基于概率轉移矩陣的氨基酸連接偏好性研究
2012-01-11 05:10:22唐旭清
食品與生物技術學報 2012年1期
張 堃, 唐旭清
(江南大學 理學院,江蘇 無錫 214122)
基于概率轉移矩陣的氨基酸連接偏好性研究
張 堃, 唐旭清*
(江南大學 理學院,江蘇 無錫 214122)
在Markov模型的基礎上,提出了狀態空間上合并映射的概念,以及合并過程下轉移概率的計算方法。在已有氨基酸分類方法的基礎上,結合Markov模型的概率轉移矩陣,對氨基酸連接的偏好性進行了研究。結果表明:同一家族的蛋白質序列的氨基酸連接具有一定的偏好性,這種偏好性與氨基酸的分類有關,從而進一步說明了分類的科學性,同時這種偏好性對氨基酸序列的預測具有一定的作用。
氨基酸分類;合并映射;概率轉移矩陣;偏好性
蛋白質空間結構的所有信息均隱藏在蛋白質的線性結構里面,確切的說,均隱藏在氨基酸序列里面。因此研究蛋白質序列就成了生物信息學研究領域的一個關鍵問題。目前已經發現的構成蛋白質分子鏈上的氨基酸類型有20種之多,直接研究蛋白質分子的折疊問題有困難,用分類法研究蛋白質結構,已有多種嘗試,三聯子串(氨基酸)依據其物理和化學特征,或者是依據氨基酸的空間結構特征來進行的不同的分類方式,目前的研究主要集中在幾種簡化的模型上。K.A.Dill等人[1]提出的HP模型將氨基酸分為4類。石秀凡及朱平等人[2]提出的擬氨基酸編碼方法將氨基酸分為16類,杜曉林等人[3]應用信息聚類的方法將氨基酸分為5類,Soumalee Basu等人[4]在蛋白質序列的混沌游走表達一文中將20種氨基酸分為12類研究它們的分布情況。分類的依據和偏重不同,分類結果也不同。而這些分類事實上是一種狀態合并的問題,即將具有一定關聯的對象合并到一個類中,不同的分類對應著不同的粒度劃分。在實際問題求解中,粒度劃分是動態的,常用的氨基酸分類方法都是靜態的。Markov過程是由其轉移概率矩陣和初始概率分布構成的,其中的概率轉移矩陣描述了其動態性。馬氏鏈預測法[5]是通過對事物不同狀態的初始概率及狀態之間的轉移概率的研究,預測事物的未來狀態,在股票預測[6],外匯收益預測[7],基因預測[8-9]等方面都有廣泛的應用。作者針對 Markov模型,結合氨基酸分類方法,對氨基酸連接的偏好性進行了研究,并以木聚糖酶家族[10]的蛋白質序列為例進行了分析。
