基于GPU的視頻轉碼技術研究
2012-06-06 08:14:00宋建新
電視技術 2012年1期
黃 興,宋建新
(南京郵電大學 圖像處理與圖像通信實驗室,江蘇 南京 210003)
隨著多種視頻壓縮標準的廣泛應用,以及接收終端和內容表現形式的多樣化,不同系統和網絡之間的交互則越發重要。在這種情況下,需要對已經編碼的視頻數據根據實際的應用需求進行相應的轉換。最新提出的H.264/AVC標準在圖像質量和壓縮率方面都有了很大提高,該標準在視頻壓縮和網絡傳輸方面具有廣泛的應用。而MPEG-2是當前數字電視和DVD采用的壓縮標準,因此本文所研究的從MPEG-2到H.264的視頻轉換極具研究價值。然而,視頻轉碼是個復雜的過程,它需要對已經壓縮過的視頻流進行解碼然后經過處理轉換成滿足信道傳輸特性和解碼終端要求的目標碼流。視頻轉碼密集的運算量使得 CPU 承受著巨大的壓力[1-2]。
近年來,低成本、高性能且可編程的圖形處理器(GPU)不斷推出并普及,使得GPU被越來越多地用在通用計算上,人們意識到可以將一些運算量巨大的工作通過GPU來完成。本文根據視頻轉碼的要求和GPU的運算特點,提出了一種利用GPU強大的并行計算能力來幫助視頻轉碼的方法,該方法將視頻轉碼過程中耗時最多、最復雜的運動估計和模式選擇轉移到GPU上并行執行。在開發GPU并行計算能力時,該方法采用NVIDIA公司的CUDA(統一計算設備架構)計算平臺,實現了在GPU上執行的并行幀間預測,有效地提高了視頻轉碼的速度和效率[3-4]。
1 CUDA計算模型
CUDA是NVIDIA公司推出的開發圖形處理器通用計算能力(GPGPU)并行計算模型。近年來計算機顯卡運算單元的速度越來越快,在某些應用方面甚至已經大幅超越CPU,基于GPU的通用計算已成為一個新的研究領域,它主要研究在圖形處理的范圍之外如何利用GPU來進行更為廣泛的應用計算。CUDA計算平臺以C語言為基礎,它使開發者無需學習特定的顯示芯片的指令或其他3D API就可以寫出在圖形處理器上執行的程序,為開發GPU的通用計算能力提供了便捷的開發研究平臺。
1.1 CUDA硬件模型
CUDA模型的計算核心由流處理器SP(Stream Multiprocessor)組成,SP是由GPU中的頂點渲染器和像素渲染器組成的統一計算單元。每8個SP組成1個流多處理器SM(Streaming Multi-processor),每個SM含有4種不同的片上內存:本地寄存器、共享內存(shared memory)、只讀常量存儲器(constant cache)和紋理內存(texture memo-ry)。而且每個SM都是基于 SIMT(Single Instruction,Multiple Thread,單指令多線程)的指令架構,用相同的指令執行不同的線程。雖然SM之間不能直接交換數據,但每個SM都可以讀取和修改設備內存(Device Memory),所以SM之間可以通過設備內存來交換數據。但由于設備內存屬于外部存儲器,并且沒有緩沖,以致于讀取設備內存的速度延遲比片上內存大,因此在程序設計上要盡量避免從設備內存交換數據。另外,SM線程之間的同步是通過每個SM內的SP執行同步函數來實現。
1.2 CUDA線程執行模型
