基于數學模型的關聯規則實用性測度指標在養豬過程中的應用
2012-06-02 09:31:22王越,邢茜
重慶理工大學學報(自然科學) 2012年1期
王 越,邢 茜
(重慶理工大學計算機科學與工程學院,重慶 400054)
隨著計算機技術、網絡技術、人工智能與模式識別技術的發展,各領域的信息化建設也不斷向前推進。而信息化建設以及信息技術的應用,使各領域積累了海量的數據。在數據倉庫技術的支持下,這些海量數據可以通過聯機(在線)分析處理(online analaytic processing,OLAP),為決策者提供可行的決策依據。但對于潛在的、不明顯的數據關系,就不能直接應用OLAP算法,例如經典的購物籃問題。關聯規則(association rule)挖掘是數據挖掘的一項重要任務,其目的就是從事物數據庫、關系數據庫中發現項目集或屬性之間的相關性、關聯關系和因果關系。
生長肥育階段的豬所消耗的飼料占全期耗料的70%~75%,如果在該階段采用有效的飼料配方和飼料調制,必將大幅度提高生產效益。在強調豬胴體總重的同時,還必須滿足消費者要求,即提供高品質、低脂肪、高瘦肉率的胴體。由于動物生產性能、健康狀況、體重、采食量、環境及其他因素的差異,不同品種豬的差別極大。只有相應調整飼料的調制方法,不同品種的豬才可能表現出其生長的潛在優勢,因此,在豬場易于收集的數據中提取相關樣本數據,并與計算機技術進行結合,從而可以對豬群的整體新城代謝情況和生長狀況進行診斷,為及時調整飼喂方式提供依據。本研究利用數據挖掘中的關聯規則分析以及有效性和實用性分析,對大量數據進行挖掘,揭示出數據間隱藏的依賴關系。
1 關聯規則
1.1 關聯規則基本概念及形式
關聯規則最早由 Agrawal、Imielinski和Swami提出,既可用于挖掘尋找給定數據集中項之間的關聯關系,也可用于挖掘直觀的表達數據中項集間的關系。關聯規則的一般形式是:
X→Y(規則支持度,規則置信度)
其中:X稱為規則前項,可以是一個項目或項集,也可以是一個包含邏輯與(∪)、邏輯非(~)的邏輯表達式;Y稱為規則后巷,一般為一個項目,表示某種結論或事實。例如,面包→牛奶,前項和后項均為一個項目。這種規則表示方式適合于事務數據組織成事實表的情況,表示購買面包和牛奶,即購買面包則會購買牛奶。
1.2 Apriori算法
Apriori算法是基本的關聯規則挖掘算法。為了減少候選數據項集的數目,Apriori算法使用逐層搜索的方法,通過對數據庫D的所有事務數據項掃描來發現所有的頻繁項目集,大致可分為2步:
1)連接(類矩陣運算):通過將2個符合特定條件的k項頻繁集作連接運算,從而尋找k+1項頻繁項集,而這些頻繁項集是發現關聯規則的基礎。
2)剪枝:去掉那些沒必要的中間結果,即通過引入一些經驗性或經數學證明的判定條件,來減少一部分不必要的計算步驟,提高算法效率。
