H.264色度分量插值算法的速度優化
2010-08-09 05:03:46曾嘉亮
電視技術 2010年12期
關鍵詞:優化
曾嘉亮
(汕頭職業技術學院 機電工程系,廣東 汕頭 515078)
責任編輯:哈宏疆
1 引言
隨著H.264標準在視頻壓縮領域日益廣泛的應用,在嵌入式系統中實現H.264的實時編解碼器具有越來越重要的實用意義,這一趨勢對編、解碼程序的執行速度提出了更高的要求。
由于H.264運動補償的插值算法已經標準化,其速度優化的必要性往往被忽視,主流的開源編解碼器[1-3]一般直接在C語言層面上實現標準化的插值公式。
事實上,通過對插值算法的詳細分析發現,至少在色度插值算法上可以進行效率可觀的優化。
2 標準化的H.264色度插值算法
與傳統的視頻壓縮標準相比較,H.264的運動補償機制支持更高精度的亞像素插值,最高可達1/4亞像素精度。
色度分量的水平、垂直分辨力是亮度分量的1/2,因此,亮度分量的1/4亞像素插值對應到色度分量,就需要進行1/8亞像素插值。H.264標準規定對色度分量的插值統一采用雙線性插值算法[4-7],利用4個整數坐標處的像素值插值得到。如圖1所示。
H.264標準并且給出了由4個整數坐標處的像素值A,B,C,D插值生成任意1/8位置處的新像素值G的公式[4]
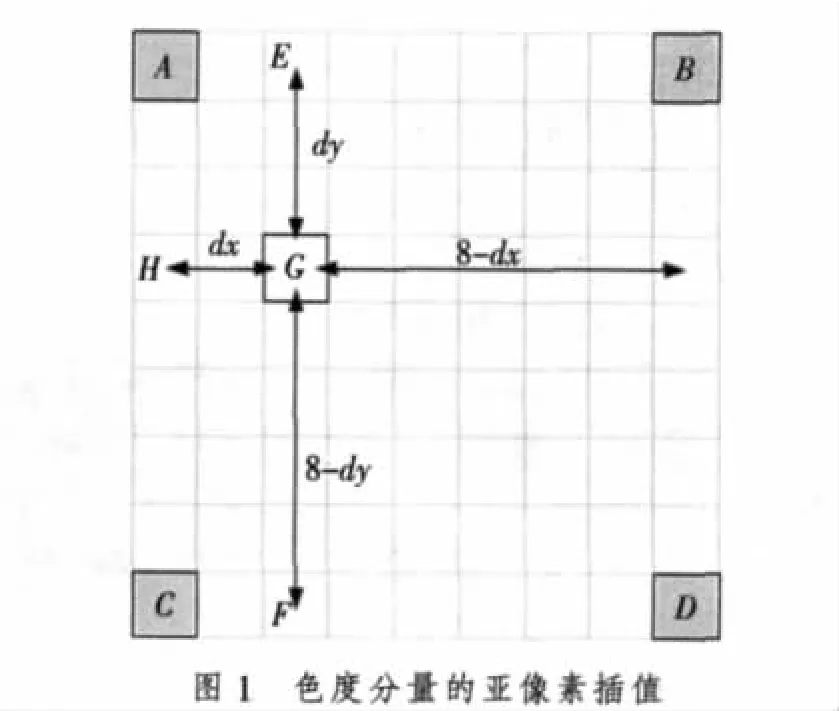
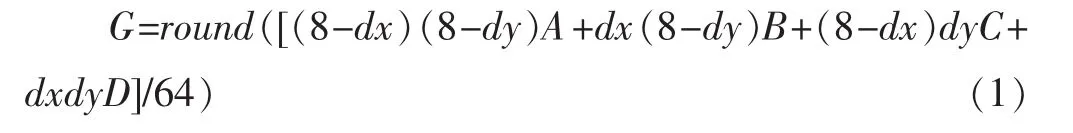
式中:dx和dy是色度塊運動矢量的水平、垂直分量,其值域均為[0,7];round()函數表示對括號內的結果進行四舍五入操作。
由于色度插值是以塊 (宏塊或其子塊)為單位進行的, 對于同一圖像塊而言,4個插值系數 Ca=(8-dx)(8-dy),Cb=dx(8-dy),Cc=(8-dx)dy 和 Cd=dxdy 是相同的,因此對整個塊所有像素做插值前,只需計算一次系數。
為便于描述,把標準化的色度分量插值算法的主要步驟抽象為如圖2所示代碼。
圖中式(2)是標準H.264編解碼器對色度插值的實際動作,也是需要改進速度的核心步驟。

3 H.264色度插值算法的速度優化
3.1 基于統計特性的速度優化
由式(1)易知,若 dx=0,則有 Cb和 Cd為 0;若 dy=0,則 Cc 和 Cd 為 0;若 dx=dy=0,則 Cb,Cc,Cd 均為 0。
在這3種dx或dy為0的特殊情況下,式(2)中的乘法操作的數目均可大大減少,從而提高運算速度。事實上,如下文所述,經過精心設計后,在這3種特殊情況下可以不用任何乘法實現式(2)的等價運算。