在進行CUDA并行程序設計時,可以將GPU看作真正并行執行很多個線程的計算設備,它作為CPU的協處理器(Co-processor)而運作。在CPU上執行的程序稱為Host程序,而在GPU上執行的程序稱為Device程序或Kernel程序。一般情況下,GPU與CPU協同工作,CPU負責進行邏輯性強的事務處理和串行計算,而GPU則專注于執行高度線程化的并行處理任務。通常,Host端程序會將數據準備好后復制到顯卡內存中,由GPU執行完Kernel程序后,再由Host端程序將所需的結果從顯卡內存中取回。數據在Host端和Device端傳輸使用高性能直接內存訪問(DMA)引擎。
Kernel執行的最小單位是線程(Thread),若干個線程組成線程塊(Block),1個線程塊所包含的線程數目是有限的,本文用的GT240M中1個線程塊最多可以容納512個線程。1個線程塊的所有線程都在1個SM(Streaming Multiprocessor)上執行,因此,同1個線程塊中的線程可以通過共享內存來相互共享數據。在1個SM中處于執行狀態的線程塊稱為活動塊(Active),每個活動塊都劃分到被稱為線程束(Warp)的線程組中,其中每個Warp包含相同數量的線程,一般為32個,其通過SIMT的方式由SM執行,多個Warp分時復用SM。每個線程都有唯一的線程ID(Thread ID)作為標識,同樣每個線程塊也有唯一的ID(Block ID),它們都處于全局狀態供程序使用。CUDA線程塊模型結構如圖1所示,若干個線程組成線程塊(Block),數個線程塊再組成1個網格(Grid),具有相同維度和大小的塊可以分批組合到1個塊網格中。這樣,單個內核可以啟動的線程總數就將變得很大,大大提高了并行計算的能力[5]。
2 基于GPU的MPEG-2到H.264視頻轉碼方法
2.1 視頻轉碼架構
由于本文的重點是研究利用GPU的參與來加速視頻轉碼,MPEG-2到H.264視頻轉碼只完成格式間的轉換,并未涉及分辨力的轉換和目標碼率的控制,因此轉碼器的框架采用級聯式的像素域轉碼結構[6]。
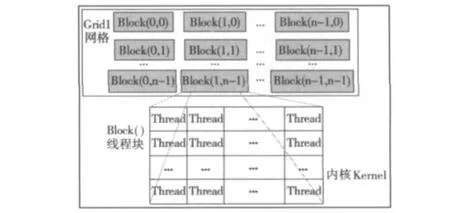
圖1 CUDA線程塊模型結構圖
在從MPEG-2到H.264的轉碼過程中,由于解碼過程相對簡單,大約只占10%的運算量,故解碼過程仍由CPU來完成。而計算量較大的步驟如H.264編碼過程中的運動估計和模式選擇,占據著轉碼過程絕大部分的計算復雜度,所以在設計利用GPU來參與轉碼的方法時,首先考慮將運動估計和模式選擇的過程轉移到GPU上來加速實現。其他步驟諸如量化和反量化、VLC和VLD、DCT和IDCT仍然在CPU上完成。
整個轉碼過程采用級聯式的像素域轉碼結構,轉碼框架圖如圖2所示。首先在對MPEG-2視頻流經過熵解碼、反量化、IDCT和運動補償將其解碼到像素域,然后GPU執行CUDA內核函數,完成并行運動估計和初步的模式選擇,并將搜索得到的運動矢量和模式選擇信息從顯存上傳送給主機,主機對收到的GPU的運動矢量進行精細化搜索并完成剩余的編碼步驟[7]。
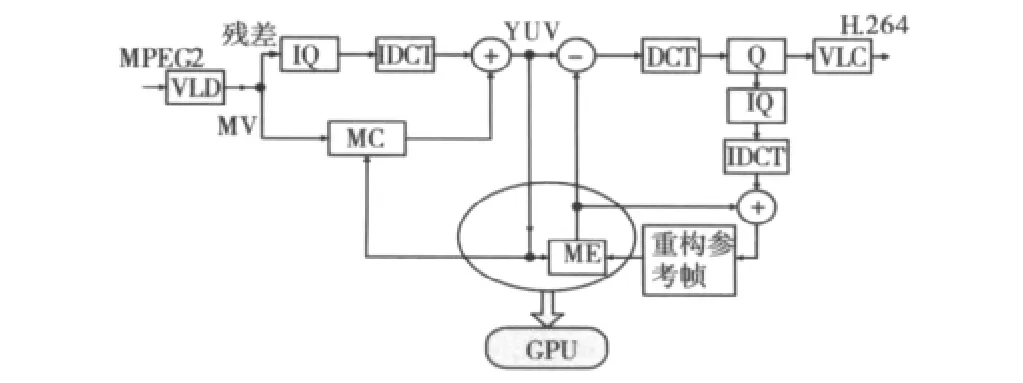
圖2 MPEG-2到H.264的視頻轉碼框架圖
2.2 并行運動估計
2.2.1 算法介紹
