基于CEVA平臺的WMV視頻解碼器優化
2011-10-09 09:45:58趙建仁
電子設計工程 2011年23期
關鍵詞:優化
趙建仁,邢 玲,陳 蕾
(西南科技大學 信息工程學院,綿陽 四川 621010)
在當今多媒體技術的不斷進步下,手機視頻、IP機頂盒、HD-TV(高清電視)、Bluetooth(藍牙)成為其發展前沿的代表,這就需要低功耗的嵌入式處理器和具備高分辨率的輸出設備。為了支持高清視頻的實時編解碼,必須提供有效的硬件體系結構,因為在視頻編解碼過程中包含了大量的數據處理,這些數據的處理大部分都是在像素(8 bits)水平進行的,比如說在宏塊(16×16)里面的每個像素點上,其處理的方式包含乘法、累加、加法、像素掃描、四舍五入、移位、飽和度計算等。考慮到相同的處理將在宏塊內所有的像素點上進行,這里采用并行的處理方式將有效地提高編解碼效率,CEVA的VLIW和SIMD技術在這里有突出的作用[1]。
現在許多用于無線和移動多媒體應用的復雜SOC都采用多處理架構來提供最佳性能和所需的豐富功能集,這種多處理器方案通常意味著整個應用的調試會更為復雜,增加了開發成本。CEVA與ARM9的組合簡化了調試過程,同時也加強了對嵌入在子系統和軟硬件應用解決方案中的全面多處理器的支持[2]。CEVA指令集在視頻編解碼算法優化上也有著非常好的適用性。
現有許多新的復雜的算法被運用到不同的處理器上[3],但這些算法并不適用于CEVA的SIMD結構。文中通過VLIW實現并行算法的操作,多數據的處理利用SIMD技術通過單指令完成,VLIW允許一個周期同時執行8條單指令,這樣不僅僅提高了DSP的處理能力,也降低了能耗。
筆者著重于利用SIMD技術對WMV解碼器算法進行優化設計與仿真實現。所描述的VC-1解碼器[4]優化方法也同樣適合于其它的編解碼如MPEG-4、H.264等。
1 CEVA體系結構
文中所采用的是CEVA-X1622型號的DSP芯片[5],它具備的一些主要特性包含:高代碼密度,支持16位和32位兩種指令長度、9級流水線、16個40位的累加寄存器、16個32位的存儲器訪問和尋址寄存器、支持多種尋址方式、豐富的指令集功能、對8位和16位的分離操作提供全面支持。
CEVA-X系列是一個基于超長指令字結合單指令多數據處理的DSP芯片,利用這一特點能夠更好的實現數據并行處理,提高代碼密度,并有效地降低功耗。如圖1所示,CEVA-X塊圖大致分為3個部分:PCU(程序控制單元)、DAAU(數據地址運算單元)、CBU(運算與位操作單元)。PCU分為3個子單元:指令分派器、程序排序器和OCEM(片上仿真模塊)。CBU負責所有的DSP計算和移位操作,它包含4個計算子單元(M0、M1、S、L),子單元是相互獨立的并且能夠進行并行處理,CBU還包含有16個40位寄存器組成的累加寄存器文件(ACF),如圖2所示,每一個40位的累加器由2個16位部分和一個8擴展位組成,擴展位主要在計算中起保護作用。DAAU主要用于控制所有的數據存儲單元,它有2個相同的加載/存儲單元(LS0和 LS1),還包含有 25個 32位的地址寄存器文件。