下一個問題是——上述3種特殊情況的色度塊數量所占的比例是多少。因為如果特殊情況的比例太小,那么對于整體圖像的速度優化便沒有太大的意義。
表1給出了對3個標準測試視頻序列壓縮后碼流的統計結果,表中的3個H.264碼流均是經過主流編碼器[3]壓縮產生的,每個碼流均包含300幀圖像,且量化參數QP均為26。
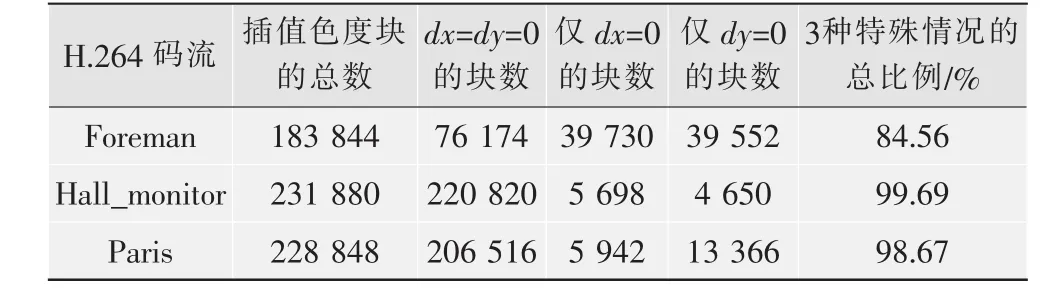
表1 dx或dy為0的色度塊比例統計表
統計結果表明,dx或dy為0的色度塊數目,在總色度塊數占據相當大的比例。因此,對這3種特殊情況進行分別處理,對于提高運算速度具有重要的現實意義。
3.1.1 dx和dy均為0的優化
這種情況下,Cb=Cc=Cd=0,而Ca=64。將4個系數代入式(1),得

對比式(2)和(3),不難看出,對于同一色度塊的所有插值像素而言,式(3)所需要的僅僅是直接將參考圖像像素A的值賦予當前待插值像素G,比式(2)減少了4個乘法、4個加法和一個移位操作,極大地提高了運算效率。
3.1.2 僅dx為0的優化
此時,Cb=Cd=0,Ca=8(8-dy),Cc=8dy。 代入式(1)并化簡,得
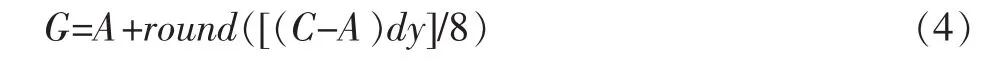
由于 C,A 的取值范圍在[0,255]之間,因此(C-A)的值在[-255,255]之間,共511種可能情況;而dy的值在[1,7]間,有 7 種可能。
由上述分析,可以為式(4)中的 round([(C-A)dy]/8)這一項,構建一張數據查找表(Look Up Table,LUT),通過查表來加速插值操作,見
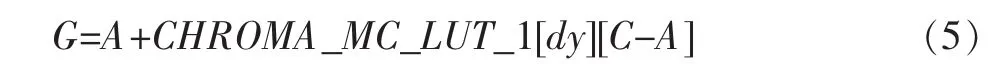
式中:CHROMA_MC_LUT_1是一張二維數據表,填入dy和(C-A)即可得到對應的 round([(C-A)dy]/8)的值。
對比式(2),式(5)用 2 個加(減)法、1 個查表代替了式(2)的4個乘法、4個加法和一個移位操作,較大地提高了運算效率。
3.1.3 僅dy為0的優化
將dy=0代入式(1)并化簡,得
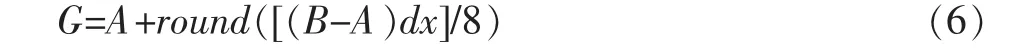
與 3.1.2 節同理,(B-A)的值在[-255,255]之間,dx 的值在[1,7]間,一樣可以通過查表來加速此種情況的插值操作,見式(7)
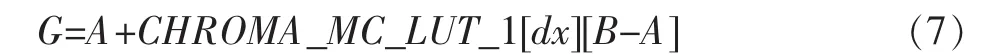
式(7)同樣是用2個加(減)法、1個查表代替了式(2)的4個乘法、4個加法和一個移位操作,實現了加速。
3.2 常規情況的優化
