一種基于云計算的關聯規則改進研究
2015-12-15 07:47:00劉姜
電子設計工程 2015年10期
劉姜
(撫順職業技術學院 信息工程系,遼寧 撫順113006)
一種基于云計算的關聯規則改進研究
劉姜
(撫順職業技術學院 信息工程系,遼寧 撫順113006)
隨著數據挖掘技術的成熟,其中關聯規則在大規模數據中的應用成為了目前的熱點。為了提高在大規模數據下進行數據挖掘的效率,在MapReduce中通過引入歸并函數Fusion來提高執行剪枝任務的效率并進行了優化研究,提出了一種基于云理論的關聯規則Apriori算法,詳細論述了實現的過程以及關鍵技術。通過實驗表明,該方法取得了良好的實驗效果,克服了Apriori算法耗時多、識別率低下等問題,是實現在大規模數據進行數據挖掘的實用工具。
MapReduce;數據挖掘:關聯規則;Apriori算法
數據挖掘是由半自動化或自動化的計算器工具對資料存儲庫中的海量資料進行有條理且可重復的探索與分析的過程,對研究人員與知識需求者來說,其主要目的在于發掘出未知的、新穎的、有價值的、可利用的知識與規律。通過這些知識與規律,人們可以預測未來可能發生的結果。
數據挖掘作為一個新型智能資料分析技術,與傳統分析技術“假設-收集-檢驗"的不同點在于,其使用“發現-匹配"等算法來獲取資料之間的有價值關聯。不同種類資?的涌現也導致數據挖掘技術經歷了多次變革,由原本的事務集數據挖掘轉向文件挖掘、多媒體挖掘、Web頁面集挖掘、時序氣象資料挖掘及三維結構DNA挖掘等。數據挖掘與以往的數據庫查詢也有相當程度的不同,其處理目標在于分析海量且復雜的數據庫,其服務對象在于高級決策者,其主旨在于為高級決策者的決策提供有形且有力的數據支持。近年來,數據挖掘已成?各?同專業的研究熱點之一[1]。Apriori算法是數據挖掘技術中的經典算法,由于傳統的Apriori算法需要重復搜索數據庫來得到候選集,影響了其運行的效率和計算精度。隨著第四次IT產業革命的到來,云計算已成為大規模計算未來發展的方向,由Google提出的MapReduce編程框架是云計算中的核心技術之一,它適用于處理大規模數據集,計算效率非常高[2]。
針對傳統 Apriori算法性能差的特點,本文立足MapReduce框架使用云計算技術傳統的Apriori算法進行了改進,充分利用云計算的大數據存儲和計算的能力來提高Apriori算法的運行效率。
1 傳統的Apriori算法
傳統的Apriori算法是在海量數據庫中挖掘關聯規則最基本的算法,由數據庫專家是由Agrawal Rakesh等人在1994年所提出的[3]。該算法目的在于快速地尋找海量數據庫中的頻繁項集,是一種單維單層的布林關聯規則,與市場購物籃分析的結果相同。使用Apriori算法進行關聯規則挖掘時是利用支持度閾值來減少在尋找頻繁項集時,全部項所可能生成的候選項集組合個數,主要分為以下幾個步驟:
1)Apriori算法將先掃描一次整個事務集合,由此計算每一個項的支持度(出現頻率)。該動作結束后,根據預設的最小支持度閾值(min_sup)限制,便可得到所有頻繁項集的集合F1;
2)循環依序選取上一步經迭代所得到的頻繁(K-1)項集,進而產生新的候選K項集;
3)Apriori算法須將重新再掃描整個事務集合一次,該動作是為了要重新計算新候選K項集的支持度計數 (出現次數)。接著,通過子集函數subset()來確定包含在每一個事務ti中的CK所有候選K項集;
4)經過計算候選K項集的支持度計數(出現次數)后,Apriori算法將剔除支持度計數少于最小支持度計數閾值(N*min_sup)的候選K項集。該動作是為了要從候選K項集中選取所有的頻繁K項集;
5)當計算到FK=Φ時,這意味沒有新的頻繁項集能夠產生。此時,Apriori算法產生頻繁項集的部份計算結束;
6)輸出頻繁K項集集合的結果。
Apriori算法的偽代碼如下:

2 優化M apReduce框架
MapReduce是目前非常流行的分布式計算架構主要是通過網絡來處理在云端上儲存的大量數據[4]。將要執行的MapReduce程序復制到 Master node以 及各個Worker,Master node會決定要給哪臺WorkerWorker去執行Map程序或者Reduce程序。通過Map程序將數據切成許多區塊,經過Map階段產生出 Key/Value,將此 Key/Value存儲在 Local disc,然后經過Shuffle(將相同屬性的key排序在一起)。而Reduce程序將這些Shuffle后的結果進行整合,最再將產生出來。
