正交頻分復用系統中同步位置估計方法的研究*
2011-06-11 11:03:44鄒麗紅余建國張向鵬
電信科學 2011年9期
鄒麗紅,余建國,張向鵬
(北方烽火科技有限公司武漢郵電科學研究院 北京100085)
1 引言
OFDM是一種將高速率的數據流調制成多個較低速率的子數據流,再通過已被劃分為多個子載體的物理信道進行通信的技術。OFDM技術已經應用在諸如數據廣播和數字電視等通信系統,以及無線局域網標準IEEE 802.11和無線城域網標準IEEE 802.16中。OFDM符號由多個子載波信號疊加構成,各個子載波之間利用正交性進行區分,因此為了確保OFDM系統的正交性,接收方和發送方需要進行嚴格的時間同步和載波同步,才能對數據進行正確接收。
目前OFDM系統的同步方法可分為兩種:數據輔助型和非數據輔助型。數據輔助估計在現有技術中使用較多,需要多個OFDM塊傳導頻符號或訓練序列,不僅造成資源浪費,而且在接收端需要接收完整個符號數據才能啟動同步估計,從而帶來信息速率的損失[2],該方法中的訓練序列對數據干擾過大,且發射數據的能量效率較低;非數據輔助估計雖然沒有浪費資源,但估計精度不高,最常見的同步方法是Jan-Jaap vande Beek等人在1997年提出的基于循環前綴的最大似然估計(ML)算法[3],該算法實現簡單,但頻偏估計范圍僅為OFDM系統子載波間隔的1/2,定時估計也較為粗糙,且幀同步性能較差。
為了解決上述技術問題,本文提出了一種OFDM同步位置估計方法,以解決現有同步位置估計方式容易造成的資源浪費和信息速率損失的問題。
2 OFDM同步位置估計方法
本文提出一種基于循環前綴的OFDM同步位置估計方法,其在接收到OFDM符號的循環前綴后,將待分段信號等分為第一段信號和第二段信號,分別將第一段信號和第二段信號中的訓練序列和數據符號分離,根據分離出的訓練序列和數據符號,計算第一段信號和第二段信號的信噪比并進行比較,按照二等分遞歸方式查找所述OFDM符號的同步參考位置,根據同步參考位置獲得OFDM符號有效數據部分的同步起始位置[1]。
本文提出的基于CP的OFDM同步位置估計方法,是將訓練序列插入循環前綴中,因此可以看作在循環前綴部分的數據中加入了噪聲,故而接收端的信噪比比不加噪聲時的信噪比要小,并且由于發生延時擴展,所接收的循環前綴部分的數據如果疊加了其他子載波的數據 (如有效數據符號等),則可以看作增加了信號功率,從而信噪比會增加。
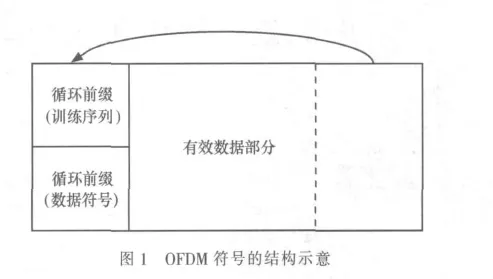
本方案需要發送端在傳輸OFDM符號之前,在循環前綴中插入發送端和接收端均已知的訓練序列。具體操作為:將訓練序列多次重復成與循環前綴長度相等的序列,然后將該序列與循環前綴進行加權,生成新的循環前綴部分,加權系數為0.5。OFDM符號的結構如圖1所示。
從圖1可以看出,循環前綴部分的數據一半為訓練序列部分,一半為數據符號部分,因此發送端在傳輸OFDM符號時,訓練序列和數據符號的發射功率分別為總發射功率的一半。其中,訓練序列可以為時域偽隨機序列,滿足相互正交的特性,如m序列。
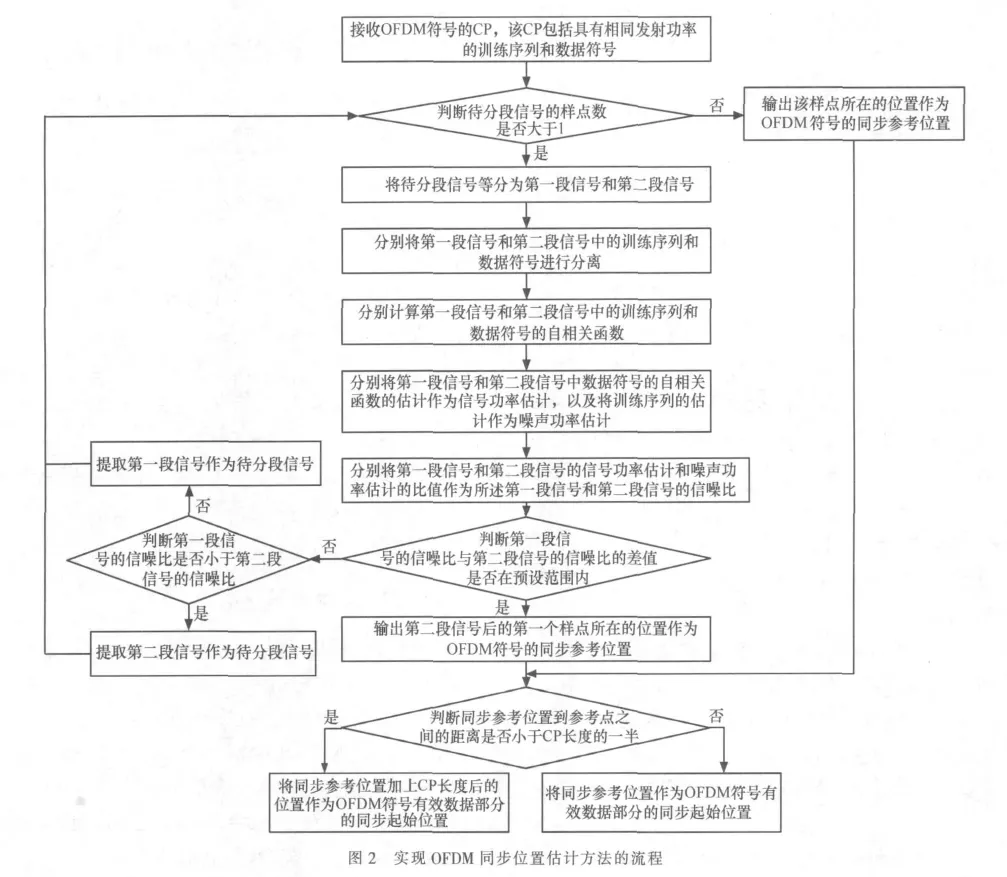
