最大熵和規(guī)則相結(jié)合的藏文句子邊界識(shí)別方法
2011-06-28 06:27:08才藏太姜文斌呂雅娟
中文信息學(xué)報(bào) 2011年4期
李 響,才藏太,姜文斌,呂雅娟,劉 群
(1. 中國(guó)科學(xué)院 計(jì)算技術(shù)研究所,中國(guó)科學(xué)院 智能信息處理重點(diǎn)實(shí)驗(yàn)室,北京 100190;2. 青海師范大學(xué) 計(jì)算機(jī)學(xué)院,青海 西寧 810008)
1 引言
藏語(yǔ)是屬于漢藏語(yǔ)系的一種古老語(yǔ)言,在漫長(zhǎng)的語(yǔ)言演變過(guò)程中,藏語(yǔ)形成了獨(dú)特的標(biāo)點(diǎn)符號(hào)體系,并仍然在現(xiàn)代藏語(yǔ)文本中得到廣泛使用。
藏文標(biāo)點(diǎn)符號(hào)體系僅含有限的標(biāo)點(diǎn)符號(hào),并且標(biāo)識(shí)句子結(jié)束的標(biāo)點(diǎn)符號(hào)存在較多的歧義,功能不確定,嚴(yán)重影響了藏語(yǔ)句子邊界的準(zhǔn)確識(shí)別。作為藏文信息處理的一項(xiàng)基礎(chǔ)性工作和藏語(yǔ)自然語(yǔ)言處理的一項(xiàng)關(guān)鍵技術(shù),藏語(yǔ)句子邊界識(shí)別問(wèn)題解決的好壞直接影響到詞性標(biāo)注,詞語(yǔ)切分、句法分析及機(jī)器翻譯等其他藏文自然語(yǔ)言處理應(yīng)用的性能,因此,解決現(xiàn)代藏語(yǔ)句子邊界的自動(dòng)識(shí)別問(wèn)題顯得日益重要。
現(xiàn)有的藏語(yǔ)句子邊界識(shí)別方法主要以采用規(guī)則方法為主[1],可以對(duì)特定領(lǐng)域的藏文文本實(shí)現(xiàn)較好的識(shí)別準(zhǔn)確率,但是該方法需要制作針對(duì)性的規(guī)則,人工代價(jià)較大,同時(shí)領(lǐng)域適應(yīng)性較差。本文提出了一種最大熵和規(guī)則相結(jié)合的藏語(yǔ)句子邊界識(shí)別方法。最大熵模型可以增強(qiáng)對(duì)不同領(lǐng)域文本句子邊界識(shí)別的魯棒性,但由于最大熵模型會(huì)因訓(xùn)練語(yǔ)料稀疏或低劣而產(chǎn)生對(duì)句子邊界的錯(cuò)誤識(shí)別,而引入規(guī)則方法可以提高最大熵模型的準(zhǔn)確率。本文提出的方法首先利用人工總結(jié)和分析藏語(yǔ)語(yǔ)料得到的藏語(yǔ)句子邊界詞表和非邊界詞表識(shí)別藏語(yǔ)句子邊界,對(duì)于無(wú)法識(shí)別的藏語(yǔ)句子邊界,最后利用最大熵模型進(jìn)行識(shí)別。實(shí)驗(yàn)表明,本文提出的方法可以對(duì)現(xiàn)代書(shū)面藏語(yǔ)文本的句子邊界進(jìn)行較好的識(shí)別。
