
基于YOLOv5的高后果區智能識別研究
2025-01-18 00:00:00王彥青尚嘉年劉新劉建沖
科技創新與應用 2025年1期








摘" 要:針對目前長輸管道高后果區識別效率低,需耗費大量的人力、物力和時間成本,該文借助目標檢測算法YOLOv5s,利用遙感影像及無人機航飛影像數據,結合高后果區識別規范,對不同類型的高后果區建立高后果區智能識別模型,通過評估,模型準確率和召回率均達到90%以上,能有效識別高后果區。又以國內某管道高后果區為例,進一步驗證模型的有效性,數據表明,該模型智能識別出的高后果區信息與傳統人工輔助識別信息一致,能滿足長輸管道高后果區自動識別的實際需求,為高后果區風險管理提供及時準確的數據支持,為高后果區識別的自動化、智能化管理開拓新思路。
關鍵詞:長輸管道;高后果區;YOLOv5s;目標檢測;智能識別模型
中圖分類號:TE973" " " 文獻標志碼:A" " " " " 文章編號:2095-2945(2025)01-0110-06
Abstract: In view of the current low efficiency of identifying high-consequence areas in long-distance pipelines, which requires a lot of manpower, material resources and time costs, this paper uses the target detection algorithm YOLOv5s, uses remote sensing images and drone flight image data, and combines high-consequence area identification specifications. Intelligent identification models for high-consequence areas are established for different types of high-consequence areas. Through evaluation, the model accuracy and recall rate have reached more than 90%, which can effectively identify high-consequence areas. Taking a high-consequence area of a domestic pipeline as an example to further verify the effectiveness of the model. The data shows that the information of the high-consequence area intelligently identified by the model is consistent with the traditional manual auxiliary identification information, and can meet the actual needs of automatic identification of high-consequence areas of long-distance pipelines. The actual needs provide timely and accurate data support for risk management of high-consequence areas, and open up new ideas for automated and intelligent management of high-consequence area identification.
