基于語料庫的中國(guó)高級(jí)英語學(xué)習(xí)者過程詞匯使用研究
2010-12-07 07:19:12張霞
當(dāng)代外語研究 2010年5期
張 霞
(1. 上海交通大學(xué)外國(guó)語學(xué)院,上海,200240 2. 山西大學(xué)外國(guó)語學(xué)院,太原,030006)
1. 概念
過程詞匯源于長(zhǎng)期存在的“共核詞匯”(common core vocabulary)概念。早期的共核詞匯研究以詞頻為基礎(chǔ),典型的有West(1953)編制的英語常用詞總表(General Service List of English Words)。后續(xù)研究發(fā)現(xiàn),某些高頻詞不僅頻率高,分布范圍也很廣,因而得出下列結(jié)論:頻率高分布廣的共核詞匯不受“圖式”限制,因此意義也趨于多樣化,就像化學(xué)反應(yīng)中活潑的高價(jià)位金屬元素,這些詞在語言使用中的用途在于引出與話語圖式有關(guān)的特殊概念,也就是圖式詞匯(Widdowson 1983:92-93)。Widdowson這樣區(qū)別過程詞匯與圖式詞匯:“過程詞匯支持和確立了圖式詞區(qū)別圖式和語用域的地位”。
過程詞匯頻率高、分布廣且平均、意義多樣化,一直受到語言和教學(xué)研究者的關(guān)注,但其意義多樣化特征也使之成為二/外語習(xí)得的難點(diǎn)。本文的目的就在于設(shè)計(jì)一套有效的過程詞匯抽取方案,來考察外語學(xué)習(xí)者和本族語者過程詞匯使用的不同,并進(jìn)一步提出教學(xué)方面的建議。
2. 抽取
過程詞匯的抽取研究遠(yuǎn)遠(yuǎn)落后于圖式詞匯。但是鑒于兩者分布特征上的互補(bǔ)性,圖式詞匯的抽取對(duì)過程詞匯的抽取有重要參考價(jià)值。我們首先回顧三個(gè)有代表性的圖式詞匯抽取方案及其對(duì)過程詞匯抽取的啟發(fā)。
2.1 Strzalkowski指數(shù)
Strzalkowski(1994)提出一個(gè)用于計(jì)算特定術(shù)語對(duì)語料庫中特定篇章重要性的指數(shù)tf·idf。這個(gè)指數(shù)與術(shù)語在特定篇章中出現(xiàn)的頻率tf和術(shù)語在語料庫中出現(xiàn)的篇章數(shù)的倒數(shù)idf成正比。而過程詞匯與篇章數(shù)是成正比的關(guān)系,頻率和分布范圍的結(jié)合指標(biāo)如tf·idf應(yīng)能粗略區(qū)分出與篇章或話題無關(guān)的過程詞匯,但還是無法捕捉過程詞匯的全部分布特征。
2.2 關(guān)鍵詞
關(guān)鍵詞從功能和統(tǒng)計(jì)特征上都類似于上文提到的圖式詞匯和術(shù)語。一個(gè)詞的“關(guān)鍵性”是建立在下列概念上的:如果特定詞在特定篇章中的出現(xiàn)頻率高于由參照語料庫頻率信息生成的預(yù)期頻率(expected frequency),那么它就是該篇章的關(guān)鍵詞(Scott 1999;李文中1998)。在Mike Scott開發(fā)的Wordsmith軟件中,一個(gè)關(guān)鍵詞要滿足兩個(gè)條件:
a. 它在特定篇章中的出現(xiàn)頻率必須高于或等于一個(gè)指定的最低頻率;
b. 它在特定篇章中與參照語料庫中的頻率必須在統(tǒng)計(jì)意義上顯著不同,軟件中使用的統(tǒng)計(jì)標(biāo)準(zhǔn)有卡方值(chi-square)和對(duì)數(shù)似然率(log -likelihood)。
