基于RGB三通道分離的運動目標檢測方法
2012-06-25 03:31:26沈盼盼伍瑞卿
電視技術 2012年3期
沈盼盼,樊 豐,伍瑞卿
(電子科技大學,四川 成都 611731)
1 背景介紹
對視頻序列中運動目標的提取是計算機視覺和視頻分析的基本部分,在視頻監控[1]、體育運動分析[2]、人機交互[3]、輔助臨床醫療診斷[4]等領域有廣泛的應用前景。基于背景差分的運動目標檢測是最常用的方法[5],該方法中背景的獲取和更新是關鍵。近年來,人們對如何構建背景進行了大量的研究,例如高斯模型的法、中值法、時間平均法等,大多數都是針對像素建立的。
本文從直接計算背景像素值的角度研究。因為時間平均法容易將前景運動目標混入到背景圖像中,導致提取的背景圖像出現混影。自適應平滑算法利用通過時間段內像素點的不變性建立背景模型,但是如果運動目標運動緩慢或者暫時靜止時候會將前景像素值誤判為背景像素值,產生錯誤結果。基于像素在時間軸上變化提出的中值法,檢測過程中可能會因光照的變化將噪聲點像素值誤判為背景。針對這些問題,本文根據運動目標像素值的變換比背景的變化快[6]的思想,采用幀間差分法和中值法相結合構造背景模型,并且利用幀差信息對背景實時更新。采用對RGB空間的三通道分離的運動目標檢測方法,采用Osto法[7]獲取閾值來提取運動區域。本文算法在運動目標存在的情況下也能建立較完整的背景模型,構建的背景可適應光照變化和微小物體的抖動,克服了在對目標和背景灰度相近的情況下難以提取準確的目標對象的問題,另外,背景更新是針對每個像素點更新,大大減少了運算時間。
2 背景模型的建立
首先,利用中值法獲取背景BM;然后,利用相鄰幀間差分的變化獲取背景BS;考慮到光照等影響,中值法難免會將噪聲點誤判為背景,所以最后將得到的BM和BS進行加權,得到初始背景模型。圖1為初始背景模型的獲取流程圖。
算法步驟為:
1)從N幀視頻呢序列中獲取n幀圖像,記作(f1,f2,…,fn)。
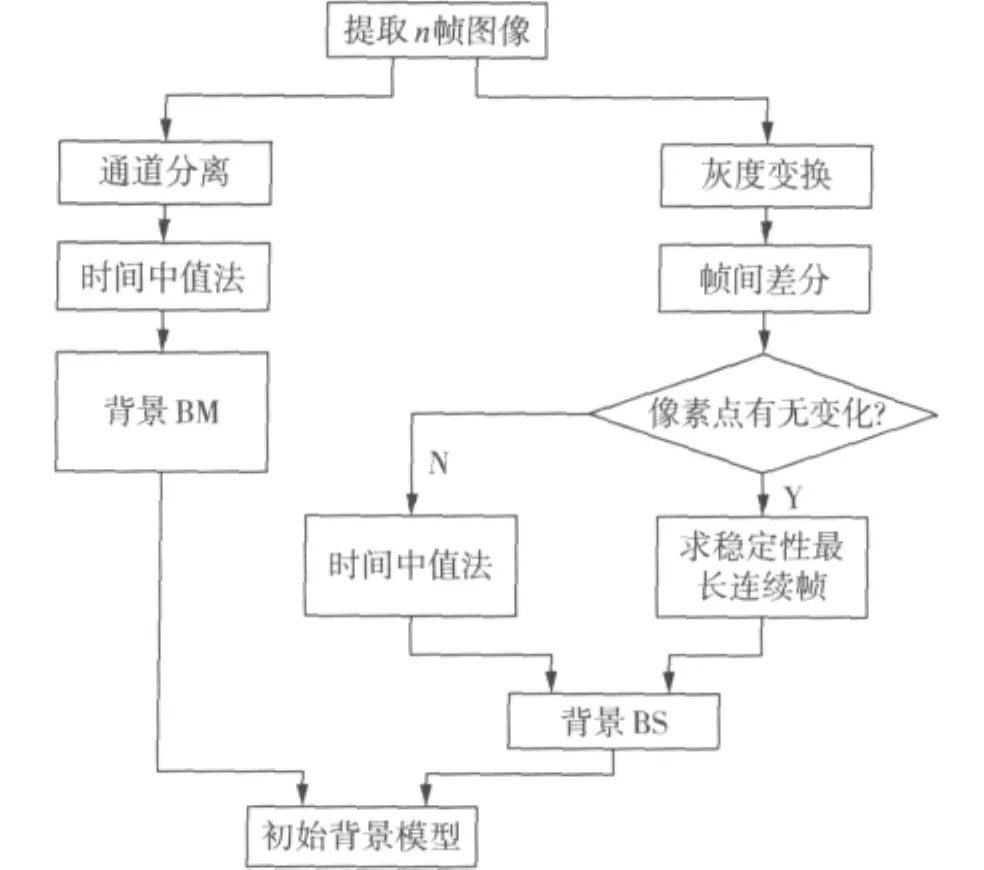
圖1 背景模型獲取流程圖
4)對n幀圖像進行灰度變換,變換后的灰度圖像序列記為 (g1,g2,…,gn)。
5)對n幀灰度圖像(g1,g2,…,gn)進行幀間差分,對差分后的每個灰度圖像進行二值化,閾值的選取由Otsu 法確定,得到一個二值圖像序列 D2(i,j),D3(i,j),…,Dn(i,j)。
6)在二值圖像序列中,每個像素點的值可看作是由0和1組成的一維數組,找出其一維數組中連續性最長的0 的區間,例如點 (i,j)的像素點變化情況為[0,1,0,0,1,0,0,0,1,1],可以看出最長的0 區間中有 3 個 0。求出這個區間中最中間的元素所在的列數,找出其對應的視頻序列號,如果是奇數個0就取最中間一列,對應視頻序列號為M,如果是偶數個0就取中間兩列,對應視頻序列號為M1和M2。
7)假設提取的最長0區間有m個0,則背景圖像BS的每個像素值計算公式如下

