基于短語統計機器翻譯模型蒙古文形態切分
2011-06-28 06:37:08應玉龍烏達巴拉
中文信息學報 2011年4期
李 文,李 淼,梁 青,朱 海,應玉龍,烏達巴拉
(1. 中國科學院 合肥智能機械研究所,安徽 合肥 230031;2. 中國科學技術大學 自動化系,安徽 合肥 230027;3. 大同電力高級技工學校,山西 大同 037039)
1 引言
形態切分的目標是將詞切分為詞素(詞義基本單位,本文指的是詞干、詞綴的集合)。形態豐富的語言,例如蒙古語、土耳其語、俄語、西班牙語等,通常語言構形成分承載著大量的語法信息。形態切分成為自然語言處理中的很多領域,包括語音識別[1]、機器翻譯[2-3]、信息檢索[4]等重要研究方向,因而形態分析是蒙古文信息處理諸多應用系統的一個不可或缺的模塊。
蒙古文形態分析屬于序列標注問題,當前所采用的主要方法有: (1)詞典和規則相結合的分析方法[5];(2)統計和規則相結合的分析方法[5]。基于詞典的方法通過查詞典的方式查到一個詞是由哪些詞干和詞綴構成的,雖然對語料庫中詞切分準確率可以達到很高,但該方法受詞典的規模限制且存在二義性問題。基于規則的方法主要依據專家總結規則,存在規則總結不完全、切分錯誤和切分二義性問題。基于統計和規則相結合的蒙古語形態切分方法[6],主要利用規則生成形態切分候選項,蒙古文詞素統計語言模型作為排歧依據,分別有基于詞性的語言模型和Skip-N語言模型,其正確率與基于規則和詞典相結合的形態切分系統相比有較大的提高,然而該方法仍然受到規則的限制。
與上述方法不同,針對詞表詞切分存在二義性的問題,本文將蒙古文形態切分類比為機器翻譯問題,提出了基于短語統計機器翻譯形態切分模型(Phrase Based Statistical Machine Translation Morphological Segmentation, PSMTMS)。該模型的核心思想將切分前的序列視為源語言,切分后的序列視為目標語言,采用統計機器翻譯的方法達到形態切分的目的。由于采用了基于統計的短語機器翻譯系統,形態分析是以短語為單位進行切分的。相對以單個詞為單位進行切分,短語更好地考慮了切分的上下文信息。
機器翻譯的思想也曾在自然語言的相關領域有應用,Quirk[7]將統計機器翻譯系統用于釋義生成系統,Stefan Riezler[8]將統計機器翻譯技術用于問答系統的問題詢問擴展,Ming Zhou[9]將基于短語的統計機器翻譯系統用于對聯生成系統。由于基于短語的機器翻譯形態切分系統考慮了詞的上下文關系,系統不僅可以很好地處理詞的歧義切分問題,而且對語料庫中錯誤的人工標注具有很強的容錯能力。
對未登錄詞的切分,采用了最小上下文代價構成模型(Minimum Constituent - Context Cost Model, MCCCM),此模型主要考慮了詞的一元上下文切分信息。為了在切分過程中更全面地考慮切分上下文信息,融入了詞綴的N元上下文信息。
2 短語統計機器翻譯形態切分模型
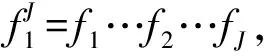
(1)
其中,hm(e,f)是e,f的特征函數,λ1,…,λM是與這些特征分別對應的特征參數。