幀間預測是為了消除視頻序列之間的時間冗余而采用的時域壓縮方法。在H.264標準中,幀間預測采用可變塊的多種模式的運動估計來實現,比如亮度塊的模式可分為P16×16,P16×8,P8×16和 P8×8這4種,而每個P8×8塊又有4種子宏塊模式:P8×4,P4×8和P4×4。除了這7種模式之外,H.264的幀間預測在P幀中還支持SKIP編碼模式和I4×4,I16×16這2種幀內編碼模式。SKIP模式是針對P16×16的宏塊在運動矢量為(0,0)時采用的模式。
目前雖然有不少學者和研究人員提出了很多有效的快速運動估計算法,但這些算法并不適合于CUDA并行環境。所以本文設計了一種在CUDA并行環境中運行的并行運動估計算法,這里的并行通過兩方面來實現:一是線程塊中的線程各自獨立的計算搜索位置的SAD(Sum of Absolute Difference);二是多個線程塊并發的完成16×16塊的運動搜索。該算法在GPU上采用全搜索來實現整數像素的運動搜索,然后在CPU上實行1/4像素的精細化[8]。
據統計,在P幀編碼中,P16×16,P16×8,P8×16和P8×8這4種模式占7種模式的80%以上,所以在設計算法時考慮到算法的改進效率,只將P16×16,P16×8,P8×16和P8×8這4種模式放在GPU上執行,而將其余3種模式仍留在CPU上執行。
由于GPU上的運動估計是宏塊級并行,所以該算法在運動搜索之前要將所需的參考幀和當前待編碼幀一次傳送到GPU顯存,經過GPU運算得到4種模式的代價之后,再選擇最佳模式并計算其運動矢量。當轉碼器的編碼端收到GPU回傳的運動矢量時,對其進行簡單的精細化后即可利用其計算殘差進行后續編碼環節。算法流程如圖3所示,具體實現步驟見2.2.2節所述[9]。
2.2.2 并行運動估計算法實現步驟
為了便于并行程序的設計和執行,該并行運動估計算法的并行粒度為宏塊級,將CUDA線程塊的大小設計為16×16=256,正好與1個宏塊(MB)的大小相對應。該算法在GPU上進行整像素的全搜索和最佳宏塊模式選擇,將分數像素插值和1/4像素精細化搜索的過程放在GPU上進行,主要步驟為:
1)讀入當前的參考幀,并對其進行邊界擴展,以便于全搜索。邊界擴展是在原參考幀圖像的四周分別擴展32行和32列,擴展的像素值和邊界處的像素值相等。
2)在顯存上開辟全局內存,用于存儲當前編碼幀和經過邊界擴展之后的參考幀。
3)將當前待編碼的幀和經過邊界擴展之后的參考幀從主機(CPU)拷貝到設備端(顯存),并綁定到顯存的紋理內存(Texture Memory)。
4)根據轉碼視頻的分辨力,在GPU上合理劃分線程塊和Grid,設置好傳入GPU的參數和分配的Block數目以及Thread數目。這里初步將線程塊的大小定為16×16=256,設定搜索范圍的寬度為16,則線程塊的數目即Grid網格的大小恰好為1幀中的宏塊數。
5)在每個Block內部分配每個Thread都可以訪問的共享內存。并且計算線程塊中每1個8×8子塊對應于搜索范圍內每個位置的SAD。
6)利用上一步驟中計算得到的SAD值,根據子塊位置的對應關系,以4個8×8塊SAD為基礎,直接求和得出P16×8,P8×16,P16×16等塊的 SAD。然后分別以這些塊的SAD作為根據,選擇最小SAD對應的位置為運動矢量,并記下其最小的SAD值作為該子塊模式的代價。
