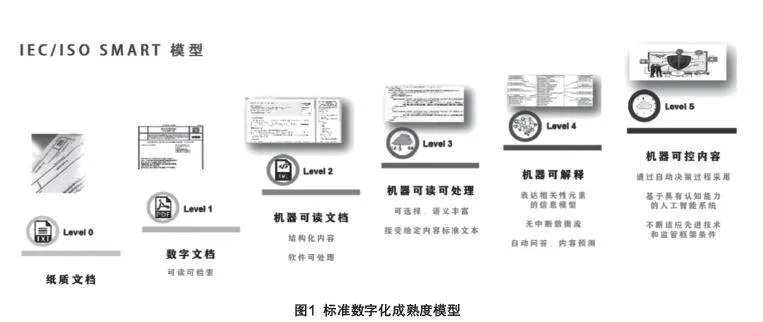
如何實現標準的機器可讀是實現標準數字化平臺的關鍵問題。一般來講,研究機器可讀離不開分級模型,可利用計算機技術和人工智能技術,為機器可讀標準提供分類和分級的框架。在標準領域,針對標準的特殊性,ISO的SMART標準提供了一種標準數字化成熟度級別劃分,它將機器可讀融入到標準數字化技術各個階段,體現了標準數字化和標準的機器互操作性的關聯關系,基本為未來標準機器可讀制定了明確的技術路線圖,也是標準數字化發展路線的重要依據,如圖1所示。
標準數字化成熟度分級中,level_0表示傳統的紙質標準,沒有和機器相交互。level_1表示電子化的文檔,可以在計算機上展示內容,比如我們現在常用的pdf版的電子標準。Level_2表示機器可讀文檔,這些文檔內容經過數據處理加工,成為結構化的信息文本;這兩級標準代表著標準可以實現形式信息化和基本字符的定位,目前來說,2級水平也是國際標準和部分先進國家標準普遍能達到的級別。Level_3表示機器可讀和可執行內容。這個級別重點突出了信息元素之間的關聯關系,可以實現多目標關聯,根據不同需求對跨文檔的內容進行加工處理。Level_4表示機器可解釋內容,能學習分析和自動驗證,實現智能推送,問題回答等功能;這兩級主要側重標準語料的含義分析,以及相關聯信息知識的獲取與學習,比如,DIN基于自身的產業實踐探索,按照XML多標簽的方式,將已有標準構建成“機器可讀”的程度,達到了3-4級。Level_5表示機器可控內容,實現在數字標準方面具有認知能力的人工智能系統,可以根據標準內容的修訂,自動決策過程采用。Level_5級屬于遠期的目標,目前處于理論探索階段。這0到5級成熟度模型中,機器對于信息數據分類細化和智能化要求逐步提高。因國內標準機構發展水平不均,總體數字化水平還處于1-2級標準,投入力度大的平臺,如國家標準館、中國標網、中國知網等已在專業領域開展3-4級標準數字化的探索。
4 標準數字化平臺建設技術路徑
標準數字化平臺實現關鍵在于底層標準數據的處理和知識庫的建立。已有研究表明,數據處理技術路徑可以為:數字化、結構化、知識化、網絡化、圖譜化[5]。其本質是在明確標準數據的完整性、準確性、關聯性、可讀性的基礎上,實現標準數據的知識化、協同化、交互化、智能化等要求。
本研究簡化了數據知識庫的獲取方式,采用json格式作為基礎,通過信息采集、數據清洗、圖譜生成三個數據處理過程,外加使用采用自回歸空白填充的自監督訓練方式,實現從電子化文檔到知識庫的轉化。信息化時代的標準文本加工,已經讓大部分紙質標準轉化成了pdf電子檔,所以本研究在采集過程中,主要針對還未經過ORC識別標準電子文本,將符合要求的標準電子版標準作為信息采集過程的輸入,采集過程解決標準文本的信息化和結構化問題。數據清洗過程針對信息采集過程的輸出,利用規則將標準數據進行加工并整合打上標簽,形成json條目的干凈數據,完成標準數據知識化和關系立體化。圖譜生成過程主要將形成的語料進行關聯性分析,構建知識庫,完成標準數據圖譜化。最后利用自回歸空白填充模型的自監督訓練方式搭建標準大模型,用于支撐標準智能化中對比分析、智能填寫、智能問答等標準數字化平臺功能。下文將針對部分內容進行重點說明。
4.1 標準數據清洗加工
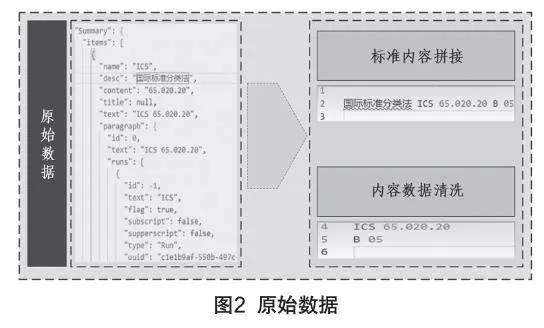
本研究中數據清洗主要是對OCR處理后的數據進行篩選、轉換、合并、去重的過程,此過程可以消除數據中的錯誤、缺失、重復、異常等問題。數據清洗主要根據篩選規則,利用Pandas工具,將問題數據去除,實現對ORC后標準數據的重新檢查和校驗,提高數據質量。基于傳統技術文檔的電子版標準多通過圖片或pdf文檔轉換而來,內容存在大量不可讀標簽、文本等,其內容無法直接使用,該過程基本步驟為:數據收集、數據預處理、數據清洗、數據驗證。通過這幾步,可以將臟數據清洗為可用的原始數據。如圖2所示。