即使對于dx,dy均非0的情況,式(2)也仍然有優化的余地。圖1所示G即為這種常規情況。
3.2.1 針對雙線性插值算法原理[6]的優化
由圖1易知,E相對于A和B,F相對于C和D,均滿足3.1.3節所述的dy為0的情況,即
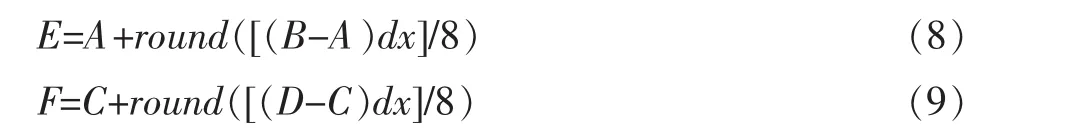
而G相對于E和F滿足3.1.2節所述的dx為0的情況,即
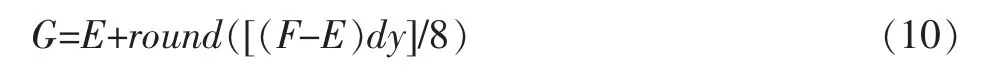
可見,dx,dy均非0的情況下仍然可以通過查表操作來減少乘法運算。
理論上,式(8)(9)(10)聯立的運算結果與式(1)的結果是等價的。但是實際上,由于E,F在求取過程中各自經過了一次舍入操作,所以式(10)中的G經過了2重舍入運算,導致在某些情況下與式(1)中的插值結果會有誤差。
解決問題的辦法是避免2重舍入。將等式(8)左、右兩側均乘以8,便可以消去舍入運算round()

同理,式(9)可以轉換為

由此得到新的插值公式
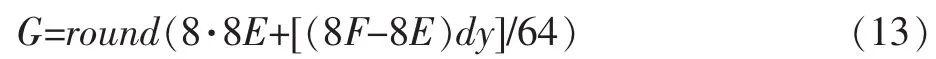
式(11)(12)(13)聯立的運算結果,與式(1)不管是在理論上還是實踐上都是等價的。
對式(11)而言,由于A是非負整數,8A可以通過對A左移3位得到,從而減少了一次乘法。至于(B-A)dx這一項,則必須通過預先建立查找表的方法來避免乘法操作。
式(12)的優化方法與式(11)相同。
對式(13),8·8E可以通過對8E左移3位得到。而對(8F-8E)dy這一項,由于可能的結果太多,構建數據查找表是不現實的,因此只能在程序中直接進行乘法運算。
3.2.2 針對塊操作特點的優化
前已述及,色度插值是以塊為單位進行的,所以上述的所有優化操作都是在一個像素矩陣內循環進行的。
設圖像中坐標為(x,y)處插值像素為G0,其2個插值源數據分別為 E0和 F0;G0正下方的(x,y+1)處插值像素為G1,其2個插值源數據分別為E1和F1。
觀察圖1不難發現:E1=F0。推廣到塊中的一行,就是:當前行的所有G對應的F,剛好是下一行所有G對應的E。
這一發現使得對每個插值像素的E,F計算量可以減少50%——只需在插值循環開始前預先計算下一行的所有像素的8E。具體操作見程序清單2。
綜合3.2.1節和3.2.2節所述,即使對dx,dy均非0的情況,也可以進行速度優化。圖3所示的代碼直觀說明了如何對一個色度塊執行這一優化過程。

在程序清單2中,CHROMA_MC_LUT_2是為了減少乘法操作而構建的數據查找表,用于查找式(11)的(B-A)dx項以及式(12)的(D-C)dx項。
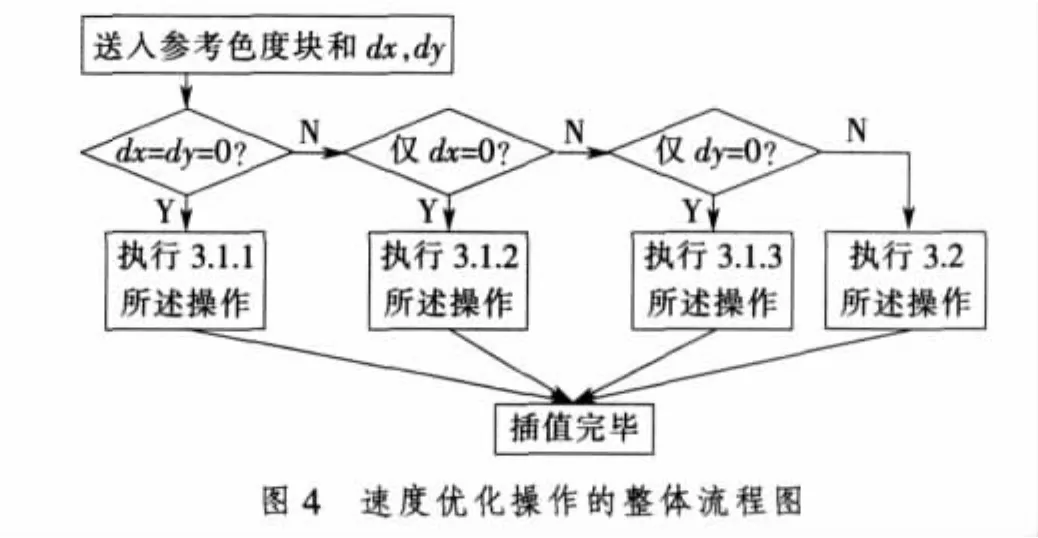
