英漢醫學平行語料庫的創建與初始應用研究
2011-12-05 06:37:56管新潮胡開寶張冠男
當代外語研究 2011年9期
關鍵詞:文本
管新潮 胡開寶 張冠男
(上海交通大學,上海,200030)
1.引言
自20世紀90年代中期起,無論國內還是國外,與語料庫相關的翻譯研究與應用得到了迅猛的發展。已建成的各種語料庫如翻譯語料庫、平行語料庫和可比語料庫為數眾多,這使得在語料庫支持下的翻譯研究收獲頗豐(胡開寶、陶慶2010:49)。然而,在各類已建成的語料庫中,只有若干通用類語料庫包含有科技類語料內容,專門的科技語料庫則更少,其中最著名的就是建成于上世紀80年代的上海交通大學科技英語語料庫(JDEST)(楊惠中2002:35)。大多數語料庫均以翻譯研究或教學作為目標,而將語料庫應用于翻譯實踐的還不多見。
另一方面,隨著中國圖書推廣計劃和“中國文化走向世界”國家戰略的實施,漢譯外人才奇缺的現象更為嚴重(莊智象2007:120)。有鑒于此,我們于2009年7月起在上海市科委立項并開始創建英漢醫學平行語料庫(English-Chinese Medical Parallel Corpus,簡稱為ECMPC)。總體目標是創建一個1000萬字(詞)庫容的英漢醫學平行語料庫,開發出基于該語料庫的翻譯教學與機助翻譯軟件,以應用于教學和翻譯實踐,尤其是漢譯英實踐。同時,借助于語料庫做一些探索性的翻譯研究。
2.語料庫的設計
2.1 目的
本項目旨在建設一個示范型的臨床醫學科技文獻雙語語料庫,并基于該語料庫,實現以漢譯英為主的在線機助翻譯和翻譯教學,為醫學英語教學與醫學文獻翻譯實踐服務。因此ECMPC的設計將專注于語料的使用便捷性及語料匹配效果。
2.2 語料選取標準
根據我國“醫學學科分類與代碼”所列的學科內容,醫學可分為基礎醫學、臨床醫學、預防醫學與衛生學、軍事醫學與特種醫學、藥學。這五個方向可分別繼續細分,僅基礎醫學就有17個學科,臨床醫學有20個學科。就這一點而言,醫學是一個非常寬泛的概念,涵蓋的內容相當豐富。為了符合ECMPC的研究與應用要求,按照學科分類的特點,本項目選定以臨床醫學所屬的各個方向作為語料選取范圍。
在選定具體語料時,主要考慮的選用標準為:1.原文與譯文呈一一對應關系;2.原文應具備一定的表現力;3.譯文應符合所在國的閱讀習慣和表述要求,而且該譯文是已被認可的;4.按專題模塊匯集語料文本,使語料文本具有同質性;5.選用具有代表性的語料文本;6.所選用的每一篇語料文本都是一個完整的單元(孫迎春2011)。
2.3 語料對齊層面
