基于Web挖掘的網(wǎng)絡(luò)課程平臺研究
2012-09-27 01:41:42李偉群
電子設(shè)計工程 2012年4期
李偉群
(廣州民航職業(yè)技術(shù)學院 計算機系,廣東 廣州 510403)
基于Web挖掘的網(wǎng)絡(luò)課程平臺研究
李偉群
(廣州民航職業(yè)技術(shù)學院 計算機系,廣東 廣州 510403)
通過分析了目前網(wǎng)絡(luò)課程應(yīng)用中存在的問題,提出基于web挖掘的網(wǎng)絡(luò)課程平臺設(shè)計模型,并重點對Web挖掘系統(tǒng)模塊關(guān)鍵技術(shù)進行介紹。論文對增強網(wǎng)絡(luò)課程應(yīng)用的實用性、可評價性有較大作用。
網(wǎng)絡(luò)課程,Web挖掘,系統(tǒng)結(jié)構(gòu),挖掘方法
網(wǎng)絡(luò)課程沒有準確的定義,一般是指在先進的教育思想、教學理論與學習理論指導下的基于Web的課程,從教育技術(shù)手段來看就是在Internet上通過WWW瀏覽器來學習的課程。通過使用網(wǎng)絡(luò)課程平臺,使學員學習突破時空限制,并增強師生交互性,實現(xiàn)學習開放性,它成為課堂教學的有益補充,為教學質(zhì)量的提高起到推動作用。在國家“教育信息化”和“學習終身化”的教育進程中,網(wǎng)絡(luò)課程更是通過其教學資源的豐富可共享的優(yōu)勢得到教育機構(gòu)的高度重視。
目前,網(wǎng)絡(luò)課程主要包括以下功能模塊:各類學習資源(主要以“發(fā)布”的方式出現(xiàn),包括PPT、案例、作業(yè)等),自我測試(可以自動判分),公告欄,討論區(qū)(聊天室、BBS等),站內(nèi)消息,個別平臺還利用虛擬現(xiàn)實技術(shù)增加了“模擬實驗”模塊等,這些立體化的學習資源為學生的學習提供了很大幫助。但是,在互聯(lián)網(wǎng)資源無限豐富的今天,網(wǎng)絡(luò)課程的學習給教學機構(gòu)也帶來了一系列值得思考的問題:
第一,在師生時空分離的環(huán)境下,學生良好的自我約束能力成為保障網(wǎng)絡(luò)課程學習效果的前提。然而,事實證明,缺乏有效監(jiān)控機制的學習其學習效果難以令人滿意。因此,如何收集學員的在線學習時間、學習情況,并通過平臺給予信息推送、學習監(jiān)督顯得尤為重要和有意義。
第二,“學習資源豐富,知識貧乏搜索”。近些年來,國家倡導建立“學習資源庫”,將網(wǎng)絡(luò)教學資源共享,面對大量的網(wǎng)絡(luò)課程資源,如何讓其變成“知識”是教育界關(guān)注的熱點問題。自然語言處理技術(shù)為“智能搜索引擎”的實現(xiàn)提供了技術(shù)支持。
第三,資源完善,站點改進。根據(jù)學生對學習資源的學習頻率和關(guān)注度,增加、完善、調(diào)整學習資源,解決學生學習問題,同時,根據(jù)學員行為記錄和反饋信息為網(wǎng)站設(shè)計者提供改進依據(jù)。
根據(jù)對學生特征數(shù)據(jù)的分析,將學生進行分類,并進行管理,為其提供個性化服務(wù)。
因此,開發(fā)一個能解決以上問題的網(wǎng)絡(luò)課程平臺顯得尤為重要。論文提出的基于Web挖掘的網(wǎng)絡(luò)課程平臺旨在解決以上問題。
1 基于Web挖掘的網(wǎng)絡(luò)課程平臺設(shè)計
1.1 平臺設(shè)計原理
利用Web挖掘技術(shù)進行網(wǎng)絡(luò)課程平臺的數(shù)據(jù)挖掘,其系統(tǒng)架構(gòu)如圖1所示。
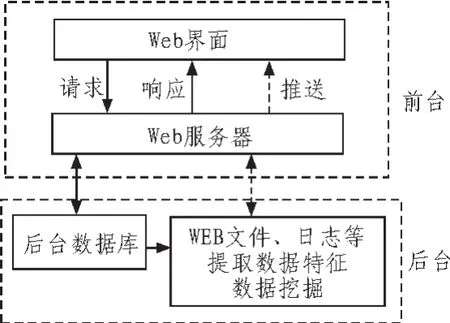
圖1 “Web挖掘”網(wǎng)絡(luò)課程平臺系統(tǒng)架構(gòu)圖Fig.1 Structure diagram of the network course platform based on web Mining
