句法分析與消解PCFG改進
2012-07-13 03:06:40金新生
電子設計工程 2012年4期
金新生
(河南省財經學校 河南 鄭州 450012)
句法分析是自然語言處理的一個基本問題。許多自然語言處理任務,比如機器翻譯、信息獲取、自動文摘等都要依賴句法分析的精確結果才能最終獲得滿意的解決。隨著信息社會的到來,人們對自然語言處理的需求日益迫切,因而對句法分析的研究具有重要的意義。
所謂句法分析是根據給定的語法,自動地推導出句子的語法結構,即句子所包含的句法單位和這些句法單位之間的關系。句法分析的目的主要有兩個,一個是確定句子所包含的譜系結構,另一個是確定句子的各成分之間的關系。目前為止,句法分析的研究大體分為兩種途徑:基于規則的方法和基于統計的方法。而這兩種途徑目前分析的精確度仍然不高,離實際應用還有不少差距。
1 概率上下文無關文法
概率型上下文無關文法[1](Probabilistic Context Free Grammar or Stochastic Context Free Grammar)是最早也是最常用的句法分析分析模型,它是上下文無關文法的展,將CFG的每一條規則與概率組合,就構成PCFG。
PCFG的分析過程與非概率型上下文無關文法相同,也是從非終結符S開始擴展。通過概率型上下文無關文法賦予每棵分析樹一個概率,當句子具有結構岐義時,可以利用該概率來選擇句子的分析結果t*,即

分析樹t的概率就是生成t所用到的所有產生式的條件概率的乘積:

其中,r是產生式,D(t)表示用于生成分析樹t的有序產生式集合。
1.1 規則的概率
概率上下文無關語法跟非概率的上下文無關語法基本,區別只是在于給每條句法規則附加一個概率值。所給的概率值可以是來自語感,或者來自語料統計。不管來源如何,都必須滿足:左部分符號相同的若干條規則,其概率之和等于1。
1.2 語句的概率
一棵分析樹的概率,等于推導出這棵分析樹時所使用的各條規則的概率的乘積。如,“咬/vt死/adj了/utl獵人/noun的/de狗/noun”得到的兩棵分析樹的概率計算如下所示[3]:


結果表明,前一種分析的概率小于后一種分析,這主要是因為在我們的語法中,由名詞類短語構成句子的概率(0.1)小于由動詞性短語構成句子的概率(0.2),由動詞結構加“的”構成“的”字結構的概率(0.4)小于由名詞性結構加“的”構成的“的”字結構的概率(0.6)。
同時也表明,這個詞串分析為合法的句子(S)的概率是:

這個概率也就是語句“咬/vt死/adj了/utl獵人/noun的/de狗/noun”的概率。如果一個詞串不合語法,其概率為0。
對于給定一個語句W=w1w2…wn和一部概率上下文無關語法G,有以下3個基本問題需要研究:
1)如何快速計算由語法G產生語句W的概率P(W|G)?
2)如果語句W有岐義的,如何快速選擇概率最高的分析?
3)如何調整語法G的參數(即每條規則的概率),使得P(W|G)最大?
解決這些問題,需要引入兩個概念:內部概率(Inside Probability)和外部概率(Outside Probability)。
1.3 內部概率
設A是語句推導過程中用到的一個非終結符,它的起點為i,終點為j;A的內部概率就是用語法G從A推導出詞串wi…wj的概率。
我們先假定G中所有規則都遵從喬姆斯基范式,即,假定從A開始推導時所用的規則或者形如 “A→a”,或者形如“A→B C”(A,B,C)是非終結符,a是終結符)。 當規則右部是一個終結符時,有i=j,A的內部概率就是規則“A→n”的概率:


內部概率的計算是遞歸的,求一個非終結符的內部概率,需要先求出它的所在局部分析的各構成成分的內部概率。有了內部概率的概念,就可以順利地解決上面提到的第1個問題。所謂“由語法產生語句W的概率”,就是α1,n(S)的內部概率。
有了內部概率的概念,上面提到的第2個問題也很容易解決。如果非終結符A是多個起點、終點都相同的局部分析的根,我們總是選擇內部概率最大的那個局部分析,作為以后在若干個內含式岐義分析中排除那些概率較低的分析。如果起始符S是起點為1,終點為n的局部分(整個句子的分析可看成是一個特殊的局部分析)的根,并且這樣的局部分析有若干個,我們最后就選擇內部概率最大的那個局部分析作為輸出結果。
1.4 外部概率
解決第3個問題(規則概率的調整)需要用到外部概率的概念。非終結符A的外部概率,是指給定概率上下文無關語法G和語句W時,推導出A的上下文的概率。
先考慮A是整個語句捆綁后的符號(或者從生成的觀點看,是由A推導出整個語句)這一特殊情形,這時A(在句子范圍內)沒有上下文,如果A=S,A的外部概率為1.0,否則為0。