ECMPC將借助于必要的技術手段,實現語篇、句子、語塊三個層面的對齊。語篇和句子對齊是雙語平行語料庫的根本,否則就無從談起這是雙語平行語料庫。語塊對齊不僅有利于翻譯教學中關鍵語言教學點的組合,而且還可以增強翻譯實踐中的翻譯匹配效果。在本項目中,因為實現了三個層面的對齊,機助翻譯時除了句對和術語外,還可參照語篇和句式。這尤其有利于漢譯英翻譯實踐。
3.語料庫的創建
ECMPC的創建主要分為五個步驟:語料的采集;語料的電子化;語料的句級對齊;語塊的提取;誘導詞的選取。
3.1 語料的采集
如2.2所述,ECMPC的語料以圖書、論文、報告為主,專業方向涉及微生物學、生物化學、解剖學、病理學、藥理學、臨床診斷學、內科學、外科學、婦產科學、兒科學、眼科學、耳鼻喉科學、口腔醫學、皮膚病學、神經病學、精神病學、感染病學等。文本按照語篇連續性進行劃分,圖書語料按章節劃分,每一章為一個語篇,英文部分每篇詞數為500至15000;論文或報告語料以一篇論文為一個語篇,英文部分每篇詞數為500至6000詞。漢語部分均與英文部分一一對應。
3.2 語料的電子化
項目所采用的語料有兩大類,即紙質和電子語料。前者外包給專業機構,通過手工錄入或掃描實現電子化,并進行校對,以使電子文檔與紙質文檔相一致。后者為PDF格式,若是掃描的,則同樣外包給專業機構;若是由WORD轉化而來的,則以ABBYY軟件轉化為WORD格式或直接拷貝成WORD格式,之后同樣需要校對。這一階段的操作相對簡單,但需要專業機構來處理,否則就會出現文字上的錯誤,從而影響到語料庫建成后的翻譯匹配效果。
在實現句級對齊之前,還需要對語料進行降噪處理和再次校對。降噪處理主要涉及以下五類:
?公式:若轉化為TXT格式的公式仍未變形,則予以保留,否則就剔除;
?表格:一般將表格內的文字提取出;
?圖片:不保留圖片,但需提取出圖片中的文字;
?外包校對中遺留的某些問題,如空格、斷句、標點、字母大小寫、數字;
?將WORD格式轉化為TXT格式時會發生變形的符號,如破折號“——”等;
再次校對主要是檢查文檔中的英漢段落是否平行對齊,是否滿足軟件自動對齊的需要。
3.3 語料的句級對齊
在語篇(加注篇頭信息)及段落對齊后,方可進行句子對齊。為了獲取最佳句對齊效果,在軟件自動實現句子對齊的同時,還需要人工介入。本項目采用Trados軟件的對齊功能,并依據下列原則對語料進行句對齊處理(見圖1):
?英文原文與中文譯文的句子對齊以一一對應為主,但也允許語句一對多或多對一等情況的存在。
?一般以句號、分號、問號等為分句標記,但總有例外情形存在。這里最為重要的是,必須考慮到英文語句在句法邏輯上是一個完整的單元,中文語句與之相應匹配。