由于MapReduce只能對單個數據集合進行操作的情況下去執行,對于Apriori算法中需要進行剪枝操作(也就是再次訪問讀取數據庫中的事務記錄),會導致計算效率會下降。這就需要對MapReduce框架進行優化。我們引入了一個歸并函數Fusion,用于將候選項集合中不需要二次讀取數據庫性質的項集進行刪除。Fusion函數的流程如圖1所示。
圖1 Fusion函數流程圖Fig.1 Flow chart fusion function
3 云計算下改進的Apriori算法
在改進后的MapReduce計算框架基礎上,提出了基于此框架的關聯規則Apriori算法,稱為動態數據分配Apriori算法(DDAS:Dynamic Data Apriori Scheduler)。算法的主要思想是:將Apriori算法中關于頻繁集和項集的計算部署到云計算環境下執行,同時采用改進的MapReduce計算框架,簡化了任務執行的復雜度,提高系統響應時間,并且控制剪枝任務的數量避免引起任務抖動[5]。
1)Map函數從數據庫中讀取文件記錄[6],并將這些事務記錄保存為項集,同時判斷是否可以進行連接,不能進行連接的舍棄,從而產生頻繁集的一個列表。同時,Map函數將輸入的數據切割成固定大小,并記錄下頻繁集中的所有記錄在數據庫中出現的頻度,最后將產生的候選集結果當做中間結果返回。
2)MapReduce框架中的節點會選擇Mapper對讀取的表進行遍歷,然后將預處理得到中間結果輸出給Reducer,并將最終得到的結果進行存儲。
3)對于Apriori算法存在剪枝任務須再次讀取數據的特性,我們采用自身合并(self-Fusion)操作,引入Fusion函數。Fusion函數基于最小支持度和Apriori性質(任何非頻繁項集的子集都不可能是頻繁項集的子集)對項集進行壓縮,計算出頻繁項集集合,刪除掉候選項集中不符合Apriori性質的項集。如果此時項集已經為空(即處理完成),則將結果保存到數據庫上并輸出去給用戶;否則,執行2)[7-9]。
4 實驗及分析
在局域網內使用4節點的集群環境,每個節點的配置相同,CPU是酷睿2 1.83 GHz,內存2 G;千兆以太網卡。操作系統是Ubuntu Linux 13.10,Java環境為 JDK 1.7,Hadoop版本是0.20.2,HBase版本為0.90.1,配置好MapReduce的分布式計算環境。使用來自于加里福利亞大學提供的一個公用數據集進行測試,這個數據集記錄了某血液中心獻血者的一些數據,我們選擇其中呢 40人的數據作為實驗樣本。
在Eclipse平臺下編寫了改進版本的Apriori算法與傳統的Apriori算法測試結果進行比較,結果如圖2所示。

圖2 所用時間趨勢Fig.2 Diagram of time trend
通過改進版本的Apriori算法,所使用的時間如圖2所示,較傳統的特征方法有明顯的減少,以40人的樣本數為例,改進版本的Apriori算法所用時間為Apriori算法的1/3。
本文將網絡環境下的數據識別作為必要手段,統計了處理前后隨著樣本數變化在識別率方面的差異,如圖3所示。實驗結果表明使用改進版本的Apriori算法能夠有效提升數據的識別率,以40人的樣本數為例,傳統的Apriori算法識別率為73%,而改進版本的Apriori算法的識別率為91%,在識別率方面提升了18%。
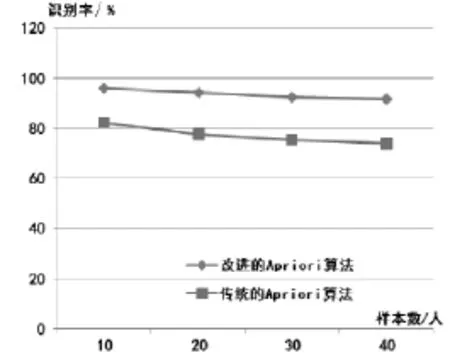
圖3 識別率的差異Fig.3 Diagram of recognition rate
5 結束語
文中通過對傳統的關聯規則Apriori算法進行分析,在現有的云計算框架MapReduce的基礎上進行改進,提出了一種新的關聯規則改進Apriori算法,通過利用云計算的高速數據處理能力來解決傳統關聯規則Apriori算法性能較差的缺點。實驗表明,該算法簡單易實現,所需時間大幅降低,能夠有效提高關聯規則Apriori算法的運算效率。
[1]韓家煒.數據挖掘[M].北京:機械工業出版社,2009.
