廣告段落分割系統中的字幕檢測
2010-08-10 07:47:36謝志揚
電視技術 2010年2期
關鍵詞:檢測
葛 菲,史 萍,姚 彬,謝志揚
(中國傳媒大學 信息工程學院,北京 100024)
1 引言
在廣告視頻分析和廣告段落分割的研究中,一個重要問題就是將整段電視節目按段落進行分割,從而使整段電視節目分解為正片、廣告等場景,以便于組織和檢索。一般的電視節目大致由一系列正片、片頭、片尾、廣告簡單連接而成,而且部分廣告段落是與片頭和片尾緊密相連的,片頭片尾部分包含大量的字幕信息,因此可以利用字幕特性確定片頭和片尾片段。此外,在電視劇、新聞、綜藝等節目播出時,在屏幕的左下角或右下角都會出現標志該節目名稱的字幕區域。因此,字幕段落的出現往往表示一個廣告段落的結束和新的電視節目的開始,或者一個電視節目的結束和新的廣告段落的開始,它可以作為廣告段落分割的邊界。可見,判斷出字幕段落對廣告段落的檢測是十分有意義的。
近年來,國內外對于從靜態圖像、運動視頻中提取文字有大量的研究。Ohya等[1]使用灰度門限法對西文字符進行分割;Lopresti等[2]使用圖像分析法對互聯網上的靜態圖像進行了文字分割;黃祥林等[3]提出了在壓縮域內利用紋理進行檢測文字的算法;Lienhart等[4]基于分裂/合并算法對視頻幀中的文字進行分割;胡宏斌[5]利用邊緣檢測對數字視頻中固定區域(屏幕下方四分之一區域)的中文字符進行了檢測和分割。
筆者在分析了整段視頻節目字幕特征的基礎上,針對片頭片尾字幕片段提出了一種綜合字幕邊緣、字幕區域像素密度及字幕幀連續度的算法進行字幕段落的提取。在此基礎上,針對特定區域節目標志的字幕,提出了在指定檢測范圍內進行字幕檢測、以鏡頭為單位提取出字幕鏡頭的方法。
2 算法基本原理
通過對視頻分析發現,在視頻流中如果有字幕則一般出現在一段連續的幀內,不會只出現在一幀或幾幀內,因為這樣人眼將無法識別字幕,這樣就形成了字幕段。字幕通常由漢字組成,而漢字在水平和垂直方向出現的筆畫較多,根據漢字的這一結構特點,在電視節目的字幕片段檢測中,主要利用Sobel算子[6]的水平和垂直模板對從電視節目視頻中解碼出來的每一幀圖像進行字幕檢測。圖1所示為Sobel算子的水平和垂直模板。

圖1 Sobel算子的水平和垂直模板
2.1 字幕特征提取
視頻字幕的檢測是通過利用圖像邊緣檢測技術,進而得到圖像的邊緣像素點來實現的,這里將圖像的邊緣像素點作為字幕檢測的特征值。
對視頻中的每一幀圖像進行分析,將圖中的每個點都用水平邊緣Sobel算子和垂直邊緣Sobel算子這2個卷積核做卷積,一個核對垂直邊緣影響最大,而另一個對水平邊緣影響最大。邊緣檢測算子的中心與中心像素相對應,進行卷積運算。運算結果是一幅邊緣幅度圖像。進行卷積時會遇到一些較復雜的問題,首先是圖像邊界問題。當在圖像上逐個移動卷積核時,只要卷積核到達圖像邊界,就會出現計算上的問題。這時在原圖像上就不能完整找到與卷積核中卷積系數相對應的9個 (對3×3卷積核)圖像像素。解決這一問題的簡單方法是:忽略圖像邊界數據,在圖像的四周復制圖像的邊界數據。
圖2顯示了原始圖像中3×3大小的像素鄰域灰度模板,對于一幀圖像中的每一個像素點來講 (邊界像素點除外),它經過Sobel算子的水平和垂直模板計算后得到的一階偏導數為