Keywords: long-distance pipeline; high-consequence area; YOLOv5s; target detection; intelligent recognition model
GB 32167—2015《油氣輸送管道完整性管理規范》將“高后果區”明確定義為“管道泄漏后可能對公眾和環境造成較大不良影響的區域”,是指油氣管道發生泄漏失效后,可能造成嚴重人員傷亡或者嚴重環境破壞的區域[1]。管道高后果區作為油氣輸送管道安全管理的關鍵區域,一旦發生管道破裂或油氣泄漏,將對公共安全、環境和財產造成巨大影響和損失。隨著城市建設進程的加快,管道周邊的環境也在不斷發生變化,因此需要定期開展管道高后果區識別[2]。
目前,識別輸氣管道高后果區主要依靠遙感技術[3]、地理信息系統[4]、數據挖掘、機器學習[5]等方面的技術,并輔助人工勘察和經驗判斷,這些方法識別效率低、不滿足高后果區識別的實時性。隨著計算機視覺的迅猛發展,深度學習技術在圖像識別領域中迅速崛起,如何利用深度學習技術實現管道高后果區的智能識別成為一個很具有前景的研究領域。本文重點針對規范中的高后果區識別準則,結合地理信息系統及無人機航飛數據,利用YOLOv5改進算法實現高后果區AI智能識別,以期降低高后果區識別的人工成本,提高高后果區識別精度,提升管道完整性管理的工作效率。
1" 高后果區識別現狀
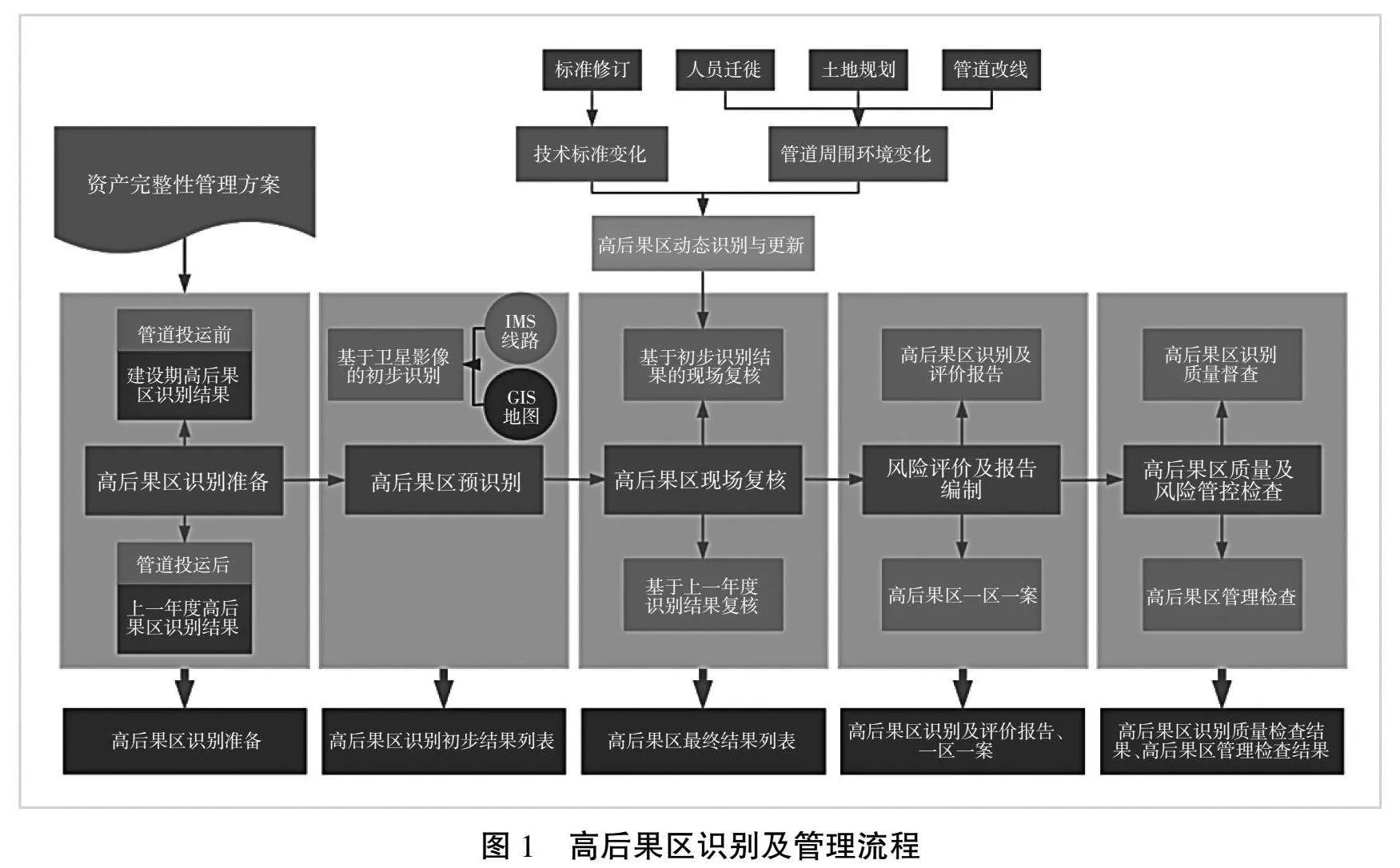
目前,輸油氣管道現場作業識別高后果區的主要方法仍是基于遙感影像的在線人機交互識別,完整的高后果區識別及管理流程如圖1所示。
高后果區識別準備:結合上一年度高后果區識別結果及技術標準變化情況,為后續高后果區識別做好準備工作。
高后果區預識別:基于IMS數字管道地圖工具根據前期采集的管道中心線、站場、閥室和管道樁數據,疊加GIS高清影像圖對管道沿線的地物環境信息進行排查,在潛在影響區域內初步圈定人員密集、環境敏感區域、隱蔽場所等重點目標,并形成初步識別列表,作為現場復核的主要識別內容。
高后果區現場復核:現場復核主要采用現場調查、走訪的方式進一步核實人員分布、規模及周邊環境情況,并采用現場定位、埋深測量等方式,進一步確定高后果區區間,并進一步完善高后果區識別信息,為后續的風險評估和管控措施的制定提供更加準確的依據。
風險評價及報告編制:按照國家管網高后果區識別與評價報告編制要求及一區一案報告編制要求,結合高后果區所屬管道基礎信息、高后果區識別結果、數據對齊后的內檢測、外檢測、陰極保護測試等相關信息自動生成報告,為高后果區的日常管理提供依據。
高后果區質量及風險管控檢查:基于國家管網體系文件要求,對高后果區信息填報質量進行全方位檢查,包括但不限于信息完整性、信息有效性、信息邏輯的一致性。針對高后果區評價發現的中高風險,及時建立風險與預防措施的關系,為高后果區的風險管控提供保障,確保風險管控的及時響應。
通過以上步驟可以看出,當前高后果區識別外業現場復核是必不可少的一步,而且人力、物力、時間成本均相對比較高。每年的高后果區風險評價及報告更新需要人工進行比對完善,工作量較大,時間效率相對較低。根據GB 32167—2015《油氣輸送管道完整性管理規范》、Q-GGW03001.2—2022《油氣儲運資產完整性管理規范 第2部分:管道線路》要求,目前高后果區識別均需要每年進行,鑒于此項工作的重要性及高頻性,研究高后果區智能識別模型勢在必行,以此提高工作效率,為管理提供更精準的數據支持。
2" 研究方法
隨著人工智能深度學習技術的發展,其在自動化、智能化產業上得到了廣泛的應用。通過使用深度學習算法,可以進行輸油氣管道高后果區的自動識別,提高識別的精度和效率,為實現高后果區的自動識別提供技術支持。YOLO系列算法作為當前主流的深度學習目標檢測算法之一,在識別小目標圖像上已被證明具有較高的準確性與可靠性。其中,YOLOv5算法運算速度快、精度高、模型小,在嵌入式設備上的應用前景非常廣泛[6]。