圖1 語料句級初步對齊效果
在人工介入對齊的同時,還可以對語篇進行校對,即觀察已鏈接的英漢句對是否完全對應,是否存在漏譯現象。
3.4 語塊的提取
在真實的語言中,語塊是一個具有一定意義的翻譯單位,能準確表達其在文本中的含義。語塊的大小介于句子與單詞之間,它有連續與非連續兩種。本項目的連續語塊為醫學術語,它既可以是一個詞,也可以是多個詞,主要取決于語篇中所出現的具體情況。提取連續語塊時采用對一個語篇進行全額術語提取的方式。連續語塊示意如下:
animal models 動物模型
annual cumulative exposure 年累積暴露
antibiotic prophylaxis for infective endocarditis 抗生素預防感染性心內膜炎
antibiotic prophylaxis 抗生素預防
antibiotic resistance 抗生素耐藥性
非連續語塊為句式即句子結構,主要由非專業術語組成。非連續語塊示意如下:
Few cases of...are now secondary to 現在很少有……繼發……的病例
relevance of...is questionable 是否具有關聯性尚存疑問
之所以將語塊劃分為連續和非連續兩類,是因為作為連續語塊的術語將在機助翻譯系統中助力譯者識別術語,而非連續語塊一是為專業翻譯教學之用,二是在翻譯句子匹配無果時用于句子結構的匹配,尤其是漢譯英。如此劃分的另一個原因是為了計算機編程方便。
基于語塊匹配的機助翻譯,可以達到最準確的語義翻譯狀態。傳統的機器翻譯主要基于單個詞,這在文本使用中意義容易發生改變,產生歧義。而目前國外所開發的機助翻譯軟件一般均以單個句子為翻譯單位,翻譯過程中出現較為常見的翻譯匹配缺失現象。
為了實現基于語塊匹配的機助翻譯,必須事先從已經實現英漢匹配的句對中提取語塊。為此,我們開發了PhrasExt語塊提取系統。該系統以機助方式助力于連續與非連續語塊的提取,旨在提取出符合翻譯教學和實踐要求的語塊(見圖2)。系統所起的關鍵作用包括:1.由軟件來生成語塊格式,即在目視確定后語塊自動進入數據庫,無需人工介入;2.在軟件中設置校對編輯框,以免出現字母缺失現象;3.語塊提取人員只需專注于語塊的確定即可(熊秋平、管新潮2011:31)。
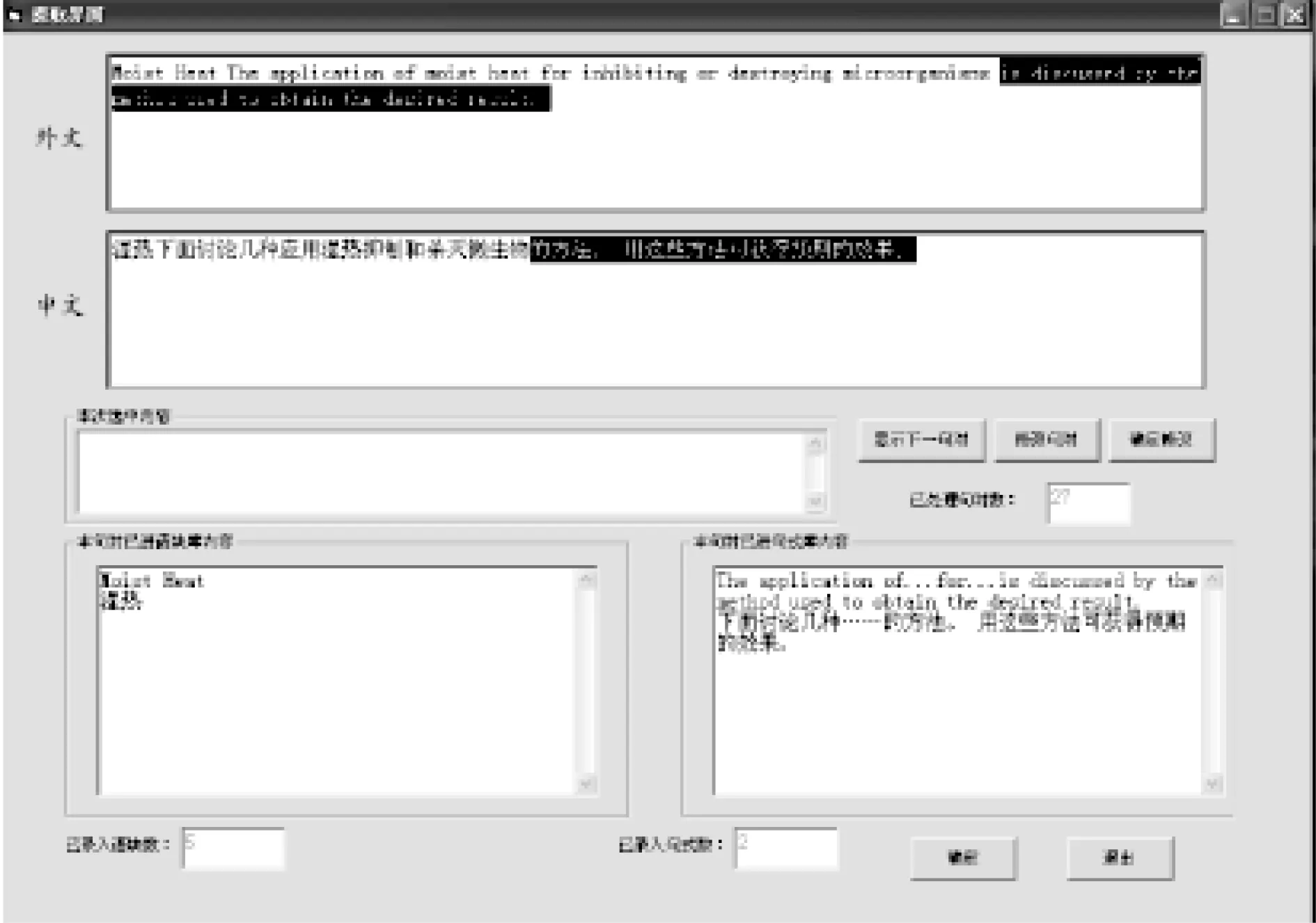
圖2 術語及句式提取界面
3.5 誘導詞的選取