本文包括如下部分: 第2節(jié)首先介紹藏語(yǔ)標(biāo)點(diǎn)符號(hào)體系和對(duì)藏語(yǔ)句尾的分析,提出基于規(guī)則方法的藏語(yǔ)句子邊界識(shí)別方案;第3節(jié)主要說(shuō)明最大熵模型的原理,提出基于最大熵方法的藏語(yǔ)句子邊界識(shí)別方案;第4節(jié)為實(shí)驗(yàn)結(jié)果;第5節(jié)為總結(jié)和展望。
2 規(guī)則方法
2.1 藏語(yǔ)標(biāo)點(diǎn)符號(hào)體系
藏語(yǔ)獨(dú)特的標(biāo)點(diǎn)符號(hào)系統(tǒng)中涉及標(biāo)識(shí)句子結(jié)束的標(biāo)點(diǎn)符號(hào)主要有[2]:
在這些標(biāo)點(diǎn)符號(hào)中,楔形符在藏文句子中主要用于句末,也可用于詞或者短語(yǔ)之后,在功能上相當(dāng)于漢語(yǔ)標(biāo)點(diǎn)符號(hào)的頓號(hào)、逗號(hào)、句號(hào)、問(wèn)號(hào)及嘆號(hào)。例如:

第二條 活佛轉(zhuǎn)世應(yīng)當(dāng)遵循維護(hù)國(guó)家統(tǒng)一、維護(hù)民族團(tuán)結(jié)、維護(hù)宗教和睦與社會(huì)和諧、維護(hù)藏傳佛教正常秩序的原則。活佛轉(zhuǎn)世尊重藏傳佛教宗教儀軌和歷史定制,但不得恢復(fù)已被廢除的封建特權(quán)。
從上面的例句中我們可以通過(guò)逗號(hào)、頓號(hào)和句號(hào)的位置準(zhǔn)確識(shí)別出漢語(yǔ)句子邊界,但是對(duì)應(yīng)的藏語(yǔ)句子共出現(xiàn)了6個(gè)楔形符,導(dǎo)致無(wú)法準(zhǔn)確識(shí)別藏語(yǔ)句子邊界。
2.2 藏語(yǔ)句尾結(jié)構(gòu)分析
藏語(yǔ)的句子語(yǔ)序結(jié)構(gòu)屬于SOV型,即{主語(yǔ)+賓語(yǔ)+謂語(yǔ)}的語(yǔ)序結(jié)構(gòu)。藏語(yǔ)句子的構(gòu)成是以動(dòng)詞為核心,運(yùn)用各種關(guān)系詞將詞語(yǔ)聯(lián)接起來(lái)組成句子的過(guò)程。動(dòng)詞的句法位置始終位于句子結(jié)尾部分,因此藏語(yǔ)句子中謂語(yǔ)部分的末端應(yīng)當(dāng)是整個(gè)句子的結(jié)尾。