基于非負矩陣分解特征提取的垃圾郵件過濾
2010-03-06 09:36:04劉遵雄
華東交通大學學報 2010年6期
陳 俊,劉遵雄
(華東交通大學信息工程學院,江西南昌 330013)
1 研究概況
垃圾郵件一般是指沒有經過用戶許可,卻被強塞到用戶郵箱的電子郵件。隨著電子郵件成為人民生活中交流的一個主要方式,垃圾郵件也不斷的泛濫起來,它對我們的危害也越來越大。其危害主要表現在以下幾個方面:垃圾郵件的大量的存在占用了很大的網絡帶寬,甚至可能堵塞網絡帶寬,使網絡傳輸效率降低,并且還占用了存儲空間;有的垃圾郵件還會侵害別人的隱私權,給了黑客有可乘之機;垃圾郵件給世界的經濟造成了巨大的損失;有些垃圾郵件還會蠱惑人心,騙人錢財,傳播色情等不健康內容的垃圾郵件,從而會對現實社會造成危害,尤其是對青少年的危害很大。因此,垃圾郵件過濾技術的研究成為一個急需解決的問題。
早期的垃圾郵件過濾技術主要是基于規則的技術,并且這些規則都是人工預先制定的,對郵件進行模式匹配過濾技術。若在郵件中找到屬于垃圾郵件關鍵字的個數達到一定閥值則判定此郵件為垃圾郵件。基于規則的過濾技術有以下幾個缺點:首先,其自身的工作原理決定了這種過濾技術總是滯后于垃圾郵件的出現。例如,新的垃圾詞匯出現,規則庫中沒有就不能準確過濾。其次,它是一種生硬二值判斷,缺少可信的知識和模糊的判斷。再次,系統需要用戶定制自己的規則庫,這就對用戶有較高的要求,同時需要用戶花大量時間更新規則,如果用戶興趣發生變化,這些規則也要進行很大變動,因此這種過濾技術不利于在普通用戶中推廣。還有,為避免郵件中出現垃圾詞匯而被過濾掉,垃圾郵件發送者常常對某些關鍵詞做個變形,就能輕易騙過過濾器。
隨著模式識別和機器學習的不斷發展,現在大多數的垃圾郵件過濾技術都是自動構建過濾模型和對垃圾郵件進行分類。目前大多數的垃圾郵件分類方法都是原先通用的文本分類方法,分為基于規則的方法和基于內容的分類方法兩大類。主要有貝葉斯方法、支持向量機、KNN方法、邏輯回歸方法、決策樹方法等。
由于垃圾郵件是高維的數據,直接對高維數據進行分類的話很容易發生維數災難和錯分的問題。因此,對高維數據進行降維顯得很重要。現在主要的降維方法有特征提取和特征選擇兩種方法。特征選擇是通過一些標準的統計方法選擇出對分類貢獻最大的若干特征,常用的有文檔頻率、χ2統計和信息增益等方法;而特征抽取是將原始的特征空間投影到低維特征空間,投影后的二次特征是原始特征的線性或者非線性組合。常用的方法有主要成分分析、Fisher線性判別分析、非負矩陣分解等。
本文使用的降維方法是非負矩陣分解,非負矩陣分解方法首先把原始的實驗數據分解成B和C數據矩陣。而B*C正是原始數據的另外一種相似的表達。B代表了原始數據的一個新的基坐標,并且這個基坐標的維數遠小于原始數據的維數。而C是原始數據在新的基坐標B上的投影數據,也可以理解為在B上的權值系數。因此我們可以把對原始的高維的垃圾郵件分類的問題轉化為對 C進行分類的問題。而C是一個低維的數據,所以在對它進行分類的時候有很多的優點,并且也很容易對它進行準確的分類。然后再用支持向量機,邏輯回歸和核邏輯回歸方法對分解之后的數據進行分類。
2 特征降維方法
2.1 特征提取
(1)非負矩陣分解(NMF)。NMF是一種常常用來分解和降維的方法,該方法是通過構造B和C來實現維度的降低。該算法的數學表達式是 V≈BC,它的基本思想是對非負的原始數據進行非負的分解。并且在功能上它基本上實現了對大腦的基于部分感知功能的模擬分析;在它的算法中它采用簡單有效的迭代規則很好的保證了分解后數據的非負性;在應用上,非負性的數據大量的存在,且非負分解的結果具有明確的物理含義,作為一種低秩逼近的算法,它能有效的節約存儲空間和計算資源。
