霧天環(huán)境下的指針式儀表檢測與讀數(shù)識別
2025-01-31 00:00:00吳攀超楊鵬孫電洋楊明昊
化工機械 2025年1期






摘 要 針對霧天油田巡檢機器人對指針式儀表漏檢及讀數(shù)識別準確率低的問題,提出一種結合FFA Net去霧算法和Yolov5檢測網(wǎng)絡的方法。首先,對于霧天圖像,改進了FFA Net算法,通過多尺度結構、特征融合殘差塊和優(yōu)化模塊,有效地提升了算法在去霧任務中的性能表現(xiàn)。其次,對于儀表檢測與讀數(shù)識別,采用較小的檢測頭來提升Yolov5對小目標的檢測能力,并引入空間轉換模塊將檢測到的表盤圖像轉換為更符合人眼觀感的正視圖像。最后,創(chuàng)建了一個端到端的框架,緊密耦合儀表成分檢索和儀表讀數(shù)識別,提高了儀表讀數(shù)的準確性。實驗結果表明,所提方法在油田霧天環(huán)境下展現(xiàn)出了良好的魯棒性,提升了霧天環(huán)境下指針式儀表檢測與讀數(shù)識別的準確性。
關鍵詞 圖像去霧 Yolov5 儀表檢測 儀表識別
中圖分類號 TP391"" 文獻標志碼 A"" 文章編號 1000 3932(2025)01 0101 10
近年來,隨著人工智能在各個領域的快速發(fā)展,油田逐漸引入巡檢機器人來進行巡檢工作,以此提高識別準確率,減少設備漏檢和誤檢所帶來的經(jīng)濟損失[1]。一些機器人通過拍攝室外的指針式儀表圖像,再利用圖像處理技術來進行讀數(shù)識別。然而,在霧霾天氣環(huán)境下,會導致采集到的指針式儀表圖像質量降低,出現(xiàn)無法識別儀表、指針讀數(shù),識別準確率低等問題。
目前,研究人員對指針式儀表的檢測與讀數(shù)識別進行了大量研究。LIU Y等首先采用Faster R CNN技術準確定位儀表位置,隨后利用特征對應算法和透視變換獲取高質量圖像,最終通過Hough變換確定指針位置并讀取讀數(shù)[2]。WU X等提出一種基于二值掩模和改進Mask RCNN的儀表圖像偏斜校正算法,實現(xiàn)了高精度橢圓擬合[3]。LIU Z等利用高斯尺度空間增強ORB算法的尺度不變性,并利用RANSAC對匹配點進行濾波,以提高特征指針匹配的精度,最后,通過霍夫變換擬合指針,獲得讀數(shù)[4]。WANG L等采用Faster R CNN目標檢測方法定位儀表區(qū)域,并利用泊松融合方法和K fold驗證算法擴展數(shù)據(jù)集,優(yōu)化數(shù)據(jù)集質量[5]。
雖然以上方法都取得了不錯的識別結果,但是在霧霾天氣下,地面附近的空氣中含有大量微粒會導致圖像質量降低,出現(xiàn)色彩暗淡、對比度降低等問題,無法精確定位指針式儀表并且降低讀數(shù)識別的準確率。針對此問題,筆者利用圖像增強和深度學習方法來去除霧霾對表盤的干擾,并結合改進的Yolov5目標檢測算法,對去霧后的指針式儀表圖像進行檢測與讀數(shù)識別。
1 儀表檢測與讀數(shù)識別模型
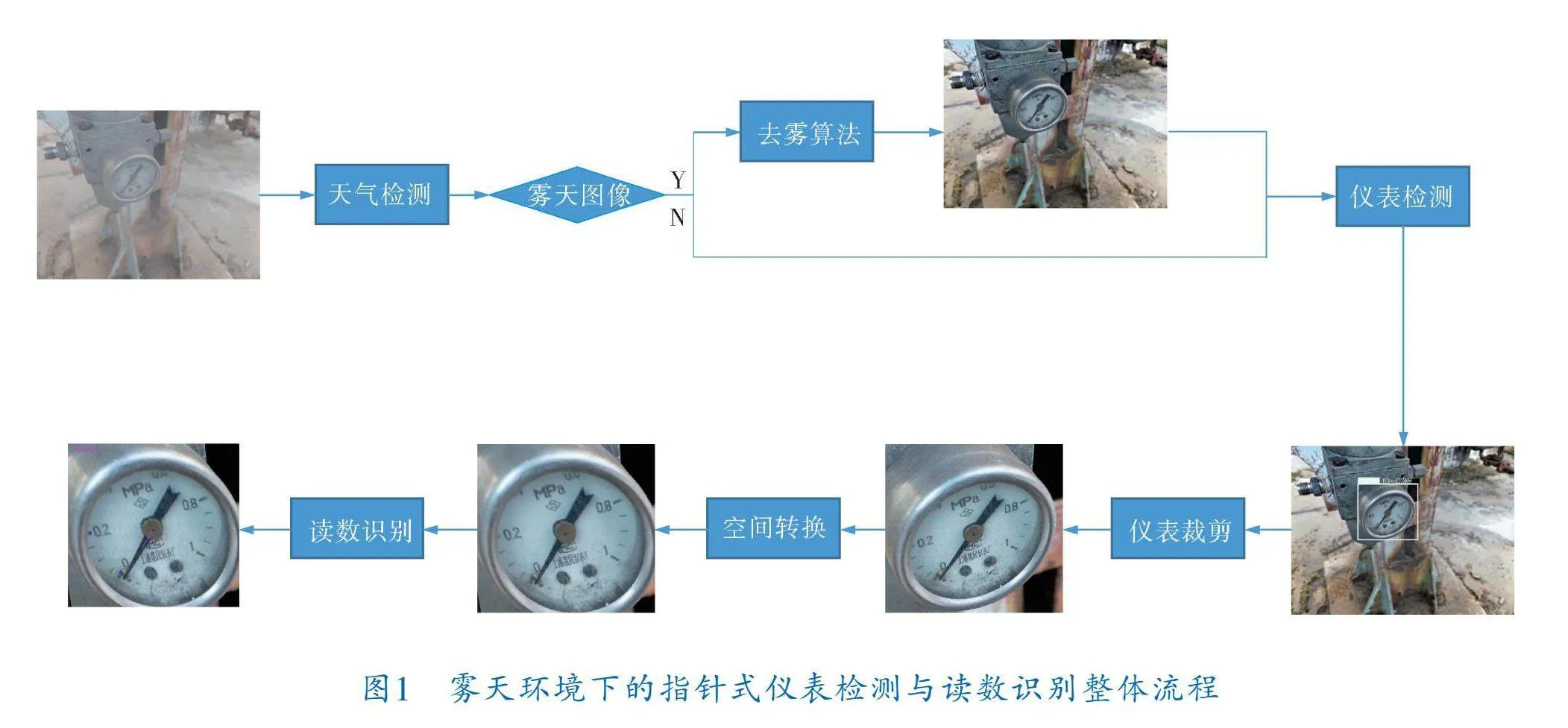
針對霧天環(huán)境下對指針式儀表定位不準與讀數(shù)識別準確率低的問題,筆者提出了基于特征融合注意力網(wǎng)絡(FFA Net)和Yolov5的霧天環(huán)境下指針式儀表檢測與讀數(shù)識別方法。首先判斷采集到的圖像是否為霧天圖像,采用基于FFA Net的圖像去霧算法降低霧霾對儀表圖像的干擾,然后對去霧后的儀表圖像采用目標檢測技術進行定位,排除圖像中其他物體的干擾,識別正確的目標區(qū)域。根據(jù)目標區(qū)域的位置信息提取儀表表盤區(qū)域,縮小圖像范圍。對于傾斜、畸變的表盤圖像,使用空間轉換方法進行校正,從而得到高質量的表盤正視圖像。筆者創(chuàng)建了一個讀數(shù)識別模塊,包括基于語義分割的儀表組件檢索分支和基于文本識別器的儀表讀數(shù)識別分支。通過儀表組件檢索分支得到指針圖和關鍵刻度圖,通過儀表讀數(shù)識別分支得到最終的識別結果。整體流程如圖1所示。
