連續語音識別網格技術在新聞制播平臺的應用
2010-08-10 07:47:42張秋野王力劭
電視技術 2010年2期
張秋野,王力劭,丁 鵬
(1.中國國際廣播電臺,北京 100040;2.中國科學院自動化所,北京 100080)
1 引言
眾所周知,對于視音頻類內容,經典的檢索方法依賴于前期的內容編目過程,針對多媒體信息的元數據標引細度決定了多媒體文件日后可被資產化利用的程度。“媒體”能夠成為“資產”不僅依賴內容的海量性,更重要的是在需要時能夠被低成本、高精度地定位。
基于音素網絡的連續語音識別技術顛覆了經典的新聞素材檢索方法。如果僅考慮多媒體數據內涵而不關心其外延衍生信息,并不需要人工編目標引過程,而是通過對新聞類視音頻伴音進行處理,采用音素網絡技術提取發音信息并作為元數據,這種變革為多媒體新聞制播平臺帶來質變,并能夠最大限度提升多媒體素材資產化能力。
2 非特定人連續語音識別技術
非特定人語音識別常用技術分為基于有限詞表集合的詞表識別技術和連續識別技術[1]。詞表識別技術是指對識別結果在預先給定的有限詞表中進行匹配,根據置信度來篩選結果并進行后續工作,例如語音撥號、信息查詢以及設備聲控等。連續識別技術則是將語音段落進行預處理,先將其形成“音素”集合,然后將待識別內容轉化為“音素”短語,通過語言模型在音素集合中進行類似“全文檢索”式的匹配查找。這種技術非常適合應用在語音素材檢索領域。
連續語音識別技術一般有3種基本方法:有限集全文識別并匹配關鍵詞方法[2]、關鍵詞加垃圾網絡識別法[3]和音素網絡法[4-5]。只有音素網絡能夠連續有效地在相對開放的識別集合范圍內提供良好的識別結果。因此,針對信息量大、內容靈活的新聞類素材進行檢索的要求來說,該方法是最有效的連續語音識別方法。
3 連續語音識別網格技術
3.1 音素網絡識別技術簡介
此技術分為2個階段,第1階段通常稱為索引階段,系統利用音素(音節)特性產生音素網絡;第2階段為檢索階段,根據相似度在網絡上搜尋關鍵詞。這種技術的優點是更換詞表方便,不需要二次識別,很適合新聞類音頻信息內容的識別。
音素網絡的構建就是記錄語音識別過程中間結果的一種緊湊的表示方式,是1個有向無環的加權圖,其中,音素網絡的橫坐標為時間軸,音素網絡上每個節點表示1個在特定時間結尾的音素,到達該結點的邊表示該詞的持續時間區間,邊上的權值為其對應的聲學得分。音素網絡的生成是通過語音識別過程得到的:每搜索到一個音素的尾部,系統就將這個詞記錄到音素網絡結點中,并且記錄相應的得分和狀態信息。在音素網絡上每條從起始結點到終止結點的路徑,都是一個候選識別結果,利用音素網絡系統就可以得到很多的識別結果候選,這些候選都是在搜索的競爭過程中保留下來的[5]。當用戶輸入檢索詞匯時,系統會自動將檢索詞匯轉換為音素,并在索引過程中生成的音素網絡上進行搜索,計算聲學得分作為輸出的置信度。
3.2 連續語音識別網格構建
綜上所述,采用音素網絡連續識別技術需要2個步驟:多媒體信息的識別索引過程和檢索識別過程[6]。由于識別索引是個耗時操作,因此可以采用網格技術構建音素索引集群以構成連續語音識別網格系統(Continuous Speech Recognition Grid,CSRG),從而大規模提升系統效率。圖1為應用在多媒體新聞直播平臺上典型的CSRG結構拓撲圖。

圖1 CSRG結構拓撲圖
3.3 CSRG效率分析
3.3.1 CSRG系統參數
前端的語音信號經采集系統通過AD轉換形成數據,然后通過調度系統經CSRG產生音素數據集合。從排隊論的觀點來看,新聞素材隨機到達,CSRG構成了一個M/M/n的排隊模型,CSRG服務能力參數為