由于在傳輸過程中,整個OFDM符號都會受到信道加性噪聲的干擾,故此處不必單獨考慮信道噪聲的影響。由于在發射端,OFDM系統的調制采用IFFT(逆快速傅里葉變換)變換完成,因此發射的OFDM符號為離散的數據塊,離散的數據塊由一個個的樣點組成,故一個OFDM符號可看作由多個樣點組成。接收端在接收OFDM符號時,首先接收到循環前綴部分,通常循環前綴的長度可以設定為延時擴展的4~5倍,因此接收端能夠根據所接收數據的長度(樣點數)獲知是否已經接收完循環前綴部分。本方案的具體實現方式如圖2所示。
在本文提出的方法中,令CP的第一個樣點所在的位置為參考點,具體的實施步驟如下所述。
步驟1:接收 OFDM符號的 CP,該CP包括具有相同發射功率的訓練序列和數據符號。
步驟2:判斷待分段信號的樣點數是否大于1,若是,則執行步驟3;否則,執行步驟16。
在本文提出的方法中,初始接收到CP時,待分段信號即為該完整的CP,后續經過信噪比比較,返回的待分段信號為CP中的一部分,即在執行二等分遞歸的過程中,待分段信號均屬于該CP。
步驟3:將待分段信號等分為第一段信號和第二段信號。
步驟4:分別將第一段信號和第二段信號中的訓練序列和數據符號分離。
以第一段信號為例,在分離第一段信號中的訓練序列和數據符號時,可以采用去噪聲處理得到數據符號,然后用第一段信號減去數據符號,即得到第一段信號的訓練序列。
步驟5:分別計算第一段信號和第二段信號中的訓練序列和數據符號的自相關函數。
以第一段信號為例,設第一段信號中分離出的數據符號為x(n),訓練序列為r(n),則對應的自相關函數分別為:
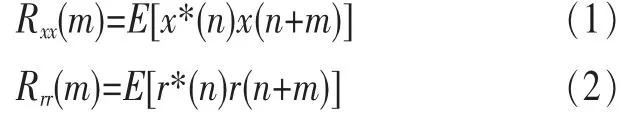
其中,Rxx(m)為數據符號的自相關函數,Rrr(m)為訓練序列的自相關函數。假設第一段信號中共有K個樣點,則m表示K個樣點中的任意一個。第二段信號的訓練序列和數據符號的自相關函數計算過程與第一段信號相同,在此不再贅述。
步驟6:分別將兩段信號數據符號的自相關函數的估計作為信號功率估計,將訓練序列的估計作為噪聲功率估計。
仍然以第一段信號為例,取第一段信號中的數據符號和訓練序列的一個取樣時間序列,用時間平均的方法計算數據符號和訓練序列的自相關函數估計[4]:
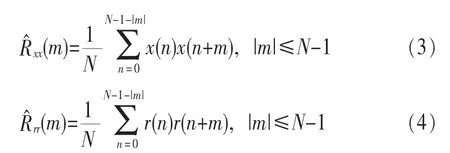
其中,N為取樣時間序列內的樣點數,x(n)={x(0),x(1),…,x(N-1)}xx(m)為數據符號的自相關函數估計rr(m)為訓練序列的自相關函數估計。
進一步得到式(5):
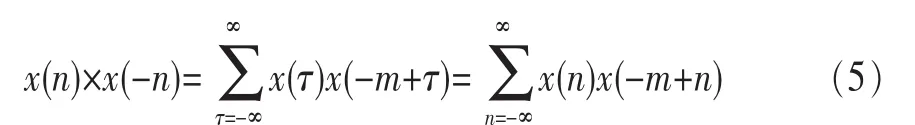
其中,τ為(-∞,+∞)內的任意一個整數。
從而得式(6)和式(7):

信號功率和噪聲功率的估計可直接由自相關函數估計得出[5]:

其中,S^為信號功率估計,N^為噪聲功率估計。采用上述方法計算信噪比可以簡化系統的復雜度。雖然該方法有一定的誤差,但整個計算過程均采用這種方式,相對誤差較小,可以忽略不計。第二段信號的信號功率估計和噪聲功率估計的計算過程與第一段信號相同,在此不再贅述。
步驟7:分別將第一段信號和第二段信號的信號功率估計和噪聲功率估計的比值作為所述第一段信號和第二段信號的信噪比。信噪比定義為信號平均功率與噪聲平均功率之比,設第一段信號計算出的信噪比為SNR1,計算如下:

同理,可求得第二段信號的信噪比為SNR2。
步驟8:判斷第一段信號的信噪比與第二段信號的信噪比的差值是否在預設范圍內,若是則執行步驟12;否則執行步驟9。
即求第一段信號和第二段信號的信噪比差值的絕對值,如果該差值的絕對值在預設范圍內,則可認為兩段信號的信噪比值近似相等。例如,SNR1和SNR2滿足以下近似關系:
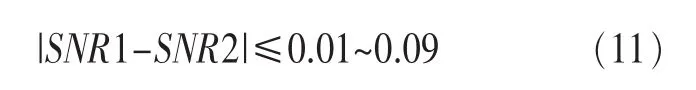
步驟9:判斷第一段信號的信噪比是否小于第二段信號的信噪比,若是則執行步驟10;否則執行步驟11。
步驟10:提取第二段信號作為待分段信號,返回步驟2,繼續尋找OFDM符號的同步參考位置。
步驟11:提取第一段信號作為待分段信號,返回步驟2,繼續尋找OFDM符號的同步參考位置。
步驟12:輸出第二段信號后的第一個樣點所在的位置作為OFDM符號的同步參考位置。
步驟13:判斷同步參考位置到參考點之間的距離是否小于CP長度的一半,若是則執行步驟14;否則執行步驟15。
步驟14:將同步參考位置加上CP長度后的位置作為OFDM符號有效數據部分的同步起始位置,結束當前流程。
步驟15:將同步參考位置作為OFDM符號有效數據部分的同步起始位置,結束當前流程。
步驟16:輸出該樣點所在的位置作為OFDM符號的同步參考位置,返回步驟13。
當樣點數等于1時,說明二等分遞歸判決結束,所輸出的該樣點的位置即為OFDM符號的同步參考位置。由于待分段信號在計算信噪比之前已經進行過判決,因此其樣點數不會小于1,故不必考慮樣點數小于1的情況。
由于上述實現方法,在接收到CP后就能啟動同步估計,通過比較分段信號的信噪比以及遞歸方法得出OFDM有效數據符號的同步起始位置,計算簡單,同步速度快。
3 仿真及其分析
基于圖2所述的處理流程,本文為了驗證同步位置估計方法的準確性,以64個樣點的有效數據部分和16個樣點的循環前綴部分為例,對該同步方法進行驗證。本文選擇16個樣點的CP為例,是由于該OFDM同步位置估計方法采用信噪比估算起始位置,因此采樣點數越多,信噪比計算越精確。
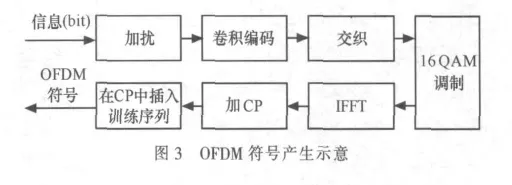
OFDM符號產生示意如圖3所示,首先對數據信息進行加擾、卷積編碼、交織、16QAM(正交振幅調制)、IFFT(逆快速傅里葉變換)和加CP,將訓練序列插入CP部分,形成OFDM符號,然后將形成的OFDM符號在信噪比小于10 dB、頻偏為100 kHz的條件下接收,分別用常規方法和本文提出的方法對其進行同步位置估計。
由于本文提出的方法是對起始位置的估計,因此在仿真中需要對其進行大量的測試,以1 000次的測試為例,記錄每次估計的同步起始位置和信噪比估計,如圖4所示。

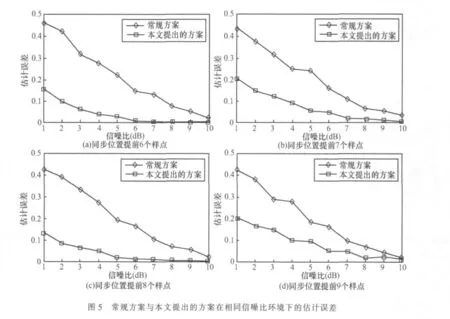
圖4所示為本文提出的方案在同步位置提前6、7、8和9個樣點并試驗1 000次之后,記錄的同步起始位置。
從圖4中可以看出,當同步位置提前6、7、8和9個樣點時,得到的同步起始位置極大部分落在第11、10、9和8個樣點,與實際相符,而極少數部分的同步起始位置落在其他點,這是可以容忍的。然后根據記錄的同步起始位置按照式(12)計算估計誤差。

