基于Indri的檢索模型研究
2012-07-13 06:30:08王莉軍
電子設計工程 2012年24期
王莉軍
(渤海大學 遼寧 錦州 121013)
Indri是開源的信息檢索工程Lemur的一個子項目。Indri是一個完整的搜索引擎,支持各種不同格式文本的索引創建,提出了優秀的文檔檢索模型,支持結構化查詢語言,在研究和實際應用領域都有比較高的價值。Indri系統采用C++語言編寫,提供了方便的API供使用者調用,由于項目本身開源,對于開發者而言,也可以方便的對其進行二次開發。
1 Indri檢索模型
Indri結合了推理網絡模型 (Inference net)和語言模型(language modeling)的優點,提出了一套檢索模型,其利用推理網絡模型的優勢來支持比較復雜的結構化查詢(結構化通常指查詢語言中的用來表達檢索文檔中詞與詞之間聯系的operators),又利用語言模型及平滑技術對推理網絡中的一些節點進行有效的預估,從而使查詢得到比較好的效果[1]。這之前,單純的推理網絡模型節點的預估采用的是規格化的tf.idf(這個值與詞在文檔中出現的頻率稱正比,與包含該詞的文檔數成反比)權重,而單純的語言模型則無法支持結構化查詢。所以Indri檢索模型采用了兩種模型相結合的方式[2]。
推理網絡模型網絡圖如圖1所示,實際上是一個貝葉斯網絡(Bayesian networks)。貝葉斯網絡是一個有向,無環圖。
網絡中每個節點代表一個事件,有一個連續或者離散的結果集。每個非根節點存儲了一個條件概率表,這個條件概率表完全描述了與給定父節點的情況下該節點出現相關聯的結果集的概率。每個與根節點相關聯的結果集被指派了一個先驗概率。這樣在已知網絡圖,先驗概率,條件概率表和節點代表的事件之后,就可以通過網絡計算出檢索文檔中出現查詢的概率,并按照這個概率值的大小進行排序輸出。

圖1 推理網絡模型網絡圖Fig.1 Inference network network diagram
主要包含有以下幾類節點[3]:
1)文檔節點 D(Document Node);
2)平滑參數節點 alpha,beta(Smoothing parameter nodes);
3)模型節點 θ(Model nodes);
4)特征表示節點 r(Representation concept nodes);
5)查詢節點 q(Belief nodes);
6)信息需求節點 I(Information need node)。
文檔節點(Document Node):文檔節點是文檔表示的一個隨機值。Indri采用二進制特征向量集對文檔進行表示,而不是一般模型中單純的term序列,文檔的特征向量表示可以挖掘出更多的文本的信息,例如短語,是否是大寫字母詞等。文檔中每個term的位置被一個特征向量表示,向量中的元素表示特征的有無。如此一來可以將文檔看作一個多伯努利分布(Multiple-Bernoulli distribution)的抽樣。
舉一個文檔表示很簡單的例子,假設文檔是由5個詞組成的,則我們用下面12個特征組成的特征序列來表示文檔,如下[4],
Document:A B C A B
假設特征序列是[A B C AA AB AC BA BB BC CA CB CC]

平滑參數節點:是為模型節點提供平滑參數。
模型節點Model nodes(M):模型節點代表所謂的特征語言模型。在Indri框架中,它們是平滑過的多伯努利分布,該分布是對文檔表示的一個建模。網絡中可能會有不止一個模型節點,與同一文檔的不同表示相關聯,如上圖所示,模型節點包括title,body,h1等3個模型節點,分別為文檔的title,body,h1部分的表示,這樣就允許模型通過不同的文檔表示來進行預估,合并。
