一種改進粒子群算法在參數辨識中的應用
2012-07-25 03:20:04程勇
微處理機 2012年2期
關鍵詞:優化
程 勇
(西安科技大學,西安710054)
1 引言
1995年Eberhart和kennedy提出了粒子群優化算法(Particle Swarm Optimization,PSO),通過種群粒子間的配合和競爭達到群體指導搜索目標[1]。該雖然算法簡單、易實現。但是,仍然存在著收斂速度慢等缺點。因此,很多學者針對這一研究熱點提出了改進算法[2-3]。提出一種隨機粒子群優化算法—DPRPSO。結果驗證了DPRPSO算法不易陷入局部最小點和收斂速度快的特性。
2 隨機粒子群搜索算法
2.1 標準粒子群算法
標準PSO算法首先初始化一群隨機粒子(particle),假設在D維搜索空間中,有m個粒子組成一群體,第 i個粒子在 D維空間中的位置表示為xi=(xi1,xi2,...,xiD),第 i個粒子經歷過的最好位置(有最好適應度)記為 pi=(pi1,pi2,...,piD),每個粒子的飛行速度為vi=(vi1,vi2,...,viD)。在整個群體中,所有粒子經歷過的最好位置為 pg=(pg1,pg2,...,pgD),每一代粒子根據下面公式更新自己的速度和位置:
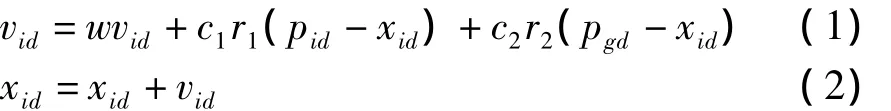
其中,w是慣性權重;c1和c2是學習因子;r1和r2是[0,1]之間的隨機數。公式分別說明了,第一部分粒子先前的速度,即粒子目前的狀態;第二部分認知部分,即從當前點指向此粒子自身最好點的一個矢量,反映了粒子的動作來源于自身經驗的部分;第三部分為社會部分(Social Modal),是一個從當前點指向種群最好點的一個矢量,反映了粒子間的協同合作和知識共享。
2.2 兩群并列隨機粒子群優化算法
結合標準粒子群算法的特點本文提出了一種兩群并列隨機粒子群算法。
2.2.1 隨機搜索
隨機搜索算法最顯著的特點在于其算法本身的簡單性,非常容易進行編程運算,以應用于特定的函數優化問題求解,而且基本上可以不需要預先設定的算法控制參數。
2.2.2 算法介紹
隨機粒子群算法如下:
(1)將粒子群平均分成兩群A、B。
(2)按照(3)混沌初始化 A、B粒子群(共 n個),并且從中選出,適應度高的n個粒子。
Logistic映射如下:
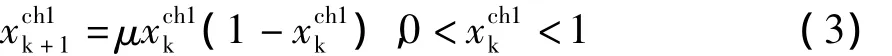
(3)找出全局最優粒子。
(4)進行PSO全局搜索,然后進行最優粒子半徑r范圍內的隨機搜索,如果發現更好的粒子位置就要更新A、B兩群中的最優粒子位置。
同時計算最優粒子的連續p次適應度的變化值,如果小于Δ,而且仍然沒有達到目標誤差,有可能已經陷入了局部最小值。這時,需要把最優粒子的位置在范圍r內,利用隨機算法優化,幫助最優粒子跳出局部最優值。這時的r表示隨機搜索的半徑,開始應該取的較小,當跳出局部最優值失敗時,就需要擴大隨機搜索的半徑。
(5)對適應度差的最后m個粒子進行原位置上的混沌迭代,更新其位置,提高它的適應度。
(6)達到條件,停止搜索。算法結果如圖1所示。
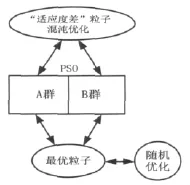
圖1 算法結構圖
3 算法驗證
在參數辨識中以優化為基礎的非線性系統參數辨識方法主要是尋找一組最優的參數向量,使預定的誤差目標函數F(Z)值達到最小[5]。本文定義誤差目標函數為輸出誤差的平方和,即:
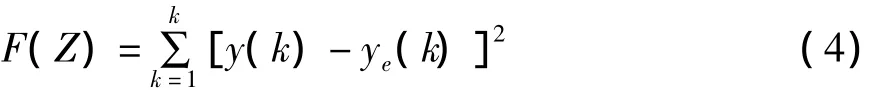
適應值是評定粒子優劣的標準,取式(4)的倒數作為適應度函數。設學習因子c1=1.4962;學習因子c2=1.4962;慣性權重w=0.7298;最大迭代次數MaxDT=1500;PSO粒子個數N=50;收斂誤差終止條件enorm=10-6,RPSO算法中有5個隨機搜索粒子。針對算法提出的算法特性,選取指數函數模型為辨識對象。
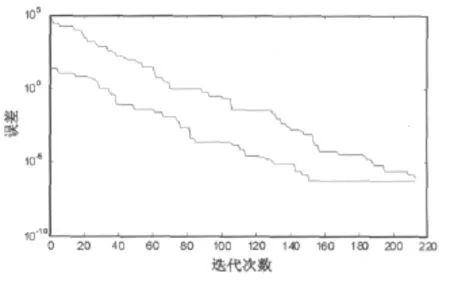
圖2 標準PSO和RPSO算法誤差收斂曲線
在y=aeb+cx中,原模型中 a=4.1240;b=2.1297,c=5.4900。x取值范圍[-5,5]。需要辨識的參數是a,b,c。連續搜索100次,對結果進行統計:
PSO平均搜索229步,成功率74%,達到誤差精度,停止搜索。a=4.113345480867251,b=2.109754600729356,c=5.510000331108581。
RPSO平均搜索153步,成功率95%,達到誤差精度,停止搜索。a=4.123002142000102,b=2.120300570417860,c=5.489655809122442。
圖2給出了搜索的平均結果,藍色的曲線表示RPSO算法,綠色的曲線表示PSO算法。
可以看出,由于混沌算法的初始化,在辨識的開始階段,DPRPSO就比PSO算法具有優勢。隨著算法的進一步展開,本文的算法在辨識過程中,利用兩個并行的PSO集體,不僅提高了算法的效率,而且更加高效的利用了最優粒子的引導特性。因此,這個辨識過程具有更高的效率,更快的速度。
4 結束語
介紹了基于粒子群多樣性和隨機搜索所提出的一種改進型PSO算法DPRPSO。應用在參數辨識中,粒子群算法具有收斂速度快,辨識精度高的特點。最后辨識結果充分說明了DPRPSO是一種有效的PSO改進算法,也證明了該算法的有效性。
[1] Kennedy J,Eberhart R.Particle swarm optimization[C].Proc of IEEE Int Conf on Neural Networks.Perth,1995:1942-1948.
[2] Kennedy J.Small worlds and mega-minds:Effects of neighborhood topology on particle swarm performance[C].Washington DC:Proc of the Congress on Evolutionary Computation,1999:1931-1938.
[3] 陳貴敏,賈建援,韓琪.粒子群優化算法的慣性權值遞減策略研究[J].西安交通大學學報,2006,40(1):53-56.
[4] Mendes R,Kennedy J,Neves J.The fully informed particle swarm:Simpler,maybe better[J].IEEE Trans on Evolutionary Computation,2004(8):204-210.
[5] 馮培悌.系統辨識[M].杭州:浙江大學出版社,1999.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
