基于BP神經網絡的糧食產量預測模型
2011-06-08 07:53:38郭慶春何振芳
湖南農業科學 2011年17期
關鍵詞:模型
郭慶春 ,何振芳 ,李 力
(1.陜西廣播電視大學教務處,陜西 西安 710068;2.中國科學院寒區旱區環境與工程研究所,甘肅 蘭州 730000;3.中國科學院地球環境研究所中國科學院黃土與第四紀地質國家重點實驗室,陜西 西安 710075;4.中國科學院研究生院,北京 100049)
糧食安全關系到國計民生、社會政治穩定和經濟發展,一直是各國學術界和決策層研究和考慮的重要問題。保障國家糧食安全的首要目標是保障糧食安全供給,對于自給率高達95%的我國而言,主要是保障國內的糧食生產量。我國糧食生產的人均產量和消費量并不高,糧食結構性矛盾相當突出,面臨著人口增加和耕地面積減少的兩大壓力。因此必須對我國糧食供需形勢有一個清醒認識,而做好糧食產量預測,對各級政府決策部門來講都是一項重要的決策依據。預測糧食產量是典型的多指標小樣本系統的預測問題,國際上主要采用氣象預報法、遙感技術和統計動力學生長模擬法進行糧食產量預測。其預測誤差一般為產量的5%~10%。近年來,隨著智能技術發展,人工神經網絡預測等新技術解決了傳統方法的很多缺陷,神經網絡方法能很好地處理原始數據的隨機特性,即不需要對這些數據作任何統計假設,有較好的抗干擾能力。人工神經網絡還具有很強的處理大規模復雜非線性系統的能力,許多學者已將人工神經網絡成功地應用于實際問題的預測中,取得了令人滿意的結果[1-4]。本文引入人工智能最新方法BP神經網絡來進行糧食產量預測,旨在使糧食產量預測精度更高,更符合我國糧食生產的客觀實際。
1 我國糧食產量模型的建立
1.1 BP神經網絡原理
人工神經網絡具有模擬人類大腦思維功能的能力,是一種模仿人腦結構及其功能的非線性信息處理系統,能自動調整內部神經元之間的連接權重,以匹配輸入輸出響應關系,理論上可以實現任意函數的逼近,達到人們希望的精度要求。其中BP模型是目前應用最成功和廣泛的人工神經網絡。BP神經網絡(back-propagation neutral network)是指基于誤差反向傳播算法(簡稱BP算法)采用有導師訓練方式的多層前向神經網絡,由D.E.Rumelhart及其研究小組在1986年設計。由于它可以實現輸入和輸出的任意非線性映射,具有高度非線性和很強的自適應學習能力,因此被廣泛應用于模式識別、函數逼近、經濟預測等領域。
BP神經網絡的學習訓練過程由兩部分組成,該網絡輸入信號正向傳播和誤差信號反向傳播,按有導師學習方式進行訓練。在正向傳播中,信息從輸入層經隱含層逐層計算傳向輸出層,在輸出層的各神經元輸出對應輸入模式的網絡響應。如果輸出層得不到期望輸出,則誤差轉入反向傳播,按減小期望輸出與實際輸出的誤差原則。從輸出層經到中間各層,最后回到輸入,層層修正各個連接權值。隨著這種誤差逆傳播訓練不斷進行,網絡對輸入模式響應的正確率也不斷提高,如此循環直到誤差信號達到允許的范圍之內或訓練次數達到預先設計的次數為止。但傳統BP神經網絡也具有學習過程收斂慢、容易陷入局部極小、魯棒性不好、網絡性能差等缺點。因此本文引入Levenberg-Marquardt優化算法,其基本思路是使其每次迭代的不再沿著單一的負梯度方向,而是允許誤差沿著惡化的方向進行搜索,同時通過在最速梯度下降法和高斯-牛頓法之間自適應調整來優化網絡權值,使網絡能夠有效收斂,大大提高網絡的收斂速度和泛化能力,它能夠降低網絡對誤差曲面局部細節的敏感性,有效抑制網絡陷入局部極小。