等式右邊是一個克羅奈克函數,兩參數數值相等時函數值為1,否則為0。
接下來,再進行一般化處理。A的外部概率涉及3個方面:
1)A做了哪個局部分析的成分,因為這個局部分析的上下文(姑且稱之為“大語境”)必然也是A的上下文,它的外部概率必須影響A的外部概率;
2)這個局部分析所使用的規則的概率;
3)這個局部分析的構成成分中,A以外的其他構成成分的內部概率的乘積,因為其他構成成分也是A的上下文。
把這3種概率相乘,就得到A處于這個局部分析中的外部概率。如果只有一個這樣的局部分析,那么它就是A的外部概率;如果存在多個這樣的局部分析,可以用類似的方法得到A在每一個這樣的局部分析中外部概率,經求和就得到A的外部概率。這樣,當使用的規則不限于喬姆斯基范式時,外部概率的計算公式可重新表達為:

其中,是所有以A(A的起點和終點分別是i和j)為構成成分之一的局部分析的集合,C是這種分析的根,first(e)和last(e)是這種局部分析的起點和終點,rule(e)是這種局部分析用的規則,rhs(e)是這條規則的右部符號,即該局部分析的構成成分;B是該局部分析的外部概率;由此層層上推,必須先求出整個詞串的概率。
1.5 規則使用的期望次數
現在我們來討論如何調整語法G的參數。一個樸素的想法是,從訓練語料(由已經標注句法結構的句子組成)中計算每條規則的使用次數;某規則的使用次數除以跟它左部相同的全部規則的使用次數之和,就是該規則的概率[1-2]。即:

其中,A是一個非終結符;ξ和μ都是由終結符和/或非終結符組在成的符號串,后者包括前者。
當規則不限于喬姆斯基范式時,計算期望次數的公式是:

其中,P(w1,…,w2)是整個語句的概率,即 α1,n(S)。 顯然,如果這個概率為0(語句不合語法),就不應計算該語句分析過程中任何規則的使用次數。如果語句的概率大于0,我們則對于該規則的每一次使用,都計算該符號的外部概率、該規則的概率以及每個構成成分的內部概率,并且將這些概率相乘,然后求和,除以該語句的概率,便得到使用該規則的期望次數。
1.6 語法參數的調整
概率上下文無關語法的第3個基本問題是,如何調整語法G的參數,使得P(W|G)最大。為此,開始時可以隨機地給每條規則賦予一個概率(但左部相同的規則的概率之和必須為1),得到語法G0;接著從訓練語料用公式計算每一條規則的期望次數,并重新估計每一條規則的概率,得到語法G1。重復這些步驟,得到語法G2,G3,……,直到規則的概率收斂于最大似然估計值。每得到一部新的語法,都有可能使得訓練語料中的平均概率有增加,因為語法中規則的概率更趨向于合理。不過,這種優化仍是局部的,并且是跟語料的性質有關的。如果語料的代表性不夠,就很難說規則的概率估值是否合理。舉一個極端的例子,假定訓練語料訓練語料僅僅包含語句“孩子/noun喜歡/vt狗/noun”,使用的是本章所列的句法規則,最后的結果“S→NP”、“S→VP”等規則的概率為 0,也就是說,把這些規則都“優化”掉了。所以語料的規模要有一定的代表性。
1.7 算法基本步驟
1)隨機地給每條規則賦予一個概率,得到語法G0;
2)建立局部分析;
3)計算合法句子的概率;
4)獲取外部概率;
5)獲取規則使用的期望次數;
6)重新估計規則概率,得到語法Gi;
7)若得到的概率已收斂,則終止,否則轉到步驟2)。
2 改進過的PCFG算法
2.1 用句子內部短語結構搭配+短語內部語義相關度進行句法消岐[2-4]
研究這兩個句子:
例1:維修/vt圖書館/noun的/de空調/noun
從圖 1A中結構抽取可得:“維修空調”(VP→VC NP,動賓結構),“XX 的空調”(定中結構),明顯地“的”字結構在這樣并沒有起決定性作用。查 《知網》、《現代漢語語法信息詞典》數據庫、《現代漢語搭配詞典》、《現代漢語實詞搭配詞典》,有“維修電機(動賓結構)”,而“空調”與“電機”的相似度為0.390 947,比較高,因此維修空調相關度為0.470 947,同樣比較符合動賓結構搭配。從圖1B中結構抽取可得:“維修圖書館”(VP→VC NP,動賓結構),“XX 的空調”(定中結構),查上述知識庫:裝修房子(動賓結構)。“房子”與“圖書館”相似度為0.111628,而“裝修”與“維修”相似度為0.186047,所以“維修”和“圖書館”的相關度只有:0.106047。通過計算,我們很容易選擇圖1 A的分析。
例2:裝修/vt圖書館/noun的/de工人/noun