但是單獨(dú)分析謂語(yǔ)部分時(shí),其謂語(yǔ)結(jié)構(gòu)又各有不同的特點(diǎn),構(gòu)成要素之間相互影響。一般在藏語(yǔ)句子的謂語(yǔ)部分中核心動(dòng)詞后總是附加包含有一些其他成分,例如輔助動(dòng)詞等,其謂語(yǔ)的語(yǔ)序格式為: { (謂語(yǔ)動(dòng)詞 (+狀語(yǔ)補(bǔ)語(yǔ)) (+助動(dòng)詞[情態(tài)和趨向]) (+體貌-示證標(biāo)記) (語(yǔ)氣詞)}[3]。
另外,藏語(yǔ)句子的主要成分一般都要與格助詞相關(guān)聯(lián)。格關(guān)系是動(dòng)詞和其周?chē)鷮?duì)象發(fā)生事件的約束關(guān)系,只有這樣才能把句子各成分之間的語(yǔ)義關(guān)系表達(dá)清楚[4]。通過(guò)對(duì)48 000句藏文語(yǔ)料中歧義句子邊界左側(cè)的格助詞等詞的分析和統(tǒng)計(jì),我們從中總結(jié)出406個(gè)非邊界詞和166個(gè)邊界詞,這些詞可以確定性地表示藏語(yǔ)句子邊界的功能,如表1和表2所示。

表1 非邊界詞表(部分)
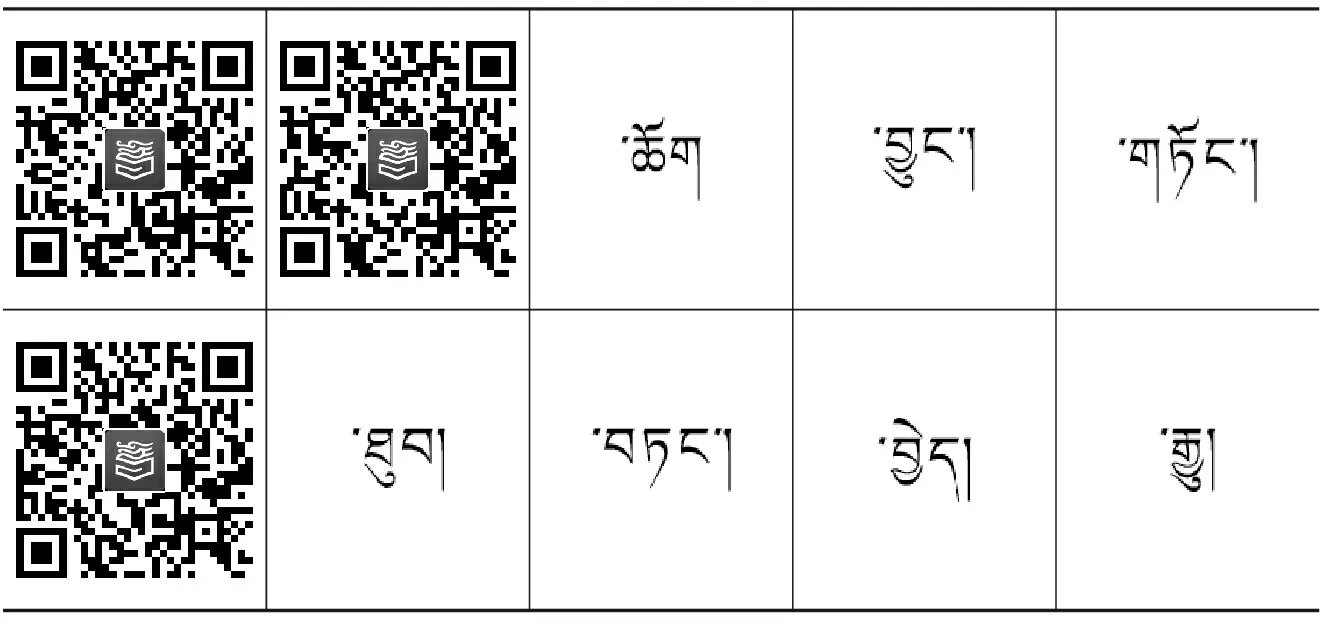
表2 邊界詞表(部分)
基于規(guī)則的方法利用表1和表2的詞表識(shí)別歧義的藏語(yǔ)句子邊界,對(duì)于每一次的識(shí)別結(jié)果,標(biāo)記該句子邊界的確定功能,從而根據(jù)該標(biāo)記決定最大熵模型需要識(shí)別的未確定的句子邊界。
3 最大熵方法
現(xiàn)有許多機(jī)器學(xué)習(xí)方法可以應(yīng)用于句子邊界識(shí)別問(wèn)題,例如,決策樹(shù)[5]、神經(jīng)網(wǎng)絡(luò)[6]和條件隨機(jī)場(chǎng)[7]等。由于最大熵模型已經(jīng)非常成熟,可以采用那些可以開(kāi)源的最大熵訓(xùn)練工具包來(lái)進(jìn)行訓(xùn)練,因此本文選擇最大熵模型來(lái)解決藏語(yǔ)句子邊界識(shí)別問(wèn)題。
3.1 最大熵原理
如果將一段文本看作一個(gè)詞序列,則可將句子邊界識(shí)別問(wèn)題視為一個(gè)將文本劃分為句子的隨機(jī)過(guò)程,建立隨機(jī)過(guò)程的聯(lián)合概率分布模型p,p∈P,輸出值集合Y={sb,nsb},y∈Y,其中y是歧義句子邊界是否為有效邊界的結(jié)果,在這個(gè)隨機(jī)過(guò)程中,Y受到上下文信息x的影響,上下文集合X,x∈X,其中x表示此序列中所有可能的上下文特征組合,同時(shí),從訓(xùn)練數(shù)據(jù)中獲得N個(gè)樣本的集合S={(x1,y1),(x2,y2),…,(xn,yn)},其中(x1,y1)是觀察到的一個(gè)事件,我們可以根據(jù)這些樣本定義一個(gè)事件空間X×Y,而對(duì)于句子邊界識(shí)別問(wèn)題,特征是一個(gè)二值函數(shù)f:X×Y→{0,1}。