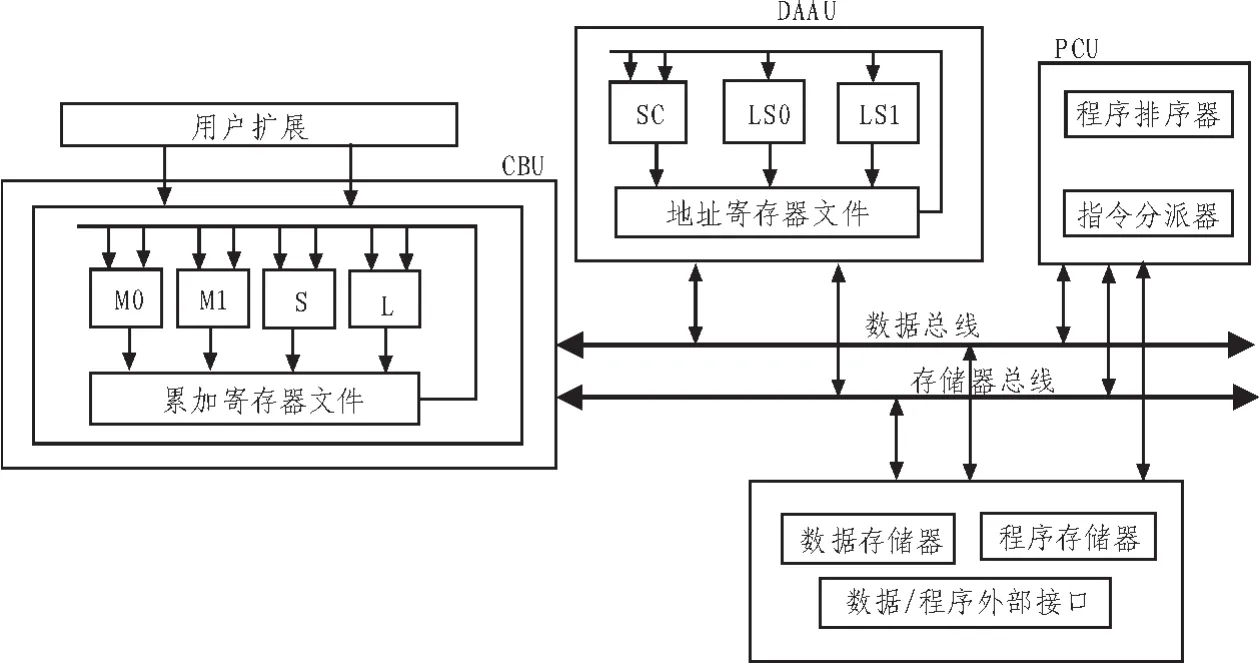
圖1 CEVA-X塊圖Fig.1 CEVA-X architecture diagram

圖2 40位累加寄存器結構圖Fig.2 40-bit accumulate register structure
2 VC-1解碼器優化設計
VC-1[6]是源于微軟公司視頻壓縮編碼技術WMV9,經過美國電影與電視工程協會(SMPTE)審批并命名的。VC-1支持3個類別:簡單類主要針對低復雜度的圖像壓縮應用,主要類是在高碼率或高復雜度的視頻傳輸中得到廣泛應用,而高級類是在主要類的基礎上增加了隔行方式的廣播級應用,本文把研究的重點放在了主要類,解碼流程如圖3所示。
VC-1區別于其它視頻編解碼標準主要是采用了自適應塊變換、16位精度的變換處理、多種方式的運動補償、環路濾波和重疊平滑化、均勻與非均與量化[7]。通過上述優點,它能夠利用較低的計算復雜度實現高清的視頻編解碼(類似與H.264/AVC)。 VC-1 支持不同尺寸的塊變換 (8×8、8×4、4×8、4×4),大尺寸的塊變換有利于計算空間域里面的相似點,小尺寸的塊變換能夠有效地減少邊界與塊邊緣不連續區域的振鈴效應,這里所采用的16位定點算術運算將有利于SIMD操作。VC-1運動補償支持16×16和8×8塊大小,運動矢量精度可達到1/4像素,它采用不同的模式來實現運動補償,主要參數為運動矢量精度、預測塊大小和內插濾波器類型,有如下4種組合方式:
1)混合塊尺寸(16×16,8×8),1/4 像素精度,四抽頭雙三次濾波器。
2)16×16塊,1/4像素精度,四抽頭雙三次濾波器。
3)16×16塊,1/2像素精度,二抽頭雙三次濾波器。
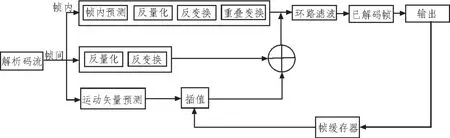
圖3 VC-1主檔次解碼流程Fig.3 VC-1 Main profile decoder block-diagram
4)16×16塊,1/2像素精度,二抽頭雙線性濾波器。
這4種模式能夠提供足夠的靈活性去獲得運動補償的參考塊,同時,由于沒有提供上述參數的所有組合,降低了算法復雜度。VC-1的去方塊濾波不僅僅是一個后處理過程,在編碼環中引入能有效的提高圖像質量,其環路濾波將減少經過反量化和反變換產生的邊緣失真,它是一個高條件度算法,所以在處理器上實現它具有一定的難度,為了降低其復雜度,VC-1每隔4個像素判斷一次是否需要濾波。環路濾波不能有效地區分塊真實邊界和量化導致的偽邊界,所以通過重疊平滑化來解決這一問題。重疊平滑將加強邊緣的預處理并在后處理過程中進行平滑化,執行它的過程并不需要滿足很多條件,因此它能夠被用于低復雜度簡單類的實現。VC-1同時允許使用死區量化器和常規均勻量化器,在低碼率情況下,采用死區量化器,在高碼率時,采用均勻量化器。