以上方案的核心是參照語料庫和預(yù)期頻率概念的引入,參照語料庫頻率信息的加入是抽取過程詞匯的又一項(xiàng)啟發(fā)。
2.3 科技術(shù)語
科技術(shù)語和次技術(shù)詞匯(sub-technical words)是圖式詞匯和過程詞匯在學(xué)術(shù)篇章條件下的另一個(gè)翻版。楊惠中(1986:98)設(shè)計(jì)了一套參數(shù)以區(qū)分科技英語(EST)語料庫中不同類型的詞匯,前提是該語料庫按學(xué)科分類。其中,distribution(D)是特定詞在不同學(xué)科中的分布范圍,average frequency(F)是該詞在不同學(xué)科子庫中出現(xiàn)頻率的均值,relative standard deviation(SD)即上文均值與標(biāo)準(zhǔn)差的比值用以測(cè)量該詞在子庫中的頻率分布情況,peakratio(P)和rangeratio(R)分別代表該詞在子庫中的最大頻率與平均頻率和最小頻率的比值。楊惠中(1986)的研究顯示,功能詞和次技術(shù)詞的SD值、P值和R值都相對(duì)較低,而科技術(shù)語的D值很低,P值和R值很高。這些信息都給本文的過程詞匯抽取方案以很大啟發(fā)。
3. 方法
3.1 過程詞匯抽取方案的重要性
在此我們要再次強(qiáng)調(diào)過程詞匯抽取方案設(shè)計(jì)的雙重重要性:首先,如上文提到圖式詞匯的抽取過程研究相對(duì)成熟,如關(guān)鍵詞和科技術(shù)語等,而過程詞匯作為具有最普遍用法的最普遍詞,其抽取工作的研究卻遠(yuǎn)遠(yuǎn)落后于圖式詞匯;其次,過程詞匯因其意義和使用的多樣化是二/外語習(xí)得中的難點(diǎn),設(shè)計(jì)一個(gè)行之有效的抽取方案可以幫助我們發(fā)現(xiàn)英語學(xué)習(xí)者使用過程詞匯的特點(diǎn)和問題,對(duì)語言教學(xué)大有裨益。
3.2 本文采用的語料庫
本文的研究對(duì)象是中國(guó)高級(jí)英語學(xué)習(xí)者的過程詞使用,主要采用的英語學(xué)習(xí)者語料庫是COLSEC(College Learners’ Spoken English Corpus)和CLEC(Chinese Learner English Corpus)的非英語專業(yè)大學(xué)生部分COLEC(College Learner English Corpus)。這兩個(gè)語料庫是英語學(xué)習(xí)者口語和筆語產(chǎn)出的姊妹庫,也是目前為止最具代表性的中國(guó)非英語專業(yè)大學(xué)生英語產(chǎn)出的語料庫。由于采用Granger(1996)的中介語對(duì)比分析法(CIA),本文采用的本族語對(duì)比語料庫是BNC(British National Corpus)的會(huì)話部分和LOCNESS(Louvain Corpus of Native English Essays),后者是比利時(shí)Louvain大學(xué)建立的本族語大學(xué)生作文語料庫,也是ICLE(International Corpus of Learner English)系列研究中常用的本族語筆語參照庫。在經(jīng)過“去碼”(clean text)等一系列處理后,兩個(gè)口語語料庫均為560,000詞左右,兩個(gè)筆語語料庫均為280,000詞左右。