4 色度插值速度優化的整體操作流程
圖4給出了前述的速度優化操作的整體流程圖。
5 實驗結果
表2列出了加速優化方法與標準方法的執行速度對比實驗數據。
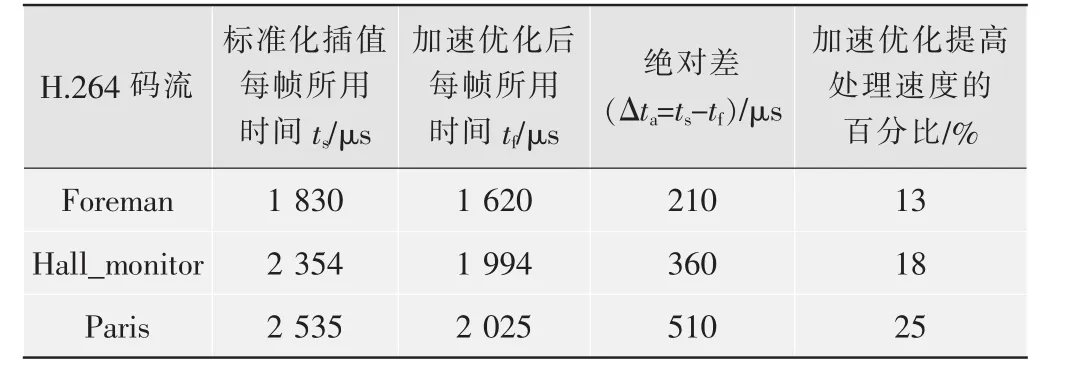
表2 速度對比實驗數據表
該實驗數據是以主流解碼器[2]為基礎,對與表1相同的3個H.264標準碼流進行解碼得到的。執行解碼程序的計算機采用Intel Celeron M 1.5 GHz CPU,896 Mbyte內存。
實驗數據表明:在解碼結果完全一致的情況下,優化后的插值方法的執行效率比標準化插值方法提高了13%~25%。
6 結論
筆者通過對H.264色度插值標準公式以及雙線性插值算法的詳細分析,提出了根據運動矢量的值將插值情況進行詳細分類,再針對每一類的具體情況進行特殊處理,以加速插值操作的方法;并在此基礎上結合色度插值的塊操作這一特性,進一步提高了算法的執行速度。
實驗數據表明,在解碼結果完全一致的情況下,該方法的執行速度比標準化方法有明顯的提高。
[1]X264 software[EB/OL].[2010-02-03].ftp://ftp.videolan.org/pub/videolan/x264/snapshots.
[2]FFMPEG software[EB/OL].[2010-02-03].http://ffmpeg.org.
[3]T264 software[EB/OL].[2010-02-03].http://sourceforge.net/projects/t264/.
[4]RICHARDSON I E G.H.264 and MPEG-4 Video Compression[M].Hoboken,NJ:John Wiley&Sons Ltd.,2003:159-223.
[5]WIEGAND T,SULLIVAN G J,BJ?NTEGAARD G, et al.Overview of the H.264/AVC video coding standard[J].IEEE Trans.Circuits And Systems for Video Technology,2003,13(7):560-576.
[6]胡力,王峰,鄭世寶.H.264中1/4精度像素插值算法的一種硬件實現架構[J]. 電視技術,2005,29(10):14-17.
[7]章毓晉.圖像工程(上冊)圖像處理[M].2版.北京:清華大學出版社,2006:73-76.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