圖1 “維修圖書館的空調”結構分析Fig.1 Structure analysis of“repair of the library’s air conditioning”
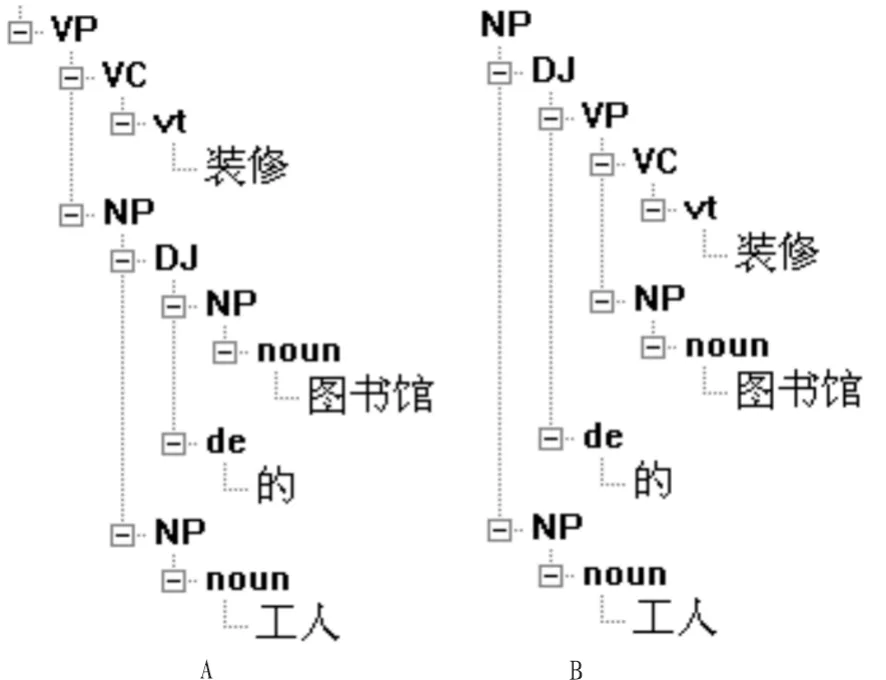
圖2 “裝修圖書館的工人”結構分析Fig.2 Structure analysis of workers of the library’s renovation
同樣方法,我們可以輕松選擇圖2B的分析。
由此可知,句子結構內部的短語結構搭配(結構相關)和由詞組的短語語義內部的相關度對消解這種句型岐義起決定作用。
2.2 利用邏輯相關解決岐義
再看看下面的句子:
例3:
1)孩子/noun喜歡/vt穿/vt好/adj衣服/noun
2)天/noun 很/adv 冷/adj,/jw穿/vt好/adj衣服/noun
從結構分析來看,利用詞語搭配和語義相關度很難排岐。 但“天冷”→“穿好”,“喜歡”→“好衣服”,存在邏輯相關。
2.3 利用句子間成分前后相關進行消岐
考察下句:
例句4 I saw a girl with a telescope

