基于GPU加速的光線跟蹤體繪制算法研究
2010-03-16 07:43:40陳占芳張國玉師為禮任濤
長春理工大學學報(自然科學版) 2010年1期
關鍵詞:模型
陳占芳,張國玉,師為禮,任濤
(長春理工大學,長春 130022)
光線跟蹤體繪制算法是體繪制技術中的一種經典算法,傳統算法中所有的計算都在CPU上進行,重建速度較慢,無法達到實時效果。本文使用GPU編程技術,將原先在CPU中進行的場景求交和光線遍歷采樣等步驟,移入GPU中進行,利用GPU的高速浮點運算能力,來實現三維圖像的實時繪制。與在 CPU上實現光線跟蹤體繪制算法相比,速度大大提高。
1 GPU原理與光線跟蹤技術分析
GPU(Graphic Processing Unit),即圖形處理器,是顯示卡的核心。GPU使顯卡減少了對CPU的依賴,并進行部分原本CPU的工作,特別在三維圖像處理時,更能體現 GPU的浮點運算能力。但GPU的指令執行方式和CPU不一樣,無法直接實現遞歸,所以不能直接執行在 CPU中實現的算法。依據 GPU特性,本文把光線跟蹤表示成一種流計算模式,把可編程的 GPU抽象成通用的流處理器,充分利用了 GPU并行處理體系結構的性能優勢來實現算法。
實現基于流的光線跟蹤最大的難度是如何把光線跟蹤映射到設計的流計算模型中。GPU有很強的流處理能力,但實現遞歸非常困難。把光線跟蹤細分成多個內核,內核通過數據流聯系在一起。不管是靜態場景還是動態場景繪制,首先要確定光線跟蹤能夠處理的幾何體片元的類型和系統實現中所使用的加速結構的類型。光線跟蹤能夠渲染由不同幾何體片元組成的場景,其中最適合的是三角形。同時圖形硬件僅支持三角形渲染,其它表面形狀雖能使用,但在渲染之前它們都要被轉換成三角形。所以使用三角形來表示場景中幾何體。其次,建模程序和掃描軟件產生的模型都是由三角形網格組成的,當在場景中只有一種簡單圖形單元時,光線跟蹤會顯得更加簡單有效。對于流計算來說,場景中所有繪制可以被相同的內核集來處理,這種方式使系統的數據流得到簡化。
2 算法實現
光線跟蹤算法可以分解為兩大部分。一部分由CPU端來完成,主要負責整體計算的控制和平衡。另一部分則在GPU中,主要負責光線跟蹤的計算,這部分主要由四個類型的計算內核來完成。
2.1 CPU端控制
CPU用來進行算法的整體控制和計算平衡。
在 GPU上進行光線衍生技術時,會獲得一組反射和一組折射光線,整個計算過程是一個多路徑的復雜計算,在多個路徑之間進行切換需要CPU的控制。GPU無法對這些光線同時進行計算,這需要CPU對計算資源進行控制分配,即當光線生成或光線衍生產生光線時,將生成的光線壓入棧,由CPU來分配GPU計算資源。