3.3 本文的過程詞匯抽取方案
基于Widdowson(1983)的過程詞匯概念并參考前人經(jīng)驗(yàn),本文的過程詞匯抽取采取了3個(gè)統(tǒng)計(jì)標(biāo)準(zhǔn):初選標(biāo)準(zhǔn)是頻率,過程詞必須在語料庫中頻繁出現(xiàn),本文的標(biāo)準(zhǔn)是每個(gè)語料庫的前150個(gè)高頻詞;第二和第三個(gè)標(biāo)準(zhǔn)分別考察詞的分布范圍和分布均勻程度。實(shí)現(xiàn)過程如下:
a. 把要研究的語料庫盡量均勻和隨機(jī)地分成7等分。以COLSEC為例說明隨機(jī)標(biāo)準(zhǔn)的實(shí)現(xiàn),COLSEC由302個(gè)獨(dú)立篇章構(gòu)成,編號(hào)從1到302;然后用一個(gè)隨機(jī)數(shù)生成工具把這302個(gè)編號(hào)盡量平均地編為7組;再用隨機(jī)生成的7組編號(hào)把原語料庫編為7個(gè)子庫。
b. 在隨機(jī)生成的7個(gè)子庫上用Wordsmith軟件做詳細(xì)的一致性分析(detailed consistency analysis)①分析,取得每個(gè)子庫中都出現(xiàn)的前150個(gè)高頻詞在每個(gè)子庫中的頻率信息,這樣取得的150個(gè)詞滿足了本文過程詞匯的兩個(gè)初選標(biāo)準(zhǔn),分布范圍廣且出現(xiàn)頻率高。
c. 把高頻詞在7個(gè)子庫中的頻率信息“統(tǒng)一化”(normalization②)處理之后,可以計(jì)算得到每個(gè)詞的變異系數(shù)CV(coefficient of variance③),CV值小則意味著該詞在7個(gè)子庫中分布均勻,反之CV值大則意味著該詞在7個(gè)子庫中分布不均勻。將150詞按CV值從小到大排列后取得的前100詞即本文要研究的過程詞匯樣本。
以LOCNESS為例,建成的數(shù)據(jù)庫大致如表1所示:
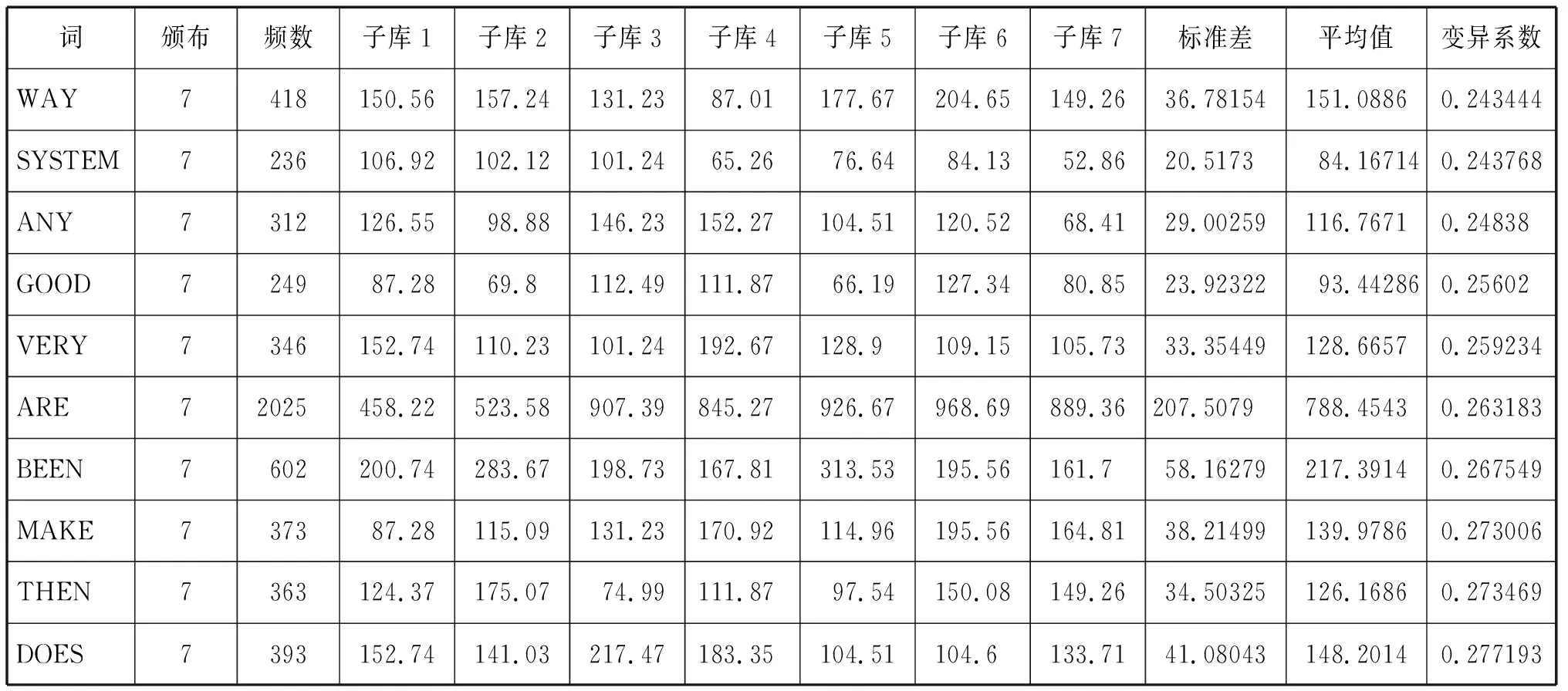
表1 LOCNESS過程詞匯數(shù)據(jù)庫示例
這樣我們就盡可能地滿足了Widdowson(1983)提出的高頻、分布廣且平均的判斷標(biāo)準(zhǔn)。
4. 結(jié)果和分析
這部分中,我們將在兩個(gè)層面上對(duì)比分析外語學(xué)習(xí)者與本族語者的過程詞匯使用:較泛層面的過程詞等級(jí)信息和更細(xì)一層的實(shí)虛詞分布。前者使用的統(tǒng)計(jì)工具是秩相關(guān)和聚類分析,后者使用的是單因變量多因素方差分析。
4.1 過程詞等級(jí)信息
我們已按照頻率、分布范圍和變異系數(shù)從各個(gè)語料庫中抽取了100個(gè)過程詞并加以排序,以表明特定詞對(duì)特定語言使用的“共核”程度。然后編寫了一個(gè)能夠返回各詞在各語料庫中等級(jí)的小程式,對(duì)得到的等級(jí)信息進(jìn)行秩相關(guān)分析,應(yīng)用的系數(shù)是spearman’s rho。并在此基礎(chǔ)上進(jìn)行等級(jí)聚類分析,以揭示過程詞匯等級(jí)信息在各語料庫之間的相互關(guān)系。結(jié)果如表2和圖1所示:

表2 四庫100個(gè)過程詞的秩相關(guān)分析
注:**在0.01水平上顯著;*在0.05水平上顯著.