1.3 關聯規則的有效性
依據樣本數據可以得到很多關聯規則,但是并不是所有的關聯規則都是有效的。換句話說,有的規則并不足以讓人們信服。那么,判斷一條關聯規則是否有效,應依據各種測度指標,其中最常用的指標是關聯規則的置信度和支持度。
1)規則支持度(support)。規則支持度是指在事物數據庫D中包含項目集X的事物占整個事物的比例,記為sup(X),看作是項目集X在總事務中出現的頻率,其數學表示為
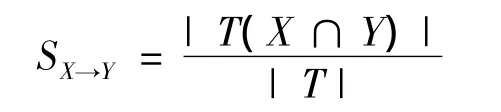
其中:|T|表示總事務數;|T(X∩Y)|表示同時包含項目X和項目Y的事務數。支持度應用于發現頻率出現較大的項目集,體現“項目集相對總事物所占的比重”。支持度太低,說明規則不具有一般性。
2)規則置信度(confidence)。規則置信度是指在事物數據庫D中,同時包含項目集X和Y的事物與含項目集X的事物的比,看作是項目集X出現,使項目集Y也出現這一事件在總事物中出現的頻率,其數學表示為
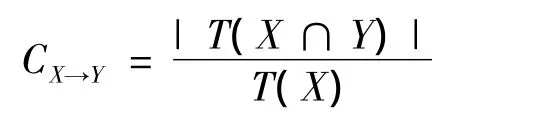
其中T(X)表示包含項目X的事務數。可信度應用于在出現頻率較大的項目集中發現頻率較大的關聯規則,體現“項目集在另一項目集影響下相對總事物所占的比重”。例如,如果面包→牛奶(S=85%,C=90%),則表示購買面包則同時購買牛奶的可能性為90%。
關聯規則挖掘就是在D中找出滿足指定的最小支持度min_sup和最小可信度min_conf的所有關聯規則,它們之間具有內在聯系,即
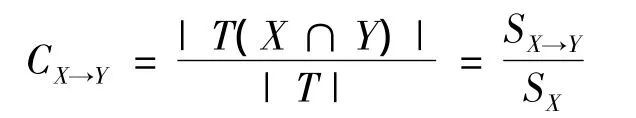
也就是說,包含項目X的事物中可能同時包含項目Y,也可能不包含。規則置信度反映的是其包含項目Y的概率,是規則支持度與前項支持度的比。
1.4 關聯規則的實用性
通常情況下,如果規則置信度和支持度大于用戶指定的最小置信度和支持度,那么這個規則就是一條有效規則。事實上,有效規則在實際應用中并不一定實用,也就是說,有效規則未必具有正確的指導意義。
例如,在豬場數據中,通過關聯規則分析發現,斷奶日齡在20~25 d之間的仔豬,出欄體重40%未達到一級標準,即:斷奶日齡(20~25 d)→體重(未到一級標準)(S=40%,C=40%)。如果用戶指定的最小置信度和支持度為20%,表面上看該規則是一條理想規則,但是進一步計算發現,此時出欄中體重未達到一級標準的豬也為40%,即后項支持度為40%,也就是說,體重未達到一級標準的仔豬(斷奶日齡20~25 d)比例與所有未達到一級標準的豬的比例一致,此時所反映的只是一種前后項無關聯下的隨機性關聯,并沒有提供更有意義的科學指導,因此不具有實用性。