除了搭建一般網(wǎng)絡(luò)課程的功能模塊,在線學習、資源庫、交流互動、虛擬實驗平臺等之外,系統(tǒng)應(yīng)重點解決網(wǎng)絡(luò)課程“有效監(jiān)控”、“資源調(diào)整”、“個性化服務(wù)”幾個問題。其中,Web個性化服務(wù)是指Web站點能夠根據(jù)用戶的喜好和需求自動調(diào)整Web站點的信息組織和表示[1]。解決思路如下:當用戶在Web界面發(fā)送請求時,Web服務(wù)器根據(jù)請求類型選擇是向后臺數(shù)據(jù)庫存取數(shù)據(jù)還是通過Web挖掘系統(tǒng)提取相關(guān)數(shù)據(jù),數(shù)據(jù)庫和Web挖掘系統(tǒng)會向Web服務(wù)器發(fā)送響應(yīng)數(shù)據(jù),同時,Web挖掘系統(tǒng)也會根據(jù)挖掘情況向用戶(學員)推送相關(guān)信息,例如一些學習建議等,為學員提供個性化服務(wù)。
1.2 Web挖掘系統(tǒng)
Web挖掘是指用數(shù)據(jù)挖掘技術(shù)在WWW相關(guān)資源和行為中發(fā)現(xiàn)潛在的、感興趣的信息[2]。Web資源中蘊藏著大量的知識,但是Web數(shù)據(jù)由于數(shù)據(jù)的分布性、異構(gòu)性、動態(tài)性,復雜性,其挖掘相對于普通數(shù)據(jù)挖掘來講較復雜,因此,Web挖掘是目前數(shù)據(jù)挖掘領(lǐng)域及知識發(fā)現(xiàn)領(lǐng)域研究的重要課題之一。
Web挖掘可以根據(jù)挖掘?qū)ο蟮牟煌譃?類[3],即Web內(nèi)容挖掘、Web結(jié)構(gòu)挖掘、Web使用挖掘。Web內(nèi)容挖掘是從Web上的文檔內(nèi)容或描述信息中獲取潛在的、有價值的信息或模式的過程,有兩種方式:Web文檔挖掘,如Web查詢語言Web Log,Web SQL等;搜索結(jié)果挖掘,如對搜索引擎的返回結(jié)果進行聚類。Web結(jié)構(gòu)挖掘是指從Web的鏈接結(jié)構(gòu)中獲取有用知識的過程。對Web站點的結(jié)果進行分析、變形和歸納將Web頁面進行分類,使其有利于信息的檢索[4]。Web使用挖掘主要是利用是從Web訪問日志 (如Web服務(wù)器日志、代理服務(wù)器日志、瀏覽器日志、用戶profiles、注冊數(shù)據(jù)、用戶事務(wù)、cookies、用戶查詢、地址簿、鼠標點擊和其它人機交互數(shù)據(jù)等)中發(fā)現(xiàn)用戶的訪問模式,預測用戶的瀏覽行為,因此,有時又被稱作Web日志挖掘[5]。通常,應(yīng)根據(jù)挖掘?qū)ο蟮牟煌x用相應(yīng)的挖掘技術(shù)。當然,很多時候都是多種技術(shù)綜合運用。
1.2.1 web挖掘系統(tǒng)結(jié)構(gòu)
“Web挖掘系統(tǒng)”主要包括了3個過程:Web資源收集、數(shù)據(jù)預處理、挖掘算法執(zhí)行。如圖2所示。
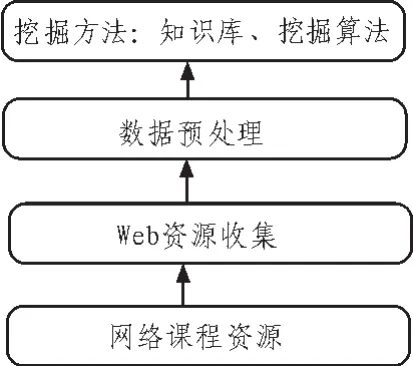
圖2 Web挖掘系統(tǒng)結(jié)構(gòu)圖Fig.2 Structure diagram of Web mining
Web挖掘的網(wǎng)絡(luò)課程平臺應(yīng)該對學生的學習行為進行跟蹤和收集。系統(tǒng)中的Web資源收集模塊主要是記錄學員訪問系統(tǒng)的行為,包括學員登錄的IP地址、訪問頻率、在線學習時間、日志文件、Web緩存等。其主要通過客戶端、代理服務(wù)器端的數(shù)據(jù)采集的數(shù)據(jù)采集,這些數(shù)據(jù)將為有效的挖掘提供支撐。