機器翻譯的思想與形態切分系統對應,源語言即為切分前表面詞形s。由于蒙古文形態切分存在切分歧義的問題,其切分后存在n種切分狀態s1s2…sn,為了消除切分歧義,找到s的最佳切分組合。本文以短語為單位,考慮s中詞切分的上下文特征。類似于基于短語的機器翻譯模型,本系統選取了反映切分忠實度的短語翻譯模型、反應短語有效性的詞匯化翻譯模型和反映切分流利度的語言模型等特征,具體見表1。

表1 特征選取
2.1 短語翻譯模型
短語翻譯模型反映了切分忠實度, 并體現了原始表面詞形和切分后表面詞形的依賴關系。可以根據如下公式通過計算相對頻率的方法計算短語翻譯概率:
(2)
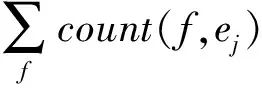
2.2 詞匯化翻譯模型
Koehn等證實詞匯化翻譯模型[12]能夠體現短語翻譯對的有效性。為了保證切分前后,詞素序列的有效性,形態切分系統里也增加了詞匯化翻譯模型。
(3)
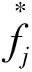
(4)
count(fj,ej)是詞fj和ej同時出現在F和E對齊語料中的次數,與機器翻譯里的詞匯化模型類似,本文也考慮了逆向詞匯化模型。
2.3 詞素語言模型
形態切分后的結果是詞素序列,詞素的統計語言模型能夠衡量詞素序列的有效性,其公式為:
hlm=log∏ip(ei|ei-2,ei-1)
(5)
3 最小上下文構成代價模型
本模型的基本思想: 根據選取的特征定義切分代價,對任意待切分的詞,搜索使切分代價總和最小的切分狀態,其核心是詞素上下文特征的選擇和構建, 解碼算法采用維特比算法。
3.1 特征選取
上下文構成模型(Constituent-Context Model, CCM)最早由Klein和Manning[11]用作語法歸納。Hoifung在非監督式的對數線性形態切分模型中借用該方法構建詞素環境模型[13],Klein考慮了一元上下文特征,Hoifung考慮了N-gram詞素上下文環境。因為本模型所處理的對象是未登錄詞,切分出來的詞干很多也是語料庫中未出現過的,所以本文不僅考慮了一元詞素上下文環境,而且也考慮了詞綴N-gram上下文環境。詞的形態切分可視作一棵樹,樹根表示詞,樹葉分別表示詞素。
例如: 拉丁蒙文$0G0DB0RILAGDAHV-ACA切分后,可以表示為圖1所示的一棵樹形圖。

圖1 詞切分樹結構
3.2 代價模型
最小切分代價考慮了兩方面: 1. 詞匯一元上下文切分代價,即各詞綴構成整詞的代價;2. 詞綴N-gram上下文切分代價,即詞與詞間的詞綴的n元關系代價。D=m1m2…mn構成詞的詞素符號序列,蒙古文的詞綴可能有多個,本文考慮了詞綴n元語言模型信息Suf=s1s2…sl,以句子為輸入單元,句子總的代價C定義為:
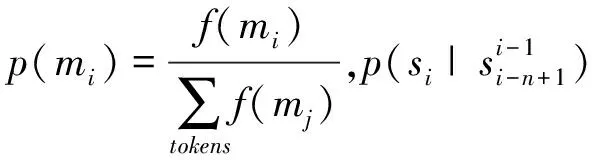
(7)
3.3 解碼算法
訓練過程抽取得到詞綴一元詞典和詞綴的N元概率詞典設詞。根據一元詞典,枚舉出對待切分的詞的所有的切分狀態,采用動態規劃算法搜索切分代價最小的最佳切分狀態。word長度為T,其字符序列word=a1a2…aT。設Cost(T)為長為T的詞切分代價,對于整個詞其切分代價由一元上下文切分代價和詞綴N-gram上下文切分代價組成,Min{Cost(T)}表示長度為T的詞最小切分代價。Cost(T,l)表示長度為T的字符串a1a2…aT切分成aT-laT-l+1aT和a1a2…al兩個子串的代價。Cost(T-l)表示長度為T-l的字符串切分代價,Suf(aT-laT-l+1aT)為詞綴aT-laT-l+1aTN-gram上下文切分代價。