為了實現矩陣的非負性的分解,首先需要定義一個差異函數來描述分解前后的逼近程度,然后才在非負性約束條件下求解.。最早提出的非負矩陣分解方法采用傳統的梯度下降算法與加性迭代規則。有時也采用乘性迭代規則,更適合非負分解的特點,也就是在非負性初始化的基礎上,在迭代過程中能簡單地保持非負性,而加性迭代規則中就需要一個強制性的將負值變為零的步驟。
將矩陣分解看成如下含加性噪聲的線性混合體模型

其中X代表是原始的數據,B和C代表是分解之后的結果,而n和m代表原始矩陣有n行m列,r代表分解之后的行數,E代表的是原始的數據和分解后的結果之間的差距,也就是損失數據。一般情況下r的選擇要滿足(n+m)*r<n*m,因為只有這樣才可以保證分解之后的B和C的維數小于原始矩陣的維數。從上面的公式可以看出可以把B看成是對原始矩陣X的一組線性的逼近基向量,而 C就可以看成是在基向量B上面的投影系數或者投影權值。這樣的話就實現了用少量的基向量來表示大量的高維數據,也就是發現了原始數據之間的潛在關系。并且可以取得很好的逼近效果。
于是原先的問題就轉化成了如何求解B和C。下面是求解B和C的過程。為了求解出B和C的數值,一般是通過最大似然法來求解。它的過程如下

假設噪聲服從的是不同的概率分布,就可以得到不同類型的目標函數.考慮噪聲是高斯噪聲,也就是
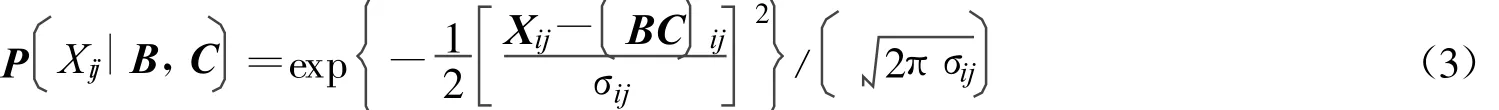
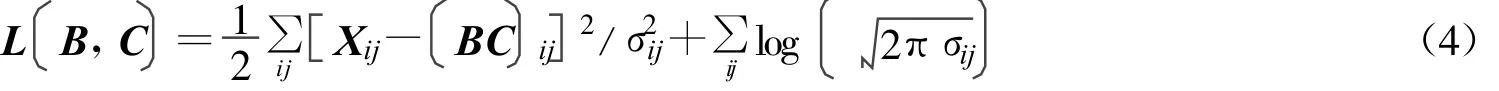
因為要得到的解是一個局部的最優解,所以就需要對上式進行求導。分別對B和C進行求導就可以得到

從而最大似然解就是下面的損失函數
而這也就是在優化過程中不斷的迭代公式,經過一定次數的迭代之后就會發現它的結果會最終趨于某一個值,而這個值也就是所要求的局部的最優解。
(2)主要成分分析(PCA)。PCA是一種常用的特征提取的算法,也稱為K2L變換。PCA是將多個變量通過線性變換以選出較少個數重要變量的一種多元統計分析方法。它在人臉識別領域得到了廣泛的應用,并且提出了特征臉的概念。它首先通過求解原始數據矩陣X減去它平均值之后的協方差矩陣,然后求解協方差矩陣的特征值和特征向量。最后按照特征值絕對值的大小對它所對應的特征向量進行排序,選擇出前面幾個最大特征值所對應的特征向量作為主要成分。因為對應最大特征值的特征向量能夠反映數據的最大相異性。
(3)偏最小二乘(PLS)。PLS是1983年被提出來的一種綜合考慮自變量對因變量的一種回歸建模的方法。它的基本思想是,分別在X和Y中提取他們各自的潛在變量t和u,即分別對X和Y進行線性化。并且要求t和u應盡可能的攜帶它們各自數據表中的變異信息,并且 t和u之間的相關程度應該最大。這樣依次對X和Y進行最大差異潛在變量的提取,直到達到滿意的精度為止。
2.2 特征選擇
特征選擇也是一種常見的特征降維方法,它是從原始眾多的屬性和特征之中根據具體的方法選擇出一些對分類或者表現差異貢獻大的特征,并且選擇出來的特征是原始特征的真子集。在剛開始的文本預處理階段都會用到特征選擇的方法。常見的特征選擇的方法有:度量詞條w和文檔類別c之間的相關程度的CHI方法;選擇有效的特征進行相關反饋的幾率比方法;計算特征權值的方法;構造樹結構模型的方法和信息增益等方法。
3 垃圾郵件分類算法和技術
目前存在著很多垃圾郵件的分類方法,其中包括支持向量機方法,貝葉斯方法,KNN,Ripper方法,決策樹和邏輯回歸等方法。這里主要采用的方法是支持向量機,邏輯回歸和核邏輯回歸方法。
3.1 支持向量機(Support Vector Machine,SVM)
SVM是一種在機器學習領域比較流行的分類算法,它不但有很好的性能比并且可以通過它特有的核函數來處理高維的數據。所以它在處理二元分類的問題上有很大的優點,該算法是通過構造一個最大間隔的最優分類超平面來實現分類的目標。由于SVM的求解最后轉化成二次規劃問題的求解,因此SVM的解是全局唯一的最優解。
