Skype發送模型及其應用*
2010-05-18 07:28:06周井泉姬德浪
網絡安全與數據管理 2010年3期
周井泉,姬德浪
(南京郵電大學 電子科學與工程學院,江蘇 南京 213000)
Skype是世界一流的 P2P(對等方到對等方)網絡語音溝通工具,以無縫穿透網絡地址轉換器(NAT)和防火墻的工作能力、良好的通話質量,成為發展最快的基于IP語音(VoIP)系統。Skype使用了專用的通信協議,并用高強度密碼加密負載,但至今為止沒有公布過任何有關協議或其他技術專題的文檔。對于使用了高強度的加密算法和專用通信協議的Skype系統,目前檢測其流量的效果并不理想。
面對這種現狀,許多學者希望建立一種常規模型。一方面可以加深對Skype系統的了解;另一方面簡化Skype業務設別的過程。
自Skype得到廣泛應用以來,很多研究人員對其進行了分析研究。參考文獻[1]分析了Skype報文在應用層的協議特征字和端口的某些規律,揭示了Skype不僅可以通過UDP和TCP進行通信,而且通信端口不固定。指出其登錄過程可以分為UDP探測、TCP握手和TCP認證3個部分,分析了各個過程中存在的應用層特征字。提出了一種根據Skype用戶和超級節點連接的特征字和報文長度、順序來識別Skype的方法。參考文獻[2]使用了報告UDP的Skype報文結構,發現了部分未加密的功能字段的特征,為準確識別基于UDP的Skype流量提供了一種可能。通過實際收集并分析Skype語音通信的流量,參考文獻[3]提出了一種獨特的模型來量化VoIP用戶滿意度,其中使用了兩階段過濾方法來識別Skype VoIP會話,即先用一種啟發式算法過濾出可能的Skype流量存儲在磁盤中,采用離線識別算法提取Skype通信流量,該離線方法計算復雜度較高。參考文獻[4]討論了識別超級節點的兩階段方法,即先采用參考文獻[5]給出的過濾器方法識別P2P流量,再用超級節點過濾器區分超級節點和普通節點。
綜上分析,以前的理論研究缺少完善的Skype語音源模型,造成業務識別過程復雜。本文建立了一種通用Skype語音源模型,簡化了Skype業務識別的整個過程。
1 插件模型
Skype業務包括語音業務、數據業務等,因其之間有相關性,所以本文只對Skype的語音業務進行建模。按其通信的終端不同,可以分成以下兩類:
(1)通信雙方是安裝Skype客戶端的PC,稱為E2E。
(2)一端安裝 Skype客戶端的 PC;另一端是傳統的電話機,稱為E2O。
1.1 KM模型
插件模型簡稱為KM模型。圖1所示為Skype語音信號建立的模型,首先語音源通過語音編碼器將語音的脈沖編碼調制(PCM)樣值編碼成少量的比特(幀)。在幀被創建好之前加入一些頭部,如圖中的H1、H2等。圖中的存檔器和加密功能是通過一些算法對數據流進行壓縮和加密。最后,幀在被發送出去之前在其頭部會加上未加密的開始信息特殊字段,這對于流量的識別非常重要。這時不論幀被封裝在TCP還是UDP中,發送出去的就是Skype信息。
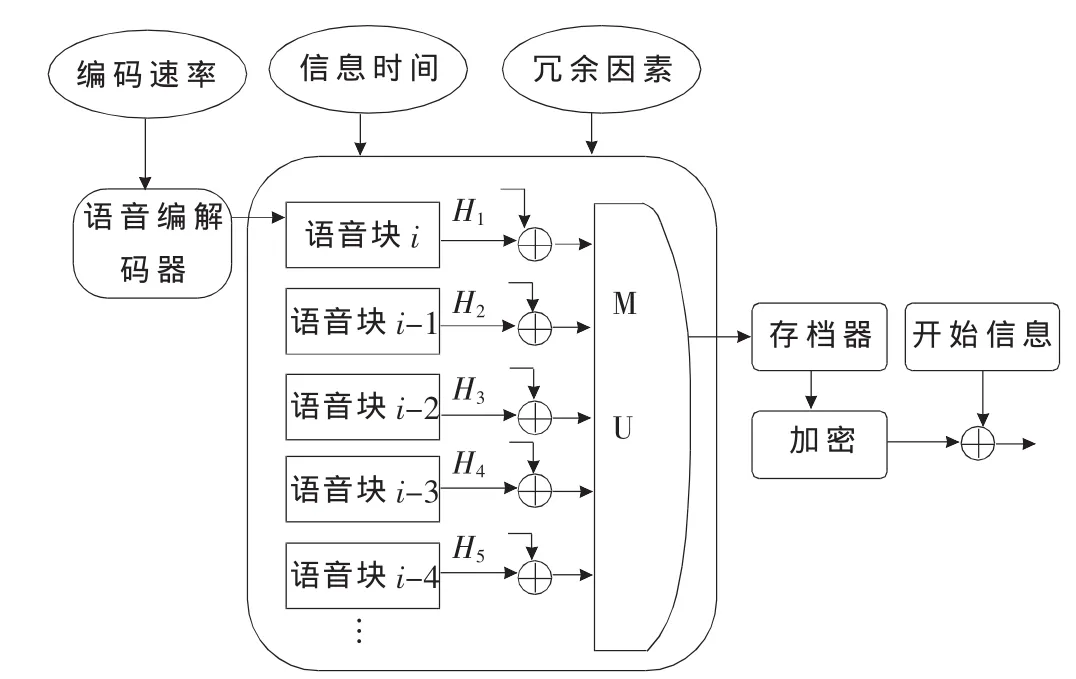
圖1 Skype語音信號模型
在KM模型中,3個參數決定了業務的特征:(1)速率 Vi,表征語音的編碼速率;(2)信息時間 T,表征 1個幀的長度;(3)冗余因數 RF,表征相對于當前的幀,重傳幀的數量(與編碼方式無關)。