誘導詞是基于非連續語塊的翻譯匹配效率而提出的,因為在系統設計過程中,當句子無法實現翻譯匹配時,緊接著采用非連續語塊(句式)進行翻譯匹配。為了使翻譯匹配符合要求,即以非連續語塊中的關鍵詞來誘導非連續語塊(句式)實現翻譯匹配,將關鍵詞定義為誘導詞。誘導詞的作用是在翻譯教學與機助翻譯系統中誘導非連續語塊(句式)的匹配,增強翻譯匹配的效果。誘導詞也是醫學語料中的通用詞,一個誘導詞可以匹配多個非連續語塊(句式),以供翻譯時選用適當的句式。
誘導詞的選取采用WordSmith軟件,從非連續語塊的英語部分中將相關單詞按詞頻順序排列。刪除其中的虛詞,選取實詞和詞組作為誘導詞,并按英漢對照句式配以中譯文(見表1)。注意所選取的對應中譯文均須出現在對照句式中,不可參照詞典選取義項。選取單個誘導詞的同時,還需觀察某些誘導詞是否構成固定搭配;若是,則須按固定搭配選取(見表1的下半部分)。

表1 英漢匹配誘導詞
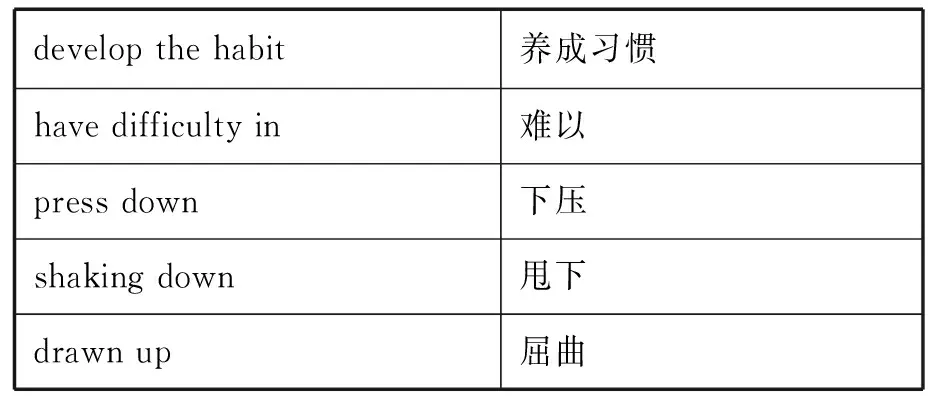
(續表)
實際上,提取術語之后再通過誘導詞的選取,就可以將一個語篇劃分成若干術語和通用詞。術語表述準確,翻譯時無需多加考慮,對應選中即可。而通用詞是翻譯的關鍵,即語篇中的通用詞是如何將不同的術語串接起來的,這也是翻譯教學中的關鍵。
4.ECMPC特點
本節將以ECMPC的若干數據與王克非(2003:114)基于1000萬字(詞)的英漢漢英雙語平行語料庫得出的結果進行對比分析。其中1000萬字(詞)語料庫內英譯漢約占60%,非文學類約有45%,相當于270萬字(詞);而ECMPC隨機考察了約400萬字(詞)語料。而且,ECMPC的句對齊原則與王克非所定的識別句子的標準相類同,因此,兩個語料庫具有較強的可比性。
王克非(2003:414)敘述:“從本文的發現看,句子仍不失為翻譯的一個主要轉換單位,特別是除文學漢譯英之外的另三類翻譯,其1:1的句對比例均達到80%以上。……這一點在翻譯教學中,特別是在自動翻譯研究中,有引人重視的價值。”從ECMPC實際對齊結果來看,其中1∶1的句對語料比例超過80%.實際上,本課題立項的初衷就是將雙語對齊語料應用到機助翻譯實踐和教學之中。這一點與王克非的結論不謀而合。
王克非(2003:414)又說:“譯文受原文影響的程度有差異。英譯漢1∶1的語句對應高于漢譯英,主要原因是漢語譯者翻譯時多參照原文的句式和標點,特別是在比較嚴肅的文本中。”這一點在醫學語料中也表現無遺,因為醫學語料本身就是非常嚴肅的文本。
相對于英漢漢英雙語平行語料庫英譯漢部分(非文學)而言,ECMPC的專業性更強。那么兩者在翻譯文字量上會有何種異同呢?考察語料數、文字量比例,結果詳見表2.
