基于LBS(位置服務)的隱私保護算法研究
2011-05-11 04:03:00黃小英
制造業自動化 2011年9期
黃小英
(廣西工商職業技術學院,南寧 530003)
基于LBS(位置服務)的隱私保護算法研究
黃小英
(廣西工商職業技術學院,南寧 530003)
0 引言
數據挖掘和數據發布是當前數據庫應用的兩個重要方面。一方面,數據挖掘與知識發現在各個領域都扮演著非常重要的角色。數據挖掘的目的在于從大量的數據中抽取出潛在的、有價值的知識(模型或規則)。傳統的數據挖掘技術在發現知識的同時,也給數據的隱私帶來了威脅。另一方面,數據發布是將數據庫中的數據直接地展現給用戶。而在各種數據發布應用中,如果數據發布者不采取適當的數據保護措施,將可能造成敏感數據的泄漏,從而給數據所有者帶來危害。所以,如何在各種數據庫應用中保護數據的隱私,成為近年來學術界的研究熱點。
1 隱私保護技術的分類與性能評估
1.1 隱私保護技術的分類
沒有任何一種隱私保護技術適用于所有應用。隱私保護技術分為三類:
1)基于數據失真(Distorting)的技術:使敏感數據失真但同時保持某些數據或數據屬性不變的方法。例如,采用添加噪聲(Adding Noise)、交換(Swapping)等技術對原始數據進行擾動處理,但要求保證處理后的數據仍然可以保持某些統計方面的性質,以便進行數據挖掘等操作。
2)基于數據加密的技術:采用加密技術在數據挖掘過程中隱藏敏感數據的方法。多用于分布式應用環境中,如安全多方計算(Secure Multiparty Computation,以下簡稱SMC)。
3)基于限制發布的技術:根據具體情況有條件地發布數據。如:不發布數據的某些域值,數據泛化(Generalization)等。
1.2 隱私保護技術的性能評估
隱私保護技術需要在保護隱私的同時,兼顧對應用的價值以及計算開銷。通常從以下三方面對隱私保護技術進行度量:
1)隱私保護度:通常通過發布數據的披露風險來反映,披露風險越小,隱私保護度越高。
2)數據缺損:是對發布數據質量的度量,它反映通過隱私保護技術處理后數據的信息丟失:數據缺損越高,信息丟失越多,數據利用率(Utility)越低。具體的度量有:信息缺損(Information Loss)、重構數據與原始數據的相似度等。
3)算法性能:一般利用時間復雜度對算法性能進行度量。例如,采用抑制(Suppression)實現最小化的k-匿名問題已經證明是NP-hard問題;時間復雜度為O(k)的近似k-匿名算法,顯然優于復雜度為O(klogk)的近似算法。均攤代價(Amortized Cost)是一種類似于時間復雜度的度量,它表示算法在一段時間內平均每次操作所花費的時間代價。除此之外,在分布式環境中,通訊開銷(Communication Cost)也常常關系到算法性能,常作為衡量分布式算法性能的一個重要指標。
2 基于數據失真的隱私保護技術
數據失真技術通過擾動(Perturbation)原始數據來實現隱私保護。它要使擾動后的數據同時滿足:
1)攻擊者不能發現真實的原始數據,也就是說,攻擊者通過發布的失真數據不能重構出真實的原始數據。
2)失真后的數據仍然保持某些性質不變,即利用失真數據得出的某些信息等同于從原始數據上得出的信息。這就保證了基于失真數據的某些應用的可行性。
2.1 隨機化
數據隨機化即是對原始數據加入隨機噪聲,然后發布擾動后數據的方法。需要注意的是,隨意對數據進行隨機化并不能保證數據和隱私的安全,因為利用概率模型進行分析常常能披露隨機化過程的眾多性質。隨機化技術包括兩類:隨機擾動(Random Perturbation)和隨機化應答(Randomized Response)。
2.2 隨機擾動
隨機擾動采用隨機化過程來修改敏感數據,從而實現對數據隱私的保護。一個簡單的隨機擾動模型如表1(a)所示。
對外界而言,只可見擾動后的數據,從而實現了對真實數據值的隱藏。但擾動后數據仍然保留著原始數據分布X的信息,通過對擾動后的數據進行重構如表1(b)所示,可以恢復原始數據分布X的信息。但不能重構原始數據的精確值x1,x2,…,xn。

表1 隨機擾動與重構過程
隨機擾動技術可以在不暴露原始數據的情況下進行多種數據挖掘操作。由于通過擾動數據重構后的數據分布幾乎等同于原始數據的分布,因此利用重構數據的分布進行決策樹分類器訓練后,得到的決策樹能很好地對數據進行分類。在關聯規則挖掘中,通過往原始數據注入大量偽項(False Item)來對頻繁項集進行隱藏,再通過在隨機擾動后的數據上估計項集支持度,從而發現關聯規則。除此之外,隨機擾動技術還可以應用到OLAP上實現對隱私的保護。
2.3 隨機化應答
隨機化應答的基本思想是:數據所有者對原始數據擾動后發布,使攻擊者不能以高于預定閥值的概率得出原始數據是否包含某些真實信息或偽信息。雖然發布的數據不再真實,但在數據量比較大的情況下,統計信息和匯聚(Aggregate)信息仍然可以較為精確地被估算出。隨機化應答技術與隨機擾動技術的不同之處在于敏感數據是通過一種應答特定問題的方式間接提供給外界的。
隨機化應答模型有兩種:相關問題模型(Related-Question Model)和非相關問題模型(Unrelated-Question Model)。相關問題模型是通過設計兩個關于敏感數據的對立問題,
3 基于數據加密的隱私保護技術
在分布式環境下實現隱私保護要解決的首要問題是通訊的安全性,而加密技術正好滿足了這一需求,因此基于數據加密的隱私保護技術多用于分布式應用中,如分布式數據挖掘、分布式安全查詢、幾何計算、科學計算等。在分布式下,具體應用通常會依賴于數據的存儲模式和站點(Site)的可信度及其行為。
