Apriori算法改進研究
2011-04-23 12:11:04羅曉麗福州職業技術學院計算機系福建福州350007
長江大學學報(自科版) 2011年7期
羅曉麗 (福州職業技術學院計算機系,福建福州350007)
隨著信息時代的到來,越來越多數據大量涌現,如何從這些大量的、復雜的、有噪聲的原始數據中發現有價值的信息成為目前數據挖掘的主要任務,數據挖掘[1]即從大量的、不完全的、有噪聲的數據中,挖掘出的隱含的、事先未知的、潛在的對決策者有用的信息和知識的過程。Agrawal等提出經典的關聯規則挖掘算法,即Apriori算法[2]。該算法每次循環都要掃描一遍數據庫,用來計算候選項集的支持數。但隨著項集階數的增加,候選項集的個數逐漸減少,包含這些候選項集的記錄數也越來越少,因而沒有必要對數據庫中的所有記錄都進行掃描計算支持數,由此導致數據挖掘效率較低。為此,許多學者對Apriori算法進行了改進,如基于散列 (Hash)技術的優化算法[3]、基于項編碼的Cording-Apriori算法[4](簡稱CA算法)、基于減少數據掃描記錄數的AprioriTid算法[5](簡稱TID算法)等。筆者在研究上述改進算法的基礎上,通過壓縮原有數據庫生成包含有頻繁1-項集的數據庫作為掃描的數據庫,并運用CA算法進行編碼轉換,逐步縮小了數據庫搜索的時間和編碼轉換的時間和位長,從而提高數據挖掘的效率。
1 Apriori算法原理
Agrawal等首次提出將關聯規則[6]應用于解決挖掘顧客交易數據中項目集間問題,其核心是基于2階段頻繁集思想 (即發現頻繁項目集和生成關聯規則)的遞推算法,其典型算法是Apriori算法,該算法的主要內容如下:①使用逐層搜索的迭代方法。首先掃描數據庫,計算出各個頻繁1-項集的支持度,找出所有頻繁1-項集L1,得到頻繁1-項集的集合。②連接步。由2個只有一個項不同的頻繁1-項集進行JOIN運算得到的候選頻繁2-項目集C2。③剪枝步。對C2進行修剪得到頻繁項集L2。④通過掃描數據庫,計算各個項集的支持度,將不滿足支持度的項目集去掉,通過迭代循環,重復步驟2~4,直到找到最大頻繁項集,此時算法停止。
隨著掃描的數據量增大,Apriori算法也呈現出明顯不足:①候選集Ck中的每個元素都必須通過掃描數據庫一次計算支持度,來確定其是否能成為頻繁項集Lk中的元素,而多次掃描事務數據庫,需要很大的I/O負載。②隨著掃描數據庫的事務量增大,可能有龐大的候選集產生。規模巨大的候選項集,不僅處理需要占用大量的主存空間,而且算法必須耗費大量的時間來處理。例如:對于頻繁1-項集個數如果是10000個,那么可能產生的候選集就會有個。
2 基于項編碼的CA算法
基于項編碼的CA算法[7],只需要掃描數據庫一次,并對每個項完成編碼轉換,根據它在數據庫中出現的事務記錄用0和1進行編碼,以后的過程都是針對編碼進行運算,統計1的個數計算支持數k項頻繁項集,通過編碼與運算生成k+1項頻繁項集,不需要再次掃描數據庫。其具體特點如下:①編碼運算。該算法只需要掃描一次數據庫,并對每個項在某個事務記錄中是否出現進行編碼,以 “出現為1,不出現為0”的原則進行編碼,以后的過程都是針對編碼進行與運算。與Apriori算法相比,該算法僅掃描數據庫一次,因而減少了算法的I/O負載。②連接前剪枝。CA算法在對頻繁 (k-1)-項集Lk-1通過與運算進行連接,得到候選頻繁k-項集Ck,并對Lk-1中1的個數進行計數處理,根據計數結果刪除Lk-1中包含出現次數小于 (k-1)的項的項集,以減少參加連接的 (k-1)項的數量,從而降低了組合的數據量,也減小了候選頻繁k-項集Ck的大小。但該算法在進行編碼轉換時需要消耗大量時間,而且編碼數位過長,I/O的負載過大;同時由于編碼過長,造成與運算的繁復,可見記錄的個數極大地影響了該算法運行的時間。
3 基于減少數據掃描記錄數的Tid算法
