文本挖掘的方法及應(yīng)用研究
2011-08-08 12:48:26張曉艷華英
電腦與電信 2011年12期
張曉艷 華英
(蘇州市職業(yè)大學(xué)計算機(jī)工程系,江蘇 蘇州 215104)
1.引 言
傳統(tǒng)的數(shù)據(jù)挖掘主要針對結(jié)構(gòu)化的數(shù)據(jù),如關(guān)系的、事務(wù)的和數(shù)據(jù)倉庫數(shù)據(jù)。但隨著互聯(lián)網(wǎng)應(yīng)用的興起和普及,涌現(xiàn)出巨量的電子信息,如電子文檔、電子出版物、萬維網(wǎng)等,其中以文本形式的信息占比最大。這些文本信息存儲在文本數(shù)據(jù)庫中,屬于半結(jié)構(gòu)化數(shù)據(jù)。文檔挖掘技術(shù)可幫助用戶比較非結(jié)構(gòu)化的文本信息,確定文檔的重要性和相關(guān)度,找出多個文檔的共通模式或趨勢,成為數(shù)據(jù)挖掘中的一個重要研究方向。
2.文本挖掘的處理過程
文本挖掘從數(shù)據(jù)挖掘發(fā)展而來,但面向的是半結(jié)構(gòu)化或非結(jié)構(gòu)化的文本數(shù)據(jù),無確定形式并且缺乏機(jī)器可理解的語義;因此除采用數(shù)據(jù)挖掘的一些常見方法之外,還涉及到文本分析、模式識別、統(tǒng)計學(xué)、數(shù)據(jù)可視化、數(shù)據(jù)庫、機(jī)器學(xué)習(xí)等技術(shù)的運(yùn)用。
文本挖掘的處理過程主要包括對含有大量文檔集合的內(nèi)容進(jìn)行文本預(yù)處理、特征提取、結(jié)構(gòu)分析、文本摘要、文本分類、文本聚類、關(guān)聯(lián)分析、質(zhì)量評估、模式生成、結(jié)果輸出等,如圖1所示。
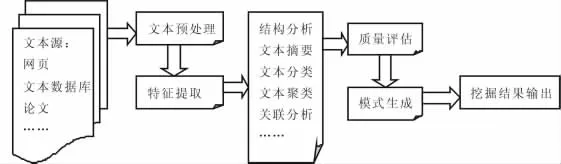
圖1 文本挖掘的處理過程
文本預(yù)處理的目的是選取任務(wù)相關(guān)的文本并將其轉(zhuǎn)化成文本挖掘工具可以處理的中間形式。特征提取一般會構(gòu)造一個評價函數(shù),對每個特征進(jìn)行評估,按分值高低排列,預(yù)定數(shù)目分?jǐn)?shù)最高的特征被選取。接著將進(jìn)行一系列分析挖掘步驟,利用機(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘以及模式識別等方法提取面向特定應(yīng)用目標(biāo)的知識或模式。在最后挖掘結(jié)果輸出前,需根據(jù)已經(jīng)定義好的評估指標(biāo)對獲取的知識或模式進(jìn)行質(zhì)量評估。如果不符合要求,則要返回到前面的環(huán)節(jié)重新調(diào)整和改進(jìn)。
3.文本挖掘主要方法分析
從圖1可以看出,整個文本挖掘處理過程中,重點集中在一系列分析挖掘步驟上,這些步驟的操作對象是提取出來的關(guān)鍵詞、標(biāo)記或語義信息,其中最主要使用的方法有:關(guān)聯(lián)分析、文本分類和文本聚類。
3.1 關(guān)聯(lián)分析