3.2 邏輯回歸(Logistic Regression,LR)
邏輯回歸模型是1920美國學者柏爾和利德(Robert B.Pearl and Lowell J.Reed)提出的,并開始用在人口估計和預測中推廣應用,并引起了廣泛的注意。邏輯回歸是研究因變量為二分類或多分類觀察結果與影響因素(自變量)之間關系的一種多變量分析方法,屬概率型非線性回歸。邏輯回歸根據因變量的取值類型不同,又可分為二項分類邏輯回歸、有序分類邏輯回歸和無序多項分類邏輯回歸,其中二項分類邏輯回歸是其他邏輯回歸的基礎。LR的建模過程本身就具有挑選變量的功能,即只有對因變量貢獻率達到一定程度的特征變量才能進入回歸模型中,對因變量沒有貢獻或者貢獻很小的特征變量最終會被剔除。由于Logistic回歸是非線性模型,因此最大似然估計法經常用于模型估計。
3.3 核邏輯回歸(Kernel Logistic Regression,KLR)
邏輯回歸是一種經典的利用線性模型估計的算法,屬于廣義線性模型方法中的一種,它不需要任何關于樣本分布的假設。由邏輯回歸模型的方法是一種線性的方法,所以它在解決一些非線性問題上有很多缺陷,因此就誕生核邏輯回歸。核邏輯回歸把支持向量機里面的核方法引入到邏輯方法里面。從而可以解決一些非線性的問題,核邏輯回歸經常使用的核方法有線性核函數,多項式核函數,RBF核函數和sigmoid核函數。
4 試驗結果
本文的垃圾郵件的試驗數據是從UCI機器學習知識庫上下載的。這里總共有4 601封電子郵件,其中包括1 813封垃圾郵件和2 788封非垃圾郵件。并且一般的Zero-rule分類方法采用這個數據的準確率只有60.6%左右。
從UCI機器學習知識庫中下載的數據是以文本形式存儲的,并且每篇郵件都有不同的長度。在這個數據的基礎上排除一些不相關和一些無關緊要的屬性之后,得到了轉換之后的實驗數據。
原始的郵件數據是不能被計算機識別的,因此需要選擇郵件數據中的某些有代表性的特征來表示原始的郵件數據。這里用57個屬性和一個是否為垃圾郵件的屬性來表示原來的垃圾郵件數據,其中57個屬性中的48個屬性是郵件中常用詞組,它們是make,address,all,3d,our,over,remove,internet,order,mail,receive,will,people,report,addresses,free,business,email,you,credit,your,font,000,money,hp,hpl,george,650,lab,labs,857,data,415,85,technology,1999,parts,pm,direct,cs,meeting,original,project,re,edu,table,and conference。除了這些詞組以外還有6個常用的標點符號,它們是;,(,[,!,$,and#。最后還有最后3個屬性是:平均每個句子有多少詞組;在郵件中最長的句子有多少詞組和郵件中總共包括多少詞組。最后的那個屬性中1代表垃圾郵件,0表示不是垃圾郵件。
本實驗主要采用支持向量機,邏輯回歸,核邏輯回歸3種方法來對實驗數據進行分類。第一部分是直接用上面的3種方法對垃圾郵件的數據進行分類,結果它們的分類準確率都只有61%左右。表1為直接用分類方法對垃圾郵件數據進行分類的結果。

表1 原始數據的分類準確率和時間
從上面的實驗結果可以看出,直接用分類方法對實驗數據進行分類的話,準確率只有61%左右。從實驗所用的時間來看,KLR所花的時間最長,因為它要把低維的數據投影到高維的空間再進行分類,所以它花的時間比其他的2個方法要多。
本實驗的第二部分是先用非負矩陣分解的方法對實驗數據進行分解之后,然后再用分類方法對分解之后的數據進行分類。為了更好的得出不同維度對原始數據的解釋能力,本文特意把原始的57維的實驗數據分解為5維,10維,20維,30維,40維。然后在上述分解之后的數據基礎上,分別用支持向量機,邏輯回歸和核邏輯回歸三種方法對它們進行分類。表2和表3分別為經過特征提取之后的分類準確率和分類時間表。