1.2 糧食產量模型的參數確定
糧食產量是受不確定性因素影響的,是一個復雜的非線性系統,從人工神經網絡分析方法來看,則是一個多輸入、單輸出非線性系統。由于BP神經網絡是通過若干的簡單非線性處理神經元的復合映射,可獲得復雜的非線性處理能力,以及具有全局逼近網絡的特性,因此通過設置隱層多個神經元,可使非線性問題優化的可調參數增加,使解更精確,即擬合精度更高,本文的預測系統模型即采用改進的BP算法。
我國歷年糧食產量資料來源于國家統計局。將我國連續20 a的糧食產量構成一個時間序列,并規定連續4 a的數據作為一個樣本輸入,第5年的糧食產量作為與其對應的期望輸出。也就是將1990~1993年連續4 a的數據作為第一個輸入樣本,其對應的期望輸出為1994年的糧食產量,依次類推。由輸入矩陣可以確定輸入層節點數為4,根據“2N+1”這一經驗,可確定隱含層節點數為9;輸出層節點數為1,這樣就構成了一個“4-9-1”的BP神經網絡模型。其中,訓練函數為trainlm,輸入層到隱含層以及隱含層到輸出層的傳遞函數分別為logsig和purelin;最大訓練次數epochs為20 000次;訓練誤差精度goal為0.000 1;show為50;其他參數均選用缺省值。
2 BP神經網絡模擬結果
神經網絡的樣本訓練取1990~2004年的實際產量作為學習樣本,將2005~2009年的實際產量作為預測效果檢驗樣本,也就是利用前15 a的數據建立BP神經網絡模型,用于后5 a的數據來檢驗模型的有效性,神經網絡的學習樣本的擬合值和檢驗樣本的預測值見表1。
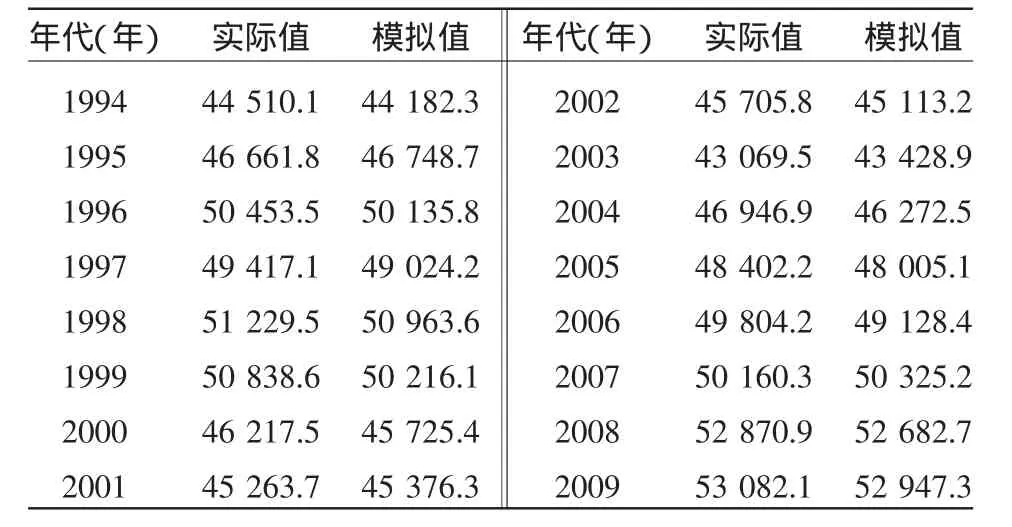
表1 BP神經網絡模擬結果 (萬t)
如表1所示,利用基于BP神經網絡預測模型得到的預測值和實際值具有較好的擬合效果。訓練樣本的模擬輸出與期望輸出的相對誤差均在±1.5%的范圍內,最大相對誤差為1.436 6%,最小相對誤差僅為-0.834%。模型的收斂效果很好。改進BP算法的結果與目標值很接近,訓練結果理想。從模型的檢驗看,結果表明檢驗樣本預測值平均相對誤差為0.491 7%,最大相對誤差為1.357%,最小誤差-0.329%,檢驗樣本的模擬輸出與期望輸出的相對誤差有4個小于±0.9%,另1個小于±1.5%。對檢驗樣本作預測時,BP網絡模型整體的平均預測誤差小,僅在2005、2006年糧食產量出現突然下跌時誤差較大,但在2007年預測時就迅速適應調整過來,顯示出模型具有良好的適應性。無論是擬合精度還是逐年預測5個獨立樣本,BP神經網絡模型的預測精度都高,而且預測結果穩定,結果比較令人滿意。