每個像素都進行處理,最后得到第二個背景模型BS。
8)考慮到兩種方法的優缺點,本文將獲取的兩個背景模型按照式(2)結合來作為初始背景模型B0
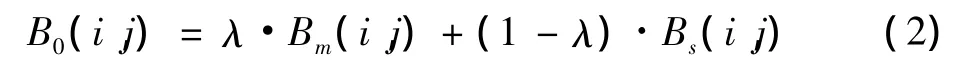
式中,λ在(0,1)的范圍內。
圖2和圖3顯示了對SampleVideo和highway分別利用時間均值法、文獻[4]的方法以及本文算法建立的背景模型。序列SampleVideo中λ取值為0.97,序列highway中λ取值為0.9。從圖中可以看出,用時間平均法獲取的背景模型會殘留前景部分的重影,尤其在運動目標速度較快的時候比較明顯。文獻[4]的方法在目標存在或者移動緩慢的情況下會將目標部分誤判為背景。而本文算法建立的背景效果較好。


3 背景模型的更新
取n幀視頻序列,由視頻序列每個圖像和初始化背景模型對比得到一個差異累計圖像。在差異累計圖像每個像素點設置一個計數器,序列圖像和初始化背景模型之間在某個像素點出現一次較小差異就令計數器加1,差異大小根據閾值Tf來判斷。當第k幀圖像與初始化背景模型相比較時,差異累計圖像可看作是隨時間變化的一個動態矩陣A(i,j,tk)。根據運動對象的像素值變化比背景像素值變化快的特點,按照如下方法更新背景:
設有 m 幀視頻序列 f1(i,j),f2(i,j),…,fm(i,j),差異累計矩陣為