從表2可以看出,ECMPC的英漢詞字數比例范圍大于英漢漢英雙語平行語料庫,因為就有限的專業領域而言,前者的語料多于后者的語料。考慮到每個譯者的翻譯風格各不相同,這種比例差異是允許存在的。至于該比例小到或大到多少才算得上真正意義的欠量或過量翻譯,還有待進一步的研究,因為所選語料畢竟經過第三方認可,而且有選取原則可循。常見英漢詞字數比例范圍兩者基本相同,平均詞字數比例完全一致,這說明哪怕是專業性再強的翻譯,其翻譯文字量也與專業性較弱的翻譯基本保持一致。

表2 英漢漢英雙語平行語料庫英譯漢部分(非文學)與ECMPC英譯漢文字量對比
5.ECMPC的初始應用研究
由于專業類語料庫的稀缺,此方向的實證研究明顯滯后。ECMPC收錄了選自真實語境的語料,并配以相應的自動檢索和統計功能,為專業翻譯的實證研究提供了堅實的物質基礎,使翻譯研究實現定量與定性的結合。ECMPC的語言特征是指整體語料在詞匯、句法和語篇等層面上所表現出的特征。由于醫學類語料在語言表述形式上的學科遵從性,語料的語言特征有其獨特之處。這里,我們分別對語料庫原語統計特征和詞語搭配情況進行考察。
5.1 原語統計特征
本文所提供的涉及語料庫統計特征的相關數值均源自于ECMPC的一個子語料庫的英文部分。由WordSmith統計得出子語料庫的統計特征(見表3)。

表3 ECMPC子語料庫的統計特征
由表3可知,該語料庫的標準類符/形符比(standard type/token ratio)為42.14,略高于JDEST的形符/類符比(40.40),表明ECMPC的詞匯比JDEST的詞匯豐富。這一現象乍一看有些反常,因為JDEST收錄了來自天文學、圖書館學、通訊等41個領域的論文,而ECMPC僅僅由醫學文本組成。由Wordlist可知,在所有35514個類符中,有17062個只出現了一次,如onychomycosis,zoonsis,yomesan等。可見醫學術語比較豐富,而這些詞的出現頻率又不高。這充分體現了醫學文本的特點,即術語多而專。對二語學習者而言,很難將這些術語都記住。普通醫學辭典不可能收錄如此眾多的術語,因此建立在線醫學語料庫詞典勢在必行。
ECMPC的平均句長為20.6,低于JDEST的平均句長(25.96)。通過查看原文可知,ECMPC的短語式標題較多,這是縮短句長的主要原因。其二,它包含有不少的短語式句子,使句長明顯縮短,例如:
...a combination of the following mechanisms:
Deletion of uridine kinase.
Deletion of nucleoside phosphorylase.
...