因此,規則置信度和支持度只能分析出一條規則的有效性,但是并不能衡量是否具有實用性和實際意義。在上述例子中,豬場養殖戶更希望通過關聯規則分析出具有實際意義的規則,以提高其養殖效益。
1.5 基于數學模型的實用性測度指標
1)信譽度(prestige)。信譽度是置信度和后項支持度的比,其數學表達式為
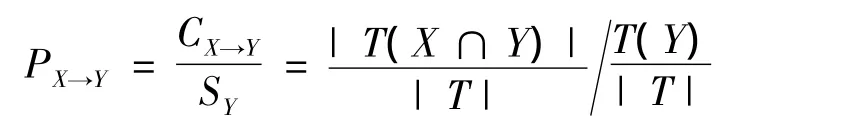
信譽度反映了項目X的出現對項目Y(研究項)出現的影響程度,一般大于1才有意義,意味著X的出現對Y的出現有促進作用,因此,信譽度越高越好。對于上述提出的問題,信譽度為40%/40%=1,雖然該規則是有效的,但并沒有意義。
2)置信差(confidence different)。置信差與信譽度類似,也利用了后項支持度,是置信度與后項支持度的絕對差,數學表示為
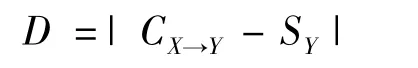
例如,后項支持度是80%,即80%的豬出欄體重達到一級標準,如果置信度是82%,即通過學習知道仔豬斷奶日齡在20~25 d的個體豬,出欄體重達到一級標準的概率是82%,那么置信差為2%,應該說此關聯規則提供的信息量并不高。置信差應高于某個最小值,所得到的關聯規則才有意義。
3)置信率(confidence ratio)。置信率的數學定義為
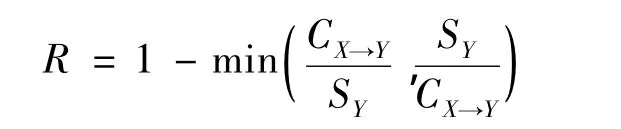
其中括號中的第1項為信譽度,第2項為信譽度的倒數。由于信譽度越大越好,所以R也是越大越好。
4)正態卡方(normalized chi-square)。正態卡方從分析前項與后項的統計相關性角度評價規則的有效性,其數學定義為
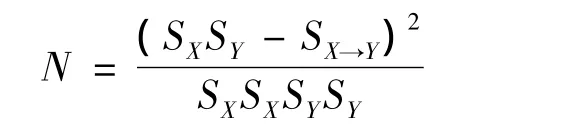
不難得出:當項目X和項目Y獨立時,SXSY=SX→Y,N為0;當項目X和項目Y完全相關時,N為1。因此N越接近于1說明前項和后項的關聯性越強。
5)信息差(information difference)。信息差是在交互熵的基礎上計算出來的。交互熵(cross entropy)也稱為相對熵,是Shannon的信息論中非常重要的理論,主要用于度量2個概率分布間的差異性。
設 P=(p1,p2,…,pn)和 Q=(q1,q2,…,qn)是2個離散型隨機變量的概率分布向量,則H(P|Q)稱為P對Q的交互熵,其數學定義為
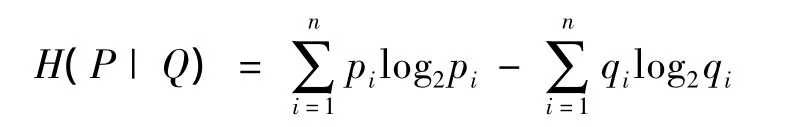
其中:第1項可替換為X條件下Y的分布;第2項可替換為X獨立于Y情況的期望分布。
仍以豬場豬仔斷奶日齡和出欄體重為例來說明信息差的含義,具體數據見表1。
表1中:每個單元格的第1個數據為X和Y獨立條件下的期望概率分布,第2個數據為實際概率分布;r為關聯規則的置信度;a為前項支持度;c為后項支持度。現計算這2個概率分布的差異。信息差定義的數學公式為