7)根據上一步驟中得到的各個模式的代價值,選擇最小的作為最終模式,并將該模式對應的運動矢量寫入到顯存的全局內存并回傳至主機。
2.2.3 SAD的計算
首先計算8×8塊的SAD。8×8塊SAD的計算由1個線程塊(Block)中的256個線程并行完成,每個線程單獨計算1個對應參考位置的SAD值,如圖4所示。圖中,坐標頂點(0,0)處為參考幀搜索范圍的頂點,由線程塊中的Thread 0來完成SAD值計算,依次類推,最后一個搜索點為(15,15),由線程塊中的Thread 255來計算SAD值。線程塊中的所有線程各自獨立完成計算,互不干擾和依賴。計算完成之后它們通過同步函數進入同步點掛起。
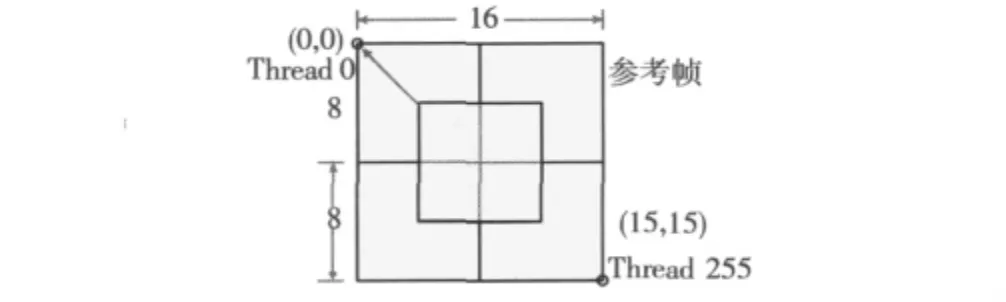
圖4 8×8塊SAD計算
當P8×8子塊的SAD計算出來之后,其他模式比如P16×8,P8×16和P16×16的SAD都可以由相對應位置的8×8子塊的SAD值相加得到,如圖5所示。P16×8塊的SAD分別由Ⅰ、Ⅱ塊和Ⅲ、Ⅳ塊的SAD之和組成;P8×16塊的SAD則分別由Ⅰ、Ⅲ塊和Ⅱ、Ⅳ塊的SAD之和組成;而P16×16塊的SAD則由4個8×8子塊之和共同組成[10]。
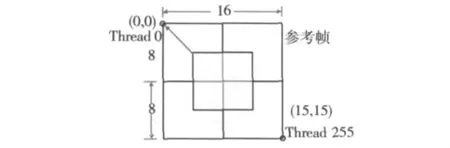
圖5 其它模式的SAD推算
2.3 模式選擇
對于模式選擇,由于在設計整個轉碼系統時只考慮將幀間預測轉移到GPU上完成,而幀內編碼仍然在CPU上執行,所以這里將模式選擇分兩步完成。第一步是在GPU上完成,負責完成幀間宏塊如P16×16、P16×8等塊的模式選擇;第二步是在CPU上完成的,此步驟在分數像素精細化之后,主要負責將幀間模式選擇的結果再與幀內模式如I16×16、14×4比較,選擇代價最小的模式作為最終模式。模式選擇流程圖如圖6所示,其中第一步比較在GPU上完成,后面兩個步驟則在CPU上完成。
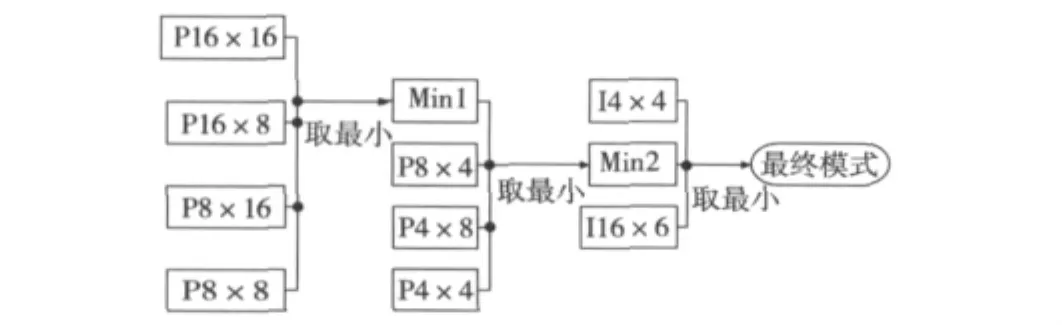
圖6 模式選擇過程
3 測試結果
為了驗證該方法對視頻轉碼的加速效果,本文對基于GPU的轉碼方法和傳統的CPU轉碼方法分別進行性能測試。實驗環境為Intel Core 2 Duo T6600 2.2G CPU+NVIDIA Geforce GTX280M。使用的測試視頻為CIF格式的MPEG-2視頻源mother-daughter.m2v和QCIF格式的視頻源foreman.m2v,測試的轉碼視頻長度均為30幀,測試結果如表1所示,該表記錄的是兩種轉碼方法分別轉碼30幀MPEG-2視頻所需的時間。
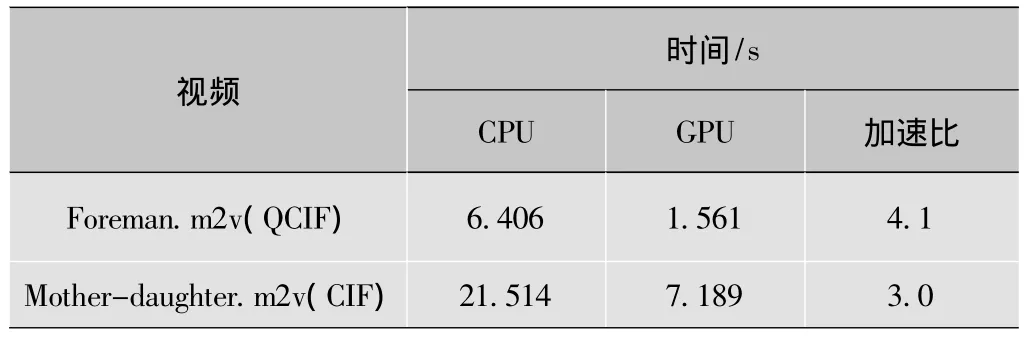
表1 算法性能對比
由表1可以看出,采用GPU來幫助視頻轉碼的方法比傳統的CPU轉碼的方法在速度上提高了3~4倍。實驗證明,利用GPU的通用計算能力來加快視頻處理的設計思路是可行的。
4 小結
本文提出了使用GPU來加速視頻轉碼的算法,并通過實驗驗證了基于CUDA的視頻轉碼算法的可行性,且取得了較好的效果。在此基礎上可以在以下兩個方面進行深入研究:一是考慮將更多的模塊轉移到GPU上實現;二是設計另外一種框架,讓GPU在執行幀間預測的同時,CPU也執行量化編碼模塊而不是被掛起。這樣可以進一步改善轉碼器的性能。
