基于蟻群算法的MPLS網絡負載均衡研究
2012-09-11 10:17:00王盛明盧秉亮孔宇菲
微處理機 2012年6期
王盛明,盧秉亮,孔宇菲
(1.沈陽航空職業技術學院,沈陽 110034;2.沈陽航空航天大學計算機學院,沈陽 110136;3.沈陽航空航天大學圖書館,沈陽 110136)
1 引言
QoS算法計算出最能滿足服務質量要求的最短路徑,負載均衡算法[1-6]用于計算受到多個約束條件限制的路由,同時還要滿足網絡性能的要求,達到優化網絡資源使用的目的。基于負載均衡策略在路由時同時考慮網絡的拓撲結構,所以該算法有可能選取一條路徑較長但負載較輕的通路,這要好于選取路徑最短但負載較重的通路,它可以使得業務流更均勻地分布在整個網絡內。
文獻[1-6]中的算法有效緩解了最短路由上的擁塞。但考慮到網絡中數據流的到達是隨機的,假設先到的低速率數據流占據大容量鏈路,而后到的高速率數據流因各條路由上的空閑容量均不滿足其帶寬要求而無法得到服務,因而造成了吞吐率及網絡資源利用率的降低。
造成這種局限性的最根本原因是由于這些負載均衡算法都是靜態的,一條路由一旦建立,是不會被其它路由搶占資源的,也不會自動重選路由到更合適的新路由。而在某些情況下,如果一條路由能夠主動將其所承載的數據流重選到另一條路由上去,就能使該數據流原先所在的路由上原本較小的空閑容量變成較大的空閑容量,供給一個高帶寬要求的數據流使用,既能保證原先數據流傳輸不被中斷,又能增大網絡吞吐率和提高網絡資源的利用率。
由此,提出了蟻群算法實現MPLS(多協議標簽交換)網絡負載均衡,增大網絡吞吐率和提高網絡資源的利用率。
2 負載均衡模型
用G=(V,E,C)抽象描述網絡拓撲。V是網絡節點集合,E是網絡鏈路集合,參數C則是E和V的容量和其它一些約束條件限制。用集合K表示網絡中的LSP(標簽交換路徑)請求。對任意k∈K,用三元組(sk,tk,lk)表示,其中 sk,tk分別為入口節點和出口節點,lk表示(sk,tk)業務流的帶寬需求。kij表示 LSPk是否經由鏈路(i,j),(i,j)∈E,hk為LSPk的跳數限制。優化的目標是使最大鏈路利用率最小化,這樣可以使業務流向相對輕載的鏈路轉移,使得由于流量分布不均衡造成擁塞的可能性降到最低[4]。另一方面,在最大鏈路利用率最小化的同時,相應鏈路的剩余帶寬得到最大化,因而網絡對將來到達的連接請求具有更高的接納能力,而不需要對已存在的連接進行重新路由。
如果在很長一段時間內只有少數幾個低速率數據流在發送,則網絡中的大容量鏈路可能長時間處于空閑狀態。同時由于分配給數據流的空閑容量與其帶寬要求非常接近,所以這些算法不能很好地適應數據流的突發性,有可能由于一段時間內數據流突發速率很高而丟包。
3 蟻群算法
3.1 應用蟻群算法進行聚類的原理[7]
蟻群聚類算法是將聚類數據隨機散布到一個二維網格中,模仿n個虛擬螞蟻在二維網格內對聚類數據的搬動。空載的螞蟻遇到一個聚類數據時計算拾起數據概率,滿足拾起條件時拾起數據并隨機運動;滿載螞蟻走到新的位置時計算所背負數據與周圍數據的相似性,滿足條件時放下數據然后繼續移動。重復上述數據搬運過程,實現相似數據的聚集。