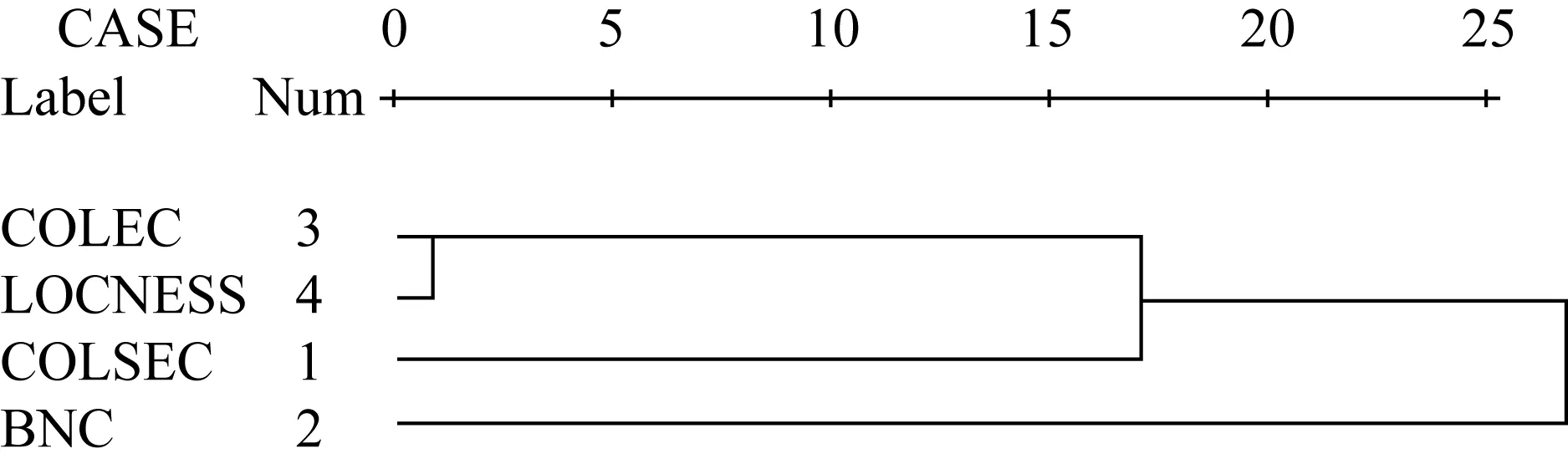
圖1 100個(gè)過程詞等級(jí)信息的四庫聚類分析
從表2的相關(guān)系數(shù)矩陣和聚類分析樹形圖1中可以看出,英語學(xué)習(xí)者和本族語者的筆語在過程詞匯使用上最為相近,相關(guān)系數(shù)為0.595;而英語學(xué)習(xí)者口語中的過程詞使用與本族語口語相比,更為接近筆語簇的用法。
為進(jìn)一步確認(rèn)和豐富以上結(jié)論,我們又引入兩個(gè)語料庫抽取并建立了過程詞數(shù)據(jù)庫,FLOB(Freiberg LOB Corpus of British English)和COLEN(College English Corpus),與以上四庫對(duì)比過程詞匯的使用。與LOCNESS的本族語大學(xué)生筆語相比,前者代表更大范圍和更多場(chǎng)景下本族語的筆語產(chǎn)出,后者則是Xue(2004)編輯的目前中國(guó)通用的四種大學(xué)英語教材語料庫,用以檢驗(yàn)英語學(xué)習(xí)者用法受教材用法的影響,兩庫大小均為1,000,000詞左右。秩相關(guān)分析中除Spearman’s rho系數(shù)外我們還引入了另一考慮結(jié)點(diǎn)影響的系數(shù)Kendall’s tau_b,得出結(jié)果如圖2和表3所示:
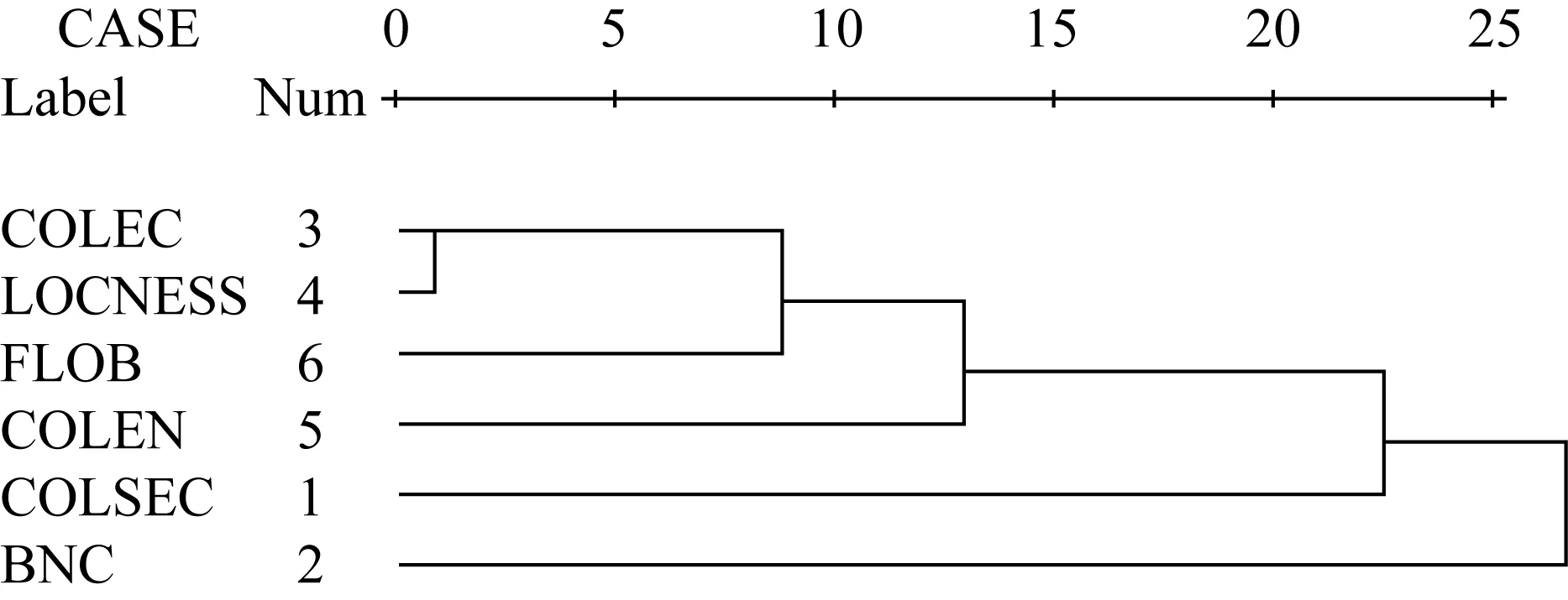
圖2 100個(gè)過程詞等級(jí)信息的六庫聚類分析
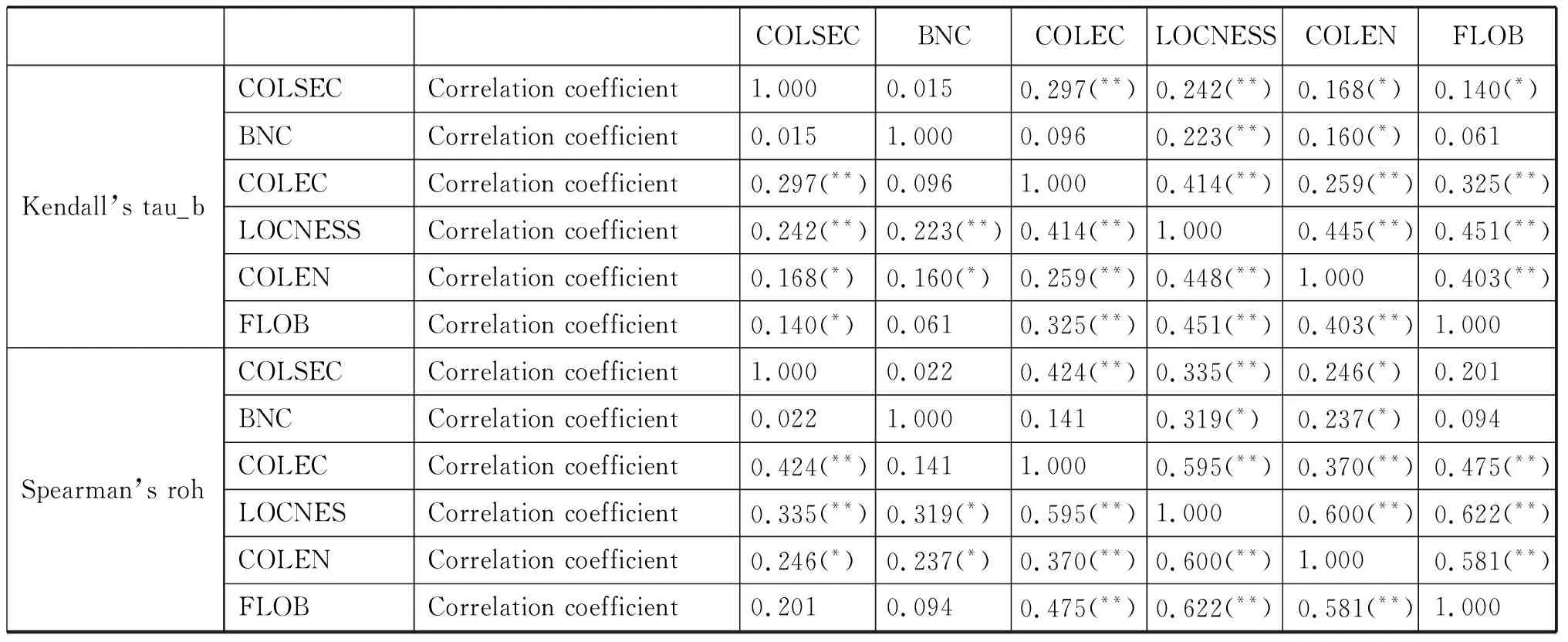
COLSECBNCCOLECLOCNESSCOLENFLOBKendall’s tau_bSpearman’s rohCOLSECCorrelation coefficient1.000 0.015 0.297(**)0.242(**)0.168(*)0.140(*)BNCCorrelation coefficient0.0151.0000.0960.223(**)0.160(*)0.061COLECCorrelation coefficient0.297(**)0.0961.0000.414(**)0.259(**)0.325(**)LOCNESSCorrelation coefficient0.242(**)0.223(**)0.414(**)1.0000.445(**)0.451(**)COLENCorrelation coefficient0.168(*)0.160(*)0.259(**)0.448(**)1.0000.403(**)FLOBCorrelation coefficient0.140(*)0.0610.325(**)0.451(**)0.403(**)1.000COLSECCorrelation