2.1 運動補償模塊優化
運動補償通過參考塊和運動矢量來生成預測塊,如果運動矢量指向了小數部位的像素,那么就需要用像素插值來獲得該位置的像素值 (1/2,1/4),VC-1使用 3種濾波器進行運動補償,一種是1/4像素處的四抽頭雙三次濾波器,另一種是1/2像素處的二抽頭雙三次和二抽頭雙線性濾波器。公式(1)、(2)、(3)是四抽頭雙三次濾波器在 1/4、1/2、3/4 像素處插值方法[8]。Xnm表示第m行第n列處的像素值。假如需要在一個宏塊的垂直1/4像素處進行像素插值,為了能對整個宏塊的小數位置進行插值,需要在所有列都運用該濾波器。如果想充分利用SIMD來實現像素插值 (并行處理8個像素),那么如圖4所示,在前4行采用四抽頭濾波器進行插值操作。這里把一個宏塊分為4個8×8子塊,對于一個8×8塊,把它一行的像素全部放入累加寄存器中,那么一個8×8塊需要8個累加寄存器(不考慮擴展位),然后在利用SIMD技術來并行計算8個內插像素值。除法操作通過移位來實現,Ymn表示垂直1/4位置處的像素值,uint8表示8位無符號整型數據。
1/4像素處:
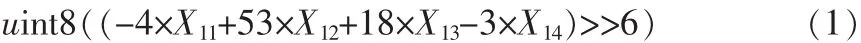
1/2像素處:
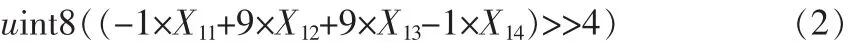
3/4像素處:
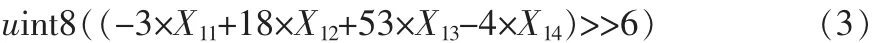
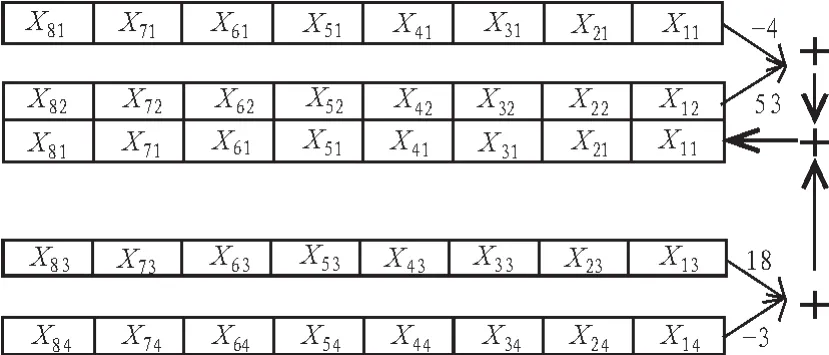
圖4 像素垂直方向插值Fig.4 Pixel vertical interpolation
為了利用SIMD技術實現水平方向的插值,需要對數據進行一個特殊的排列,如圖5所示,給出了采用SIMD技術對第一行8個像素進行濾波的數據排列方式。這里Xnm表示第m行第n列處的像素值,剩下的過程類似于垂直插值。
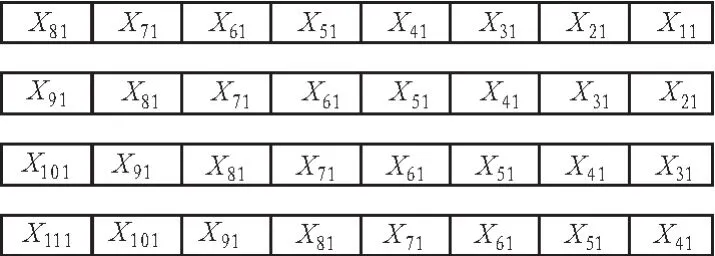
圖5 水平方向像素插值的數據排列方式Fig.5 Data arrangement for horizontal filtering
2.2 去方塊濾波模塊優化
去方塊濾波[9]主要用于消除由反變換、反量化、運動補償造成的塊效應,有利于獲得更好的參考圖像,進而提高運動估計的精度,但由于它計算量較大,同時也消耗大量解碼時間。 去方塊濾波的執行區域基于塊(8×8、8×4、4×8、4×4)的邊緣,對于P和B類的圖像來說,塊邊界能出現在第4、8或12個像素位置處 (行或列),這取決于它們采用何種塊變換尺寸。對于I圖像而言,塊邊界只出現在第8、16、24行或列像素處,因為它只采用8×8塊變換。