Min{Cost(T)}=Min{Cost(T,l)+Cost(Suf(aT-laT-l+1…aT))}+Min{Cost(T-l)}
(8)
解碼算法采用維特比算法計算使切分代價C最小的狀態,總體分為兩步: (1)遍歷各種切分狀態并保存切分代價和路徑;(2)回溯求解最小切分代價下的狀態組合。
4 語料預處理及統計分析
本文所使用的訓練語料由內蒙古大學提供,語料中的詞已經被人工切分為詞干和構型詞綴,因而,本文的詞素特指詞干和構形詞綴的集合。考慮到蒙古語詞形還原的變化特點和機器翻譯的具體應用,本文研究了兩種形態切分方式,一種對詞干進行了還原變化處理,另一種則忽略了詞干還原這一現象,使詞干字符串序列與出現在詞中的字符串保持一致。
4.1 語料預處理
蒙古語的詞形變化是通過將構形詞綴黏附于詞干后來實現的,且一個詞干后可以層層附加多個構形詞綴以表達詞語之間復雜的語法關系。本文使用的原始語料庫是以拉丁轉寫形式錄入,利用內蒙古大學的蒙古語詞法分析系統Darhan進行詞的切分和標注,得到蒙古語詞素及其標注信息,并通過人工校對來確保詞法分析結果的準確性[14]。蒙古語的詞法切分過程中,詞干的切分存在詞干還原的現象,如BAYIG_A切分為BAI+G_A,其詞干BAYI還原為了BAI,如上所述,除了保留詞干還原這一變化現象的切分方法以外,本文同時考慮了忽略詞干還原后的形態切分方法。因此本文將語料庫中還原的詞干轉換為表面詞形中存在的形式,即將BAYIG_A的切分結果轉換為BAYI+G_A。
4.2 語料統計
語料庫中存在著大量的錯誤切分,依據切分后單個詞干、詞綴的長度不大于切分前詞的長度的原則,將錯誤的語料過濾掉。將語料劃分為形態切分訓練語料和測試語料,劃分比例為9∶1。訓練語料共34 171句、246 688詞,測試語料3 796句、27 332詞。劃分后,測試集的未登錄詞有1 901個,占測試集總詞數的7.0%。
同時,為了形象了解語料庫中的切分粒度,本文依據切分后構形詞綴的數目,統計了詞的概率分布。其中,切分后沒有構形詞綴的詞占51.69%,有一個構形詞綴詞占39.51%,有兩個及兩個以上數目構形詞綴詞占8.8%。
5 切分實驗及分析
5.1 PSMTMS形態切分
利用機器翻譯方法進行形態切分的基本思想是將切分前的表面詞形和切分后的詞分別看作機器翻譯的目標語言和源語言句子。將切分好的語料格式轉換為雙語語料的形式,源語言為切分前表面詞形,目標語言為切分后的表面詞形,示例如下:
蒙古文切分前源語料:
DVRALAL DAYIN H0YAR-TV ILADAG ARG_A BOHON-I HEREGLEJU B0L0N_A
蒙古文切分后目標語料:
DVRALAL DAYIN H0YAR+-TV ILA+DAG ARG_A BOHON+-I HEREGLE+JU B0L+0+N_A
