基于PageRank值的文本相似度改進模型
2010-08-07 08:20:48熊才權田浩
網絡安全技術與應用 2010年6期
熊才權 田浩
湖北工業大學計算機學院 湖北 430068
0 引言
在Google模式中,PageRank值的計算和向量空間模型的計算是相互獨立的,在向量空間模型的計算中也沒有考慮到 PageRank值本身所包含的信息含義。本文在計算文本相似度時結合 PageRank值所包含的信息提出在計算文本相似度時先以 PageRank值的大小作為特征選擇的條件,然后在VSM模型中考慮類別信息以提高檢索的質量。
1 基于PageRank值的VSM改進模型
對文本進行分類是一個比較復雜的問題,文本自動分類是信息檢索與數據挖掘領域的研究熱點與核心技術,而基于機器學習的文本分類技術的相關研究已經取得較大進展。本文首先簡單的把具有相同 PageRank值的網頁歸為同一類,然后在計算相似度的過程中考慮這種分類的影響,并區分不同類別間的信息差異,最終得到更為有效的檢索結果。如果把具有相同 PageRank值的網頁歸為同一類,就可以把所有網頁文本根據其重要性簡單劃分為11種類別。在下載系統中對網絡爬蟲添加部分代碼使其根據 PageRank值的大小對網頁分類存儲可以簡單實現這種初步的分類。
1.1 詞頻的統計方法
在文本分類中詞頻一般是基于自然語言的,經過文本分類后得到的詞條可以認為是計算機可識別的機器語言,在真實生活中使用頻率高的詞條可能在機器語言中使用率并不高。在考慮文本分類的同時為了保證相似度計算的一致性,可以對機器語言的文本頻率進行統計以在文本相似度計算中使用。
詞條頻率的統計過程如下:
(1)對所有分類后的頁面提取特征詞;
(2)統計各個類別Ci的文本總數Mi和包含詞條t的文檔數mi;
(3)計算詞條t在各個類別的各個文本中的詞頻,公式如下:

在詞條頻率的統計過程中首先需要提取特征詞,特征詞的提取與用戶可能的檢索詞是相關的。例如“搜索引擎”、“天安門”等都可能是用戶潛在的檢索詞,所以必須做為特征詞進行統計。本文提供了包含 1370個檢索內容的檢索庫,所有檢索庫中的詞都作為特征詞進行統計。然而,在搜索引擎中進行的每一次檢索都對詞條進行一次頻率統計是不現實的,即使根據本文所提供的檢索庫所得到的最終統計結果也是不全面的。但是,由 PageRank算法可知,網頁的連接是基于詞條的,所以詞條頻率的變化與 PageRank值的傳遞具有一致性,在 PageRank值更新的時期內,基于網絡的詞條頻率可認為保持不變。可以在計算 PageRank值的同時進行詞條頻率的統計計算,也可以改進 PageRank算法,利用PageRank算法計算出詞條頻率。
1.2 改進的IDF方法
一個詞條如果在一個類別的文檔中頻率較高,則說明該詞條能夠很好的代表這個類別的文本特征,這樣的詞條應該給它們賦予較高的權重,并選來作為該類文本的特征詞以區別其它類文檔。例如,計算機類的文本中“CPU”會出現在許多文檔中,“CPU”應該選來作為計算機類文本的特征詞以區別其它類文檔。
根據上述原理提出改進的IDF方法如下:
設總的文檔數為 N,包含詞條t的文檔數為 n,其中某一類Ci中包含詞條t的文檔數為mi,除Ci類外,包含詞條t的文檔數為k,則t在Ci類中的IDFi值為:

顯然,IDFi隨mi增大而增大,隨k增大而減小。如果在某一類Ci中包含詞條t的文檔數量大,而在其它類中包含詞條t的文檔數量小的話,則t能夠代表Ci類的文本的特征,具有很好的類別區分能力。
1.3 改進的VSM模型
綜上所述,在對搜索引擎中文本相似度計算的方法和過程進行改進后提出“基于PageRank值的VSM改進模型”,其文本相似度的計算過程如下:
(1)對所有下載的頁面根據PageRank值的大小進行分類,并統計特征詞條在各個類別中的詞頻TFi;
(2)由改進的IDF方法計算詞條在各個類別中的IDFi;
(3)計算該特征項t在文本d中的重要程度Wt,d;
(4)計算文本d和查詢式q的相似度sim(q,d);其公式如下:
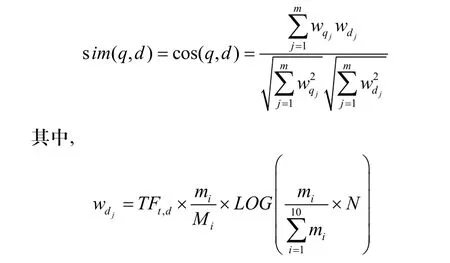
(5)根據相似度的大小生成相似度排序列表。其中,具有相同相似度的頁面PageRank值大的排在前面。
為了驗證改進后的效果,需對原模型和改進后的模型所生成的結果進行比較。假設:由原模型(VSM)得到的排序為:{A1,A2,……,An};由改進后的模型(BPVSM)得到的排序為:{B1,B2,……,Bn}。
定義1:相關:若檢索結果頁面Ai或Bi中包含檢索信息則Ai或Bi相關,否則Ai或Bi不相關。
定義2:異點:在兩次排序中若Ai≠Bi則Ai和Bi為異點。
定義 3:優異點:在兩次排序中?Ai≠Bi,若 Ai相關而Bi不相關則Ai為優異點,若Bi相關而Ai不相關則Bi為優異點;在兩次排序中?Ai=Bj,若i>j則Ai為優異點,若i<j則Bj為優異點。
2 實驗結果及分析
網絡上的數據是極其巨大的,對所有網絡數據進行完備的實驗分析是困難的。整個互連網是由一個個網絡構成的,其中任意一個網絡都可以認為是一個較小的互連網。例如:分別對中國教育網和對中國電信網進行實驗所得到的結果幾乎沒有區別。所以,適當縮小實驗范圍不會影響最終的實驗結果。在本實驗中,限制網絡蜘蛛的爬取范圍是在中國教育網內(即網址后部分為.edu.cn)。但是即使僅對中國教育網進行全面的分析計算也是一個巨大的工程,為了證明改進后的算法對檢索結果的影響可進行驗證性實驗,其過程如下:
首先,精選檢索內容,生成包含了 1370個檢索條目的檢索內容庫,然后分別在Google中檢索,并用網絡蜘蛛爬取檢索結果頁面。
其次,根據改進后的模型對檢索結果進行再排序。由于在搜索引擎中一個頁面顯示 10個結果,而用戶一般難以容忍翻看到 10以后的結果,所以盡量避免對后面的結果頁面進行分析計算。在實驗中,只對結果頁面的前1/3進行了分析計算(檢索結果少于 300則全部進行分析計算),最終只顯示前10個頁面的排序。
最后,分別統計兩次排序前十個頁中所包含的相關頁面的數目,比較兩次排序的相關性;分別統計兩次排序的優異點,比較兩次排序的優異性;并用 MATLAB對統計結果進行模擬得到仿真圖。
在實驗中,檢索內容庫主要分為復雜檢索和簡單檢索,復雜檢索為可以確定具體結果的檢索,例如檢索內容為“毛澤東 開國典禮 語錄”為復雜檢索,而“毛澤東 語錄”為簡單檢索。同時考慮到部分新詞如“綠領”并未被詞典收錄,檢索內容庫具有 37條包含新詞的檢索如“綠領 含義”。檢索內容庫概要見表1。