式中:Gx及Gy分別為經橫向及縱向邊緣檢測的圖像。

圖2 3×3像素鄰域灰度模板
對一階偏導數求平方和

然后對每一個像素點的G值進行累加求平均值并乘以系數4,得到該幀圖像的邊緣閾值

式中:m和n分別表示該幀圖像像素點的行數和列數。
最后進行判決,判斷該幀中哪些像素點屬于邊緣部分。判決條件如下

水平方向上

垂直方向上

式中:Gx′和Gx″分別為Z2和Z8在水平方向的一階偏導,Gy′和Gy″分別為Z4和Z6在垂直方向的一階偏導。
滿足式(5)和式(6)或式(5)和式(7),則當前像素點屬于水平邊緣部分或者垂直邊緣部分,也即該像素點屬于邊緣像素點。
最后對屬于邊緣部分的像素點進行統計累加,得到值A,即為字幕特征值。
圖3為字幕特征提取中的邊緣像素點檢測流程圖。

圖3 邊緣像素點檢測流程圖
2.2 片頭片尾字幕片段的檢測
字幕片段幀圖像的A值要遠大于其他幀圖像的A值。經過計算觀察,可以設定閾值Ath來判斷當前幀是否為字幕片段幀圖像。由于部分廣告中也會出現字幕片段,因此在檢測過程中也會將這部分內容檢測出來,但是廣告中字幕片段持續時間遠小于電視劇中字幕片段的持續時間,也即廣告中字幕片段持續幀數遠小于電視劇中字幕片段的持續幀數。因此,可以設定一個持續幀數閾值Fth來判斷是否為電視劇中的字幕片段。Ath和Fth共同來判決一段幀序列是否為字幕片段。
由于字幕占據的區域文字排列較緊密,根據這一特性,可用字幕的塊密度[7]來判定該幀是否為字幕幀,這樣可避免因不必要的紋理及條紋而造成的圖像邊緣點的增加,只要塊中的邊緣點Ba的數量大于閾值Tth,則判定其為字幕塊,當字幕塊的數量Bn大于閾值Bth,則判定該幀為字幕幀。
圖4為片頭片尾字幕片段檢測算法流程圖。
2.3 特定區域節目標志的字幕檢測
由于一般節目一般都附帶當前正在播出節目的節目標志,例如電視劇名稱,新聞名稱或綜藝節目名稱等,這些節目標志往往放置在電視節目的左下角或右下角,這里對這2個敏感區域進行研究。如圖5所示,以352×288的視頻圖像為例,將下面的左下角和右下角區域設為敏感區域,并根據統計經驗設定該區域的寬高值,單位為像素。

圖4 片頭片尾字幕檢測算法流程圖

圖5 電視節目標志的敏感區域


圖6 左下角或右下角節目字幕標志檢測流程圖
3 實驗結果及分析
3.1 片頭片尾字幕檢測實驗結果
為了突出字幕檢測的效果,將幀圖像經過Sobel算子計算后得出的邊緣圖像進行二值化,得到幾組圖像如圖7所示。