2 基于FFA Net的圖像去霧算法
QIN X等提出了FFA Net,該網(wǎng)絡結合了像素注意力、通道注意力以及局部殘差模塊來進行去霧,取得了顯著的效果[6]。但由于FFA Net的特征提取部分相對簡單,去霧效果受到了限制,在霧濃度大的情況下經(jīng)過處理的圖片不僅出現(xiàn)了嚴重的色彩偏差,而且有大量的霧氣殘留,不利于后續(xù)的儀表識別。
2.1 改進的FFA Net圖像去霧網(wǎng)絡模型
針對上述問題,筆者在FFA Net的基礎上,使用多尺度結構,改善了特征注意力模塊,讓網(wǎng)絡能夠更好地學習到所需的特征,提高了網(wǎng)絡的泛化能力,并加入一個優(yōu)化模塊,進一步恢復圖像的細節(jié)信息,提升網(wǎng)絡的去霧效果。
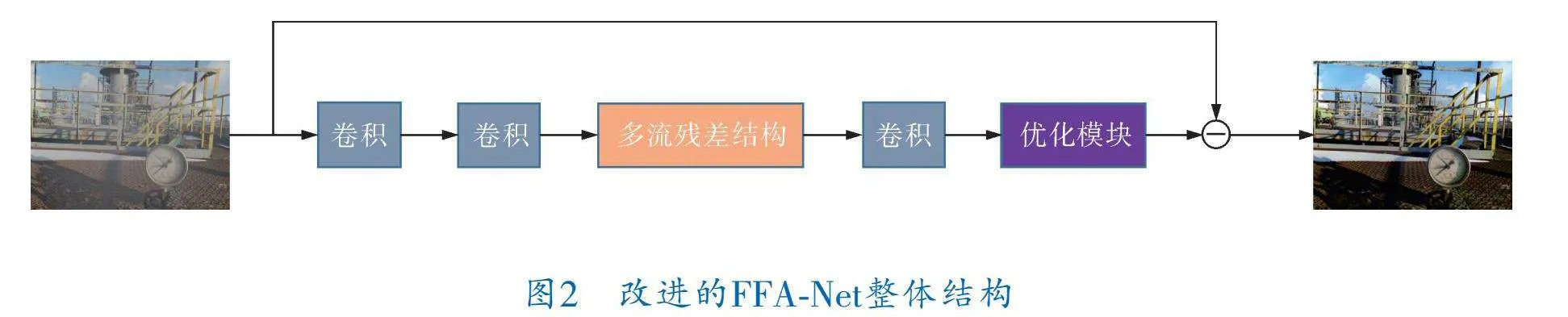
改進的FFA Net整體結構如圖2所示。首先將有霧圖像輸入到網(wǎng)絡中,經(jīng)過兩次卷積來提取淺層特征,然后將提取到的淺層特征輸入到由特征融合殘差塊組成的多流殘差結構中來提取不同尺度的特征,最后通過優(yōu)化模塊保證生成圖像的細節(jié)信息,從而輸出無霧圖像。
2.2 多流殘差結構
FFA Net的特征提取部分僅通過單一的卷積神經(jīng)網(wǎng)絡來提取特征,這種情況只能捕獲局部信息,忽略了全局和上下文信息,導致網(wǎng)絡的處理能力受到限制。改進的FFA Net去霧網(wǎng)絡建立在圖像去霧任務中廣泛采用的編碼器-解碼器架構之上,編碼器可以有效地提取輸入圖像中的特征信息,解碼器則可以將這些特征信息映射回原始圖像空間,并幫助恢復清晰的圖像。由編碼器-解碼器網(wǎng)絡引發(fā)的大感受野能夠獲取更廣泛的上下文信息,但隨著網(wǎng)絡層的逐漸加深,淺層特征信息往往難以保留。為了識別和融合不同層次的特征,筆者使用多流殘差網(wǎng)絡來提取不同尺度的特征,將淺層和深層信息集成在一起,得到更全面、更準確的圖像表示。
多流殘差結構如圖3所示,首先將提取到的淺層特征送入不同尺度的編碼器中,編碼器對輸入特征圖進行下采樣操作,編碼器中的每一層都由卷積和特征融合殘差塊組成,在逐步降低分辨率的同時,不斷地提取圖像特征,并擴展特征圖的維度。然后再經(jīng)過解碼器來重構圖像,對經(jīng)過編碼器的特征圖做上采樣操作逐步恢復到輸入圖像的尺寸。在編碼器和解碼器的對應層之間使用跳躍連接將特征圖在通道維度上進行拼接,有利于實現(xiàn)淺層特征和深層特征之間的直接傳遞,使得不同層次的特征可以更好地相互融合,降低網(wǎng)絡訓練的難度。該結構可以描述為:
M(x)=[F3×3(x),F(xiàn)5×5(x),F(xiàn)7×7(x)]""" (1)
其中,M(x)表示多流殘差結構,F(xiàn)(·)表示內核大小為i的特征提取模塊,[·]表示級聯(lián)操作。
2.3 特征融合殘差塊
以往的深度學習去霧模型通常對通道特征和像素特征的處理是一視同仁的,忽略了實際有霧圖像中霧霾分布的不均勻性,導致去霧效果不佳且限制了網(wǎng)絡的表示能力。