本系統將開源的Moses[15]系統作為實驗平臺。本文利用開源語言模型訓練工具SRILM進行N-gram語言模型的訓練,平滑算法統一采用改進的 Kneser-Ney 平滑算法,本文對切分后的語料訓練了三元語言模型。語料庫中,在特定的上下文環境中一個詞只有一種切分結果,因而切分前后的語料是句子對齊的平行語料。為了充分利用Moses系統里的短語抽取及翻譯模型訓練工具,本文將切分前后的平行語料的對齊關系轉換為雙向GIZA++對齊格式。解碼使用了基于短語的解碼器Moses,特征選取了翻譯模型,語言模型,所有的模型特征參數值設定為均勻分布的概率值。
5.2 最小切分代價
此模型考慮到了詞素的一元上下文信息,構形詞綴的N-gram上下文信息。對于詞素的一元上下文信息,訓練語料庫的每個詞只考慮一種切法。初始語料庫中一個詞可能有多種切法,其中不乏有錯誤的切分,因而對每種詞本文保留頻率最高的切分狀態。
詞綴的N-gram上下文信息用到了N-gram語言模型, 為了方便處理,直接采用語言模型訓練工具SRILM進行N-gram語言模型的訓練。本文訓練了詞綴五元語言模型,也采用了改進的 Kneser-Ney 平滑算法。
5.3 實驗設計及結果分析
本文共設計了兩組實驗: PSMTMS 是基于短語的統計機器翻譯形態切分系統,SMTMS+ MCCCM 先用基于短語的形態切分系統對詞表詞進行形態切分,然后采用MCMM對未登錄詞進行處理,忽略了詞干還原。PSMTMS+MCCCM +STEM則是在PSMTMS+ MCCCM上考慮了詞干還原這一語言現象。
本系統的評測以整詞為評測單元,對形態切分效果的評價,以準確率為評價指標, 切分結果統計見表2。
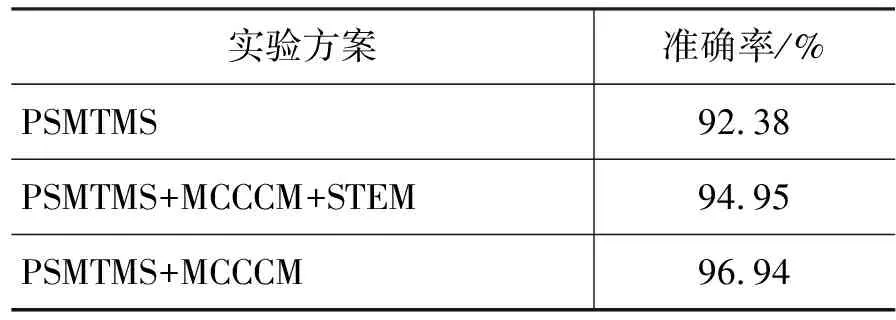
表2 切分結果
如表2所示,系統提出的基于短語統計機器翻譯形態切分系統總的切分正確率為92.38%,未登錄詞處理后總的正確率為96.94%。未考慮詞干還原的切分準確率略高于考慮詞干還原現象。
本文的切分考慮的是字符串層面上的切分,以未進行詞性標注的語料為輸入,對上下文信息的考慮以詞綴本身為主,故而與Kurimo[4], 那順烏日圖[14]不同,未對兼類詞和某種具體的詞性進行特殊的處理。在不考慮未登錄詞的切分情況下,而只對詞表詞進行切分,基于短語統計機器翻譯形態切分系統切分的準確率達到了99.71%。若只考慮未登錄詞的切分,最小代價模型主要考慮的詞的一元上下文信息及詞綴的N元語言語言模型信息,對未登錄詞的切分準確率為63.61%。測試語料中未登錄詞占7.0%,基于短語統計機器翻譯形態切分為對未登錄詞進行處理,未登錄詞處理之前準確率為92.38%,未登錄詞處理后總的形態切分準確率為96.94%,可見兩種模型的有機結合大大的提高了蒙古語形態切分準確率。
5.4 結論和討論
針對PSMTMS中形態切分特征選取問題,本文詳細分析了每個特征加入后對切分結果的影響,具體的特征選取實驗結果見表3。
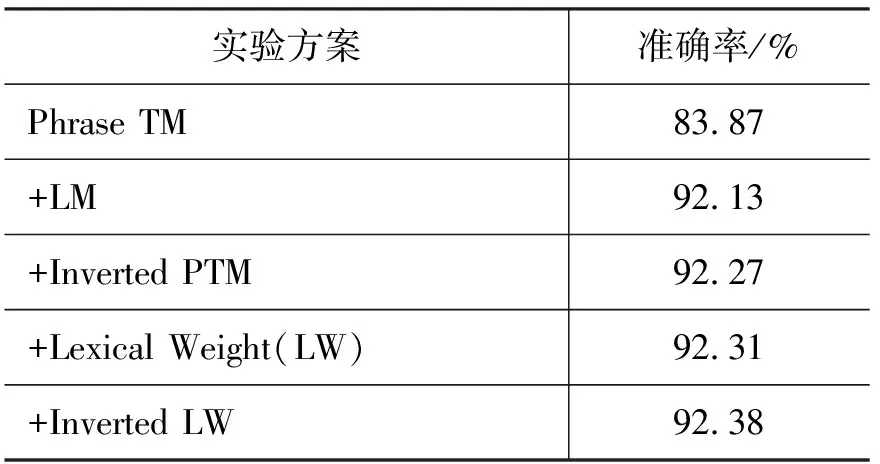
表3 特征選取實驗結果