對(duì)于一個(gè)特征(x0,y0),定義特征函數(shù)如下:
(1)
對(duì)于一個(gè)特征(x0,y0),在樣本中的期望值如下:
(2)
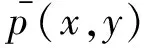
對(duì)于一個(gè)特征(x0,y0),在模型中的期望值如下:
(3)
最大熵模型的約束條件為對(duì)每一個(gè)特征(x,y),模型所建立的條件概率分布的特征期望值應(yīng)與從訓(xùn)練樣本中得到特征的樣本期望值一致,如公式:
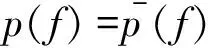
(4)
聯(lián)合概率分布模型p的熵函數(shù)如公式:
H(p)=-∑p(x,y)logp(x,y)
(5)
最大熵模型如公式:
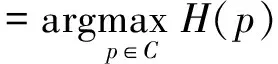
(6)
其中,C是滿(mǎn)足條件約束的模型集合,下面需要尋找p*,p*具有如下的形式:
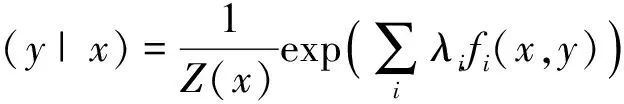
(7)
其中,Z(x)是歸一化常數(shù),表示形式如下:
(8)
λi是模型參數(shù),每一個(gè)特征fi對(duì)應(yīng)一個(gè)λi,λi決定了每個(gè)特征fi對(duì)概率分布的貢獻(xiàn)程度,同時(shí),可以采用GIS算法[8]對(duì)這些模型參數(shù)進(jìn)行參數(shù)估計(jì)。
3.2 特征選擇
針對(duì)藏語(yǔ)句子邊界識(shí)別問(wèn)題,選擇有效的句子邊界特征是使用最大熵模型需要解決的一個(gè)關(guān)鍵問(wèn)題。根據(jù)藏語(yǔ)句子邊界上下文的特點(diǎn)確定模型的上下文激發(fā)環(huán)境,從而選擇所需特征。本文考察了影響藏語(yǔ)句子邊界識(shí)別的多種因素,定義了藏語(yǔ)句子邊界識(shí)別的特征模板,具體的特征模板如表3所示,其中單詞表示藏語(yǔ)中兩個(gè)音節(jié)點(diǎn)之間的字串。
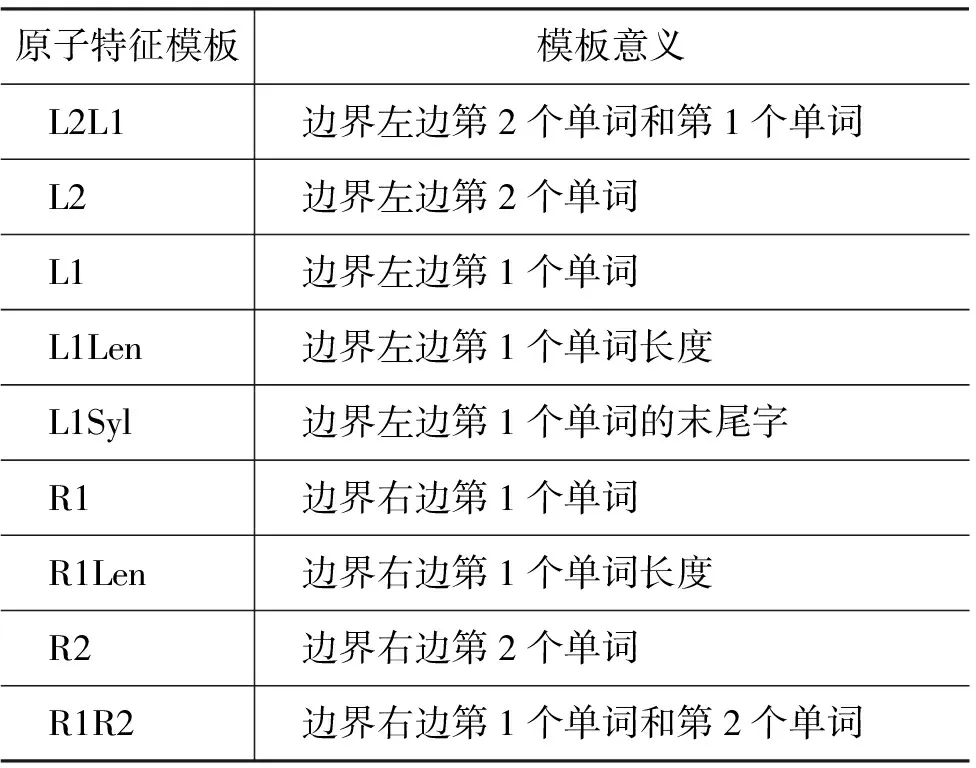
表3 藏語(yǔ)句子邊界識(shí)別的特征模板
同時(shí),由于訓(xùn)練語(yǔ)料存在較多的數(shù)字、標(biāo)點(diǎn)和英文等非藏文字符,為了避免數(shù)據(jù)稀疏對(duì)藏語(yǔ)句子邊界識(shí)別效果的影響,我們采用泛化的方法,對(duì)這些字符進(jìn)行分類(lèi)處理,形成了如表4所示的單詞類(lèi)型表。