FFA Net特征注意力模塊通過結合通道注意力和像素注意力,能夠不平等地處理不同像素區(qū)域的特征。但隨著模型復雜度的提升,特征注意力模塊的計算量也隨之增加,且通道注意力中的降維操作會對通道注意力的預測產(chǎn)生負面影響。
WANG Q等通過研究表明避免降維對學習通道注意力非常重要,提出一種高效通道注意力模塊(ECA),可在只增加少量參數(shù)的情況下顯著提升其性能[7]。因此引入ECA模塊來避免降維操作并有效促進跨通道交互,降低模型復雜度并增強泛化能力。此外,將殘差塊和特征注意力模塊相結合,在減少網(wǎng)絡深度的同時實現(xiàn)特征的融合,從而加快網(wǎng)絡的收斂,進一步增強了網(wǎng)絡的學習能力。
所提的特征融合殘差塊結構如圖4所示,它可以讓網(wǎng)絡更加關注有用的通道信息和像素信息,給予不同濃度的區(qū)域不同的權重,讓網(wǎng)絡更加關注高頻信息且不會忽略低頻信息,從而達到更好的去霧效果。其整體結構如下:
F(x)=FA(ReLU(GN(Conv(Res(x)))))" (2)
其中,x為輸入特征圖,Res(·)為殘差塊,GN為組歸一化,Conv為卷積模塊,ReLU為激活函數(shù),F(xiàn)A為改進后的特征注意力模塊,F(xiàn)(x)為特征融合殘差塊。
2.4 優(yōu)化模塊
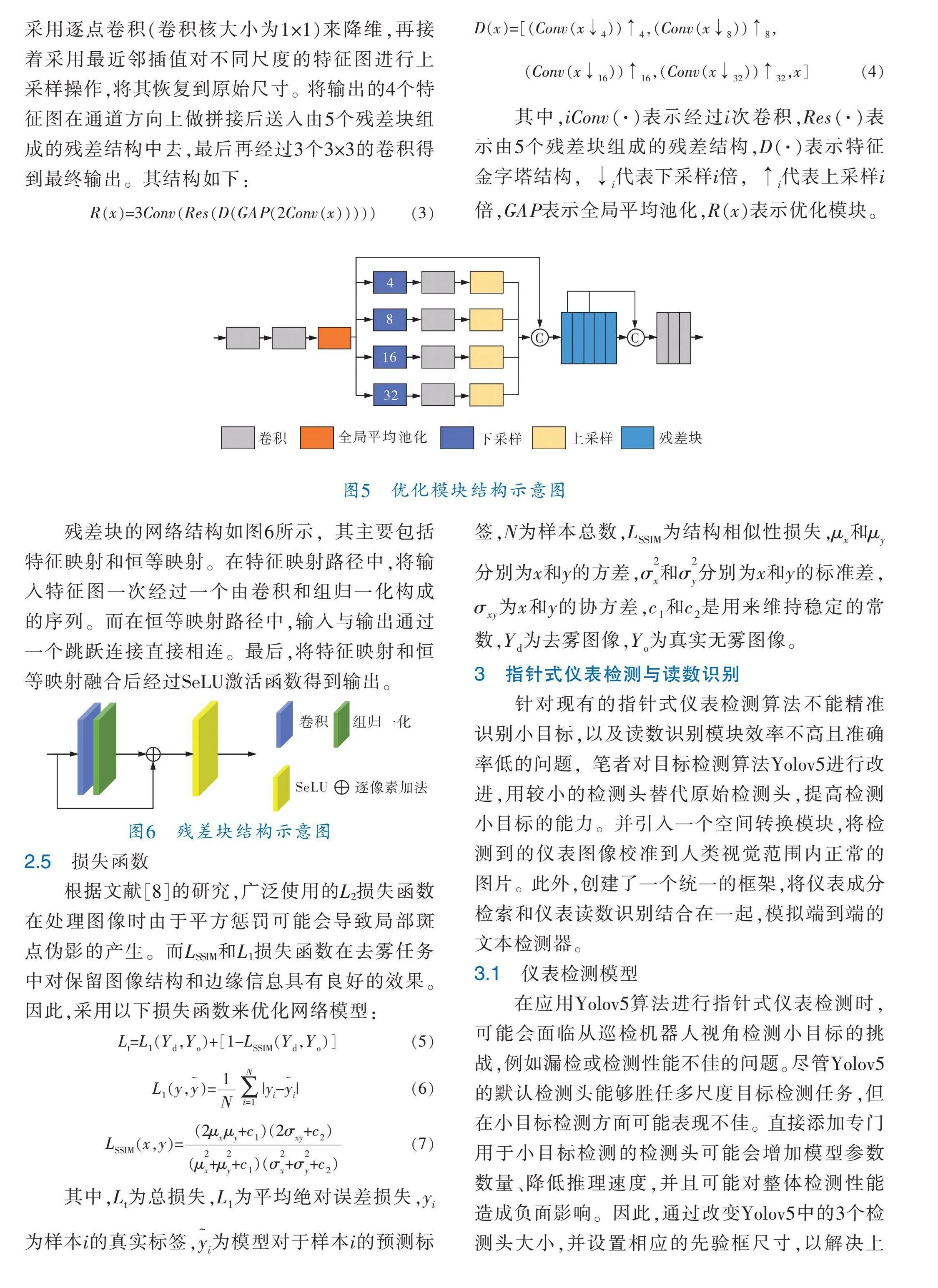
多流殘差結構會導致生成的圖像缺乏細節(jié)信息,優(yōu)化模塊的主要目的就是對聚在一起的特征映射進行精細調整。
優(yōu)化模塊的結構如圖5所示,首先將輸入特征圖經(jīng)過兩個3×3的卷積和全局平均池化后,對特征圖分別采用4、8、16、32的系數(shù)進行下采樣來構造特征金字塔,接著對于不同尺寸的特征圖,采用逐點卷積(卷積核大小為1×1)來降維,再接著采用最近鄰插值對不同尺度的特征圖進行上采樣操作,將其恢復到原始尺寸。將輸出的4個特征圖在通道方向上做拼接后送入由5個殘差塊組成的殘差結構中去,最后再經(jīng)過3個3×3的卷積得到最終輸出。其結構如下:
R(x)=3Conv(Res(D(GAP(2Conv(x)))))" (3)
D(x)=[(Conv(x↓))↑,(Conv(x↓))↑,
(Conv(x↓))↑,(Conv(x↓))↑,x]"" (4)
其中,iConv(·)表示經(jīng)過i次卷積,Res(·)表示由5個殘差塊組成的殘差結構,D(·)表示特征金字塔結構,↓代表下采樣i倍,↑代表上采樣i倍,GAP表示全局平均池化,R(x)表示優(yōu)化模塊。
殘差塊的網(wǎng)絡結構如圖6所示,其主要包括特征映射和恒等映射。在特征映射路徑中,將輸入特征圖一次經(jīng)過一個由卷積和組歸一化構成的序列。而在恒等映射路徑中,輸入與輸出通過一個跳躍連接直接相連。最后,將特征映射和恒等映射融合后經(jīng)過SeLU激活函數(shù)得到輸出。
2.5 損失函數(shù)
根據(jù)文獻[8]的研究,廣泛使用的L2損失函數(shù)在處理圖像時由于平方懲罰可能會導致局部斑點偽影的產(chǎn)生。而LSSIM和L1損失函數(shù)在去霧任務中對保留圖像結構和邊緣信息具有良好的效果。因此,采用以下?lián)p失函數(shù)來優(yōu)化網(wǎng)絡模型:
L=L(Y,Y)+[1-L(Y,Y)]""""""""""""""" (5)
L(y,)=|y-|"""""" """"" (6)
L(x,y)=""" (7)
其中,L為總損失,L為平均絕對誤差損失,y為樣本i的真實標簽,為模型對于樣本i的預測標簽,N為樣本總數(shù),L為結構相似性損失,μ和μ分別為x和y的方差,σ和σ分別為x和y的標準差,σ為x和y的協(xié)方差,c和c是用來維持穩(wěn)定的常數(shù),Y為去霧圖像,Y為真實無霧圖像。
