基于數據挖掘技術的Snort檢測系統模型
2010-03-16 07:43:40郎振紅
長春理工大學學報(自然科學版) 2010年1期
郎振紅
(天津電子信息職業技術學院,天津 300132)
據不完全統計,中國互聯網絡信息中心(CNNIC)于2008年7月發布的《第22次中國互聯網絡發展狀況統計報告》顯示,截至2008年6月底,僅我國網民數量就高達 2.53億。而且,截至2004年12月底,我國上網的計算機總數達到4160萬臺,從1997年到2004年,僅在七年之內,計算機上網總數增長了139倍。并且網絡的應用領域已由最早的信息瀏覽發展到網絡銀行、電子商務、電話會議等應用服務。因此,隨著日益龐大的網絡規模以及多樣化的網絡服務,網絡的安全機制受到新的挑戰。由于網絡中惡意或無意的攻擊手段變得越來越隱蔽,對系統的破壞威力越來越大,就目前網絡用戶經常使用的防火墻、防病毒軟件、加密技術以及數字簽名技術等安全防護措施在應用中表現出各自的弊端。為了彌補以往安全防護措施的不足,誕生了一種嶄新的安全保護機制——即網絡入侵檢測技術。將網絡安全的防護手段由消極被動的防御變為積極主動的檢測與預防,在不影響網絡性能的前提下,可以實時保護系統免受來自于內部的攻擊或外部的攻擊。
1 入侵檢測系統模型的分析
所謂入侵檢測(Intrusion Detection)是指對入侵行為的發覺,它通過對計算機網絡或計算機系統中的若干關鍵點收集信息并對其加以分析,從中發現網絡或系統中是否有違反安全策略的行為和被攻擊的跡象[1]。為了更好地對網絡入侵行為進行有效地檢測與分析,自從1984年喬治敦大學的Dorothy Denning和SR/ICSL(SRI公司計算機科學實驗室)的PeterNeumann研究出一個實時入侵檢測系統模型,命名為IDES(入侵檢測專家系統)以來,相繼開發出大量的入侵檢測系統(Intrusion Detection System,IDS),將入侵檢測的相關軟件與硬件設備進行有效的結合,即防火墻之后的第二道安全屏障,是防火墻系統的有利補充。
通常根據IDS檢測對象及檢測方法的不同,可以細分為:基于主機的IDS、基于網絡的IDS、混合方式的IDS、基于誤用檢測的IDS和基于異常檢測的 IDS等。目前使用最廣泛的是由 Sourcefire公司MartinRoesch等人開發的Snort入侵檢測系統,它是一個免費開放源代碼的網絡入侵檢測系統(NIDS)。Snort以其發展速度、檢測功能、結構簡單、高效的代碼、多樣化的插件機制等優勢受到業界人士及眾多學者的親昧。而且許多公司為了滿足不同網絡的安全需求,已經在Snort系統的基礎之上進行了二次開發,本文就是一個基于Snort系統的二次開發應用實例。
Snort系統主要有6個組件構成,分別是:包嗅探器、解碼器、預處理器、檢測引擎、輸出插件和規則庫等。其系統結構如圖1所示。
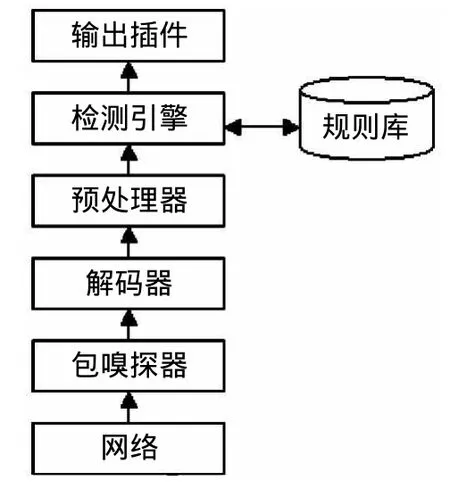
圖1 Snort系統結構Fig.1 Snort system structure
Snort系統的基本工作過程是,利用包嗅探器捕獲網絡中的數據包將其送到解碼器,把特殊的協議元素轉換成特定的數據結構;經過預處理器調用預處理函數完成數據包的預處理操作,改進的Snort系統可以嵌入某些外部的預處理程序,提高系統的檢測功能;隨后將數據包傳遞到檢測引擎組件,與事先設置好的規則庫進行模式配合,如果匹配成功,則說明發生了入侵行為;及時將報警信息及審計日志提交輸出插件,利用輸出函數輸出相關信息。由此可見,Snort是一個基于誤用檢測的NIDS,系統運行成功與否的關鍵點就是規則庫的信息實時更新與擴展機制問題,這也是本文所要探討的問題。
2 數據挖掘技術
數據挖掘(Data Mining,DM)的定義有廣義與狹義之分[2],從廣義的觀點上講,數據挖掘是從大型數據庫(可能是不完全的、有噪聲的、不確定性的、各種存儲形式的)中,挖掘隱含在其中的人們事先不知道的對決策有用的知識的過程。從狹義的觀點上講,可以定義數據挖掘是從特定形式的數據集中提煉知識的過程。因此,數據挖掘的功能是從大量的數據信息中進行高度智能化的分析與推測,挖掘出潛在的知識與數據模型,預測未來對象的行為模式。