數(shù)據(jù)預處理是指對Web數(shù)據(jù)進行數(shù)據(jù)清理、用戶識別、會話識別和路徑補充4個部分。其中數(shù)據(jù)清理主要是消解數(shù)據(jù)的不一致性,并將多個數(shù)據(jù)源中的數(shù)據(jù)統(tǒng)一為一個數(shù)據(jù)存儲。用戶識別指從訪問日志中識別出訪問網(wǎng)站的每個用戶。較多見技術(shù)就是日志/站點的方法,并通過一些啟發(fā)式規(guī)則來幫助識別用戶。
接下來,在Web挖掘之前,信息檢索和信息抽取很重要,前者主要是獲取相關(guān)的Web文檔,常見的有模板方式和網(wǎng)頁庫結(jié)構(gòu)化兩種方法。后者從Web文檔中獲取所需的感興趣的信息,并對Web文檔進行整理、排序。
1.2.2 Web挖掘方法
整個挖掘系統(tǒng)最重要的部分就是挖掘方法的選用。模式庫由規(guī)則組成,用于對學員在線學習的活動進行分類、推理。這里對相關(guān)技術(shù)做簡要介紹,為系統(tǒng)模式庫的建立提供了支持。
關(guān)聯(lián)規(guī)則用于發(fā)現(xiàn)用戶之間、頁面之間以及用戶瀏覽頁面和網(wǎng)上行為之間存在的潛在關(guān)系。Apriori算法是一種最有影響的挖掘布爾關(guān)聯(lián)規(guī)則頻繁項集的算法。另外,Agrawal的頻集方法[6],主要是避免需要大量空間存儲中間結(jié)果和需要反復掃描數(shù)據(jù)庫而帶來的算法上的缺陷。
Web分類是一種機器學習的方式,先按照預先定義的分類方法,將每一個Web文檔歸入某一類別。其優(yōu)勢是通過限制搜索范圍提高搜索效率,同時方便用戶瀏覽文檔。典型有VSM方法,其分類效果較好,得到較多應(yīng)用。
Web聚類在智能信息檢索、自動文摘等諸多領(lǐng)域應(yīng)用非常廣泛。Web聚類不同于Web分類,其目標是將相似的文檔盡可能聚在一起,而不相似的文檔分到不同類。挖掘系統(tǒng)中,常采用的有3種聚類方法:基于詞、基于知識、基于信息。其典型算法有層次聚類算法、平面劃分法、基于密度的方法、基于網(wǎng)絡(luò)的方法等。
樸素貝葉斯(NB)在Web挖掘中其思路是將Web文檔中的詞匯應(yīng)用貝葉斯算法進行分類。它的特點是貝葉斯分類中所有的屬性都參與分類,因此所有屬性都潛在地起作用。除此之外還有其他的一些方法,例如支持向量機(SVM)方法等。
利用知識庫對挖掘出來有用信息需要一定的處理,以良好的方式呈現(xiàn)給學員,一般來講有可視化技術(shù)、知識查詢等方式。統(tǒng)計分析以文字、數(shù)字的形式呈現(xiàn)給學員;可視化適合顯示數(shù)據(jù)對象的各種統(tǒng)計值,如某頁面的訪問次數(shù)、頁面跳轉(zhuǎn)的頻率或次數(shù)等或者是表現(xiàn)用戶的訪問序列。例如目前提出的幾種適合在數(shù)據(jù)挖掘過程中使用的查詢語言,如DMQL,WebSSQL、WebLQM 和 Squeal等。
2 結(jié)束語
對網(wǎng)絡(luò)課程進行Web挖掘是一個有巨大應(yīng)用前景的研究方向,同時也是推進教育信息化、提升網(wǎng)絡(luò)課程價值,提高網(wǎng)絡(luò)課程生命力的有效途徑之一。本文提出基于Web挖掘技術(shù)的網(wǎng)絡(luò)課程平臺系統(tǒng)架構(gòu),并對其關(guān)鍵技術(shù)進行介紹。深入研究和改進Web挖掘技術(shù)的各種算法以及設(shè)計更高效的Web挖掘網(wǎng)絡(luò)課程是今后努力的方向。
[1]朱志國,鄧貴仕.Web使用挖掘技術(shù)的分析與研究[J].計算機應(yīng)用研究,2008(1):30-35.
ZHU Zhi-guo,DENG Gui-shi.Analysis and research on web usage mining[J].Application Research of Computers,2008(1):30-35.
