改進YOLOv5的密集小目標安全帽檢測研究
2025-01-19 00:00:00鄒磊蘇家儀黎恒黃宇徐韶華鄭飛宇
物聯(lián)網(wǎng)技術(shù) 2025年2期





摘 要:針對當(dāng)前安全帽在復(fù)雜情況下出現(xiàn)漏檢、誤檢和檢測精度低等問題,提出了一種基于改進YOLOv5的輕量級安全帽檢測算法。首先,選用YOLOv5s輕量級模型,將原始非極大值抑制算法(NMS)改為DIoU-NMS,手動設(shè)置閾值提高其對密集目標檢測的準確率,改善模型的微調(diào)與推理效果。其次,在原算法的主干網(wǎng)絡(luò)融入并重構(gòu)BoTNet網(wǎng)絡(luò),來提升其對小目標信息特征的提取能力,降低訓(xùn)練的復(fù)雜度。最后,在Neck網(wǎng)絡(luò)中引入了NAM注意力機制,增強模型的魯棒性,使其更加輕量化。實驗結(jié)果表明,改進后的YOLOv5s算法對安全帽佩戴識別的準確率達到98.93%,并能準確識別密集小目標,有效滿足輕量化安全帽佩戴檢測的需求,有利于提高安全檢查和監(jiān)督水平。
關(guān)鍵詞:安全帽檢測;YOLOv5;BoTNet網(wǎng)絡(luò);NAM注意力機制;DIoU-NMS;密集小目標
中圖分類號:TP391.41 文獻標識碼:A 文章編號:2095-1302(2025)02-000-06
0 引 言
近年來,隨著現(xiàn)代工業(yè)化生產(chǎn)的不斷發(fā)展,自動化和智能化已成為工業(yè)生產(chǎn)應(yīng)用中的重要研究方向。其中,自動檢測和識別技術(shù)在保障工業(yè)生產(chǎn)安全方面發(fā)揮著越來越重要的作用。對于建筑行業(yè)而言,工人按要求佩戴安全帽是保障施工安全的重要環(huán)節(jié)。隨著我國基礎(chǔ)設(shè)施建設(shè)的快速發(fā)展,建筑工地安全事故也逐年增加,因此對建筑工地工人的安全帽佩戴情況進行研究,對于深入了解和預(yù)防安全事故的發(fā)生具有重要意義。
目前,大部分建筑工地的安全帽佩戴管理主要通過人工監(jiān)管的方式,但由于施工現(xiàn)場存在作業(yè)面積廣、人員流動性大的特點,通過人工監(jiān)管很難實時掌握各個施工單位的具體安全情況,不僅耗時長且效率低下,還存在誤檢、漏檢等情況。隨著人工智能的不斷發(fā)展,基于深度學(xué)習(xí)的目標檢測方法在安全帽佩戴檢測領(lǐng)域可實現(xiàn)對施工現(xiàn)場的實時監(jiān)測,既節(jié)約了人力成本,又提高了安全性,為安全生產(chǎn)和執(zhí)法、打造智能安全管理系統(tǒng)提供了很好的技術(shù)保障。文獻[1]結(jié)合Hu矩陣和支持向量機對人員安全帽佩戴情況進行了檢測。
文獻[2]使用類似Haar的特征檢測人臉方法,再使用邊緣檢測算法查找安全帽輪廓特征實現(xiàn)對安全帽佩戴情況的檢測。文獻[3]通過選取SIFT角點特征和顏色統(tǒng)計特征的方法來進行安全帽佩戴情況檢測。近年來,以SSD和YOLO為代表的單階段算法在檢測速度方面具有優(yōu)勢。文獻[4]提出了遵循“one-stage”思想的YOLO網(wǎng)絡(luò),它可以將整張圖像作為網(wǎng)絡(luò)的輸入,僅通過一次前向傳播就能得到目標的位置和類別,這為安全帽檢測提供了一個新的思路。文獻[5]利用YOLOv3算法對圖像中的人臉區(qū)域進行定位,根據(jù)人臉與安全帽的關(guān)系估算出安全帽的可能區(qū)域,再利用HOG進行特征提取,借助SVM分類器判斷相關(guān)人員是否佩戴安全帽。