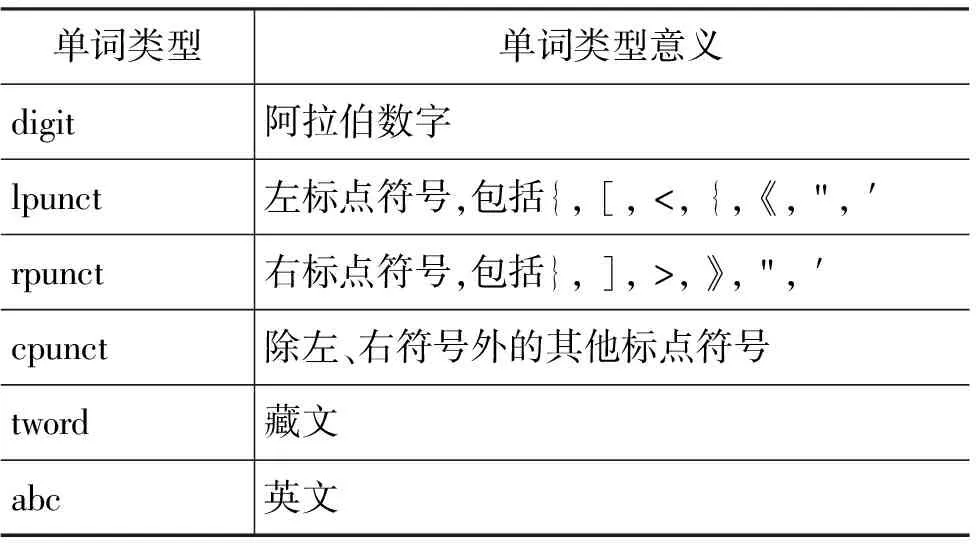
表4 單詞類(lèi)型表
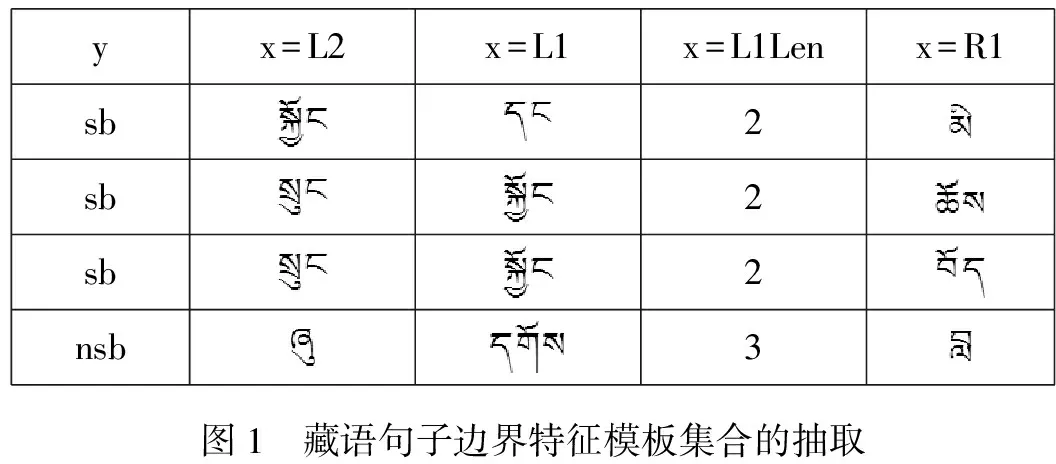
下面通過(guò)圖1來(lái)簡(jiǎn)要說(shuō)明對(duì)2.1節(jié)中例句邊界特征模板的抽取,其中采用簡(jiǎn)單的特征集合{L2, L1, L1Len, R1}。如圖1所示,將每一個(gè)句子邊界的功能標(biāo)記為斷句(sb)或不斷句(nsb),用左斜線劃分藏語(yǔ)單詞,空格表示非有效句子邊界,@符號(hào)表示有效句子邊界,共抽取了5個(gè)邊界特征。

4 實(shí)驗(yàn)
實(shí)驗(yàn)采用的藏語(yǔ)訓(xùn)練語(yǔ)料規(guī)模為48 000句,測(cè)試語(yǔ)料規(guī)模為140句,對(duì)應(yīng)的參考語(yǔ)料規(guī)模為560句,測(cè)試語(yǔ)料和參考語(yǔ)料的句數(shù)比為1∶4,從而可以較客觀地測(cè)試句子邊界識(shí)別性能。
本文采用了張樂(lè)開(kāi)發(fā)的最大熵模型訓(xùn)練工具包*網(wǎng)址: http://homepages.inf.ed.ac.uk/lzhang10/maxent_toolkit.html.,在訓(xùn)練過(guò)程中,迭代次數(shù)設(shè)為100次,為了避免過(guò)訓(xùn)練,高斯先驗(yàn)設(shè)為1.0,其他的參數(shù)都為缺省設(shè)置。
4.1 評(píng)價(jià)指標(biāo)
為了客觀評(píng)價(jià)本文提出的藏語(yǔ)句子邊界識(shí)別方法的性能,依據(jù)本文提出的方法,我們實(shí)現(xiàn)了一個(gè)藏語(yǔ)句子邊界自動(dòng)識(shí)別系統(tǒng),以準(zhǔn)確率、召回率和F1值為指標(biāo)對(duì)系統(tǒng)的藏語(yǔ)句子邊界識(shí)別結(jié)果進(jìn)行評(píng)價(jià),相關(guān)計(jì)算公式如下所示。
對(duì)于基于最大熵模型解決藏語(yǔ)句子邊界識(shí)別問(wèn)題,當(dāng)需要對(duì)藏文文本識(shí)別句子邊界時(shí),利用公式(7)可以獲得句子邊界標(biāo)記的概率,而句子邊界識(shí)別可以看作兩類(lèi)情況的分類(lèi)問(wèn)題,因此,實(shí)驗(yàn)采用p(y=sb|x)≥0.5作為判別句子邊界的閾值。
4.2 特征模板的選擇