給定一路由(信息素)X,把每個路由Xj(j=1,2,...,N)看作是一只螞蟻,根據上述特征進行特征提取,則可將每個路由提取為特征的二維向量,最優路由就是這些具有不同特征的信息素尋找各自類別的過程。設任意一信息素Xi與Xj的相似度即兩者之間的距離為dij,采用歐氏距離計算公式則如下式所示:
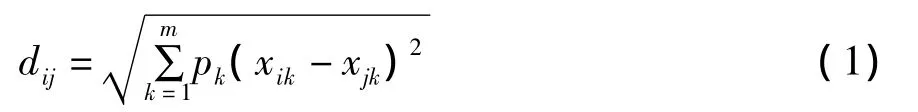
上式中m為螞蟻信息素的特征維數,這里m為2,p是加權因子,根據信息素特征各分量影響聚類的程度確定。通過利用啟發式引導函數可反映信息素之間的相似度,啟發函數越大,信息素歸于相同特征聚類的概率就越大。啟發式引導函數如式(2)所示:

各路徑上的信息素計算公式為:
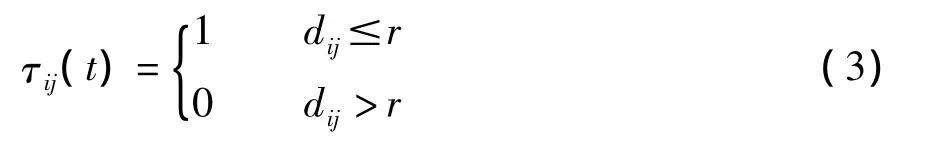
其中r為設置的一閾值,當反應兩信息素之間的距離dij小于設置的閾值時,則螞蟻在這條路徑上的信息激素為1,否則螞蟻在該條路徑上的信息激素為0。
對于任意一信息素(螞蟻)Xi選擇轉移到Xj的轉移概率為:
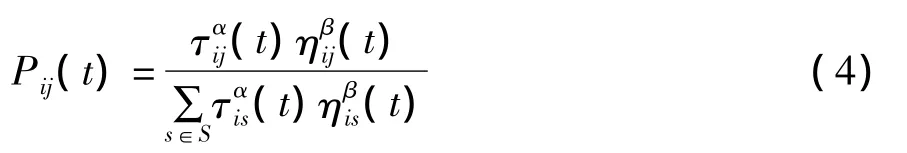
其中ηij(t)是啟發式引導函數,τij為螞蟻在路徑上的信息素,α,β分別是信息素聚類過程中啟發式引導函數ηij(t)和路徑上積累的信息素函數τij對路徑選擇的影響因子。S={Xs|dis≤r,s=1,2,...,N}為每個螞蟻(信息素)的可行路徑集合,s為所有的可選路徑。
隨著螞蟻的不斷移動,各路徑上的信息素量會發生變化。經過一次循環,各路徑上的信息量可根據下式進行調整:

其中,ρ為信息素揮發系數,則1-ρ表示信息素殘留因子,為了防止信息素的無限累積,ρ的取值范圍為(0,1);Vτij為本次循環中路徑信息素增量,由下式計算得出:


其中Q為一大于0的整數,dkj為像素之間的距離(相似度)。
3.2 蟻群算法的流程[7]
下面給出的蟻群算法流程如下:
(1)初始化 α,β,r,Q,ρ等參數,并設置循環次數nc;
(2)根據原始路由設置初始聚類中心,并根據二階微分值將聚類中心劃分為邊緣、目標和中間三類。
(3)計算網絡中每個信息素點(節點)與聚類中心的相似度函數,啟發式引導函數。
(4)開始聚類,對每個信息素與可行聚類中心進行轉移概率選擇計算,選取概率最大的聚類中心進行聚類。
(5)一次蟻群聚類后,更新信息激素,根據所得到的聚類個數,計算各類的聚類中心,計算類間與類間距離,當類間與類間距離之差小于閾值時,合并兩類,更新聚類中心的特征值。
(6)判斷循環次數,若循環次數大于nc,停止運行,否則轉步驟(4)繼續執行。
4 仿真實驗及結果分析
以圖1所示的網絡為例,假設數據源發送的順序是Src3在第0.1s開始發送、Src2在第2.0s開始發送、Src1在第4.0s開始發送,應用網絡仿真軟件NS2.26對原有的負載均衡路由算法與本文所提出的負載均衡蟻群聚類算法進行仿真分析,如圖2所示。