2.1" YOLO算法概述
2015年,Redmon等[7]提出了YOLO目標檢測算法,YOLO的核心是將目標檢測問題變成一個回歸問題,將整張圖片作為輸入,僅通過一個卷積神經網絡就能得到目標的邊界和類別,檢測速度大幅提升[8]。2017年,YOLO的研發者Redmon提出了YOLOv2[9],YOLOv2提出了聯合訓練方法,兼顧了識別速度和識別的準確率,識別對象的種類也多達9 000種[8]。2018年YOLOv3[10]橫空出世。YOLOv3是在YOLOv2的基礎上又進行了一系列的改進,利用特征金字塔網絡結構實現了多尺度檢測,并且在分類方法上使用了邏輯回歸,在保障了檢測的準確性上兼顧了實時性[11]。YOLOv4[12]算法是2020年4月23日提出的,在特征提取上采用CSPDarknet53網絡,同時應用SPP模塊增強特征表達能力,其精度與速度的平衡性在當前目標識別領域為最佳[13]。YOLOv5于2020年6月10日發布,與之前的YOLO算法對比,YOLOv5在速度、精度、可部署性等方面有非常大的提升[11]。
YOLOv5網絡的主要原理是通過卷積神經網絡實現對輸入的圖像進行特征提取和處理,進而計算出目標的位置和類別。YOLOv5系列共有5個模型,網絡結構均一樣,區別在于每個模型的寬度、深度以及參數量略有差別,綜合精度、速度及參數量考量,本文選擇YOLOv5s作為本次研究的模型算法。
2.2" 基于YOLOv5的高后果區識別模型建立
基于YOLOv5的高后果區識別模型建立流程如下:首先,針對不同的高后果區類型,收集不同類別的數據集,同時使用旋轉、平移、縮放等技術對數據集進行增廣,再利用Labelimg軟件對數據集進行標注,構建不同種類的高后果區智能識別樣本庫。其次,采用YOLOv5s算法構建不同類型的高后果區智能識別模型,將不同種類的樣本庫按照訓練集和驗證集8∶2進行劃分,采用訓練集對相應的模型進行訓練,尋找智能識別模型的最優參數。最后,采用驗證集對訓練好的模型進行驗證,使用評價指標精確率和召回率對模型識別效果進行評估。
2.2.1" 數據集
本文數據集主要指高后果區圖像形式的數據,用來訓練和測試高后果區智能識別模型。高后果區識別類型包含人員密集型、環境敏感型、交通設施型和易燃易爆場所4類。相應地,需收集4類數據樣本集。本文的高后果區圖像數據來源于2個方面,自建數據庫和開源數據庫,數據圖像均是利用衛星及無人機航拍獲得。
樣本數量越多,訓練出來的模型效果越好,模型的泛化能力越強。因此為提高高后果區智能識別模型的魯棒性和識別能力,本文對采集到的高后果區圖像進行了旋轉、平移、縮放等操作以達到數據集增廣的效果。然后采用Labelimg軟件對數據集進行標注,根據不同的數據類型建立相應的智能識別樣本庫。
人員密集型樣本庫主要是指人口聚集、建筑物密集的區域,這些區域擁有豐富的人力資源和經濟活動,但同時也伴隨著巨大的風險。在本次高后果區智能識別模型中主要是通過對管道周邊建筑物的識別,進一步估算人口密度;交通設施型樣本庫是指交通密集、交通網絡復雜的區域,這些區域主要包括公路、鐵路、車站和碼頭等;環境敏感型樣本庫主要是指油氣泄漏易對周邊環境造成污染的區域,這些區域擁有豐富的自然資源,主要包括河流、大型水域、自然保護區等;易燃易爆場所樣本庫主要是指管道兩側各200 m內有加油站、油庫、煤氣站庫房、煙花車間、易燃粉塵的區域、化學品倉庫和燃料倉庫等,此類區域會對周圍人員及環境產生比較嚴重的毀壞。
本次模型基于3.7萬張衛片和2.2萬張航片,標注建筑物信息,構建了人員密集型樣本庫;基于1萬張衛片和1萬張航片,標注道路信息,構建了交通設施型樣本庫;基于1萬張衛片和1萬張航片,標注河流、水體等信息,構建了環境敏感型樣本庫;基于1萬張衛片和1萬張航片,標注加油站、加氣站等信息,構建了易燃易爆場所樣本庫。建立的不同種類樣本庫如圖2所示。
2.2.2" 模型建立
YOLOv5s作為高后果區智能識別模型建立的核心算法,其主要由輸入端、骨干網絡、頸部網絡和輸出端4部分組成[14]。