1 材料與方法
1.1 數據來源
文中的數據來自Swiss-prot和Genebank中木聚糖酶家族的6條蛋白質序列O43097,P07528,P14768,P23030,P19127,P35811進行研究。另外文中的相關性分析是通過統計軟件SPSS來完成的。
1.2 基于粒度下的Markov鏈
1.2.1 合并映射設 {X n,n≥0}有限狀態空間X上的齊次Markov鏈,其中X= {x1,x2,…,x N},如果將X中N個狀態分類成M個狀態分類成C={C(1),C(2),…,C(M)},(M<N)。對于給定的分類,建立了一個從X= {x1,x2,…,x N}到Y= {y1,y2,…,y M}的一個映射φ:?x k∈X,?y l∈Y,φ(x k)=y1?k∈C(l),其中映射φ稱為合并映射或壓縮映射,C稱為X的一個劃分。同時這一過程{Y n=φ(X n)}就成為相對于映射φ的合并過程[11]。
事實上,這里所給出的合并映射φ所起的作用就是給定了原始狀態空間X上的一個商空間[12-13]Y= [X],以這個商空間作為狀態空間(或觀測空間)來研究原始馬爾科夫鏈在這較粗狀態空間(即X的商空間[X]下)的性質。在隨機線性動力系統中,若給定輸入 — 輸出動力系統:x n+1=Ax n,y n=Cx n,則在什么樣的條件下,y n具有線性動力系統的性質,特別是當x n是隨機變量X n的概率分布時,這個序列與Markov鏈相應,這里A是Markov鏈{X n,n≥0}的轉移矩陣,而矩陣C就是壓縮映射φ,即y n是隨機變量φ(X n)的概率分布。1.2.2 合并過程的概率轉移矩陣 若Markov鏈{Xn,n≥0}的狀態空間為I= {1,2,…,N},設φ為從I到集合Y= {y1,y2,…,y M}(M<N)的合并映射,即,?k∈I,?y l∈Y,φ(k)=y l?k∈φ-1(y l),此時稱Y為I的商空間,{Y n=φ(Xn)}就成為相對于映射φ的合并過程。若{Xn,n≥0}的初始概率向量為X0= (π1,π2,…,πN),則

令ast=P(Y1=y t|Y0=ys),矩陣A=(ast)s,t∈Y為合并過程{Y n=φ(X n)}在狀態空間Y上的轉移矩陣。