式中:λ為新聞素材采集強度,t為新聞素材在CSRG節點的平均服務時間。
通過上述CSRG系統參數,可以精確定義CSRG的服務能力,并且可以根據新聞素材的生成強度來確定CSRG的規模。因此,CSRG是可控的,如果素材到達強度過大,通過適度追加網格節點,無限排隊過程是完全可避免的,而且并不需要重建集群,僅需追加少量設備投入。
3.3.2 CSRG相對于經典新聞音視頻檢索方法的優勢
為了對特定短語從新聞視音頻伴音素材庫中進行充分檢索,經典方法需要通過人工預聽進行編目標引后產生元數據,方可進行全文檢索。一般來說,識別檢索環節的算法效率與目前主流全文檢索技術是相同的,因此形成元數據所耗費的時間將產生不同檢索技術間的成本差別。
設待處理的新聞有x小時,經典的人工方法中新聞閱讀的平均語速為每小時μ個字,y個人類工作者,每個工作者記錄每小時內容的時間為內容時間的λ倍,且每小時平均錄入z個字,則最理想狀態下采用經典方法,x小時的內容通過編目轉化為文本元數據所需要的時間成本(先聽1次進行速記后再進行錄入的時間總和)t1為

同樣x小時的新聞,CSRG由n個處理單元組成,每個單元處理能力為實際內容時長的m倍,則x小時內容通過CSRG轉化為可識別音素集合的時間成本t2為

則時間成本比ρ為

根據上述公式給出算例如下:目前的計算機設備條件下最優的語素網絡識別算法至少可以達到m=1/3[2]。假設工作者記錄內容的速度均可達到140字/分鐘(速記員水平),μ=280 字/分鐘[7],則 λ=μ/140=2,z=140 字/分鐘(速錄員水平)。假設CSRG由4個節點組成,即n=4,為了達到ρ=1,即水平相當,帶入式(9)得y=48。說明為了達到同樣的檢索目的,4節點的CSRG理論上需要48個人連續工作方可滿足,如果每個工作者每天只能工作8小時,三班輪換則需要144人可達到4節點CSRG的服務水平。
上述結果是人類工作者在理想的極限條件下計算得到的,實際工作中不可能長時間集中精力進行如此高強度的工作,而且工作過程中的錯誤會高于CSRG,所以CSRG的表現將遠優于上述計算數據。由此可知,CSRG相對于經典多媒體新聞檢索方法具有極大的優勢。
4 CSRG在中國國際廣播電臺(CRI)多媒體新聞制播平臺的應用
由上述分析可知,CSRG在多媒體新聞制播平臺的應用能夠為其新聞素材帶來更高的資產化水平。因此,CRI在2008年奧運會前搭建的多媒體全業務新聞處理平臺(以下簡稱“平臺”)上,引進并充分融入了CSRG技術。
平臺涉及音頻、視頻、文稿等多種媒體形式的新聞內容涵蓋采集、制作、存儲到播出的整體流程,業務流程之間具有復雜的關系。平臺設計采用云計算模型,內部通過信息門戶(SOA)結構模型借助系統(ESB)/媒體(EMB)雙總線及插件式系統實現異構系統的在線擴充能力,并且通過企業信息門戶將所有復雜系統關系屏蔽在云體內,使用戶可以快速按需獲取功能,輕易享受云計算中軟件即服務(SaaS)特性所帶來的便捷性[8-9]。同時,在整體系統平臺上根據安全極差進行了多層次網絡受限連接[10],從而提供了靈活而安全的良好動態系統擴充架構。
在平臺中,平行于視音頻采集系統構建了CSRG系統,該系統按照SOA架構規范以插件系統方式接入平臺,成為緊密連接平臺的服務模塊。CSRG的連接方法采用帶外方式異步地對所有的新聞視音頻伴音進行索引,并將音素網絡數據存入主存儲空間,如圖2所示。
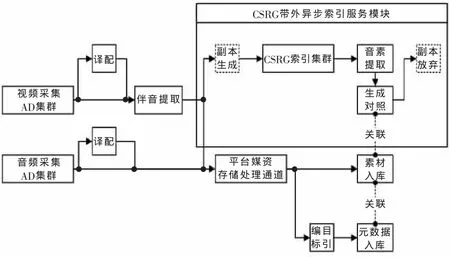
圖2 CSRG在CRI平臺的應用方式
伴以關鍵字檢索和全文檢索系統能夠帶來的外延式元數據提供,CSRG與其共同組成了企業信息門戶中強大的綜合檢索門戶,可以讓用戶采用多種手段快速定位到任意需要的多媒體內容。通過整體設計結構良好的云計算SaaS特性,用戶使用過程非常簡單,但是能夠獲得強大的資源素材再獲取能力。同時,CSRG的存在使平臺完全杜絕了多媒體新聞制播平臺中任何無效“死數據”的產生,使多媒體新聞的利用率和資產化達到了極高水平。檢索門戶界面如圖3所示,采用谷歌式(Google Like)的設計方式,便于用戶使用。
在支撐2008年奧運會宣傳報道及正式使用一年半的過程中,系統表現穩定,能力出色,每日數據吞吐量達數十吉字節,平均用戶訪問量日近百次,對于關鍵字和全文無法獲取的數據以及未做編目標引的多媒體新聞素材,CSRG表現了異常出色的檢索效果,并發峰值在50線程情況下,響應時間在3 s以內,識別正確率在96%以上,成為多媒體新聞制播平臺的輔助利器。