1)輸入端(Input)。輸入端主要包括Mosaic數據增強、自適應錨框計算、自適應圖片縮放3部分內容。Mosaic數據增強主要是通過選取任意4張圖片進行翻轉、裁剪和縮放等操作,然后進行拼接構成新的圖片(主要增加數據多樣性、增強模型的魯棒性,加強歸一化效果、提升小目標檢測性能)。自適應錨框計算主要根據不同的訓練集自適應計算出目標的大致位置;自適應圖片縮放主要是將圖片統一縮放至尺寸為640×640,若圖片未達到模版則采用自適應黑邊來填充。
2)骨干網絡(Backbone)。骨干網絡中主要包括Focus、CSP、SPPF 3個模塊。Focus模塊主要對圖片進行切片操作,再通過拼接得到新的圖片,經過卷積操作后,最終得到了沒有信息丟失的二倍下采樣特征圖。CSP模塊主要使用的是C3_v1結構,是將輸入的特征分成2個分支,一個分支先通過CBS結構,即(Conv(卷積)+BN(批量歸一化)+SiLU(激活函數)),再通過多個Bottleneck殘差結構,再進行一次卷積;另一個分支直接進行卷積,然后2個分支進行Concat實現拼接完成特征層的映射操作,最后再通過一個CBS結構即可得到最終的特征圖。SPPF模塊的主要功能是通過融合局部和全局的特征來增大網絡的感受野。
3)頸部網絡(Neck)。頸部網絡也叫Neck網絡,主要是對特征進行融合處理,由FPN(Feature Pyramid Networks)和 PAN(Path Aggregation Networks)構成。PAN網絡可以將低層的位置信息由低向高傳遞,增強底層特征的傳播。在Neck網絡中使用的是C3_v2結構,主要是將上支路的Bottleneck殘差結構替換成CBS結構,然后通過上下分支將輸出經過Concat拼接完成特征映射操作,可以增強網絡的特征融合能力。
4)輸出端(Head)。輸出端主要是把目標位置和類別信息輸出,由多個檢測頭構成,負責預測不同尺度目標的類別和位置。
YOLOv5s算法的網絡結構圖如圖3所示。
本文搭建的智能高后果區識別模型如圖4所示。
2.2.3" 模型訓練與評估
根據高后果區識別類型,分別對人員密集型、環境敏感型、交通設施型和易燃易爆場所4種樣本庫進行模型訓練,設置batch_size、leraning_rate和epochs等超參數開啟模型訓練,通過計算損失函數,待模型收斂完成后,使用驗證集進行模型評估,計算每個模型的準確率和召回率;然后通過調整樣本和超參數進行遷移學習訓練,最終輸出人員密集型、環境敏感型、交通設施型和易燃易爆場所智能識別模型。
此次采用的評價指標為精確率(Precision)和召回率(Recall),精確率(Precision)和召回率(Recall)是基于混淆矩陣得到的。此處以二分類混淆矩陣為例進行闡述,如圖5所示。
其中,Positive和Negative分別表示樣本的正例和負例,在目標檢測算法中,正例通常為待檢測的目標,負例通常為背景。TP又稱真陽性,表示是正例并正確預測為正例的結果;FP又稱假陽性,表示是負例并將負例預測為正的結果;FN又稱假陰性,表示是正例并將正例預測為負例的結果;TN又稱真陰性,表示是負例并正確預測出負例的結果。
1)準確率(Precision)又稱為查準率,表示正例正確預測為正例占整個實際正例的比值,用來評估預測是否準確,具體公式如下
P= 。 (1)
2)召回率(Recall)又稱查全率,表示正例正確預測為正例占預測為正例的比值,用來評估找的全不全,具體公式如下
R= 。" (2)
通常情況下,準確率和召回率越趨近于1,模型效果越好。通過評估發現,現有人員密集型模型準確率為0.96,召回率為0.95;交通設施型模型準確率為0.95,召回率為0.97;環境敏感型模型準確率為0.94,召回率為0.95;易燃易爆場所準確率為0.96,召回率為0.97。數據表明,不同類別的模型滿足實際高后果區識別需求。
3" 實例驗證