coefficient1.0000.0220.424(**)0.335(**)0.246(*)0.201BNCCorrelation coefficient0.0221.0000.1410.319(*)0.237(*)0.094COLECCorrelation coefficient0.424(**)0.1411.0000.595(**)0.370(**)0.475(**)LOCNESCorrelation coefficient0.335(**)0.319(*)0.595(**)1.0000.600(**)0.622(**)COLENCorrelation coefficient0.246(*)0.237(*)0.370(**)0.600(**)1.0000.581(**)FLOBCorrelation coefficient0.2010.0940.475(**)0.622(**)0.581(**)1.000
注:**在0.01水平上顯著;*在0.05水平上顯著.
表2相關(guān)系數(shù)矩陣和聚類分析樹形圖2再次確認(rèn)了以上結(jié)論,即筆語用法成簇。在0.01的顯著水平下,三個(gè)筆語庫(COLEC,LOCNESS,FLOB)的最低相關(guān)系數(shù)Spearman’s rho達(dá)到了0.475,而結(jié)點(diǎn)影響系數(shù)Kendall’s tau_b也達(dá)到了0.325。與本族語一般的筆語產(chǎn)出相比,本族語大學(xué)生的筆語產(chǎn)出更接近中國(guó)高層英語學(xué)習(xí)者的筆語產(chǎn)出。一個(gè)新的發(fā)現(xiàn)是,COLEN與其它各庫的相關(guān)都顯著,與LOCNESS相關(guān)系數(shù)最大,為0.600,與BNC相關(guān)系數(shù)最小,也達(dá)到了0.237。也就是說教材中的過程詞使用是介于筆語簇和口語簇之間的一個(gè)獨(dú)特變體,沒有明顯的聚類特征。
4.2 實(shí)虛詞的分布
為了進(jìn)一步考察不同語言社團(tuán)中的過程詞匯使用,我們又把四庫中的過程詞區(qū)別為實(shí)詞和虛詞兩大范疇,并加以標(biāo)注和統(tǒng)計(jì)。COLSEC和BNC即英語學(xué)習(xí)者和本族語口語中實(shí)虛詞的比例分別為2∶3和1∶3,COLEC和LOCNESS即英語學(xué)習(xí)者和本族語筆語中實(shí)虛詞的比例分別約為2∶3和1∶4,結(jié)果如表4所示:
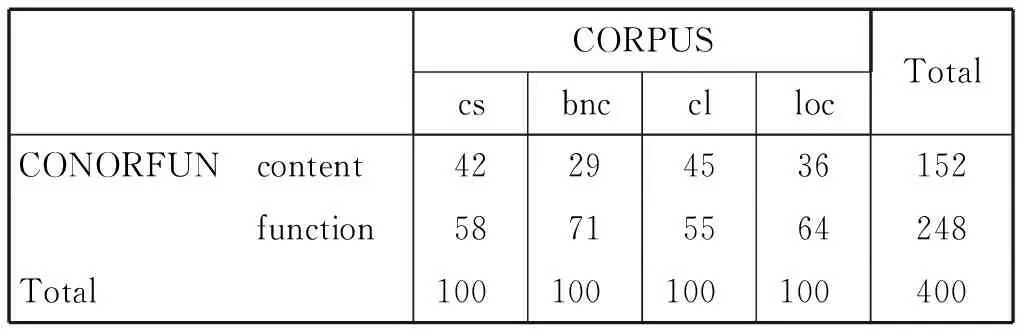
表4 四庫中過程詞匯實(shí)虛詞的統(tǒng)計(jì)信息