這里需要計算 P(M|D),
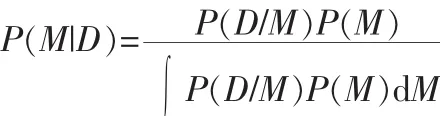
特征表示節點Representation concept nodes(r):特征表示節點是與上述文檔表示中提到的特征向量直接相關的二進制隨機值。這里,同樣的特征節點可能會在網絡中出現多次,因為每個相同的特征節點可能會有一個不同的父節點。
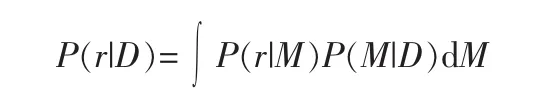
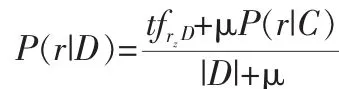
查詢節點Belief nodes(q):查詢節點是用來合并特征節點或者其他查詢節點的二進制隨機值。每個查詢節點關聯到不同的條件概率表,允許節點以多種不同的方式合并。查詢節點是根據Indri的結構化查詢動態的添加到網絡中,因此網絡拓撲是隨著每次查詢改變的。這使得網絡很強大,根據不同的查詢式,使用不同的打分方法。
信息需求節點Information need node(I):信息需求節點可以看作一個簡單的查詢節點,將所有的查詢節點合并到一個節點,這個節點作為rank的基礎[5]。
也就是說 rank的依據是 P(I=1|D,alpha,beta)。
例如一個查詢:#weight(2.0#or(#1(north korea)iraq )1.0 policy),查詢的意思大概是 “包含韓國或者伊朗以及policy的文檔,并且包含north korea或者iraq所占的比重系數為2.0,而包含policy的比重系統為1.0”。推理網絡如圖2所示。
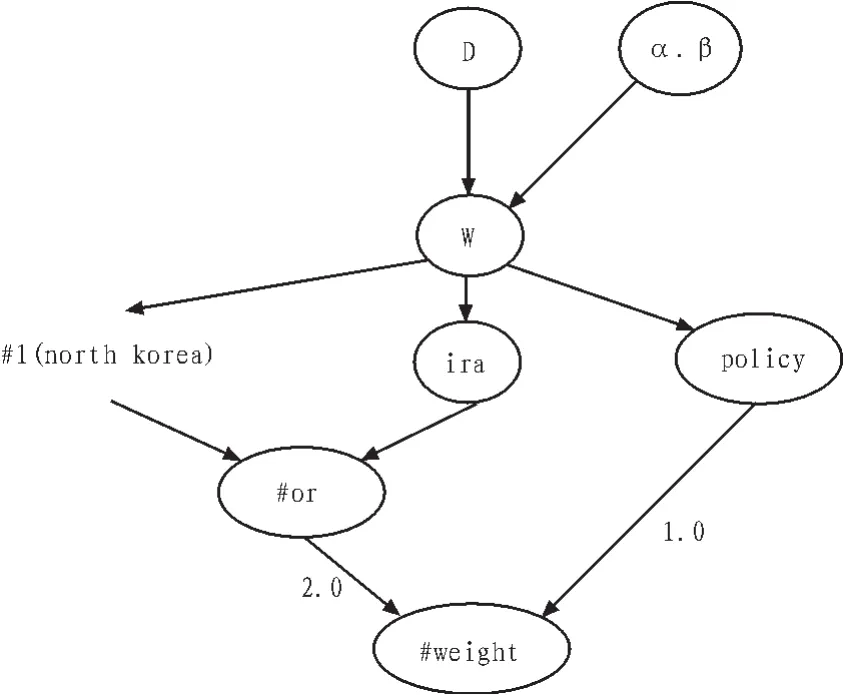
圖2 推理網絡Fig.2 Inference network
再例如一個查詢:#combine( #uw8( hurricane wind ).(title)damage),這個查詢的大概意思是“文檔題目域中包含一個8個詞的窗口,窗口中可以無序的包含hurricane和wind兩個詞,并且文檔中包含damage這個詞”。推理網絡如圖3所示。

圖3 推理網絡Fig.3 Inference network
2 Indri查詢語言
為了充分利用上面提到的檢索模型,Indri提供了一套查詢語言可以表達復雜的概念。Indri查詢語言是一種結構化查詢語言,是由一些operation組成的,每個operation代表了推理網絡中的一個查詢節點(即q節點)[6]。
Operation可以分為以下幾類:
1)Basic operation
第三,時間和空間延展性的變化帶來的影響。互聯網上沒有時間和空間的限制,企業只需花費較少的成本就可以加入到全球信息網絡和貿易網絡中,與消費者進行溝通,將產品的信息傳遞到消費者中去。網絡商城的空間可以無限擴張,可以陳列無限多的商品,消費者通過互聯網可以用很低的價格選購商品,所看到的商品比任何一間大商場的產品都多,方便消費者進行商品的比較和擇優。
Indri查詢語言的基本操作是繼承Inquery結構化查詢語言的,舉一些簡單的例子:
#uwN(t1 t2…)包含N個單詞的無序窗口
#odN(t1 t2…)包含N個單詞的有序窗口
#combine(q1 q2…) 合并查詢q1和q2
#weight(w1q1 w1q2…) 合并查詢q1和q2并且設置了每個查詢的權重
#filrej(c s) 當c不滿足的情況下計算表達式s
2)Field operation