由于CEVA具備足夠的寄存器資源,在加上其豐富的SIMD指令集,能夠同時對4個4×4塊或2個8×4/4×8塊進行去方塊濾波,這種方法有利于提高緩存效率和減少解碼時間。如圖6所示為水平方向的去方塊濾波,塊分割類型為兩個4×8塊,優化時利用CEVA寄存器裝載P0,P1,……,P7像素值,在經過合理的指令操作,計算出P3,P4濾波后的像素值,余下的像素采用相同的處理過程。濾波并不是針對原始圖像的真實邊界,而是對因為變換、運動補償所造成的偽邊界進行處理。對于P幀圖像而言,如果相鄰兩塊具有同樣的運動矢量或兩塊殘差為0,則不做任何處理。
圖6 水平濾波Fig.6 Horizontal deblocking
2.3 反量化模塊優化
反量化恢復出量化系數,它是量化的逆過程。利用CEVA豐富的寄存器資源能對4個4×4塊并行處理,反量化能夠運用斜向掃描或光柵掃描兩種方式,為了更有效利用SIMD指令,可以選擇光柵掃描方式,這樣能同時裝載8個量化系數,并重新調整它們。掃描操作會在所有的系數包括零系數處被執行,因此,有效增益依靠在一個塊中的非零系數。由于這些不必要的計算和光柵掃描命令相關,優化時把反量化的計算合并到VLD中。
2.4 反變換模塊優化
VC-1 反變換尺寸支持 4 種模式:8×8、8×4、4×8、4×4,能夠只通過加法和移位操作實現,而不需要乘法等計算復雜度高的運算,這樣大大提高了運算效率,如圖7所示為4種變換模式。反變換優化[10]時,同時執行兩個8×4或4×8塊、4個4×4塊的反變換,加法和移位操作利用SIMD指令(add、shift)實現。這里能并行處理8個系數,在對行變換計算以后,利用CEVA指令進行矩陣轉置,行變換后的系數能夠直接作為列變換的輸入,這樣能降低內存的實用,減少中間步驟,有效地提高處理效率。

圖7 變換模塊尺寸Fig.7 Variable block sizes for the transform
3 實驗仿真
文中主要針對VC-1主檔次解碼算法進行了優化處理,采用Apollo-1 pro開發板進行移植和性能測評。這款開發板基于ARM9采用多核多總線結構,通過CEVA-X1622與Apollo-1 pro的結合,實現對解碼器的優化和調試。
