利用接觸跟蹤機制實現Email蠕蟲的檢測
2011-02-10 05:45:26黃智勇曾孝平周建林石幸利
電子科技大學學報 2011年3期
黃智勇,曾孝平,周建林,石幸利
(1. 重慶大學通信工程學院 重慶 沙平壩區 400044;2. 重慶科技學院學報編輯部 重慶 渝中區 401331)
近年來,Email蠕蟲逐漸成為一種主要的網絡攻擊手段,各種Email蠕蟲程序在網絡中廣泛傳播[1],如Melissa、Love Letter、W 32/Sircam、SoBig、MyDoom、Bagle和Netsky等[2]。大量無用的Email數據存在于整個網絡,直接導致網絡數據傳輸阻塞,嚴重地影響了郵件系統網絡的工作性能[3],針對Email蠕蟲的檢測和控制成為研究熱點之一。文獻[4]介紹的“反饋防御系統”檢測法(feedback defense system),利用現有的入侵檢測軟件對可疑郵件進行攔截,再采用虛擬的蜜罐系統進行分析檢測。該方法對Email用戶有很好的保護作用,但是對于Email蠕蟲在網絡中轉播的主動控制,效果不是很明顯。文獻[5]介紹的利用機器學習對網絡異常流量進行監測方法,能夠有效地減少檢測誤報率,但是該方法需要對網絡流量進行統計,存在一定的檢測延遲性。文獻[6]提出利用熵值來歸類垃圾郵件,即通過對垃圾郵件行為特征的分析(如在單位時間段里連續發送郵件的數量),利用熵值的大小快速區分垃圾郵件和正常郵件。該歸類方法的精度取決于閾值的大小,對于防御者來說,很難找到一個合適的閾值使檢測結果同時達到最小的假陽性和最小的假陰性。針對這些問題,為了提高檢測速度,并保證檢測的精度,針對Email蠕蟲的傳播,本文提出了CTCBF 檢測方法,該方法應用了傳染病檢測的接觸跟蹤機制[7-8],通過建立跟蹤鏈對異常的Email傳播過程進行監控,并根據跟蹤鏈的狀態確認Email蠕蟲感染節點。
1 CTCBF檢測方法
1.1 檢測系統基于假設
Email蠕蟲最大的特點是能夠利用Email的方式進行主動自我傳播,本文的檢測機制是基于蠕蟲的這一行為特征進行研究的。系統考慮了兩種行為特征——感染特征和連接特征。感染特征指被監控節點出現了異常的主動連接其他網絡節點的行為(如在單位時間段里主動連接其他節點的數目超過規定的閾值);連接特征指節點被感染節點或者可疑節點連接的行為。根據這兩種特征,對網絡中的節點做如下假設:
1) 一個節點如果是感染節點,那么它一定會再次感染其他節點。
2) 一個節點如果出現了感染特征,那么它可能已經是感染節點。
3) 一個節點如果出現了連接特征,那么它存在被其他節點感染的可能性,一旦它又出現感染特征,那么它也可能成為新的感染節點。
1.2 CTCBF算法
CTCBF算法由單點檢測算法和多點跟蹤算法兩部分組成:1) 利用單點檢測算法對單個節點的感染特征進行檢測;2) 利用跟蹤算法提高檢測精度,在單個節點感染特征的基礎上,通過分析節點之間的連接特征,從而確認真正的感染節點。
1.2.1 單點檢測算法


利用文獻[10]的試驗數據,本文進行仿真。如圖1所示,整個觀測周期劃分為4個時間段:T1、T2、T3、T4,利用“差分熵”的定義分別對4個時間段的數據進行計算。分析仿真結果,得出以下結論:
1) 當v(t)>>M 時,V(t)與V′(t)的相似度較高,DH→0。
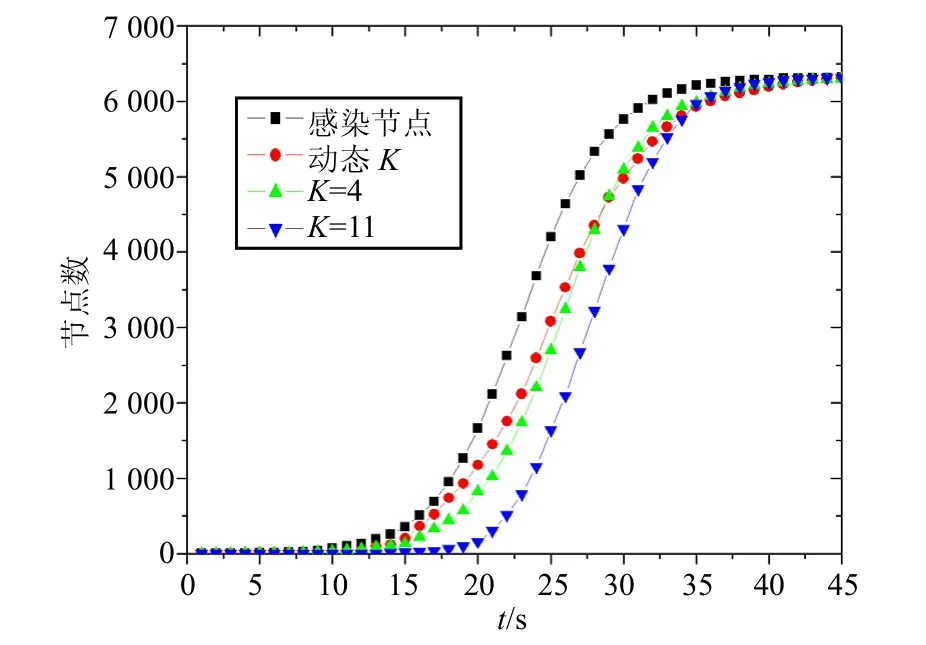
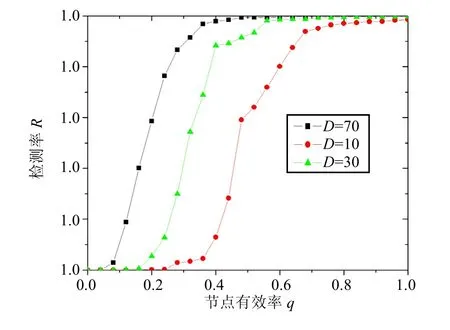
2) 當v(t)< 圖1 差分熵檢測效果 多點跟蹤的目的是在假陽性較高的單點檢測機制基礎上,利用跟蹤鏈提高檢測精度。 定義 1 網絡中的任意節點r∈S都可能與其他節點發生連接,并且成為任意跟蹤鏈的根節點,所以每個節點分配S-1跟蹤鏈存儲空間。 定義 3 根據網絡節點的行為特征,將節點劃分為正常類型(NS);連接類型(CS);可疑類型(SS);感染類型(IS) 4個類型。 1) NS:沒有出現感染特征和連接特征; 2) CS:出現連接特征,但沒有出現感染特征; 3) SS:出現感染特征; 4) IS:出現過感染特征,且所在跟蹤鏈被確認為感染鏈。 根據定義,算法初始化為: ① 節點之間建立跟蹤鏈的聯系必須存在因果關系,即一個NS類型的節點必須首先被其他節點感染以后才可能去感染另外的節點。 ② 由于重復感染的存在,跟蹤鏈上的節點類型一旦被確定為感染類型,所有節點信息應立刻被重新初始化。采用該算法可以發現更多的感染路徑,加快了檢測速度。 ③ 閾值K的大小直接決定了系統的性能,K值越大,跟蹤鏈的誤報率越低,但是檢測速度會降低;K值越小,檢測的速度提高,系統的精度會降低。本文將介紹一種動態調節閾值K的方法來平衡檢測精度和速度之間的關系。 圖2 跟蹤鏈建立過程 典型的蠕蟲傳播周期分為初始期、上升期、飽和期3個階段。定義?I為單位時間段內增加的感染節點數目,用?I代表網絡的感染等級。 2) 上升期:感染節點數目逐漸增多,增長速度急劇加快,?I迅速增大,網絡感染等級增加。 3) 飽和期:感染節點數目的增加速度減慢,?I逐漸減小,網絡感染等級逐漸降低。 本文的策略是在網絡感染等級較低時,采用較大的閾值K以提高跟蹤鏈的精度,減少誤報率;在網絡感染等級較高時,采用較小的閾值K以提高跟蹤鏈的速度,減少更多節點被感染的可能性。分別定義Kmin和Kmax為上限閾值和下限閾值,動態閾值K( t)的算法為: 上限閾值和下限閾值的設定限制了動態閾值參數的波動范圍。區別于單點檢測,需要滿足閾值K越大,檢測精度會越高,但同時也降低了檢測靈敏度。Kmax值不能設置過大,可以綜合其他因素進行設定,如跟蹤算法的效率、網絡拓撲結構、蠕蟲傳播效率等。 本文應用C語言編寫仿真程序來驗證跟蹤算法的性能。設定網絡總節點數 S= 6 400;網絡中的節點可以描述為表示節點i的狀態;irP表示節點i被感染的概率,每個節點的感染概率不能確定,但是可以作如下假設: 1) 網絡中節點數目足夠多; 2) 節點具有分布性,且節點之間的連接行為相互獨立。 基于以上兩點假設,定義irP服從高斯分布代表節點i的度數,節點度數越高,感染其他節點的可能性越大。仿真實驗將驗證跟蹤鏈的效率和跟蹤鏈的魯棒性。 圖3為在不同閾值K的情況下,跟蹤鏈的跟蹤效率的變化,閾值越大,跟蹤鏈被確認需要的時間也越長。