由于特征模板可以形成很多特征集合,但在對(duì)藏語(yǔ)句子邊界進(jìn)行充分分析的情況下,沒(méi)有必要嘗試所有的特征集合,根據(jù)經(jīng)驗(yàn)和分析,在表3描述的特征模板的基礎(chǔ)上選擇特征形成如下6個(gè)特征模板集合。
(1) 特征集合A: A={L2L1, L2, L1Syl, L1Len, L1, R1, R1Len, R1Syl, R2, R1R2},包含了表3中的所有特征模板,作為評(píng)估其他特征模板的參考。
(2) 特征集合B: B = {L1Len, L1},用于評(píng)價(jià)句子邊界左側(cè)第一個(gè)單詞及單詞長(zhǎng)度對(duì)句子邊界識(shí)別的影響。
(3) 特征集合C: C = {L1Syl, L1Len, L1},用于評(píng)價(jià)句子邊界左側(cè)第一個(gè)單詞的尾部字對(duì)句子邊界識(shí)別的影響。
(4) 特征集合D: D = {L2, L1Syl, L1Len, L1},用于評(píng)價(jià)句子邊界左側(cè)第二個(gè)單詞對(duì)句子邊界識(shí)別的影響。
(5) 特征集合E: E = {L2L1, L2, L1Syl, L1Len, L1},用于評(píng)價(jià)句子邊界左側(cè)第二個(gè)單詞和第一個(gè)單詞共現(xiàn)對(duì)句子邊界識(shí)別的影響及句子邊界左側(cè)特征對(duì)句子邊界識(shí)別的貢獻(xiàn)。
(6) 特征集合F: F = {L2L1, L2, L1},用于評(píng)價(jià)候選句子邊界左側(cè)第二個(gè)單詞和第一個(gè)單詞共現(xiàn),第二個(gè)單詞以及第一個(gè)單詞這種簡(jiǎn)單特征模板集合對(duì)句子邊界識(shí)別的影響。
為了驗(yàn)證每個(gè)特征集合的性能以及選擇最有效的特征集合,分別采用以上每個(gè)特征集合識(shí)別藏語(yǔ)句子邊界,實(shí)驗(yàn)結(jié)果如圖2所示。
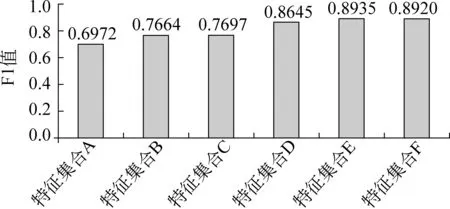
圖2 6個(gè)特征集合的測(cè)試結(jié)果
實(shí)驗(yàn)結(jié)果表明,采用特征集合E的實(shí)驗(yàn)結(jié)果最好,特征集合A的實(shí)驗(yàn)結(jié)果最差,因此選擇特征集合E作為最有效的特征模板集合。另外,從實(shí)驗(yàn)結(jié)果比較可見(jiàn),特征集合A的實(shí)驗(yàn)結(jié)果最差,說(shuō)明句子邊界右側(cè)特征并不能對(duì)實(shí)驗(yàn)結(jié)果產(chǎn)生較大貢獻(xiàn),所含信息量較少。
4.3 不同識(shí)別方法的比較