[2]陳康,鄭緯民.云計算:系統實例與研究現狀[J].軟件學報,2009,20(5):1337-1348.CHEN Kang,ZHENG Wei-Min.Cloud Computing:System Instances and Current Research[J].Journal of Software, 2009,20(5):1337-1348.
[3]邵峰晶,于忠清.數據挖掘原理與算法[M].北京:中國水利水電出版社,2003.
[4]鄭啟龍,房明,汪勝,等.基于MapReduce模型的并行科學計算[J].微電子學與計算機,2009,26(8):13-17.ZHENG long,FANG Ming,WANG Sheng,et al.Scientific parallel computing based on mapReduce model[J].Microel Ectronics&Computer,2009,26(8):13-17.
[5]Apache基金會.Hadoop[EB/OL].(2009)[2014].http://lucene.apache.org/hadoop/.
[6]王鄂,李 銘.云計算下的海量數據挖掘研究[J].現代計算機(專業版),2009,10(11):22-25.WANG E,LI Ming.Research on mass data mining under cloud computing[J].Modern Computer,2009,10(11):22-25.
[7]劉華元,袁琴琴,王保保.并行數據挖掘算法綜述[J].電子科技,2006,9(1):65-73.LIU Hua-yuan,YUAN Qin-qin,WANG Bao-bao.Review of the parallel data mining algorithm[J].Electronic science and technology,2006,9(1):65-73.
[8]李志堅,莫建麟.一種改進的基于概念格的數據挖掘算法[J].重慶師范大學學報:自然科學版,2013(2):92-95.LI Zhi-jian,MO Jian-lin.An improved concept lattice-based data mining algorithm[J].Journal of Chongqing Normal University:Natural Science,2013(2):92-95.
[9]朱德利.基于Weka的就業數據分析和模式挖掘--以重慶市信管專業為例 [J].重慶師范大學學報:自然科學版,2014(4):120-125.ZHU De-li.Employment data analysis and pattern mining based on Weka--take specialty of information management and information system in chongqing for example[J].Journal of Chongqing Normal University:Natural Science,2014(4):120-125.
An improved association rules based on cloud computing
LIU Jiang
(Department of Information Engineering,Fushun Vocational Technology Institute,Fushun 113006,China)
With the mature of data mining technology,including the application of association rules in large scale data has become the current hot spot.In order to improve the efficiency of data mining,in MapReducethe is introduced Fusion function and optimized,the Apriori algorithm based on Cloud was designed,the process and key technology was discussed in details.Experiments show that this method has obtained the good experimental effect,overcomes the Apriori algorithm is time-consuming and low recognition rate,It is a practical tool that realizing the data mining.
MapReduce;data mining;association rule;Apriori algorithm
TN919.5
A
1674-6236(2015)10-0048-03
2014-10-26 稿件編號:201410191
劉 姜(1980—),男,遼寧昌圖人,講師。研究方向:計算機網絡應用與安全。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