Tid算法[5]使用了Apriori-Gen函數,以便在遍歷事務數據庫之前確定候選頻繁項集。該算法的特點是在第一次掃描之后就不再使用原來的事務數據庫來計算支持度,而是通過在第一次掃描生成的候選事務數據庫Ck,來計算候選頻繁項集的支持度。隨著頻繁項集的維數的增加,掃描的數據庫遂漸縮小,因而減少了掃描的時間。尤其是對于數據庫的記錄是海量數據時,運行掃描的時間大大減少,同時減少的數據量,減少了內存的占用空間,因而數據挖掘的效率較高。
4 改進算法
通過上述分析可知,要提高算法的運行效率,可從如下方面進行處理:①降低掃描事務的記錄數。②計算支持度時減少掃描數據庫的次數。由此筆者提出通過減少數據庫的記錄數來減小編碼轉換時間的改進算法,其基本思路是先進行一次掃描,計算出候選頻繁1-項目集,將含有1-項目集的記錄重新組合生成新的數據庫 (比原來的數據庫記錄大為減少,尤其是海量數據庫減少的記錄數量更多),并利用CA算法對新生成數據庫進行編碼轉換。這樣以后不再掃描的數據庫,而是通過編碼與運算生成候選頻繁項集,通過統計項編碼中1的個數計算支持度。由于只進行一次掃描,且縮小了掃描范圍,因而加快了運算速度,提高數據挖掘的效率。
改進算法的具體描述如下:

5 實例分析
為了解改進算法與CA算法、Tid算法在性能上的差異,進行以下相關試驗。試驗用服務器:P4 2.0GHz 4G內存、SQL Server2000;客戶機:P4 2.0GHz、1M內存。以福州職業技術學院計算機系2007級計算機專業學生 (600名)成績構成原始數據庫,該數據庫共有61113條記錄。
使用數據庫中前30000條記錄在不同最小支持度閾值條件下進行關聯規則挖掘。最小支持度閾值min_sup分別設置為5%、10%、15%、20%、25%。分別用Tid算法、CA算法和改進算法法進行關聯規則挖掘,其結果如圖1所示。
從圖1可以看出,隨著最小支度的增大,3種算法的執行時間呈下降趨勢,其中改進算法的執行時間始終最少,說明其挖掘效率較高。
在最小支持度閾值相同的條件下,選取數據庫中不同記錄數進行關聯規則挖掘。分別選取數據庫的前5000條、前10000條、前15000條、前20000條、前25000條和前30000條記錄,最小支持度閾值min_sup=20%。分別用Tid算法、CA算法和改進算法進行關聯規則挖掘,其結果如圖2所示。

圖1 不同最小支持度閾值條件下改進算法、Tid算法和CA算法的執行時間比
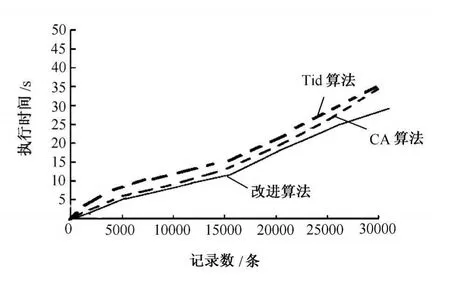
圖2 不同記錄數條件下改進算法、TiD和CA算法執行時間
從圖2可以看出,當數據記錄比較少時,3種算法的執行時間差別不大;當數據庫中記錄數較大時,CA算法與Tid算法的執行時間比改進算法的執行時間多。究其原因,是因為隨著數據庫規模的增大,由于編碼轉換的位長增長和與運算的復雜性加大,導致CA算法與Tid算法的執行時間較多,而改進算法由于先進行數據庫的壓縮,當針對海量數據時,其運行時間明顯減少。
6 結 語
通過闡述Apriori算法原理,指出該算法的不足。針對該算法的不足之處,提出了一種保留含有頻繁1-項集的數據庫作為掃描數據庫的改進方案。實例分析表明,改進算法不僅縮小了掃描數據庫的規模,而且減少編碼轉換位長,逐步縮小了數據庫搜索及與運算的時間,從而提高了數據挖掘的效率。
[1]韓家瑋.數據挖掘·概念與技術[M].北京:機械工業出版社,2006.
[2]焦亞冰.關聯規則挖掘算法的研究與應用 [D].濟南:山東師范大學,2008.
[3]彭永供,王靚明.基于散列技術的高效剪枝關聯規則挖掘算法[J].南昌大學學報,2009,33(5):494-498.
[4]葉曉波.一種基于二進制編碼的頻繁項集查找算法 [J].楚雄師范學院學報,2009,24(3):13-19.
[5]曲春錦.Aproiri-T IDS算法設計及其在教育決策信息挖掘中的應用 [D].上海:上海海事大學,2006.
[6]黃建明.關聯規則挖掘算法的研究與應用 [D].西安:西安建筑科技大學,2009.
[7]李磊,向正義.一種基于二項編碼的改進設計[J].微計算機信息,2009,7(3):214-215.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