圖3 含語音識別檢索的谷歌式綜合檢索門戶界面
5 小結
非特定人連續語音識別技術是一種非常具有應用價值的模式識別技術[11-12],基于音素網絡和網格技術構建的連續語音識別網格(CSRG)具有極其出色的新聞視音頻伴音搜索特性。經過精確分析和充分試驗后,CRI在其多媒體全業務新聞制播平臺中創新性地引入并可控地應用了CSRG,提高了平臺的檢索應用能力及素材資產化率,獲得了良好的應用效果。
[1]崔金芳,張雪英,白靜.基于OMAP5912的嵌入式非特定人連續語音識別系統[J]. 電聲技術,2009,33(9):70-72.
[2]WEINTRAUB M.LVCSR log-likelihood ratio scoring for keyword spotting[C]//Proc.ICASSP 1995.[S.l.]:IEEE Press, 1995:297-300.
[3]LIANG Jiaen, MENG Meng, WANG Xiaorui, et al.An improved mandrin keyword spotting system using mce training and contextenhanced verification[C]//Proc.ICASSP 2006.Toulouse,France:IEEE Press, 2006:1-7.
[4]CHELBA C,ACERO A.Position specific posterior lattices for indexing speech[C]//Proc.ACL′05.Ann Arbor, Michigan:[s.n.], 2005:443-450.
[5]MEMBER K T,SFIDHA S.Rapid and accurate spoken term detection[C]//Proc.ICASSP 2007.[S.l.]:IEEE Press, 2007:346-357.
[6]RABINER L R, JUANG B H.Fundamentals of speech recognition[M].北京:清華大學出版社,1999.
[7]孫紅梅.電視新聞播音語速之我見[J].聲屏世界,2004(12):31-32.
[8]周毅,王力劭.云計算與多媒體綜合業務制播平臺[J].寬帶互聯網世界,2009(6):14-20.
[9]王力劭,周毅.云模型與多媒體全業務平臺的結構安全特性[J].電視技術,2009,33(10):10-12.
[10]廣播電臺數字化網絡工作組.廣播電臺數字化網絡建設白皮書(2009)[EB/OL].[2008-01-31].http://blog.fjtv.net/UpAttachment/2008-6/200861885613.doc.
[11]丁昊,姚天任.基于mel標度頻譜和音素分割的漢語語音單詞端點檢測方法[J].計算機與數字工程,2005(3):57-59.
[12]江銘虎,袁保宗.一種適應域的漢語N-Gram語言模型平滑算法[J].清華大學學報:自然科學版,1999,39(9):99-102.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
名師在線·上旬刊(2021年3期)2021-09-10 04:20:48
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
消費導刊(2018年10期)2018-08-20 02:56:28
家庭影院技術(2017年9期)2017-09-26 03:41:45
中國教育技術裝備(2016年11期)2016-12-01 06:52:45
中小學電教(2016年3期)2016-03-01 03:40:51