1.2 開始信息
根據參考文獻[6],Skype用AES和RSA算法加密信息,對傳輸層協議的選擇有著重要的意義。TCP執行定向可靠傳輸的連接,能夠保證按照正確順序接收數據。因此,利用TCP協議可以加密整個信息。但UDP協議提供的連接服務并不可靠,不能保證數據是有序的全部得到傳輸。當利用UDP協議時,接收端需要從應用層中提取出一些頭部探測和處理不正確的數據流,不能通過加密來傳輸,只能通過單一數據包的有效載荷功能進行偽裝,因此利用UDP協議時不能加密整個信息。此外,Skype利用固定端口發送和接收UDP部分。
基于上面的分析,發現當Skype信息被封裝在UDP協議的數據流中,通過檢測UDP靜態負荷部分設別出一部分Skype信息。這個靜態信息為開始信息。
(1)E2E信息
在2個Skype客戶端之間尋找封裝在UDP中的信息時,可以識別出ID號、干擾信號和結構標志。ID號是16比特長的識別標志符,在發送端被隨意選取,在接受端被拷貝。干擾信號是5比特長的識別標志符,偽裝在呈現有效載荷類型的1個字節中。其3個隨機比特可以通過0X8f位掩碼去除。結構標志包含編碼序列和語音塊的復序列。ID號和干擾信號是開始信息字段的一部分。
(2)E2O信息
E2O呼叫時,在客戶端和超級節點之間有初始的信令連接。觀察封裝在UDP協議中的有效載荷,在一系列初始信息中,前4個字節總是相同的,與E2E相比,E2O有著不同的開始信息的格式。可以把這4個字節作為唯一的識別標志符,從第5字節以后就沒有實質性的意義。
2 KM模型在語音設別中的應用
KM模型可以用χ2分布來判斷被分析的信號是否滿足Skype信息的格式。χ2分布能夠判斷信息的加密部分。在識別的過程中主要分為3類:
(1)應用UDP協議傳輸的E2E,干擾信號是透明的,其他信號被加密。假定編碼器處于最佳編碼狀態,被編碼的信息可出現完全隨機(例如均勻分布)。
(2)應用 UDP協議傳輸的 E2O,其前 4個字節是透明的,即識別標志符。其余字節全是加密的,相應的比特出現是隨機的。
(3)應用TCP傳輸的Skype流,整個信息都被加密,和前面2種情況不同的是整個信息出現全是隨機的。
在實驗中對于每個屬于Skype流的信息,考慮前G個組,每個組有b比特,即首先考慮Gb比特的數據流。對于每個數據塊g=1,…G,變量表征第g數據塊中值i出現的次數。在流的末端,評估每個組的χ2的值。如表1所示。
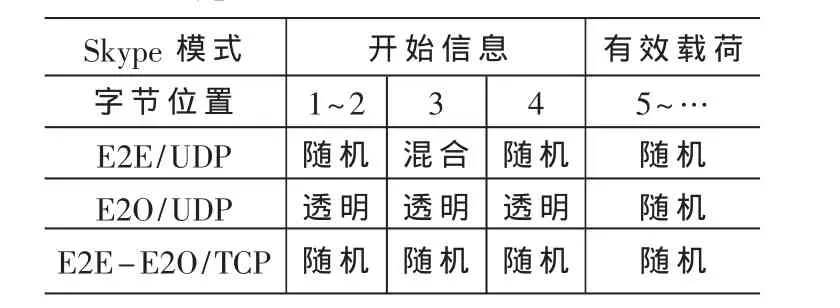
表1 Skype KM模型的信息結構特征
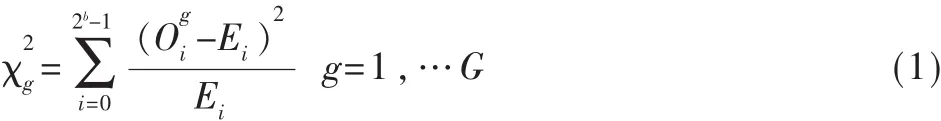
必須將試驗得出的χ2的值和預計的值進行比較。期望依靠流的的類型特征和傳輸層的協議(表1)識別出Skype業務信息。
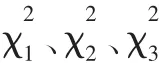
(1)E2E/UDP
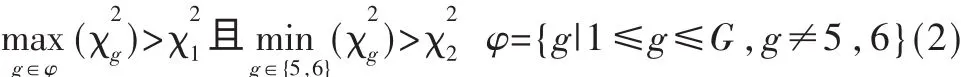
φ={g|1≤g≤G,g≠5,6}是 E2E 隨機部分,這個標準的依據是隨機部分與均勻分布類似,導致χ2分布的值較小。同時,混合情形包括一些透明部分,得出的值較大,因為在一定意義上,典型的隨機信號偏離較大。
(2)E2O/UDP