1.2.3 應用舉例 對于一條由610個氨基酸構成的蛋白質序列來說,作如下假設,設610個位置為610個時刻,{A,F,I,L,M,P,V,W,Y,T,S,Q,N,G,C,H,K,R,D,E}為由20種氨基酸構成的狀態空間,該狀態空間對應于一個號碼集合I= {1,2,…,20},令X(n)表示氨基酸n后面所連接的氨基酸種類,顯然X(n)是一個隨機變量,{X(n),n=1,2,…,20}是一個離散參數的隨機過程,并且每個氨基酸后面所連接氨基酸與前面的狀態無關,只與蛋白質序列本身有關,氨基酸i與氨基酸j連接的概率與i所在的時刻無關,因此氨基酸之間的連接過程可以看成是一個Markov過程。于是Markov預測模型可以定義為一個三元組(X,P,π),其中X為20種氨基酸構成的狀態空間,P為一階概率轉移矩陣,π為初始分布。定義X到Y1= {y1,y2,y3,y4,y5,y6,y7,y8,y9,y10,y11,y12}上 的 合 并 映 射φ1,X到Y2={y1,y2,y3,y4}上的合并映射φ2。
φ1(x i)=y i,x i∈ {{C},{H},{N},{P},{Q},{W},{Y,F},{A,G},{S,T},{K,R},{D,E},{I,L,V,M}}
φ2(x j)=y i,x j∈ {{A,F,I,L,M,P,V,W},{Y,T,S,Q,N,G,C},{H,K,R},{D,E}}

這樣我們就得到了6個初始概率和6個20×20的一階概率轉移矩陣,通過合并映射φ1,φ2和公式(1)可得合并后的12×12,4×4轉移矩陣。
2 結果與分析
2.1 相關性分析
衡量事物之間或變量之間線性相關程度的強弱,并用適當的統計指標表示出來,這個過程就是相關分析[14]。它是研究變量間密切程度的一種常用統計方法。主要分為線性相關分析,偏相關分析,距離相關分析3類,作者主要研究線性相關分析。線性相關分析是研究兩個變量間線性關系的程度,相關系數是描述這種線性關系程度和方向的統計量,用r來描述,若變量Y與X間是函數關系,則r=1或r=-1;如果變量Y與X間是統計關系,則-1<r<1,一般地,|r|>0.95存在顯著性相關;|r|>0.8高度相關;0.5≤|r|<0.8中度相關;0.3≤|r|<0.5低度相關;|r|<0.3關系極弱,認為不相關。