WenkeLee在1999年首次將數據挖掘技術引入到了網絡入侵檢測系統中,可以在入侵檢測過程中實施智能化的信息分析以及動態更新規則庫,實現對于未知入侵行為的有效檢測。在數據挖掘算法中應用廣泛的算法有:關聯分析算法,可以用于挖掘關聯模式,描述入侵行為并進行異常檢測[3];序列分析算法,通過描述發現數據的先后關系,挖掘出序列模式[4];分類分析算法,該算法可以用于構造分類器[5],分類器經過大量的入侵數據集訓練之后可以用于入侵檢測;聚類分析算法,可以用于構造網絡正常行為模式或入侵行為模式[6],進行異常檢測。本文著重介紹如何利用數據挖掘技術對捕獲信息進行二次檢驗,以便減少系統漏報率,提升對新入侵行為的檢測效率。
3 基于數據挖掘的 Snort系統模型的設計
通過上述分析可以得出如下的結論,Snort系統存在的最大問題是,無法檢測到未知類型的入侵行為,系統的檢測能力受到規則庫信息量大小的限制,因而造成系統出現極大的漏報率與誤報率,影響系統的整體性能。
針對已存在的Snort系統進行多方面的改進,所提出的基于數據挖掘技術的Snort檢測系統模型如圖2所示,該系統的具體設計思想如下:
(1)利用嗅探器捕獲正在網絡中傳輸的數據包,并且嗅探IP網絡的流量,該系統利用libpcap捕包程序庫函數實現數據信息的采集,該庫函數的最大功能之一就是將網卡設置為混雜模式后,就可以直接從數據鏈路層捕獲數據包,或直接從網卡獲取數據包,為下一步的解碼操作提供了數據信息。
(2)將利用嗅探器獲取的數據包送入解碼器進行數據解析,在解碼器中根據 TCP/IP的層次,有針對性地對數據包進行分析、解碼等操作,將進行解析后的數據包信息傳入到預處理器。
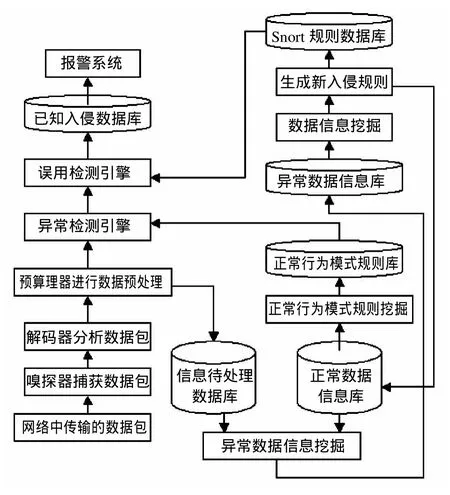
圖2 基于數據挖掘的Snort系統模型結構圖Fig.2 Based on data mining Snort system model
(3)在預處理器中,將采用不同網絡協議的原始數據包進行預處理,可以實現應用層協議的某些附加操作以及數據包再次被分析等功能,以便提高檢測引擎的處理速度。預處理器通常是由功能各異的多個模塊組成,在實際的應用中,可以將其以插件的方式友好地集成到Snort系統中。本文所討論基于數據挖掘的Snort檢測系統,將預處理后的數據包信息在送入異常檢測的同時,存儲到信息待處理數據庫,主要目的是為了與正常數據信息庫中的內容配合進行異常數據挖掘操作。
(4)異常檢測引擎
異常檢測的依據主要來源于正常行為模式規則庫,該模式庫的信息是在正常數據庫的信息基礎上利用關聯數據挖掘算法、序列數據挖掘算法和聚類數據挖掘算法進行正常行為模式的數據挖掘,實時更新正常行為模式規則庫。因此,Snort檢測系統實施檢查之前,已知檢測規則全部設定好,可以用于檢測用戶所有的正常行為,但是對于正常行為模式規則庫中沒有的規則項,在此無法檢測出來,為了避免系統的漏報率,將未知入侵的數據傳輸到誤用檢測引擎模塊。
(5)誤用檢測引擎
誤用檢測引擎又稱Snort檢測引擎,它是該系統的設計核心,在進行檢測過程中,將Snort檢測規則組織成鏈表形式,其中將每一個鏈表項細分為規則頭和規則選項。在進行規則模式匹配時,誤用檢測與Snort規則數據庫中的內容進行模式匹配,起初只檢測Snort規則數據庫中設定好的規則項,如果檢測結果出現規則匹配,則將其檢測結果輸入已知入侵數據庫,入侵信息被記錄后,直接送入報警系統,提示用戶;否則,沒有檢測到匹配的模式,系統并沒有將入侵信息進行簡單的丟棄,而是從信息待處理數據庫與正常數據信息庫中提取數據,進行異常數據信息挖掘,將數據挖掘的結果直接輸入到異常數據信息庫,根據信息庫中的頻繁項集再次進行數據信息挖掘,生成新的入侵規則,更新Snort規則數據庫,然后再進行誤用檢測,與此同時,將入侵檢測的新規則送入正常數據信息庫,與該信息庫中的頻繁項集再次進行正常行為的數據挖掘,從而更新正常行為規則模式庫,為下次檢測做準備,此時就實現了入侵信息的二次檢測,可以大大減少漏報率與誤報率。