3 指針式儀表檢測與讀數(shù)識別
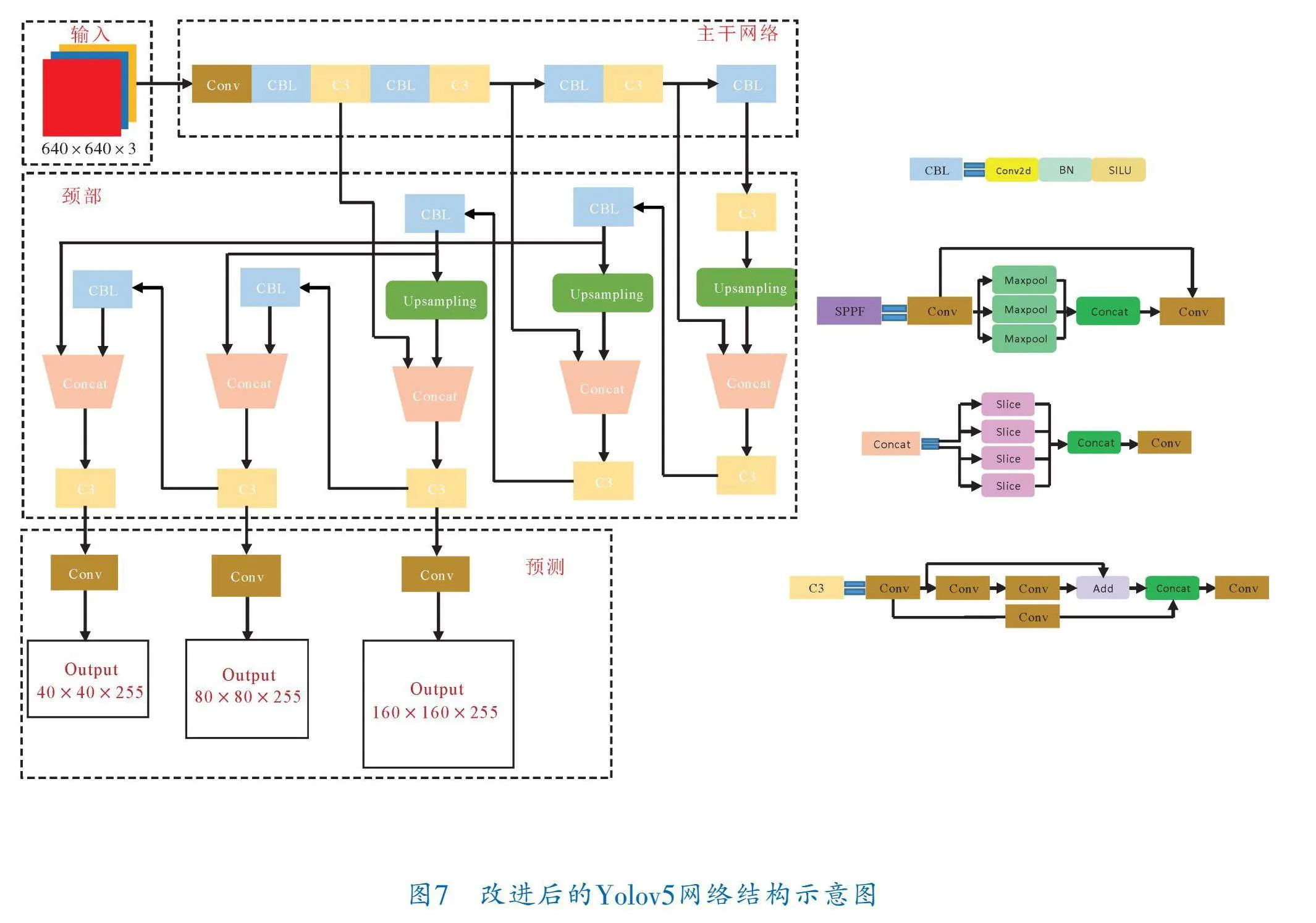
針對現(xiàn)有的指針式儀表檢測算法不能精準識別小目標,以及讀數(shù)識別模塊效率不高且準確率低的問題,筆者對目標檢測算法Yolov5進行改進,用較小的檢測頭替代原始檢測頭,提高檢測小目標的能力。并引入一個空間轉換模塊,將檢測到的儀表圖像校準到人類視覺范圍內正常的圖片。此外,創(chuàng)建了一個統(tǒng)一的框架,將儀表成分檢索和儀表讀數(shù)識別結合在一起,模擬端到端的文本檢測器。
3.1 儀表檢測模型
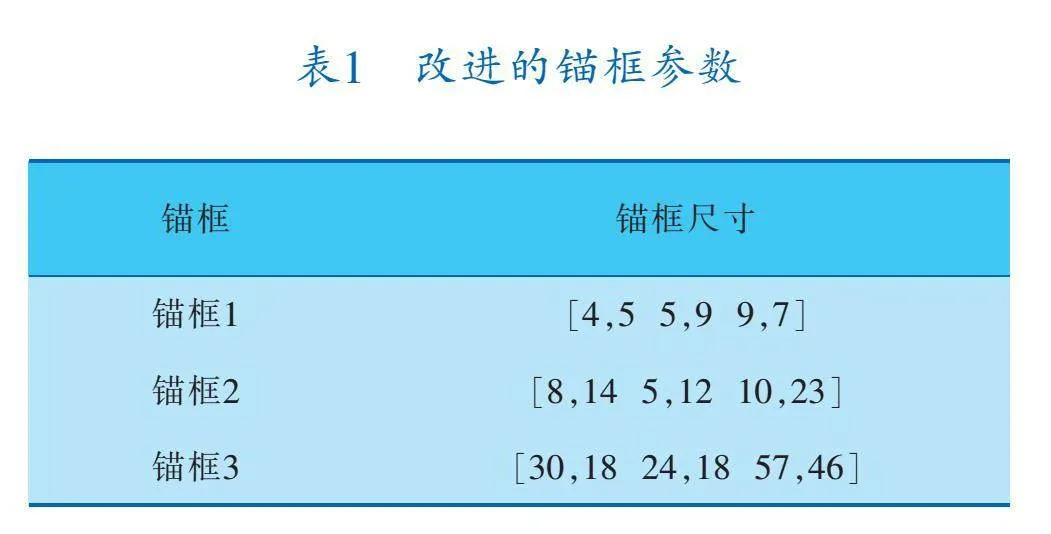
在應用Yolov5算法進行指針式儀表檢測時,可能會面臨從巡檢機器人視角檢測小目標的挑戰(zhàn),例如漏檢或檢測性能不佳的問題。盡管Yolov5的默認檢測頭能夠勝任多尺度目標檢測任務,但在小目標檢測方面可能表現(xiàn)不佳。直接添加專門用于小目標檢測的檢測頭可能會增加模型參數(shù)數(shù)量、降低推理速度,并且可能對整體檢測性能造成負面影響。因此,通過改變Yolov5中的3個檢測頭大小,并設置相應的先驗框尺寸,以解決上述問題。
為了匹配檢測頭大小的更改,先驗框的錨框尺寸必須進行調整,以提高對小目標的檢測性能。先驗框的錨框尺寸設置見表1。經(jīng)過修改的小目標檢測頭能夠更好地聚焦于特征圖中的小目標特征,并對小目標更敏感。改進后的Yolov5網(wǎng)絡結構如圖7所示。
3.2 空間轉換模塊
因為受到定位模塊的限制以及拍攝視角的影響,將檢測到的儀表圖像直接傳遞給讀數(shù)識別模塊進行讀數(shù)識別通常效果不佳。傳統(tǒng)的方法是采用透視變換來校準相機角度,以獲取正視圖圖像。然而,這種方法的計算時間較長且不夠穩(wěn)健。為了克服此問題,筆者引入了一個更高效、更強大的空間轉換模塊[9],它可以更高效地對齊儀表,將裁剪的儀表圖像轉為更符合人類視覺的正視圖圖像。
3.3 讀數(shù)識別
先前的讀取儀表的方法通常是讀取儀表的指針、刻度和數(shù)字,但這些方法往往會創(chuàng)建獨立的模塊來處理不同的組件和數(shù)字,導致讀數(shù)識別效果不佳。為此,筆者創(chuàng)建了一個數(shù)值獲取模塊,它由一個儀表組件檢索分支和一個儀表數(shù)字識別分支組成,以探索它們之間的深層關系,整體結構如圖8所示。
受Mask R CNN[10]的啟發(fā),筆者使用語義分割方法來檢索儀表指針和關鍵刻度。該分支通過對主干特征執(zhí)行兩個不同的1×1卷積操作,生成1通道的指針圖和關鍵刻度圖,如圖9所示。指針圖用于指示儀表指針的位置,而關鍵刻度圖則指示儀表指針的角度。
3.4 損失函數(shù)
總體損失函數(shù)可以計算如下:
L=L+L+L"""" (8)
其中,L表示儀表組件檢索分支損失,L表示關鍵字檢測損失,L表示關鍵字識別損失。
儀表組件檢索分支主要生成指針圖和關鍵刻度圖,這兩個分割圖均通過最小化Dice損失來進行訓練,具體如下:
L=1-"" (9)
L=1- (10)
其中,下標PointerMap表示指針圖,下標KeyScaleMap表示關鍵刻度圖,P(i)表示預測結果中第i個像素的值,G(i)表示真實標簽區(qū)域中第i個像素的值。
儀表組件檢索分支的最終損失是指針圖和關鍵刻度圖的權重組合,由(0,1)范圍內的λ進行平衡:
L=λL+(1-λ)L(11)
將λ設置為0.4。因為在訓練過程中,關鍵刻度圖空間占用較小,相對較難學習,因此將更多的重要性分配給關鍵刻度圖。
儀表數(shù)字識別分支的損失包括關鍵字檢測損失和關鍵字識別損失。其中,關鍵字檢測損失可以表述為:
L=(-pln p-(1-p)ln(1-p)) (12)
其中,‖·‖表示集合中的元素數(shù)量,p是預測像素,p是實際標簽,Ω為正樣本數(shù)量。
關鍵字識別損失可以表示為:
L=-ln p(y|x)""" (13)
其中,N′是輸入圖像中數(shù)字區(qū)域的數(shù)量,y是識別標簽,p(y|x)是條件概率。
4 實驗驗證
4.1 實驗設置
本研究的實驗環(huán)境為Python 3.8、PyTorch 1.11和CUDA 11.3。所有網(wǎng)絡在NVIDIA GeForce RTX4090 GPU上訓練,周期設置為300。在訓練之前,對所有圖片進行尺寸調整,使其大小統(tǒng)一為640×480。使用Adam優(yōu)化器,并將動量設置為0.9,批次大小設為16。初始學習率設置為10-4,在訓練過程中將學習率逐步降低到10-6。
4.2 圖像去霧實驗
使用峰值信噪比(PSNR)和結構相似性指數(shù)(SSIM)來評估去霧網(wǎng)絡的性能。這兩個指標通常用于量化去霧圖像恢復的質量。PSNR值越高,代表重建性能越好;SSIM值越大,代表失真越少。
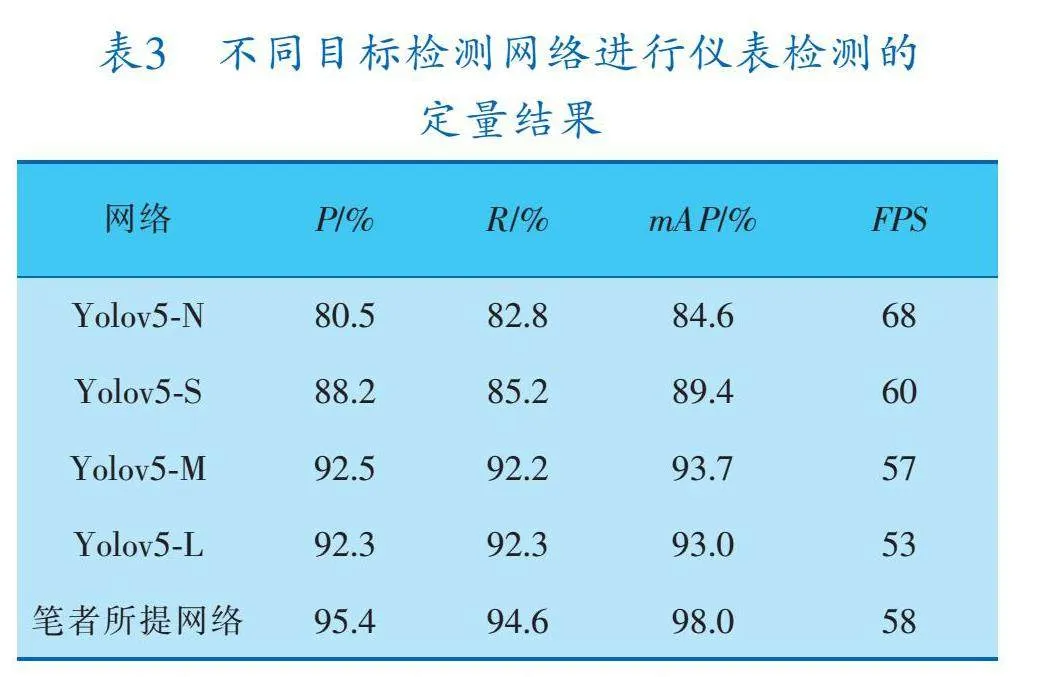
在指針式儀表圖像中添加不同濃度的霧霾,對筆者提出的基于FFA Net的圖像去霧算法與DCP[11]、AOD Net[12]、FFA Net、SGID PFF[13]進行比較。表2為不同去霧算法在霧天合成數(shù)據(jù)集上的定量比較結果,圖10展示了不同算法的去霧結果。從圖中可以看出,經(jīng)DCP和AOD Net去霧后的圖片出現(xiàn)了嚴重的色彩失真。FFA Net和SGID PFF在霧濃度越來越高的情況下,依然有大量霧殘留。相比之下,筆者提出的去霧算法在不降低圖像亮度的情況下能夠有效地將霧去除,去霧效果最好,與真實圖像最為接近。
4.3 指針式儀表檢測與讀數(shù)識別實驗
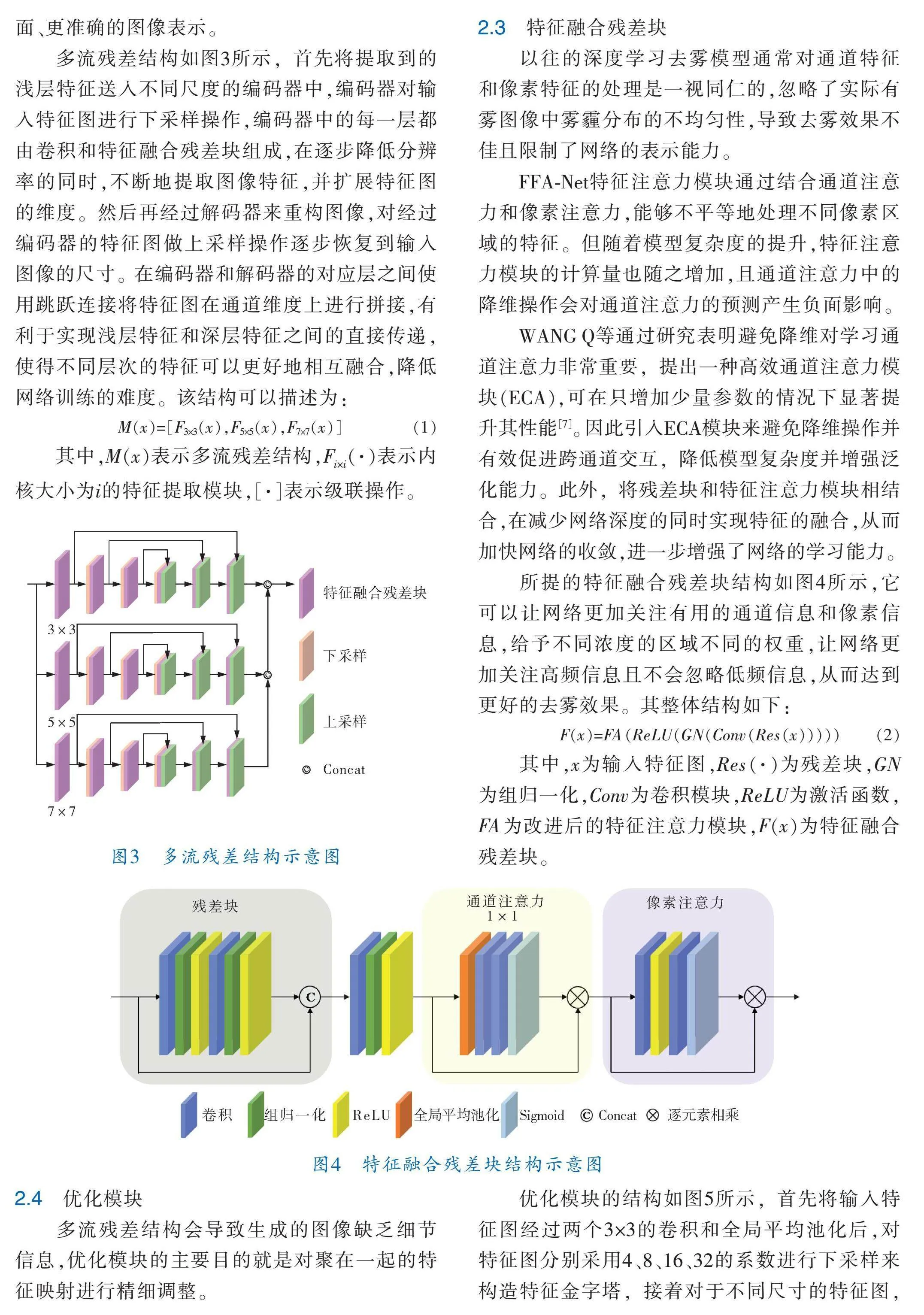
采用了一些目標檢測中常用的性能指標來評價改進后的模型性能,這些指標包括精確度P、召回率R、平均精度mAP和每秒幀數(shù)FPS。不同目標檢測網(wǎng)絡進行儀表檢測的定量結果見表3。
由表3可知,與原始幾種Yolov5相比,筆者提出的目標檢測網(wǎng)絡獲得了更好的檢測精度。例如,與Yolov5 M相比,筆者所提網(wǎng)絡的mAP提高了4.3%,R提升了2.4%。圖11展示了Yolov5 S與筆者所提的檢測網(wǎng)絡的定性比較結果,其中邊界框表示指針式儀表。可以看出,Yolov5 S對于小目標的檢測不盡如人意,如圖11a第2行右圖,Yolov5 S未能將小的指針式儀表檢測出來。相比之下,筆者提出的網(wǎng)絡能夠檢測出不同形狀和大小的儀表。
如圖12所示,無論相機角度如何,空間轉換模塊都能夠輕松自動地將圖像轉換為正視圖圖像。但是,在一些極大相機角度下,將儀表圖像轉換為正視圖圖像仍然存在挑戰(zhàn)。
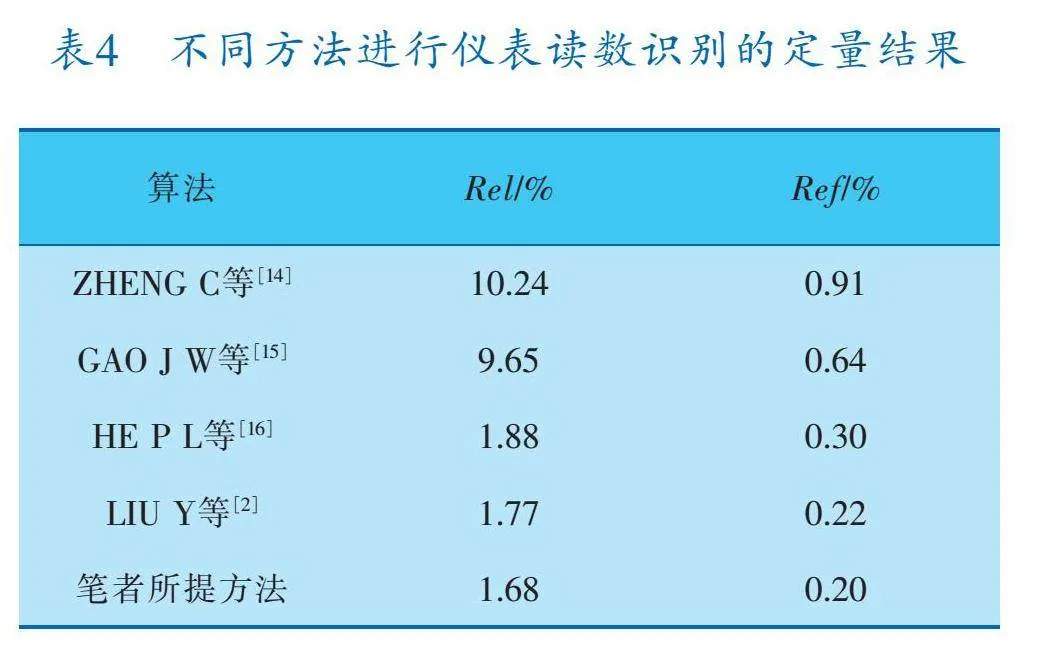
在指針式儀表讀數(shù)識別中,選擇了平均相對誤差Rel和平均參考誤差Ref作為評估指標[2],其值越小代表效果越好。不同方法進行儀表讀數(shù)識別的定量結果見表4,可以看出筆者所提方法要優(yōu)于其他方法。圖13展示了筆者所提方法的可視化結果。