如表3所示,短語翻譯模型(TM)和語言模型(LM)對形態切分系統的影響最大,只有短語翻譯模型和語言模型時,準確率為92.13%,隨著模型的增多,系統的準確率也隨著增大,當加入短語翻譯模型、逆向短語翻譯模型(Inverted PTM)、詞匯化模型(Lexical Weight)、逆向詞匯化模型(Inverted LW)后準確率為92.38%。PSMTMS是通過增加特征模型來考慮上下文環境的,上述實驗顯示,逐漸的加入不同的特征模型后,PSMTMS系統的切分準確率也隨之增大。
詞表詞的形態切分主要是解決詞表詞切分歧義和錯誤切分問題。本實驗顯示,PSMTMS對詞表詞切分的準確率高達99.7%,足可證明,PSMTMS不僅有效地解決切分歧義問題,同時對語料庫中存在的錯誤切分問題可以很好的處理。
針對未登錄詞處理,本文采用了最小上下文構成代價模型對未登錄詞進行處理,模型中詞干和詞綴都視為詞素信息。然而在實際問題中,詞干、詞綴在長度、頻率等方面有一定差異,若是不將它們加以區分,會導致詞干過度切分。依據語料庫中每種詞切分后的詞素數量進行統計,由三個及三個以上詞素構成的詞占總數的8.8%,由一個和兩個詞素構成的詞占91.2%。在這樣的語料環境下,過度切分問題會進一步加重。因此,本文的未登錄詞的處理準確率很大程度上受過度切分影響。
本文的形態切分系統沒有考慮詞形的變換和標注,且測試集、訓練集存在較大差異,故測試結果與文獻[4,14]中的蒙古語形態分析方法沒有可比性,僅作為參考。
6 形態切分提高機器翻譯質量
6.1 機器翻譯系統概要
漢蒙機器翻譯系統中,漢語屬于非形態語言(孤立語),蒙古語屬于形態豐富(黏著語)的語言。由于語言形態信息不對稱,當從漢語向蒙古語進行翻譯時,經常會遇到由于基本詞形變化(即形態特征)而導致的選擇歧義問題,從而造成譯文詞形變化上的錯誤(例如,數、格、人稱、性別的不一致以及動詞時態、語態不符合上下文等),加深了譯文在語法、語義、語用等多個層面的錯誤。同時,鑒于漢蒙雙語語料規模有限,語言形態的變化進一步加重了數據稀疏問題。鑒于此問題,本文將蒙古語形態切分結果用于機器翻譯系統,通過機器翻譯的效果進一步驗證本文所提出的方法的有效性和實用性。
本文所采用的機器翻譯系統結構視為以詞素為軸的鏈式機器翻譯系統。采用文中所提出的形態切分方法,將蒙古語切分為詞素后,即可得到蒙古語-詞素的平行語料。 首先利用漢語蒙古語詞素訓練漢語到詞素的短語機器翻譯系統(SMT1),將漢語翻譯成蒙古語詞素,然后利用蒙古語詞素平行語料訓練詞素到蒙古語的短語機器翻譯系統 (SMT2),以此將詞素翻譯成蒙古語表面詞形。具體的系統框圖請參考圖2。
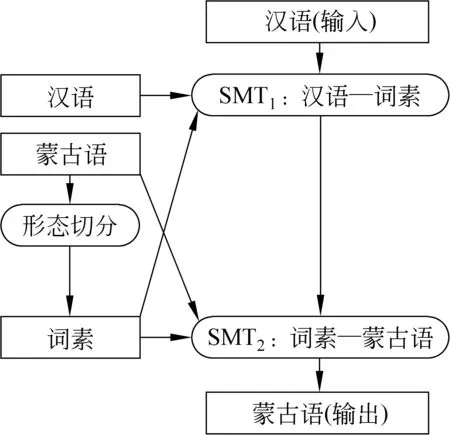
圖2 鏈式機器翻譯系統
6.2 結果評測
機器翻譯系統的訓練使用了第五屆全國機器翻譯研討會提供的67 255句對漢蒙雙語語料,本文將雙語的蒙古語部分統一轉換為拉丁轉寫形式。單一機器翻譯訓練借助了Moses開源平臺,測試集選用了訓練集之外的400句日常用語,由以蒙古語為母語的專業人員進行翻譯,每個漢語句子對應四種譯文。評測時,將拉丁轉寫的結果轉換為傳統蒙文的形式進行評測。基線系統(Baseline)是蒙古語未經切分的基于短語的漢蒙統計機器翻譯系統。表4和表5分別是參數調整前和調整后的評測結果,其中,Chain1和Chain2均是利用了詞素信息的鏈式機器翻譯系統,Chain1的形態切分方法考慮了詞干還原語言現象,Chain2的形態切分方法忽略了詞干切分還原的現象。