從圖中可見,在采集標準ICS和CCS碼信息時,數據采集端的輸入數據包含很多無用的標簽信息和非必要元素,目標信息被隔離分散。因此,經過數據清洗后,需要提取全部有效數據,然后通過規則將目標信息內容提取拼接。對于此類數據,常用的判斷規則可參考“國際標準分類法”中ICS與CCS的固定格式,判斷其內容的含義。經過類似清洗拼接過程,最終獲得有效的結構化數據,還可以通過規則定義,解析出其它有含義的信息,如:圖片、表格、指標項、公式等信息。
在此基礎上,對最終數據進行初步的標記分類,記錄在json文件中,形成可用的“語料”,為后期構建標準大模型提供有效輸入。利用json架構標識時,應考慮層次、要素的多對多關系,有了合理的架構設計,才能提高標識的效率。一是要明確目的,要確定結構化標準的分類方式,如基礎標準、管理標準、技術標準等,以此來明確標準內容所包含的內容要素。二是要根據不同分類的標準構成要素的關聯關系,形成可以覆蓋屬性、要素、特殊要求等關鍵信息,能夠反映標準內容的結構關系。三是要定義json標識,簡潔、明確,且相互之間確保唯一性,能快速識別。目前該過程初始標識需要手動完成,后續在數據使用中,可以利用訓練學習,對已有數據增加標識。
4.2 知識圖譜構建
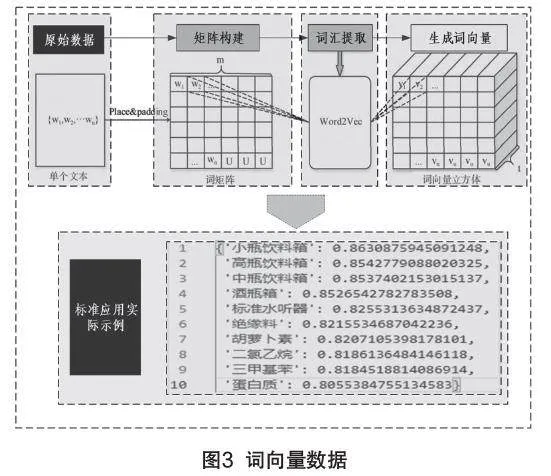
構建知識圖譜一直以來有較多學者研究,傳統的方法是將標準信息解構后,按照人員、單位、引用關系、系列文本、體系覆蓋等因素作為關聯關系,將眾多標準相關聯形成圖譜。而本研究主要支撐標準數字化平臺的智能問答功能,最終要形成一段語義豐富、內容準確的智能回復,因此采用簡單化神經網絡Word2Vec模型來構建語料間的知識圖譜。如圖3所示。
先通過模型標記數據集中語料分塊單詞,利用One-hot encoder將字詞轉化為單獨的離散符號,再將離散符號轉化為低維度的稠密向量,利用提取命令找出關鍵詞中關聯度最高的詞匯,形成詞向量。在構建圖譜關系時,還可將所有關聯的產品名稱作為獨立的產品庫合集,當用戶鍵入相關或類似的產品時,能快速地從中提取到關聯的指標項。
5 實驗結果對比
在實驗中,如輸入“蛋白質的指標有哪些?”的時候,得益于構建的詞庫,模型可快速地從用戶輸入內容中提取到“蛋白質”“指標”等有效的關鍵詞。通過對比某通用大模型對“蛋白質”相關指標的輸出,相同問題下,標準大模型的回答更為專業,并能根據需要展示更多相關的內容。如圖4所示。
6 結 語
本文根據ISO的SMART標準數字化成熟度劃分方法,探索level 3-4的標準數字化技術實現路徑,重點介紹了標準大模型實現知識圖譜、智能問答功能的實現方法。目前研究處于初始階段,后續將持續優化。
參考文獻
[1]劉彥林,甘克勤,馬小雯,等.標準數字化發展現狀與演進態勢[J].中國標準化,2024(3):49-53.
[2]馬超.標準數據形態變革視域下我國標準數字化轉型發展綜述[J].信息通信技術與政策,2024,50(2):74-81.
[3]袁文靜,方洛凡.標準對話:標準數字化的階段性目標與實踐[J].中國標準化,2024(3):6-29.
[4]張偉.標準數字化現狀分析及發展建議[J ] .大眾標準化,2024(7):1-3.
[5]狄矢聰.標準數字化平臺建設機制與發展路徑研究[J].標準科學,2024(1):64-71.
作者簡介
顧鑫,通信作者,博士,標準化高級工程師,國家軟件與系統工程分技術委員會(SAC/TC 28/SC 27)專家委員,主要研究領域為數字標準化、全域標準化、綜合標準化、信息安全、大數據挖掘等。
(責任編輯:張佩玉)
基金項目:本文受國家市場監督管理總局科技研發計劃“標準數字化轉型創新應用研究”(項目編號:2022MK088)資助。