另外,由于訪問存儲空間的限制,光線的遍歷和求交成為了算法實現最難解決的問題。為此,必須設計合適的遍歷加速結構來組織場景中的幾何基元數據。在經典的加速結構中,主要有兩種組織方式。一種以場景的幾何基元為中心,一種以場景的空間為中心。本文使用后一種,構建類 BSP的算法,同時為了提高效率,采取一組光線并行入棧的方式。
2.2 GPU端算法實現
在 GPU端進行光線跟蹤計算,使用一種基于流的光線跟蹤算法。整個框架由四個功能內核組成:光線生成、場景遍歷、模型求交、渲染和光線衍生。每一種對應于GPU中一個路徑的計算。
(1)光線生成:生成初始光線的起點和方向。
(2)場景遍歷:使用類二叉樹結構來組織場景,利用光線信息在整體場景的空間剖分結構中尋找可能需要進行光線求交的模型表面基元。
(3)模型求交:主要完成交點的探測及光線與表面基元的求交計算。
(4)渲染和光線衍生:利用 phone光照模型來進行光照計算,并將獲得值累加到幀緩存相關象素中。如果光線有交,就利用交點信息生成相應的反射或折射光線。必要時,也會生成陰影測試光線。
如圖1所示,每個功能內核的輸入顯示在盒子的左邊,內核之間傳輸的流數據的類型由虛線所指的內容表示。這種細分的方式在流編程模型中并不是強制性的。
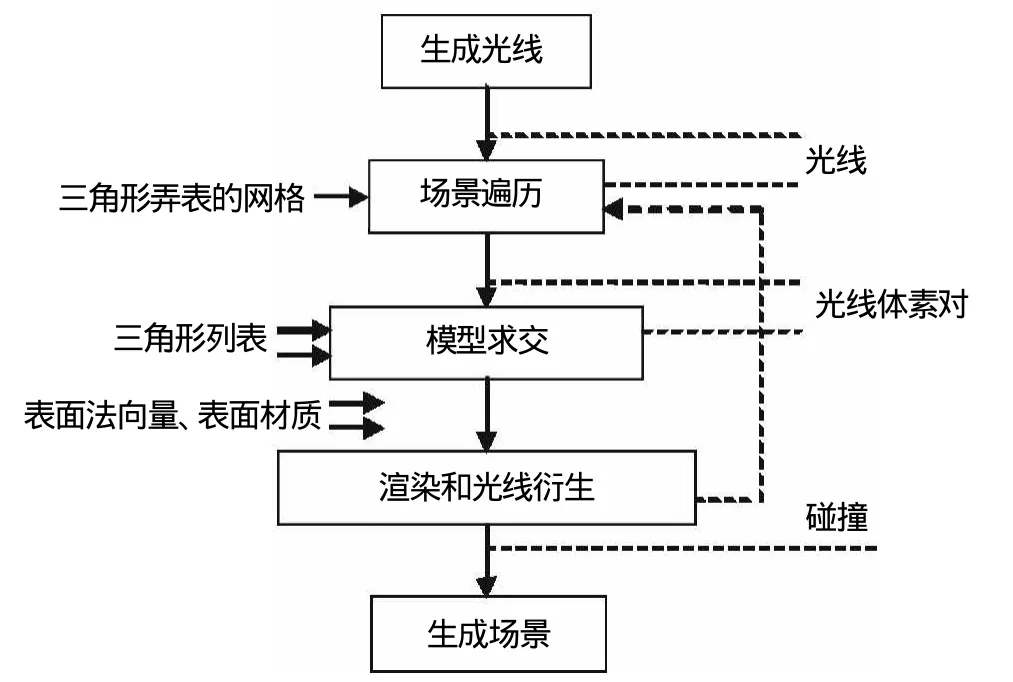
圖1 基于流的光線跟蹤算法流程Fig.1 the ray tracing based on flow
光線產生器內核產生一束光線流,每根光線都和圖像中的某個像素相關聯,以此形成光線向量集。網格遍歷內核讀取由光線產生器產生的光線流,然后作用光線,使光線一步一步地遍歷網格直到碰到一個包含三角形面片的體素,光線和體素對被輸出并傳遞到光線與三角形面片求交測試內核里。
場景遍歷中,改進的遍歷算法描述如下:
第一步,建立2維KD_Tree結構來存儲場景信息,該樹中的每個節點代表一個軸向包圍盒;每一個內部節點表示分離平面,該平面將場景劃分為兩個子區域。劃分包圍盒的方法是沿軸循環分割,首先從根節點沿x軸對盒子進行分割,然后再沿y軸分割子盒子,最后再沿 z軸分割孫子盒子,以此循環。
第二步,在求交和遍歷之前將該樹中序線索化為線索二叉樹;
第三步,如果光線的跨度區間橫跨分離軸的兩側,說明該光線同時穿過兩個子包圍盒,則先和第一個子節點求交,只要先遍歷第一個節點,不將第二個節點壓入堆棧;否則,和相交的子節點求交;
第四步,如果該節點是葉子節點,且射線和該子節點有交,則返回成功,否則,直接搜索該節點的后繼節點。
本算法可避免堆棧操作帶來的開銷。雖然建立線索二叉樹本身也會有一定的開銷,但該操作在初始化時一次完成,后面的每次操作都將加快遍歷速度。在實際應用中,通過限制中間節點的深度,并保證KD_Tree的平衡性,平均的算法時間復雜度為O(log2n)。