式中:τ(i,j)記錄每個像素差異累計的次數,由二值圖像序列(g1,g2,…,gn)中每個像素點的最長0區間長度決定,因此每個像素點的τ值不同。假如當前的背景模型為Bk-1(i,j),則當累計至 τ(i,j)時,點 (i,j)處的背景像素值根據式(2)自動更新,而差異累計圖像中為0的像素點處背景像素值不變,公式為
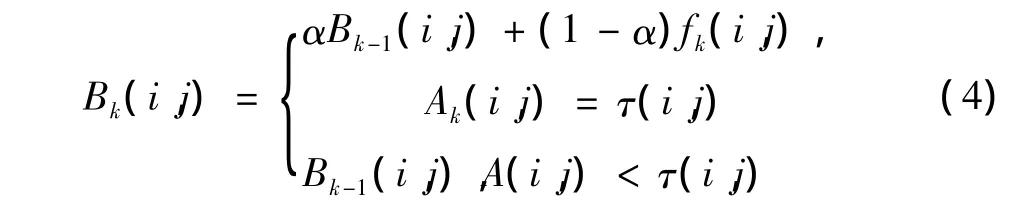
式中:α為更新率,取值在(0,1)區間。
4 運動目標的檢測
為了在閾值化時消除部分噪聲的影響,首先對背景差后的灰度圖像進行濾波處理,本文采用的中值濾波。fk為當前視頻圖像,Bk為當前背景圖像。本文采用Otsu法自動選取分割閾值T0,另外為了抑制光照突變的影響,增加一個動態閾值Ts。計算公式如下
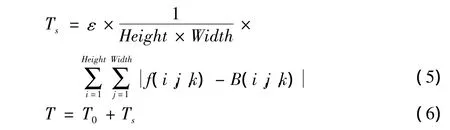
式中:T為選取的閾值,Ts體現了光照的整體變化,增加Ts能夠在閾值時候抑制光線的影響。ε為抑制系數,如果光照變化明顯則取較大值反之,取較小值。
閾值化后的二值圖像中,運動對象已經大致獲取,但是由于光照的突變或者噪聲的影響使得檢測到得前景中含有噪聲點、空洞、間隙等,需要進一步優化才能得到較準確的運動目標。本文首先采用形態學的開、閉操作來填充小的空洞間隙,消除小一些的噪聲點,然后對整個圖像進行連通性分析,將面積較小的區域去除,最后留下的即是運動區域。
5 陰影去除
背景圖像中,被陰影遮擋后的區域的灰度值將比原來減小,但是在色度變化不大的情況下可認為歸一化的顏色空間對陰影造成的像素點顏色、亮度變化不敏感,具有一定穩健性[8]。考慮到只用RGB空間會丟失像素值的亮度信息,因此,分別按照式(4)計算當前視頻圖像和當前背景圖像的歸一化顏色空間的r和g的值,計算當前視頻圖像和當前背景圖像的亮度值為

如果在 (r,g,I)空間的當前像素值為 (rk,gk,Ik),背景像素值為(rb,gb,Ib),則當前像素值同時滿足式(10)的3個條件時,即為陰影

最后將檢測出的陰影部分從提取出運動目標的二值圖像中清除,得到更加精確的目標對象。
6 實驗結果與分析
為了驗證本文算法的有效性,選取了2組視頻序列進行目標檢測,并將本文算法在灰度域進行試驗,與在RGB域的試驗結果進行比較。圖4顯示了SampleVideo在灰度域獲取的初始背景模型、目標檢測結果以及經過形態學處理后得出的目標區域的二值圖像。圖5顯示了SampleVideo在RGB空間獲取的初始背景模型、各個通道的目標檢測結果、3個通道相結合的檢測結果以及經過形態學處理后得出的目標區域二值圖像。