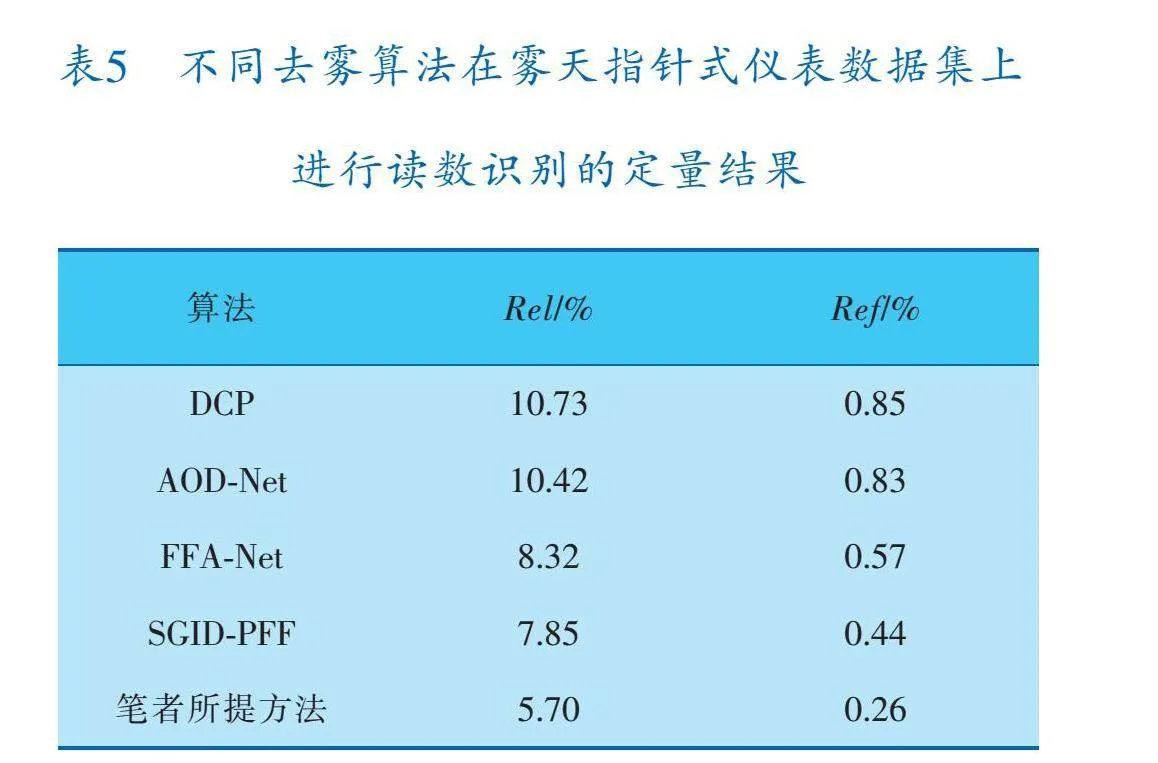
4.4 霧天指針式儀表檢測與讀數(shù)識別實驗
表5為經(jīng)過不同去霧算法去霧后對霧天環(huán)境下捕獲的指針式儀表進行檢測與讀數(shù)識別的結果,可以看出,經(jīng)筆者提出的去霧算法去霧后讀數(shù)識別準確率最高,表明所提的去霧算法對提升霧天環(huán)境下的指針式儀表檢測與讀數(shù)識別的準確率有顯著的效果。圖14展示了經(jīng)過筆者所提方法進行檢測與讀數(shù)識別的結果。
5 結束語
筆者所提方法有效地解決了油田現(xiàn)場巡檢機器人在霧天環(huán)境下對指針式儀表的漏檢和讀數(shù)識別準確率低的問題。然而,除了霧天環(huán)境外,雨雪、低光照等復雜環(huán)境也會對儀表檢測與讀數(shù)識別的準確率造成影響。未來的研究方向將著重優(yōu)化指針式儀表在雨雪、低光照等復雜環(huán)境下的檢測與讀數(shù)識別算法,以提升算法在復雜環(huán)境下的泛化能力。
參 考 文 獻
[1] 朱斌濱.雨霧環(huán)境下變電站指針式儀表識別方法[D].長沙:長沙理工大學,2021.
[2] LIU Y,LIU J,KE Y C.A detection and recognition system of pointer meters in substations based on computer vision[J].Measurement,2020,152:107333.
[3] WU X,SHI X B,JIANG Y C,et al.A High Precision A "utomatic Pointer Meter Reading System in Low Light Environment[J].Sensors,2021,21(14):4891.
[4] LIU Z,HUANG H,WANG N,et al.A pointer meter re "ading recognition method based on improved ORB algorithm for substation inspection robot[J].Journal of Physics:Conference Series,2022,2189(1).DOI:10.1088/1742 6596/2189/1/012027.
[5] WANG L,WANG P,WU L H,et al.Computer Vision B "ased Automatic Recognition of Pointer Instruments:Data Set Optimization and Reading[J].Entropy,2021,23(3):272.
[6] QIN X,WANG Z L,BAI Y C,et al.FFA Net:Feature Fusion Attention Network for Single Image Dehazing[J].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):11908-11915.
[7] WANG Q,WU B,ZHU P,et al.ECA Net:Efficient cha "nnel attention for deep convolutional neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2020:11534-11542.