為了驗(yàn)證不同方法對(duì)句子邊界識(shí)別性能的影響,分別采用基于規(guī)則的方法、基于最大熵模型的方法以及最大熵模型和規(guī)則相結(jié)合的方法,對(duì)相同測(cè)試語(yǔ)料測(cè)試藏語(yǔ)句子邊界識(shí)別性能,其中特征集合采用4.2節(jié)中的特征集合E,實(shí)驗(yàn)結(jié)果如表5所示。
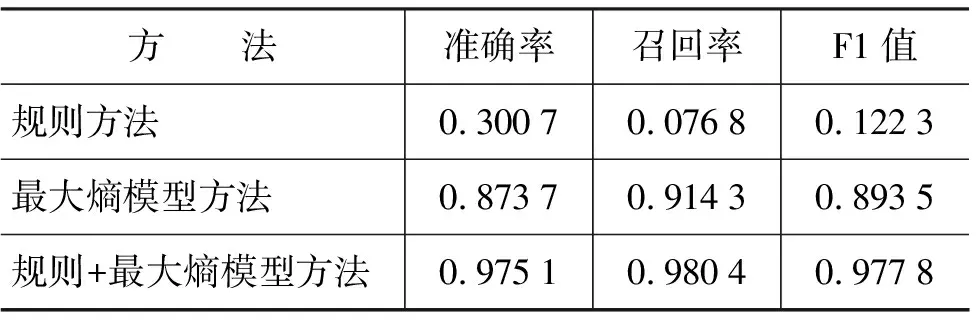
表5 不同邊界識(shí)別方法的實(shí)驗(yàn)結(jié)果
表5表明,雖然最大熵模型方法已經(jīng)實(shí)現(xiàn)了較好的性能,但是小規(guī)模訓(xùn)練語(yǔ)料并不能較好地反映藏語(yǔ)復(fù)雜的邊界特征分布,通過(guò)結(jié)合藏語(yǔ)句子邊界的規(guī)則,藏語(yǔ)句子邊界識(shí)別性能得到大幅提高,減少了最大熵模型對(duì)歧義句子邊界識(shí)別的誤判,具有對(duì)錯(cuò)誤識(shí)別較好的約束作用。
5 總結(jié)與展望
藏文標(biāo)點(diǎn)符號(hào)的特殊性和復(fù)雜性使我們不易準(zhǔn)確地識(shí)別藏語(yǔ)句子邊界,從而影響其他藏文自然語(yǔ)言處理的相關(guān)工作。通過(guò)對(duì)藏文語(yǔ)料以及對(duì)藏語(yǔ)句尾結(jié)構(gòu)的分析,結(jié)合藏文語(yǔ)法規(guī)則,本文總結(jié)出大量的邊界詞及非邊界詞,可以利用詞表在一定程度上確定歧義的藏語(yǔ)句子邊界的功能,而對(duì)于規(guī)則不能識(shí)別的藏語(yǔ)句子邊界,采用最大熵模型進(jìn)行邊界識(shí)別。實(shí)驗(yàn)結(jié)果表明,本文提出的最大熵與規(guī)則相結(jié)合的藏語(yǔ)句子邊界識(shí)別方法能夠較好的解決藏語(yǔ)句子邊界識(shí)別問(wèn)題。
在此基礎(chǔ)上,我們一方面計(jì)劃擴(kuò)大訓(xùn)練語(yǔ)料,減少數(shù)據(jù)稀疏,提高語(yǔ)料質(zhì)量,從而改善最大熵模型的判別能力,另一方面,將針對(duì)識(shí)別錯(cuò)誤的句子優(yōu)化邊界規(guī)則和特征模板選擇;其次,嘗試解決解決藏語(yǔ)復(fù)句以及嵌套語(yǔ)句的邊界識(shí)別問(wèn)題;最后,我們希望利用其他機(jī)器學(xué)習(xí)方法嘗試解決藏語(yǔ)句子邊界識(shí)別的問(wèn)題,從而比較不同方法的優(yōu)劣。
[1] 趙維納,劉匯丹,于新,等. 基于法律文本的藏語(yǔ)句子邊界識(shí)別[C]//第五屆全國(guó)青年計(jì)算語(yǔ)言學(xué)研討會(huì)論文集,2010: 480-486.