文獻[6]提出了一種以YOLOv2目標檢測方法為基礎(chǔ),并在原網(wǎng)絡(luò)中加入密集塊的方法,以實現(xiàn)低層語義信息與深層語義信息的結(jié)合,從而解決傳統(tǒng)檢測方法準確率低、魯棒性差的問題。文獻[7]提出了YOLOv4模型,使用CSPDarkNet53主干網(wǎng)絡(luò)進行特征提取,該算法檢測精度高,可滿足安全帽佩戴檢測精度的要求,但由于網(wǎng)絡(luò)較為復(fù)雜,實時性需求難以得到滿足。上述改進算法檢測的速度和準確率不夠理想,且未能及時解決準確識別密集小目標的問題。
因此,本文以輕量級模型YOLOv5s為基礎(chǔ),首先,將原始NMS算法改進為DIoU-NMS,提高對密集目標檢測的準確率;其次在主干網(wǎng)絡(luò)引入并重構(gòu)BoTNet網(wǎng)絡(luò)結(jié)構(gòu),不僅提升了其對小目標信息特征的提取能力,還能降低訓(xùn)練的復(fù)雜度;最后,在Neck網(wǎng)絡(luò)中引入了NAM注意力機制,增強了模型的魯棒性。
1 YOLOv5s網(wǎng)絡(luò)結(jié)構(gòu)
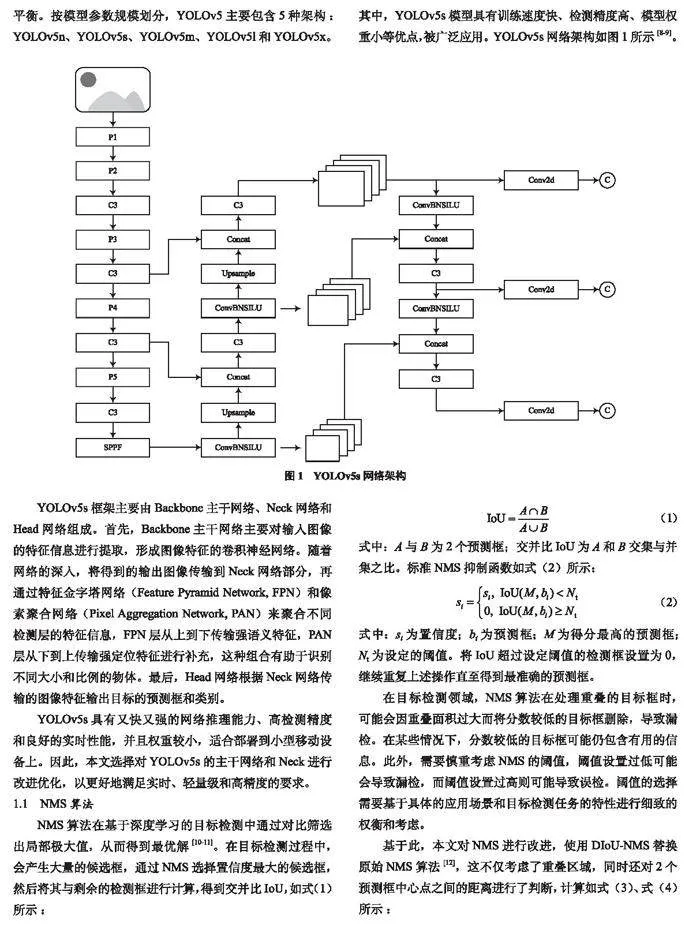
YOLO是一種專注于目標檢測的深度神經(jīng)網(wǎng)絡(luò),屬于單階段算法模型,可完成端到端目標檢測任務(wù)[4]。YOLOv5基于YOLO改進得到,在預(yù)測精度和速度上取得了較好的平衡。按模型參數(shù)規(guī)模劃分,YOLOv5主要包含5種架構(gòu):YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x。其中,YOLOv5s模型具有訓(xùn)練速度快、檢測精度高、模型權(quán)重小等優(yōu)點,被廣泛應(yīng)用。YOLOv5s網(wǎng)絡(luò)架構(gòu)如圖1所示[8-9]。
YOLOv5s框架主要由Backbone主干網(wǎng)絡(luò)、Neck網(wǎng)絡(luò)和Head網(wǎng)絡(luò)組成。首先,Backbone主干網(wǎng)絡(luò)主要對輸入圖像的特征信息進行提取,形成圖像特征的卷積神經(jīng)網(wǎng)絡(luò)。隨著網(wǎng)絡(luò)的深入,將得到的輸出圖像傳輸?shù)絅eck網(wǎng)絡(luò)部分,再通過特征金字塔網(wǎng)絡(luò)(Feature Pyramid Network, FPN)和像素聚合網(wǎng)絡(luò)(Pixel Aggregation Network, PAN)來聚合不同檢測層的特征信息,F(xiàn)PN層從上到下傳輸強語義特征,PAN層從下到上傳輸強定位特征進行補充,這種組合有助于識別不同大小和比例的物體。最后,Head網(wǎng)絡(luò)根據(jù)Neck網(wǎng)絡(luò)傳輸?shù)膱D像特征輸出目標的預(yù)測框和類別。
YOLOv5s具有又快又強的網(wǎng)絡(luò)推理能力、高檢測精度和良好的實時性能,并且權(quán)重較小,適合部署到小型移動設(shè)備上。因此,本文選擇對YOLOv5s的主干網(wǎng)絡(luò)和Neck進行改進優(yōu)化,以更好地滿足實時、輕量級和高精度的要求。
1.1 NMS算法
NMS算法在基于深度學(xué)習(xí)的目標檢測中通過對比篩選出局部極大值,從而得到最優(yōu)解[10-11]。在目標檢測過程中,會產(chǎn)生大量的候選框,通過NMS選擇置信度最大的候選框,然后將其與剩余的檢測框進行計算,得到交并比IoU,如式(1)所示:
(1)
式中:A與B為2個預(yù)測框;交并比IoU為A和B交集與并集之比。標準NMS抑制函數(shù)如式(2)所示:
(2)
式中:si為置信度;bi為預(yù)測框;M為得分最高的預(yù)測框;Nt為設(shè)定的閾值。將IoU超過設(shè)定閾值的檢測框設(shè)置為0,繼續(xù)重復(fù)上述操作直至得到最準確的預(yù)測框。
在目標檢測領(lǐng)域,NMS算法在處理重疊的目標框時,可能會因重疊面積過大而將分數(shù)較低的目標框刪除,導(dǎo)致漏檢。在某些情況下,分數(shù)較低的目標框可能仍包含有用的信息。此外,需要慎重考慮NMS的閾值,閾值設(shè)置過低可能會導(dǎo)致漏檢,而閾值設(shè)置過高則可能導(dǎo)致誤檢。閾值的選擇需要基于具體的應(yīng)用場景和目標檢測任務(wù)的特性進行細致的權(quán)衡和考慮。
基于此,本文對NMS進行改進,使用DIoU-NMS替換原始NMS算法[12],這不僅考慮了重疊區(qū)域,同時還對2個預(yù)測框中心點之間的距離進行了判斷,計算如式(3)、式(4)所示:
(3)
(4)
式中:Ti為分類置信度;ε為NMS所設(shè)定的閾值;M為置信度最高的預(yù)測框;RDIoU為在IoU損失函數(shù)的基礎(chǔ)上所添加的懲罰項,用于最小化2個預(yù)測框之間的中心點距離;b為預(yù)測框中心;bgt為真實框中心;ρ為預(yù)測框與真實框的中心距離;c為包含了2個框的最小矩形框的對角線長度。當(dāng)2個預(yù)測框之間的IoU較大,但2個框的距離又較遠時,認為預(yù)測框?qū)儆?個物體,不會被抑制。相比于原算法,改進的算法對密集目標、小目標等的檢測精度有一定的提高。
1.2 BoTNet網(wǎng)絡(luò)
BoTNet是Berkeley和谷歌團隊在2021年CVPR上提出的一種混合模型[13-14],它同時使用了卷積和自注意力機制,模型將自注意力納入了多種計算機視覺任務(wù),將殘差網(wǎng)絡(luò)(Residual Network, ResNet)最后3個瓶頸塊中的空間卷積用全局自注意力模塊進行替換,即多頭自注意力(Multi-Head Self-Attention, MHSA)替換3×3卷積參數(shù)(Conv),構(gòu)成的新模塊為BoTNet。BoTNet模塊結(jié)構(gòu)如圖2所示。
BoTNet模塊結(jié)構(gòu)簡單,功能強大,其充分利用了卷積網(wǎng)絡(luò)與自注意力的優(yōu)勢,對不重要的目標特征進行了抑制并降低了特征的權(quán)重,從而提升了模型檢測識別的能力。本文選擇將此結(jié)構(gòu)融入到Y(jié)OLOv5s的主干網(wǎng)絡(luò)中,重建其特征提取網(wǎng)絡(luò)結(jié)構(gòu),以有效減少參數(shù)從而將延遲最小化。
1.3 NAM注意力模塊
NAM是一種高效的輕量級注意力機制[15-16],其主要由通道注意力子模塊(Channel Attention Module, CAM)和空間注意力子模塊(Spatial Attention Module, SAM)組成。本文重新設(shè)計了NAM的CAM和SAM,使得NAM可以嵌入到每個網(wǎng)絡(luò)block的最后。對于ResNet,它嵌入在殘差結(jié)構(gòu)的末端,利用權(quán)重的貢獻因子來改善注意力機制。對于CAM,則借助批量歸一化(Batch Normalization, BN)中的比例因子,使用標準差來表示權(quán)重的重要性,如式(5)所示。比例因子可反映各個通道的變化情況,進一步表示了該通道的重要性。BN中的方差越大,表示該通道所包含的信息越豐富,重要性越高;反之方差越小,表示信息越單一,重要性越低。