[8] ZHAO H,GALLO O,F(xiàn)ROSIO I,et al.Loss Functions for Image Restoration with Neural Networks[J].IEEE Transactions on Computational Imaging,2017,3(1):47-57.
[9] SHU Y,LIU S,XU H,et al.Read Pointer Meters Based on a Human Like Alignment and Recognition Algorithm[C]//CCF National Conference of Computer Applications.Singapore:Springer Nature Singapore,2023.
[10] HE K,GKIOXARI G,DOLLR P,et al.Mask R CNN[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2017:2961-2969.
[11] HE K M,SUN J,TANG X O.Single Image Haze Removal Using Dark Channel Prior[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(12):2341-2353.
[12] LI B Y,PENG X L,WANG Z Y,et al.Aod net:All in one dehazing network[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,2017:4770-4778.
[13] BAI H R,PAN J S,XIANG X G,et al.Self Guided Image Dehazing Using Progressive Feature Fusion[J].IEEE Transactions on Image Processing:A Publication of the IEEE Signal Processing Society,2022,31:1217-1229.
[14] ZHENG C,WANG S R,ZHANG Y H,et al.A robust a nd automatic recognition system of analog instruments in power system by using computer vision[J].Measurement,2016,92:413-420.
[15] GAO J W,XIE H T,ZUO L,et al.A robust pointer m eter reading recognition method for substation inspection robot[C]//2017 International Conference on Robotics and Automation Sciences(ICRAS).Piscataway,NJ:IEEE,2017:43-47.
[16] HE P L,ZUO L,ZHANG C H,et al.A value recognit "ion algorithm for pointer meter based on improved Mask RCNN[C]//2019 9th International Conference on Information Science and Technology(ICIST).Piscataway,NJ:IEEE,2019:108-113.
(收稿日期:2024-05-15,修回日期:2024-10-25)
The Method for Pointer Instrument Detection and Reading Recognition in Foggy Conditions
WU Pan chao, YANG Peng, SUN Dian yang, YANG Ming hao
(School of Electrical and Information Engineering,Northeast Petroleum University)
Abstract"" Aiming at the oilfield inspection robots’ missed detection and low recognition accuracy of the pointer instrument in foggy weather, a method which combining FFA Net dehazing network and Yolov5 detection algorithm was proposed. Firstly, it has a FFA Net algorithm improved for the foggy images and has the multi scale structure and the feature fusion residual block and optimization module based to effectively enhance the algorithm′s performance in dehazing operation; and then, as for the instrument detection and reading recognition, it has a smaller detector head adopted to improve Yolov5’s ability in detecting small targets, and has a spatial transformation module introduced to convert the dial’s images detected into a front elevation in line with human perception; finally, it has an end to end framework created to tightly couple the meter component retrieval and meter reading recognition so as to improve the accuracy of meter readings. The experimental results show that, the proposed method boasts good robustness in the oilfield foggy environment, and it improves both accuracy of detection and reading recognition of the pointer meter in foggy environment.
Key words"" image dehazing, Yolov5, instrument detection, instrument recognition