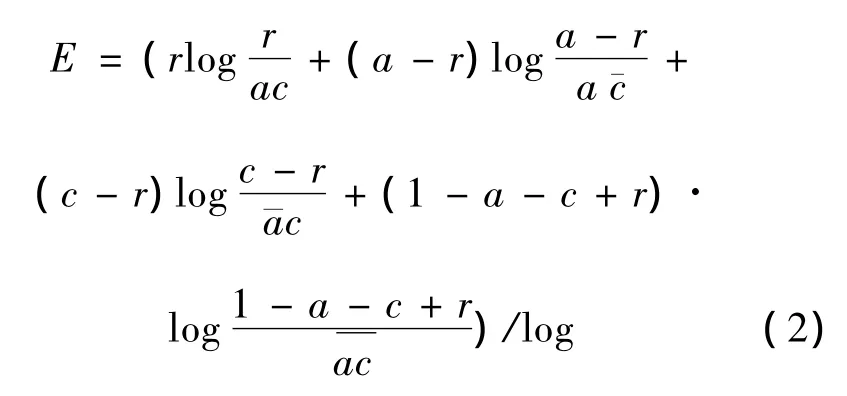
可見,信息差越大說明實際前后項的關聯性越強。同樣,信息差應高于某個最小值,所得到的關聯規則才有意義。下面,就以個體豬養殖問題出發,通過上述各指標的分析,得出有實際應用價值的關聯規則,以提高養殖效益。

表1 斷奶日齡和出欄體重達標的列聯表
2 實例
2.1 數據源
本研究所用數據來自豬場自動喂食系統所采集到的數據(如圖1)。由于數據較多,圖1中只列出部分數據,包括:個體豬生理數據,如個體豬類型、成熟體體重、當前體重、飼喂次數、生理階段等;個體豬飼養效果分析;生理營養指標分析診斷結果,如采食量;飼料類型與料肉比分析結果;瘦肉生長率等。
圖1 豬場自動喂食系統測定性能報告
2.2 數據處理
1)數據預處理。如果僅分析個體豬瘦肉率或高或低的關聯關系,可刪去個體豬個體信息數據庫中的一些數據,如個體豬編號、耳號、總采食次數、總采食時間等噪聲數據,結果如表2所示。
2)數據離散化處理。表2中的數據包括分類屬性數據和連續屬性數據,其中:分類屬性數據有品種類型、生理階段、能量攝入水平;連續屬性數據有當前體重、日增重量、日采食量、瘦肉增長率。在挖掘數據的關聯規則之前,首先將分類屬性和連續屬性的數據轉換成“項”,即對每個數據進行識別編號。如對某列分類屬性的一個數據,如果其同列前面有相同的數據,則取該數據的編號;如與其同列前面的數據都不同,則取同列中與其最鄰近數據的編號加1為其編號。對連續屬性數據的變換可以使用基于離散化的方法,由用戶填入對連續屬性數據進行分類的跨度,系統將每個連續數據按分類的跨度轉換成一個整數,對其進行編號的方法同分類屬性數據。按照以上對分類屬性數據和連續屬性數據的處理方法將數據編號為i,即將每個數據轉換成一個數據項Ii,并存入數據庫中。
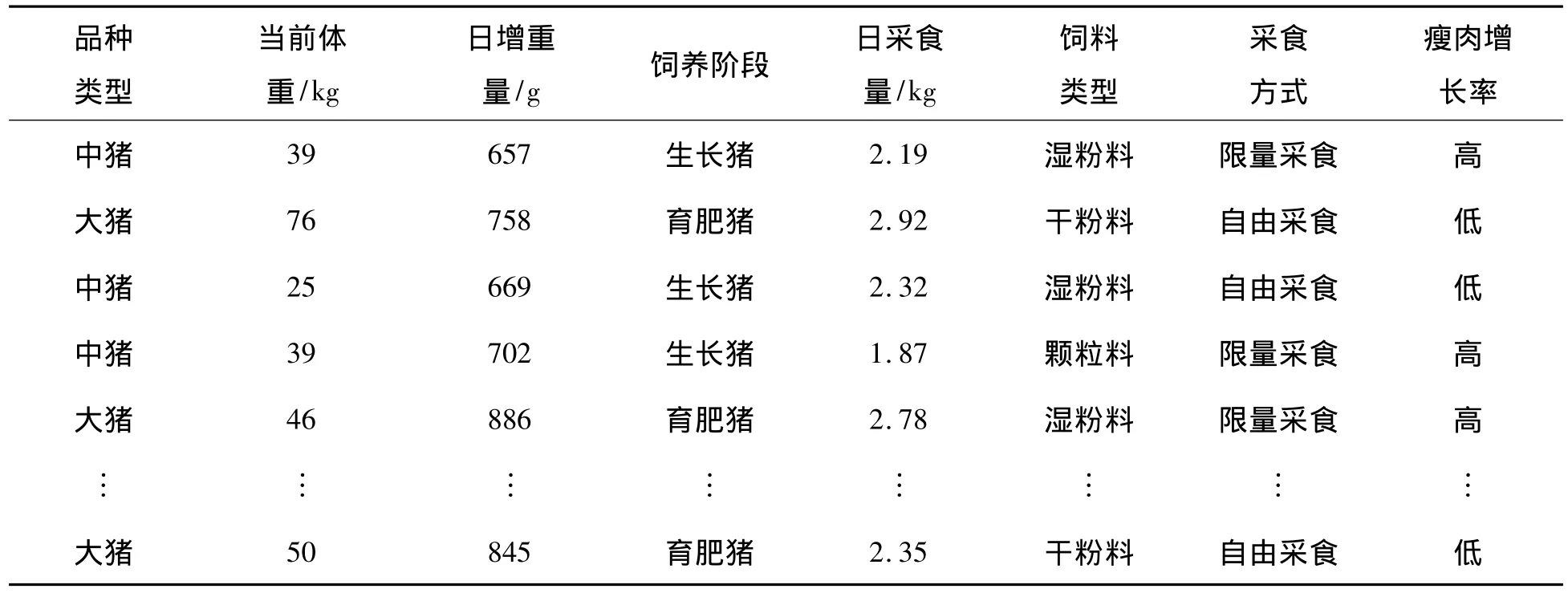
表2 個體豬個體信息數據的預處理
3)數據分析。①利用Apriori算法將表中的數據進行運算,取最小支持度為20%,掃描所有事物數據,找出頻繁項集。② 由頻繁k-項集的非空子集產生規則,若滿足最小可信度,則稱此規則為關聯規則。對結果數據進行關聯分析,輸入置信度和支持度參數,設支持度參數為0.2,置信度參數為0.7。該組參數可以靈活變動,但取值過大,會丟掉有意義的關聯規則,取值太小,則會將一些無意義的關聯規則包含進來。設定一組參數,可得出該組數據中的關聯規則。
3 結果分析
使用Apriori算法對經過預處理的豬場數據進行關聯分析,得出以下關聯規則。
由頻繁3-項集產生的關聯規則:
①{飼料類型:濕粉料}∧{采食方式:限量采食}?{瘦肉率:高},confidence=80%。說明該豬場采用限量飼喂以及濕粉料的個體豬的瘦肉率高的可信度為80%。