圖3 “喜歡穿好衣服”的結構分析Fig.3 Structure analysis of people being fond of fashion dress
根據上面實驗結果,有3種意思:(為了能正確表達,本文為它加了上下文)
1)我用望遠鏡看到一個女孩(I took the telescope when I went out this morning,今早我出門時帶上了望遠鏡,分析這個句子結構說明“我”與“望遠鏡”實際相關。)
2)我看到一個女孩和一個望遠鏡 (That telescope placed on goods,那個望遠鏡放在貨架上,說明望遠鏡與女孩實際意義距離較大,實際相關度小。同時沒有找到與“我”的特殊相關關系。)
3)我看到一個女孩帶有望遠鏡。(Looked carefully,the telescope was in girl’s hand仔細一看,望遠鏡在女孩手中。說明望遠鏡與女孩實際存在相關。)
綜上所述,我們可以定義句子成分結構語義關聯度來進行句型消岐[2-3]:

其中:RPhraseStruct是句子總相關度;RPhraseStruct是短語搭配相關度,符合的取 1,不符合者取 0;R(Wi,Wj)phrase短語內部兩個詞匯意義相關度,可利用公式計算參考;LogicR是邏輯相關,符合取1,不符合取0,由于邏輯相關目前比較難計算,故此項可暫時省略;RContextInfor句間成分實際相關度,存在則取1,不存在則取0。
利用(9)對PCFG結果進行計算,Rsentence取最大值作為最后輸出,則可有效地解決一些如上述類型的句子岐義。
3 結束語
由于漢語語法層次模糊的特點,所以以往很多學者分別研究的是未登錄詞、分詞、詞類、詞義、句法各階段最優,但是事實表明,未登錄詞、分詞詞類標注等都要不同程度地用到了句子結構信息和上下文語境信息,在不充分考慮到這些因素情況下的“各層最優”隱含著不少錯誤,并且這些錯誤會逐放大,可以想象:若未登錄詞認別錯誤,會對分詞有影響,分詞消歧錯誤,那么后面的所謂“詞類標注、詞義標注、句法分析”全部變成無稽之談。故筆者在研究大量資料后,這種符合人的大腦思維方式的全局回溯式尋優應該是最好的解決辦法,這也是筆者現在正在努力的方向。
[1]劉群,李素建.基于《知網》的詞匯相似度計算[C]//第三屆漢語詞匯語義學研討會,臺北:中文計算語言學,2002.
[2]許云,樊孝忠,張鋒.基于《知網》的語義相關度計算[J].北京理工大學學報,2005,25(5):411-414.
XU Yun,FAN Xiao-zhong,ZHANG Feng.Semantic relevancy computation based on HowNet[J].Journal of Beijing Institute of Technology,2005,25(5):411-414.
[3]陳小荷.現代漢語自動分析——Visual C++實現[M].北京:北京語言文化大學出版社,2000.
[4]詹衛東.面向中文信息處理的現代漢語短語結構規則研究[M].北京:清華大學出版社,2002.
[5]周強.基于語料庫和面向統計學的自然語言處理技術介紹[J].計算科學,1995,22(4):36-40.
ZHOU Qiang.Natural language processing technology based on corpus and for statistics[J].Computing Science,1995,22(4):36-40.
[6]周強,黃昌寧.漢語概率型上下文無關語法的自動推導[J].計算機學報,1998,21(5):387-392.
ZHOU Qiang,HUANG Chang-ning.Chinese probabilistic contextfree grammar automatic derivation[J].Chinese Journal of computers,1998,21(5):387-392.
[7]劉群,張華平,俞鴻魁,等.基于層疊隱馬模型的漢語詞法分析[J].中國科學院計算技術研究所計算科學,2001(4):211-214.
LIU Qun,ZHANG Hua-ping,YU Hong-kui,et al.Chinese lexical analysis base on Hierarchical hidden Markov model[J].Institute of Computing Technology of Chinese Academy of Sciences,2001(4): 211-214.
[8]郭池,陳駿,王啟祥.一種基于語料庫的詞義消岐策略[J].計算機學報,2005(6):99-102.
GUO Chi,CHEN Jun,WANG Qi-xiang.Word sense disambiguation strategy base on corpus[J].Journorl of Computer,2005(6):99-102.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
哲學評論(2021年2期)2021-08-22 01:53:34
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中華詩詞(2019年7期)2019-11-25 01:43:04
電子制作(2018年18期)2018-11-14 01:48:24
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
山東工業技術(2016年15期)2016-12-01 05:31:22
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