比較圖4和圖5可以看出,在目標灰度值和背景相近的情況下,在灰度域進行背景差分必然會丟失掉一些有用信息,本文將各個通道分離后分別進行目標檢測,然后取并集可以得到更完整的運動對象。
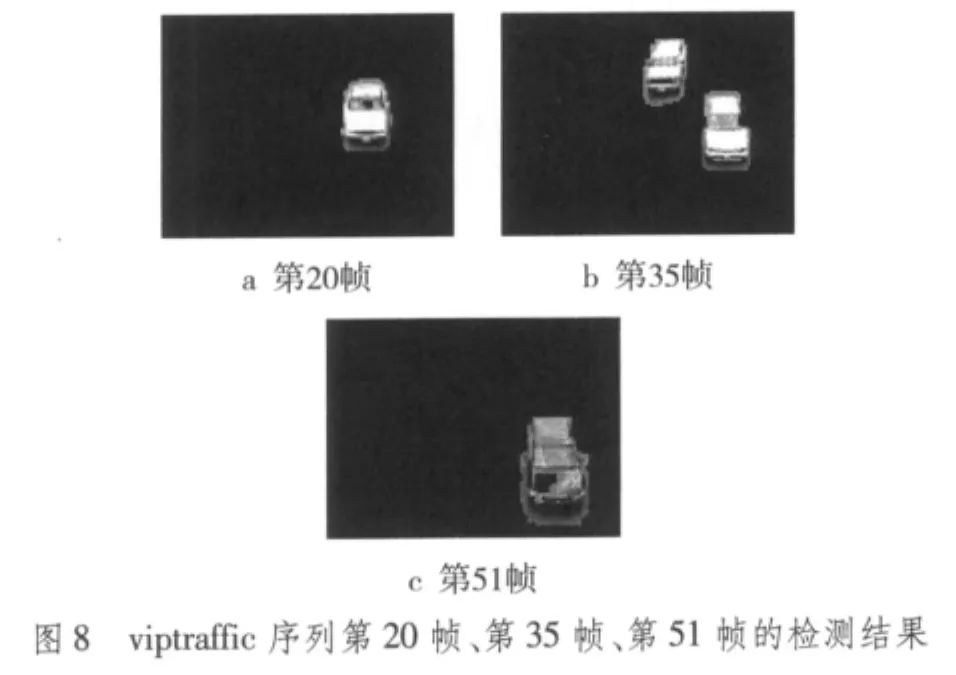
圖6是對SampleVideo序列第21幀、第30幀、第45幀的檢測結果,圖7是對hall的第15幀、第80幀、第100幀的檢測結果,圖8是對viptraffic的第20幀、第35幀、第51幀的檢測結果。


7 結論
本文主要對初始背景模型的獲取加以改進,采用三通道分離來檢測運動目標,實時性好,對目標和背景灰度相近的情況有較好的檢測結果。但是也存在一些不足,如果目標長時間停留或者做微小的運動,獲取的背景模型會摻雜較多目標區域,使得檢測結果不夠理想,有待進一步研究,結合其他方法進行改進。
[1]于忠校.視頻監控圖像的運動目標檢測方法綜述[J].電視技術,2008,32(5):72-76.
[2]JI Xiaofei,LIU Honghai.Advances in view-invariant human motion analysis:a review[J].IEEE Transaction on Systems,Man,and Cybernetics,Part C:Applications and Reviews,2010,40(1):13-24.
[3]FAI H,YAMAMOTO S.Bayesian online change point detection to improve transparency in human-machine interaction systems[C]//Proc.the 49th IEEE Conference on Decision and Control.[S.l.]:IEEE Press,2010:3572-3577.
[4]楊紅梅.基于人體運動跟蹤的遠程康復系統關鍵技術的研究[D].重慶:重慶郵電大學,2010.
[5]齊志才.自動化儀表[M].北京:中國林業出版社,2006.
[6]YANG T,LI S Z.Real-time and accurate segmentation of moving objects in dynamic scene[C]//Proc.the ACM 2nd International Workshop on Video Surveillance & Sensor Networks.[S.l.]:IEEE Press,2004:136-143.
[7]朱瑾瑜,劉海燕,黃淑梅.基于連通性檢測的視頻監控運動目標提取[J].電視技術,2007,31(10):78-80.
[8]毛曉波,謝曉芳,張曉林.消除運動物體陰影的最大色度差分檢測法[J].電子技術應用,2007,33(1):61-63.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車工程師(2021年12期)2022-01-17 02:29:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
當代陜西(2020年14期)2021-01-08 09:30:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
光學精密工程(2016年6期)2016-11-07 09:07:19