② {飼料類型:濕粉料}∧{瘦肉率:高}?{采食方式:限量采食},confidence=80%。說明該豬場采用濕粉料且瘦肉率高的個體豬是采用限量飼喂方式,可信度為80%。
③{品種類型:中豬}∧{當前體重:35~75 kg}?{飼養階段:生長期},congfidence=85%。說明當前體重為35~75 kg的中豬,其飼養階段為生長期的可信度為85%。
④ {品種類型:大豬}∧{當前體重:75~100 kg}?{飼養階段:育肥期},congfidence=85%。說明當前體重為75~100 kg的大豬,其飼養階段為育肥期的可信度為85%。
⑤ {日增重:600~785 g}∧{飼養階段:生長期}?{品種類型:中豬},congfidence=82%。說明日增重在600~785 g并處于生長期的豬類型為中豬,其可信度為82%。
由頻繁2-項集產生的關聯規則:
① {當前體重:35~75 kg}?{品種類型:中豬},congfidence=83%。說明當前體重為35~75 kg的個體豬類型為中豬,其可信度為83%。
② {日增重:600~785 g}?{飼養階段:生長期},confidence=85%。說明日增重為600~785 g的個體豬處于生長期的飼養階段,其可信度為85%。
③{采食方式:自由采食}?{瘦肉率:低},confidence=70%。說明采食方式為自由采食的個體豬瘦肉率比較低,其可信度為70%。
④{采食方式:限量采食}?{瘦肉率:高},confidence=70%。說明采食方式為限量采食的個體豬瘦肉率比較高,其可信度為70%。
⑤ {飼料類型:濕粉料}?{瘦肉率:高},confidence=72%。說明飼料類型為濕粉料的個體豬瘦肉率高,其可信度為72%。
⑥ {瘦肉率:高}?{飼料類型:濕粉料},confidence=76%。說明瘦肉率高的個體豬采用的飼料類型為濕粉料,其可信度為76%。
通過Apriori算法得出上述關聯規則,但是,并不是所有得出的規則都是有意義并且令人信服的,因此,運用基于數學模型的實用性測度指標對上述規則進行驗證,找出其中對于豬場有效、并對養豬業有實際應用意義的規則。
例如:根據頻繁2-項集得出的關聯規則①,利用實用性測度指標中的信譽度來研究其前項的出現對后項的出現是否有促進作用。計算發現,該豬場有80%的個體豬類型為中豬,即后項支持度為80%,根據其數學定義,計算其信譽度為:70%/80% <1。由信譽度的概念可知,一般計算結果大于1才有意義。此時,該結果意味著雖然此規則是有效的,但是并沒有意義。
同理,依次對推導出的每一個關聯規則進行數學模型的判定,得出以下結論:
頻繁3-項集:
①{飼料類型:濕粉料}∧{采食方式:限量采食}?{瘦肉率:高},confidence=80%。