[2] 胡書(shū)津.簡(jiǎn)明藏文文法[M]. 昆明: 云南民族出版社,1988.
[3] 格桑居冕,格桑央京. 實(shí)用藏文文法教程[M]. 成都: 四川民族出版社,2004.
[4] 扎西加,頓珠次仁. 自然語(yǔ)言處理用藏語(yǔ)格助詞的語(yǔ)法信息研究[J]. 中文信息學(xué)報(bào),2010,24(5): 41-45.
[5] Riley, M. D. Some applications of tree-based modeling to speech and language indexing [C]//Proceedings of the DARPA Speech and Natural Language Workshop, 1989: 339-352.
[6] Palmer, D.D., Hearst M.A. Adaptive Multilingual Sentence Boundary Disambiguation [J]. Computational Linguistics, 1997, 23(2): 241-269.
[7] Liu, Y., Stolcke, A., Shriberg, E. and Harper, M. Using Conditional Random Fields for Sentence Boundary Detection in Speech[C]//Proc. ACL, 2005: 451-458.
[8] Darroeh J. N. and D. Ratcliff. Generalized Iterative Scaling for Log-Linear Models [J]. The Annals of Mathematical Statistics, 1972, 43(5): 1470-1480.
[9] 胡書(shū)津. 書(shū)面藏語(yǔ)常用關(guān)聯(lián)詞語(yǔ)用法舉要[M]. 昆明: 云南民族出版社,1993.
[10] 格桑居冕. 藏語(yǔ)復(fù)句的句式[J]. 中國(guó)藏學(xué),1996,(1): 132-141.
[11] 王詩(shī)文. 漢、藏語(yǔ)句子結(jié)構(gòu)對(duì)比研究[J]. 西南民族大學(xué)學(xué)報(bào)(人文社科版),2007,28(4): 50-55.
[12] 祁坤鈺. 信息處理用藏文自動(dòng)分詞研究[J]. 西北民族大學(xué)學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版),2006,(4): 92-97.
[13] 艾山·吾買(mǎi)爾,吐?tīng)柛ひ啦嚼? 統(tǒng)計(jì)與規(guī)則相結(jié)合的維吾爾語(yǔ)句子邊界識(shí)別[J].計(jì)算機(jī)工程與應(yīng)用,2010,46(14): 162-165.
[14] Berger A. L., Della Pietra, S. A. and Della Pietra V. J. A Maximum Entropy Approach to Natural language Processing [J]. Computational Linguistics, 1996, 22(1): 39-71.
[15] Ratnaparkhi, Adwait. A Maximum Entropy Model for Part-of-speech Tagging [C]//Proceedings of EMNPL, 1996: 133-142.
[16] Mikheev, A. Tagging Sentence Boundaries [C]//Proceedings of ANLP-NAACL 2000: 264-271.
[17] Reynar, J. C. and Ratnaparkhi, A. A Maximum Entropy Approach to Identifying Sentence Boundaries[C]//Proceedings of the Firth Conference on ANLP, 1997: 803-806.
[18] Glenn Slayden, Mei-Yuh Hwang, and Lee Schwartz. 2010. Thai Sentence-Breaking for Large-Scale SMT [C]//Proceedings of the 1st Workshop on South and Southeast Asian Natural Language Processing at COLING 2010: 8-16.
[19] Jiang Di. Identification of Boundaries of Object Clauses in Causative Verb Sentences in Modern Tibetan [J]. Journal of Chinese Language and Computing, 2006, 15(4): 185-192.
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
閱讀(快樂(lè)英語(yǔ)高年級(jí))(2020年8期)2020-01-08 02:21:16
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
河南科技(2014年23期)2014-02-27 14:19:15