K=11時,跟蹤鏈的檢測速度明顯慢于K=4時的檢測速度。采用動態閾值算法,由于仿真僅僅驗證動態閾值算法在不同感染等級下對跟蹤鏈的影響,所以,根據前文介紹的閾值設定原則,在有效范圍內設置參數初始狀態下,仿真結果顯示算法能夠根據不同的感染等級?I調整動態閾值達到調整檢測速度的目的。 圖3 不同的閾值K檢測效果對比 跟蹤鏈的魯棒性直接影響檢測的效率,考慮影響跟蹤鏈魯棒性的兩個因素: 1) 節點度數。節點度數D體現為蠕蟲發送Email的目標地址數目,通常蠕蟲不僅僅從被感染節點獲取Email地址,也可以從網絡收集得到。攻擊者為了提高攻擊效率,會收集更多的Email地址,而節點度數的提高更有利于跟蹤鏈的建立。 2) 節點有效率。前面討論的情況都基于所有網絡節點能夠參與跟蹤鏈建立的假設,但實際情況并非如此。如一些節點沒有安裝檢測軟件,一些節點參與了跟蹤鏈的建立,但是由于受到攻擊(如DOS攻擊)而失效,這類網絡節點統稱為失效節點。能夠有效參與跟蹤鏈建立的節點稱為有效節點,定義為有效節點數目,定義節點有效率節點有效率越高,建立跟蹤鏈的可能性就越大。定義檢測率為通過跟蹤鏈確定的感染節點數目,為被感染節點數目。 圖4 跟蹤鏈魯棒性仿真 如圖4所示,產生的3個隨機網絡平均節點度數分別為 D= 70,30,10。在范圍[0,1]內逐步增加節點有效率q,分別運行跟蹤算法。結果顯示: 1) 當D= 70時,即使存在大量的無效節點,算法仍然維持比較高的檢測率R(當q>0.3時,R>0.95);2) 節點度數減小,要維持高的檢測率R>0.95,需要存在大量的有效節點,當D=30時,q>0.5,當D=10時,q>0.7。從攻擊者的角度看,高的節點度數更有利于維持攻擊網絡的魯棒性,同樣,高的節點度數也更有利于跟蹤鏈發現更多的感染節點。刻意地降低節點度數會降低跟蹤鏈的魯棒性,同時也會使攻擊網絡更容易被破壞。另外,減小失效節點的數量能夠增強跟蹤鏈的魯棒性。 本文闡述了基于CTCBF機制檢測Email蠕蟲的方法,檢測系統由單點檢測和多點跟蹤兩部分組成。分別介紹了利用“差分熵”歸類的單點檢測算法和利用接觸跟蹤機制的多點跟蹤算法。為了動態適應網絡環境變化,采用了動態閾值算法。與單點檢測機制相比較,多點跟蹤機制通過傳輸跟蹤鏈能夠有效減小單點檢測誤差引起的誤報率。通過仿真,認為CTCBF機制能夠快速準確實現對Email蠕蟲傳播的檢測。今后的研究工作還需要進一步提高單點檢測算法和多點跟蹤算法的檢測效率,特別是在復雜多變的網絡環境下能夠保證算法的高效性。 [1] KHERA R. Messaging anti-abuse working group[EB/OL].[2009-09-25]. http://www.maawg.org. [2] CERT/CC advisories[EB/OL]. [2009-09-27]. http://www.cert.org/ advisories. [3] SYMATEC. Internet security threat report trends Jan-June’ 07[EB/OL]. [2009-08-02]. http://www.symantec.com. [4] ZOU