② {飼料類型:濕粉料}∧{瘦肉率:高}?{采食方式:限量采食},confidence=80%。
頻繁2-項集:
①{采食方式:自由采食}?{瘦肉率:低},confidence=70%。
②{采食方式:限量采食}?{瘦肉率:高},confidence=70%。
③ {飼料類型:濕粉料}?{瘦肉率:高},confidence=72%。
④ {瘦肉率:高}?{飼料類型:濕粉料},confidence=76%。
4 討論
豬的采食和飼喂方式對豬的生產性能有著明顯影響,選用合適的飼喂料類型和飼喂方式將明顯增加個體豬瘦肉增長率,提高養豬業的經濟效益。
該豬場飼喂濕粉料的限量采食的個體豬瘦肉率較高的可信度為80%;瘦肉率高的飼喂濕粉料的個體豬,采食方式為限量采食,其可信度也為80%。該分析結果提示,飼喂濕粉料的個體豬,其瘦肉率較高的可能性較大,表明該豬群由于采食方式的不同,導致個體豬可能由于自由采食過多,降低其生產性能,故應注意調整飼喂方式或改飼喂濕粉料。
使用關聯規則挖掘算法對豬場記錄數據進行相關性分析是一種有效應用。挖掘所得的規則模式通過數學模型進行有效性和實用性的測定,對豬場養殖業具有指導意思。本文只對一個簡單的個體豬采食數據庫進行實驗性測試,但該方法同樣適合于其他豬場的相關數據分析。
[1]韓家煒.數據挖掘:概念與技術[M].北京:機械工業出版社,2001:132-161.
[2]Jie Dong,Min Han.BitTableFI:An efficient mining frequent itemsets algorithm[J].Knowledge-Based Systems,2007,20:329 -335.
[3]薛薇,陳歡歌.Clementine數據挖掘方法及應用[M].北京:電子工業出版社,2010:242-251.
[4]廖芹,郝志峰.數據挖掘與數學建模[M].北京:國防工業出版社,2010:188-221.
[5]張云洋,袁源.關聯規則挖掘研究[J].計算機時代,2009(7):6-8.
[6]文拯,梁建武,陳英.關聯規則算法的研究[J].計算機技術與發展,2009,19(5):57 -58.
[7]蔣雨,劉宗慧.飼料加工方式對豬飼料營養價值和生產性能的影響[J].飼料與營養,2010(5):7-9.
[8]李云峰,陳建文,程代杰.關聯規則挖掘的研究及對Apriori算法的改進[J].計算機工程與科學,2002,24(6):65-68.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
當代陜西(2019年15期)2019-09-02 01:52:00
幸福(2018年33期)2018-12-05 05:22:42
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