這類操作符是為了支持結構化文檔設計的。最簡單的形式,比如term.field,意思是term只有出現在field時才是與查詢相關的。
域可以是文檔中的任何打了標簽的信息。例如可以是文檔的一大段(如一個章節),一小段(如一個自然段),或者只有幾個句子(如名詞短語等)。一個域也可以多次出現在文檔中。
例如wash.np就可以用來實現這樣的查詢,“查找出現在名詞短語中的wash”。
3)Extent retrieval
Indri也支持用域來在某一區域中打分。例如查詢#combine[field](q1,…qn),在 field 指定的區域中對(q1,…qn)進行打分和排序。這樣可以方便地支持類似段落查詢或者語句查詢等這樣的需求。
4)Date and numeric retrieval
Indri來識別數字相關的性質,包括日期等。為了查詢數字相關的性質,Indri提供了#less,#greater和 #equal等操作。對 于 日 期 的 查 詢 ,Indri提 供 了 #date:before,#date:before 和#date:before 等操作。
一些相關操作符的計算如下[5]:
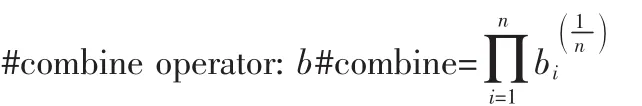

3 結 論
Indri的檢索模型合并了推理網絡模型和語言模型,可以比較好的支持結構化查詢和推理網絡節點的預估,里面還涉及了多伯努利分布,貝葉斯方法等數學行比較強的推導過程,從測試結果來看,查詢效果比較好,具有較大的參考實用價值。
[1]Strohman T,Metzler D,Turtle H,et al.Indri.A language model-based serach engine for complex queries,IA 2005[C]//Proceedings of the 2nd International Conference on Intelligence Analysis (to appear),2005:5-10.
[2]Strohman T.Dynamic collections in Indri[C]//Technical Report IR-426, University of Massachusetts Amherst,2005:124-125.
[3]Strohman T.Low Latency Index Maintenance in Indri[C]//IR-503, University of Massachusetts Amherst,2006:54-58.
[4]Metzler D,Croft W B.Combining the language model and inference network approaches to retrieval[C]//Info.Proc.and Mgt,2004,40(5):735-750.
[5]Metzler D,Lavrenko V,Croft W B.Formal multiple Bernoulli models for language modeling[C]//2004:540-541.
[6]Zhai C,Lafferty J.A study of smoothing methods for language models applied to information retrieval ACM Trans.Inf.Syst[C]//2004:179-214.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