表1給出了核心模塊優化前和優化后占用解碼時間比,有如下 3 個參考序列[1]:Foreman(QVGA-384Kbps),Akiyo(Qvga-384Kbps)和 Stefan(QVGA-384Kbps)。 Akiyo 序列的運動量很少并且背景基本沒有變,Foreman序列包含中等的運動量和紋理變化,Stefan序列有較高的運動量和幅度較大的紋理變化。我們發現其中Foreman序列的運動補償優化最為明顯,導致它的整體優化效果最好,根據2.1的分析,我們知道整個解碼過程中,大部分時間是用來進行運動補償的,Akiyo序列比不上Foreman和Stefan的優化效果正是因為它包含較少的運動補償。
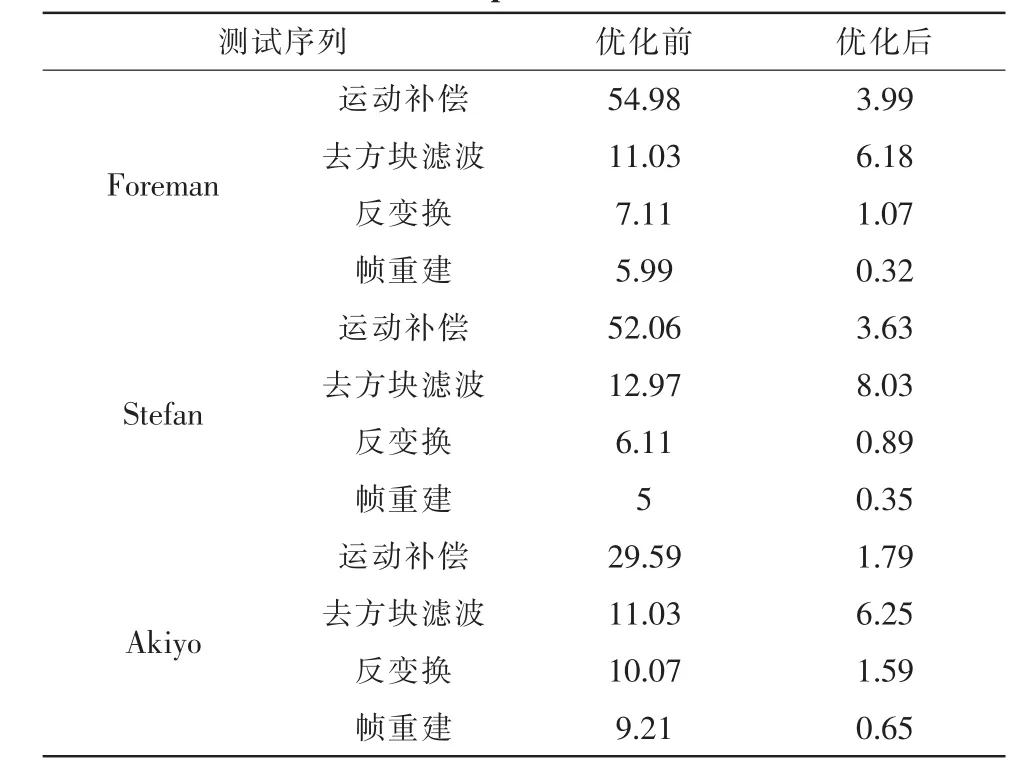
表1 測試序列優化前后不同模塊解碼時間占有比/%Tab.1 Module decoder time improvement in percentage after optimization
表2給出了經過了優化后,每個序列解碼速度的提高值。Foreman相對于其它兩個序列優化效果更明顯,根本原因歸結于對運動補償模塊的優化程度,可見整體優化性能的提升與序列運動補償多少成正比。實驗時同時發現視頻參考序列在該平臺上解碼速度最高可達30 fp/s。

表2 測試序列解碼器優化后整體性能比較Tab.2 Overall performance improvement in FPS
4 結束語
文中重點研究了CEVA開發平臺下WMV實時解碼的算法優化及實現。主要完成了以下幾方面工作:針對CEVAX1622的體系結構,對解碼器部分核心模塊的算法結構做了優化,并且利用SIMD技術進行了DSP實現。結果表明在經過優化處理后,解碼算法的各個模塊所需的解碼時間得到了降低,同時解碼器解碼速度能夠有效支持標清和高清視頻的解碼需求。
[1]沈鉦,孫義和.一種支持同時多線程的VLIW DSP架構[J].電子學報,2010,(2):352-353.
SHEN Zheng,SUN Yi-he.Architecture design of simultaneous multithreading VLIW DSP[J].Acta Electronica Sinica,2010(2):352-353.
[2]CEVA和ARM聯手增強CEVA DSP+ARM多處理器SOC的開 發 支 持 [EB/OL].(2008-06-10)http://www.eefocus.com/article/08-06/4322410100603d0oY.html.
[3]Srinivasan S,Regunathan S L.An overview of VC-1[J].Visual Communications and Image processing,Proc.Of SPIE, 2005(5960):720-728.
[4]Srinivasan S,Hsu P,Holcomb T,et al.Windows Media Video 9:overview and applications[C]//Signal Processing:Image Communication,2004(19):851-875.