為進(jìn)一步確認(rèn)由實(shí)虛詞比例得到的直觀印象的統(tǒng)計(jì)顯著性,我們首先作了2(英語學(xué)習(xí)者和本族語者)×2(實(shí)詞和虛詞)單因變量多因素方差分析(ANOVA)。結(jié)果顯示,就過程詞匯的實(shí)虛詞分布而言,英語學(xué)習(xí)者和本族語者這兩個(gè)語言使用團(tuán)體有顯著差別(F(1,3977)=23.997,p=0.000),這從統(tǒng)計(jì)意義上證實(shí)了我們的初步印象。
與本族語用法相比,英語學(xué)習(xí)者的過程詞匯更可能是實(shí)詞。可能的原因包括:第一、中國(guó)英語學(xué)習(xí)者不習(xí)慣使用虛詞,因?yàn)樽鳛槟刚Z的中文虛詞極少;第二、英語學(xué)習(xí)者的用法不如本族語用法多樣化,他/她們對(duì)于概念和語言形式的對(duì)應(yīng)關(guān)系或語言使用因循性(conventionality)的掌握沒有那么豐富的層次,導(dǎo)致他/她們的語言產(chǎn)出有時(shí)過于重復(fù),有時(shí)又用已掌握的語法規(guī)則“過分生成”一些非母語式的用法。這些導(dǎo)致英語學(xué)習(xí)者用法的單調(diào)性,因此其統(tǒng)計(jì)意義上的過程詞匯中出現(xiàn)高比例的實(shí)詞。如果本族語者對(duì)于實(shí)詞的過程化使用可以看做詞匯的虛化或語法化過程,那么英語學(xué)習(xí)者對(duì)于實(shí)詞的過多使用則有多重原因,如中介語的、二語內(nèi)的和語際的原因等等;如果說本族語對(duì)實(shí)詞的過程化使用是全社團(tuán)的使用共性,那么英語學(xué)習(xí)者對(duì)實(shí)詞的過度使用則更有可能是個(gè)人策略的規(guī)模化反映。
為進(jìn)一步考察口筆語文體對(duì)過程詞匯實(shí)虛詞分布的影響,我們又做了4(COLSEC,COLEC,BNC和LOCNESS)×2(實(shí)詞和虛詞)單因變量多因素方差分析,結(jié)果再次顯示語料庫對(duì)過程詞匯實(shí)虛詞的分布具有顯著影響(F(1,399)=13.557,p=.000)。
進(jìn)行庫與庫之間的兩兩比較,我們發(fā)現(xiàn),英語學(xué)習(xí)者的口筆語中過程詞匯的實(shí)虛詞分布模式相似,在兩兩比較統(tǒng)計(jì)意義上不顯著(p=0.344),而其它各對(duì)都有顯著不同(p<0.01)。本族語的口筆語比較實(shí)虛詞分布有顯著不同,筆語虛詞使用更多,進(jìn)一步證明英語學(xué)習(xí)者的文體意識(shí)還是有待發(fā)展。
5. 結(jié)論和展望