同時,我們檢查了ECMPC的Wordlist,得出ECMPC中出現頻率最高的前10個實詞(見表4)。
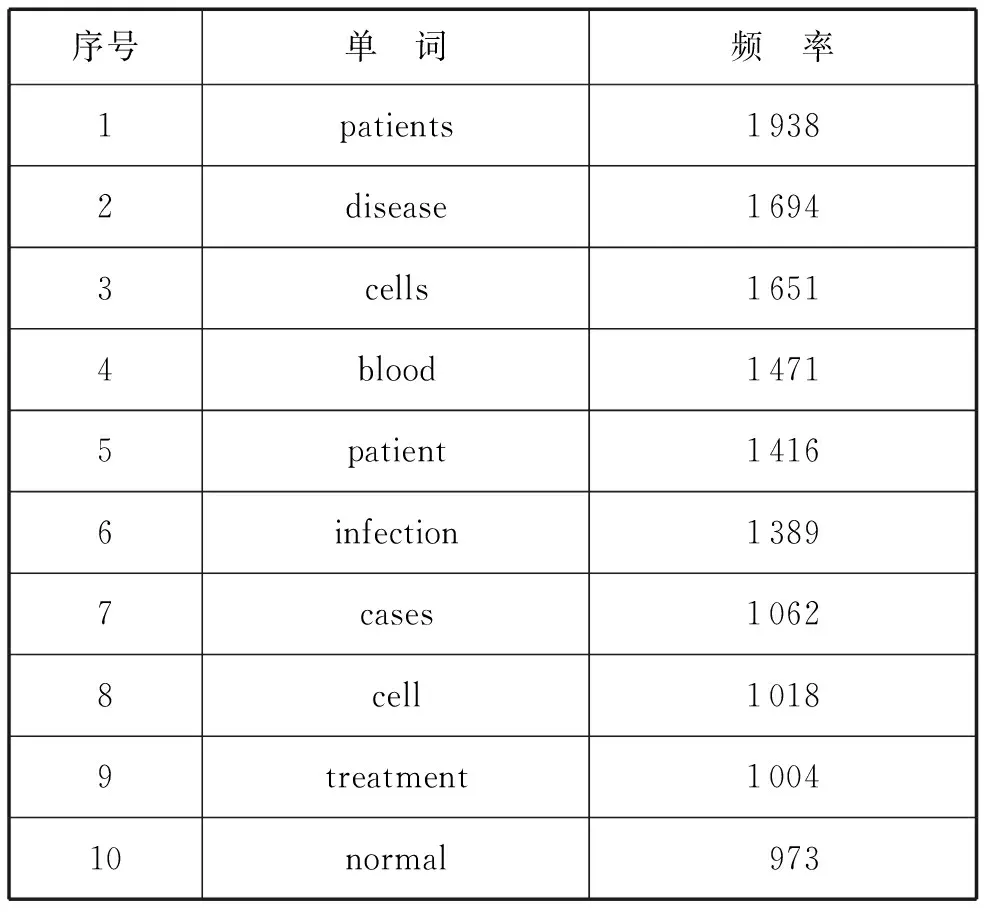
表4 ECMPC子語料庫最高詞頻實詞(前10個)
上面10個實詞都與醫學有關,尤其是patients,disease,cells,blood,patient,infection和cell是與疾病、治療直接相關的,即這些詞的主要義項與醫學直接相關。這些詞雖然是醫學術語,但又是通用詞,經常出現在各種普通文本中。醫學文本的特征是這些詞出現的頻率極高。patients/patient是醫學治療的對象,disease是醫學存在的原因,而blood,cell(s)和infection則是醫學研究的對象。相較這些詞而言,cases,treatment和normal在醫學文本中則主要是以其不太常見的義項出現的,體現了詞匯義項的窄化(narrowing)。如cases最常見的義項為“情況”,而在醫學文本中則以“病例”的義項出項。treatment常見義項為“對待”,醫學文本中義項為“治療”。
normal一詞在ECMPC中涉及“生命體征”的有下列表述:Vital signs were normal“生命體征平穩/未及異常/正常/無異常”。而《英漢大詞典》(陸谷孫1993:1231-1232)所列的相關義項僅顯示為:“【醫】【心】精神(或身體、智力等)正常的”。顯而易見,從語料庫中檢索出的normal一詞的義項更為豐富。繼續查看Wordlist,可以發現此類詞匯很多,如management一詞,《英漢大詞典》中與醫學相關的義項為:“【醫】(疾病等的)處理(法)”。從ECMPC中檢索出的義項為:“處理,治療,予以,療法,管理”等。又以administration一詞為例,《英漢大詞典》中與醫學相關的義項為:“(藥的)配給;服法,用法”。從ECMPC中檢索出的義項則包括:“給藥,治療,服用,給予,應用,使用,投入,補充,輸(入)”等。
5.2 詞語搭配
以表4中的實詞為例,從詞語搭配角度來考察ECMPC中代表性句式的表現,會發現詞語搭配明顯受到語域的影響,反映了不同語域中詞語使用的特點(楊惠中2002:105),其檢索結果可分為活躍與不活躍搭配兩種:
活躍搭配為:
?在醫學領域里,patient是常見詞。若要表達“某種疾病的患者”,通常采用patient(s) with(疾病名稱)的搭配(楊惠中2002:105)。這一點與ECMPC中的句式表現相吻合。
?與disease搭配的形容詞主要有active,acute,chronic,common,infectious,malignant,serious,severe,systemic等,用以表示疾病的性質;搭配的動詞主要有cause,develop,spread,transmit等,用以表示疾病的產生或發展情況。
?與blood進行搭配的主要是些名詞,可分為3類:一是表示醫學物理現象,如loss,concentration,pressure,stream/flow,supply,volume等;二是表示人體的醫學名稱,如brain,glucose/sugar,vessel等;三是表示醫學操作,如culture,transfusion等。