分布式應用采用兩種模式存儲數據:垂直劃分(Vertically Partitioned)的數據模式和水平劃分(Horizontally Partitioned)的數據模式。垂直劃分數據是指分布式環境中每個站點只存儲部分屬性的數據,所有站點存儲的數據不重復;水平劃分數據是將數據記錄存儲到分布式環境中的多個站點,所有站點存儲的數據不重復。
對分布式環境下的站點(參與者),根據其行為,可分為:準誠信攻擊者(Semihonest Adversary)和惡意攻擊者(Malicious Adversary):準誠信攻擊者是遵守相關計算協議但仍試圖進行攻擊的站點;惡意攻擊者是不遵守協議且試圖披露隱私的站點。一般地,假設所有站點為準誠信攻擊者。
3.1 安全多方計算
眾多分布環境下基于隱私保護的數據挖掘應用都可以抽象為無信任第三方(Trusted Third Party)參與的SMC問題,即怎樣使兩個或多個站點通過某種協議完成計算后,每一方都只知道自己的輸入數據和所有數據計算后的最終結果。
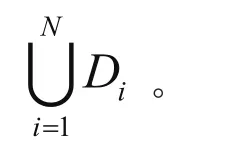
可以證明,由于采用了可交換加密技術的順序無關性,在整個求集合并集的過程中,除了集合交集的大小和最終結果被披露外,沒有其它私有信息泄露,所以該計算集合并的方法是安全的。
由于多數SMC基于“準誠信模型”假設之上,因此應用范圍有限。SCAMD(Secure Centralized Analysis of Multi-party Data)協議在去除該假設基礎上,引入準誠信第三方實現當站點都是惡意時進行安全多方計算;文獻[6]提出拋棄傳統分布式環境下對站點行為約束的假設,轉而根據站點的動機,將站點分為弱惡意攻擊者和強惡意攻擊者,用可交換加密技術解決在分布環境下的信息共享問題。
當前,關于SMC的主要研究工作集中于降低計算開銷、優化分布式計算協議以及以SMC為工具解決問題等。
3.2 分布式匿名化
匿名化即是隱藏數據或數據來源。因為對大多數應用而言,首先需要對原始數據進行處理以保證敏感信息的安全;然后再在此基礎上,進行數據挖掘、發布等操作。分布式下的數據匿名化都面臨在通訊時,如何既保證站點數據隱私又能收集到足夠的信息來實現利用率盡量大的數據匿名。
以在垂直劃分的數據環境下實現兩方的分布式k-匿名為例。兩個站點S1和S2,它們擁有的數據分別為{ID,A11,A12,...,A1n1},{ID,A21,A22,...,A2n1}。其中Aij為Si擁有數據的第j個屬性。利用可交換加密在通訊過程中隱藏原始信息,再構建完整的匿名表判斷是否滿足k-匿名條件來實現。
4 結論
隱私保護技術在諸多領域都有廣泛的應用,是近年來學術界新興的研究課題。本文側重數據庫應用,對隱私保護技術的研究現狀進行綜述。首先給出了隱私及其度量的定義,然后在對已有的隱私保護技術進行分類的基礎上,介紹了基于失真、加密和匿名化的三大類隱私保護技術,特別是,對當前隱私保護領域的研究熱點“基于數據匿名化的隱私技術”進行了比較詳盡的闡述與分析。
容易看出,每類隱私保護技術都有不同的特點,在不同應用需求下,它們的適用范圍、性能表現等不盡相同。當針對特定數據實現隱私保護且對計算開銷要求比較高時,基于數據失真的隱私保護技術更加適合;當更關注于對隱私的保護甚至要求實現完美保護時,則應該考慮基于數據加密的隱私保護技術,但代價是較高的計算開銷(在分布式環境下,還會增加通訊開銷)。而數據匿名化技術在各方面都比較平衡:能以較低的計算開銷和信息缺損實現對隱私保護。
[1]J.Han and M.Kamber.Data Mining:Concepts and Techniques.2nd edition,San Francisco:Morgan Kaufmann Publishers,2006.
[2]D.Agrawal and C.C.Aggarwal.On the Design and Quantification of Privacy Preserving Data Mining Algorithms. In Sym.on Principles of Database Systems (PODS),Santa Barbara, California,USA,2001:247-255.
[3]張鵬,童云海,唐世渭,楊冬青,馬秀莉.一種有效的隱私保護關聯規則挖掘方法[J].軟件學報,2006,17(8):1764-1774.
[4]羅永龍,黃劉生,荊巍巍,姚亦飛,陳國良.一個保護私有信息的布爾關聯規則挖掘算法[J].電子學報,2005,33(5):900-903.
The privacy preservation study based on LBS
HUANG Xiao-ying
隨著數據挖掘和數據發布等數據庫應用的出現與發展,如何保護隱私數據和防止敏感信息泄露成為當前面臨的重大挑戰。隱私保護技術需要在保護數據隱私的同時不影響數據應用。根據采用技術的不同,出現了數據失真、數據加密、限制發布等隱私保護技術。
隱私保護;隨機化;安全計算
黃小英(1976 -),女,廣西寧明人,講師,工程碩士,研究方向為計算機應用。
TP312
A
1009-0134(2011)5(上)-0096-03
10.3969/j.issn.1009-0134.2011.5(上).33
2011-01-05
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
中華手工(2017年2期)2017-06-06 23:00:31
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