按照式(12),在信噪比為1~10 dB時,將本文提出的方案與常規方案進行比較,如圖5所示。
從圖5中可以看出,本文提出的方案在相同信噪比條件下得到的估計誤差比常規方案低,且當信噪比為10 dB時,估計誤差小于1%,同步位置估計精度更高,同時通過式(6)和式(7)的簡化方法得出信號和噪聲的功率估計,繼而求得信噪比,可以大大降低系統的復雜度。
4 結束語
本文提出一種基于CP的OFDM同步位置估計方法,該方法利用信噪比的差異,通過二等分遞歸方式,在接收到CP后啟動同步估計,判定OFDM系統中的同步起始位置,其計算簡單,同步速度快,并且與現有技術相比,由于不需要在傳輸的有效數據部分疊加訓練序列和導頻,因此不會影響有效數據部分的傳輸速率,降低了系統的冗余度,并能在較短時間內完成同步。
另外,利用本文提出的方法獲得的OFDM符號有效數據的同步起始位置,計算出同步起始點與整個循環前綴末端的位置關系,向后端處理部分傳輸該位置關系信息,并可以作為后續的信道估計及均衡等處理的參考。同時,由于插入循環前綴中的訓練序列為發送端和接收端均已知的訓練序列,因此可以通過參考接收的訓練序列與已知訓練序列之間的差異,計算出誤碼率等性能指標。
1 鄒麗紅,余建國,洪媛等.OFDM同步位置估計方法及裝置,201010590426.9,2011.04.20
2 Tufvesson F,EdforsO,FaulknerM.Timeand frequency synchronization forOFDM usingPN-sequencepreambles.In:Vehicular Technology Conference,IEEE VTS 50th,1999
3 Vande Beek,Sandel J J,Borjesson M,et al.ML estimation of time and frequency offset in OFDM system.IEEE Transaction on Signal Processing,1997,45(7):1 800~1 805
4 尹長川,羅濤,樂光新.多載波寬帶無線通信技術.北京:北京郵電大學出版社,2004
5 Sandrine Boumard.Novel noise variance and SNR estimation algorithm for wireless MIMO OFDM systems.IEEE on Globecom,2003(3):1 330~1 334
猜你喜歡
幼兒園(2021年6期)2021-07-28 07:42:14
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
小學生學習指導(低年級)(2019年11期)2019-11-25 07:31:48
電子制作(2018年11期)2018-08-04 03:25:42
小學生導刊(2017年13期)2017-06-15 20:29:38
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