?infection的搭配非常活躍。與形容詞搭配時主要用于表示感染程度(heavy,light,mild,significant)、性質(active,chronic,endemic)和部位/位置(facial,nosocomial,systemic);與其搭配的動詞有acquire,cause,lead,transmit,spread,suspect等,表示感染的生成、傳播、揭示等;與其搭配的名詞有area,focus,intensity,source,rate,risk等,表示感染源和程度。
?與treatment搭配的主要是形容詞appropriate,conservative,effective,external,medical,special等,表示治療的方式與合理性。
?normal一詞搭配最為活躍,可實現任意形式的搭配,以致無法檢索歸類。
非活躍搭配為:
?cell(s)一詞雖然在表4中位居3和8,但除與red搭配外,無其他明顯的搭配表現。
?與case搭配的主要是些數字,因其意為“病例”之故。
6.結語
雖然ECMPC的建設難度很大,但其研究與實踐應用的價值已初現成效。ECMPC的建成不僅為醫學英語的教學提供了一個平臺,而且還可以在翻譯實踐中得到應用。同時,這是一次創建專業性語料庫的嘗試,為同類語料庫的建設積累了經驗。基于ECMPC的統計結果與初始研究表明:翻譯文字量與專業性強弱關系不大;醫學中的通用詞表現活躍,是學習醫學英語的重點,尤其是詞語搭配。
Baker M.1993.Corpus linguistics and translation studies: Implications and applications [A].In M.Baker,etal.(eds.)TextandTechnology:InHonourofJohnSinclair[C].Amsterdam/Philadelphia: John Benjamins.233-250.
管新潮.2011.漢譯外實踐中的平行語料庫解決方案[A].孫迎春.2009譯學詞典與翻譯研究文萃[C].上海:上海外語教育出版社.52-63.
管新潮.2008.專業翻譯與管理[A].第18屆世界翻譯大會分論壇論文集——工程翻譯與本地化服務[C].上海市工程翻譯協會.46-52.
胡開寶、陶慶.2010.漢英會議口譯語料庫的創建與應用研究[J].中國翻譯(5):49-56.
陸谷孫(主編).1993.英漢大詞典(第1版)[Z].上海:上海譯文出版社.
孫迎春.2011.2009譯學詞典與翻譯研究文萃[C].上海:上海外語教育出版社.
王克非.2003.英漢/漢英語句對應的語料庫考察[J].外語教學與研究(6):014-614.
王平庚.2008.信息化時代的翻譯與本地化服務[A].第18屆世界翻譯大會論文集[C].北京:外文出版社.7-12.
熊秋平、管新潮.2011.基于工作研究的語塊提取系統PhrasExt軟件設計[J].工業工程與管理(1):14-117.
楊惠中.2002.語料庫語言學導論[C].上海:上海外語教育出版社.
莊智象.2007.我國翻譯專業建設:問題與對策[M].上海:上海外語教育出版社.
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