C, Gong W, TOWSLEY D. Feedback email worm defense system for enterprise networks[R]//Umass: ECE,2004. [5] GUPTA A, SEKAR R. An approach for detecting self-propagating Email using anomaly detection[C]//Proceedings of Recent Advances in Intrusion Detection.Pittsburgh PA: Springer, 2003: 55-72. [6] HUSNA H, PHITHAKKITNUKOON S, DANTU R. Traffic shaping of spam botnets[C]//Proceedings of CCNC 2008,5th IEEE. Las Vegas, NV: IEEE, 2008: 786-787. [7] HYMANA J, LI Jia, STANLEY E. Modeling the impact of random screening and contact tracing in reducing the spread of HIV[J]. Mathematical Biosciences, 2003, 181: 1-16. [8] EAMES K, KEELING J. Contact tracing and disease control[C]//Proceedings of the Royal Society. London:PubMed, 2003: 443-454. [9] SHANON C. A mathematical theory of communication[J].Bell System Technical Journal, 1948: 379-423. [10] ZHANG Jun. Storm Worm & Botnet Analysis[EB/OL].[2009-03-02]. http://www. securitylabs.websense.com/content. [11] ZOU C, TOWSLEY D, GONG W. Modeling and simulation study of the propagation and defense of internet email worm[J]. IEEE Transactions on Dependable and Secure Computing, 2007, 4(2): 105-118. 編 輯 張 俊
1.2.2 多點跟蹤算法





1.3 動態閾值
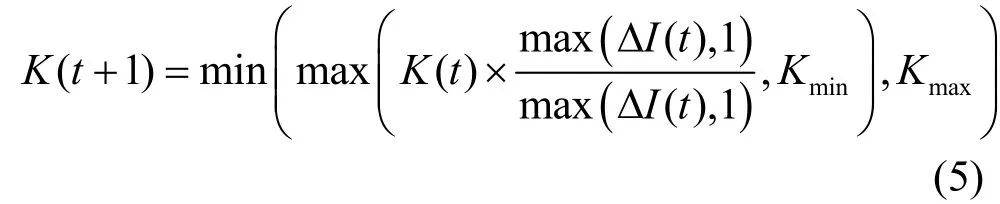
2 試驗仿真
2.1 跟蹤鏈效率仿真
2.2 跟蹤鏈魯棒性仿真
3 總結與展望
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