在1.2.3節中得到了6條序列的12×12和4×4概率轉移矩陣,以序列O43097為例,令α=(α1T,…,α2T,α12T)T,其中αi表示該序列所對應的12×12概率轉移矩陣中的第i列,則α為含144個分量的列向量,同樣的方法可以得到其他五條序列的所對應的列向量,利用SPSS軟件對這六個列向量進行了相關性分析,結果如表2.1所示。按照同樣的步驟可以得到4×4概率轉移矩陣所對應的列向量,相關性分析如表2.2所示。
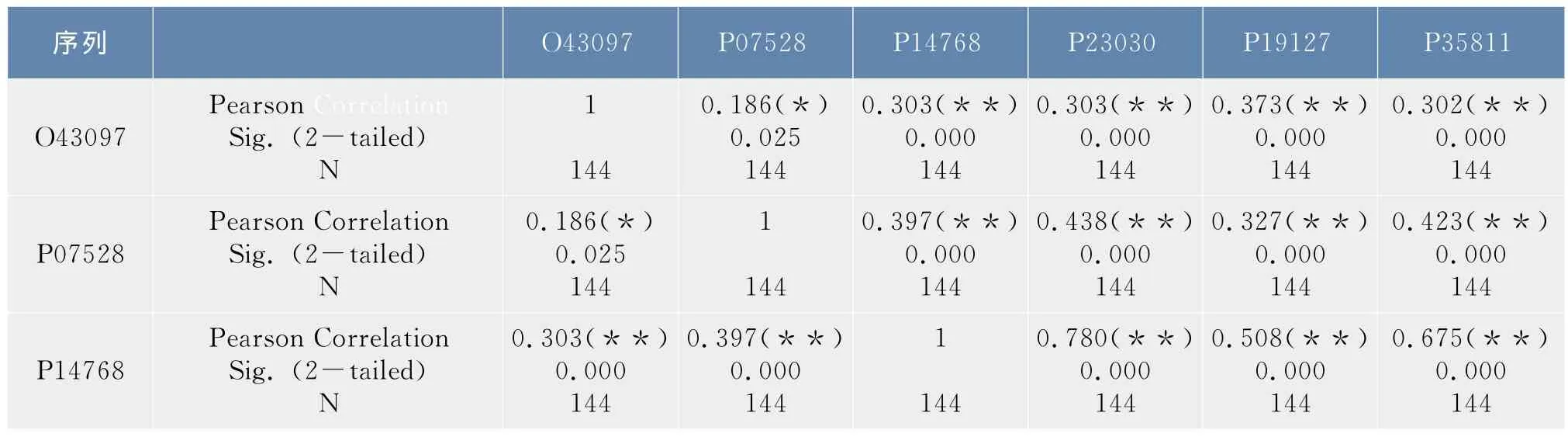
表1 合并映射φ1下6條序列概率轉移矩陣的相關性分析Tab.1 Correlation analysis of the probability transition matrix of the six sequences under the lumping mapφ1

續表1
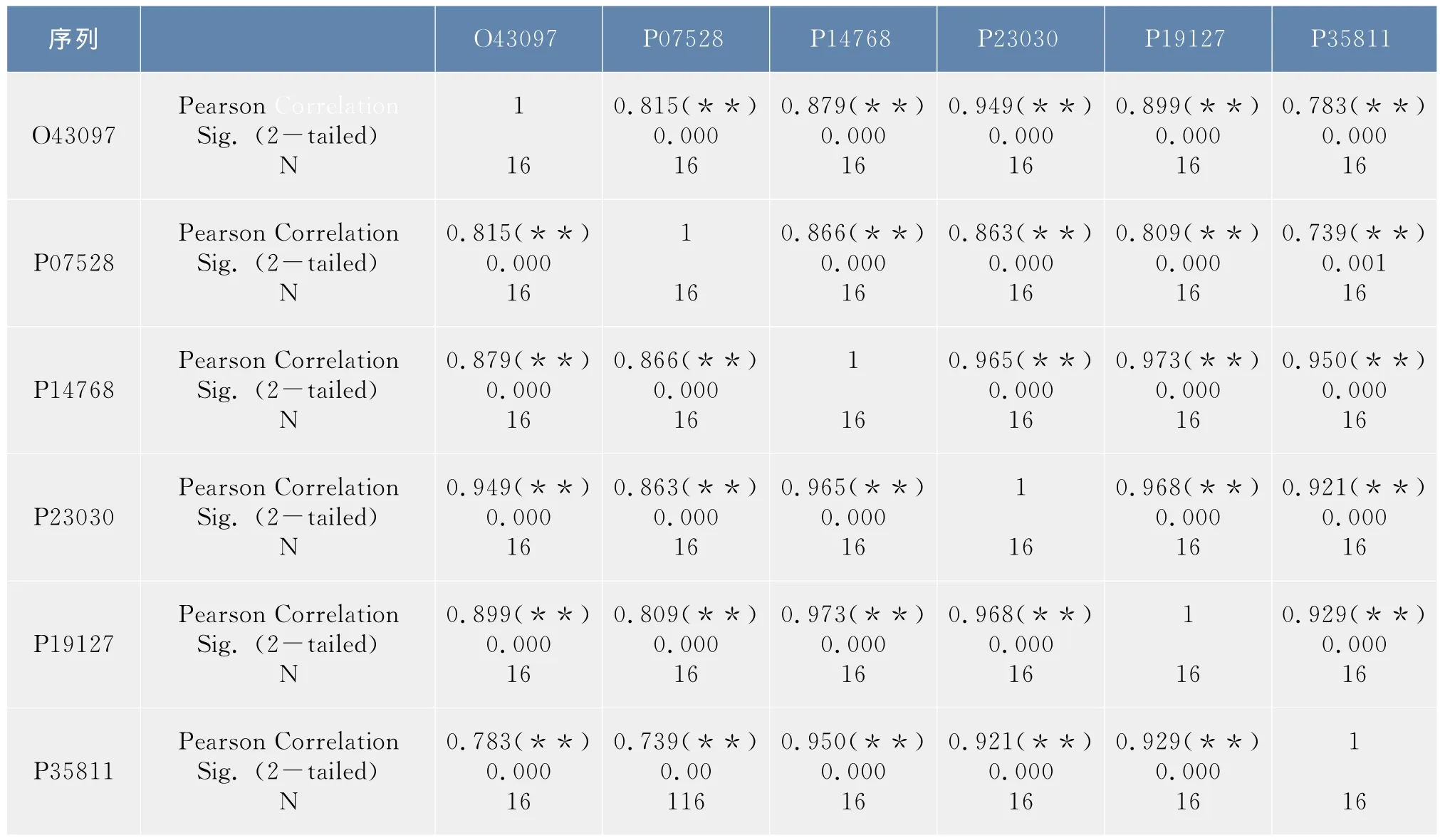
表2 合并映射φ2下6條序列概率轉移矩陣的相關性分析Tab.2 Correlation analysis of the probability transition matrix of the six sequences under the lumping mapφ2
在上述相關性分析表中,Pearson Correlation表示的是相關系數r,Sig.表示的是顯著性概率,N表示的是向量中分量的個數。
從表1中可以看出除序列O43097和序列P07528之間的顯著性概率值介于0.01和0.05之間外,其他序列間的顯著性概率均小于0.01,從表2中可以看出,所有序列之間的顯著性概率值都小于0.01,均高度相關,而且相關系數均大于0.7,相關性都非常顯著。這說明在映射φ1,φ2下6條序列都是高度相關的,因此可以將6條序列合并處理,得到了合并序列所對應的20×20概率轉移矩陣及初始分布。
2.2 合并后的概率轉移矩陣
根據1.1節得到的數據,包括木聚糖酶家族的6條蛋白質序列,按照1.2.3節定義的合并映射以及公式(1),得到了2.1節中合并序列在φ1,φ2下的概率轉移矩陣,如表3和表4所示。矩陣中的元素表示兩個氨基酸類之間的連接概率,例如,0.025 641表示的是氨基酸C后面連接的氨基酸為H的概率是0.025 641,0.307 692表示的是氨基酸C后面連接的氨基酸為A或者G的概率為0.307 692。