筆者對中央電視臺播放的部分節目進行了實驗,經過計算統計,字幕片段被正確地檢測出來,檢測結果如表1所示。

表1 中央電視臺某播出視頻片頭片尾字幕檢測結果
3.2 節目標志字幕檢測實驗結果
本文選取中央電視臺播出的視頻作為實驗對象,這里以黃金時段播出的一段電視劇加廣告的視頻為例,將threshold1選為125,threshold2選為0.7,分析本系統對節目標志字幕檢測的實驗結果。節目共計時長6 min 16 s,共9 402幀,其中包含廣告內容及廣告前后的電視劇部分,實驗結果見表2。
3.3 實驗結果分析
從實驗數據可以看出節目標志的字幕檢測存在漏檢和誤檢的情況,分析原因如下:
1)由于廣告視頻內容豐富多樣,圖像內采取多種線條紋理,在廣告中敏感區內垂直水平線條豐富的情況下會造成廣告片段內節目標志的誤檢,如圖8所示。
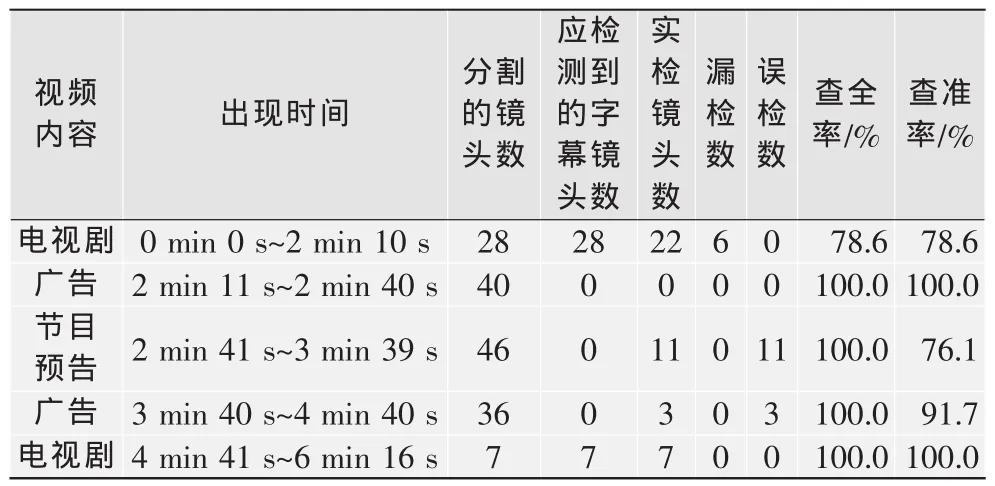
表2 中央電視臺某播出視頻節目標志字幕檢測結果

2)采集視頻有較多雪花,造成誤檢,如圖9所示。

3)字幕幀閾值threshold1和字幕鏡頭閾值threshold2是字幕片段檢測的關鍵。如果閾值選得太低,則某些廣告片段就會被誤檢出來;如果閾值選得過高,則某些字幕片段就會出現漏檢。本文選取的閾值是經過對大量帶有字幕標志的片段和廣告片段的敏感區域進行統計得到的值,雖然在大部分情況下能夠正確檢測,但仍會出現漏檢和誤檢的情況,因此對閾值的選擇還需要進一步優化。
4 小結
筆者提出了廣告段落分割中的字幕檢測算法,利用Sobel算子進行圖像邊緣檢測,對邊緣點進行統計分析,進而判斷字幕幀,字幕鏡頭以及字幕段落。后續要對閾值的選取及模板的選擇等方面進行優化,以達到更好的實用效果。
[1]OHYA J,SHIO A,AKAMATSU S.Recognizing characters in scene images[J].IEEE Transactions on Pattern Analysis and Machine In?telligence, 1994, 16(7): 214-224.
[2]LOPRESTI D,ZHOU J.Document analysis and the world wide web[C]//Proceedings of International Workshop on Document Analysis Systems.Malvern:[s.n.],1996:651-669.
[3]黃祥林,沈蘭蓀.基于DCT壓縮域的圖象字符定位[J].中國圖象圖形學報,2002,1,7A(1):22-26.
[4]LIENHART R,STUBER F.Automatic text recognition in digital videos[R].Mannheim Germany: University of Mannheim,1995.
[5]胡宏斌.基于語義信息提取的視頻索引技術研究[D].武漢:武漢大學,2001.
[6]楊淑瑩.VC++處理程序設計[M].北京:清華大學出版社,2005.
[7]蔡波,周洞汝,胡宏斌.數字視頻中字幕檢測及提取的研究和實現[D].武漢:武漢大學,2003.
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