表2 特征提取之后的分類準確率
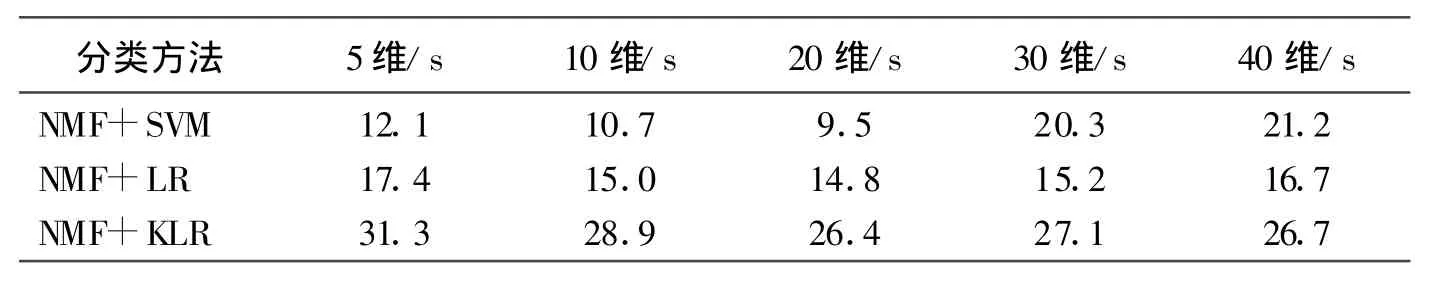
表3 特征提取之后的分類時間
從上面的實驗結果可以看出,分類的正確率呈現一個先升后降和分類時間減少的發展過程。這是由于維度過低不能完好的表達原始的所有特征,所以隨著維度的增高有一個分類準確率上升和時間縮短的發展階段。但是實驗所用的數據本身的維度不是很高,所以當達到20維左右就相似的表達了原始郵件的信息,因此正確率不再上升和時間不在縮短;并且隨著維度的增加有一個很小的遞減過程。比較表2和表1可以看出,經過非負矩陣分解特征提取之后的正確率比直接分類的方法有更高的分類準確率。其中以支持向量機提高的最多,提高了20%左右;比較表3和表1可以知道分類的時間縮短了一半左右。
表4是實驗的查全率對比的一個表格,其中前面幾列是經過NMF分解之后的結果,最后一列是沒有經NMF分解的實驗結果。

表4 幾種方法查全率的比較
從表4中可以看出,經過NMF之后的實驗數據比沒有經過NMF分解的數據有更高的查全率。
5 結論和今后的工作
通過上面的理論分析和試驗的結果可以知道,經過非負矩陣分解之后的數據不但實現了降維,而且還很好的保留了原始數據潛在的特征。這點可以從支持向量機的試驗中很清楚的看出,試驗結果表明經過非負矩陣分解之后的數據比原始的實驗數據有更高的分類正確率和查全率,并且縮短了分類的時間。因此它在今后的垃圾郵件的分類中會有很好的應用。
在今后的工作中將從以下幾方面作進一步研究:第一,郵件之間的潛在聯系好多時候都是非線性的,嘗試尋找一些非線性的特征提取方法。比如核偏最小二乘,核主要成分分析等;第二,在郵件處理中,一般來說,將一封正常郵件錯分為垃圾郵件的代價要遠遠大于將垃圾郵件分為正常郵件的代價,這種評價機制被稱為代價敏感評價機制。可嘗試在今后的工作中引入這種機制進行郵件過濾。
[1]張禾.邏輯回歸法在遙感數據特征選擇和分類中的應用[J].Science&Technology Association,2007,5(3):17-18.
[2]盛鵬.基于全文過濾的垃圾郵件防范機制[D].云南:西南大學,2006:40-45.
[3]曹兆龍.基于支持向量機的多分類算法研究[D].上海:華東師范大學,2007:15-17.
[4]陳治平,王雷.基于自學習K近鄰的垃圾郵件過濾算法[J].計算機應用,2005,25(12):7-8.
[5]趙向軍,路梅.垃圾郵件過濾算法研究[J].徐州師范大學學報,2006,24(5):52-55.
[6]劉維湘,鄭南寧,游屈波.非負矩陣分解及其在模式識別中的應用[J].科學通報,2006,51(3):241-250.
[7]GUILLAMET D,VITRIà J,SCHIELE B.Introducing a weighted non-negative matrix factorization for image classification[J].Pattern Recognition Letters,2003,24(14):2447-2454.
[8]李滔,王俊普,吳秀清.基于特征矢量集的核Logistic回歸[J].小型微型計算機系統,2007,27(6):980-985.
[9]喻軍.幾種典型特征抽取方法比較及其在人臉識別中的應用[J].江南大學學報,2009,8(5):543-546.
[10]王鵬鳴,吳水秀,王明文,黃國斌.基于偏最小二乘特征抽取的垃圾郵件過濾[J].中文信息學報,2008,22(1):74-79.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