因此可以用該網絡對未來年代的我國糧食產量進行預測。用2006~2009年的數據作為樣本輸入,預測2010年的糧食產量,仿真結果為54 396.7萬t,國家統計局公布的2010年我國糧食產量為54 641萬 t,二者相差不大,誤差較小,說明經改進的BP算法對我國糧食產量進行預測是完全可行的。最后將2010年糧食產量的預測數據作為新的輸入,2007~2010年的糧食產量則可以用來預測2011年的糧食產量,依次類推,可以預測出我國未來多年的糧食產量。2015年、2020年我國糧食產量的預測值分別為55 684.2、57 382.6萬 t。
3 結論
針對我國的糧食產量預測問題,由于常規統計模型難以滿足農業糧食產量的預測要求,將BP神經網絡應用于國家糧食安全預警系統中,本文提出的改進BP算法較好地解決了神經網絡收斂慢和易陷入局部極小值的問題,通過建立時間序列預測模型,運用該改進方法對我國糧食產量進行了模擬。結果表明,運用基于Levenberg-Marquardt算法的改進BP神經網絡無論從訓練結果精度上還是在收斂性能上都較好,這說明運用該方法來預測糧食產量是完全可行的,彌補了傳統BP的不足,提高了預測精度,加快了收斂速度,而且具有很好的外延性。
以1994~2009年我國糧食產量為檢測樣本進行了模擬預測,結果顯示,BP神經網絡模型的預測精度高,且預測結果穩定,結果令人滿意。對2010~2020年我國糧食產量進行了中長期預測,結果表明,我國糧食產量將較長期地穩定在54 396.7萬~57 382.6萬t之間,基本滿足我國人口的增長需要。BP神經網絡在時間序列預測問題上,有著傳統方法不可比擬的優勢。它可以真實反映復雜的非線性系統問題,并可以取得相當好的泛化(推廣)能力,其預測趨勢更為合理些。
本文將BP神經網絡模型引入到糧食產量預測,采用改進算法,提高了神經網絡的泛化能力,為解決歷史數據不足的復雜系統建立神經網絡模型提供了一種解決辦法,該預測模型同時也能夠較好的擬合復雜的非線性系統問題。提高了預測效率而且改進了預測精度,為我國糧食產量的預測研究提供了一種有效的方法。但這種基于時間序列的預測方法沒有充分考慮糧食產量與其影響因素之間的模型關系,因此,只是一種宏觀的預測方法。此外,Levenberg-Marquardt算法有占用內存大,訓練速率及效果同樣受訓練樣本和網絡結構的明顯影響等缺陷,有待進一步優化。
[1] 王海蘭,田 野,趙燕東.基于徑向基函數網絡的垂柳莖體含水量日變化模型的研究 [J].湖南農業科學,2010,(15):145-147.
[2] 柳皓笛,李文彬,闞江明.基于神經網絡的立木枝干測量方法研究[J].湖南農業科學,2009,(3):115-117.
[3] 侯 銅,姚立紅,闞江明.基于葉片外形特征的植物識別研究[J].湖南農業科學,2009,(4):123-125.
[4] 劉 星,李壯闊,王文輝.基于BP神經網絡的化肥供應商選擇模型研究[J].湖南農業科學,2007,(6):169-170.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