表1 檢索內容庫
經過對實驗數據統計分析發現改進后的模型在提高檢索的準確率上比原模型更加有效,在對包含新詞的檢索中貢獻更加明顯。最終統計結果見表2。
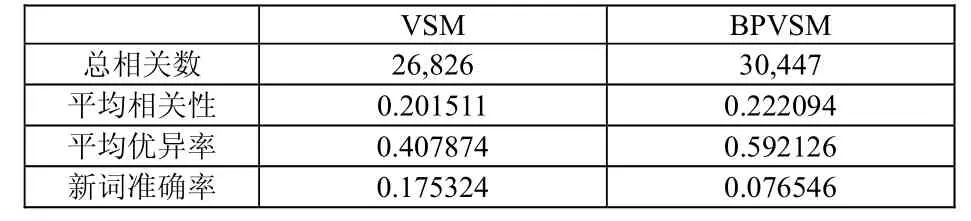
表2 兩次排序的效率比較
對 1370次排序的相關性進行模擬,發現兩條相關性曲線相互交織在一起,其中BPVSM的大部分略高于VSM;見圖 1(縱坐標表示相關頁面的數目,橫坐標表示按照相關頁面的數目的大小排列的1370次統計)。

圖1 相關性統計圖
對相關數(其范圍為0-100)進行逆向統計的模擬,發現兩條曲線在11%和20%左右有較大的起伏;BPVSM在11%和20%有兩次波峰,而VSM僅在20%有一次波峰。見圖2(橫坐標為頁面相關數,縱坐標表示具有某個相關數的統計次數)。

圖2 相關性逆向統計圖
對1370次排序的優異點統計進行模擬,發現VSM曲線有少量的奇異點落在BPVSM曲線的上方,忽略少量的奇異點后可認為BPVSM曲線在VSM曲線的上方。見圖 3(縱坐標表示優異點數目,橫坐標為按照優異點數目排序的 1370次統計)。

圖3 優異點統計圖
綜上所述,實驗結果表明:
(1)兩種模型檢索結果的查準率比較接近,但改進后的模型查準率更高;
(2)兩次排序的查準率在7%-35%之間,在11%和20%左右達到最大概率;
(3)改進后的模型可以明顯提高對新詞的查準率;
(4)改進后的模型對前 100個網頁的可信度提高了約1.45174倍。
3 結束語
相似度的計算與排序是搜索引擎的一個重要部分,提高相似度的計算與排序的效率和質量對提高整個搜索引擎的質量具有重大的意義。本文基于搜索引擎的文本檢索部分提出了基于 PageRank值的文本相似度改進模型,通過模擬實驗表明改進后的模型可以提高檢索的準確率,在對新詞的檢索中更加明顯。
基于 PageRank值統計詞頻,詞頻的統計必須保持與PageRank值的更新同步,這必然會增加整個搜索引擎的工作量;其次,改進后的模型依然存在奇異點(即完全不相關的頁面卻獲得了很高的相似度),若在改進后的模型中考慮消去產生奇異點的原因可以提高模型的穩定性。
[1] PAGE.L,BRIN.S.The anatomy of a large scalehyper textual Web search engine [J].Computer Networks and ISDN Systems.1998.
[2] PAGE.L,BRIN.S,MOTWAN.R.WINOGRAD.T. The PageRank citation Ranking:Bringing Order to the Web[J]. Stanford Digital Library Technologies Project.1998.
[3] MATTEW.R,PEDRO.D.The intelligent surfer: Probabilistic combination of link and content information in PageRank[J].Neural Information Processing Systems.2002.
[4] SALTON G,WONG A,YANG C.A Vector SpaceModel for Automatic Indexing[J]. Comm-unications of ACM.1975.
[5] YANG Y.An Evaluation of Statistical Approaches to Text Categorization[J].Information Retrieval.1999.
[6] 梁斌.走進搜索引擎[M].北京:電子工業出版社.2007.
[7] 蘇金樹,張博鋒,徐昕.基于機器學習的文本分類技術研究進展軟件學報[J].2006.
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
中國衛生(2015年12期)2015-11-10 05:13:38
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
電腦愛好者(2011年11期)2011-06-22 08:20:18