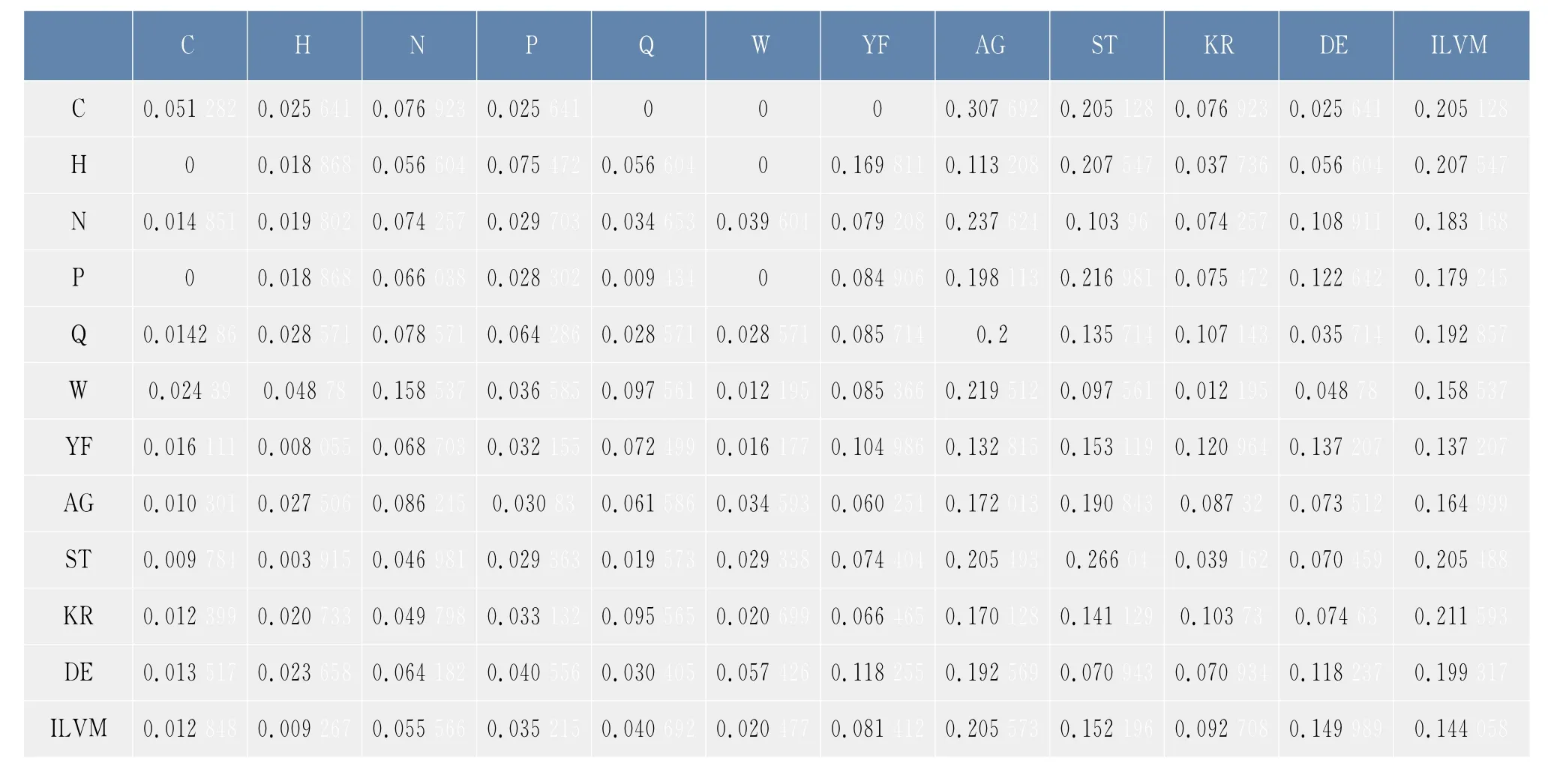
表3 合并序列在φ1下的概率轉移矩陣Tab.3 Probability transition matrix of the lumped sequence under the lumping mapφ3

表4 合并序列在φ2下概率轉移矩陣Tab.4 Probability transition matrix of the lumped sequence under the lumping mapφ2
觀察表3和表4,可以發現氨基酸之間的連接具有一定的偏好性,通過比較兩種分類方式的轉移概率,發現該家族的蛋白質序列均偏好使用氨基酸A,G,S,T,I,L,V,M 均不偏好使用氨基酸 H,K,R,D,E等,同時還發現氨基酸之間連接的偏好性與氨基酸的分類有關,極性不帶電荷R基團氨基酸,即{C,N,Y,G,Q,S,T},后面連接{C,N,Y,G,Q,S,T}的概率接近二分之一,而與帶正電荷的氨基酸{H,K,R}及帶負電荷的氨基酸{D,E}相連的概率則非常小。
3 結語
氨基酸之間的連接并非隨機的均勻的,而是具有一定偏好性的,作者在Markov模型的基礎上,結合已有氨基酸的分類方法,提出了一種基于概率轉移矩陣的氨基酸連接偏好性的研究方法,并以木聚糖酶家族的蛋白質序列為例進行了系統的闡述。研究表明,氨基酸之間的連接具有一定的偏好性,這種偏好性與氨基酸的分類密切相關,同時與密碼子使用的偏好性有關。對于木聚糖酶家族而言,極性不帶電荷R基團氨基酸,后面連接極性不帶電荷R基團氨基酸的概率接近二分之一,而與帶正電荷的氨基酸及帶負電荷的氨基酸相連的概率則非常小。這些氨基酸之間連接的偏好性研究對于蛋白質結構預測具有一定的指導意義,一方面可以進一步說明氨基酸分類方式的科學性,同時對蛋白質氨基酸序列的預測有一定的作用,相對于實驗室測序、拼裝這樣預測節省人力物力財力,這將是下一步研究的主要內容。
(References):
[1]Lau K F,Dill K A.A lattice statistical mechanics model of the conformation and sequence spaces of proteins[J].Macromolecules,1989,22:3986.