[1] AHMAD I,WEI Xiaohui,SUN Yu,et al.Video transcoding:an overview of various techniques and research issues[J].IEEE Transactions on Multimedia,2005,7(5):793-804.
[2]程愷英,王宏遠,樊淳標.數字視頻轉碼技術綜述[J].電視技術,2005,29(4):13-16.
[3]NVIDIA Corporation.NVIDIA CUDA compute unified device architectureprogramming guide version 3.2[EB/OL].[2010-08-10].http://www.nvidia.cn.
[4]NVIDIA Corporation.NVIDIA CUDA compute unified device architecturebest practices guide version 3.2[EB/OL].[2010-08-10].http://www.nvidia.cn.
[5]張舒,褚艷利.GPU高性能運算之CUDA[M].北京:中國水利水電出版社,2009.
[6]KALVA H,PETLJANSKI B,FURHT B.Complexity reduction tools for MPEG-2 to H.264 video transcoding[J].WSEAS Transactions on Information Science & Applications,2005,2(2):295-300.
[7]LIU Y,TANG C,CHIEN S.Coding mode analysis of MPEG-2 to H.264/AVC transcoding for digital TV applications[C]//Proc.ISCAS 2007.[S.l.]:IEEE Press,2007:1995-1998.
[8]CHEN W,HANG H.H.264/AVC motion estimation implementation on compute unified device archetecture(CUDA)[C]//Proc.ICME 2008.[S.l.]:IEEE Press,2008,17:697-700.
[9]RODRIGUEZ R,MARTINEZ J,FERNANDEZ E G,et al.Accelerating H.264 inter prediction in a GPU by using CUDA[C]//Proc.ICCE 2010.[S.l.]:IEEE Press,2010:463-464.
[10]CHEUNG N,FAN X,AU O,et al.Video coding on multicore graphics processors[J].IEEE Signal Processing Magazine,2010,27(2):79-89.