本次研究結合YOLOv5算法創建了高后果區AI智能識別平臺,如圖6所示。為進一步驗證模型的有效性,本文以國內某成品油管道為例對高后果區智能識別模型進行驗證,該管道長490.3 km,管徑Φ559 mm、Φ508 mm,管道壁厚為6.3~12.5 mm,設計壓力8~13.3 MPa,管道沿線環境復雜,經過密集居民區、河流、濕地和面粉廠等,管道一旦泄漏,將對周邊環境和人員造成較大影響。根據輸油管道高后果區識別項內容,采用現場航飛對管線進行數據采集,通過高后果區智能識別模型對管道沿線的高后果區進行識別,部分識別結果見表1。
將上表識別出的高后果區情況與管線最新高后果區信息列表中的數據進行對比發現,該模型智能識別出的高后果區信息與傳統人工輔助識別信息一致,說明該模型有效,可以準確地識別出人員密集型、交通設施型、環境敏感型和易燃易爆場所等不同類型高后果區及其長度與等級。實例表明,基于目標檢測算法YOLOv5s建立的高后果區智能識別模型可以滿足長輸管道高后果區自動識別的實際需求。
4" 結束語
針對輸油氣管道高后果區識別效率低的問題,本文采用目標檢測算法YOLOv5對高后果區智能識別進行了研究,根據高后果區識別類型建立人員密集型樣本庫、交通設施型樣本庫、環境敏感型樣本庫和易燃易爆場所樣本庫,在YOLOv5智能高后果區識別模型中對其訓練,訓練結果的精確率和召回率均達到90%以上。結合實例驗證,模型能快速準確地識別出高后果區的起止、類型、等級,符合實際識別需求。
鑒于本文對人員密集型的高后果區識別基于建筑物的數量,人員的數量是根據建筑物數量進行預估的,與實際相差較大,下一階段將結合信令分布、高德定位信息、紅外技術和騰訊人口分布等進一步明確高后果區的人口基數,使人員密集型高后果區識別更加精準。
參考文獻:
[1] 油氣輸送管道完整性管理規范:GB 32167—2015[S].
[2] 夏志偉,高春元,彭名超,等.輸氣管道高后果區智能識別技術[J].礦山工程,2023,11(3):334-338.
[3] 劉翼,張安祺,陳璐瑤,等.基于多源遙感影像的高后果區變化檢測方法[J].油氣儲運,2021,40(3):293-299.
[4] 高海康,戴連雙,賈韶輝,等.基于GIS的管道高后果區管理升級及其實踐[J].石油工業技術監督,2020,36(5):60-63.
[5] 耿艷磊,陶超,沈靖,等.高分辨率遙感影像語義分割的半監督全卷積網絡法[J].測繪學報,2020,49(4):499-508.
[6] 吳思妃.基于改進YOLOv5的茶芽檢測[J].福建茶葉,2024,46(2):30-32.
[7] REDMON J, DIVVALA S, GIRSHICK R, et al.You only look once: Unified, real-time object detection[C]// Computer Vision amp; Pattern Recognition.IEEE, 2016.
[8] 喻柏煒.基于卷積神經網絡YOLOv5模型的圖表識別方法[D].南昌:南昌大學,2021.
[9] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[J].IEEE, 2017:6517-6525.
[10] REDMON J, FARHADI A. YOLOv3: An ineremental improvement [J]. arXiv eprints,2018.
[11] 楊龍歡,董效杰,黃施懿,等.基于YOLOv5的輕量型絕緣子缺陷檢測算法研究[J].通信與信息技術,2023(5):13-18.
[12] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[J].2020.
[13] 鄭紅彬,宋曉茹,劉康.基于YOLOv5的交通標志識別[J].計算機系統應用,2023,32(8):230-237.
[14] 葉豐.基于改進YOLOv5算法的移動機械臂手眼協作技術研究[D].濟南:山東大學,2023.