[2]朱平,高雷,徐振源.基于擬氨基酸編碼方法下的同義密碼子的偏好性仍與結合強度密切相關[J].物理學報,2009,6:714-719.
ZHU Ping,GAO Lei,XU Zhen-yuan.The usage degree of synonymous codon is close correlated with the strength of combination based on the quasi-amino acid coding[J].Acta Physica Sinica,2009,6:714-719.(in Chinese)
[3]杜曉林,郝玉蘭.氨基酸數量化分類的研究初探[J].生物數學學報,1994,9(5):105-107.
DU Xiao-lin,HAO Yu-lan.Preliminary study on the quantified Classification of amino acid[J].Journal of Biomathematiccs,1994,9(5):105-107.(in Chinese)
[4]Soumalee B,Archana P,Chitra D,et al.Chaos game representation of proteins[J].Journal of Molecular Graphics and Modelling,1997,15:279-289.
[5]Huseyin P,Wenliang D,Sahin R,et al.Private predictions on hidden markov models[J].Artifical Intelligence Review,2010,34(1):153-172.
[6]Md.Rafiul H,Baikunth N,Michael K.A fusion model of HMM,ANN and GA for stock market forecasting[J].Expert Systems with Applications,2007,33:171-180.
[7]Dueker M,Christopher J.Neely.Can Markov switching models predict excess foreign exchange returns?[J].Journal of Banking & Finance,2007,31(2):279-296.
[8]馬寶山,朱義勝.基于隱馬爾科夫模型的基因預測算法[J].大連海事大學學報,2008,34(4):41-44.
MA Bao-shan,ZHU Yi-sheng.Gene-prediction algorithm based on hidden Markov model[J].Journal of Dalian Maritime University,2008,34(4):41-44.(in Chinese)
[9]張新生,王梓坤.生命遺傳信息中若干數學問題[J].科學通報,2000,45(2):113-119.
ZHANG Xin-sheng,WANG Zi-kun.Several methematical problems of genetic information of life[J].Chinese Science Bulletin,2000,45(2):113-119.(in Chinese)
[10]劉亮偉,楊海玉,胡瑜,等.F/10木聚糖酶研究進展[J].食品與生物技術學報,2009,6:727-732.
LIU Liang-wei,YANG Hai-yu,HU Yu,et al.A review of F/10 xylanase[J].Journal of Food Science and Biotechnology,2009,6:727-732.(in Chinese)
[11]Leonid G,James L.Markov property for a function of a markov chain:A linear algebra approach[J].Linear Algebra and its Applications,2005,404:85-117.
[12]張鈴,張鈸.問題求解理論與應用:商空間粒度計算理論及應用[M].北京:清華大學出版社,2007.
[13]Tang X Q,Zhu P,Cheng J X.The structural clustering and analysis of metric based on granular space[J].Pattern Recognition,2010,43:3768-3786.
[14]朱建平,殷瑞飛.spss在統計分析中的應用[M].北京:清華大學出版社,2007.
Research on the Connection Bias of Amino Acids Based on Probability Transition Matrix
ZH ANGKun,TANGXu-qing*
(School of Science,Jiangnan University,Wuxi 214122,China)
In this manuscript,a novel concept of lumping map and a computing method of the transition probability in lumped process were suggested based on Markov model,to investigate the connection bias of amino acids.The results demonstrated that the connection of amino acids had a particular preference which was related to the classification of amino acids,and further verified the scientific of the classification of amino acids.At the same time,the preference would give some help for the prediction of amino acids sequence.
classification of amino acids,lumping map,probability transition matrix,bias
Q 71;O 29
A
1673-1689(2012)01-0106-06
2011-01-03
*
唐旭清(1963-),男,安徽望江人,工學博士,教授,主要從事智能計算,生態系統建模與仿真及生物信息學研究。Email:txq5139@jiangnan.edu.cn
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