本文在Widdowson(1983)提出的過程詞匯概念基礎(chǔ)上提出了一套過程詞匯的抽取方案④,并將之應(yīng)用于英語學(xué)習(xí)者和本族語者的過程詞匯使用考察中。較泛層面的秩相關(guān)和聚類分析結(jié)論如下:英語學(xué)習(xí)者和本族語的筆語在過程詞匯使用上最為相近,相關(guān)系數(shù)為0.595(p=0.000);COLSEC與BNC,即英語學(xué)習(xí)者口語中的過程詞使用與本族語口語相比,更為接近筆語簇的用法。更細(xì)層面的各庫過程詞匯實(shí)虛詞分布的方差分析結(jié)論如下:就過程詞匯的實(shí)虛詞分布而言,英語學(xué)習(xí)者和本族語者這兩個(gè)語言使用團(tuán)體有顯著差別,英語學(xué)習(xí)者的過程詞匯更可能是實(shí)詞,這可能是英語學(xué)習(xí)者用法單調(diào)和母語中虛詞用法較少導(dǎo)致;英語學(xué)習(xí)者的口筆語中過程詞匯的實(shí)虛詞分布模式相似,而本族語的口筆語比較,筆語虛詞使用更多,英語學(xué)習(xí)者的文體意識(shí)有待發(fā)展。
當(dāng)然,抽取出的過程詞匯數(shù)據(jù)庫的應(yīng)用還不止這些,還可以做更深層次的比較分析,如圍繞各具體詞的詞塊(lexical chunk),詞性碼串(POS tag sequence)和搭配(collocation),類聯(lián)結(jié)(colligation)的研究。過程詞匯的分布模式?jīng)Q定了它與語言使用因循性的密切聯(lián)系,以上各個(gè)層面的研究一定會(huì)有更豐富的成果,揭示英語學(xué)習(xí)者過程詞匯使用和語言使用因循性掌握的特點(diǎn)和問題,對(duì)語言教學(xué)實(shí)踐的啟示也會(huì)更加具體。
附注:
① 一致性分析是Wordsmith的一項(xiàng)功能,可以找到在特定語料庫所有子庫中都出現(xiàn)的詞,分為簡(jiǎn)單和詳細(xì)兩種模式。詳細(xì)的一致性分析能顯示特定詞在各子庫中的頻率信息。
② 統(tǒng)一化處理就是把不同規(guī)模語料及其生成的頻率信息按比例統(tǒng)一到相同的基礎(chǔ)上,以使頻率信息有可比性。本文
的統(tǒng)一化標(biāo)準(zhǔn)是100,000詞,即7個(gè)子庫的頻率信息都按比例調(diào)整為相應(yīng)的100,000詞語料中的預(yù)期比例。
③ 在概率理論和統(tǒng)計(jì)學(xué)中變異系數(shù)(CV)是一個(gè)用以測(cè)量概率分布的統(tǒng)一化尺度,定義為標(biāo)準(zhǔn)差σ與平均值μ的比值:CV=σ/μ。
④ 需要獲取從四庫中抽取的過程詞匯范例者請(qǐng)與作者聯(lián)系。