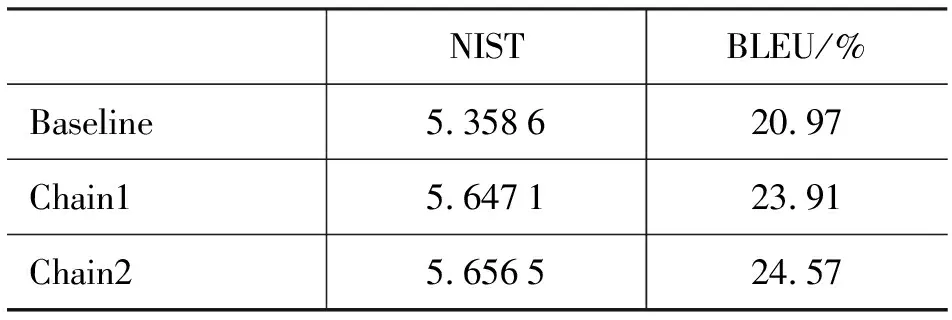
表4 調參前的評測結果
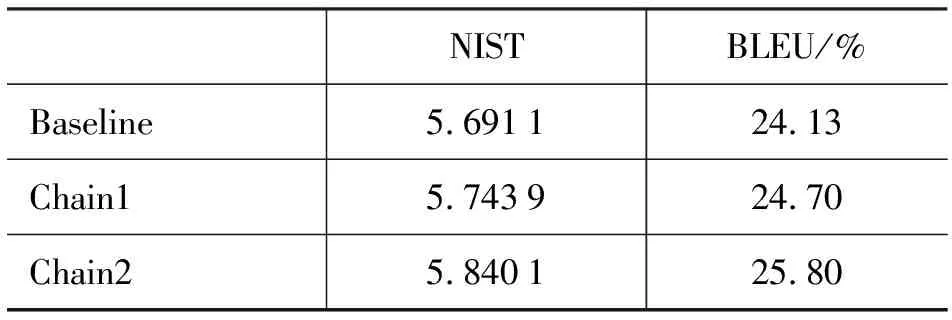
表5 調參后的評測結果
評測標準選用了N-gram匹配的方法BLEU[16]和NIST。BLEU評測方法主要是統計翻譯結果與參考譯文間共同出現的N-gram數,再將N-gram數除以翻譯結果的單詞總數,得到最終的評測結果。NIST評測方法是在BLEU的基礎上提出的一種不同的N-gram統計方法,BLEU中各種不同元數的N-gram的權值是一樣的,而NIST考慮了N-gram的信息量,對不同的N-gram賦予對應于信息量的不同權重。如果一個N-gram在參考譯文中出現次數越少,則其所包含的信息量越大,對應的權重也更高。
6.3 結果分析
由表4和表5的機器翻譯評測結果可以看到,本文所提到的形態切分方法所切分的詞素均可以提高機器翻譯系統的性能。Chain1中考慮了詞干切分還原現象,Chain2中忽略了此變化,機器翻譯評測結果顯示,忽略詞干變化后的翻譯效果略優于考慮了詞干還原現象的翻譯效果。產生此現象的原因可能源于考慮詞干還原后,詞干本身就以表面詞形的形式出現在語料庫中,導致切分出來的詞干無法與語料庫中的部分表面詞形區分開來。例如,Chain1考慮了詞干還原,BAYIGA會被切分為BAI+GA,而Chain2忽略了詞干還原,BAYIGA會被切分為BAYI+GA。與此同時,BAI在語料庫中也會以一個獨立的詞的形式出現,因而,Chain1無法區分BAI究竟是詞素還是整詞。
7 結束語
本文借鑒了機器翻譯的思路,嘗試使用基于短語的統計機器翻譯系統,解決蒙古文的形態切分問題。為了解決未登錄詞切分問題,引入了最小上下文構成切分代價模型,實驗表明,兩種模型的有機結合,使蒙古文的切分正確率達到很高。然而本文所提出的蒙古文形態切分系統仍存在一些問題有待進一步探索。本文所提出的短語機器翻譯切分系統對語料庫中出現的詞表詞的切分準確率較高,然而無法對未登錄詞進行處理,因而如何在PSMTMS中引入未登錄詞處理的特征模型還有待進一步研究。最小上下文構成代價模型,對未登錄詞的處理準確率不是特別高,因而對該模型的特征選取和相應的約束限制方法也需要更加深入的研究。將切分結果用于機器翻譯系統里,實驗評測結果顯示,機器翻譯的效果有了顯著的提高,間接的證實了本文方法的有效性。與此同時,測評結果顯示,切分過程中,忽略詞干變化后的翻譯效果略優于考慮了詞干還原的翻譯效果。因而,在今后的研究工作中,除了考慮通用的切分方法,同時還要針對具體的應用探討新的形態切分方案。
[1] Creutz, Mathias.Induction of the Morphology of Natural Language: Unsupervised Morpheme Segmentation with Application to Automatic Speech Recognition[D].Ph.D.Thesis, Computer and Information Science, Report D13, Helsinki, University of Technology, Espoo, Finland,2006.