(5)
式中:μβ和σβ分別表示小批量β的均值和標準差;γ和b表示可訓(xùn)練的仿射變換參數(shù),即尺度和位移;φ表示為了數(shù)值穩(wěn)定而添加到小批量方差中的常數(shù)。
CAM如圖3所示。
輸出特征MC和權(quán)重ωθ如式(6)、式(7)所示:
(6)
(7)
式中:θ為每個通道的比例因子。Sigmoid為激活函數(shù),形式如
式(8)所示:
(8)
SAM如圖4所示。NAM將BN的比例因子應(yīng)用于空間維度以衡量像素的重要程度,稱為像素歸一化(Pixel Normalization, PN)。
權(quán)重ωλ和輸出特征MS如式(9)、式(10)所示:
(9)
(10)
式中:λ為比例因子。Sigmoid為激活函數(shù),形式同式(8)。
此外,為了抑制不重要的特征,在損失函數(shù)Loss中添加了一個正則化項L(*)。損失函數(shù)Loss和正則化項L(*)分別如式(11)、式(12)所示:
(11)
(12)
式中:x和y分別表示輸入和輸出;W表示網(wǎng)絡(luò)權(quán)重;g( )表示L1范數(shù)懲罰函數(shù);p表示平衡g(λ)和g(θ)的懲罰項。
該注意力機制保留了通道和空間方向上的信息,增強了它們之間跨緯度的交互性,通過減少信息和放大全局交互表示來提高網(wǎng)絡(luò)的性能,提高了模型檢測效果。本文在Neck網(wǎng)絡(luò)中融合了NAM注意力機制,在不增加全連接、卷積等額外的參數(shù)和計算量的前提下,提升了注意力的效果并使模型更加輕量化。
1.4 改進的YOLOv5s
圖5為改進的YOLOv5s網(wǎng)絡(luò)構(gòu)架,其主干網(wǎng)絡(luò)添加了BoTNet和在Neck網(wǎng)絡(luò)中融合的NAM。通過引入BoTNet,模型能夠在保持較小規(guī)模的同時,學(xué)習(xí)到更豐富的特征表示。這有助于提高模型的檢測性能,同時減少模型的計算量和內(nèi)存占用。為進一步提高準確性,在YOLOv5s的Neck網(wǎng)絡(luò)中融合NAM模塊。NAM模塊可與FPN結(jié)構(gòu)結(jié)合,根據(jù)輸入特征自動調(diào)整其通道數(shù)和卷積核的大小。這種自適應(yīng)的特性使得NAM能夠更好地適應(yīng)不同尺度和長度的特征,從而提供更準確的目標檢測結(jié)果。本文提出改進的YOLOv5s網(wǎng)絡(luò)結(jié)構(gòu),使得模型能夠更好地利用圖像中的局部和全局信息,從而提升檢測目標的檢測精度與檢測速度。
2 實驗結(jié)果與分析
2.1 實驗準備
本文的實驗環(huán)境配置見表1。
實驗數(shù)據(jù)集:數(shù)據(jù)集選用不同復(fù)雜場景下的圖片素材以增強模型的泛化能力,篩選出2 319張圖片,使用LabelImg軟件標注,構(gòu)建出本文安全帽檢測數(shù)據(jù)集。將數(shù)據(jù)集分為正確佩戴安全帽“Hat”和未佩戴安全帽“Head”2類,不同場景的展示如圖6所示。
2.2 評價指標
為證明實驗方法的有效性,本文選擇精確率P、召回率R和均值平均精度mAP作為評價指標來評估模型性能[17],其計算如式(13)、式(14)所示:
(13)
(14)
式中:TP為被模型正確劃分為正樣本的數(shù)量;FP為被模型錯誤劃分為正樣本的數(shù)量;FN為被模型錯誤劃分為負樣本的數(shù)量;AP為單個類別的平均精度,即通過積分法計算出的P-R曲線與橫縱坐標所圍成的面積;mAP即為所有類別AP值的均值。計算如式(15)、式(16)所示:
(15)
(16)
2.3 實驗結(jié)果及對比分析
本文采用自制數(shù)據(jù)集來進行訓(xùn)練和測試,并且對不同的目標檢測模型進行實驗和評價。訓(xùn)練時輸入的圖像大小為640×640,初始學(xué)習(xí)率設(shè)為0.001,權(quán)重衰減為0.005,batch size為8,epoch共迭代300個。
2.3.1 消融實驗
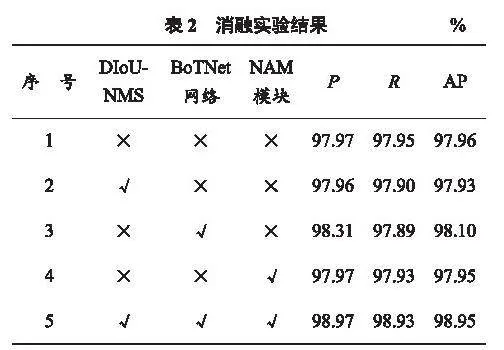
為驗證所提方法的有效性,本文對DIoU-NMS算法、BoTNet網(wǎng)絡(luò)、NAM注意力機制等在相同的實驗條件下進行消融實驗,選擇正確佩戴安全帽的類別“Hat”進行對比,目的是驗證融合各個模塊時對檢測效果的影響。消融實驗結(jié)果見表2。在引入單一注意力模塊NAM或DIoU-NMS時,AP值略有降低;融合BoTNet網(wǎng)絡(luò)結(jié)構(gòu)后,AP值提高了0.14個百分點;在運行本文的改進方法時,AP值提高了0.99個百分點。因此選擇在此方法基礎(chǔ)上進行實驗。
2.3.2 不同檢測模型性能對比
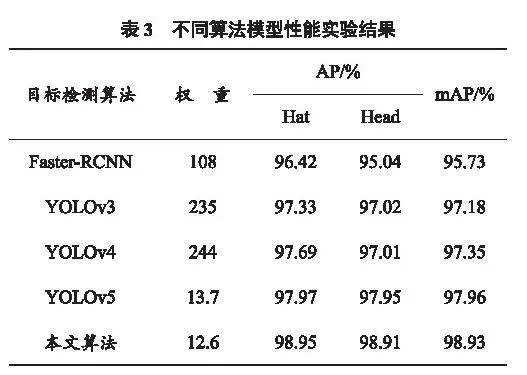
為進一步檢驗本文中提出的改進方法的性能,選擇Faster R-CNN、YOLOv3、YOLOv4、YOLOv5等具有代表性的目標檢測算法進行對比實驗[18],基于相同的數(shù)據(jù)集、參數(shù)、訓(xùn)練策略,不同算法模型性能實驗結(jié)果見表3。實驗結(jié)果表明,改進后的模型權(quán)重明顯減小,達到12.6,對安全帽佩戴識別的準確率較高,mAP值達到98.93%,高于其他算法模型。
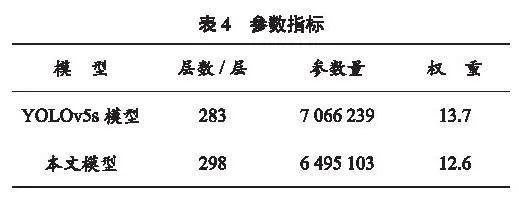
此外,為了證明輕量化改進的有效性,本文對改進前后模型的參數(shù)指標進行了對比,見表4。本文所提方法在層數(shù)略有增加的前提下,參數(shù)量較原算法大幅減少,權(quán)重降低了1.1,使模型更加輕量化,并降低了模型計算的復(fù)雜度。
2.4 在密集小目標場景的應(yīng)用
為進一步表征改進算法的優(yōu)勢,選取密集場景和復(fù)雜場景來進行對比實驗(圖7)。第一行圖片為YOLOv5的檢測結(jié)果,第二行為改進算法的檢測結(jié)果。如圖7(a)所示,在密集場景下,改進算法可正確識別全部目標,而YOLOv5的識別效果不佳,存在漏檢的情況(圖片中使用白色框顯示)。在復(fù)雜的室外環(huán)境中,改進算法可正確識別所有小目標,而YOLOv5存在4處漏檢情況,如圖7(b)所示。
3 結(jié) 語
為提高在復(fù)雜場景下安全帽佩戴的檢測效果,本文提出了一種改進的安全帽智能檢測方法。針對不同的場景自制數(shù)據(jù)集進行訓(xùn)練,對YOLOv5s檢測模型進行了輕量化改進,將NMS改為DIoU-NMS,提高了在密集場景中的目標檢測精度,并從主干網(wǎng)絡(luò)和Neck網(wǎng)絡(luò)入手,重建其特征提取網(wǎng)絡(luò)結(jié)構(gòu),實現(xiàn)了對密集小目標的識別,有效提升了對安全帽佩戴情況的識別精度,降低了模型的訓(xùn)練難度和模型權(quán)重,使其易于在移動設(shè)備中使用。
參考文獻
[1]劉曉慧,葉西寧.膚色檢測和Hu矩在安全帽識別中的應(yīng)用[J].華東理工大學(xué)學(xué)報,2014,40(3):365-370.