Scott, M. 1999.WordsmithV3.0Manual[M]. Oxford: Oxford University Press.
Strzalkowski, T. 1994. Document Representation in Natural Language Text Retrieval [R]. Human Language Technology Conference, Plainsboro, New Jersey.
West, M. 1953.AGeneralServiceList[M]. London: Longman.
Widdowson, H. G. 1983.LearningPurposeandLanguageUse[M]. Oxford: Oxford University Press.
Willis, D. 1990.TheLexicalSyllabus:ANewApproachtoLanguageTeaching[M]. London: Collins COBUILD.
Xue, X. 2004. The Pedagogic COLEN Corpus and Corpus-orientated Website Construction [R]. The 4th International Symposium on ELT in Beijing, China.
李文中.1998. An Analysis of the Lexical Words & Word Combinations in the College Learner English Corpus [D]. Ph.D. dissertation, Shanghai Jiaotong University.
楊惠中.1986. A new technique for identifying scientific/technical terms and describing science texts: an interim report [J].LiteraryandLinguisticComputing(2): 93-103.
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
山東醫(yī)藥(2017年35期)2017-10-10 02:45:28
新東方英語·中學(xué)版(2017年9期)2017-09-25 20:25:46
小學(xué)生導(dǎo)刊(低年級(jí))(2016年2期)2016-02-24 23:02:11
小天使·五年級(jí)語數(shù)英綜合(2014年5期)2014-06-25 05:22:42
中華胰腺病雜志(2013年3期)2013-10-19 03:16:56
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