負載均衡路由算法見仿真結果1,負載均衡蟻群聚類算法見仿真結果2,從在第4.0s到第6.0s之間,網絡資源利用率接近于100%。但在第0.1s到第4.0s之間,Src1尚未發送數據包,網絡資源利用率限制在60%以下。
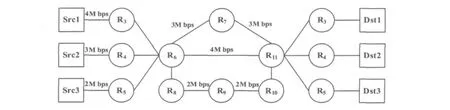
圖1 網絡拓撲結構圖
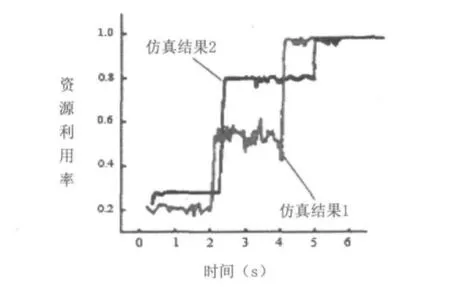
圖2 負載均衡路由算法和蟻群算法
負載均衡蟻群聚類算法在0.2s~2.2s時間內利用率略高于負載均衡路由算法(DLB),DLB在2s~4s時間內在0.6附近波動,負載均衡蟻群聚類算法在2.2s~5s時間內達到了0.8,在5s以后就達到了100%,原因在于蟻群聚類算法完成最后結果需要的時間比負載均衡路由算法長,總體上,負載均衡蟻群聚類算法優于負載均衡路由算法。
5 結束語
負載均衡蟻群聚類算法能不同程度的緩解最短路由上的擁塞問題,其性能優于靜態負載均衡算法和動態負載均衡算法。本文僅研究了無優先級情況下的負載均衡算法,在多優先級情況下的負載均衡算法尚待進一步研究。
[1]杜永波,李毓麟.MPLS的帶優先級的負載均衡算法研究[J].計算機工程與應用,2003(34):165-166.
[2]蔣國明,魏仰蘇,孟兆航.MPLS的基于最小干涉的負載均衡算法研究[J].計算機工程與設計,2007(2):371 -372,476.
[3]張中山,隆克平,程時端.MPLS業務量工程中負載均衡算法的研究[J].北京郵電大學學報,2001(3):46-50.
[4]賈艷萍,孟相如,麻海園,郝自建.基于MPLS流量工程的多路徑約束負載均衡方法[J].計算機應用,2007(3):522-524.
[5]劉紅,白棟,丁煒.應用于MPLS網絡負載均衡的啟發式自適應遺傳算法[J].通信學報,2003(10):39-45.
[6]王紅梅,趙政,趙增華.基于延遲的MPLS網絡流級多徑負載平衡[J].計算機應用,2004(3):4 -5,12.
[7]Sim K M,Sun W H.Ant colony optimization for routing and load - balancing:Survey and new directions[J].IEEE,2003,33(5):33 -41.
猜你喜歡
語言與文化論壇(2019年4期)2019-03-29 06:01:56
電子測試(2018年15期)2018-09-26 06:01:36
中華手工(2017年2期)2017-06-06 23:00:31
中國教育技術裝備(2016年15期)2016-03-01 02:46:18
新教育時代電子雜志(學生版)(2015年31期)2015-12-20 08:29:22
中外會展(2014年4期)2014-11-27 07:46:46
電子設計工程(2014年18期)2014-02-27 12:00:25
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