關(guān)聯(lián)分析首先要對文本數(shù)據(jù)進(jìn)行分析、詞根處理、去除停用詞等預(yù)處理,再調(diào)用關(guān)聯(lián)挖掘算法,如Apriori算法。關(guān)聯(lián)挖掘算法多使用支持度—置信度框架,最小支持度和置信度閾值可排除大量無益的規(guī)則。在文本數(shù)據(jù)庫中,視每個文檔為一個事務(wù),文檔中關(guān)鍵詞的集合視作是事務(wù)中的項集。所以文本數(shù)據(jù)庫中關(guān)鍵詞關(guān)聯(lián)挖掘的問題就映射為事務(wù)數(shù)據(jù)庫中項的關(guān)聯(lián)挖掘。關(guān)聯(lián)挖掘過程有助于找出復(fù)合關(guān)聯(lián),即領(lǐng)域相關(guān)的術(shù)語或短語,如[西紅柿,蔬菜],也可找出非復(fù)合關(guān)聯(lián),如[基金,銀行,證券,投資]。這樣的關(guān)聯(lián)挖掘也被稱為“術(shù)語級關(guān)聯(lián)挖掘”,便于找出術(shù)語和關(guān)鍵詞間的關(guān)聯(lián)。具有無需人工標(biāo)記文本、極大減少算法的執(zhí)行時間和無意義結(jié)果的優(yōu)點。
3.2 文本分類
由于存在大量的文本,自動對這些文本分類組織以便于檢索和分析,是文本挖掘至關(guān)重要的任務(wù)。文本分類是一種“有教師”的機(jī)器學(xué)習(xí)方法。首先要取一組預(yù)處理的文本特征向量集作為訓(xùn)練集,每個訓(xùn)練集有個類別編號;然后選擇分類方法分析訓(xùn)練集并導(dǎo)出分類模式;再檢驗這個分類模式以求精;最后用訓(xùn)練好的分類模型對其它待分類文本進(jìn)行分類。常用的文本分類方法有:
(1)最鄰近分類法。將全部訓(xùn)練文本進(jìn)行簡單索引,每個文本都關(guān)聯(lián)到對應(yīng)的類別編號。當(dāng)提交一個檢驗文本時,把它當(dāng)作查詢提交,并從訓(xùn)練集中檢索出與查詢最相似的n個文檔。檢驗文檔的類別編號由它的n個最鄰近的類別編號的分布決定。這種方法需要相對其它分類方法會占用更多的存儲訓(xùn)練信息的空間和查找倒排索引所消耗的時間。
(2)特征選擇分類法。向量空間模型可能會將大權(quán)重賦予某些稀有詞,而不管它的類分類特征如何,這些稀有詞的存在可能會導(dǎo)致無效的分類。此時可以使用特征選擇分類法刪除訓(xùn)練文本中與類別編號不相關(guān)或冗余的詞,其目的是找出最小特征集,使得數(shù)據(jù)類的概率分布盡可能接近使用所有特征得到的原分布。使用特征選擇刪除非特征詞后,產(chǎn)生的訓(xùn)練文本分類結(jié)果更有效。
(3)貝葉斯分類法。這是一種統(tǒng)計學(xué)分類方法,因為文本分類可以看作是計算文本在特定類中的統(tǒng)計分布。貝葉斯分類器首先通過對每個類x計算文本y的生成的文本分布P(x|y)來訓(xùn)練模型,然后測試哪個類最可能產(chǎn)生檢驗文本。貝葉斯分類可以預(yù)測類成員關(guān)系的可能性,適用于處理高維的數(shù)據(jù)集,準(zhǔn)確率和速度均較高。
3.3 文本聚類
文本聚類是一種“無教師”的機(jī)器學(xué)習(xí)方法。依據(jù)著名的聚類假設(shè):同類的文本相似度較大,不同類的文本相似度較小。它從給定的文本本身出發(fā),根據(jù)文檔特征詞向量,將相關(guān)者聚為一類。與分類不同,聚類由于不需要訓(xùn)練過程,也不需要預(yù)先對文本標(biāo)注類別,聚類要劃分的類是未知的,因此靈活性和自動化處理能力更強(qiáng)一些。常用的文本聚類方法有:
1.光譜聚類法。先將原始數(shù)據(jù)運(yùn)行維度歸約(光譜嵌入),然后對維度歸約后的文本空間運(yùn)用k均值或k中心聚類算法。光譜聚類法因與微分幾何學(xué)聯(lián)系密切,便于發(fā)現(xiàn)文本空間中的流行結(jié)構(gòu),而具有處理高度非線性數(shù)據(jù)的能力。這種方法也有缺點,對嵌入的學(xué)習(xí)要使用到所有的數(shù)據(jù)點,如果數(shù)據(jù)集很大,那會消耗大量的時間,因此并不太適用于大型數(shù)據(jù)集。
2.混合模型聚類方法。分為兩個步驟:①基于文本數(shù)據(jù)和附加的先驗知識估計模型參數(shù);②基于估計的模型參數(shù)推斷聚類。這種方法通常涉及多項式支模型,能同時聚類詞和文本。概率潛在語義分析和潛在狄利克雷分配是經(jīng)常使用到的模型。混合模型聚類方法的優(yōu)勢是,可以對簇進(jìn)行設(shè)計,更有利于文本的比較分析。
4.文本挖掘的常見應(yīng)用
(1)信息檢索。信息檢索關(guān)注的是基于大量文本的文檔信息的組織和檢索。信息檢索包括聯(lián)機(jī)圖書館目錄系統(tǒng)、聯(lián)機(jī)文檔管理系統(tǒng)和Web搜索引擎等。信息檢索的典型問題是根據(jù)用戶查詢,在文本集合時定位相關(guān)文檔。信息檢索系統(tǒng)的一般流程為:對文本集合建立倒排索引、分析用戶查詢請求、匹配文檔與查詢請求、對查詢結(jié)果進(jìn)行排序以及用戶相關(guān)度回饋。
(2)自定義組織聯(lián)機(jī)文檔。對于聯(lián)機(jī)文檔,可以自行制定組織方案,利用文本分類對這些文檔進(jìn)行自動編目。方便用戶不僅能夠瀏覽文檔,并且還可以通過限制搜索范圍提高查找效率。
(3)改進(jìn)搜索引擎的檢索結(jié)果。利用文本聚類方法,把搜索引擎的檢索結(jié)果分為若干簇,加以標(biāo)注,改善用戶查看檢索結(jié)果的方式,幫助用戶從無關(guān)聯(lián)的線性文檔列表轉(zhuǎn)為查看有規(guī)律的分類結(jié)果。
(4)提升商務(wù)電子化的管理效率。實施電子商務(wù)的企業(yè)可通過對客戶訪問信息、商品訪問情況和銷售記錄情況等的文本挖掘,了解客戶的興趣與需求,跟蹤產(chǎn)品的市場反映,收集客戶的信譽(yù)度,幫助企業(yè)提升管理效率。
5.結(jié)束語
文本挖掘作為數(shù)據(jù)挖掘的研究分支,在對半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)提取有效規(guī)律和規(guī)則方面有著明顯的優(yōu)勢。在處理不同數(shù)據(jù)集時,應(yīng)根據(jù)數(shù)據(jù)集的維度和組織情況選擇最適用的挖掘分類方法。隨著文本挖掘研究的深入,其應(yīng)用領(lǐng)域還將不斷拓展。
[1]阮忠,鄧春燕.Web文本挖掘的方法及其應(yīng)用研究[J].農(nóng)業(yè)網(wǎng)絡(luò)信息.2008,(9):27-29.
[2]程顯毅,朱倩著.文本挖掘原理[M].北京:科學(xué)出版社,2010.
[3]Bing Liu著,俞勇,薛貴榮,韓定一譯.Web數(shù)據(jù)挖掘[M].北京:清華大學(xué)出版社,2009.
[4]白翎雁,才書訓(xùn).Web文本挖掘及相關(guān)技術(shù)研究[J].沈陽工程學(xué)院學(xué)報(自然科學(xué)版).2008,4(3):260-261.
[5]謝冬,劉宏申.文本挖掘中若干關(guān)鍵問題的研究[J].電腦知識與技術(shù).2009,5(18):4773-4774.