[2] 楊攀,張建,李淼,等.漢蒙統計機器翻譯中的形態學方法研究[J].中文信息學報,2009,23(1): 50-57.
[3] 駱凱,李淼,烏達巴拉,等.漢蒙翻譯模型中的依存語法與形態信息應用研究[J].中文信息學報,2009,23(6): 98-104.
[4] Kurimo, Mikko and Ville Turunen.2008.Unsupervised Morpheme Analysis Evaluation by IR Experiments-Morpho Challenge 2008[C]//Working Notes for the CLEF 2008 Workshop.
[5] 葉嘉明.基于規則的蒙古語詞法分析研究與實現[D].碩上學位論文.北京: 北京大學,信息科學技術學院,2005.
[6] 侯宏旭,劉群,那順烏日圖.基于統計語言模型的蒙古文詞切分[J].模式識別與人工智能,2009,22(1): 108-112.
[7] Chris QUIRK, Chris BROCKETT and William DOLAN.Monolingual Machine Translation for Paraphrase Generation[C]//Proceedings of EMNLP. 2004: 142-149.
[8] Stefan Riezler, Alexander Vasserman, Ioannis Tsochantaridis, Vibhu Mittal and Yi Liu. Statistical Machine Translation for Query Expansion in Answer Retrieval[C]//Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, 2007: 464-471.
[9] Long Jiang, Ming Zhou. Generating Chinese Couplets using a Statistical MT Approach[C]//Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008). 2008: 377-384.
[10] F.J. Och and H. Ney. Discriminative training and maximum entropy models for statistical machine translation[C]//Proceedings o the 40th Annual Meeting of the Association for Computational Linguistics (ACL), 2002: 295-302.
[11] Dan Klein and Christopher D. Manning. Natural language grammar induction using a constituent context model[C]//Advances in Neural Information Processing Systems 14. 2001: 35-42.
[12] Philipp Koehn, Franz Josef Och, and Daniel Marcu. Statistical phrase-based translation[C]//Proceedings oHLT-NAACL, 2003: 127-133.
[13] Hoifung Poon, Colin Cherry, Kristina Toutanova. Unsupervised Morphological Segmentation with Log-Linear Models[C]//The 2009 Annual Conference of the North American Chapter of the ACL. 2009: 209-217.
[14] 那順烏日圖.蒙古文詞根、詞干、詞尾自動切分系統[J].內蒙古大學學報: 人文社會科學版,1997,29(2): 53-57.
[15] P.Koehn, Hieu Hoang, Alexandra Birch et al. Moses: Open source toolkit for statistical machine translation[C]//Proceedings of the ACL 2007 Demo and Poster Sessions(ACL 2007). 2007: 177-180.
[16] Kishore Papieni, Salim Roukos,Todd Ward, et al. BLEU: A Method for Automatic Evaluation of Machine Translation[C]//Proceedings of the ACL, 2002: 311-318.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
紅河學院學報(2021年4期)2021-11-19 08:59:14
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
西夏研究(2017年1期)2017-07-10 08:16:55
光學精密工程(2016年6期)2016-11-07 09:07:19