在此業務中,KM模型開始信息是透明的,其他的是隨機的。
(3)E2E/TCP E2O/TCP

其所有數據流全是隨機的。
3 實驗
為了驗證本文提出的模型,通過實驗環境,利用RAW SOCKET獲取流過本機的所有數據包,并將其所有信息導入1個數據庫中,實現Skype業務基于TCP、UDP傳輸協議的識別。
本地測試環境為WindowsXP系統,實驗室局域網環境。由于檢測速度的原因,采用非實時檢測。先把數據放到數據庫中,再對數據庫中的數據進行檢測和分析。
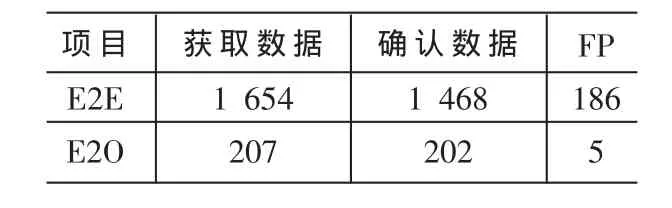
表2 實驗數據
測試結果分析:FP為誤判數,即非Skype通信數據被當作Skype測試數據,測試結果如表2所示。
根據實驗結果得出基于KM模型,χ2分布可以有效地識別出Skype的語音業務。
本文根據對Skype流量特征的分析,提出一種基于流外部特征的模型來識別Skype,并且對KM模型進行實驗驗證。此實驗模型不但可以有效地識別P2P應用,而且可以對Skype的通話類型進行區分,以便對E2O的電話進行計費。另外本文提出的Skype模型具有很好的擴展性。可以對Skype的數據業務、實時業務統一到KM模型中,實現更加通用的Skype發送端模型。雖然KM模型通用可行,但是識別率還達不到網絡所規定的要求,這需要在模型和算法中進一步地改進。
[1]EHLERT S,PETGANG S.Analysis and signature of Skype VoIP session traffic[C].Berlin: Fraunhofer FOKUS, Technical Report: NGNI2SKYPE206b, 2006.
[2]BIONDIP,DESCLAUXF.Silver needle in the Skype[C].Amsterdam: Black Hat Europe’06, 2006.
[3]CHEN Kuan2ta, HUANG Chun2ying, POLLY H, et al.Quantifying Skype user satisfaction[C].Pisa:Proceedings of ACM Sigcomm’06, 2006.
[4]ONEILD, KANGH, KIM J,et al.Transport layer identification of P2Psupernodes[C].Taormina:Proceeding of Internet Measurement Conference,2004.
[5]KARAGIANNIST,BROIDOA,FALOUTSOSM,et al.Transport layer identification of P2P traffic[C].Taormina:Proceeding of Internet Measurement Conference,2004.
[6]BERSON T.Skype security evaluation.[DB/OL].http://www.skype.com/security/files/2005-031securityevaluation.pdf,2005.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