[2] SHRESTHA K, SHRESTHA P P, BAJRACHARYA D, et al. Hard-hat detection for construction safety visualization [J]. Journal of construction engineering, 2015, 2015: 1-8.
[3]馮國臣,陳艷艷,陳寧,等.基于機器視覺的安全帽自動識別技術(shù)研究[J].機械設(shè)計與制造工程,2015,44(10):39-42.
[4] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 779-788.
[5]楊莉瓊,蔡利強,古松.基于機器學(xué)習(xí)方法的安全帽佩戴行為檢測[J].中國安全生產(chǎn)科學(xué),2019,15(2):152-157.
[6]方明,孫騰騰,邵楨.基于改進YOLOv2的快速安全帽佩戴情況檢測[J].光學(xué)精密工程,2019,27(5):1196-1205.
[7] QI X, SHI L, LI L, et al. Detection of abnormal hot spots infrared images of power equipment based on YOLOv4 [C]// Journal of Physics: Conference Series. Bristol, England: IOP Publishing, 2021, 2005(1): 012074.
[8] ZHOU F, ZHAO H, NIE Z. Safety helmet detection based on YOLOv5 [C]// Proceedings of 2021 IEEE International Conference on Power Electronics, Computer Applications, ICPECA 2021. Shenyang, China: Institute of Electrical and Electronics Engineers, 2021:"6-11.
[9] YANG G, LEI Q. The system of detecting safety helmets based on YOLOv5 [C]// 2021 International Conference on Electronic Information Engineering and Computer Science, EIECS 2021. [S.l.]: Institute of Electrical and Electronics Engineers, 2021: 750-755.
[10] QIU S, WEN G, DENG Z, et al. Accurate non-maximum suppression for object detection in high-resolution remote sensing images [J]. Remote sensing letters, 2018, 9(3): 237-246.
[11] WU F, ZHU C, XU J, et al. Research on image text recognition based on canny edge detection algorithm and k-means algorithm [J]. International journal of system assurance engineering and management, 2022, 13: 72-80.
[12] ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [S.l.]: [s.n.], 2020, 34(7): 12993-13000.
[13] SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck transformers for visual recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). NashVille, TN, USA: IEEE, 2021: 16519-16529.
[14] CHEN Y, XIA S, ZHAO J, et al. ResT-ReID: transformer block-based residual learning for person re-identification [J]. Pattern recognition letters, 2022, 157: 90-96.
[15]李小波,李陽貴,郭寧,等.融合注意力機制的YOLOv5口罩檢測算法[J].圖學(xué)學(xué)報,2023,44(1):16-25.
[16]LIU Y, SHAO Z, TENG Y, et al. NAM: Normalization-based attention module [EB/OL]. (2021-11-24). https: //doi.org/10.48550/arXiv.2111.12419.
[17]呂宗喆,徐慧,楊驍,等.面向小目標的YOLOv5安全帽檢測算法[J].計算機應(yīng)用,2023,43(6):1943-1949.
[18]儲開斌,葉托,張繼.基于改進Faster R-CNN的頭盔檢測算法研究[J].國外電子測量技術(shù),2022,41(6):86-92.
作者簡介:鄒 磊(1985—),男,廣西柳州人,工程師,研究方向為大數(shù)據(jù)、圖像處理和人工智能。
收稿日期:2024-01-12 修回日期:2024-02-26
基金項目:廣西重點研發(fā)計劃資助項目(AB22035047);廣西重點研發(fā)計劃資助項目(AB23026038)