[5]CEVA-X ARCHITECTURE CEVA-X1620/1622[EB/OL].[2011-09-27]http://www.ceva-dsp.com/products/cores/pdf/cevax1622_datasheet.pdf.
[6]Proposed SMPTE Standard for Television VC-1 Compressed Video Bitstream Format and Decoding Process[C]//SMPTE Technology Committee C24 on Video Compression Technology,2005.
[7]尹明,王宏遠.VC-1視頻編碼技術研究[J].電視技術,2005(11):19-20.
YIN Ming,WANG Hong-yuan.Technical study of VC-1 video encoding[J].Digital TV&Digital Video,2005(11):19-20.
[8]馮麗.VC-1解碼算法研究及其DSP移植與優化[D].北京:北京交通大學,2008.
[9]VC-1 Compressed Video Bitstream Format and Decoding Process[S].SMPTE 421M-2006,SMPTE Standard,2006.
[10]聶勝猛,張澤建,歐建平,等.多重頻解模糊中降低頻道量化誤差的新方法[J].現代電子技術,2011(11):179-181,185.
NIE Sheng-meng,ZHANG Ze-jian,OU Jian-ping,et al.A new method to reduce channel quantization error in resolving velocity ambiguity by PRF varied method[J].Modern Electronics Technique,2011(11):179-181,185.
[11]張坤,王瑩,高凱.基于TOD信息的長周期跳頻序列產生及其性能分析[J].現代電子技術,2010(9):4-6,10.
ZHANG Kun,WANG Ying,GAO Kai.Generation of long period FH sequences vbased on TOD and property analysis[J].Modern Electronics Technique,2010(9):4-6,10.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