模型求交內核主要負責測試該光線是否和體素中包含的三角形面片有交點。光線跟蹤實際上就是復雜場景和一個光線樹的遍歷求交過程,每次重新生成的光線都是原來光線的子光線,這樣將動態生成一個光線樹。每個像素點的最終顏色都是沿著光線樹向下迭代求交所得,由于 GPU體系結構的限制,無法動態生成光線樹,可以利用光線棧來管理每次求交生成的子光線。對于反射光線,為了提高效率,可以利用循環迭代來代替原來的遞歸調用。N次迭代的公式可以表示如下:
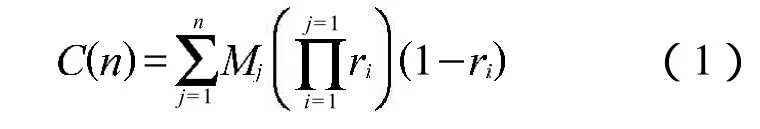
其中 表示模j,ri表示i物體的反射系數, 為像素的最終顏色,N為反射深度。
渲染和光線衍生的功能主要是計算顏色值。如果一根光線終止在相交點上,那么把這個相交點的顏色值寫進累加的圖像上。此外,繪制內核可能產生陰影或次光線,這種情況下,將這些新產生的光線返回到遍歷階段,開始新的跟蹤。
3 結果與分析
基于 GPU加速的光線跟蹤繪制速度的測試不包含加速結構構建時間,因為實驗的目的是測試GPU加速對場景繪制速度的影響。對于靜態場景繪制,加速結構構建可在預處理階段完成。上述算法中,GPU實現部分使用NVIDIA推出的通用并行計算架構 CUDA(Compute Unified Device Architecture)完成,根據 GPU中獨立 ALU(算術邏輯部件)數量將光線投射運算拆分,所有 ALU并行運算,提高光線投射處理速度。兩種實現方式在分辨率為256×256、512×512情況下,繪制速度如表1所示。
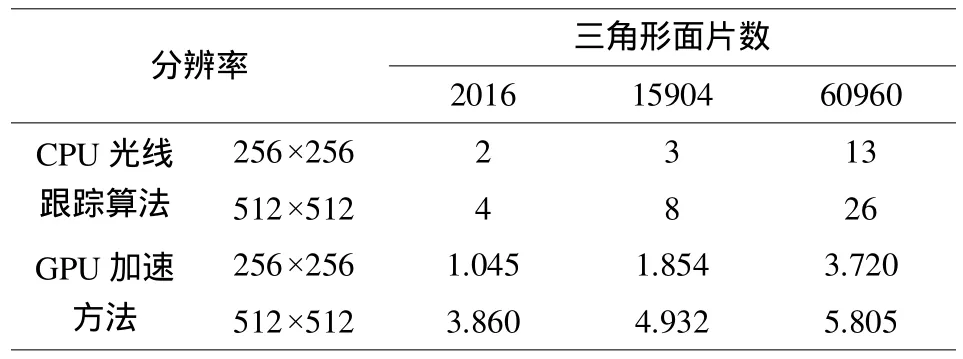
表1 光線跟蹤算法在CPU和GPU上實現時的速度比較Tab.1 speed of the ray tracing on CPU and GPU
4 結論
主要討論了一種改進的光線跟蹤算法,它是一種基于GPU的快速光線跟蹤繪制算法,在普通PC機上(Pentium4 3.0G,ATI9500),根據3個不同復雜度的場景,在分辨率分別為256*256、512*512時,實現了GPU和CPU實現光線跟蹤繪制,并進行結果比較分析。從實驗結果可得到基于GPU加速的光線跟蹤的優勢,隨著場景復雜度的增加,基于GPU加速的光線跟蹤算法將明顯優于CPU上的算法。
[1]楊俊華,符紅光,郭惠.基于GPU快速光線跟蹤算法的設計與實現[J].計算機應用,2007,27(8):2033-2035.
[2]儲璟駿.基于GPU的直接體繪制技術[D].上海交通大學碩士論文,2007.
[3]章圣潔,王國榮,王小平.基于GPU加速的光線跟蹤技術研究[J].計算機時代,2007(6):3638.
[4]王碧薇.基于GPU的光線跟蹤算法的分析[J].科技資訊,2007,23(6):64-.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