[2]鄭巖.數(shù)據(jù)倉庫與數(shù)據(jù)挖掘原理及應(yīng)用[M].北京:清華大學出版社,2011.
[3]Madria S K,Bhowmick S.Research issue in web data mining[C]//Proc.of the lstlnt’l on Data warehousing and knowledge Discovery,Canada:AAAI Press,1999:303-312.
[4]龔漢明,周長勝.一種Web挖掘的框架[J].計算機工程與設(shè)計,2005(8):2118-2130.
GONG Han-ming,ZHOU Chang-sheng.Framework for Web mining[J].Computer Engineering and Design,2005 (8):2128-2130.
[5]高鵬,高嶺,王崢.基于Web挖掘的個性化算法及其在網(wǎng)絡(luò)教學平臺的應(yīng)用[J].計算機應(yīng)用,2005(5):1012-1015.
GAO Peng,GAO Ling,WANG Zheng.Personal recommendation algorithm based on Web mining and its application in Web basededucation[J].ComputerApphcafions,2005(5):1012-1015.
[6] Cohen E,Datar M,F(xiàn)ujiwara S. Finding interesting associations without support pruning[J].Communications of ACM,2002,49(8):122-131.
Research of network course platform based on Web mining
LI Wei-qun
(Department of Computer,Guangzhou Civil Aviation College,Guangzhou510403,China)
By anaylizing the problems in the application of Network course,this paper proposed a network course platform model based on Web mining by analyzing the problems of the application of network course,then mainly introduced the key techniques on Web mining.This paper plays an role on enhancing the practicality and evaluation of the network course’s application.
network course; Web mining; system structure; mining method
TP391
A
1674-6236(2012)04-0133-02
2011-12-16 稿件編號:201112098
李偉群(1980—),女,山西襄汾人,碩士研究生,講師。研究方向:計算機網(wǎng)絡(luò)、圖形圖像。
猜你喜歡
內(nèi)蒙古教育(2021年20期)2021-03-08 01:09:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
計算機教育(2020年5期)2020-07-24 08:53:38
家庭影院技術(shù)(2019年11期)2019-12-09 09:14:30
電力與能源(2017年6期)2017-05-14 06:19:37
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