4 基于數據挖掘的 Snort系統模型的實現
系統主要是在 Snort系統的基礎之上進行改進的,通過互聯網下載了一個最新版的 Snort入侵檢測系統Snort2.8.1,部署到Windows2003操作系統的平臺上,進行系統的開發與檢測運行。在開發的過程中用到的組件有:(1)WinPcap:網絡數據包的捕獲工具,其主要功能為Win32應用程序提供訪問網絡底層的能力,隨時監聽網絡上傳輸的數據信息,以更高的效率捕獲數據包。(2)MySQL:本系統中用于存儲各種數據信息的數據庫采用MySQL數據庫,連接技術采用ADODB技術,從技術可行性和經濟可行性上講,該數據庫都可以有效地支持快速、穩定的分布式檢測操作。(3)Visual C++:該系統的開發設計語言與數據挖掘規則算法語言采用的是面向對象程序設計語言 VC++,通過編輯信息更新函數、連接用戶函數、檢測入侵信息函數等實現Snort的二次入侵檢測操作。(4)ACID:主要是用來分析入侵數據是已知規則還是未知規則,從而將正常數據與可疑數據分離,進行數據信息的挖掘和生成新的規則信息,在實現過程中主要利用php語言所編輯的動態網頁形式反映給用戶,實現人機互動。(5)Apriori:該算法是數據挖掘中的關聯規則挖掘算法,本系統是在Apriori算法的基礎上進行了必要的改進,使之實現對原始數據、正常數據、異常數據等信息的規則挖掘。(6)Apache:該系統服務器軟件采用的是基于Web的Apache,它以其簡單、快速、兼容、穩定、安全等特點而著稱。
5 結束語
系統是在構建了一個C/S模式的局域網中進行結果檢測,為了能夠更好的說明系統的檢測效果,采取了對比的方式進行測試。先用普通的Snort系統進行檢測,并記錄相應的檢測結果,然后安裝并配置基于數據挖掘技術的Snort檢測系統,同樣記錄檢測結果。通過數據的逐一對比,不難發現,系統檢測的總耗時有所減少,檢測的正確率卻大幅度地提高,并且系統的漏報率也有明顯地下降。在實驗中還有一個更有意義的發現,隨著檢測數據量的增大,上述的檢測結果更為明顯。
本文是在已有檢測系統的基礎上,通過應用數據挖掘技術,增加了新功能,實現了實時更新規則信息和對未知數據的二次檢測,從而降低了系統的漏報率與誤報率。但是,在檢測效率及進一步減少漏報率與誤報率的數據挖掘算法上還有待于改進。
[1]唐正軍,李建華.入侵檢測技術[M].北京:清華大學出版社,2004.
[2]毛國軍,段立娟,王實.數據挖掘原理與算法[M].北京:清華大學出版社,2005.
[3]陳耿,朱玉全,孫志輝.一種基于異常檢測的關聯模式挖掘模型[J].計算機工程與應用,2004,40(12):158-198.
[4]宋世杰,胡化平,胡笑蕾.數據挖掘技術在網絡型異常入侵檢測系統中的應用[J].計算機應用,2003,23(12):20-23.
[5]宋世杰,胡化平,胡笑蕾.數據挖掘技術在網絡型異常入侵檢測系統中的應用[J].計算機應用,2003,30(16):126-127.
[6]張博,李偉華,布日古德.數據挖掘中的關聯規則在入侵檢測系統中的應用[J]. 航空計算技術,2004,34(4):124-127.
[7]孫振龍,宋廣軍,李曉曄,等.基于數據挖掘技術的Snort入侵檢測系統的研究[J].微計算機信息,2006,33:16-22.
[8]崔冬霞.基于數據挖掘技術的分布式網絡入侵檢測系統[D].西安交通大學碩士研究生學位論文,2005.
[9]王艷春,郭小利,陳鴻,等.基于數據挖掘算法的教學評測系統研究[J].長春理工大學學報,2006,29(4):73-76.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
